1.本发明涉及数据处理技术领域,具体涉及一种畜牧粪便成分检测与识别方法。
背景技术:
2.各种畜牧在养殖过程中常常会产生大量的粪尿,而这些粪尿中存在大量农作物生长所必需的氮磷钾等营养成分和大量有机质。目前畜牧粪便作为有机肥在农业生产中已得到了广泛应用,但如果不合理使用畜牧粪便或连续过量使用,不仅起不到应有的效果,还会影响农作物生长和人类健康,造成生态环境的二次污染,因此对于畜牧粪便的成分检测非常重要。
3.目前,对于畜牧粪便的成分检测的常用方法是:通过检测畜牧粪便的电阻率,选择畜牧种类和肥料成分种类,将检测到的电阻率、选择的畜牧种类和肥料成分种类作为输入来选择预测估算模型,利用预测估算模型对输入的数据进行分析,以根据分析结果计算畜牧粪便中的肥料成分含量。但是考虑到检测电阻率的传感器,随着长时间的使用,其稳定性和灵敏度都会下降,或者传感器的探针没有很完美的紧贴被测粪便,进而导致传感器数据存在较大误差,进而使得成分检测结果也存在较大误差。
技术实现要素:
4.为了解决上述技术问题,本发明的目的在于提供一种畜牧粪便成分检测与识别方法,所采用的技术方案具体如下:在畜牧粪便的成分检测过程中,根据每个采样时刻的畜牧粪便的电阻、测量设备在畜牧粪便中的应力和畜牧粪便的ph值,分别对应得到电阻序列、应力序列和ph值序列;根据所述电阻序列、应力序列和ph值序列构建所述成分检测过程中的特征矩阵;获取连续多个所述成分检测过程中的特征矩阵,基于明氏距离计算任意两个所述特征矩阵之间的相似程度,基于所述相似程度利用km算法将测量误差相似的两个所述成分检测过程作为一个匹配对,得到多个匹配对;根据当前匹配对所对应两个所述成分检测过程的上一个所述成分检测过程的所述特征矩阵,计算测量设备误差状态指数,将当前匹配对所对应两个所述成分检测过程中每个采样时刻的电阻、应力、ph值和所述测量设备误差状态指数构成对应采样时刻的特征向量;获取每个匹配对的所述测量设备误差状态指数,得到连续多个所述成分检测过程对应每个采样时刻的所述特征向量,利用所述特征向量训练lstm预测网络,以获取实时采样时刻下实时电阻、实时应力和实时ph值所对应的所述测量设备误差状态指数的预测值,利用预测值对畜牧粪便中检测的实时tk含量进行优化补偿,得到实际tk含量。
5.进一步的,所述特征矩阵的构建方法,包括:计算所述电阻序列中第k个电阻与前面第n个电阻之间的差值绝对值,k和n都为正整数,k大于n,以第k个电阻为底数、对应差值绝对值为幂指数得到的结果作为第k个电阻的第一误差因子,组成一维的第一误差因子序列;
计算所述应力序列中第k个应力与前面第n个应力之间的差值绝对值,以第k个应力为底数、对应差值绝对值为幂指数得到的结果作为第k个应力的第二误差因子,组成一维的第二误差因子序列;计算所述ph值序列中第k个ph值与前面第n个ph值之间的差值绝对值,以第k个ph值为底数、对应差值绝对值为幂指数得到的结果作为第k个ph值的第三误差因子,组成一维的第三误差因子序列;将所述电阻序列中的第k个电阻所对应的前n个电阻作为一个子集合,获取子集合中的最大电阻和最小电阻,分别计算第k个电阻与最大电阻之间的第一电阻差值绝对值、第k个电阻与最小电阻之间的第二电阻差值绝对值,以第二电阻差值绝对值为分子、第一电阻差值绝对值为分母得到对应的比值,将该比值作为第k个采样时刻的测量质量下降因子,组成一维的测量质量下降因子序列;其中第k个电阻是在第k个采样时刻采集的;将所述第一误差因子、所述第二误差因子、所述第三误差因子和所述测量质量下降因子序列组成所述成分检测过程中的4维特征矩阵。
6.进一步的,所述基于明氏距离计算任意两个所述特征矩阵之间的相似程度的方法,包括:分别计算两个所述特征矩阵中每个维度下的明氏距离,结合所有维度的明氏距离得到所述相似程度。
7.进一步的,所述测量设备误差状态指数的获取方法,包括:基于所述成分检测过程的先后顺序,分别获取当前匹配对所对应的两个所述成分检测过程相邻上一个所述成分检测过程的所述特征矩阵,将两个相邻的上一个所述成分检测过程的所述特征矩阵之间的相似程度作为当前匹配对的所述测量设备误差状态指数。
8.进一步的,所述利用预测值对畜牧粪便中检测的实时tk含量进行优化补偿,得到实际tk含量的方法,包括:获取实时tk含量与预测值之间的第一乘积;基于历史tk含量获取历史tk含量的中值,获取历史tk含量的中值与第一优化值之间的第二乘积,第一优化值与预测值之和为1,将第一乘积和第二乘积之间的均值作为实时tk含量。
9.本发明实施例至少具有如下有益效果:(1)获取成分检测过程中畜牧粪便的电阻、测量设备在畜牧粪便中的应力和畜牧粪便的ph值,根据连续测量过中的数据得到每个成分检测过程对应测量设备测量误差的特征矩阵,基于特征矩阵的相似性将测量误差相似的两个成分检测过程作为一个匹配对,根据匹配对中的两个成分检测过程的上一个成分检测过程的特征矩阵之间的差异,分析对应匹配对的测量设备误差状态指数,将测量设备误差状态指数作为对应成分检测过程中每个采样时刻的测量设备的测量误差指标,以保证了lstm预测网络的训练数据集的有效性和准确性,进而利用时序上每个采样时刻的电阻、应力、ph值和对应的测量设备误差状态指数对lstm预测网络进行训练,使得lstm预测网络的预测结果更加准确。
10.(2)利用训练好的lstm预测网络获取实时采样时刻下的测量设备误差状态指数,利用测量设备误差状态指数对实时检测的畜牧粪便的tk含量进行优化补偿,使得最后的检测结果更加接近真实值。
附图说明
11.为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
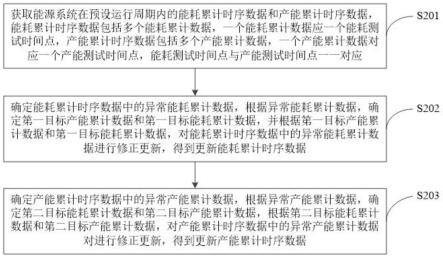
12.图1为本发明一个实施例提供的一种畜牧粪便成分检测与识别方法的步骤流程图。
具体实施方式
13.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种畜牧粪便成分检测与识别方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
14.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
15.下面结合附图具体的说明本发明所提供的一种畜牧粪便成分检测与识别方法的具体方案。
16.本方案所针对的具体场景为:畜牧粪便的自动化成分检测流程,此流程包括送料、成分检测、导料和堆垛。
17.请参阅图1,其示出了本发明一个实施例提供的一种畜牧粪便成分检测与识别方法的步骤流程图,该方法包括以下步骤:步骤s001,在畜牧粪便的成分检测过程中,根据每个采样时刻的畜牧粪便的电阻、测量设备在畜牧粪便中的应力和畜牧粪便的ph值,分别对应得到电阻序列、应力序列和ph值序列;根据电阻序列、应力序列和ph值序列构建成分检测过程中的特征矩阵。
18.具体的,对于畜牧粪便成分检测,一般是在批量的回收粪便过程中,对其进行抽样或连续采样检测,例如在传送带安装设备,探针持续采样。
19.首先,在畜牧粪便的成分检测过程中,获取每个采样时刻的畜牧粪便的电阻,以构成电阻序列。
20.具体的,电化学法是基于检测物在电化学反应过程中产生的电流、电阻或电位的变化进行检测的方法,在传统实践中,保证准确的电化学法的核心要义是电极材料和探针的选择,电极材料和探针能否紧贴被测粪便或粪便的固液性状决定了测量设备的稳定性和灵敏度等。故利用测量设备采集畜牧粪便的电阻,此处得到的是等效电阻,其中畜牧粪便的电阻的获取方法是公知技术,本方案中不再赘述。
21.优选的,本发明实施例中使用常规的插入粪便的接触式探头作为测量设备,每测量完成一个得到一个数值,数值单位为kω,因此将畜牧粪便的成分检测过程中每个采样时刻的电阻r构成电阻序列r。
22.然后,在畜牧粪便的成分检测过程中,获取每个采样时刻下测量检测畜牧粪便时,测量设备探入过程中受到的各向应力,构成应力序列。
23.具体的,因电阻测量时由于粪便过干裂开、撞击到异物、内部溏心等原因,不能保证粪便与测量设备的探头完全接触,进而会出现电阻数据的采集误差。为了提高粪便成分检测的准确性,引入测量设备采集时的各向应力。
24.为了测量电阻,测量设备的探针性状如同π形,且是一种直杆状的较细的插入式结构,通过上下导轨移动在完成穿透粪便的过程后具有一定的应力,使得探头能够紧贴粪便,因此通过确定测量设备的应力,以根据应力差异表征测量设备的采集误差。
25.鉴于粪便质地柔软,基于应力传感器获取所有的轴向应力分量和径向应力分量,将最大的应力分量作为对应采样时刻的测量设备在畜牧粪便中的应力p,进而得到畜牧粪便的成分检测过程中的应力序列p。
26.最后,在畜牧粪便的成分检测过程中,获取每个采样时刻的畜牧粪便的ph值,以构成ph值序列。
27.因粪便的来源不同,动物的消化系统特性的差异,导致ph指标不同,虽然不影响其正常施肥使用,但酸碱度能够体现粪便的金属盐和氨氮的理化特性,以便加以区分,故在畜牧粪便的成分检测过程中,利用测量设备采集每个采样时刻对应畜牧粪便的ph值,记为f,构成ph值序列f。
28.进一步的,为了能够准确评估畜牧粪便的测量设备的误差情况,通过对采集完成电阻序列r、应力序列p和ph值序列f进行计算与分析,能够得到畜牧粪便的测量设备的误差趋势。
29.计算电阻序列中第k个电阻与前面第n个电阻之间的差值绝对值,k和n都为正整数,k大于n,以第k个电阻为底数、对应差值绝对值为幂指数得到的结果作为第k个电阻的第一误差因子,组成一维的第一误差因子序列。
30.作为一个示例,令n为10,则第一误差因子的计算公式为:其中,为电阻序列中第k个电阻的第一误差因子;为电阻序列中的第k个电阻;为绝对值函数;为电阻序列中第k个电阻之前的第10个电阻。
31.需要说明的是,k10,也即是从电阻序列中的第10个电阻开始计算第一误差因子,由于前期畜牧粪便不会出现测量设备的测量误差,因此默认第10个电阻之前的电阻没有误差,进而将计算当前采样时刻的电阻和前面第10次采样时刻的电阻的差值,差值越大,说明当前采样时刻对应电阻的测量误差越大。
32.同理,计算应力序列中第k个应力与前面第n个应力之间的差值绝对值,k和n都为正整数,k大于n,以第k个应力为底数、对应差值绝对值为幂指数得到的结果作为第k个应力的第二误差因子,组成一维的第二误差因子序列。
33.作为一个示例,令n为10,则第二误差因子的计算公式为:其中,为应力序列中第k个应力的第二误差因子;为应力序列中的第k个应
力;为绝对值函数;为应力序列中第k个应力之前的第10个应力。
34.需要说明的是,k10,也即是从应力序列中的第10个应力开始计算第二误差因子,由于前期畜牧粪便不会出现测量设备的测量误差,因此默认第10个应力之前的应力没有误差,进而将计算当前采样时刻的应力和前面第10次采样时刻的应力的差值,差值越大,说明当前采样时刻对应应力的测量误差越大。
35.同理,计算ph值序列中第k个ph值与前面第n个ph值之间的差值绝对值,k和n都为正整数,k大于n,以第k个ph值为底数、对应差值绝对值为幂指数得到的结果作为第k个ph值的第三误差因子,组成一维的第三误差因子序列。
36.作为一个示例,令n为10,则第二误差因子的计算公式为:其中,为ph值序列中第k个ph值的第三误差因子;为ph值序列中的第k个ph值;为绝对值函数;为ph值序列中第k个ph值之前的第10个ph值。
37.需要说明的是,k10,也即是从ph值序列中的第10个ph值开始计算第三误差因子,由于前期畜牧粪便不会出现测量设备的测量误差,因此默认第10个ph值之前的ph值没有误差,进而将计算当前采样时刻的ph值和前面第10次采样时刻的ph值的差值,差值越大,说明当前采样时刻对应ph值的测量误差越大。
38.随着采样次数的增加,测量设备的测量数据的误差程度也会随之增加,相对应检测的畜牧粪便的检测质量也会逐渐下降,因此基于电阻序列中每个采样时刻下的电阻差异计算对应采样时刻下的测量质量下降因子,具体方法为:将电阻序列中的第k个电阻所对应的前n个电阻作为一个子集合,获取子集合中的最大电阻和最小电阻,分别计算子集合中第k个电阻与最大电阻之间的第一电阻差值绝对值、第k个电阻与最小电阻之间的第二电阻差值绝对值,以第二电阻差值绝对值为分子、第一电阻差值绝对值为分母得到对应的比值,由于电阻序列中的第k个元素是在第k个采样时刻下采集的,因此将该比值作为第k个采样时刻的测量质量下降因子,同理k10,进而得到一维的测量质量下降因子序列。
39.因畜牧粪便的检测质量时的测量设备的误差分析需要从多方面的数据来作支撑,单一方面的数据不能得到有力支持,因此结合电阻的第一误差因子序列、应力的第二误差因子序列、ph值的第三误差因子序列和测量质量下降因子序列构成畜牧粪便的成分检测过程中的特征矩阵,该矩阵包括4个维度,一个维度表示一行,第一维度为第一误差因子,第二维度为第二误差因子,第三维度为第三误差因子,第四维度为测量质量下降因子,其中该特征矩阵更加能够综合体现对应畜牧粪便的成分检测过程中因测量设备误差导致的畜牧粪便检测结果的变化情况。
40.步骤s002,获取连续多个成分检测过程中的特征矩阵,基于明氏距离计算任意两个特征矩阵之间的相似程度,基于相似程度利用km算法将测量误差相似的两个成分检测过程作为一个匹配对,得到多个匹配对;根据当前匹配对所对应两个成分检测过程的上一个
成分检测过程的特征矩阵,计算测量设备误差状态指数,将当前匹配对所对应两个成分检测过程中每个采样时刻的电阻、应力、ph值和测量设备误差状态指数构成对应采样时刻的特征向量。
41.具体的,成分检测系统是面向于批次成分检测中所有的成分检测过程,因此利用步骤s001的方法,获取连续多个成分检测过程中的特征矩阵u。
42.由于同一批次中不同成分检测过程对畜牧粪便的连续测量都是不同的,因此会出现在相同连续测量段内的特征矩阵是不同,故对任意两个成分检测过程所对应的特征矩阵计算其差异性。
43.由于特征矩阵是由多个不同方面的因素构成的,存在量纲,故此处采用明可夫斯基距离来表征两个特征矩阵之间的差异性,其中,明可夫斯基距离是欧式距离的推广,是对多个距离度量公式的概括性的表述,则基于明氏距离得到任意两个特征矩阵之间的相似程度的计算公式为:度的计算公式为:其中,为批次内成分检测过程a和成分检测过程b之间对应特征矩阵的相似程度;n为矩阵的维度;为成分检测过程a和成分检测过程b对应特征矩阵的第n维度之间的明氏距离;为成分检测过程a的特征矩阵中第n维度的第i个数值;为成分检测过程b的特征矩阵中第n维度的第i个数值;为常数。
44.明氏距离越大,说明这两个成分检测过程中的测量设备误差情况越不相同,对应两个成分检测过程之间对应特征矩阵的相似程度越小,当相似程度趋于0时,可认为这两个成分检测过程中的测量设备误差情况不相同。
45.由上述计算出的相似程度可以得知同一批次下不同的成分检测过程的畜牧粪便的测量设备误差情况是不同的,且不同成分检测过程之间的差异性都比较大,对于不同测量误差情况的畜牧粪便,可以使用km算法将测量误差相似的成分检测过程分配为相互对照的匹配对。
46.将任意两个成分检测过程之间的相似程度d投入到km算法中,将相似程度最大的两个成分检测过程进行匹配,得到畜牧粪便的测量设备误差最为接近的两个成分检测过程,将其作为一个匹配对,进而将多个成分检测过程进行了配对,得到了多个匹配对。
47.所配对的成分检测过程的畜牧粪便的测量设备误差是相同,若出现孤立的样本,则将其在后续的数据处理中视为一个匹配对,但匹配对中是两个同样的孤立样本。
48.基于km算法,根据每个成分检测过程中特征矩阵对多个成分检测过程进行匹配的目的是找到测量结果相似的数据,从而对其分析测量设备误差状态,即两个匹配对之间若
测量记录中误差较大,又因此匹配成一对,则很有可能是探头出现了误差。
49.根据匹配对中的两个成分检测过程的特征矩阵建立测量设备误差状态指数w,则测量设备误差状态指数w的构建方法为:以一个匹配对为例,基于成分检测过程的先后顺序,分别获取当前匹配对所对应的两个成分检测过程相邻上一个成分检测过程的特征矩阵,进而将两个相邻的上一个成分检测过程的特征矩阵之间的相似程度作为当前匹配对的测量设备误差状态指数。
50.需要说明的是,获取当前匹配对中两个成分检测过程相邻上一个成分检测过程的特征矩阵,进而计算两者之间的相似程度的目的是为了比较两个相邻上一个成分检测过程的特征矩阵对应测量设备误差是否一致,若不一致,则认为当前匹配对中两个成分检测过程相邻上一个成分检测过程的测量状态虽然不同,但最后导致当前匹配对中两个成分检测过程的测量状态又相同,则认为探头出现了较明显的因插入状态受到影响而导致的误差。
51.步骤s003,获取每个匹配对的测量设备误差状态指数,得到连续多个成分检测过程对应每个采样时刻的特征向量,利用特征向量训练lstm预测网络,以获取实时采样时刻下实时电阻、实时应力和实时ph值所对应的测量设备误差状态指数的预测值,利用预测值对畜牧粪便中检测的实时tk含量进行优化补偿,得到实际tk含量。
52.具体的,利用步骤s002的方法,获取每个匹配对所对应的测量设备误差状态指数w,且每个匹配对所对应的两个成分检测过程共用一个测量设备误差状态指数w,进而能够得到同一批次下连续多个成分检测过程对应每个采样时刻的特征向量。
53.将时序上的特征向量作为lstm预测网络的训练集,利用训练集训练lstm预测网络,且以特征向量中的电阻、应力和ph值作为lstm预测网络的输入数据、特征向量中的测量设备误差状态指数作为lstm预测网络的输出数据。由于lstm预测网络是一种端到端、序列到序列的深度神经网络,基于这样的训练集可以让lstm预测网络基于电阻、应力和ph值的连续变化特征预测对应的测量设备误差状态指数。
54.需要说明的是,lstm预测网络是公知技术,本方案中不再赘述。
55.利用步骤s001的采样方法,能够获取实时采样时刻下的实时电阻、实时应力和实时ph值,将实时电阻、实时应力和实时ph值输入训练好的lstm预测网络能够得到实时采样时刻下对应的测量设备误差状态指数的预测值。
56.基于实时电阻能够得到畜牧粪便中检测的实时tk含量,进而利用预测值对实时tk含量进行优化补偿,以得到实际tk含量。
57.作为一个示例,对于牛而言,其畜牧粪便中的tk含量的计算公式为tk=0.479/r 0.437;首先将实时电阻代入tk含量的计算公式中能够得到实时tk含量,然后基于历史计算的历史tk含量获取历史tk含量的中值,利用历史tk含量的中值和测量设备误差状态指数的预测值对实时采样时刻的实时tk含量进行优化补偿,得到实际tk含量,其优化补偿公式为:,其中,为实际tk含量,为实时含量,为预测值,为历史tk含量的中值。
58.需要说明的是,预测值越大,说明检测的实时tk含量的误差越大,畜牧粪便的识别结果越不准确,进而需要对实时tk含量进行更多的补偿,反之,预测值越小,说明检测的实
时tk含量的误差越小,畜牧粪便的识别结果越准确,进而对实时tk含量的补偿越少,因此预测值与实际tk含量之间呈正相关关系;历史tk含量的中值越大,预测值对中值的补偿越少,对应得到的实际tk含量越接近真实值。
59.综上所述,本发明实施例提供了一种畜牧粪便成分检测与识别方法,该方法获取畜牧粪便的成分检测过程中畜牧粪便的电阻、测量设备在畜牧粪便中的应力和畜牧粪便的ph值,以得到对应的特征矩阵;根据连续多个成分检测过程的特征矩阵将测量误差相似的两个成分检测过程作为一个匹配对,得到多个匹配对;计算每个匹配对的测量设备误差状态指数,以得到由电阻、应力、ph值和测量设备误差状态指数构成的特征向量;利用特征向量训练lstm预测网络,以根据预测值对畜牧粪便中检测的实时tk含量进行优化补偿。本发明利用训练好的lstm预测网络对实时检测的畜牧粪便的tk含量进行优化补偿,使得最终的检测结果更加接近真实值。
60.需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对本说明书特定实施例进行了描述。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
61.本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
62.以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。