1.本发明属于计算机技术领域,涉及一种基于开源软件供应链的软件安全舆情事件抽取方法与装置。
背景技术:
2.提升信息安全态势感知、检测预警能力及应急响应能力,既是构建国家信息安全屏障的重要问题,也是保护个人隐私数据的必要因素。开源软件供应链是指开源软件在开发和运行过程中,涉及到的所有开源软件的上游社区、源码包、二进制包、第三方组件分发市场、应用软件分发市场,以及开发者和维护者、社区、基金会等,按照依赖、组合等形成的供应关系网络。其中,通过社交媒体、新闻媒体、资讯网站快速识别、收集信息安全领域发生的各类安全事件,能够帮助信息安全相关从业者快速了解全球范围内正在发生的恶意软件入侵、信息泄露、漏洞披露等事件信息,从而积极制定预防及应对策略,做到快速感知、及时响应。因此,面向信息安全领域,通过机器对社交媒体、新闻资讯文本进行舆情事件抽取是一个很有意义的任务。
3.目前,事件抽取的方法通常基于深度学习技术,通过从自然语言文本中抽取指定类型的事件以及相关的实体信息,形成结构化数据并输出文本。一般来说,事件抽取可以分解为两个子任务。首先是事件检测,通常包含检测触发词,对触发词/事件类型进行识别,每种事件类型对应唯一的事件表示框架;其次是元素识别,即检测事件论元角色,对事件论元值进行识别。其中元素识别依赖于事件检测输出对应的事件表示框架。
4.信息安全领域专业性高,领域数据相对稀缺,同时数据标注门槛高,训练数据相对较少。同时通过对相关语料的观察,其事件论元往往分散在多个句子中,且存在论元实体嵌套以及同一论元角色存在多个论元值的复杂情况。在此条件下,本发明综合运用多种抽取策略,针对领域数据进行优化,保证舆情事件信息抽取准确率,以提高相关从业者浏览、筛选、分析领域信息的工作效率。
技术实现要素:
5.本发明的目的在于提供一种基于开源软件供应链的软件安全舆情事件抽取方法与装置,通过构建深度学习模型,大范围获取可能相关的语料并通过加入动态多池化的textcnn变体算法快速过滤掉非目标文本,利用lda主题模型充分获取事件类别,帮助建立事件schema,将事件类型识别转化为文本分类任务,使用bert-dgcnn模型求解,然后采用span negativesampling的序列标注模型进行事件论元抽取,有效解决了领域数据较少及数据复杂导致的抽取准确率无法保证的问题。
6.为实现上述目的,本发明采用如下技术方案:
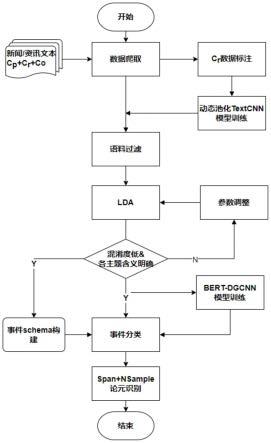
7.一种基于开源软件供应链的软件安全舆情事件抽取方法,包括以下步骤:
8.1)构建基于textcnn和动态多池化的文本分类模型,利用该文本分类模型从大量
互联网网页文本中识别属于网络信息安全领域的目标文本;
9.2)利用lda模型对目标文本进行主题聚类,并在聚类基础上构建事件schema;
10.3)对lda模型的聚类结果数据进行人工修正,作为事件分类训练数据,利用事件分类训练数据训练bert-dgcnn事件分类模型;
11.4)根据bert-dgcnn事件分类模型获得的事件分类结果,使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。
12.进一步地,步骤1)半自动地构建文本分类训练语料,并搭建文本分类模型用于从大量互联网网页文本中识别属于网络信息安全领域的目标文本。其中文本分类训练语料初始来源分为信息安全领域的专业网站、包含科技/it资讯的相关网站、随机选取的其他新闻网站。textcnn将卷积神经网络cnn应用到文本分类任务,利用多个不同size的kernel来提取句子的关键信息,从而能够更好地捕捉局部相关性。实践中textcnn在常规语料上往往能取得和基于bert的大型深度网络相近的精度,但具有模型小、速度快的优势。本发明在其基础上增加了动态多池化策略,使模型能够学习到不同方面的信息。
13.进一步地,步骤2)利用lda模型对获取的目标文本进行软聚类,并通过人机协作的方式确定抽取目标事件的schema(schema是指模式,用于定义事件体的数据格式,在异构系统中实现可靠的数据交换)。lda是用于分析文本信息的经典主题模型,它能够识别语料库中潜藏的主题信息,本发明从同一主题的文本中总结出它们属于的事件及其schema。利用lda模型辅助构建事件schema,有效降低人工标注量。
14.进一步地,步骤3)基于bert-dgcnn对事件类型进行抽取。bert基于双向transformer,创新地引入了mask语言模型与next sentence prediction机制,其效果得到了学术及工业界的一致认可。dgcnn指膨胀门卷积神经网络,其相对于普通cnn提升了感受野,能够捕获更远位置的特征。同时,使用此类文本分类方法进行事件类型抽取避免了对触发词标注的依赖。
15.进一步地,步骤4)采用基于span negativesampling(负采样)的事件角色抽取模型。信息安全领域高质量标注数据获取困难,同时存在大量嵌套实体的复杂情况。因此使用span negativesampling的策略,有效处理嵌套实体同时降低漏标注数据对抽取效果的负面影响。
16.进一步地,在步骤1)中,包括以下步骤:
17.a)使用预先训练的词嵌入模型构建输入特征向量,n为一个句子中的token数(token是指句子切分后得到的子字符串序列),k是每个token对应的词向量的维度,则textcnn模型的输入层为一个n
×
k维的矩阵,使用表示句子中第i个token的k维嵌入。
18.b)利用卷积层对textcnn的输入层的特征进行提取,每个卷积核kernel与一个窗口的词向量进行卷积操作,产生一个特征ci:
19.ci=f(w
·
x
i:i h-1
b)
20.其中,x
i:i h-1
表示输入矩阵从第i行到第i h-1行所组成的一个大小为h
×
k的窗口,f表示非线性函数,w表示h
×
k维的权重矩阵,b表示偏置参数。kernel的宽度与词向量大小k相同;使用多个size(大小)的不同kernel获取纵向的差异信息,相当于使用了n-gram;
每个size又有多个卷积核用于学习到多个不同的信息。
21.c)使用textcnn的池化层将每个滑动窗口产生的特征向量中选出代表特征,并将这些特征拼接起来构成向量表示;获取向量表示后接入一个全连接层,并使用softmax激活函数输出每个类别(目标文本与非目标文本两类)的概率。
22.进一步地,在步骤2)中,包括以下步骤:
23.a)假设文档主题的先验分布是dirichlet分布,假设主题中词的先验分布是dirichlet分布,即:
[0024][0025][0026]
上式中θd表示文档d的主题分布,βk表示主题k对应的词语分布,α,η为dirichlet分布的超参数,表示向量。
[0027][0028]
其中,表示狄利克雷分布,表示分布概率,表示分布的参数,αk表示k维度的参数,k表示分布的维度。
[0029]
对于数据中任意篇文档d中的第n个词,可以从主题分布中得到它的主题编号z
dn
的分布为multi(θd),而对于该主题编号,得到词w
dn
的概率分布为其中multi表示多项式分布,表示主题编号为z
dn
的词分布。组成了dirichlet-multi共轭,multi共轭,组成了dirichlet-multi共轭,其中表示d文档中词的主题编号分布,βk表示主题编号k的词分布,表示观测词的分布,因此:
[0030][0031][0032]
其中,表示d文档中词对应的主题编号的分布条件,表示d文档中各个主题的词的计数,表示k主题对应词的条件分布,表示k主题中各个词的分布,δ表示归一化。
[0033]
本发明可以得到主题和词的联合分布如下:
[0034][0035]
其中,表示主题和词的联合分布,
∝
表示成比例关系,表示超参数条件下的联合分布,表示所有文档主题的先验条件分布,表示所有主题对应的词的条件分布,m表示文档的总数。
[0036]
使用gibbs采样算法对lda进行求解,每个词对应主题的gibbs采样的条件概率公式为:
[0037][0038]
其中,zi表示i对应的主题,i是一个二维下标,对应第d篇文档的第n个词;表示去掉下标为i的词对应的主题后的主题分布;表示去掉下标为i的词对应的主题后,在第d个文档中第k个主题的词的个数;表示去掉下标为i的词对应的主题后,在k个主题中第t个词的个数;η
t
表示t对应的分布参数;表示去掉下标为i的词对应的主题后,在d个文档中第s个主题的词的个数;αs表示主题s对应的参数分布;v表示总词数;表示去掉下标为i的词对应的主题后,在k个主题中第f个词的个数;ηf表示词f对应的分布参数。
[0039]
b)训练时,指定主题数k,指定超参数向量对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号z;重新扫描语料库,对于每一个词,利用gibbs采样公式更新它的主题编号,并更新语料中该词的编号;重复gibbs采样直至收敛;统计语料库中的各个文档各个词的主题,得到文档主题分布θd,统计语料库中各个主题词的分布,得到lda的主题与词的分布βk。
[0040]
c)在预测时,对应当前文档的每一个词,随机赋予一个主题编号z;然后重新扫描当前文档,对于每一个词,利用gibbs采样公式更新它的主题编号;重复gibbs采样直至采样收敛;统计文档中各个词的主题,得到该文档主题分布。
[0041]
进一步地,在步骤3)中,包括以下步骤:
[0042]
a)bert-dgcnn模型使用两个形式一致但权重不共享的conv1d网络,其中一个使用激活函数而另一个不使用,之后再逐位相乘:
[0043][0044]
其中,y表示卷积输出,x表示卷积输入,conv1d1、conv1d2表示一维卷积,表示逐位相乘,σ表示sigmoid激活函数。
[0045]
b)bert-dgcnn模型使用残差结构将输出1-ξ的概率直接通过,以ξ的概率经过变换后通过:
[0046][0047]
ξ=σ(conv1d2(x))
[0048]
其中,σ表示sigmoid函数。
[0049]
c)bert-dgcnn模型使用如下损失函数:
[0050][0051]
其中y
ti
为标签值,yi为预测值,y
ti
logyi为原始交叉熵损失函数。δi为边界指示函数,n为样本数,其定义如下:
[0052][0053]
其中θi=sign((y
i-0.5)(y
ti-0.5)),用来表示已可分样本,m为样本被正确识别的阈值。
[0054]
进一步地,步骤4)中,包括以下步骤:
[0055]
a)基于span方式获取每个论元实体的向量表示,基于bert softmax进行数据表征和预测。
[0056][0057]
其中,s
i,j
表示数据的向量表示,表示逐列向量连接,
⊙
表示逐元素相乘,hi为输入xi经过bert编码后的输出:[h1,h2,
…
,hn]=bert(x),s
i,j
会经过多层感知机的处理并使用softmax计算获取表示标签分布的输出o
i,j
。
[0058]
其中,span方式即span标注策略,是指直接对多个token组成的候选子片段整体进行标注,而非对每个token进行序列标注。
[0059]
b)在训练时,会对所有非标注的片段进行负采样。这是因为在所有的非标注的片段中,可能存在一部分漏标的实体。对其进行负采样,可以有效降低漏标对抽取效果的负面影响。根据如下公式进行负采样:
[0060][0061]
其中,表示采样实体的数量,n表示输入句子的长度,m表示标注实体的数量,i表示采样数据的下标。
[0062]
通过负采样,不将漏标注实体作为负样本的概率大于可以有效缓解漏标注导致的指标下降。
[0063]
c)最后使用span-level(指直接对多个token组成的候选子片段整体进行标注)的
max pooling静态池化策略,本发明将其更改为动态多池化,动态多池化是指使用多个不同大小的池化层而非一个固定大小的池化层,如下所示:
[0081]ciα
,c
iβ
,c
iγ
…
=f_split(ci,split_n)
[0082]c′
ij
=1-maxpooling(c
ij
)
[0083]c′i=concat(c
′
ij
)
[0084]
其中,c
iα
,c
iβ
,c
iγ
…
表示卷积层输出向量的切分,f_split表示切分函数,ci表示动态多池化的输入,c
ij
表示单个池化操作的输出,c
′i表示动态多池化的输出,concat表示向量连接操作,本发明随机将卷积层的输出向量进行切分后,对切分后的向量再进行1-max pooling,切分次数split_n为3。最后利用训练好的模型处理更多来自计算机、科技等相关资讯网站的数据,将被模型标记为正例的数据作为有效目标数据c
′
。
[0085]
(3)利用lda模型对c
′
数据进行软聚类,尝试不同的主题数量n_topics参数并按照perplexity(困惑度)的大小选择最佳语言模型,perplexity的计算方式如下式:
[0086][0087]
其中,d表示c
′
中的测试集,共m篇文档,nd表示每篇文档d中的单词数,wd表示文档d中的词,p(wd)即文档中词wd产生的概率。
[0088]
(4)根据lda模型的聚类结果,总结出语料中包含的事件类型,制定事件schema。并在lda聚类效果的基础上,人工对被错误分配主题的数据进行修正调整,从而构建事件分类训练数据。其中,制定事件schema具体包括:
①
目标事件类型,如“数据泄露事件”、“报告发布事件”、“网络攻击事件”、“漏洞披露事件”;
②
各事件的目标论元角色,如“网络攻击事件”的论元角色为“攻击方”、“被攻击方”、“攻击方式”、“发生时间”。
[0089]
(5)使用事件分类训练数据训练bert dgcnn模型框架如图3所示,由bert、膨胀卷积层dgcnn、平均池化层avg pooling和全连接层dense组成。图3中predicate list表示模型预测的事件类别列表。其中预训练模型采用chinese-bert-wwm-ext,该模型使用12层的transformer,共110m参数量。训练超参数为:序列长度max_length为256,批次大小batch_size为32,学习率为2e-5,dropout为0.3,训练轮数epoch为10。
[0090]
(6)根据bert dgcnn模型获得的结果,使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。舆情事件论元抽取使用的深度学习模型框架如图4所示,其中训练超参数为:训练长度max_length为256,批次大小batch_size为32,学习率为1e-5,dropout为0.1,训练轮数epoch为15。在进行负采样时,首先获取排除标注实体的候选集,然后从候选集中根据负采样率λ采集出其大小负采样率λ设置为0.3。
[0091][0092][0093]
这里o表示非实体标签,l表示所有标签空间,表示采样实体集合,表示候选实体集合,random_choice表示随机选取操作;(i,j,o)表示以xi为头以xj为尾,并以o为标签的非实体片段;(i,j,l)表示以xi为头以xj为尾,并以l为标签的未标注实体片段;y表示标注实体集合,n表示输入句子长度。
[0094]
基于同一发明构思,本发明的另一实施例提供一种基于开源软件供应链的软件安全舆情事件抽取装置,其包括:
[0095]
目标文本识别模块,用于构建基于textcnn和动态多池化的文本分类模型,利用该文本分类模型从大量互联网网页文本中识别属于网络信息安全领域的目标文本;
[0096]
主题聚类模块,用于利用lda模型对目标文本进行主题聚类,并在聚类基础上构建事件schema;
[0097]
事件分类模块,用于对lda模型的聚类结果数据进行人工修正,作为事件分类训练数据,利用事件分类训练数据训练bert-dgcnn事件分类模型;
[0098]
论元识别模块,用于根据bert-dgcnn事件分类模型获得的事件分类结果,使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。
[0099]
基于同一发明构思,本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0100]
基于同一发明构思,本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
[0101]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。