1.本发明属于输电工程技术领域,尤其涉及一种用于输电线路可视化检测场景的视频稳像方法。
背景技术:
2.随着信息化技术的发展与进步,数字化社会和新基建等概念相继提出,作为城市流动血液载体的输电线路在这场变革中承担着重要职责。因此,输电线路的智能可视化检测技术被广泛应用,但由于外部因素的影响,输电线路的监控拍摄视频经常存在抖动现象,严重影响导线舞动等异常事件的检测。
3.通常采用视频稳像技术来克服这一问题,视频稳像技术是指利用相关的算法,对视频设备采集的原始视频序列进行处理,去除其中的抖动。视频稳像的目的,一方面是为了让人眼观感舒适,有利于人工观测、判别等,另一方面也作为诸多其它后续处理的预处理阶段,例如检测、跟踪和压缩。目前最常用的是电子(数字)稳像,基于在连续视频图像之间进行运动估计,然后对视频中的每一帧图像进行运动滤波和运动补偿处理得到稳定的图像。电子(数字)稳像的方法大体上说包括三个步骤:运动估计,运动补偿和图像修补。
4.其中,制约数字稳像技术发展的主要因素是运动估计,运动估计的基本思想是将图像序列的每一帧分成许多互不重叠的宏块,并认为宏块内所有像素的位移量都相同,然后对每个宏块到参考帧某一给定特定搜索范围内根据一定的匹配准则找出与当前块最相似的块,即匹配块,匹配块与当前块的相对位移即为运动矢量。视频压缩的时候,只需保存运动矢量和残差数据就可以完全恢复出当前块,得到运动矢量(也称运动向量);这一过程被称为运动估计。现有技术中通常使用局部运动矢量来近似代替全局运动矢量,例如上述的块匹配法,以及光流法、特征点检测法等进行运动矢量的计算。但是上述方法选取或计算的区域具有随机性,不具有固定属性。这会导致全局运动估计的不准确,例如当相机和导线同时抖动时,如果按照导线区域进行前后帧之间的运动向量计算,稳像后将可能弱化导线的抖动,从而导致进一步的导线舞动检测的精度下降。
5.本背景技术所公开的上述信息仅仅用于增加对本技术背景技术的理解,因此,其可能包括不构成本领域普通技术人员已知的现有技术。
技术实现要素:
6.本发明针对现有技术的运动估计算法通常使用局部运动矢量来近似代替全局运动矢量,选取或计算的区域具有随机性,不具有固定属性。这会导致全局运动估计不准确,尤其是稳像后可能弱化导线的抖动,导致进一步的导线舞动检测精度下降的问题,设计并提供一种用于输电线路可视化检测场景的视频稳像方法。
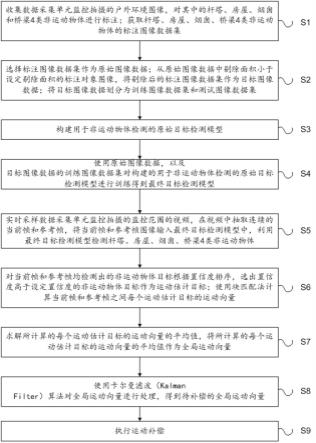
7.为实现上述发明目的,本发明采用下述技术方案予以实现:用于输电线路可视化检测场景的视频稳像方法,其特征在于,包括以下步骤:步骤s1:收集数据采集单元监控拍摄的户外环境图像,对其中的非运动物体进行
标注;获取非运动物体的标注图像数据集;步骤s2:选择标注图像数据集作为原始图像数据;从原始图像数据中剔除面积小于设定剔除面积的标注对象图像,将剔除后的标注图像数据集作为目标图像数据;将目标图像数据划分为训练图像数据集和测试图像数据集;步骤s3:构建用于非运动物体检测的原始目标检测模型;步骤s4:使用原始图像数据,以及目标图像数据的训练图像数据集对构建的用于非运动物体检测的原始目标检测模型进行训练得到最终目标检测模型;步骤s5:实时采样数据采集单元监控拍摄的监控范围的视频,在视频中抽取连续的当前帧和参考帧,将当前帧和参考帧图像输入最终目标检测模型中,利用最终目标检测模型检测非运动物体;步骤s6:对当前帧和参考帧均检测出的非运动物体目标根据置信度排序,选出置信度高于设定置信度的非运动物体目标作为运动估计目标;使用块匹配法计算当前帧和参考帧之间每个运动估计目标的运动向量;步骤s7:求解所计算的每个运动估计目标的运动向量的平均值,将所计算的每个运动估计目标的运动向量的平均值作为全局运动向量;步骤s8: 使用卡尔曼滤波(kalman filter)算法对全局运动向量进行处理,得到待补偿的全局运动向量;步骤s9:执行运动补偿,运动补偿可表示为其中,是补偿前图像中的一个像素点,是补偿后图像中的一个像素点。
8.在本技术的一些实施方式中,所述非运动物体包括杆塔、房屋、烟囱和/或桥梁。
9.在本技术的一些实施方式中,述户外环境图像为2k图像,设定剔除面积为60 像素
×
60像素。
10.在本技术的一些实施方式中,构建用于非运动物体检测的原始目标检测模型包括将faster r-cnn中的骨干网络由vgg-16模型替换为resnet50模型。
11.在本技术的一些实施方式中,运动补偿完成后使用马赛克法进行图像修补得到稳像视频。
12.在本技术的一些实施方式中,使用原始图像数据,以及目标图像数据的训练图像数据集对构建的用于非运动物体检测的原始目标检测模型进行训练得到最终目标检测模型包括以下步骤:步骤s41:将目标图像数据中的训练图像数据集中的图像输入以resnet50作为骨干网络的原始目标检测模型,经过resnet50进行特征提取,在resnet50的conv_4层输出的特征图上,进行3
ꢀ×
3的卷积操作,生成通道数为256的,大小为(h/16)
×
(w/16)的特征图;步骤s42:在3
ꢀ×
3的卷积操作之后,在((h/16)
×
(w/16)
ꢀ×
256)的特征图上分别进行两次1
ꢀ×
1的卷积操作,预测出预测边框的正负形和预测边框的坐标偏移量,其中256为通道数;步骤s43:在建议层生成建议,对于具有正向属性的预测边框进行修正、剔除和nms(非极大抑制,non maximum suppression)过滤,最终选取大于阈值p的设定个数的目标类预测边框;
步骤s44:进行感兴趣区域池化操作将选出的目标类预测边框对应到resnet50的conv_5层输出的特征图上,找到每个选出的目标类预测边框对应特征图的部分;步骤s45:在感兴趣区域池化操作输出的特征图上进行目标预测边框的回归和目标的分类;步骤s46:判断原始目标检测模型是否达到第一收敛程度;步骤s47:在原始目标检测模型达到第一收敛程度时,停止训练并保存原始目标检测模型为一次目标训练模型;步骤s48:将原始图像数据中的图像输入步骤s47输出的一次训练模型,经过resnet50进行特征提取,重复上述步骤s41至步骤s45,并判断一次目标训练模型是否达到第二收敛程度;步骤s49: 在一次目标训练模型完全收敛时,停止训练并保存一次目标训练模型为二次目标训练模型;步骤s50:原始图像数据中的图像输入步骤输出的二次训练模型,对二次训练模型进行微调,使得参数适应目标图像数据,直到二次训练模型再次收敛,停止微调并保存二次目标训练模型为最终目标检测模型。
13.在本技术的一些实施方式中,在步骤s42中,1
ꢀ×
1的卷积结果分为两个分支,上部分支生成(h/16)
×
(w/16)
ꢀ×
18通道的特征图,18通道是指:每个像素位置有9个预测边框,每个预测边框对应有是目标的概率和是背景的概率;下部分支生成(h/16)
×
(w/16)
ꢀ×
36通道的特征图,36通道是指:每个像素位置有9个预测边框,每个预测边框对应有四个独立的特征值,分别对应为中心点的x坐标的偏移量tx,中心点的y坐标的偏移量ty,边框水平方向的偏移量tw和边框垂直方向的偏移量th。
14.在本技术的一些实施方式中,定义三组纵横比ratio = [0.5,1,2]和三种尺度scale =[8,16,32]以构成预测边框。
[0015]
在本技术的一些实施方式中,判断原始目标检测模型是否达到第一收敛程度为判断是否达到轻微收敛:判断在训练过程中每个时期中是否存在前一个批大小训练产生的损失与当前批大小训练产生的损失的差值的绝对值小于第一设定损失值。
[0016]
在本技术的一些实施方式中,所述第一设定损失值为0.1。
[0017]
与现有技术相比,本发明的优点和积极效果是:与现有技术相比,本技术所提供的用于输电线路可视化检测场景的视频稳像方法特别适用于输电线路可视化检测场景,通过上述方法可以使用通过训练得到的最终目标检测模型检测出监控拍摄视频中的杆塔、房屋、烟囱和桥梁等四种非运动物体,然后使用它们进行运动向量计算,并进行全局运动估计,能够在消除视频抖动的同时,保证正常运动物体,尤其是导线的真实性和可靠性,减少了因为运动物体与视频抖动叠加产生的运动估计造成对运动物体的运动补偿不准确。此外,最终目标检测模型可以提供非运动物体的位置,使块匹配算法能够更精准的聚焦到相应位置,能够提升运动向量的准确性,进而提升后续的稳像效果。
[0018]
结合附图阅读本发明的具体实施方式后,本发明的其他特点和优点将变得更加清楚。
附图说明
[0019]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0020]
图1为本技术所提供的用于输电线路可视化检测场景的视频稳像方法一种实施方式的流程图;图2为本技术所提供的用于输电线路可视化检测场景的视频稳像方法中使用原始图像数据,以及目标图像数据的训练图像数据集对构建的用于非运动物体检测的原始目标检测模型进行训练得到最终目标检测模型的流程图;图3为以resnet50模型为骨干网络的原始目标检测模型的结构示意图。
具体实施方式
[0021]
为了使本发明的目的、技术方案及优点更加清楚明白,以下将结合附图和实施例,对本发明作进一步详细说明。
[0022]
需要说明的是,在本发明的描述中,术语“上”、“下”、“左”、“右”、“竖”、“横”、“内”、“外”等指示的方向或位置关系的术语是基于附图所示的方向或位置关系,这仅仅是为了便于描述,而不是指示或暗示所述装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0023]
针对现有技术的运动估计算法通常使用局部运动矢量来近似代替全局运动矢量,选取或计算的区域具有随机性,不具有固定属性,进一步导致全局运动估计不准确,尤其是稳像后可能弱化导线的抖动,导致进一步的导线舞动检测精度下降的问题,设计并提供一种用于输电线路可视化检测场景的视频稳像方法。导线舞动是指风对非圆截面输电线路产生的一种低频、大振幅的输电线路自激振动。导线舞动是输配电线路普遍存在的一种现象,范围较广,在各电压等级只要条件满足均会发生。导线舞动具有巨大的能量,舞动轨迹为在垂直于导线轴线的截面内呈椭圆形。导线上波腹的峰值从几十厘米到十二、三米均有出现,最大振幅可以达到输电线路直径的5至300倍。长时间持续、能量巨大、大幅度的导线舞动,会使得导线、金具、横担、电杆等所受的应力增加,会造成导线、金具、甚至杆塔的直接损伤或疲劳破坏,降低其使用寿命。
[0024]
通过输电线路状态监测装置可以实现导线舞动的检测,输电线路状态监测装置包括数据采集单元、数据监测终端、输电线路状态监测装置和输电线路状态监测主站系统;其中数据采集单元为安装在导线、地线(含光纤复合架空地线,即optical fiber composite overhead ground wire,opgw)、绝缘子、杆塔、基础等上的基于各种原理的信息测量装置,通过通信网络将测量信息传送到数据监测终端,并响应数据监测终端的指令;数据监测终端为汇集各数据采集单元的信息,并进行现场存储、处理,同时能和主站系统进行信息交换的装置;输电线路状态监测装置为能够实时采集输电线路本体、气象环境、通道状况等信息,并通过通信网络,将信息传输到主站系统的测量装置;输电线路状态检测主站系统为能接入各类输电设备状态监测信息,并进行集中存储、统一处理和应用的计算机系统。主站系统一般包括信息接入前置机、集中数据库、数据服务、数据加工及各类状态监测应用功能模
块。
[0025]
本技术所提供的用于输电线路可视化检测场景的视频稳像方法可以由数据采集单元、数据监测终端、输电线路状态监测装置和主站系统的其中任意一者实现。在优选的实施方式中,考虑到数据处理能力,例如可由主站系统实现。
[0026]
本技术所提供的用于输电线路可视化检测场景的视频稳像方法包括如图1所示的多个步骤。
[0027]
步骤s1:收集数据采集单元监控拍摄的户外环境图像,对其中的杆塔、房屋、烟囱和桥梁4类非运动物体进行标注;获取杆塔、房屋、烟囱、桥梁4类非运动物体的标注图像数据集。
[0028]
在本技术一些可选的实施方式中,户外环境图像为2k图像,2k图像由2048
×
1080个像素构成,其中2048表示水平方向的像素数,1048表示垂直方向的像素数。采用2d标注框对户外环境图像中的杆塔、房屋、烟囱和桥梁4类非运动物体进行标注。标注时,烟囱仅标注烟囱本体,不包含烟雾或水汽。桥梁仅标注户外环境图像中从桥梁的侧视视角采集的图像,以俯视视角拍摄的桥梁不进行标注。标注可以由专业的数据标注人员完成。
[0029]
步骤s2:选择标注图像数据集作为原始图像数据;从原始图像数据中剔除面积小于设定剔除面积的标注对象图像,将剔除后的标注图像数据集作为目标图像数据;将目标图像数据划分为训练图像数据集和测试图像数据集。
[0030]
设定剔除面积为物体特征模型的辨认临界面积。在本技术的一些实施方式中,对于2k图像来说,设定剔除面积由60
ꢀ×
60个像素构成,60表示水平方向和垂直方向的像素数。通过对原始图像数据中各个非运动物体进行统计分析,得出对于2k图像,面积小于60像素
ꢀ×
60像素的标注框中的非运动物体存在特征模型难辨的现象。因此将设定剔除面积设定为由60
ꢀ×
60个像素构成,目标图像数据即为高质量目标图像数据。
[0031]
步骤s3:构建用于非运动物体检测的原始目标检测模型。
[0032]
构建用于非运动物体检测的目标检测模型具体包括以下步骤:将faster r-cnn中的骨干网络由vgg-16模型替换为resnet50模型。
[0033]
在本技术的一些实施方式中,目标检测模型在faster r-cnn(基于区域的卷积神经网络,region-based convolutional neural network)的基础上改进得到。传统的faster r-cnn的基本结构包括特征提取部分、区域建议网络部分(region proposal network, rpn)、建议层部分(proposal layer)以及感兴趣区域池化部分(region of interest pooling, roi pooling);其中特征提取部分用卷积和池化从待处理的图像中提取出特征图(feature map),区域建议网络部分通过网络训练的方式从特征图中获取目标的大致位置,建议层部分利用区域建议网络部分获得的大致位置,继续训练,获得更精确的位置,感兴趣区域池化部分利用获得的更精确的位置,从特征图中抠出要用于分类的目标,并池化成固定长度的数据。
[0034]
传统的特征提取部分采用vgg-16(visual geometry group)模型作为骨干网络,其中包括16层,即包括13个卷积层和3个全连接层。vgg-16模型具有强大的拟合能力,在输入图像被下采样16倍后产生的特征图上进行文本框和置信度的预测,但是vgg-16的特征提取能力有限,与本技术的特征提取要求的匹配度不足。出于提高特征提取能力的目的,在本技术的一些实施方式中,将faster r-cnn中的骨干网络由vgg-16模型替换为深度残差网
络,即resnet50模型。
[0035]
步骤s4:使用原始图像数据,以及目标图像数据的训练图像数据集对构建的用于非运动物体检测的原始目标检测模型进行训练得到最终目标检测模型。
[0036]
以下对训练过程进行介绍,具体包括如图2所示的多个步骤。
[0037]
训练图像数据集中的图像的尺寸可以记为h
ꢀ×
w,其中h表示水平方向的像素数,w表示垂直方向的像素数,示例性的,h为2048个像素,w为1080个像素。
[0038]
步骤s41:如图3所示,将目标图像数据中的训练图像数据集中的图像输入以resnet50作为骨干网络的原始目标检测模型,经过resnet50进行特征提取,在resnet50的conv_4层(conv是卷积convolution的缩写)输出的特征图上,进行3
ꢀ×
3的卷积操作,生成通道数为256的,大小为(h/16)
×
(w/16)的特征图,可以表示为((h/16)
×
(w/16)
ꢀ×
256);conv_4层之前的处理步骤与传统的resnet50模型一致,在此不再重复介绍,如图3所示包括conv_1层、conv_2层和conv_3层。在图中,conv表示卷积,relu表示激活函数,full connection表示全连接,reshape代表重构层,softmax表示softmax函数,proposal代表建议层,roi pooling代表感兴趣区域池化,bbox代表边框回归(bounding box),class代表分类器,上述术语的定义均为神经网络技术领域公知的,在此不再一一进行介绍。
[0039]
步骤s42:在3
ꢀ×
3的卷积操作之后,在((h/16)
×
(w/16)
ꢀ×
256)的特征图上分别进行两次1
ꢀ×
1的卷积操作,1
ꢀ×
1的卷积结果分为两个分支,上部分支生成(h/16)
×
(w/16)
ꢀ×
18通道的特征图,18通道是指每个像素位置有9个预测边框(anchor)。每个预测边框(anchor)对应有两个独立的特征值,分别对应为是目标的概率和是背景的概率;下部分支生成(h/16)
×
(w/16)
ꢀ×
36通道的特征图,36通道是指每个像素位置有9个预测边框(anchor),每个预测边框(anchor)对应有四个独立的特征值,分别对应为中心点的x坐标的偏移量tx,中心点的y坐标的偏移量ty,边框水平方向的偏移量tw和边框垂直方向的偏移量th。
[0040]
定义三组纵横比ratio = [0.5,1,2]和三种尺度scale =[8,16,32]以构成预测边框(anchor),通过上述两组参数可以组合成9种不同的形状和大小的边框。对于上部分支生成的预测边框,在所得到的特征值中,是目标的概率和是背景的概率中存在相对较大的一个,即为最大的预测概率p,该概率所对应的类别即为预测边框的类别,即分为目标类预测边框和背景类预测边框。
[0041]
在经过上述步骤后,可以预测出预测边框的正负性(例如目标类预测边框为正,背景类预测边框为负);同时也可以预测出预测边框的坐标偏移量。
[0042]
步骤s43:在建议层生成建议,对于具有正向属性的预测边框进行修正、剔除和nms(非极大抑制,non maximum suppression)过滤,最终选取大于阈值p的设定个数的目标类预测边框。
[0043]
步骤s44:进行感兴趣区域池化(roi pooling)操作将选出的目标类预测边框对应到resnet50的conv_5层输出的特征图上,找到每个选出的目标类预测边框对应特征图的部分。
[0044]
步骤s45:在感兴趣区域池化(roi pooling)操作输出的特征图上进行目标预测边框的回归和目标的分类。
[0045]
步骤s46:判断原始目标检测模型是否达到第一收敛程度。
[0046]
判断原始目标检测模型是否达到第一收敛程度,第一收敛程度代表轻微收敛的状态;更具体地,即判断在训练过程中每个时期(epoch:完整的训练图像数据集通过原始目标检测模型一次并且返回一次的过程)中是否存在前一个批大小(batch-size)训练产生的损失与当前批大小(batch-size)训练产生的损失的差值的绝对值小于第一设定损失值(示例性地,例如0.1)。轻微收敛是指原始目标检测模型训练过程中的一个区间,在这个区间内损失依然在持续下降,但下降幅度平缓,且上一轮损失与当前轮损失的差值的绝对值小于0.1。
[0047]
步骤s47:在原始目标检测模型达到第一收敛程度,即轻微收敛时,停止训练并保存原始目标检测模型为一次目标训练模型。
[0048]
步骤s48:将原始图像数据中的图像输入步骤s47输出的一次训练模型,经过resnet50进行特征提取,重复上述步骤s41至步骤s45,并判断一次目标训练模型是否达到第二收敛程度。
[0049]
判断一次训练模型是否达到第二收敛程度,第二收敛程度代表完全收敛的状态,也即设定的理想的收敛状态。
[0050]
步骤s49:在一次目标训练模型完全收敛时,停止训练并保存一次目标训练模型为二次目标训练模型。
[0051]
步骤s50:将原始图像数据中的图像输入步骤s49输出的二次训练模型,对二次训练模型进行微调(fine tune),使得参数适应目标图像数据,直到二次训练模型再次收敛,停止微调并保存二次目标训练模型为最终目标检测模型。 可以用测试图像数据集对训练完成的最终目标检测模型进行检测。
[0052]
步骤s5:实时采样数据采集单元监控拍摄的监控范围的视频,在视频中抽取连续的当前帧和参考帧,将当前帧和参考帧图像输入最终目标检测模型中,利用最终目标检测模型检测杆塔、房屋、烟囱、桥梁4类非运动物体。
[0053]
步骤s6:对当前帧和参考帧均检测出的非运动物体目标(杆塔、房屋、烟囱和桥梁)根据置信度排序,选出置信度高于设定置信度的非运动物体目标(示例性地,例如置信度大于0.7的目标)作为运动估计目标;使用块匹配法计算当前帧和参考帧之间每个运动估计目标的运动向量;块匹配法选用现有技术中所公开的模型,本技术未对这个部分作出改进,在此不再赘述。
[0054]
步骤s7:求解所计算的每个运动估计目标的运动向量的平均值,将所计算的每个运动估计目标的运动向量的平均值作为全局运动向量:其中表示全局运动向量,n表示运动估计目标的数量,表示运动估计目标的运动向量。
[0055]
步骤s8:使用卡尔曼滤波(kalman filter)算法对全局运动向量进行处理,得到待补偿的全局运动向量。
[0056]
步骤s9:执行运动补偿,运动补偿的过程可以表示为下式:
其中,是补偿前图像中的一个像素点,是补偿后图像中的一个像素点。运动补偿完成后使用马赛克法进行图像修补得到最后的稳像视频。
[0057]
与现有技术相比,本技术上述实施方式所提供的用于输电线路可视化检测场景的视频稳像方法特别适用于输电线路可视化检测场景,通过上述方法可以使用通过训练得到的最终目标检测模型检测出监控拍摄视频中的杆塔、房屋、烟囱和桥梁等四种非运动物体,然后使用它们进行运动向量计算,并进行全局运动估计,能够在消除视频抖动的同时,保证正常运动物体,尤其是导线的真实性和可靠性,减少了因为运动物体与视频抖动叠加产生的运动估计造成对运动物体的运动补偿不准确。此外,最终目标检测模型可以提供非运动物体的位置,使块匹配算法能够更精准的聚焦到相应位置,能够提升运动向量的准确性,进而提升后续的稳像效果。
[0058]
以上实施例仅用以说明本发明的技术方案,而非对其进行限制;尽管参照前述实施例对本发明进行了详细的说明,对于本领域的普通技术人员来说,依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明所要求保护的技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
