1.本发明属于电力行业安全域边界拟合技术领域,特别涉及一种电力系统高维静态安全域边界拟合方法。
背景技术:
2.随着高比例可再生能源及电力电子化装备接入电力系统,其不确定性及波动性急剧增加,运行方式多变,传统的逐点分析法已不再适用。
3.电力系统静态安全域作为在功率注入空间上所有满足潮流方程和系统安全约束条件的运行点集合,能够为高不确定性、高波动性的电力系统安全性评估及控制提供有力的支撑。其中,依据不同的安全约束条件,可将静态安全域细分为热稳定安全域、静态电压安全域等,适用于不同需求的应用场合。但由于潮流方程的非线性,加上各类安全性约束,使得整个电力系统静态安全域边界(steady-state security region boundary,ssrb)呈现非凸、非线性特性,基于解析法进行边界表达式推导的方法得到的结果通常过于保守,而基于超平面系数拟合的方法误差较大,且不适用于高维边界的拟合。因此,如何高精度求解ssrb成为了制约其应用的瓶颈。
技术实现要素:
4.针对背景技术存在的问题,本发明提供一种电力系统高维静态安全域边界拟合方法。
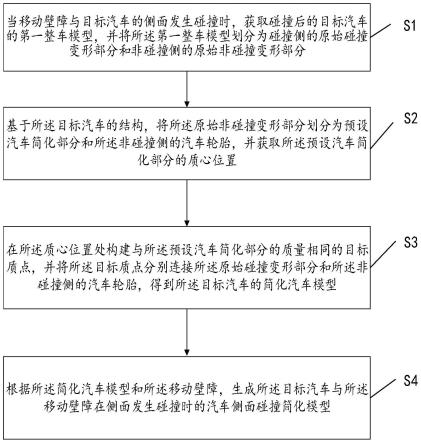
5.为解决上述技术问题,本发明采用如下技术方案一种电力系统高维静态安全域边界拟合方法,包括以下步骤:
6.步骤1、初始样本集的生成;
7.步骤2、为初始样本集中每一个样本xi寻找一个处于安全域内的样本x
s,i
,一个安全域外样本x
u,i
,并满足||x
u,i-x
s,i
||2≤ξ,ξ是距离阈值,工程需求设定;形成边界样本集sb;
8.步骤3、将边界样本集sb中数据所处的原始功率注入空间x,通过深度神经网络模型转换到新的三维特征空间z中;
9.步骤4、通过基于信息增益比的加权倾斜决策树算法在特征空间z中进行边界的提取,并评估边界性能,选出最优边界。
10.在上述电力系统高维静态安全域边界拟合方法中,步骤1的实现包括以下步骤:
11.步骤1.1、基于拉丁超立方抽样算法生成发电机出力数据;
12.设一个n节点的电力系统中,含ng个发电机节点,n
l
个负荷节点,发电机出力上下限为:
13.[p
g_min,j
,p
g_max,j
],j∈1,2,...,ngꢀꢀꢀ
(1)
[0014]
式中,p
g_min,j
为第j个发电机的出力下限,p
g_max,j
为第j个发电机的出力上限;
[0015]
设置初始样本集采样数量为n
init
,则基于拉丁超立方抽样发电机出力数据为:
[0016][0017]
式中,p
g,i,j
为第i个样本中第j个发电机的出力,且:
[0018][0019]
步骤1.2、发电机出力约束的负荷节点采样方法包括以下步骤:
[0020]
步骤1.2.1、针对第i个样本,发电机组总出力采样值为p
g_out,i
,则系统平衡机出力上下限为[p
s_min
,p
s_max
],设n
l
个负荷节点总需求采样值为不计网损情况下,为满足系统平衡机出力不越限,p
l,i
需满足:
[0021][0022]
式(4)中的约束在n
l
维空间中围成了一个凸超多面体;将问题建模为在式(5)中的超多面体中对n
l
维向量进行采样:
[0023]
s.t.a
×
p
l
≤b
ꢀꢀꢀ
(5)
[0024]
式中,a∈(n
l
2)
×nl
,p
l
∈n
l
×
1,b∈(n
l
2)
×
1,均为式(4)中的约束系数;
[0025]
步骤1.2.2、构造线性目标函数:
[0026][0027]
式中,f(p
l
)是变量为p
l
的线性函数;
[0028]
依据线性规划方法求得最优解p
l,0
,p
l,0
为式(5)所表示的超多面体的一个顶点;
[0029]
步骤1.2.3、以p
l,0
为初始值,求解超多面体的中心;构建一个非线性优化问题:
[0030][0031]
式中,a
i,:
为矩阵a中第i行元素,p
l,cen
为上述凸超多面体几何中心;
[0032]
步骤1.2.4、以p
l,cen
为出发点,随机初始化采样方向求解经过点p
l,cen
并以u为方向的直线与多面体的两个交点o1,o2:
[0033][0034]
式中,z,c为中间计算量,c
p
、cn为该直线与多面体各个平面、包含延伸面的交点,
o1、o2为该直线与多面体的实际交点;
[0035]
步1.2.5、在点o1,o2间进行均匀采样,随机生成采样系数λ∈[0,1],得到采样点:
[0036]
p
l,sam
=p
l,cen
λ
·
(ο1 (o
2-o1))
×uꢀꢀꢀ
(9)
[0037]
式中,p
l,sam
为最后采样点;
[0038]
步骤1.3、依据步骤1.2对n
init
个样本中负荷节点值进行采样,并通过交流潮流计算分析,筛选出处于安全域内的样本点,形成初始样本集合s={(xi,yi)},i∈1,2,...,ns,yi∈{0},其中,s为初始样本集合,xi为第i个样本中节点注入功率向量,由发电机出力向量p
g,i
与节点负荷向量p
l,i
组成,ns为集合s中样本数,yi∈{0}为样本标签,0的含义为该样本处于安全域内。
[0039]
在上述电力系统高维静态安全域边界拟合方法中,步骤2的实现包括以下步骤:
[0040]
步骤2.1、设定边界距离阈值ξ,搜索初始步长λ
r,set
;
[0041]
步骤2.2:依据样本集合s的样本数ns,基于拉丁超立方抽样算法采样ns个n
p
维功率增长方向向量,并对每一个方向向量进行归一化,形成搜索方向向量矩阵
[0042]
步骤2.3:对每一个处于样本集合s中的xi,执行如下算法得到边界样本集合sb,其中x
s,i
为样本对中处于安全域的边界样本,x
u,i
为样本对中处于安全域外的边界样本,集合sb中共2ns个样本;
[0043][0044]
在上述电力系统高维静态安全域边界拟合方法中,步骤3的实现包括以下步骤:
[0045]
步骤3.1、依据边界样本集数据量2ns及数据维度n
p
,选择神经网络进行特征非线性变换;若样本集数量小于10000及数据维度小于100,选择全连接神经网络;否则选择卷积神
经网络或循环神经网络;
[0046]
步骤3.2、选择神经网络优化器为自适应矩估计算法,设定神经网络超参数,进行模型训练,并选出最优模型,将边界样本集sb中数据所处的原始功率注入空间x,通过深度神经网络模型转换到新的三维特征空间z中,得到特征空间下的数据集sz。
[0047]
在上述电力系统高维静态安全域边界拟合方法中,步骤4的实现包括以下步骤:
[0048]
步骤4.1、设定信息增益比的加权倾斜决策树模型中每一非叶子节点下,其输入条件为训练数据集sz,(zi,yi)∈sz,i=1,2,3,...,2ns;设定模型最大深度为d,当前节点深度为d;
[0049]
其中,根节点下训练数据集为步骤3.2生成的数据集sz,其他非叶子结点下的训练数据集为其父节点的训练集划分得到的左子集s'
l
、右子集s'r;
[0050]
步骤4.2、基于数据集sz创建模型根节点g,并令当前节点深度d=0;
[0051]
步骤4.3、如果当前节点深度d》模型最大深度d,则节点g设为叶子结点,其标签为数据集sz内样本数量最多的对应标签k;否则,转步骤4.4;
[0052]
步骤4.4、如果数据集sz内所有样本属于同一类别k,则节点g设为叶子结点,其标签为k;否则,转步骤4.5;
[0053]
步骤4.5、随机初始化模型参数θ0;
[0054]
步骤4.6、基于拟牛顿算法和初始值θ0求解模型目标函数最小值式(10),得到模型最优参数θ
best
;
[0055][0056]
其中,l(θ)为模型目标函数,λ为l2正则化项系数,θ为模型各节点下的待训练参数,||θ||2为θ的二范数,h(sz)为样本集合s的经验熵,h(sz|θ)为样本集合sz在θ下的条件经验熵;
[0057][0058]
其中,k是样本总类别数;k表示样本中第k类样本标签;|sk|是样本集合sz中第k类样本数量,|sz|是样本集合sz总样本数量;
[0059][0060]
其中,w
l
为所有样本分属左子集的权重之和,wr为所有样本分属右子集的权重之和,h
l
为左子节点加权信息熵,hr为右子节点加权信息熵,m是该节点下样本集合sz总样本数量,θ为模型各节点下的待训练参数;
[0061][0062]
其中,为样本(xi,yi)属于左子节点的权重,s
l
各样本关联属于左子节点权重信息的集合;
[0063]
[0064]
其中,为样本(xi,yi)属于右子节点的权重,sr各样本关联属于右子节点权重信息的集合;
[0065][0066]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于左子集的权重之和,w
l
为样本集合sz中所有样本属于左子集的权重之和;
[0067][0068]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于右子集的权重之和;wr为样本集合sz中所有样本属于右子集的权重之和;
[0069][0070]
其中,(xi,yi)表示样本集合sz中第i个样本,s
l
为各样本关联分属左子集权重信息的集合,sr为各样本关联分属右子集权重信息的集合;
[0071][0072]
其中,为第i个样本分属左子节点的权重,为第i个样本分属右子节点的权重,σ(
·
)为sigmoid函数;
[0073][0074]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于左子集的权重之和;
[0075][0076]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于右子集的权重之和;
[0077]
步骤4.7、基于最优参数θ
best
得到左子集、右子集,s'
l
,s'r;其中,
[0078][0079]
其中,(xi,yi)表示样本集合sz中第i个样本,为第i个样本分属左子节点的权重,s
l
为各样本关联分属左子集权重信息的集合,为第i个样本分属右子节点的权重,sr为各样本关联分属右子集权重信息的集合;
[0080]
步骤4.8、如果s'
l
样本数量小于阈值ny,置左子节点为叶节点,标签为s'
l
中数量最
多的类别,否则,构建左子节点g
l
,并令该节点下训练集为s'
l
,d=d 1,转步骤4.3;
[0081]
步骤4.9、如果s'r样本数量小于阈值ny,置右子节点为叶节点,标签为s'r中数量最多的类别,否则,构建右子节点gr,并令该节点下训练集为s'r,d=d 1,转步骤4.3;
[0082]
步骤4.10、输出决策树模型,并转为边界表达式。
[0083]
与现有技术相比,本发明的有益效果:本发明所提方法基于特征非线性变换与倾斜决策树的电力系统高维静态安全域边界拟合能够实现高维静态安全域的边界拟合,缩小与实际边界的误差,提高边界拟合精度,可为后续基于安全域的电力系统安全性评估与控制提供支撑。
附图说明
[0084]
图1为本发明实施例电力系统高维静态安全域边界拟合方法示意图;
[0085]
图2为本发明实施例边界样本搜索示意图。
具体实施方式
[0086]
下面将结合本发明实施例对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0087]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0088]
下面结合具体实施例对本发明作进一步说明,但不作为本发明的限定。
[0089]
本实施例一种电力系统高维静态安全域边界拟合方法,包括基于拉丁超立方抽样算法进行电力系统发电机出力的采样。考虑系统发电机出力约束,进行节点负荷值采样,通过潮流计算,筛选出处于安全域内的样本,形成初始样本集。提出边界样本搜索算法,为初始样本集中每一个样本寻找一个处于安全域内的样本,一个安全域外样本,并满足二者距离小于设定的距离阈值。将所处原始功率注入空间的边界样本集中数据通过深度神经网络模型转换到新的三维特征空间中。通过基于信息增益比的加权倾斜决策树算法在特征空间中进行边界的提取,并评估边界性能,选出最优边界。本实施例方法可实现电力系统安全域高维边界的拟合,并缩小与实际边界的误差。
[0090]
本实施例是通过以下技术方案来实现的,一种电力系统高维静态安全域边界拟合方法,包括以下步骤:
[0091]
s1:初始样本集的生成;首先,基于拉丁超立方抽样算法进行电力系统发电机出力的采样。然后,考虑系统发电机出力约束,进行节点负荷值采样;通过潮流计算,筛选出处于安全域内的样本,形成初始样本集s={(xi,yi)},i∈1,2,...,ns,yi=0;其中,s为初始样本集,xi为第i个样本中节点注入功率,yi为样本标签,0表示该样本处于安全域内,ns为初始样本集样本数量;
[0092]
s2:为初始样本集中,每一个样本xi寻找一个处于安全域内的样本x
s,i
,一个安全域外样本x
u,i
,并满足||x
u,i-x
s,i
||2≤ξ,ξ是距离阈值,可由工程需求设定。最终,形成边界样本集sb。
[0093]
s3:将边界样本集sb中数据所处的原始功率注入空间x,通过深度神经网络模型转换到新的三维特征空间z中。
[0094]
s4:通过基于信息增益比的加权倾斜决策树算法在特征空间z中进行边界的提取,并评估边界性能,选出最优边界。
[0095]
具体实施时,如图1所示,s1的具体实现包括:
[0096]
s1.1:基于拉丁超立方抽样算法生成发电机出力数据。具体地,设一个n节点的电力系统中,含ng个发电机节点,n
l
个负荷节点,发电机出力上下限为:
[0097]
[p
g_min,j
,p
g_max,j
],j∈1,2,...,ngꢀꢀꢀ
(1)
[0098]
式中,p
g_min,j
为第j个发电机的出力下限,p
g_max,j
为第j个发电机的出力上限。
[0099]
设置初始样本集采样数量为n
init
,则基于拉丁超立方抽样发电机出力数据,记为:
[0100][0101]
式中,p
g,i,j
为第i个样本中第j个发电机的出力,且:
[0102][0103]
s1.2:在完成对发电机出力的采样后,考虑到所提模型后续需要基于大量安全域内初始样本进行边界样本的搜索,因此需要提高处于安全域内样本在n
init
个初始样本中的比例。为此,提出考虑发电机出力约束的负荷节点采样方法。具体地,针对第i个样本,发电机组总出力采样值为p
g_out,i
,则系统平衡机出力上下限为[p
s_min
,p
s_max
],设n
l
个负荷节点总需求采样值为在不考虑网损情况下,为满足系统平衡机出力不越限,p
l,i
需满足:
[0104][0105]
式(4)中的约束在n
l
维空间中围成了一个凸超多面体。为实现在如上超多面体内部进行负荷值的均匀采样,将问题建模为在如式(5)中的超多面体中对n
l
维向量进行采样。
[0106]
s.t.a
×
p
l
≤b
ꢀꢀꢀ
(5)
[0107]
式中,a∈(n
l
2)
×nl
,p
l
∈n
l
×
1,b∈(n
l
2)
×
1,均为式(4)中的约束系数。
[0108]
s1.3:构造线性目标函数:
[0109][0110]
式中,f(p
l
)是变量为p
l
的线性函数。
[0111]
依据线性规划方法求得最优解p
l,0
,p
l,0
实际上为式(5)所表示的超多面体的一个顶点。
[0112]
s1.4:以p
l,0
为初始值,求解超多面体的中心。为此,构建一个非线性优化问题,即:
[0113][0114]
式中,a
i,:
为矩阵a中第i行元素,p
l,cen
为上述凸超多面体几何中心。
[0115]
s1.5:以p
l,cen
为出发点,随机初始化采样方向求解经过点p
l,cen
并以u为方向的直线与多面体的两个交点o1,o2,具体地,
[0116][0117]
式中,z,c为中间计算量,c
p
、cn为该直线与多面体各个平面(包含延伸面)的交点,o1、o2为该直线与多面体的实际交点。
[0118]
s1.6:在点o1,o2间进行均匀采样,即,随机生成采样系数λ∈[0,1],得到采样点:
[0119]
p
l,sam
=p
l,cen
λ
·
(ο1 (o
2-o1))
×uꢀꢀꢀ
(9)
[0120]
式中,p
l,sam
即为最后采样点。
[0121]
s1.7:依据上述步骤对n
init
个样本中负荷节点值进行采样,并通过交流潮流计算分析,筛选出处于安全域内的样本点,形成初始样本集合s={(xi,yi)},i∈1,2,...,ns,yi∈{0},其中,s为初始样本集合,xi为第i个样本中节点注入功率向量,由发电机出力向量p
g,i
与节点负荷向量p
l,i
组成,ns为集合s中样本数,yi∈{0}为样本标签,0的含义为该样本处于安全域内。
[0122]
如图2所示,s2的具体实现包括:
[0123]
s2.1:设定边界距离阈值ξ,搜索初始步长λ
r,set
。
[0124]
s2.2:依据样本集合s的样本数ns,基于拉丁超立方抽样算法采样ns个n
p
维功率增长方向向量,并对每一个方向向量进行归一化,形成搜索方向向量矩阵
[0125]
s2.3:对每一个处于样本集合s中的xi,执行如下算法:
[0126][0127]
最终,得到边界样本集合sb,其中x
s,i
为样本对中处于安全域的边界样本,x
u,i
为样本对中处于安全域外的边界样本,集合sb中共2ns个样本。
[0128]
如图1所示,s3的具体实现包括:
[0129]
s3.1:依据边界样本集数据量2ns及数据维度n
p
,选择合适的神经网络进行特征非线性变换,通常若样本数量小于10000及数据维度小于100,可选择全连接神经网络,否则可选择其他较为复杂的神经网络如卷积神经网络,循环神经网络等;
[0130]
s3.2:选择神经网络优化器为自适应矩估计算法,设定神经网络超参数,进行模型训练,并选出最优模型,将边界样本集sb中数据所处的原始功率注入空间x,通过深度神经网络模型转换到新的三维特征空间z中,得到特征空间下的数据集sz。
[0131]
如图1所示,s4的具体实现包括:
[0132]
s4.1:设定信息增益比的加权倾斜决策树模型中每一非叶子节点下,其输入条件为训练数据集sz,(zi,yi)∈sz,i=1,2,3,...,2ns;设定模型最大深度为d,当前节点深度为d;
[0133]
其中,根节点下训练数据集为步骤3.2生成的数据集sz,其他非叶子结点下的训练数据集为其父节点的训练集划分得到的左子集s'
l
、右子集s'r;
[0134]
s4.2:基于数据集sz创建模型根节点g,并令当前节点深度d=0;
[0135]
s4.3:如果当前节点深度d》模型最大深度d,则节点g设为叶子结点,其标签为数据集sz内样本数量最多的对应标签k;否则,转s4.4;
[0136]
步骤4.4:如果数据集sz内所有样本属于同一类别k,则节点g设为叶子结点,其标签为k;否则,转s4.5;
[0137]
s4.5:随机初始化模型参数θ0;
[0138]
s4.6:基于拟牛顿算法和初始值θ0求解模型目标函数最小值,如式(10)所示,并得到模型最优参数θ
best
;
[0139][0140]
其中,l(θ)为模型目标函数,λ为l2正则化项系数,θ为模型各节点下的待训练参数,||θ||2为θ的二范数,h(sz)为样本集合s的经验熵,h(sz|θ)为样本集合sz在θ下的条件经验熵;
[0141][0142]
其中,k是样本总类别数;k表示样本中第k类样本标签;|sk|是样本集合sz中第k类样本数量,|sz|是样本集合sz总样本数量;
[0143][0144]
其中,w
l
为所有样本分属左子集的权重之和,wr为所有样本分属右子集的权重之和,h
l
为左子节点加权信息熵,hr为右子节点加权信息熵,m是该节点下样本集合sz总样本数量,θ为模型各节点下的待训练参数;
[0145][0146]
其中,为样本(xi,yi)属于左子节点的权重,s
l
各样本关联属于左子节点权重信息的集合;
[0147][0148]
其中,为样本(xi,yi)属于右子节点的权重,sr各样本关联属于右子节点权重信息的集合;
[0149][0150]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于左子集的权重之和,w
l
为样本集合sz中所有样本属于左子集的权重之和;
[0151][0152]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于右子集的权重之和;wr为样本集合sz中所有样本属于右子集的权重之和;
[0153][0154]
其中,(xi,yi)表示样本集合sz中第i个样本,s
l
为各样本关联分属左子集权重信息
的集合,sr为各样本关联分属右子集权重信息的集合;
[0155][0156]
其中,为第i个样本分属左子节点的权重,为第i个样本分属右子节点的权重,σ(
·
)为sigmoid函数;
[0157][0158]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于左子集的权重之和;
[0159][0160]
其中,k是样本总类别数;k表示样本中第k类样本标签,为样本集合中k类别下样本属于右子集的权重之和;
[0161]
s4.7:基于最优参数θ
best
得到左子集、右子集,s'
l
,s'r;其中,
[0162][0163]
其中,(xi,yi)表示样本集合sz中第i个样本,为第i个样本分属左子节点的权重,s
l
为各样本关联分属左子集权重信息的集合,为第i个样本分属右子节点的权重,sr为各样本关联分属右子集权重信息的集合;
[0164]
s4.8:如果s'
l
样本数量小于阈值ny,置左子节点为叶节点,标签为s'
l
中数量最多的类别,否则的话,构建左子节点g
l
,并令该节点下训练集为s'
l
,d=d 1,转步骤4.3;
[0165]
s4.9:如果s'r样本数量小于阈值ny,置右子节点为叶节点,标签为s'r中数量最多的类别,否则的话,构建右子节点gr,并令该节点下训练集为s'r,d=d 1,转步骤4.3。
[0166]
s4.10:输出决策树模型,并转为边界表达式。
[0167]
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。