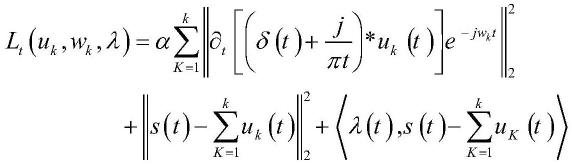1.本发明涉及一种面向水质指标的补全方法,将数据补全看作数据生成,特别是涉及一种基于编码器-解码器和自回归生成对抗网络的水质时间序列缺失数据补全方法。
背景技术:
2.水质指标可以作为判断水污染程度的具体衡量尺度。通过地表水水质自动监测站实时采集获取水质指标数据。水质监测设备容易受到外部环境的影响,如河流腐蚀、恶劣天气等,使得采集的水环境数据缺乏完整性,这极大地影响了水质分析的准确性,因此补全缺失值非常重要。此外,水质指标数据的时间序列具有很强的时间依赖性,多个指标之间存在非常复杂的非线性关系,传统的数据补全方法在水体复杂环境条件下难以对水质指标数据进行有效的补全,因此实现数据插补十分具有挑战性。
3.相较于传统的机器学习方法,深度学习能够有效地提取数据的深层特征,并能够直接挖掘出数据的隐含属性。循环神经网络(recurrent neural network,rnn)、时间卷积网络(temporal convolutional network,tcn)等深度学习模型可以有效地挖掘时间依赖,并且受到生成对抗网络(generative adversarial networks,gan)在图像数据生成方面的成功应用的启发,将rnn与gan结合用于时间序列数据是一种流行趋势。最近,越来越多的研究人员使用gan进行时间序列数据补全。为了提高gan捕捉时间序列的能力,本发明通过自回归网络辅助捕获时间依赖,并将生成器的输入从随机向量更改为有缺失的真实数据。同时,使用了一种特殊的门控循环单元(gated recurrent unit,gru)称为插值门控循环单元(imputed gru,grui),可以有效地处理由于缺失值导致的有效观测值之间的时间间隔不一致的影响。
技术实现要素:
4.针对以上现有技术的不足,本发明拟构建一种改进的生成对抗网络方法,集成生成对抗网络(gan)、编码器-解码器(encoder-decoder)结构和自回归网络(autoregressivenetwork,ar),称为geda。本发明对数据的补全分为两个阶段:1)训练geda网络; 2)生成数据并补全水质数据缺失部分。geda训练采用encoder-decoder结构来生成语义表示提取特征。采用自回归网络获得语义表示的概率分布,通过联合训练帮助编码器和生成器捕捉时间依赖性。数据补全阶段,将有缺失的真实数据输入到生成器中,然后通过生成数据与真实数据之间的重构误差和判别器输出共同调整生成器的输入,使生成的数据尽可能接近真实数据。然后将生成的数据用于补全缺失部分。由于训练数据集是有缺失的,因此为了拟合缺失值导致的有效观测值之间时间间隔不一致的情况,geda 使用grui作为rnn单元,其能够随着时间间隔的增加衰减历史值对当前输出的影响。本发明的目的通过以下技术方案来实现。
5.一种基于时间序列生成对抗网络的水质指标补全方法,该方法包括如下的步骤:
6.1)获取一条河流过去一段时间的监测的水质指标组成的时间序列数据;
7.2)对数据进行归一化,再按预设的滑动窗口大小划分为多个子序列;并划分训练集测试集;
8.3)在2)的基础上,将特征序列数据输入geda模型中,输出完整水质指标数据并补全缺失部分;
9.4)在3)的基础上,对数据进行反归一化,从而获得真正的补全后的完整水质指数据。
附图说明
10.图1一种基于时间序列生成对抗网络的水质指标补全方法组成示意图;
11.图2geda模型结构图。
具体实施方式
12.下面将详细描述本发明各个方面的特征和示例性实施例。下面的描述涵盖了许多具体细节,以便提供对本发明的全面理解。但是,对于本领域技术人员来说显而易见的是,本发明可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本发明的示例来提供对本发明更清楚的理解。本发明绝不限于下面所提出的任何具体配置和算法,而是在不脱离本发明的精神的前提下覆盖了相关元素、部件和算法的任何修改、替换和改进。
13.下面将参照附图1来描述根据本发明实施例的一种基于geda的水质指标补全方法的具体步骤如下:
14.第一步,获取一条河过去一段时间的监测的由水质指标组成的时间序列数据。
15.由于水质自动监测系统实际的监测频次通常为每4小时监测一次,在数据预处理阶段,对水质参数数据筛选,统一调整为4小时等间隔的数据。
16.第二步,归一化处理,并通过滑动窗口划分特征序列数据
17.收集到的数据要做以下滑动窗口处理,以便模型输入。
18.1)对上一步处理后的数据进行归一化。具体的公式如下:
[0019][0020]
其中,x
*
表示归一化后的目标值,x表示需要归一化的数据,x
min
代表数据中的最小值,x
max
代表数据中的最大值。
[0021]
2)按照预定的滑动窗口宽度截取时间序列。
[0022]
第三步,训练geda网络
[0023]
本发明使用一种特殊的时间序列生成对抗网络(geda)来分析水环境相关指标,数据经过上一步处理后,设定输入序列通过插值门控循环单元(grui)作为基本单元构建编码器、解码器、自回归网络、生成器、判别器,通过编码器进行特征提取生成语义表示,解码器根据语义表示重构原始空间的时间序列数据;通过自回归网络辅助生成器和编码器捕获时间依赖;生成器和判别器通过对抗训练学习数据的分布,从而生成符合真实数据分布的完整的时间序列数据,并补全真实数据中的缺失部分。
[0024]
由于缺失值的存在导致两个有效观测值之间的时间间隔是不规律的,为了学习不规则的时间间隔,本发明使用一种针对数据补全的gru单元(imputed gru,grui)。首先引入时间间隔矩阵,表示两个有效观测值之间的时间间隔δ,计算方式如下所示:
[0025][0026]
其中表示ti时刻特征j存在,反之表示数据缺失。根据时间间隔矩阵计算权重衰减向量β表示历史值对当前时刻的影响,随着上一个有效观测值的时间间隔增加,历史值对当前时刻的影响越小,具体计算公式如下:
[0027][0028]
其中w
β
,b
β
为可学习参数,通过负指数函数控制权重衰减向量β在(0,1]之间。与传统gru相比grui引入了权重衰减向量β,具体采用以下公式描述:
[0029][0030][0031][0032][0033][0034]
其中,
⊙
代表点乘,wu,wr,矩阵代表各种门和cell的参数,σ(
·
)和tanh(
·
)是 sigmoid函数和tanh函数。
[0035]
grui提取特征的同时,依据自身的多个门的机制,还可以解决由于多层神经网络的参数传播所导致的梯度消失和梯度爆炸问题。
[0036]
geda模型由编码器、解码器、自回归网络、生成器和编码器组成,编码器用以编码输入序列,解码器用以对编码后的输入序列进行解码;自回归网络用于辅助捕获时间依赖;生成器和编码器用于学习数据分布并生成数据。
[0037]
由于数据数量有限,训练补全模型的关键一步是增强原始数据集,需要提供大量各类的数据作为生成器输入。如果只使用真实数据作为生成器输入则只能生成与之相对的数据。为了解决该问题我们将生成数据加入高斯白噪声作为下一生成过程中生成器的输入,如图2所示。
[0038]
训练过程分为两个阶段预训练和联合训练:
[0039]
1)预训练:根据编码前和解码后的数据的重构误差lr来预训练编码器和解码器;
[0040][0041][0042]
自回归网络通过预测下一时间步的数据捕获时间依赖,使用预测值与目标值的均方根误差(root mean square error,rmse)l
ar
作为损失函数进行训练:
[0043]
c=en(x),c
′
=ar(c)
[0044]
l
ar
=∑||c-c
′
||2[0045]
其中,c表示经过编码器输出语义表示,c
′
是语义表示经过自回归网络后的预测值。
[0046]
2)联合训练:联合自回归网络训练编码器和解码器,辅助编码器生成具有时间依赖的语义表示,如下:
[0047]
min(λl
ar
lr)
[0048]
其中,λ≥0平衡两种损失之间的权重。接着,以对抗的方式训练生成器和判别器,判别器的输入分为两类,一类为编码器输出的语义表示和生成器生成的语义表示,一类为代表数据分布的自回归网络行为(输出),其中每一类又分为有缺失的真实数据和完整的生成数据。传统gan生成器的输入为随机向量,然而随机向量之间的元素是相互独立的不具备时间依赖,因此我们将生成器的输入从随机向量改为有缺失的真实数据。同时本发明的目的是生成与真实数据接近的数据,因此我们在损失函数中加入生成数据与真实数据之间的距离使生成数据与真实数据足够接近。生成器和判别器的损失函数可表示为:
[0049]
lg=∑[log(1-d(g(x))) ξ||de(g(x))-x||1]
[0050]
ld=-∑log(d(en(x)))-∑log(1-d(g(x)))
[0051]
其中ξ为超参数平衡重构误差和判别器损失。
[0052]
当训练生成器时,引入l
ar
使生成器生成具有时间依赖的数据,优化目标如下所示:
[0053]
min(ηl
ar
lg)
[0054]
其中η为超参数平衡自回归网络损失与生成器损失。
[0055]
第三步,生成完整时间序列数据,补全真实数据的缺失部分
[0056]
本发明的目的是生成具有时间依赖的足够真实的数据去补全真实数据的缺失部分。随机向量的每个元素间是相互独立的不具备时间依赖,因此本发明用有缺失的真实数据替代随机向量作为生成器的输入。由于输入是有缺失的,根据重构误差和判别器输出去调整生成器输入以生成完整的与真实数据接近的时间序列数据。l
imputaion
用来表示用来补全数据的合理性。
[0057]
l
imputaiton
=||x
⊙
m-g(x)
⊙
m||
2-γ[d(g(x)) d(ar(g(x)))]
[0058]
其中γ为超参平衡重构误差和判别器输出,并且只计算有效值之间的重构误差,判别器的输入包含生成器输出和自回归网络的输出两部分。
[0059]
对于有缺失的时间序列x,将其输入到生成器中获得语义表示,然后输入到解码器重构获得完整的时间序列数据。将x作为参数通过l
imputation
反向传播调整生成器输入,当损失函数最优时,用生成数据补全真实数据的缺失部分,如下:
[0060]
x
imputed
=x
⊙
m (1-m)
⊙
de(g(x))
[0061]
该水质生成模型可应用于地表水不同河流的ph值、溶解氧(do)、氨氮(nh3-n)、高锰酸盐指数(codmn)等水质指标的生成,实现相关水质数据的精确补全,便于水质预测、水质预警、水污染治理。
[0062]
本发明对上面提出的一种基于时间序列生成对抗网络的水质指标补全方法。应当理解,以上借助优选实施例对本发明的技术方案进行的详细说明是示意性的而非限制性。本领域的普通技术人员在阅读本发明说明书的基础上可以对各实施例所记载的技术方案
进行修改,或者对其中部分技术特征进行等同替换,然而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。