1.本发明涉及一种用于运行听力仪器的方法。本发明还涉及一种包括听力仪器的听力系统。
背景技术:
2.通常,听力仪器是一种电子设备,其设计用于支持佩戴它的人(该人被称为听力仪器的用户或佩戴者)的听力。特别地,本发明涉及一种助听器,即专门被配置为至少部分地补偿听力受损用户的听力损伤的听力仪器。其他类型的听力仪器旨在支持正常听力用户的听力,即在复杂的声学情况下改善语音感知。
3.听力仪器通常被设计为戴在用户的耳朵里或耳朵上,例如,作为耳后(behind-the-ear,bte)或耳内(in-the-ear,ite)仪器。就其内部结构而言,听力仪器通常包括(声电)输入转换器、信号处理器和输出转换器。在听力仪器的运行期间,输入转换器从听力仪器的环境捕获声音信号并将其转换为输入音频信号(即,传输声音信息的电信号)。在信号处理器中,对所捕获的声音信号(即,输入音频信号)进行处理,特别是根据声音频率进行放大,以支持用户的听力、特别是补偿用户的听力损伤。信号处理器向输出转换器输出经处理的音频信号(也称为经处理的声音信号)。通常,输出转换器是电声转换器(也被称为“接收器”),它将经处理的声音信号转换成处理后的空气传播声音,其被发射到用户的耳道中。替换地,输出转换器可以是机电转换器,其将经处理的声音信号转换成结构传播的声音(振动),传输到例如用户的颅骨。此外,除了前面所述的经典听力仪器之外,还有植入的听力仪器,例如耳蜗植入器,以及其输出转换器通过直接刺激用户的听神经来输出经处理的声音信号的听力仪器。
4.术语“听力系统”指提供听力仪器运行所需的功能的一个设备或设备组件和/或其他结构。听力系统可以由一个单独的听力仪器组成。作为替换方案,听力系统可以包括听力仪器和至少一个另外的电子设备,该电子设备可以是例如用于用户另一只耳朵的另一个听力仪器、遥控器和用于听力仪器的编程工具中的一个。此外,现代听力系统通常包括听力仪器和用于控制和/或编程听力仪器的软件应用程序,该软件应用程序安装在或可以安装在计算机或诸如移动电话(智能电话)的移动通信设备上。在后一种情况下,通常,计算机或移动通信设备不是听力系统的一部分。特别地,最经常的是,计算机或移动通信设备将独立于听力系统而制造和销售。
5.听力受损的人的一个典型问题是语音感知能力差,这往往是由内耳病理引起的,其导致听力受损的人的个体的动态范围缩小。这意味着柔和的声音对听力受损的听众来说变得听不见(尤其是在嘈杂的环境中),而大声的声音或多或少地保持了他们感知的响度水平。
6.助听器通常通过放大所捕获的声音信号来补偿听力损失。因此,通常使用压缩来补偿听力受损用户的减小的动态范围,即,增加经处理的声音信号的振幅作为输入信号电平的函数。然而,由于信号处理的实时性限制,听力仪器中常用的压缩方法往往会导致各种
技术问题和失真。而且,在许多情况下,压缩并不足以在令人满意的程度上增强语音感知。
7.为了改善佩戴听力仪器的用户的语音感知,ep 3 823 306 a1公开了一种用于运行听力仪器的方法,其中对从听力仪器的环境捕获的声音信号进行语音分析。在语音间隔中,即在时间间隔中(在其中所捕获的声音信号包含语音),确定所捕获的声音信号的振幅和/或音高的至少一个时间导数。如果至少一个导数满足预定义的标准,例如超过预定义的阈值,则经处理的声音信号的振幅暂时增加。已知的方法允许检测和增强有节奏的语音重读(“语音重音”),即语音的振幅和/或音高的变化,从而显著改善听力仪器用户的语音感知。
8.从ep 1 101 390 b1中已知一种包括不同语音增强算法的听力仪器。在此,增加音频流中的语音段的电平。通过分析信号电平的包络来识别语音段。特别地,检测突然电平峰值(突发)作为语音的指示。
技术实现要素:
9.本发明要解决的技术问题是,提供一种用于运行听力仪器的方法,该方法向佩戴听力仪器的用户提供进一步改进的语音感知。
10.本发明要解决的另一个技术问题是,提供一种包括听力仪器的听力系统,该系统向佩戴该听力仪器的用户提供进一步改进的语音感知。
11.根据本发明,上述技术问题分别由根据本发明的用于运行听力仪器的方法和根据本发明的听力系统独立地解决。本发明的优选实施例在随后的描述中描述。
12.根据本发明的第一方面,提供了一种用于运行听力仪器的方法,该听力仪器被设计为支持用户(特别是听力受损用户)的听力。该方法包括例如通过听力仪器的输入转换器从听力仪器的环境捕获声音信号。所捕获的声音信号例如由听力仪器的信号处理器处理(特别是至少部分地补偿用户的听力损伤),从而产生经处理的声音信号。经处理的声音信号例如由听力仪器的输出转换器输出给用户。在优选的实施例中,所捕获的声音信号和经处理的声音信号在被输出到用户之前是音频信号,即传输声音信息的电信号。
13.听力仪器可以是上述任何类型的听力仪器。优选地,其被设计为佩戴在用户的耳朵内或耳朵上,例如作为bte听力仪器(带有内部或外部接收器)或作为ite听力仪器。替换地,听力仪器可以被设计为可植入的听力仪器。经处理的声音信号可以作为空气传播的声音、结构传播的声音或作为直接刺激用户听觉神经的信号输出。
14.在语音识别步骤中,在助听器的正常运行期间,分析所捕获的声音信号以识别到(检测到)语音间隔,其中所捕获的声音信号包含语音。例如,从ep 1 101 390 b1中已知的方法可以用于检测语音和语音间隔。在增强过程中,在所识别的语音间隔期间,经处理的声音信号的振幅周期性地变化,以增强或引起经处理的声音信号中的语音重音。特别地,暂时增加经处理的声音信号的振幅。在此,振幅根据与用户的重读节奏模式(stress rhythmic pattern,srp)一致的时间模式周期性地变化。因此,包含在所捕获的音频信号中的语音适合于用户的srp。需要注意的是,在本发明的范围内,增强过程可以在信号处理的任何阶段应用于所捕获的声音信号。因此,增强过程可以以其初始形式或部分处理形式应用于所捕获的声音信号。
15.说话者的“重读节奏模式”(srp)通常描述了一种单独的加重音节奏,即包括说话
者声音的振幅和/或音高的暂时变化(峰值)的(语言)重读的时间模式,这些变化(有意识或无意识地)用于构造和强调语音。通常,在语音中使用的重读具有节奏结构,这意味着语音的srp以一种不同但相似的方式不断重复,这对说话者来说是独特的。随后,与ep 3 823 306 a1类似,srp的最小可识别单元,即用于构造和强调语音的振幅和/或音高的单个峰值,被称为“语音重音”。通常,这种语音重音具有大约5到15msec(毫秒)的持续时间,并且在彼此之间超过400毫秒的时间距离(对应于小于2.5hz的速率)中发生。
16.本发明基于这样的经验:如果说话者和听者具有相似的srp,则听者更容易理解语音,而如果说话者和听者的srp明显不同,则语音更难理解。利用这种经验,本发明建议人为地扭曲包含在所捕获的声音信号中的语音,使得语音更接近于听者、即听力仪器的用户的srp。已经发现,这可以显著地改善用户的语音感知,从而超过由原始语音失真造成的负面影响。
17.在本发明的范围内,用户的srp可以与听力仪器的运行无关地被预定义或确定。然而,在本发明的优选实施例中,确定用户的srp是作为运行听力仪器的方法的一部分来实现的。为此,优选地,该方法还包括自我声音(own-voice,ov)分析过程,其中用户的srp从包含用户语音的自我声音参考信号(ov参考信号)中确定。
18.注意,上面提到的“自我声音参考信号”(“ov参考信号”)不同于在增强过程中处理的“所捕获的声音信号”。虽然后者是在听力仪器的正常运行期间(特别是在用户沉默的时间间隔期间)获取的,但ov参考信号通常会在听力仪器的正常运行之前的步骤(特别是增强过程)中收集。优选地,在设置步骤期间由听力仪器收集ov参考信号,特别是使用听力仪器的输入转换器。然而,在本发明的范围内,也可以使用听力系统的单独部分在听力仪器外部捕获ov参考信号并可选地分析ov参考信号。例如,使用安装在智能电话上的软件来捕获ov参考信号。在该方法的合适的实施例中,所述设置步骤在初始拟合过程中执行一次,在初始拟合过程中,听力仪器的设置初始地适合于单个用户的需求和偏好。替换地,可以提供设置步骤,使得可以以有规律的间隔或根据用户或健康护理专业人员的要求来重复设置步骤。在本发明的另外的实施例中,在听力仪器的正常运行期间,在用户说话的自我声音间隔(ov间隔)中收集ov参考信号。
19.在本发明的优选实施例中,根据从ep 3 823 306 a1中已知的方法执行增强过程;关于该方法,ep 3 823 306 a1的全部内容通过引用并入本文。在该实施例中,在推导步骤中(该推导步骤在所识别的语音间隔期间并在增强过程之前执行),确定所捕获的声音信号的振幅的至少一个导数和/或音高的至少一个导数,即基频。在增强过程中,将所述至少一个导数与预定义的标准(例如预定义的阈值,参见ep 3 823 306 a1)进行比较,并且将满足所述标准作为语音重音的指示。即,每当至少一个导数满足所述标准时,识别到(检测到)语音重音。通过暂时地施加增益并因此暂时地增加经处理的声音信号的振幅,由此识别的语音重音被增强以更容易被用户感知。
20.然而,根据本发明并且与ep 3 823 306 a1的教导不同,只有与用户的srp匹配的、所捕获的声音信号的那些识别的语音重音被增强。换言之,如果该语音重音(就其在一系列语音重音中的时间出现而言)与用户的srp不匹配,则所识别的语音重音不被增强(即,在识别语音重音时,经处理的声音信号的振幅不被暂时地增加)。通过选择性地增强与用户的srp匹配的那些识别的语音重音(并且通过不增强不匹配的语音重音),包含在所捕获的声
音信号中的语音节奏适应于用户的srp,从而改善用户的语音感知。
21.在本发明的另外的实施例中,替换地或除了仅增强匹配语音重音之外,至少一个人工语音重音被叠加在所捕获的声音信号上(以其初始或部分处理的形式),其中人工语音重音的时间被选择为,使得该人工语音重音在一系列先前(人工或自然)语音重音中与用户的srp匹配。在此,“人工语音重音”是叠加在所捕获的音频信号上的、经处理的音频信号的振幅的暂时地增加,与在该时间点是否在所捕获的声音信号中识别到自然语音重音(即,自然语音中的语音重音)无关。在该实施例的一个变型中,创建一个或多个人工语音重音以填补与用户的srp匹配的一系列自然语音重音中的空白。在该实施例的另外的变型中,与用户的srp相对应的一系列人工语音重音被叠加在所捕获的音频信号上,而与自然语音重音无关。换言之,利用与用户的srp相对应的周期性的加重音信号来调制所捕获的声音信号。因此,包含在所捕获的音频信号中的语音的原始加重音节奏被用户的srp覆盖。因此,语音再次适应于用户的srp,以改善用户的语音感知。
22.优选地,人工语音重音被选择为与自然语音重音相似。为此,在预定的时间间隔(te)内,优选地在5至15毫秒、特别是10毫秒的时间间隔内,重复地增加经处理的声音信号的振幅。特别地,每个人工重音涉及在所述时间间隔内的经处理的信号的振幅的增加。
23.在该方法的合适的实施例中,在ov分析过程中,使用从ep 3 823 306a1中已知的方法来确定用户的srp。因此,使用相同的过程,即通过确定ov参考信号的振幅的至少一个导数和/或音高的至少一个导数,并将该至少一个导数与预定义的标准进行比较,来识别ov参考信号中的语音重音和不同说话者的语音中的语音重音。
24.然而,在本发明的同样优选的实施例中,使用不同的过程来确定用户的srp。这里,在ov分析过程中,确定(声音)振幅调制的调制深度,其被称为ov参考信号的“振幅调制深度”或“amd(amplitude modulation depth)”。通过分析该amd来确定ov参考信号中的语音重音,该amd是在至少一个预定义的调制频率范围内确定的。如果amd满足预定义的标准,特别是超过预定义的阈值,则识别到(检测到)ov参考信号中的语音重音。
25.在ov分析过程的两个实施例中,确定ov参考信号中所识别的语音重音的时间和/或ov参考信号中所识别的语音重音之间的时间间隔。从这些确定的时间和/或时间间隔导出用户的srp。
26.在前述中,术语“(声音)振幅调制”表示ov参考信号的声音振幅随时间的变化。振幅调制深度(amd)描述声音振幅调制的归一化的振幅:
[0027][0028]
其中a
max
和a
min
分别是ov参考信号在给定时间窗内的最大声音振幅和最小声音振幅。如果分析了多个调制频率范围,则针对所述多个调制频率范围中的每一个计算amd(即,amd的一个值),并且测试多个amd值中的每一个是否满足预定义的标准,特别是是否超过相应的阈值。
[0029]
由于振幅调制是与时间相关的量,其可以被描述为(调制)频率的分布。要注意的是,这些调制频率不同于形成ov参考信号的声音频率。优选地,用于计算a
max
和a
min
的时间窗适合于用于确定amd的调制频率范围。例如,所述时间窗可被选择为与调制频率范围的下沿密切对应。例如,如果调制频率范围的下沿是0.9hz(对应于循环时间1.1秒),则可以将归属
的时间窗设置为1.1秒至1.5秒之间的值。通常,时间窗被选择为,使得其覆盖了在相应频率范围内的声音振幅的若干(例如1到5)振荡。
[0030]
在前面提到的实施例的优选的实现中,针对三个调制频率范围分别确定和分析ov参考信号的amd,即
[0031]-12-40hz的第一调制频率范围,其对应于语音中音素的典型速率,
[0032]-2.5-12hz的第二调制频率范围,其对应于语音中音节的典型速率,以及
[0033]-0.9-2.5hz的第三调制频率范围,其对应于语音中语音重音(即重读)的典型速率。
[0034]
优选地,对于这些调制频率范围中的每一个,将相应的amd与相应的阈值进行比较。因此,如果同时超过所有三个调制频率范围的相应阈值(其对于三个调制频率范围可以具有相同的值或不同的值),则识别到(检测到)语音重音。换言之,仅在所述三个调制频率范围中的一个或两个范围内超过相应阈值的事件不被认为是语音重音。这允许以非常高的灵敏度和选择性识别ov参考信号中的语音重音。
[0035]
在本发明的简单而有效的实施例中,导出ov参考信号的所识别的语音重音之间的时间间隔的时间平均值(循环时间)作为用户的srp的表示。这表示最简单的情况,其中srp由一个语音重音和到下一个语音重音的时间间隔组成,使得在用户的语音流中,语音重音大致以等距的时间间隔出现(对于大多数情况,这是真实语音的相当好的近似)。
[0036]
在更精细和更精确的实施例中,从ov参考信号导出更复杂的srp,其包括与多个语音重音相关的时间或时间间隔,以便更精确地表征用户语音。在本发明的范围内,模式识别的统计算法或方法可以用于导出用户的srp。例如,可以使用诸如人工神经网络的人工智能。
[0037]
在该方法的另外的实施例中,仅使用形成ov参考信号的声音频率的有限频率范围来确定ov参考信号中的语音重音。优选地,这个有限频率范围包含ov参考信号的低声音频率,例如在语音中占主导地位的60hz至5khz。因此,在前面提到的实施例中,该方法包括从ov参考信号中提取低声音频率范围,并且仅从ov参考信号的所述低声音频率范围中确定用户的srp。因此,可以避免ov参考信号中包含的高频噪声对语音重音识别的可能干扰。优选地,通过将ov参考信号分成多个声音频带并且选择性地使用多个低声音频带用于识别ov参考信号中的语音重音来提取低声音频率范围。
[0038]
在该方法的另外的实施例中,在语音间隔期间确定用户的srp相对于包含在所捕获的声音信号中的重读的差异程度。在此,仅当所述差异程度超过预定义的阈值时才执行增强过程。换言之,将用户的srp与包含在所捕获的声音信号中的语音的重读进行比较。在此,仅当用户的srp明显不同于包含在所捕获的声音信号中的语音的重读时,才增强或引起所捕获的声音信号中的语音重音。否则,如果发现包含在所捕获的声音信号中的语音的重读与用户的srp非常相似甚至相同,则包含在所捕获的声音信号中的重读不被触及;也就是说,没有增强或引起语音重音。本实施例基于以下经验:如果包含在所捕获的声音信号中的重读与用户的srp非常相似或甚至相同,则根据本发明将所捕获的声音信号匹配到用户的srp既不是必要的,也不是有效的。因此,在后一种情况下,为了不降低声音质量,该匹配应被省略。可以通过根据所捕获的声音信号确定不同说话者(即,不同于用户的说话者)的srp来导出差异程度,优选地,如果适用的话,通过使用用于从ov参考信号确定用户的srp的相
同方法,并且将不同说话者的srp与用户的srp相关联;如果srp由单个循环时间表示,则可以通过计算用户的srp和不同说话者的srp的循环时间的差异来确定差异程度。如果所捕获的声音信号包含多个不同说话者的语音,则可以针对每个不同说话者导出单独的srp。在本发明的范围内,所述差异程度可以反向定义,即针对相似或相同的srp具有高值,而针对不同的srp具有低值。在这种情况下,只有当差异程度低于预定义的阈值时才执行增强过程。
[0039]
在本发明的简单而合适的实施例中,增强过程应用于所有的语音间隔,而与所捕获的声音信号是包含用户语音还是包含不同说话者的语音无关。然而,根据偏好,所识别的语音间隔被区分为用户说话的自我声音间隔和至少一个不同说话者说话的外来声音间隔。在这种情况下,优选地,语音增强过程仅在外来声音间隔期间执行。换言之,在自我声音间隔期间,语音重音不会增强或引起。该实施例反映了这样的经验,即当用户说话时不需要增强语音重音,因为用户知道他或她说了什么,所以感知他或她自己的声音是没有问题的。通过在自我声音间隔期间停止语音重音的增强,将包含自我声音的更自然的声音的经处理的声音信号提供给用户。
[0040]
根据本发明的第二方面,提供了一种具有听力仪器(如先前所述)的听力系统。该听力仪器包括:输入转换器,其被设置为从听力仪器的环境捕获(原始)声音信号;信号处理器,其被设置为处理所捕获的声音信号以支持用户的听力(从而提供经处理的声音信号);以及输出转换器,其被设置为向用户发射经处理的声音信号。
[0041]
通常,听力系统被配置为自动执行根据本发明第一方面的方法。为此,该系统包括:
[0042]-声音识别单元,其被配置为分析所捕获的声音信号以识别语音间隔;
[0043]-语音增强单元,其被配置为在所识别的语音间隔期间,根据与用户的srp一致的时间模式周期性地改变经处理的声音信号的振幅。
[0044]
对于根据本发明第一方面的方法的每个实施例或变型,存在根据本发明第二方面的听力系统的相应实施例或变型。因此,与方法相关的公开也比照地适用于听力系统,反之亦然。
[0045]
具体地,在优选的实施例中,听力系统还包括推导单元,其被配置为,在所识别的语音间隔期间确定所捕获的声音信号的振幅和/或音高的至少一个时间导数。在此,语音增强单元被配置为,如果至少一个导数满足预定义的标准,特别是超过预定义的阈值,并且如果满足预定义的标准的时间与用户的srp兼容,则暂时地增加经处理的声音信号的振幅。
[0046]
附加地或替换地,语音增强单元被配置为通过暂时地增加经处理的音频信号的振幅来在所捕获的音频信号上叠加人工语音重音,使得人工语音重音在一系列先前(人工或自然)语音重音中与用户的srp相匹配。
[0047]
在本发明的另外的实施例中,语音增强单元被配置为在预定时间间隔内重复增加经处理的声音信号的振幅,优选地在5至15毫秒的时间间隔内、特别是10毫秒内。
[0048]
在本发明的另外的实施例中,语音增强单元被配置为在语音间隔期间确定用户的srp相对于包含在所捕获的声音信号中的重读的差异程度;并且仅在所述差异程度超过预定义的阈值时执行增强过程。
[0049]
在进一步的优选的实施例中,听力系统包括声音分析单元,该声音分析单元被配置为从包含用户语音的ov参考信号确定用户的srp。优选地,声音分析单元被配置为
[0050]-通过分析ov参考信号在至少一个预定义的调制频率范围内的振幅调制的调制深度,从ov参考信号确定语音重音;
[0051]-确定ov参考信号的所识别的语音重音的时间和/或ov参考信号的所识别的语音重音之间的时间间隔;和
[0052]-从所述确定的时间和/或时间间隔导出srp。
[0053]
优选地,声音分析单元被进一步配置为
[0054]-针对12-40hz的第一调制频率范围、2.5-12hz的第二调制频率范围和0.9-2.5hz的第三调制频率范围,确定ov参考信号的振幅调制的调制深度;和
[0055]-如果所确定的调制深度同时超过所述三个调制频率范围中的每一个调制频率范围的预定义的阈值,则识别到语音重音。
[0056]
在本发明的另外的实施例中,声音分析单元被配置为导出语音重音之间的时间间隔的时间平均值,作为srp的表示。
[0057]
在本发明的另外的实施例中,听力系统被配置为提取ov参考信号的低声音频率范围。在这种情况下,优选地,声音分析单元被配置为仅从ov参考信号的所述低声音频率范围确定语音重音。
[0058]
优选地,将信号处理器设计为数字电子设备。其可以是单个单元或由多个子处理器组成。信号处理器或所述子处理器中的至少一个子处理器可以是可编程设备(例如,微控制器)。在这种情况下,上面提到的功能或所述功能的一部分可以被实现为软件(特别是固件)。此外,信号处理器或所述子处理器中的至少一个子处理器可以是非可编程设备(例如,asic)。在这种情况下,上面提到的功能或所述功能的一部分可以被实现为硬件电路。
[0059]
在本发明的优选实施例中,声音识别单元、声音分析单元、语音增强单元和/或(如果适用的话)推导单元布置在听力仪器中。特别地,这些单元中的每一个可以被设计为信号处理器的硬件或软件组件,或者被设计为单独的电子组件。然而,在本发明的其他实施例中,上述单元中的至少一个,特别是声音识别单元、声音分析单元和/或语音增强单元或其至少一个功能部分可以在诸如移动电话的外部电子设备中实现。
[0060]
在优选的实施例中,声音识别单元包括用于一般声音活动(即,语音)检测的声音活动检测(voice activity detection,vad)模块和用于检测用户的自我声音的ov检测(own-voice detection,ovd)模块。
附图说明
[0061]
随后,将参照附图描述本发明的实施例,附图中:
[0062]
图1示出了包括助听器的听力系统的示意图,助听器包括:输入转换器,其被布置为从助听器的环境捕获声音信号;信号处理器,其被布置为处理所捕获的声音信号;以及输出转换器,其被布置为向用户发射经处理的声音信号;
[0063]
图2示出了图1所示的助听器的信号处理器的功能结构的示意图;
[0064]
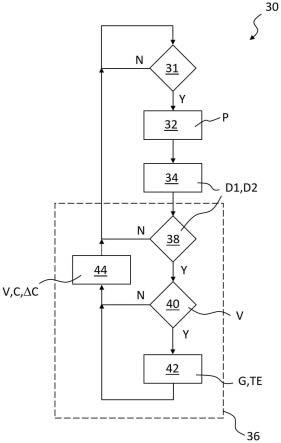
图3示出了用于运行图1的助听器的方法的流程图,该方法包括:在语音增强过程中,暂时地向所捕获的声音信号施加增益,并因此暂时地增加经处理的声音信号的振幅,以增强或引起包含在所捕获的声音信号中的语音中的语音重音,其中语音重音以与用户的预定义的重读节奏模式(srp)一致的时间模式被增强或引起;
[0065]
图4在随时间变化的三个同步图中示出了在包含在所捕获的声音信号中的外来声音语音中识别的一系列语音重音(上图)、指示时间窗的二进制的时间相关变量,在这些时间窗中,预期会出现与用户的srp相匹配的语音重音(中图)、以及用于增强与用户的srp相匹配的外来声音语音的语音重音的所施加的增益(下图);
[0066]
图5示出了用于确定用户的srp的自我声音分析过程的流程图;
[0067]
图6示出了用于确定用户的srp的自我声音分析过程的替换的实施例的流程图;和
[0068]
图7示出了包括根据图1的助听器和用于控制和编程助听器的软件应用程序的听力系统的示意图,该软件应用程序安装在移动电话上。
[0069]
类似的附图标记表示类似的部件、结构和元件,除非另有说明。
具体实施方式
[0070]
图1示出了听力系统2,其包括助听器4,即被配置为支持听力受损的用户的听力的听力仪器,其被配置为佩戴在用户的一个耳朵中或耳朵上。如图1所示,作为示例,助听器4可以被设计为耳后(bte)助听器。可选地,系统2包括第二助听器(未示出),该助听器被佩戴在用户的另一只耳朵中或另一只耳朵处,以向该用户提供双耳支持。
[0071]
助听器4在壳体5内包括作为输入转换器的两个麦克风6和作为输出转换器的接收器8。助听器4还包括电池10和信号处理器12。优选地,信号处理器12包括可编程子单元(例如微处理器)和不可编程子单元(例如asic)。
[0072]
信号处理器12由电池10供电,即电池10向信号处理器12提供电源电压u。
[0073]
在助听器4的正常运行期间,麦克风6从助听器2的环境捕获空气传播的声音信号。麦克风6将空气传播的声音转换成输入音频信号i(也被称为“所捕获的声音信号”),即,包含关于所捕获的声音的信息的电信号。输入音频信号i被馈送到信号处理器12。信号处理器12处理输入音频信号i,即以提供定向声音信息(波束形成),以执行降噪和动态压缩,并且基于用户的听力图数据单独放大输入音频信号i的不同的频谱部分,以补偿特定于用户的听力损失。信号处理器12向接收器8发射输出音频信号o(也被称为“经处理的声音信号”),即包含关于经处理的声音的信息的电信号。接收器8通过将接收器8连接到外壳5的尖端16的声音通道14和将尖端16连接到耳片(其插入到用户耳道中)的柔性声音软管(未示出),将输出音频信号o转换成发射到用户耳道中的经处理的空气传播的声音。
[0074]
如图2所示,信号处理器12包括声音识别单元18,其包括声音活动检测(vad)模块20和自我声音检测模块(ovd模块)22。优选地,模块20和22都被设计为安装在信号处理器12中的软件组件。
[0075]
vad模块20通常检测输入音频信号i中的声音(即,语音,独立于特定的说话者)的存在,而ovd模块22具体检测输入音频信号i中的用户的自我声音的存在。优选地,模块20和22应用本领域中已知的vad和ovd技术,例如,来自us2013/0148829a1或wo 2016/078786a1的vad和ovd技术。通过分析输入音频信号i(以及因此所捕获的声音信号),vad模块20和ovd模块22识别语音间隔,其中输入音频信号i包含语音,这些语音间隔被区分(细分)为用户说话的自我声音间隔(ov间隔)和用户沉默时至少一个不同说话者说话的外来声音间隔(foreign-voice interval,fv间隔)。
[0076]
此外,听力系统2包括推导单元24、语音增强单元26和声音分析单元28。
[0077]
推导单元24被配置为从输入音频信号i导出音高p(即,基频)作为时间相关变量。推导单元24还被配置为对音高p的测量值应用移动平均值,例如应用15毫秒的时间常数(即,用于平均的时间窗的大小),以导出音高p的时间平均值的第一(时间)导数d1和第二(时间)导数d2。
[0078]
例如,在简单而有效的实现中,由
…
,ap[n-2],ap[n-1],ap[n],
…
,给出音高p的时间平均值的周期时间序列,其中ap[n]是当前值,并且ap[n-2]和ap[n-1]是先前确定的值。然后,可以将第一导数d1的当前值d1[n]和先前值d1[n-1]确定为
[0079]
d1[n]=ap[n]
–
ap[n-1]=d1,
[0080]
d1[n-1]=ap[n-1]
–
ap[n-2],
[0081]
第二导数d2的当前值d2[n]可以确定为
[0082]
d2[n]=d1[n]
–
d1[n-1]=d2。
[0083]
语音增强单元26被配置为相对于随后更详细描述的标准来分析导数d1和d2,以便识别输入音频信号i(以及因此所捕获的声音信号)中的语音重音。此外,语音增强单元26被配置为,暂时地对输入音频信号i(以其初始或部分处理的形式)施加附加增益g,并且因此,如果导数d1和d2满足标准(指示语音重音),则增加经处理的声音信号o的振幅。
[0084]
优选地,推导单元24、语音增强单元26和声音分析单元28被设计为安装在信号处理器12中的软件组件。
[0085]
在助听器4的正常运行期间,声音识别单元18,即vad模块20和ovd模块22、推导单元24和语音增强单元26交互以执行图3所示的方法30。
[0086]
在所述方法的(语音识别)步骤31中,声音识别单元18以fv间隔分析输入音频信号i,即其检查vad模块20是否返回肯定的结果(这表示在输入音频信号i中检测到语音),而ovd模块22返回否定的结果(这表示在输入音频信号i中没有用户的自我声音)。
[0087]
如果识别到fv间隔(y),则声音识别单元18触发推导单元24执行下一步骤32。否则(n),重复步骤31。
[0088]
在步骤32中,推导单元24从输入音频信号i导出所捕获的声音的音高p,并如上所述对音高p应用时间平均。在随后的(推导)步骤34中,推导单元24导出音高p的时间平均值的第一导数d1和第二导数d2。
[0089]
此后,推导单元24触发语音增强单元26以执行语音增强过程36,在图3所示的示例中,该过程被细分为四个步骤38、40、42和44。
[0090]
在步骤38中,语音增强单元26分析如上所述的导数d1和d2以识别语音重音。如果识别到语音重音(y),则语音增强单元26进行到步骤40。否则(n),即如果没有识别到语音重音,则语音增强单元26触发声音识别单元18再次执行步骤31。
[0091]
优选地,语音增强单元26使用ep 3 823 306 a1中描述的算法之一来识别输入音频信号i中不同说话者的声音的语音重音,其中用于识别语音重音的前面提到的标准涉及时间平均音高p的第一导数d1与阈值的比较,该比较进一步受到第二导数d2的影响。
[0092]
根据第一算法,语音增强单元26检查第一导数d1是否超过阈值。如果是(y),则语音增强单元26进行到步骤40。否则(n),语音增强单元26触发声音识别单元18再次执行步骤31。阈值根据第二导数d2而偏移(变化),如ep 3 823 306 a1所述。
[0093]
根据第二算法,语音增强单元26将第一导数d1与根据第二导数d2确定的可变权重
因数相乘,如ep 3 823 306 a1中所述。随后,语音增强单元26检查加权的第一导数d1是否超过阈值。如果是(y),则语音增强单元26进行到步骤40。否则(n),语音增强单元26触发声音识别单元18再次执行步骤31。
[0094]
如果步骤38产生肯定的结果(y),则由语音增强单元26执行步骤40。在步骤40中,语音增强单元26检查当前时间(即,在前一步骤38中识别到语音重音的时间点)是否与用户的预定义的重读节奏模式(srp)匹配。为此,例如,语音增强单元26可以检查二进制的时间相关变量v是否具有值1(v=1?)。如果是(y),则指示识别到的语音重音与用户的个人加重音节奏相匹配,则语音增强单元26进行到步骤42。否则(n),语音增强单元26通过随后描述的步骤44触发声音识别单元18再次执行步骤31。
[0095]
在步骤42中,语音增强单元26暂时地将附加增益g应用于所捕获的声音信号。因此,对于预定义的时间间隔(被称为增强间隔te),增加经处理的声音信号o的振幅,从而增强识别到的语音重音。在增强间隔te期满后,附加增益g减小到1(0db)。语音增强单元26通过步骤44触发声音识别单元18执行步骤31,从而再次开始根据图3的方法。如前所述,可在信号处理的任何阶段将附加增益g应用于所捕获的声音信号。因此,其可以应用于最初由麦克风6捕获的输入音频i,但是其也可以应用于在一个或多个前面的信号处理步骤之后捕获的声音信号。
[0096]
如ep 3 823 306 a1中所公开的,附加增益g可以是,例如,
[0097]-逐步递增和递减(即作为时间的二元函数)或
[0098]-随着时间的线性或非线性依赖关系,逐步增加和连续减少,或
[0099]-随着时间的线性或非线性依赖关系,连续增加和减少。
[0100]
最初,变量v被预先设置为常量1(v=1)。因此,当在fv间隔内第一次执行步骤40时,总是产生肯定的结果(y),并且语音增强单元26总是进行到步骤42。
[0101]
此后,在步骤44,语音增强单元26修改变量v以指示预期未来语音重音的时间窗(根据用户的srp)。在每个所述时间窗内,变量v被赋值为1(v=1)。在所述时间窗之外,变量v被赋值为0(v=0)。在图3所示的示例中,用户的srp由用户的自我声音的连续语音重音之间的平均时间间隔(随后被称为循环时间c)表示。因此,时间窗被选择为匹配循环时间c加减其置信区间δc:从执行步骤42的时间点,第一时间窗将开始于c-δc,结束于c δc。类似地,第二时间窗将从2
·
c-δc开始并在2
·
c δc结束,第三时间窗将从3
·
c-δc开始并在3
·
c δc结束,等等。
[0102]
如果步骤31产生否定的结果(n),指示fv间隔的结束或不存在,则变量v被重置为常数1(v=1)。
[0103]
变量v对图3所示的方法30的影响在图4中示出。
[0104]
作为示例,图4的上图示出了随时间t发生的一系列事件,这些事件表征输入音频信号i以及因此所捕获的声音信号。在时刻t1,fv间隔开始。在时间t2、t3、t4、t5和t6,在输入音频信号i中识别到外来声音语音的五个连续语音重音。在时间t7,fv间隔结束。
[0105]
在图4的中图中,示出了变量v的时间依赖关系。图4的下图示出了附加增益g的相应时间依赖关系。
[0106]
可以看出,在时间t2识别到第一语音重音之前,变量v被预先设置为常数1(v=1)。因此,在时间t2,第一次执行根据图4的方法的步骤40和42。
[0107]
在步骤42中,在时间t2,暂时地增加增益g,以增强第一语音重音。
[0108]
在步骤44中,变量v被修改以指示如上所述的一系列时间窗(以阴影区域示出)。第一时间窗在时间t2 c-δc开始,第二时间窗在时间t2 2
·
c-δc开始。每个所述时间窗的持续时间为2
·
δc。如图所示,在每个所述时间窗内,变量的值为1(v=1),而在时间窗外,变量v被设置为常数为零(v=0)。
[0109]
从图4可以看出,第一时间窗过去而没有识别到进一步的语音重音。事实上,识别到第二语音重音的时间t3在第一时间窗与第二时间窗之间。由于在时间t3,变量v被设置为零(v=0),步骤40产生否定的结果(n)。因此,不执行步骤42,并且不增强第二语音重音。
[0110]
识别到第三语音重音的时间t4在第二时间窗内。因此,执行步骤42。随后,在步骤44中,变量v被重置为零并被修改以指示适配的时间窗(其中第一时间窗在时间t4 c-δc开始)。在步骤42,在时间t4,暂时地增加增益g,以增强第三语音重音。
[0111]
对于第四和第五语音重音,在时间t5和t6重复该过程。
[0112]
在时间t7,在外来语音间隔结束时,步骤31产生否定的结果。因此,变量v被重置为常数1(v=1)。
[0113]
可选地,在图3所示的方法30的改进版本中,语音增强单元26(图4)在任何在输入音频信号i中未识别到(自然)语音重音的时间窗结束时创建人工语音重音46。在图4的示例中,可以在第一时间窗结束时在时间t2 c δc创建人工语音重音46,以在与用户的srp一致的时间模式中填充在时间t2和t4识别到的自然语音重音之间的间隙。如图4中的虚线所示,通过以与在时间t2、t4、t5和t6相同的方式暂时地增加增益g,来创建人工语音重音46。
[0114]
优选地,表征用户的srp的变量,即循环时间c和置信区间δc,由听力系统2在助听器4的正常运行之前的设置过程中确定。为此,声音识别单元18、推导单元24和声音分析单元28交互以执行图5所示的自我声音分析过程(ov分析过程)50。
[0115]
在所述ov分析过程50的ov识别步骤51中,声音识别单元18以ov间隔来分析输入音频信号i,即检查ovd模块22是否返回肯定的结果(表示在输入音频信号i中检测到用户的自我声音)。如果是(y),则声音识别单元18触发推导单元24执行步骤52。否则(n),重复步骤51。
[0116]
在步骤52和随后的步骤54和56中,分别类似于图3的方法的相应步骤32、34和38,确定用户的自我声音的音高p(步骤52),由推导单元24推导时间平均音高p的第一和第二导数d1和d2(推导步骤54),并且由声音分析单元28识别用户的自我声音中的语音重音(步骤56)。如果声音分析单元28(y)识别到语音重音,则语音增强单元26进行到步骤58。否则(n),即如果没有识别到语音重音,则声音分析单元28触发声音识别单元18再次执行步骤51。
[0117]
在步骤58中,声音分析单元28确定并统计地评估在用户的自我声音中识别语音重音的时间,并且确定循环时间c和置信区间δc作为用户的srp的表示。例如,可以将置信区间δc确定为用户的自我声音的循环时间c的测量值的标准偏差或统计范围。循环时间c和置信区间δc存储在助听器4的存储器中,以便在助听器4的正常运行期间稍后使用。
[0118]
当已经识别和评估用户的自我语音的足够多的语音重音(例如,1000个语音重音)时,终止过程50。因此,听力仪器4在ov间隔期间捕获的声音信号被用作ov参考信号,以推导出用户的srp。
[0119]
在图5所示的过程50的变型中,步骤52至58在ov间隔和fv间隔中执行,特别是在助
听器4的正常运行期间。因此,在步骤58中,声音分析单元28被应用于外来声音和用户的自我声音,并且分别推导出外来声音和自我声音的循环时间c的单独值。因此,声音分析单元28确定用户的srp和外来说话者的spr。在图3所示的方法30的相应变型中,例如,在步骤44或步骤31中,语音增强单元26通过分别将外来声音和自我声音的循环时间c的值的差与阈值进行比较,来比较用户的srp和外来说话者的spr。在这种情况下,如果发现用户的srp和外来说话者的spr充分不同,即如果外来声音和自我声音的循环时间c的值的差分别超过阈值,则仅增强外来声音的语音重音(步骤42)。否则,变量v被设置为0,这导致跳过步骤42。
[0120]
可选地,分析在fv间隔期间包含在输入音频信号i中的声音以区分多个不同说话者的声音(如果存在的话)。在这种情况下,对于每个单独的不同说话者分别确定srp(即,循环时间c的值)。
[0121]
图6示出了替换的ov分析过程60用于导出表征用户的srp的变量,即循环时间c和置信区间δc。
[0122]
在该过程的ov识别步骤61中,类似于图5的过程的步骤51,声音识别单元18以ov间隔来分析输入音频信号i,即检查ovd模块22是否返回肯定的结果(表示在输入音频信号i中检测到用户的自我声音)。如果是(y),则声音识别单元18触发声音分析单元28执行步骤62。否则(n),重复步骤61。
[0123]
在步骤62中,声音分析单元28确定输入音频信号i的振幅调制a(即,输入音频信号i的时间相关的包络)。此外,声音分析单元64将振幅调制a分成三个调制频带(调制频率的频带),即
[0124]-第一调制频带,包括对应于语音中音素的典型速率的12-40hz范围内的调制频率,
[0125]-第二调制频带,包括对应于语音中音节的典型速率的2.5-12hz范围内的调制频率,以及
[0126]-第三调制频带,包括对应于语音中语音重音(即重读)的典型速率的0.9-2.5hz范围内的调制频率。
[0127]
对于三个调制频带中的每一个,在步骤64中,声音分析单元28根据等式1通过在时间窗内并且对于各自的调制频带来评估最大声音振幅和最小声音振幅,分别确定各自的调制深度m1、m2和m3。例如,对于第一调制频带,所述时间窗被设置为84毫秒的值,对于第二调制频带,所述时间窗被设置为400毫秒的值,对于第三调制频带,所述时间窗被设置为1100毫秒的值。
[0128]
在步骤66中,将调制深度m1、m2和m3与相应的阈值进行比较,以识别语音重音。如果所有的调制频带的调制深度m1、m2和m3同时超过相应的阈值(y),则声音分析单元28识别到语音重音并进行到步骤68。否则(n),即如果没有识别到语音重音,则声音分析单元28触发声音识别单元18再次执行步骤61。
[0129]
在步骤68中,类似于图5的步骤58,声音分析单元28确定并统计地评估在用户的自我声音中识别语音重音的时间。具体地,循环时间c和置信区间δc被确定为用户的srp的表示,如前所述。循环时间c和置信区间δc存储在助听器4的存储器中,以便在助听器4的正常运行期间稍后使用。
[0130]
当已经识别和评估用户的自我语音的足够多的语音重音(例如,1000个语音重音)
时,结束过程60。
[0131]
在分别根据图5或图6的过程50和60的更加改善和更精确的实施例中,在ov间隔期间从音频输入信号i导出用户的更复杂的srp,其包括连续语音重音之间的多个时间间隔。为此,例如,分别在步骤56或66中的一个中识别的语音重音之间的时间间隔被分成n个连续的语音重音的组,其中n是一个整数,其值是变化的(n=2,3,4
…
),以便找到最佳匹配模式。例如,将识别到的语音重音的时间间隔拆分为两个连续语音重音的组、三个连续语音重音的组、四个连续语音重音的组等。对于每个n值,将这些组相互比较。选择彼此最相似的组以例如通过在所选组的相应时间或时间间隔上取平均来导出srp。例如,如果该分析揭示三个连续语音重音的组(n=3)比两个连续语音重音的组(n=2)和四个连续语音重音的组(n=4)彼此更相似,那么选择三个连续语音重音的组来导出srp。在这种情况下,用户的srp可以通过在所选择的组中的相应第一时间间隔上进行平均、通过在所选择的组中的相应第二时间间隔上进行平均以及通过在所选择的组中的相应第三时间间隔上进行平均来导出。在这种情况下,srp由srp的第一语音重音与第二语音重音之间的平均第一时间间隔、srp的第二语音重音与第三语音重音之间的平均第二时间间隔以及srp的第三语音重音之后的平均第三时间间隔表示。
[0132]
在本发明的范围内,可以使用模式识别的其他静态算法或方法来导出用户的srp。例如,可以使用如人工神经网络这样的人工智能。
[0133]
在另外的实施例中,输入音频信号i(特别是在ov间隔期间捕获的输入音频信号i)在被馈送到声音分析单元28之前被分成多个(声音)频带。在这种情况下,优选地,在ov分析过程50或60中选择性地分析输入音频信号i的低声音频率范围(包括声音频带的较低子集)。换言之,一个或多个高声音频带被排除在ov分析过程50或60之外(即不进行分析)。
[0134]
图7示出了听力系统2的另外的实施例,其中听力系统2包括如前所述的助听器4和安装在用户的移动电话72上的软件应用程序(随后表示为“听力应用程序”70)。在此,移动电话72不是系统2的一部分。相反,其仅被听力系统2用作提供计算能力和存储器的外部资源。
[0135]
助听器4和听力应用程序70例如基于蓝牙标准经由无线链路74交换数据。为此,听力应用程序70访问移动电话72的无线收发器、特别是蓝牙收发器(未示出),以向助听器4发送数据并且从助听器4接收数据。
[0136]
在根据图7的实施例中,在听力应用程序70中实现前面提到的听力系统2的一些元件或功能(代替助听器2)。例如,在听力应用程序70中实现被配置为执行步骤38的语音增强单元26的至少一个功能部分。附加地或替换地,可以在听力应用程序72中实现声音分析单元28。
[0137]
本领域技术人员将理解,在不脱离本发明中广泛描述的本发明的精神和范围的情况下,可以对本发明进行如具体示例中所示的多种变化和/或修改。因此,目前的例子在所有方面都应视为说明性的,而不是限制性的。
[0138]
附图标记列表
[0139]2ꢀꢀꢀꢀ
(听力)系统
[0140]4ꢀꢀꢀꢀ
助听器
[0141]5ꢀꢀꢀꢀ
壳体
[0142]6ꢀꢀꢀꢀ
麦克风
[0143]8ꢀꢀꢀꢀ
接收器
[0144]
10
ꢀꢀꢀ
电池
[0145]
12
ꢀꢀꢀ
信号处理器
[0146]
14
ꢀꢀꢀ
声音通道
[0147]
16
ꢀꢀꢀ
尖端
[0148]
18
ꢀꢀꢀ
声音识别单元
[0149]
20
ꢀꢀꢀ
声音活动检测模块(vad模块)
[0150]
22
ꢀꢀꢀ
自我声音检测模块(ovd模块)
[0151]
24
ꢀꢀꢀ
推导单元
[0152]
26
ꢀꢀꢀ
语音增强单元
[0153]
28
ꢀꢀꢀ
声音分析单元
[0154]
30
ꢀꢀꢀ
方法
[0155]
31
ꢀꢀꢀ
(语音识别)步骤
[0156]
32
ꢀꢀꢀ
步骤
[0157]
34
ꢀꢀꢀ
(推导)步骤
[0158]
36
ꢀꢀꢀ
(语音增强)过程
[0159]
38
ꢀꢀꢀ
步骤
[0160]
40
ꢀꢀꢀ
步骤
[0161]
42
ꢀꢀꢀ
步骤
[0162]
44
ꢀꢀꢀ
步骤
[0163]
46
ꢀꢀꢀ
(人工)语音重音
[0164]
50
ꢀꢀꢀ
自我声音分析过程(ov分析过程)
[0165]
51
ꢀꢀꢀ
(ov识别)步骤
[0166]
52
ꢀꢀꢀ
步骤
[0167]
54
ꢀꢀꢀ
(推导)步骤
[0168]
56
ꢀꢀꢀ
步骤
[0169]
58
ꢀꢀꢀ
步骤
[0170]
60
ꢀꢀꢀ
自我声音分析过程(ov分析过程)
[0171]
61
ꢀꢀꢀ
(ov识别)步骤
[0172]
62
ꢀꢀꢀ
步骤
[0173]
64
ꢀꢀꢀ
步骤
[0174]
66
ꢀꢀꢀ
步骤
[0175]
68
ꢀꢀꢀ
步骤
[0176]
70
ꢀꢀꢀ
听力应用程序
[0177]
72
ꢀꢀꢀ
移动电话
[0178]
74
ꢀꢀꢀ
无线链路
[0179]
δc
ꢀꢀ
置信区间
[0180]
t
ꢀꢀꢀꢀ
时间
[0181]
t1
ꢀꢀꢀ
时间
[0182]
t2
ꢀꢀꢀ
时间
[0183]
t3
ꢀꢀꢀ
时间
[0184]
t4
ꢀꢀꢀ
时间
[0185]
t5
ꢀꢀꢀ
时间
[0186]
t6
ꢀꢀꢀ
时间
[0187]
t7
ꢀꢀꢀ
时间
[0188]aꢀꢀꢀꢀ
振幅调制
[0189]cꢀꢀꢀꢀ
循环时间
[0190]iꢀꢀꢀꢀ
输入音频信号
[0191]
d1
ꢀꢀꢀ
(第一)导数
[0192]
d2
ꢀꢀꢀ
(第二)导数
[0193]gꢀꢀꢀꢀ
增益
[0194]
m1
ꢀꢀꢀ
调制深度
[0195]
m2
ꢀꢀꢀ
调制深度
[0196]
m3
ꢀꢀꢀ
调制深度
[0197]oꢀꢀꢀꢀ
输出音频信号
[0198]
p
ꢀꢀꢀꢀ
音高
[0199]
te
ꢀꢀꢀ
增强间隔
[0200]uꢀꢀꢀꢀ
(电)电源电压
[0201]vꢀꢀꢀꢀ
变量
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。