一种基于swin-transformer与yolov5模型集成的手术器械清点方法
技术领域
1.本发明属于医疗器械管理技术领域,具体涉及一种基于swin-transformer与yolov5模型集成的手术器械清点方法。
背景技术:
2.随着科技的不断进步,计算机技术与医疗的联系越来越紧密,而将计算机视觉应用到医疗领域的例子也越来越多,云阅片和机器人无接触送药等事实也证明这些技术确实提供了非常大的助力。而在医疗过程中,手术器械是现代手术的基础,随着现代医学的飞速发展,手术器械的种类呈井喷式增长。每种不同类型的手术器械都对应了手术中的某些特定操作,高度专职化,所以通常不同手术都需要配备相应的手术包,手术包包含了完成手术所需的所有手术器械。而为了保证手术的正常进行以及防止医疗事故的发生,需要对手术包的手术器械进行分类清点。目前手术包的器械清点工作都是通过人工方式完成的,但是这种方法需要消耗大量的人力并且效率低下。因此,发展手术器械的自动分类清点具有重要意义。因此,开发一种高效、高准确率的手术器械自动分类的清点方法显得尤为重要。
3.而计算机视觉技术中的目标检测模型在训练后,可以实现对输入图像中的物体进行识别,实现自动分类和计数,可以高效的代替人工清点,减少人力资源的消耗,在实际清点环境中,无论是手术室环境还是仓储环境下,手术器械的种类数都非常巨大,包含各种形状的手术器械,尤其是包含许多长条形状器械,普通的yolov5模型无法检测此类器械。而swin-transformer(即实例分割模型)对于长条形状具有较好的检测效果,但采用swin-transformer针对器械种类数量较多,对于多角度的数据采集成本较高。
4.鉴于此,为了减少图像采集成本和模型训练成本,同时提高实际手术包清点工作环境下手术器械自动清点的准确率,本发明采用将对swin-transformer和普通的yolov5模型进行集成,同时融入视频流数据的检测,将多张图片的检测结果融合,开发一种基于swin-transformer与yolov5模型集成的手术器械清点方法。
技术实现要素:
5.本发明的目的在于提供了一种基于swin-transformer与yolov5模型集成的手术器械清点方法,以解决现有人工方式清点手术器械工作量大及检测结果准确率低的技术问题。
6.为实现上述目的,本发明提供如下技术方案:
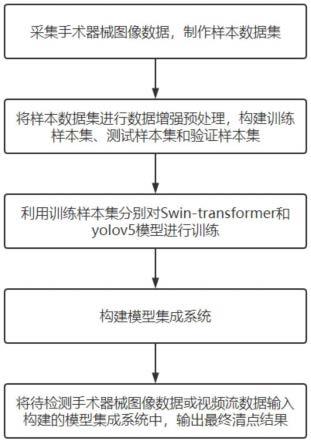
7.一种基于swin-transformer与yolov5模型集成的手术器械清点方法,包括以下步骤:
8.s1、采集手术器械图像数据,制作样本数据集;
9.s2、将样本数据集进行数据增强预处理,并对数据增强预处理后的数据集进行划分,构建训练样本集、测试样本集和验证样本集;
10.s3、利用训练样本集分别对swin-transformer和yolov5模型进行训练,并将训练结束后的模型分别作为目标检测swin-transformer和目标检测yolov5模型;
11.s4、构建模型集成系统;
12.所述模型集成系统包括:数据源检测处理模块、目标检测yolov5模型、目标检测swin-transformer以及数据合并分析模块,且所述数据源为手术器械图像数据或视频流数据,其中,
13.数据源检测处理模块的输入端输入数据源,数据源检测处理模块的输出端分别与目标检测swin-transformer和目标检测yolov5模型的输入端相连接,目标检测yolov5模型和目标检测swin-transformer并联连接,目标检测swin-transformer和目标检测yolov5模型的输出端分别与数据合并分析模块的输入端相连接,数据合并分析模块的输出端输出最终预测结果;
14.所述数据源检测处理模块,用于对输入的数据源进行检测判别和处理,若检测所述数据源判别为图像数据,则直接将所述图像数据分别输入到目标检测yolov5模型和目标检测swin-transformer中;若判别为视频流数据,则抽取所述视频流数据中的图像帧,构成图像数据集,然后将构成的图像数据集分别输入目标检测swin-transformer和目标检测yolov5模型中;
15.所述目标检测swin-transformer,用于检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果;
16.所述目标检测yolov5模型,用于检测图像数据中的普通形状器械,并输出普通形状器械的清点预测结果;
17.所述数据合并分析模块,用于将目标检测swin-transformer和目标检测yolov5模型各自输出的清点预测结果进行合并分析,并输出最终清点预测结果;
18.s5、将待检测手术器械图像数据或视频流数据输入构建的模型集成系统中,输出最终清点结果。
19.优选的,步骤s1中,所述采集手术器械图像数据,制作样本数据集,具体步骤包括:
20.a1、将手术器械按形状分成两批,分别为长条形状器械和普通形状器械,然后分开对长条形状器械和普通形状器械进行拍摄,采集手术器械图像数据;
21.a2、对所采集的手术器械图像数据进行标注,得到标签数据,并将所得标签数据保存在json文件中;其中,长条形状器械采用异形框标注,普通形状器械采用矩形框标注;
22.a3、将得到的json文件和手术器械图像集成保存在同一个文件中,同时将所得文件中的标签数据格式转换成coco格式,得到样本数据集。
23.优选的,步骤a1中,所述分开对长条形状器械和普通形状器械进行拍摄时,还包括以下步骤:
24.a11、搭建图像采集平台,并保证拍照条件统一;
25.a12、将每批手术器械按照紧靠摆放和交叉摆放的方式随机摆放在图像数据采集平台上,且每种摆放方式的图像数量比例相等,以模拟实际应用中各种复杂情况,确保图像所包含的特征信息的丰富性和平衡性;
26.a13、在分开对长条形状器械和普通形状器械进行采集时,根据设计要求拍摄指定数量的图像,采集手术器械图像数据。
27.优选的,步骤a2中,所述对采集的手术器械图像数据进行标注,具体步骤为:将采集的长条形状器械图像数据和普通形状器械图像数据分别采用标注软件进行标注,得到标签数据,然后将各自得到的标签数据保存在json文件中,得到长条形状器械json文件和普通形状器械json文件。
28.优选的,步骤a3中,所述将得到的json文件和手术器械图像集成保存在同一文件中,同时将所得文件中的标签数据的格式转换成coco格式,具体步骤为:将得到的长条形状器械json文件和长条形状器械图像集成保存到同一文件中,并将所述文件中采用标注软件标注的标签数据的格式转换为coco格式,制作长条形状器械样本数据集;同理,将得到的普通形状器械json文件和普通形状器械图像集成保存到同一文件中,并将所述文件中采用标注软件标注的标签数据的格式转换为coco格式,制作普通形状器械样本数据集。
29.优选的,步骤s2中,所述数据增强预处理采用mosaic数据增强方式,具体为:将完成标注的手术器械图像随机缩放、裁剪、排布和拼接来扩充样本数据集。
30.优选的,步骤s2中,所述构建训练样本集、测试样本集和验证样本集,具体步骤为:将数据增强预处理后的长条形状器械样本数据集进行划分,依次得到长条形状器械训练样本集、长条形状器械验证样本集以及长条形状器械测试样本集;同理,将数据增强预处理后的普通形状器械样本数据集进行划分,得到普通形状器械训练样本集、普通形状器械验证样本集以及普通形状器械测试样本集。
31.优选的,步骤s3中,所述利用训练样本集分别对swin-transformer和yolov5模型进行训练,具体步骤为:将长条形状器械训练样本集输入swin-transformer中进行训练,保存训练好的网络参数,得到目标检测swin-transformer;将普通形状器械训练样本集输入yolov5模型中进行训练,保存训练好的网络参数,得到目标检测yolov5模型。
32.优选的,步骤s5中,所述将待检测手术器械图像数据或视频流数据输入构建的模型集成系统中,输出最终清点结果,具体步骤为:
33.当将所述图像数据输入构建的的模型集成系统中时,由数据源检测处理模块将所述图像数据分别输入目标检测swin-transformer和目标检测yolov5模型中,然后由目标检测swin-transformer检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果至数据合并分析模块中;由目标检测yolov5模型检测清点图像数据中的普通形状器械,并输出普通形状器械的清点预测结果至数据合并分析模块中,最后由数据合并分析模块将目标检测swin-transformer和目标检测yolov5模型输出的清点预测结果进行合并分析,输出最终清点预测结果;
34.当将所述视频流数据输入构建的的模型集成系统中时,由数据源检测处理模块对输入的视频流数据进行抽取处理,抽取所述视频流数据中的图像帧,构成图像数据集,并将构成的图像数据集分别输入目标检测swin-transformer和目标检测yolov5模型中,然后由目标检测swin-transformer检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果至数据合并分析模块中,由目标检测yolov5模型检测清点图像数据中的普通形状器械,并输出普通形状器械的清点预测结果至数据合并分析模块中,最后由数据合并分析模块将目标检测swin-transformer和目标检测yolov5模型输出的所述图像数据集中所有图像数据输出的清点预测结果进行融合,然后求平均值,即为视频流数据最终的清点预测结果。
35.与现有技术相比,本发明有益效果如下:
36.(1)本发明中,在构建的模型集成系统中,采用swin-transformer和yolov5模型两种模型并联处理,分工合作,其中,swin-transformer(即实例分割模型)针对长条形状器械,yolov5模型针对普通形状器械,从而能够实现对复杂形状手术器械的自动分类和清点工作,大幅度提高清点效率,减少人力资源的消耗。
37.(2)本发明中,构建的模型集成系统可同时支持针对手术器械图像数据和视频流数据的清点检测,其中,在构建的模型集成系统中融入对视频流数据的检测,即通过多角度的拍摄方式对手术器械进行拍摄,形成视频流数据,然后对视频流数据抽取处理为若干个图像帧,即若干个图像数据,然后融合视频流数据中所有图像帧(即图像数据)的检测结果,求取平均值,即为视频流数据最终的清点预测结果,这样操作可减少检测单张手术器械图像漏检情况的发生,降低数据成本的同时提高系统的检测精度。
38.(3)本发明清点方法通过图像数据和视频流数据两种方式进行手术器械的清点检测,大大提高了手术器械清点的准确率与精准度。
附图说明
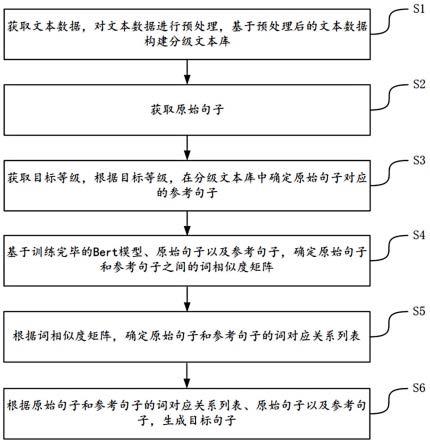
39.图1为本发明提出的一种基于swin-transformer与yolov5模型集成的手术器械清点方法的流程图;
40.图2为swin-transformer的backbone网络结构的示意图;
41.图3为yolov5模型的backbone网络结构的示意图;
42.图4为本发明中构建的模型集成系统的示意图。
具体实施方式
43.下面将结合本发明实施例及附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
44.下面结合图1-3,描述本发明提供的一种基于swin-transformer和yolov5模型集成的手术器械清点方法,包括以下步骤:
45.s1、采集手术器械图像数据,制作样本数据集;
46.具体地,包括以下步骤:
47.a1、将手术器械按形状分成两批,分别为长条形状器械和普通形状器械,然后分开对长条形状器械和普通形状器械进行拍摄,采集手术器械图像数据;
48.具体地,将所有手术器械按形状划分为两批,分别为长条形状器械和普通形状器械,然后搭建图像数据采集平台,该图像采集平台主要包括:拍摄相机,光源(用于模拟实际工作光照环境),医用包布(作为背景),钢制支架(保证手术器械、相机和照明灯固定),图像采集平台的搭建是为了统一拍照条件,规范后续的拓展实验,在图像数据采集平台上,将每一批手术器械按照不同姿势,包括按照紧靠摆放和交叉摆放的方式,依次随机摆放在图像数据采集平台上,每拍摄一张图片都需要变动摆放位置,保证每一张图像所包含的手术器械位置的信息具有特异性,这种摆放方案可以尽可能地模拟实际应用中的复杂情况,极大的丰富图像所包含的特征信息;然后开始图像数据的采集,两批手术器械需要分开进行采集,采集过程中相机高度需要保持不变,并模拟实际工作环境下光照条件,然后根据设计要
求拍摄指定图像数量,每种摆放方式的图像数量比例大致相等,这种图像采集方式可以保持数据包含信息量大且各种信息平衡,提高训练效果;
49.a2、对所采集的手术器械图像数据进行标注,得到标签数据,并将所得标签数据保存在json文件中;其中,长条形状器械采用异形框标注,普通形状器械采用矩形框标注;
50.采用标注软件进行标签标注,标注出各种手术器械图像位置和种类;具体地,首先将完成图像数据采集的手术器械设定标签名,然后将所有图像输入机器学习标注软件中进行标注,其中,长条形状器械采用异形框标注,即每一张图像中的全部手术器械使用多边形描绘出器械轮廓,多边形轮廓标注可以提供实例分割模型训练所需的像素级信息,然后对应上相应的标签名,标注完成后,将所有标签数据保存在json文件中,得到长条形状器械json文件,且该长条形状器械json文件保存包括标签名、图片名和多边形轮廓位置等标注信息;其中,多边形轮廓位置信息是通过在整张图像上建立初始坐标系,记录多边形各个顶点的x轴和y轴坐标。这样可以保证标签文件记录足够多的像素级信息;普通形状(非长条形状)器械按照与长条状器械标注步骤基本相同,不同之处在于普通形状器械采用矩形框标注,即采用矩形框框出器械位置,得到标签数据,并保存在json文件中,得到普通形状器械json文件,且该普通形状器械json文件保存包括标签名、图片名和矩形框轮廓位置等标注信息;
51.a3、将得到的json文件和手术器械图像集成保存在同一个文件中,同时将所得文件中的标签数据格式转换成coco格式,得到样本数据集;
52.具体地,将上述得到的长条形状器械json文件和长条形状器械图像集成保存到同一文件中,并将所得文件中的采用标注软件标注的标签数据格式转换为可以直接输入swin-transformer训练的数据类型,即coco格式,制作长条形状器械样本数据集;同理,将得到的普通形状器械json文件和普通形状器械图像集成保存到同一文件中,并将所得文件中采用标注软件标注的标签数据的格式转换为可以直接输入目标检测yolov5模型训练的数据类型,即coco格式,制作普通形状器械样本数据集
53.s2、将样本数据集进行数据增强预处理,并对数据增强预处理后的数据集进行划分,构建训练样本集、测试样本集和验证样本集;
54.具体地,采用mosaic数据增强方式对样本数据集进行数据增强预处理,以增强模型的学习效果,即将多张完成标注的图像随机缩放、裁剪和排布拼接来扩充样本数据集,进而增强网络模型的泛化性,确保检测结果的准确性。
55.接着,将数据增强预处理后的样本数据集按7:2:1的比例(划分比例不作特别限定)进行划分,依次得到训练(样本)集、测试(样本)集和验证(样本)集;其中,训练(样本)集用于训练网络模型,得到权重参数;验证(样本)集用于训练过程验证网络模型的检测效果,并根据检测效果调整网络模型的超参数;测试(样本)集用于最后网络模型的精度测试。具体地,将数据增强预处理后的长条形状器械样本数据集按7:2:1的比例进行划分,依次得到长条形状器械训练样本集、长条形状器械验证样本集以及长条形状器械测试样本集;同理,将数据增强预处理后的普通形状器械样本数据集按7:2:1的比例进行划分,得到普通形状器械训练样本集、普通形状器械验证样本集以及普通形状器械测试样本集;
56.s3、利用训练样本集分别对swin-transformer和yolov5模型进行训练,并将训练结束后的模型分别作为目标检测swin-transformer和目标检测yolov5模型;
57.具体地,(1)将长条形状器械训练样本集输入swin-transformer中进行训练,保存训练好的网络参数,得到目标检测swin-transformer;
58.参照图2,为swin-transformer,即实例分割模型的backbone网络结构的示意图,该backbone网络的结构主要由四个stage组成,每个stage包含一个patch merging和若干的实例分割模型block结构,其中patch merging的主要作用是降采样,用于调整图像分辨率,以及调整通道数进而形成层次化的模型架构设计,同时也能减少一定运算量。按批量输入的图片可以看成是大小为(b,c,w,h)的四维向量,每次降采样都是两倍比例,因此在行方向和列方向上,间隔2选取元素,类似池化操作。然后拼接在一起作为一整个张量,最后在通道维度上进行展开。此时通道维度会增加到先前的4倍(因为h,w各缩小2倍),此时再连接一个全连接层来调整通道维度为原来的两倍,同时聚合特征信息。
59.从数据输入的角度描述整个过程为:首先,通过patch partition使用kernel size和stride均为4的卷积操作将图片的h和w降为原来的1/4,然后通过patch embedding进行维度变换处理,将特征信息压缩,将h,w展开,并和c交换,得到(b,w*h,c)的三维向量,然后将其输入swin-transformer block中,归一化后恢复到原来的(b,c,w,h),然后再进行窗口划分,窗口划分的意思就是将w和h两个维度进行裁切,划分成数个大小相同的四维向量,将自注意力计算限制在单个窗口中,使每个小向量的维度为(b,c,w,h),再进行维度变化变为(b,w*h,c)然后将为每个不同位置窗口的向量设置一个位置编码,使其进行self attention的时候可以融合进位置信息;其中,上述之所以进行窗口划分,是因为直接将一个完整的向量进行self attention,计算量会非常大,通过窗口划分后再分别计算可以减轻网络的计算量,将复杂度降低到图像尺寸的线性比例;其中,self attention计算采用下述公式(1):
[0060][0061]
其中,q=x
×
wq,k=x
×
wk,v=x
×
wv,x为输入的向量,wq、wk以及wv为转换矩阵,由模型的初始参数决定。
[0062]
为了防止过拟合,在进行self attention计算之前需对向量进行ln操作。
[0063]
从self attention层中输出后将各个窗口重新拼接成一个完整向量,再接一个ln层和三层全连接层,这一整个结构称为w-msa,该结构中还包含了残差连接操作,后面步骤与w-msa结构基本完全一样,唯一区别是后面进行self attention操作之前对向量额外进行了shift操作,这里可以理解为将一张图片的上部和左部剪切在拼接到右部和下部,然后再进行划分窗口,这个结构称为sw-msa,这两个结构组合成一个模块,构成一个完整的实例分割模型block模块,即为swin-transformer的backbone的整体结构。
[0064]
手术器械图像经backbone提取特征后,将会输出一组向量,称为特征图,特征图的每一个点将会提前设定一定个数的roi,从而获得多个候选roi,再将所有roi送入rpn层网络中进行二分类和bb回归,此步操作可以过滤掉一部分候选的roi;接着对过滤剩下的roi进行roialign操作(即先将原图和特征图的像素对应起来,然后将特征图和固定的特征对应起来),然后使用fpn(feature pyramid networks)网络进行类别分类和bb回归,进行二次过滤候选roi,然后使用fcn(fully convolutional networks)生成mask,即像素掩码,以
此区分不同对象来实现实例分割。
[0065]
该swin-transformer的损失函数l,采用下式(2)计算:
[0066]
l=l
cls
l
box
l
mask
ꢀꢀꢀꢀ
(2)
[0067]
其中,pi为anthor预测为目标的概率,为anthor预测为目标的概率,是两个类别(目标vs非目标)的对数损失:
[0068][0069][0070][0071]
其中,y为二元标签;p(y)为标签y的概率。
[0072]
(2)将普通形状器械训练样本集输入yolov5模型中进行训练,保存训练好的网络参数,得到目标检测yolov5模型;
[0073]
参照图3,为yolov5模型的backbone网络结构的示意图,该backbone网络的结构主要由cbl模块、csp模块、focus模块和spp模块搭建组合而成。其中,cbl模块主要由卷积操作、batch normalization正则化和leaky relu激活连续排列组成,而csp模块则是将两个支路的图像特征图使用cocat操作拼接在一起,然后将输出信息输入cbl模块中。focus模块的操作为将特征图使用slice切片操作分成4个支路然后拼接在一起,后面同样接上cbl模块,spp模块的设计目的为将特征图分成三个支路,其中两个支路使用最大池化操作,然后concat操作拼接在一起,然后接cbl模块。图像经过backbone网络处理后,分别由三个csp模块输出三个尺寸的特征图,特征图的尺寸分别为75*75*c、38*38*c、19*19*c,其中c表示为每个网格单元(网格单元即特征图的尺寸)预测3个box,所以每个box需要有(x,y,w,h,confidence)五个基本参数,其中x,y,w,h为预测框对于预先设计的anchor的偏移量,anchor坐标加上偏移量即为最后预测的缺陷框的大小和位置信息,confidence为这个预测框的置信度,然后包括有n个缺陷类别的概率(前景提取模型只有一个类)。所以3*(5 n)=c,其中不同尺寸的特征图分别进行不同尺寸缺陷的预测,尺寸的标准由anchor的大小统一决定。
[0074]
该yolov5模型的损失函数由classificition loss(即分类损失函数)和bounding box regeression loss(即回归损失函数)两者之和组成;其中,
[0075]
分类损失使用交叉熵损失,交叉熵损失函数h(p,q)的计算公式如下式(3)所示:
[0076][0077]
式中,q为预测的缺陷类别,p为实际的缺陷类别。
[0078]
回归损失函数为ciou loss,其计算公式如下式(4)所示:
[0079][0080]
其中,iou为预测框与实际框的相交域,其计算公式如下式(5)所示:
[0081][0082]
其中,b
gt
=(x
gt
,y
gt
,w
gt
,h
gt
)为实际框,b=(x,y,w,h)为预测框,为预测框b和实际框b
gt
的惩罚项,b和b
gt
分别表示b和b
gt
的中心点,ρ(
·
)为欧几里得距离,c为覆盖两个盒子的最小封闭盒子的对角线长度,进而最终得到yolov5网络模型的损失函数。
[0083]
上述两个模型训练结束后,按照最佳准确率分别保存好网络参数,得到目标检测swin-transformer和目标检测yolov5模型,用于后续模型集成系统的构建。
[0084]
s4、构建模型集成系统;
[0085]
由于手术器械种类数量庞大,若兼顾所有角度进行手术器械图像数据的采集以及标注,则成本非常高昂。鉴于此,本发明在构建的模型集成系统中融入了视频流数据的检测,即通过多角度的拍摄方式对手术器械进行拍摄,形成视频流数据,然后对视频流数据抽取处理为若干个图像帧,即若干个图像数据,然后融合视频流数据中所有图像帧(即图像数据)的检测结果,求取平均值,即为视频流数据最终的清点结果,这样操作可减缓检测单张手术器械图像漏检情况的发生,降低数据成本的同时,提高了系统的检测精确度。
[0086]
本发明构建的模型集成系统可同时支持针对图像数据和视频流数据进行手术器械的清点。具体地,参照图4,为本发明构建的模型集成系统的示意图,该模型集成系统包括:模型集成系统包括:数据源检测处理模块、目标检测yolov5模型、目标检测swin-transformer以及数据合并分析模块,且数据源为手术器械图像数据或视频流数据,其中,
[0087]
数据源检测处理模块的输入端输入数据源,数据源检测处理模块的输出端分别与目标检测swin-transformer和目标检测yolov5模型的输入端相连接,目标检测yolov5模型和目标检测swin-transformer并联连接,目标检测swin-transformer和目标检测yolov5模型的输出端分别与数据合并分析模块的输入端相连接,数据合并分析模块的输出端输出最终预测结果;
[0088]
数据源检测处理模块,用于对输入的数据源进行检测判别和处理,若检测数据源判别为图像数据,则直接将图像数据分别输入到目标检测yolov5模型和目标检测swin-transformer中;若判别为视频流数据,则抽取视频流数据中的图像帧,构成图像数据集,然
后将构成的图像数据集分别输入目标检测swin-transformer和目标检测yolov5模型中;
[0089]
目标检测swin-transformer,用于检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果;
[0090]
目标检测yolov5模型,用于检测图像数据中的普通形状器械,并输出普通形状器械的清点预测结果;
[0091]
数据合并分析模块,用于将目标检测swin-transformer和目标检测yolov5模型各自输出的清点预测结果进行合并分析,并输出最终清点预测结果。
[0092]
s5、将待检测手术器械图像数据或视频流数据输入构建的模型集成系统中,输出最终清点结果。
[0093]
具体地,(1)当将图像数据输入构建的的模型集成系统中时,由数据源检测处理模块将所述图像数据分别输入目标检测swin-transformer和目标检测yolov5模型中,然后由目标检测swin-transformer检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果至数据合并分析模块中,由目标检测yolov5模型检测清点图像数据中的普通形状器械,并输出普通形状器械的清点预测结果至数据合并分析模块中,最后由数据合并分析模块将两模型输出的清点预测结果进行合并,输出最终的清点结果;
[0094]
(2)当将视频流数据输入构建的的模型集成系统中时,由数据源检测处理模块对输入的视频流数据进行抽取处理,抽取所述视频流数据中的图像帧,构成图像数据集,并将构成的图像数据集分别输入目标检测swin-transformer和目标检测yolov5模型中,然后由目标检测swin-transformer检测图像数据中的长条形状器械,并输出长条形状器械的清点预测结果至数据合并分析模块中;由目标检测yolov5模型检测清点图像数据中的普通形状器械,并输出普通形状器械的清点预测结果至数据合并分析模块中,最后由数据合并分析模块将目标检测swin-transformer和目标检测yolov5模型输出的所述图像数据集中所有图像数据输出的清点预测结果进行融合,然后求平均值,即为视频流数据最终的清点结果。
[0095]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其改进构思加以等同替换或改变,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。