一种基于网络编码的gps轨迹数据路段流量匹配方法
技术领域
1.本发明属于智能交通数据处理技术领域,涉及一种基于网络编码的gps轨迹数据路段流量匹配方法。
背景技术:
2.城市交通的特征因不同城市的人口规模、主要产业、地理位置等差异而有所不同,但是它们具有的类似的主要特点,即城市交通的重点是客运、通勤是交通高峰时期的主要交通需求、城市交通量大小与各城市的交通服务水平和交通政策和交通管理有直接关系等。随着我国机动车保有量的持续提升,城市交通拥堵问题愈发严重。微观层面的交通管理与控制是解决交通拥堵问题的有效手段,如何识别交通拥堵的常发路段与常发时间则是管理与控制的基础。
3.现有的交通调查设备通常安装在城市的主要通道上,覆盖面窄,难以有效监测全路网的流量情况,相比之下,gps设备覆盖面广,更能反映交通的实际情况。然而,gps设备采集的空间信息只包括经纬度且存在误差,难以直接在路网中定位,从而获取各路段的交通实际情况。基于此,相关领域的技术人员设计了各类地图匹配算法,但现有算法在面向全市域车辆大规模匹配时均面临计算速率的问题。
4.由于城市路网结构复杂、机动车保有量规模庞大、不同人群出行特征差异性大,因此产生了量级庞大的出行数据。在地图匹配中,范围越广的路网所包含的空间信息与拓扑关系就越多,所涉及的计算量也就越大,因此,当前通用的地图匹配算法在大数据应用中均面临着计算速率的问题,常规的地图匹配算法在面对城市交通的大规模轨迹点时难以达到实时响应的应用效果。
5.因此,设计一种基于网络编码的gps轨迹数据路段流量匹配方法,在保证匹配精度的前提下进行地图的快速匹配,提高地图匹配计算效率。
技术实现要素:
6.本发明的目的是针对现有的技术存在上述问题,提出了一种基于网络编码的gps轨迹数据路段流量匹配方法,本发明要解决的技术问题是:如何提高地图匹配计算效率。
7.本发明的目的可通过下列技术方案来实现:
8.一种基于网络编码的gps轨迹数据路段流量匹配方法,包括以下步骤:
9.s1、简化路网,在步骤s1中包括以下步骤:
10.s101、获取路网信息:准备路网文件,准备的路网文件需包含路网节点、坐标、路段方向等信息;
11.s102、将路网地图划分为三级等大小网格,网格大小根据路网大小而定;
12.s103、对已分级的网格进行编码,编码规则如下:编码共计14位数,前5位代表一级解码的x方向,6至10位代表一级编码的y方向;11位代表二级编码的x方向,12代表二级编码的y方向;13位代表三级编码的x方向,14代表三级编码的y方向;
13.编码公式以输入的经纬度为基础的,编码公式如下(见式1):
[0014][0015]
其中,min为起始点坐标,起点坐标为(0,0);gridsize为精确度,一级至三级网格精确度分别设置为0.01,0.002,0.0004;lat为经度坐标,lon为纬度坐标,min
lat
和min
lon
分别为地图网格化的初始最小经度和纬度;
[0016]
s104、对所有路段进行赋码,各路段均赋予一段序列,序列为路段所经过网格的编码序列,根据道路的方向对序列进行排序,并建立两个字典来存储两者关系,字典一键为路段编号,值为编码序列,字典二键为编码序列,值为网格内的路段编号;
[0017]
s2、对gps轨迹数据进行预处理,在步骤s2中包括以下步骤:
[0018]
s201、删除空值:删除gps轨迹数据列表中部分数据(车牌,时间,经度,纬度)为空的数据,删除空间位置在路网边界外的数据,数据按时间顺序进行排序;
[0019]
s202、对车辆按车牌号进行分类存储;
[0020]
s203、保留停留点:分别筛选出每辆车经纬度不变或距离小于15米的连续轨迹数据(两个及以上),当连续轨迹数据的时间跨度小于30分钟时,只保留第一个轨迹点,否则保留第一个轨迹数据与最后一个轨迹数据,并且给这两个轨迹数据打上停留点(车辆位置一段时间保持不变的轨迹点,车辆此时可能处于停留状态)的标签,使其不会后续的去重操作而删除;
[0021]
s204、删除异常数据:删除时间与速度异常的点,计算相邻坐标点之间的距离和时间差,再利用距离除以时间差得到速度,如果速度大于34米/每秒,将后点视为数据异常并删除后点,如果速度小于8米/每秒并且时间差大于600秒,视作车辆停止并删除后点;
[0022]
s205、对每辆车均循环步骤s203与步骤s204,得到预处理后的轨迹数据;
[0023]
s3、根据车辆轨迹点所在网格匹配路段,各匹配路段连通形成多个轨迹段,在步骤s3 中包括以下步骤:
[0024]
s301、根据轨迹点的经纬度匹配网格,在原数据中添加一列,用于存储匹配网格的编码;
[0025]
s302、相邻轨迹点去重:判断相邻轨迹点网格编码是否一致,一致则只保留第一个轨迹点,通过去重函数删除相邻轨迹重复值,去重函数表达式如下(见式2):
[0026]
dedupl(code
list
)=dedupl(code(code1,code2,,code3
…
coden))=
[0027]
code
list
{code1,code2,
…
coden}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式2)
[0028]
其中,dedupl()为去重函数,code(code1,code2,
…
coden)为相邻轨迹点集合, code
list
为经过去重最终保留的轨迹点;
[0029]
s303、通过步骤s104中的字典二获取轨迹点对应网格内的所有路段作为该轨迹点的候选路段集合;
[0030]
s304、对步骤s303得到的所有轨迹点进行删除判定(判断哪些轨迹点需要删除),判定步长为3(即每次判定相邻的3个轨迹点),每次判定的前进步长为1;判定规则如下:
[0031]
如果相邻轨迹点对应的候选路段备选集合完全相同,则删除后一个轨迹点的路段集合,公式如下(见式3),
[0032]
dedpul{point1[way1,way2,way3],point2[way1,way2,way3]}=
[0033]
{[point1,point2][way1,way2,way3]}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(式3)
[0034]
其中,dedpul{}为去重函数,point1[way1,way2,way3],point2[way1,way2,way3]为对应的候选路段集合完全相同的两个相邻轨迹点,该数据集合认定为轨迹点数据重复录入, [point1,point2][way1,way2,way3]为去重后得到的轨迹点;
[0035]
若相隔一个轨迹点的两个轨迹点的路段集合完全相同,则认为相隔的轨迹点发生偏移,对其进行删除,公式如下(见式4),
[0036]
dedpul{point1[way1,way2,way3],point2[way4,way5],point3[way1,way2,way3]}=
[0037]
{[point1,point3][way1,way2,way3],point2[way4,way5]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式4)
[0038]
其中,dedpul{}为去重函数,point1[way1,way2,way3],point3[way1,way2,way3]为对应的候选路段集合完全相同的,间隔距离为相隔一轨迹点的两个轨迹点,该数据集合认定为轨迹点发生偏移导致数据重复录入,[point1,point3][way1,way2,way3]为去重后得到的轨迹点;
[0039]
s305、构建轨迹路段集合,初始为空集,用于存储步骤s306的判定结果;
[0040]
s306、对s304结果中的相邻轨迹点的候选路段集合进行保留判定(判断路段集合中的哪些路段需要保留),判定步长为2,判定通过则存储至步骤s305构建的轨迹路段集合中,并建立轨迹点与候选路段的对应关系,判定不通过时停止,转至步骤s307;第一次判定将第一轨迹点与第二轨迹点符合条件的候选路段存储至轨迹路段集合中,第二次判定的对象为第二轨迹点与第三轨迹点,此时第二轨迹点的候选路段已在轨迹路段集合中,添加的仅为第三轨迹点符合条件的候选路段,以此类推,往后每次判定的对象实际是轨迹路段集合中最后一个轨迹点与其相邻的未在集合中的轨迹点;
[0041]
判定路段保留的规则为:当相邻轨迹点候选路段集存在相同路段时保留相同路段,此时轨迹路段集合中已有该路段,无需添加;存在不同路段时,判断路段间的连通性,当路段间可连通则保留,并将保留的路段集合添加至轨迹路段集合;判断路段之间连通性的规则如下:
[0042]
s3061、存在开始路段a与结束路段b,首先判断两个路段是否有交叉点,如果有,则会判断路段a与路段b交点是否为a的起点与b的终点,若是则路段a不能到达路段b,判断结束;若无交点将路段a存入候选路段集中,并继续以下步骤;
[0043]
s3062、每次只需要查找候选路段集中最后一个路段的下一步相连路段(方向也需一致),如果有相连路段,将路段加入对应的候选路段集即可;若相连路段有两个,则会生成两个候选路段集,对相连路段分别存储,以此类推,储存规则公式如下(见式5,对有两个相连路段的结束路段,在进行轨迹构建时根据式5可以得到两个候选路段集);
[0044]
candidate
waylist1
=[way1,way2]
[0045]
candidate
waylist2
=[way3,way4]
[0046]
intersection{candidate
waylist1
,candidate
waylist2
}=
[0047]
{[pointcode1,pointcode2],[[way1,way3],[way2,way3]]}
ꢀꢀꢀꢀꢀꢀ
(式5)
[0048]
其中,intersection{}为判断连通性函数,candidate
waylist
为存储的判定结果, pointcode为轨迹点编码,[way1,way2],[way3,way4],[way1,way3],[way2,way3]为存储的开始路段和结束路段;
[0049]
当对所有的候选路段操作完毕后转至步骤s3063;
[0050]
s3063、对于类似路段{1,2,3,1}的候选路路段进行剔除,这种会被判别为主辅路交替行驶;
[0051]
s3064、为防止连通性判断时间过长,设定候选路段集合中路段数目为8,当候选路段集合中的数量为8,还没找到可行路线时,认为两个路段不可达;若可达则将候选路段集合添加至轨迹路段集合中;
[0052]
s307、当步骤s306判断不通过时,对轨迹数据进行分段,即认为当前轨迹点为路径的终点(当前路段集合的最后一个路段);同时,认为下一轨迹点为新路径的起点(新路段集合的第一个路段),转至步骤s305;
[0053]
s4、在步骤s3中得到了多个轨迹路段集合,在5公里范围内查找可以连接相邻轨迹段的路段,如果同一批轨迹点存在多条轨迹路段,则每条轨迹路段均会与上一轨迹段与下一轨迹段相连,最终形成多条完整的轨迹;
[0054]
会存在两种轨迹段不相连的情况:(1)两个轨迹段之间的距离大于5公里;(2)程序中采取的路网与车辆行驶的路网之间存在差别;
[0055]
s5、选取步骤s4中的最短完整轨迹作为最终匹配轨迹,根据路网关系查询步骤s3与步骤s4中添加路段的节点经纬度和节点的网格编码,利用节点填补缺失的轨迹点,确保所有路段与轨迹点均有对应关系,最后赋予时间;
[0056]
缺失轨迹点的时间计算规则如下:利用需填补的轨迹点与上一轨迹点的距离除以上一轨迹点的速度,得到两轨迹点时间差,上一轨迹点的时间加上时间差即为填补轨迹点的时间;
[0057]
s6、通过对各辆车均循环步骤s3至步骤s5,获得各车辆的轨迹点与路段的空间对应关系以及车辆出现在各路段上的时间;将得到的所有车辆轨迹数据根据路段编号(link)进行分类存储,得到各路段对应的轨迹数据集合,再根据集计(在传统的交通规划或交通需求预测中,通常首先将对象地区或群体划分为若干个小区或群体等特定的集合体,然后以这些小区或群体为基本单位,展开问题的讨论,在建立模型或将样本放大时,需要以这一类的集合体为单位对数据进行集计处理,通过上述集计处理得到的数据称为集计数据,而用集计数据所建立的模型称为集计模型)的时间要求(如小时粒度、15分钟粒度)对轨迹数据集合进行进一步的划分,得到分路段、分时段的轨迹数据集,进行轨迹数据去重,去重后的数据量即为该路段在该时段的流量;
[0058]
本步骤中的轨迹数据去重规则如下:车牌号为车辆的唯一识别标识,故选择轨迹数据集合中的车牌号列作为数据去重的参照列,并按车牌号列进行排序(升序或降序均可),对车牌号出现重复的轨迹数据进行删除,只保留第一行数据。
[0059]
根据需要可以集计得到该路段的日流量、早晚高峰流量或不同区域的流量。
[0060]
与现有技术相比,本基于网络编码的gps轨迹数据路段流量匹配方法具有以下优点:
[0061]
本专利通过基于网络编码的gps轨迹数据路段流量匹配方法,在地图匹配前对道路进行拓扑构建和路网完整网格化,充分考虑实际中可能出现的情况并对轨迹进行简化预处理,提升了匹配准确率,减少了地图匹配时间成本,大幅度提高了地图匹配计算效率,面对城市交通的大规模交通流量时能够达到实时响应的应用效果。
附图说明
[0062]
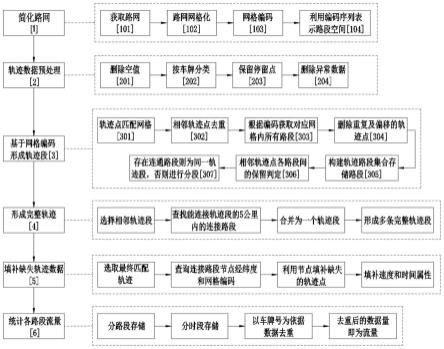
图1是本发明的技术路线示意图;
[0063]
图2是采用本发明方法进行轨迹匹配的耗时分布图;
[0064]
图3是采用本发明方法进行轨迹匹配的时间分布比例图;
具体实施方式
[0065]
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
[0066]
下面详细描述本专利的实施例,所述实施例的示例在附图中示出。下面通过参考附图描述的实施例是示例性的,仅用于解释本专利,而不能理解为对本专利的限制。
[0067]
请参阅图1,本实施例提供了一种基于网络编码的gps轨迹数据路段流量匹配方法,本实施例以车牌号为京ap5***的车辆的轨迹数据为例,采用本方法进行gps轨迹数据路段流量匹配处理。具体步骤如下:
[0068]
s1、简化路网,选取北京路网shp文件,提取空间信息进行拓扑关系化简,包括以下步骤:
[0069]
s101、获取路网信息:准备北京路网shp文件,准备的路网文件需包含路网节点、坐标、路段方向等信息。
[0070]
s102、将路网地图划分为三级等大小网格;根据北京路网的实际大小设置三级网格的大小:一级网格大小设置为1.2km*609.4m,二级网格大小设置为152.9m*152.4m,三级网格设置为39.2m*19m。
[0071]
s103、对已分级的网格进行编码,编码规则如下:编码共计14位数,前5位代表一级解码的x方向,6至10位代表一级编码的y方向;11位代表二级编码的x方向,12代表二级编码的y方向;13位代表三级编码的x方向,14代表三级编码的y方向;
[0072]
编码公式以输入的经纬度为基础的,编码公式如下(见式1):
[0073][0074]
其中,min为起始点坐标,起点坐标为(0,0);gridsize为精确度,一、二、三级网格精确度分别设置为0.01,0.002,0.0004;lat为经度坐标,lon为纬度坐标,min
lat
和min
lon
分别为地图网格化的初始最小经度和纬度。
[0075]
s104、对所有路段进行赋码,各路段均赋予一段序列,序列为路段所经过网格的编码序列,根据道路的方向对序列进行排序,如道路id为4263917的编码序列为 ["11633039913431","11633039913421","11633039913411","11633039912451","1163303 9912441"];建立两个字典来存储两者关系,字典一键为路段编号,值为编码序列,字典二键为编码序列,值为网格内的路段编号。
[0076]
s2、对gps轨迹数据进行预处理,在步骤s2中包括以下步骤:
[0077]
s201、删除空值:删除gps轨迹数据列表中部分数据(车牌,时间,经度,纬度)为空的数据,删除空间位置在路网边界外的数据,数据按时间顺序进行排序。
[0078]
s202、对车辆按车牌号进行分类存储。
[0079]
s203、保留停留点:分别筛选出每辆车经纬度不变或距离小于15米的连续轨迹数据(两个及以上),当连续轨迹数据的时间跨度小于30分钟时,只保留第一个轨迹点,否则保
留第一个轨迹数据与最后一个轨迹数据,并且给这两个轨迹数据打上停留点(车辆位置一段时间保持不变的轨迹点,车辆此时可能处于停留状态)的标签,使其不会后续的去重操作而删除。
[0080]
s204、删除异常数据:删除时间与速度异常的点,计算相邻坐标点之间的距离和时间差,再利用距离除以时间差得到速度,如果速度大于34米/每秒,将后点视为数据异常并删除后点,如果速度小于8米/每秒并且时间差大于600秒,视作车辆停止并删除后点。
[0081]
s205、对每辆车均循环步骤s203与步骤s204,得到预处理后的轨迹数据。
[0082]
京ap5***车辆的gps轨迹数据经过预处理后的数据量为437条,截取预处理后的2020年 1月13日某采样车的部分数据示例见表1。
[0083]
表1预处理后的车辆轨迹数据示例
[0084][0085][0086]
s3、根据车辆轨迹点所在网格匹配路段,各匹配路段连通形成多个轨迹段,以京ap5*** 车辆的gps轨迹数据为例,在步骤s3中包括以下步骤:
[0087]
s301、根据京ap5***车辆各个轨迹点的经纬度匹配网格,在原数据中添加一列,用于存储匹配网格的编码。
[0088]
s302、相邻轨迹点去重:判断相邻轨迹点网格编码是否一致,一致则只保留第一个轨迹点,通过去重函数删除相邻轨迹重复值,去重函数表达式如下(见式2):
[0089]
dedupl(code
list
)=dedupl(code(code1,code2,,code3
…
coden))=
[0090]
code
list
{code1,code2,
…
coden}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式2)
[0091]
其中,dedupl()为去重函数,code(code1,code2,
…
coden)为相邻轨迹点集合, code
list
为经过去重最终保留的轨迹点;
[0092]
经过步骤s301与步骤s302得到有网格编码的数据共62条,截取部分轨迹数据示例见表 2。
[0093]
表2含网格编码的车辆轨迹数据示例
[0094][0095][0096]
s303、通过步骤s104中的字典二获取京ap5***车辆轨迹点对应网格内的所有路段作为该轨迹点的候选路段集合;共计140条link,截取该轨迹点候选路段集合的部分数据示例见表3。
[0097]
表3轨迹点候选路段集合示例
[0098][0099]
s304、对步骤s303得到的京ap5***车辆所有轨迹点进行删除判定,判定步长为3,
每次判定的前进步长为1;判定规则如下:
[0100]
如果相邻轨迹点对应的候选路段备选集合完全相同,则删除后一个轨迹点的路段集合,公式如下(见式3),
[0101]
dedpul{point1[way1,way2,way3],point2[way1,way2,way3]}=
[0102]
{[point1,point2][way1,way2,way3]}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(式3)
[0103]
其中,dedpul{}为去重函数,point1[way1,way2,way3],point2[way1,way2,way3]为对应的候选路段集合完全相同的两个相邻轨迹点,该数据集合认定为轨迹点数据重复录入, [point1,point2][way1,way2,way3]为去重后得到的轨迹点;
[0104]
若相隔一个轨迹点的两个轨迹点的路段集合完全相同,则认为相隔的轨迹点发生偏移,对其进行删除,公式如下(见式4),
[0105]
dedpul{point1[way1,way2,way3],point2[way4,way5],point3[way1,way2,way3]}=
[0106]
{[point1,point3][way1,way2,way3],point2[way4,way5]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式4)
[0107]
其中,dedpul{}为去重函数,point1[way1,way2,way3],point3[way1,way2,way3]为对应的候选路段集合完全相同的,间隔距离为相隔一轨迹点的两个轨迹点,该数据集合认定为轨迹点发生偏移导致数据重复录入,[point1,point3][way1,way2,way3]为去重后得到的轨迹点。
[0108]
s305、构建轨迹路段集合,初始为空集,用于存储步骤s306的判定结果。
[0109]
s306、对s304结果中的相邻轨迹点的候选路段集合进行保留判定,判定步长为2,判定通过则存储至步骤s305构建的轨迹路段集合中,并建立轨迹点与候选路段的对应关系,判定不通过时停止,转至步骤s307。第一次判定将第一轨迹点与第二轨迹点符合条件的候选路段存储至轨迹路段集合中,第二次判定的对象为第二轨迹点与第三轨迹点,此时第二轨迹点的候选路段已在轨迹路段集合中,添加的仅为第三轨迹点符合条件的候选路段,以此类推,往后每次判定的对象实际是轨迹路段集合中最后一个轨迹点与其相邻的未在集合中的轨迹点。
[0110]
判定路段保留的规则为:当相邻轨迹点候选路段集存在相同路段时保留相同路段,此时轨迹路段集合中已有该路段,无需添加;存在不同路段时,判断路段间的连通性,当路段间可连通则保留,并将保留的路段集合添加至轨迹路段集合;判断路段之间连通性的规则如下:
[0111]
s3061、存在开始路段a与结束路段b,首先判断两个路段是否有交叉点,如果有,则会判断路段a与路段b交点是否为a的起点与b的终点,若是则路段a不能到达路段b,判断结束;若无交点将路段a存入候选路段集中,并继续以下步骤;
[0112]
s3062、每次只需要查找候选路段集中最后一个路段的下一步相连路段(方向也需一致),如果有相连路段,将路段加入对应的候选路段集即可;若相连路段有两个,则会生成两个候选路段集,对相连路段分别存储,以此类推,储存规则公式如下(见式5,对有两个相连路段的结束路段,在进行轨迹构建时根据式5可以得到两个候选路段集);
[0113]
candidate
waylist1
=[way1,way2]
[0114]
candidate
waylist2
=[way3,way4]
[0115]
intersection{candidate
waylist1
,candidate
waylist2
}=
[0116]
{[pointcode1,pointcode2],[[way1,way3],[way2,way3]]}
ꢀꢀꢀꢀꢀꢀ
(式5)
[0117]
其中,intersection{}为判断连通性函数,candidate
waylist
为存储的判定结果, pointcode为轨迹点编码,[way1,way2],[way3,way4],[way1,way3],[way2,way3]为存储的开始路段和结束路段;
[0118]
当对所有的候选路段操作完毕后转至步骤s3063;
[0119]
s3063、对于类似路段{1,2,3,1}的候选路路段进行剔除,这种会被判别为主辅路交替行驶;
[0120]
s3064、为防止连通性判断时间过长,设定候选路段集合中路段数目为8,当候选路段集合中的数量为8,还没找到可行路线时,认为两个路段不可达;若可达则将候选路段集合添加至轨迹路段集合中。
[0121]
s307、当步骤s306判断不通过时,对轨迹数据进行分段,即认为当前轨迹点为路径的终点(当前路段集合的最后一个路段);同时,认为下一轨迹点为新路径的起点(新路段集合的第一个路段),转至步骤s305。
[0122]
步骤s3的结果见表4,表4为截取的各轨迹段候选路段集合示例。由于连通性判断未通过时会导致轨迹数据分段,故最终得到的候选路段总集合为各轨迹段的候选集合的汇总。其中,网格编码只存储轨迹段的起点与终点;以网格编码为键,对应的值为该轨迹段的候选路径,候选路径可以有多条,均作为最终路段的备选。
[0123]
[0124][0125]
表4各轨迹段候选路段集合示例
[0126]
s4、在步骤s3中得到了多个轨迹路段集合,在5公里范围内查找可以连接相邻轨迹段的路段,如果同一批轨迹点存在多条轨迹路段,则每条轨迹路段均会与上一轨迹段与下一轨迹段相连,最终形成多条完整的轨迹;如从起点网格11646039863413至终点网格 11644039864424(见表4),完整的轨迹为[187844581,150585627,240635778,164948575] 与[187844581,26403549,240635778,164948575],每个候选路径均会出现在完整轨迹中。这里存在两种轨迹段不相连的情况:(1)两个轨迹段之间的距离大于5公里;(2) 程序中采取的路网与车辆行驶的路网之间存在差别。
[0127]
s5、选取步骤s4中的最短完整轨迹作为最终匹配轨迹,根据路网关系查询步骤s3与步骤s4中添加路段的节点经纬度和节点的网格编码,利用节点填补缺失的轨迹点,确保所有路段与轨迹点均有对应关系,最后赋予时间;
[0128]
缺失轨迹点的时间计算规则如下:利用需填补的轨迹点与上一轨迹点的距离除以上一轨迹点的速度,得到两轨迹点时间差,上一轨迹点的时间加上时间差即为填补轨迹点的时间;计算公式如下:
[0129]
t
缺失轨迹点
=t
上一轨迹点
s/v
上一轨迹点
[0130]
式中,t
缺失轨迹点
为缺失轨迹点的时间,t
上一轨迹点
为上一轨迹点的时间,s为缺失轨迹点与上一轨迹点的距离,v
上一轨迹点
为上一轨迹点的速度。
[0131]
s6、通过对各辆车均循环步骤s3至步骤s5,获得各车辆的轨迹点与路段的空间对应关系以及车辆出现在各路段上的时间;将得到的所有车辆轨迹数据根据路段编号(link)进行分类存储,得到各路段对应的轨迹数据集合,再根据集计的时间要求(如小时粒度、15 分钟粒度)对轨迹数据集合进行进一步的划分,得到分路段、分时段的轨迹数据集,进行轨迹数据去重,最终得到各路段在不同时段的流量。
[0132]
本步骤中的轨迹数据去重规则如下:车牌号为车辆的唯一识别标识,故选择轨迹数据集合中的车牌号列作为数据去重的参照列,并按车牌号列进行排序,对车牌号出现重复的轨迹数据进行删除,只保留第一行数据。
[0133]
与现有技术相比,本基于网络编码的gps轨迹数据路段流量匹配方法具有较高的路段准确率和计算效率,具体如下:
[0134]
(1)路段准确率
[0135]
由于本发明所采用的匹配基础为三级网格,并不以点与线之前的权重距离作为匹配的依据,在理论上会出现连续的轨迹点与匹配路段并不重合的情况,为更精确地描述本发明的准确性,设立路段准确率指标。路段准确率指匹配正确的路段占总路段数的百分比,匹配的道路与轨迹点存在重合且道路方向与轨迹前进方向一致则认为匹配正确,计算方法见式6。
[0136][0137]
其中,accuracy为路段准确率,numa为匹配正确的路段数量,num
all
为匹配的路段总数。
[0138]
现有地图匹配算法,采取常用的几何算法——融合方向的权重地图匹配算法作为对比。其中,基于最大权重的地图匹配算法是通过降噪、分段、压缩、附近道路检索、匹配以及组合分段几个阶段,通过方向相似度等指标的计算和权重筛选得到车辆匹配路段。选取车辆轨迹数据计算融合方向的权重地图匹配算法与基于本发明中涉及的地图匹配算法的路段准确率,部分车辆结果如表5所示。
[0139]
表5融合方向的权重地图匹配算法与基于网络编码的gps轨迹数据路段流量匹配方法的路段准确率对比
[0140] 京aap***京adm***京alx***京awp***融合方向的权重算法93.40%92.90%89.60%95.20%基于网格编码的算法100%99.40%97.90%99.20%
[0141]
由表5可见,融合方向的权重算法与本发明中涉及的基于网格编码的算法均有较高的准确率,但基于网格编码的算法准确率更高。在实际匹配中,融合方向的权重算法对偏移的数据仍会进行保留且匹配,导致准确率相对较低。
[0142]
(2)计算效率
[0143]
现有地图匹配算法,采取了常用的几何算法——融合方向的权重地图匹配算法作为对比,该方法的虽然能较好的完成轨迹匹配,但是垂足位置、垂直距离、轨迹与路网角度都设计到复杂计算。该方法每完成一辆车的轨迹匹配,平均耗时5分钟左右。
[0144]
采用本发明基于网络编码的gps轨迹数据路段流量匹配方法,通过路网完整网格化,即采用三级网格化的方法进行轨迹匹配,经过实验,耗时时间分布图如图2所示,横坐标为耗时区间(单位:秒),纵坐标为车辆数(单位:辆),与图2相对应的时间分布比例图如图3所示,可看出有94%的车辆能在10s内完成轨迹匹配,本方法具有较高的计算效率,在时间上可满足项目需求,达到实时快速响应的效果。
[0145]
上面对本专利的较佳实施方式作了详细说明,但是本专利并不限于上述实施方式,在本领域的普通技术人员所具备的知识范围内,还可以在不脱离本专利宗旨的前提下做出各种变化。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。