一种基于http协议的网络流量的漏洞特征提取系统及其方法
技术领域
1.本技术涉及漏洞特征提取技术领域,尤其涉及一种基于http协议的网络流量的漏洞特征提取系统及其方法。
背景技术:
2.近些年来,网络攻击愈演愈烈,其中软件安全漏洞是黑客攻击利用的主要对象,导致企业风险日益加剧。其中软件漏洞具有持久性、隐蔽性、广泛性等特点,往往会对社会造成极大的危害。所以为了保障网络安全,针对漏洞攻击进行流量分析和检测是不可或缺的。在当前实际业务开展中,对于漏洞攻击流量的特征提取主要依靠安全研究人员逆向分析样本代码,从代码中获得样本通讯协议中相对固定的部分作为特征,并按照相应产品的语言编写成规则添加到产品中。一般情况下,一个中高级分析员在日常分析软件漏洞时,少则几小时,多则好几天,但分析完毕后又有可能由于产品引擎不支持或者协议被加密等原因导致不能添加特征到产品中,白白浪费工时和资源。
3.通过算法自动提取特征则应运而生,例如专利《流量特征提取方法及装置》 (申请号:202010674631.7),但是该方案是对通过从目标流量样本中抽样获得的目标特征提取样本集进行聚类,获得扫描攻击流量样本和非扫描攻击流量样本。但是如果样本集中没有同时包含两种流量的样本,则无法产生有效的特征。同样的,在2020年12月份的论文《cmirgen:automatic signature generationalgorithm for malicious network traffic》中,也是在同时存在正常流量和恶意流量的基础上进行特征提取的。
技术实现要素:
4.为了解决问题,本技术提供一种基于http协议的网络流量的漏洞特征提取系统,包括采集模块、聚类模块、特征提取模块以及转换模块;
5.所述采集模块用于进行数据采集,获取到http协议的网络流量中的 payload数据;
6.所述聚类模块用于对所述payload数据进行聚类,得到属于同一漏洞的 payload数据集合;
7.所述特征提取模块用于在属于同一漏洞的payload数据集合中提取到所述漏洞的有效特征字符串;
8.所述转换模块用于将所述有效特征字符串及其相关信息转换成对应的 yara规则。
9.本技术还提供一种使用上述的基于http协议的网络流量的漏洞特征提取系统的提取方法,其步骤包括:
10.步骤s10,获取到http协议的网络流量中的payload数据;
11.步骤s20,对获取到的payload数据进行聚类,得到属于同一漏洞的 payload数据集合;
12.步骤s30,在同一漏洞的payload数据集合中提取到有效特征字符串;
13.步骤s40,获得有效特征字符串的相关信息,将所述有效特征字符串及其相关信息转换成对应的yara规则。
14.其中,在步骤s10中,通过蜜罐进行http协议的网络流量的数据采集,从得到的蜜罐日志文件中获得payload数据。
15.其中,在步骤s20中,通过计算类编辑距离ed
ab
和相似度similarity的方法进行聚类,具体方法为:
16.选取payload中两个字符串a和字符串b,设长度分别为la和lb,其中, a和b的类编辑距离ed
ab
是指把字符串a转换成字符串b所需要的最少操作数;其中,插入操作代表操作一次,删除操作代表操作一次,替换一次代表操作两次;
17.字符串a和字符串b的相似度similarity=1-ed
ab
/max(la,lb);其中, max(la,lb)是指两个字符串中长度的较大者;
18.设置相似度阈值q,当相似度similarity≥q时,字符串a和字符串b视为属于同一漏洞的payload数据。
19.其中,在步骤s30中,提取有效特征字符串的方法包括规则式提取方法和启发式提取方法。
20.其中,所述规则式提取方法的步骤包括:
21.s301,将所述payload数据划分为url、header和body三部分数据集;
22.s302,逐次从url数据集中提取出最长公共字符串,直至不存在公共字符串为止,将提取出的字符串作为候选串;
23.逐次从body数据集中提取出最长公共字符串,直至不存在公共字符串为止,将提取出的字符串作为候选串;
24.当所述候选串属于linux命令时,判断为有效特征字符串;
25.当所述候选串不属于linux命令时,转到步骤s3021;
26.s3021,选取字符串长度大于检索阈值p(p>4)的候选串,使用谷歌搜索提供的官方api对所述候选串进行搜索,得到排名前n的网页;
27.通过威胁情报和网页内容解析过滤掉与网络安全无关的f个网页,得到个n-f(0≤f<n)个有效网页;若所述n-f个有效网页中,有k(n-f)个包括了所述候选串,则将所述候选串判定为有效特征字符串,其中,k为阈值系数,且1/2<k≤1。
28.其中,使用谷歌搜索提供的官方api进行搜索时,若需要对完整的关键词进行精确搜索,需要在关键词两侧加上双引号。
29.其中,所述启发式提取方法的步骤包括:
30.s311,将网页上的文章内容划分成若干个部分,通过关键词搜索得到与所述漏洞相关的字符,通过使用bert bilstm crf的神经网络模型进行命名实体识别,得到候选串;
31.s312,将得到的候选串在多个payload中进行反查,如果均存在所述候选串,则判断为有效特征字符串。
32.其中,在步骤s311中,使用bert bilstm crf的神经网络模型进行命名实体识别的方法为:
33.s3111,将所述字符输入到bert模型得到词向量,将所述词向量作为双向 lstm的
输入,从前向lstm和后向lstm两个方向抓取上下文信息;
34.s3112,使用条件随机场crf,得到所述字符的类别,得到ner实体。
35.其中,其中bert使用的是多语言版本的,数据格式为bio格式,其中b、i 包含若干个种类,分别为url、cmd或para类别。
36.本技术实现的有益效果如下:
37.本技术结合http协议的数据特点及最新的威胁情报数据,并对特征进行可信验证,从而得出更加准确的特征串如果能够通过数据采集、算法自动提取特征。实现特征的自动提取和分析,分析完成后能够直接转换生成yara规则,就可以直接实现全自动添加特征到产品中,这样能够提高工作效率,从而提高检测产品的有效性。
附图说明
38.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域技术人员来讲,还可以根据这些附图获得其他的附图。
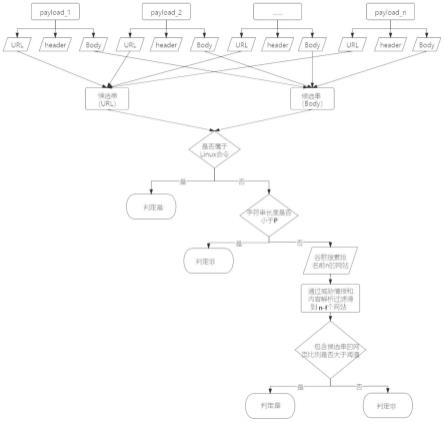
39.图1为本技术一个实施例中payload数据被分为三个部分的示意图。
40.图2为本技术的规则式提取方法判断有效特征字符串的判断流程示意图。
41.图3为本技术的规则式提取方法的一个实施例中候选串通过谷歌搜索得到的搜索结果。
42.图4为本技术的启发式提取方法中bert bilstm crf的神经网络模型结构图。
43.图5为本技术的启发式提取方法的一个实施例中通过ner实体得到的候选串。
具体实施方式
44.下面结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
45.本技术提供一种基于http协议的网络流量的漏洞特征提取系统,其特征在于,包括采集模块、聚类模块、特征提取模块以及转换模块;
46.所述采集模块通过蜜罐进行http协议的网络流量的数据采集,从而得到http协议的网络流量的蜜罐日志文件,并通过数据提取得到payload数据;
47.所述聚类模块对payload数据进行聚类,从而得到同一漏洞的多个payload数据。具体方法为:每次选取两个payload数据求类编辑距离及其相似度。其中类编辑距离指的是由一个字符串转化成另一个字符串最少的操作次数,在其中的操作包括插入、删除、替换。其中插入和删除一次代表操作一次,而替换一次代表操作两次。相似度指的是1-类编辑距离/两个字符串长度的较大者。如果相似度大于一定阈值,则认为两个payload同属于一个类别。
48.具体的,例如,选取payload中两个字符串a和b,设长度分别为la和 lb,其中,a和b的类编辑距离ed
ab
是指把字符串a转换成字符串b所需要的最少操作数;其中,插入操作代表
操作一次,删除操作代表操作一次,替换一次代表操作两次;
49.字符串a和字符串b的相似度similarity=1-ed
ab
/max(la,lb);其中, max(la,lb)是指两个字符串中长度的较大者;
50.设置相似度阈值q,当相似度similarity≥q时,字符串a和字符串b视为属于同一漏洞的payload数据。
51.所述特征提取模块主要分为两种模式,一种是规则式,一种是启发式。
52.规则式提取方法首先将每个payload数据划分为url、header和body 三大部分,其中,如图1所示,是本技术一个实施例中,payload数据被分为三个部分的示意图。
53.由图2的判断流程所示,逐次从url数据集中提取出最长公共字符串,直至不存在公共字符串为止,将提取出的字符串作为候选串;逐次从body 数据集中提取出最长公共字符串,直至不存在公共字符串为止,将提取出的字符串作为候选串;
54.当所述候选串属于linux命令时,判断为有效特征字符串;
55.当所述候选串不属于linux命令时,将候选串中字符串长度小于4的过滤掉,使用谷歌搜索提供的官方api来获取搜索结果(如果不方便获取也可以使用selenium进行动态爬虫),得到排名前n(比如10)个网页,并通过威胁情报和网页内容解析过滤掉与网络安全无关的f个网页。特别需要注意的是,为了保证搜索效果,需要在关键词两侧加上双引号(表示的是精确搜索,即对完整的关键词进行搜索,不对搜索关键词进行分词拆分)。如果在过滤后得到的n-f 个有效网页中绝大多数(大于设定的阈值,比如75%)的网页中均包括了候选串,则将候选串判定为有效特征字符串。
56.例如,在一个实施例中,在body中得到公共串bsh.servlet.bshservlet,通过谷歌搜索得到图3所示的搜索结果,其中,排名最前面的5个网页,经过筛选后依然为5个网页,其中有4个网页均包括公共串,则可将其判定为有效特征字符串。将属于同一大类的有效特征字符串表示成或运算的组合,再将不同类的有效特征字符串表示成且运算的组合。
57.启发式是对多个情报源(如https://blog.netlab.360.com/)当天的文章进行数据挖掘。首先对整篇文章进行内容划分,从而划分成若干个部分。然后通过关键词搜索得到与漏洞分析相关的部分,通过使用bert bilstm crf的神经网络进行命名实体识别。具体来说,如图4所示的模型结构,将每个字符输入到bert模型,从而得到输出的词向量,然后将其作为双向lstm的输入,从正序和反序,也就是前向lstm和后向lstm两种角度抓取上下文信息,接着使用条件随机场crf,得到每个字符对应的类别,最终得到ner实体。其中bert使用的是多语言版本的,数据格式为bio格式,其中b、i包含若干个种类,分别为url、cmd(命令)、para(参数)等类别。
58.具体的,图5中标识了本技术一个实施方式中通过ner实体得到的候选串。
59.将得到的候选串去多个payload进行反查,如果均存在该候选串,则认为是有效特征字符串。
60.得到有效特征字符串后,可以调查到其来源、传播路径等相关信息。再通过特征转换模块,将有效特征字符串及其相关信息转换成yara规则。
61.尽管已描述了本技术的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术范围的所有变更和修改。显然,本领域的技术人员可以对本技术
进行各种改动和变型而不脱离本技术的精神和范围。这样,倘若本技术的这些修改和变型属于本技术权利要求及其等同技术的范围之内,则本技术也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。