技术特征:
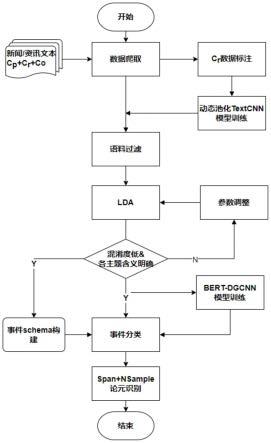
1.一种基于开源软件供应链的软件安全舆情事件抽取方法,其步骤包括:构建基于textcnn和动态多池化的文本分类模型,利用该文本分类模型从大量互联网网页文本中识别属于网络信息安全领域的目标文本;利用lda模型对目标文本进行主题聚类,并在聚类基础上构建事件schema;对lda模型的聚类结果数据进行人工修正,作为事件分类训练数据,利用事件分类训练数据训练bert-dgcnn事件分类模型;根据bert-dgcnn事件分类模型获得的事件分类结果,使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。2.如权利要求1所述的方法,其特征在于,所述大量互联网网页文本,是从信息安全领域相关的资讯网站、it领域资讯网站、以及其他新闻/资讯网站,利用网络爬虫大规模获取的新闻/资讯文本。3.如权利要求1所述的方法,其特征在于,所述基于textcnn和动态多池化的文本分类模型,是在textcnn模型中增加动态多池化策略。4.如权利要求1所述的方法,其特征在于,所述构建基于textcnn和动态多池化的文本分类模型,利用该文本分类模型从大量互联网网页文本中识别属于网络信息安全领域的目标文本,包括:a)使用预先训练的词嵌入模型构建输入特征向量,n为一个句子中的token数,k是每个token对应的词向量的维度,则textcnn模型的输入层为一个n
×
k维的矩阵,使用x
i
表示句子中第i个token的k维嵌入;b)利用卷积层对textcnn的输入层的特征进行提取,每个卷积核kernel与一个窗口的词向量进行卷积操作,产生一个特征c
i
:c
i
=f(w
·
x
i:i h-1
b)其中,x
i:i h-1
表示输入矩阵从第i行到第i h-1行所组成的一个大小为h
×
k的窗口,f表示非线性函数,w表示h
×
k维的权重矩阵,b表示偏置参数;c)使用textcnn的池化层将每个滑动窗口产生的特征向量中选出代表特征,并将这些特征拼接起来构成向量表示;获取向量表示后接入一个全连接层,并使用softmax激活函数输出目标文本与非目标文本两个类别的概率。5.如权利要求1所述的方法,其特征在于,所述利用lda模型对目标文本进行主题聚类,包括:a)假设文档主题的先验分布是dirichlet分布,假设主题中词的先验分布是dirichlet分布,使用gibbs采样算法对lda进行求解,得到每个词对应主题的gibbs采样公式;b)训练时,指定主题数k,指定dirichlet分布的超参数向量对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号z;重新扫描语料库,对于每一个词,利用gibbs采样公式更新它的主题编号,并更新语料中该词的编号;重复gibbs采样直至收敛;统计语料库中的各个文档各个词的主题,得到文档主题分布θ
d
,统计语料库中各个主题词的分布,得到lda的主题与词的分布β
k
;c)在预测时,对应当前文档的每一个词,随机赋予一个主题编号z;然后重新扫描当前文档,对于每一个词,利用gibbs采样公式更新它的主题编号;重复gibbs采样直至采样收敛;统计文档中各个词的主题,得到该文档主题分布。
6.如权利要求1所述的方法,其特征在于,所述利用事件分类训练数据训练bert-dgcnn事件分类模型,包括:a)bert-dgcnn模型使用两个形式一致但权重不共享的conv1d网络,其中一个使用激活函数而另一个不使用,之后再逐位相乘:其中,y表示卷积输出,x表示卷积输入,conv1d1、conv1d2表示一维卷积,表示逐位相乘,σ表示sigmoid激活函数;b)bert-dgcnn模型使用残差结构将输出1-ξ的概率直接通过,以ξ的概率经过变换后通过:ξ=σ(conv1d2(x))其中,σ表示sigmoid函数;c)bert-dgcnn模型使用如下损失函数:其中,y
ti
为标签值,y
i
为预测值,y
ti
logy
i
为原始交叉熵损失函数,δ
i
为边界指示函数,n为样本数。7.如权利要求1所述的方法,其特征在于,所述使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别,是将事件论元识别、论元值抽取作为序列标注处理,使用span标注策略处理论元实体嵌套的情况,使用负采样降低漏标数据对抽取效果的负面影响,具体包括:a)基于span方式获取每个论元实体的向量表示,基于bert softmax进行数据表征和预测;其中span方式是指直接对多个token组成的候选子片段整体进行标注,而非对每个token进行序列标注;b)在训练时,对所有非标注的片段进行负采样,根据如下公式进行负采样:
其中,表示采样实体的数量,n表示输入句子的长度,m表示标注实体的数量,i表示采样数据的下标;c)最后使用直接对连续文本整体进行标注的交叉熵损失函数:其中,前半部分为标注集合的损失计算,后半部分为采样集合的损失计算;o
i,j
[l]表示标注实体的预测分数;(i,j,l)表示以x
i
为头以x
j
为尾,并以l为标签的标注实体片段;y表示标注实体标注集合;o
i
′
,j
′
[l
′
]表示采样实体的预测分数,(i
′
,j
′
,l
′
)表示以x
i
′
为头以x
j
′
为尾,并以l
′
为标签的采样实体片段;表示采样实体集合。8.一种基于开源软件供应链的软件安全舆情事件抽取装置,其特征在于,包括:目标文本识别模块,用于构建基于textcnn和动态多池化的文本分类模型,利用该文本分类模型从大量互联网网页文本中识别属于网络信息安全领域的目标文本;主题聚类模块,用于利用lda模型对目标文本进行主题聚类,并在聚类基础上构建事件schema;事件分类模块,用于对lda模型的聚类结果数据进行人工修正,作为事件分类训练数据,利用事件分类训练数据训练bert-dgcnn事件分类模型;论元识别模块,用于根据bert-dgcnn事件分类模型获得的事件分类结果,使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。9.一种电子装置,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行权利要求1~7中任一项所述方法的指令。10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储计算机程
序,所述计算机程序被计算机执行时,实现权利要求1~7中任一项所述的方法。
技术总结
本发明涉及一种基于开源软件供应链的软件安全舆情事件抽取方法与装置。该方法包括:1)利用网络爬虫大规模获取新闻/资讯文本。2)构建TextCNN 动态多池化文本分类模型,用于快速过滤掉其他领域的非目标数据。3)利用LDA模型对领域内数据进行主题聚类,并在此基础上构建事件schema。4)对LDA模型的聚类结果数据进行少量人工修正,以此训练BERT-DGCNN事件分类模型。5)使用采用span标注策略和负采样策略的深度学习模型对事件论元值进行识别。本发明提供了完整的舆情事件抽取方案,它根据领域文本数据的特点,充分避免对高质量标注数据的依赖,且能够处理事件论元实体嵌套等复杂情况,有效地提升了进行信息安全领域舆情事件抽取的效果。的效果。的效果。
技术研发人员:吴敬征 武延军 崔星 罗天悦
受保护的技术使用者:中国科学院软件研究所
技术研发日:2022.09.30
技术公布日:2023/1/31
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。