一种基于transformer和密集特征融合的遥感图像变化检测方法及系统
技术领域
1.本发明属于图像处理技术领域,具体涉及一种基于transformer和密集特征融合的遥感图像变化检测方法及系统。
背景技术:
2.遥感影像的变化检测就是从不同时期的遥感数据中,定量地分析和确定地表变化的特征与过程。高分辨率遥感图像由于不同的成像条件以及场景中物体具有复杂多样的特点,具有相同语义概念的物体在不同的时间和空间位置上可能表现出不同的光谱特征,这对变化检测任务仍具有很大挑战。为了准确识别复杂场景中的变化区域,变化检测模型需要识别场景中变化区域的高级语义信息,从复杂的无关变化区域中区分真实的变化。
3.通过利用自注意力对时空中像素对间的语义关系进行建模,可以取得较好的检测效果。2020年,北京航空航天大学的hao chen等人提出stanet,它是一种新的基于度量和时空注意力的孪生网络,将网络划分不同尺度,在每个小区域内嵌入自注意力,用于建模像素间的长距离依赖关系,使用批量平衡对比损失函数缓解样本不平衡的问题,帮助网络提取富含上下文信息的特征。但模型的计算效率很低,计算复杂度很高且随着像素的数量呈二次比例增长。
4.目前许多基于深度卷积神经网络的变化检测方法无法有效捕获像素间远距离的依赖关系的问题,北京航空航天大学的hao chen等人在此背景下提出了双时相图像transformer(bitemporal image transformer,bit)检测算法,在变化检测任务中取得了不错的效果。但由于transformer中多头注意力的每个头只负责输入token序列的一个子集,当子集的通道维度较小时query和key的点积无法构成信息函数,会导致网络性能降低。同时bit采用直接相减的特征融合方式不仅容易对特征结构造成破坏,还可能产生噪音干扰。
技术实现要素:
5.本发明的目的在于克服现有技术中的不足,提供一种基于transformer和密集特征融合的遥感图像变化检测方法及系统,使得双时相多光谱遥感影像的最终变化检测结果更加精确。
6.为达到上述目的,本发明所采用的技术方案是:一种基于transformer和密集特征融合的遥感图像变化检测方法,包括:
7.a、针对已经配准的双时相光学遥感影像,首先通过基于卷积神经网络(cnn)骨干网络进行初步特征提取,其中,骨干网络采用基于改进残差块的resnet18网络;
8.b、采用语义符化器(tokenizer)将步骤a图像特征生成对应的token组,即图像特征可以用token组来表示。
9.c、通过改进的transformer编码器在基于token的时空中建模上下文信息,接着通
过transformer解码器对富含上下文信息的tokens进行解码,重新投影到像素空间获得细化后的原始特征。
10.d、对于transformer解码器增强后的特征图使用密集融合模块(dense fusion module,dfm)对直接相减取绝对值的融合方式进行改进,集成多个特性,帮助网络做出更好的决策,提高模型的鲁棒性。
11.e、在训练阶段,选用二分类交叉熵函数作为网络的损失函数,通过最小化损失函数对模型参数进行优化。网络的预测阶段采用一个浅层的卷积网络,其中分类器由两个带有批量归一化的3
×
3卷积层构成,卷积层的输出通道分别为32、2,分类器后接softmax函数输出变化概率图。
12.所述步骤a中的改进残差块的resnet18,原本的resnet有五个阶段,每个阶段进行2倍下采样,为了减少图像空间细节信息的损失,特征提取仅用resnet18的前四个阶段,并将resnet18中最后两个阶段中的步幅设置为1,随后在resnet末端加入输出通道数为32的逐点卷积对图像进行降维,通过上采样得到输出特征图。
13.所述步骤b,采用孪生的语义tokenizer,使双时相图像共享语义概念,对初步提取到的特征图进行转化,将其表达为紧凑的语义tokens。在nlp中tokenizer把输入的句子划分为其他元素,即单词或短语,并用token向量表示。类似地,本项发明中使用语义tokenizer将初步提取的特征图转化为可视化的单词,每个单词对应一个token向量,通过语义tokenizer学习一组空间注意映射,将特征图转化为紧凑的token组。
14.设分别为对应两个时相遥感图像的输入特征图,h、w、c分别对应特征图的高度,宽度与通道维数。为两组tokens,l为token词汇组的大小。具体流程为:首先对特征图xi(i=1,2)上的每个像素使用逐点卷积得到l个语义组,每个组表示一个语义概念,然后对每个维度为hw的语义组使用softmax函数计算空间注意力图,最后利用注意力图计算xi中像素的加权平均和,得到大小为l的紧凑词汇组,即语义tokensti。
15.ti=(ai)
t
xi=(σ(φ(xi;w)))
t
xiꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
16.其中φ表示输入图像xi与卷积核w进行逐点卷积,σ表示softmax函数。
17.所述步骤c中的transformer编码器、解码器包括:
18.ca、编码器通常由n个相同的层组成,并且每个层又包含两个带有残差结构的子层,其中第一个子层由多头注意力(msa)和层归一化(ln)组成,第二个子层由前馈网络(ffn)和ln组成。解码器与编码器结构类似,不同的是在解码器中存在crossattention的第三个子层,它的作用是与编码器进行信息交互。常规的每个head只负责输入tokens的一个子集,尤其是当token embedding维度较小时,query和key的点积无法构成信息函数,降低网络的性能。本发明采用改进的msa:
19.在softmax函数之后对点积矩阵加入实例归一化来重建多头注意力的多样性能力。通过这样的方式,建模不同头间的交互,同时保持多头的多样性,数学表达式为:
[0020][0021]
式中,q、k、v分别表示查询矩阵、表示键矩阵、表示值矩阵;in表示实例归一化,对h、w维度数据单独进行计算,在帮助网络收敛的同时,能保持每个图像实例及通道间的独立性;conv(
·
)是一个标准的1
×
1卷积运算,它具有跨通道信息交互的特点,用它来建模不同
头之间的交互,达到注意力每个头可以依赖于所有的keys和queries的效果;dk是query和key的向量维度。
[0022]
transformer编码器由ne层改进的多头注意力和多层感知机(multilayer perceptron,mlp)组成,与标准transformer采用的post-ln结构不同,本发明采用pre-ln结构将层归一化ln前置,即层归一化分别放置在msa与mlp之前,可以帮助网络训练过程更稳定,收敛速度更快。
[0023]
transformer中每层l的自注意力的输入为三元组形式,即(q,k,v),其通过(l-1)层的输入计算得到,计算公式如下:
[0024]
q=t
(l-1)
wqꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0025]
k=t
(l-1)
wkꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0026]
v=t
(l-1)
wvꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0027]
式中为q,k,v对应线性投影层的参数,d为通道维数。
[0028]
transformer编码器的核心思想是多头注意力,多头注意力先以并行的方式执行多个独立的注意力头,然后对多个独立注意力头的输出进行拼接,最后经过投影得到最后输出,其优点是可以联合处理不同表示子空间上不同位置的信息,第j个头headj计算公式如下:
[0029][0030]
式中为第j个q,k,v对应线性投影层的参数。
[0031]
经过esa的多个头进行拼接,再经过第二个子层中mlp神经网络得到相应的token序列。
[0032]
cb、本发明采用孪生的transformer解码器来提取每幅输入图像的特征图,和标准的transformer解码器不同,所采用的transformer解码器由nd层multi-head cross-attention(ma)和mlp blocks组成,去掉了多头注意力从而避免了xi中像素间的大量计算,层归一化的位置和编码器一样采用pre-ln结构。在transformer编码器的msa中,查询、键和值来自相同的输入序列,在transformer解码器中,查询来自输入图像特征xi,键和值则来自编码器的输出,即输入图像的每个像素可以通过紧凑的语义tokens组合来表示,输入一个特征序列xi,将其中的像素点作为查询,将tokens作为键,transformer解码器利用每个像素点与token组间的关系得到精确的特征图
[0033]
所述步骤d中的密集特征模块dfm中,dfm模块由两个分支(branch)组成:和分支和差分支,每个分支包含两个流(stream),且分支内部的两个流权值共享。模块利用求和分支可以获得增强的边缘信息,利用差值分支可以生成变化的区域。所有的卷积操作都使用3
×
3的卷积核,在最后的卷积层后使用批量归一化(bn)。除此之外,由于密集连接中存在残差连接,每个流中的最后两个特征可以看作是前一个特征的残差,这在一定程度上修正了前一个特征,使得新的特征图更加对齐。
[0034]
所述步骤e二分类交叉损失函数,计算公式如下:
[0035][0036]
式中,bceloss为二分类交叉损失,为预测值,y为真实值,预测与真实值相差越大,loss越大。
[0037]
一种基于transformer和密集特征融合的遥感图像变化检测方法及系统,包括处理器和存储设备,所述存储设备中存储有多条指令,用于所述处理器加载并执行上述任一项所述方法的步骤。
[0038]
与现有技术相比,本发明所达到的有益效果:本法所述基于transformer和密集特征融合的遥感图像变化检测方法及系统。首先使用基于resnet18的backbone进行初步的特征提取,然后将提取到的两个特征图通过语义tokenize生成两组tokens序列,将序列拼接后输入到transformer编码器,通过改进的多头注意力,在保证多头多样性的前提下,进行不同头间的交互,帮助网络在基于token的空间对图像的全局信息进行建模,接着将富含上下文信息的tokens进行分割后输入到孪生的transformer解码器,重新投影回像素空间,得到两个增强后的特征图,最后通过密集特征融合模块,帮助网络生成变化区域并增强边缘信息。该法使得双时相遥感影像的最终变化检测结果更加可靠、稳健,检测精度更高。
附图说明
[0039]
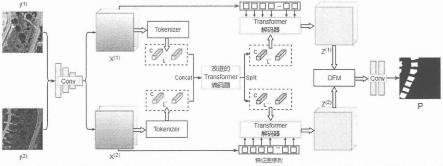
图1是本发明实施例的一种基于transformer和密集特征融合的遥感图像变化检测方法及系统的总体框图。
[0040]
图2是本发明实施例的一种基于transformer和密集特征融合的的遥感图像变化检测方法的中的esa(改进的msa)结构图。
[0041]
图3是本发明实施例的一种基于transformer和密集特征融合的遥感图像变化检测方法的中密集融合模块dfm的示意图。
[0042]
图4是本发明实施例所采用的lever光学遥感影像变化数据集及检测结果。其中图4(a)、(b)、(c)、(d)、(e)分别表示变化前影像、变化后影像、变化参考图、fc-siam-conc算法检测结果、stanet检测结果和本发明检测结果。
具体实施方式
[0043]
一种基于transformer和密集特征融合的遥感图像变化检测方法,主要包括:首先,使用基于resnet18的骨干网络进行初步的特征提取,然后将提取到的两个特征图通过语义tokenize生成两组tokens序列,将序列拼接后输入到transformer编码器,通过改进的多头注意力,在保证多头多样性的前提下,进行不同头间的交互,帮助网络在基于token的空间对图像的全局信息进行建模,接着将富含上下文信息的tokens进行分割后输入到孪生的transformer解码器,重新投影回像素空间,得到两个增强后的特征图,通过密集特征融合模块,帮助网络生成变化区域并增强边缘信息。最后,经过特征融合和浅层的卷积网络生成变化结果图。所提的方法能够提升网络的性能,提高了变化检测的精度。
[0044]
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0045]
如图1所示,是本发明所述基于transformer和密集特征融合的遥感图像变化检测方法的实现流程示意图,包括如下步骤:
[0046]
步骤1:输入同一区域、不同时相的已配准的两幅光学遥感影像,分别记为i
(1)
和i
(2)
。考虑到残差结构可以解决网络层数不断加深时导致的梯度消失问题,本发明初步特征提取骨干网络,采用resnet18网络并对其进行改进,原本的resnet18有五个阶段,每个阶段
进行2倍下采样,为了减少图像空间细节信息的损失,特征提取仅用resnet18的前四个阶段,并将resnet18中最后两个阶段中的步幅设置为1,随后在resnet末端加入输出通道数为32的逐点卷积对图像进行降维,通过上采样得到输出特征图。
[0047]
步骤2:采用孪生的语义tokenizer使双时相图像共享语义概念,对初步提取到的特征图进行转化,将其表达为紧凑的语义tokens。在nlp中tokenizer把输入的句子划分为其他元素,即单词或短语,并用token向量表示。类似地,本项发明中使用语义tokenizer将初步提取的特征图转化为可视化的单词,每个单词对应一个token向量,通过语义tokenizer学习一组空间注意映射,将特征图转化为紧凑的token组。
[0048]
设分别为对应两个时相遥感图像的经过步骤1处理的特征图,h、w、c分别对应特征图的高度,宽度与通道维数。为两组tokens,l为token词汇组的大小。具体流程为:首先对特征图xi(i=1,2)上的每个像素使用逐点卷积得到l个语义组,每个组表示一个语义概念,然后对每个维度为hw的语义组使用softmax函数计算空间注意力图,最后利用注意力图计算xi中像素的加权平均和,得到大小为l的紧凑词汇组,即语义tokensti。
[0049]
ti=(ai)
t
xi=(σ(φ(xi;w)))
t
xiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0050]
式中φ表示输入图像xi与卷积核w进行逐点卷积,σ表示softmax函数。
[0051]
步骤3:分别构建transformer的编码器和解码器。
[0052]
步骤3.1:构建transformer编码器中的改进多头注意力esa
[0053]
编码器通常由n个相同的层组成,并且每个层又包含两个带有残差结构的子层,其中第一个子层由msa和ln组成,第二个子层由ffn和ln组成。解码器与编码器结构类似,不同的是在解码器中存在包含cross attention的第三个子层,它的作用是与编码器进行信息交互。
[0054]
由于多头注意力(msa)存在两个缺点:
①
计算量随着token的数量或维度成二次方比例,在训练过程中产生大量计算和推理开销;
②
每个head只负责输入tokens的一个子集,尤其是当token embedding维度较小时,query和key的点积无法构成信息函数,降低网络的性能。bit网络为了权衡模型的效率和精度,将模型编码器深度(即transformer layer的数量)设置为1,解码器深度设置为8,且不同于标准的transformer实现,transformer解码器由nd个multi-head cross-attention(ma)和mlp blocks组成,移除了msa从而避免像素间的大量计算。
[0055]
本发明在此基础之上对msa中上述第二个缺点进行改进,如附图2所示。conv(
·
)是一个标准的1
×
1卷积运算,它具有跨通道信息交互的特点,用它来建模不同头之间的交互,达到注意力每个头可以依赖于所有的keys和queries的效果,然而这会削弱多头注意力对不同表示子集不同位置的联合处理能力。最初实例归一化in用于图像的风格化迁移,它的归一化计算方式不同于批归一化bn和层归一化ln,与批量维度和通道维度无关,它是对h、w维度数据单独进行计算,在帮助网络收敛的同时,能保持每个图像实例及通道间的独立性。本发明采用的改进msa称为esa,其在softmax函数之后对点积矩阵加入实例归一化来重建多头注意力的多样性能力。通过这样的方式,建模不同头间的交互,同时保持多头的多样性,数学表达式为:
[0056][0057]
式中,q、k、v分别表示查询矩阵、表示键矩阵、表示值矩阵;in表示实例归一化,对h、w维度数据单独进行计算,在帮助网络收敛的同时,能保持每个图像实例及通道间的独立性;conv(
·
)是一个标准的1
×
1卷积运算,它具有跨通道信息交互的特点,用它来建模不同头之间的交互,达到注意力每个头可以依赖于所有的keys和queries的效果;dk是query和key的向量维度。
[0058]
步骤3.2:构建transformer编码器
[0059]
transformer编码器由ne层esa和多层感知机(multilayer perceptron,mlp)组成,与标准transformer采用的post-ln结构不同,本发明采用pre-ln结构将层归一化ln前置,即层归一化分别放置在esa与mlp之前,可以帮助网络训练过程更稳定,收敛速度更快。
[0060]
transformer中每层l的自注意力的输入为三元组形式,即(q,k,v),其通过(l-1)层的输入计算得到,计算公式如下:
[0061]
q=t
(l-1)
wqꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0062]
k=t
(l-1)
wkꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0063]
v=t
(l-1)
wvꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0064]
式中为q,k,v对应线性投影层的参数,d为通道维数。
[0065]
transformer编码器的核心思想是多头注意力,多头注意力先以并行的方式执行多个独立的注意力头,然后对多个独立注意力头的输出进行拼接,最后经过投影得到最后输出,其优点是可以联合处理不同表示子空间上不同位置的信息,第j个头headj计算公式如下:
[0066][0067]
式中为第j个q,k,v对应线性投影层的参数。
[0068]
经过esa的多个头进行拼接,再经过第二个子层中mlp神经网络得到相应的token序列。
[0069]
步骤3.3:构建transformer解码器
[0070]
采用孪生的transformer解码器来提取每幅输入图像的特征图,和标准的transformer解码器不同,所采用的transformer解码器由nd层multi-head cross-attention(ma)和mlp blocks组成,去掉了多头注意力从而避免了xi中像素间的大量计算,层归一化的位置和编码器一样采用pre-ln结构。在transformer编码器的msa中,查询、键和值来自相同的输入序列,在transformer解码器中,查询来自输入图像特征xi,键和值则来自编码器的输出,即输入图像的每个像素可以通过紧凑的语义tokens组合来表示,输入一个特征序列xi,将其中的像素点作为查询,将tokens作为键,transformer解码器利用每个像素点与token组间的关系得到精确的特征图
[0071]
步骤4:构建密集融合模块dfm
[0072]
附图3为dfm模块示意图,由两个分支(branch)组成:和分支和差分支。dfm模块的输入为双时相图像transformer解码器输出的特征z
(1)
和z
(2)
,每个分支包含两个流(stream),且分支内部的两个流权值共享。模块利用求和分支可以获得增强的边缘信息,利
用差值分支可以生成变化的区域。所有的卷积操作都使用3
×
3的卷积核,在最后的卷积层后使用批量归一化(bn)。除此之外,由于密集连接中存在残差连接,每个流中的最后两个特征可以看作是前一个装征的残差,这在一定程度上修正了前一个特征,使得新的特征图更加对齐。
[0073]
步骤5:网络训练阶段,采用二分类交叉损失函数,计算公式如下:
[0074][0075]
式中,bceloss为二分类交叉损失,为预测值,y为真实值,预测与真实值相差越大,loss越大。
[0076]
步骤6:将两幅不同时相的多光谱图像归一化处理后输入到训练好的transformer网络进行变化和非变化类别的划分。
[0077]
下面结合具体实验数据对本发明做进一步详细说明。本次实验采用的实验数据为lever变化检测数据,图像大小裁剪为256
×
256。实验基于pytorch框架,模型选择批量大小为8,epoch设置为200,学习速率设置为0.01,线性衰减至0,优化器采用随机梯度下降(sgd)。实验中语义token的长度l设置为4,transformer编码器的层数为1,解码器的层数为8,msa和ma中头的数量设置为8,其中每个head的通道维度设置为8。预测阶段采用浅层卷积网络进行变化区域的判别,训练阶段损失函数采用二分类交叉熵损失函数优化网络参数。。
[0078]
为了验证本发明的有效性,将本发明变化检测方法与下述变化检测方法进行比对:
[0079]
(1)hao chen等人所提的stanet检测方法[“a spatial-temporal attention-based method and a new dataset for remote sensing image change detection.(remote sensing,2020,12(10)中所提的检测方法]
[0080]
(2)hao chen等人所提的bit检测方法(gan)[hao chen等.在文章“remote sensing image change detection with transformers.(ieee transactions on geoscience and remote sensing,2022,60中所提的检测方法]
[0081]
(4)本发明方法。
[0082]
检测性能用精确率(precision)、召回率(recall)、f1分数指标。f1是变化检测的综合评价指标,其值越接近于1,表明变化检测方法的性能越好。检测结果如表1所示。
[0083]
表1 levir数据集上的变化检测结果性能(%)
[0084][0085]
由表1可见,本发明所提的检测方法f1分数最大,比其他三种检测算法相比更接近于1。另外,本发明的precision和recall在对比算法中是最大的,更接近于1。综上,本发明变化检测算法的性能优于其他三种检测方法,这表明本发明所提的变化检测方法是有效的。
[0086]
图4(a)和(b)是lever数据集中前、后时相影像,图4(c)是变化检测的参考图。图4(d)、(e)、(f)分别是stanet算法、bit算法和本发明的变化检测结果,从图4的参考图的对比
来看,目视效果上,本发明所提算法的检测效果是最好的。
[0087]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0088]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0089]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0090]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0091]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。