1.本发明涉及一种基于批量更新的网络流概念漂移解决方法,属于网络管理技术领域。
背景技术:
2.实时分析主干网流量可以帮助服务提供商了解网络状态,动态优化网络带宽配置和流量路由策略,对于主干网管理具有重要意义。网络流量分类在网络管理中起着至关重要的作用,网络运营商可以通过监控不同类型流量在网络中的分布情况,进一步执行网络管理或网络安全策略。
3.由于随机端口和加密流量的增加,流量分类方法已经从传统的基于端口的方法和基于有效载荷的方法转变为基于统计的方法。基于统计的流量分类方法的本质是构建一个流量统计特征到分类类别的映射关系,此映射关系即为网络流量的“概念”。在大部分流量分类工作中,首先会依据历史流量样本实例建立映射关系,随后使用构建的映射关系预测新到达流量样本的类别。然而,这些流量分类工作忽视了网络流量的概念漂移问题:随着网络中流量的动态演变,流量的统计特征将随之发生改变,从而导致已有映射关系不再适用于新到达流量样本的分类。
4.概念漂移研究中的两个关键问题是何时更新分类器和如何更新分类器。就何时更新分类器而言,定期增量更新和检测后更新是两种主要方法。其中,定期增量更新方法在没有发生概念漂移的情况下,也会更新模型,浪费了时间和资源。然而,检测后更新方法也存在弊端。概念漂移的检测依赖于参数设置,不恰当的参数设置会导致错误和遗漏的警报。目前的研究大多是通过分类精度的降低来检测概念漂移,检测后更新方法需要事先对数据进行分类标签的标注,这需要大量的时间和资源,不适用于高速主干网流量的概念漂移检测。
5.此外,即使有效检测到概念漂移,如何及时更新分类模型也会影响主干网流量分类的准确性。有三种主要的分类模型更新方法:第一种是一次性更新方法,通过训练所有的历史数据和新到达的数据来获得一个新的分类模型,这在具有海量数据的主干网场景中是很耗时间和内存的。第二种是模型再训练法,基于集合学习思想,通过替换、增加或选择性地更新分类器集中的基础分类器来实现模型更新。这种方法对于大规模动态主干网络流量的分类是相对低效的。此外,模型再训练方法存在灾难性遗忘问题。第三种是基于实例的增量学习方法,通过训练新到达的数据来学习和更新分类模型,而不重新训练历史数据。然而,这种方法也存在更新开销和灾难性遗忘问题。
6.对网络流量分类方法来说,能够检测网络流量的动态演化带来的概念漂移问题并及时完成分类模型的更新仍是一个挑战。本发明旨在以合理的时间和内存,完成对概念漂移的检测,并更新主干网络海量流量的分类模型。
技术实现要素:
7.为了解决流量分类中的概念漂移问题,本发明首先通过概念漂移检测器监测分类
结果,然后根据漂移流量样本的数量来判断是否发生网络流概念漂移,自适应地触发分类模型的更新流程。其次,本发明基于漂移流量样本和历史流量样本进行批量更新,以获得更新后的聚类样本。最后,使用分类算法训练更新后的聚类样本来完成分类模型的更新,更新后的分类模型可用于分类后续到达的高速网络流量,该方法可以对网络流量进行自适应的概念漂移检测并自主完成分类模型的更新,可用于网络的流量分析和用户服务质量的保证。
8.一种基于批量更新的网络流概念漂移解决方法,该方法包括以下步骤:
9.步骤(1)构建流经主干网的包含漂移样本的流量数据集;
10.步骤(2)以步骤(1)构建的流量数据集作为输入,使用流量分类模型对新到达的流量特征进行预测和分类;
11.步骤(3)基于步骤(2)的分类结果,使用概念漂移检测器判断数据集中的流量是否发生概念漂移;
12.步骤(4)若数据集中的流量发生概念漂移,使用批量更新器对漂移样本和保存在本地的已聚类历史样本进行批量更新,获得更新后的聚类样本;
13.步骤(5)基于步骤(4)更新后的聚类样本中已标记的流量特征,使用有监督的机器学习算法构建新的分类模型;
14.步骤(6)使用步骤(5)中更新后的分类模型对后续到达的主干网流量进行分类。
15.进一步,步骤(1)中,构建流经主干网的包含漂移样本的流量数据集的方法如下:
16.(1.1)采集ddos流量数据,用于构建真实主干网中的漂移样本;
17.(1.2)混合ddos流量和在10gbps链路上收集的流量,用于构建流经主干网的包含漂移样本的流量数据集。
18.进一步,步骤(2)中,对新到达流量进行预测和分类的方法如下:
19.(2.1)由于tcp协议和udp协议的消息格式不同,可将流量先划分为四大类:双向tcp流、单向tcp流、双向udp流和单向udp流。针对tcp协议和udp协议分别设计了相应的流量分类模型,每一大类流量有一个对应的分类模型。
20.(2.2)fi表示第i个流量特征向量,对于每个特征向量fi=(x1,x2,
…
,xm),分类模型会给出该特征向量对应的三元组key、预测的类别标签li和预测为该类别的概率值pi等。在概念漂移检测中需要用到fi中记录的三元组key以及被预测为第li类的概率值pi。
21.将流量划分为四大类,且每一大类流量有对应的分类模型,能够实现主干网流量的准确分类。此外,当检测到网络流概念漂移时,需要更新各类流量对应的分类模型,从而保持主干网流量分类的整体准确性。
22.进一步,步骤(3)中判断数据集中的流量是否发生概念漂移的方法如下:
23.(3.1)首先需要检测特征样本是否为漂移样本。假设lowthred为类别预测概率值pi的判断阈值。步骤(2.2)给出了每个特征向量fi=(x1,x2,
…
,xm)对应的预测的类别标签li和预测为该类别的概率值pi。如果pi大于lowthred,说明这个特征向量fi与用于训练分类模型的历史特征向量相似,即该特征向量对应的样本符合历史数据的正常模式。反之,如果pi小于lowthred,说明这个特征向量对应的样本是一个漂移样本。
24.(3.2)将三元组(传输层协议,ip地址,端口)视为key,从具有相同key值的数据包中提取出一个或多个特征样本。假设keythred为一个三元组中漂移样本数量占该三元组中
总样本数量的比例的阈值,计算某三元组中漂移样本数量占该三元组总样本数量的比值为pk。如果pk≥keythred,就将该三元组判定为漂移三元组,否则将该三元组视作正常三元组。
25.(3.3)假设updatethred为用于判断是否需要触发分类模型更新流程的阈值,计算所有漂移三元组中的样本数量占全部流量样本总数的比值pu。如果pu≥updatethred,说明主干网流量中漂移样本较多,数据集中的流量发生概念漂移。
26.理论上同一个三元组对应的多个特征样本要么都是正常样本,要么都是漂移样本。但在实际的分类预测阶段,分类模型依次对每一条特征样本进行类别的预测,可能会导致同一个三元组对应的多个特征样本中的一部分特征样本被判定为漂移样本,而另一部分特征样本被判定为正常样本。因此,先根据三元组中漂移样本的占比来判定一个三元组是否为漂移三元组,随后将漂移三元组中的全部特征样本记作漂移样本,能够更客观地统计漂移样本个数。
27.进一步,步骤(4)中,更新聚类样本的方法如下:
28.(4.1)以漂移样本和保存在本地的已聚类历史样本作为输入,使用批量更新器完成对所有输入数据的批量聚类,输出更新后的聚类样本。
29.进一步,步骤(5)中,更新分类模型的方法如下:
30.(5.1)使用有监督机器学习算法训练更新后聚类结果中已标记的流量特征,从而构建一个新的分类模型。
31.进一步,步骤(6)中,对后续到达的主干网流量进行分类的方法如下:
32.(6.1)使用步骤(5)中更新后的分类模型对后续到达的主干网流量进行分类。
33.与现有技术相比,本发明的技术方案具有以下有益技术效果。
34.(1)本发明面向实时主干网流量分类模型更新,并考虑了大部分流量分类工作忽视的概念漂移问题,在显式地检测到概念漂移后,以批量的方式更新包含历史流量样本和漂移流量样本的聚类结果,在保障分类模型分类性能的同时,也提升了分类模型的更新效率,有效地缓解了网络流概念漂移问题。
35.(2)本发明在进行聚类样本更新时,不仅考虑了漂移样本,还对历史聚类样本进行了迭代,因此不会出现历史数据信息的遗忘,缓解了灾难性遗忘问题。
36.(3)本发明对主干网流量数据集进行分类、概念漂移检测以及分类模型批量更新的总时间小于主干网流量数据集的采集时间,分类模型在更新前后都保持较高的准确度且更新时间只有一次性更新的一半左右,能够准确检测并及时解决网络流概念漂移问题。
附图说明
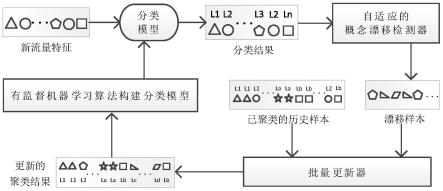
37.图1为基于批量更新的网络流概念漂移解决方法的总体架构图;
38.图2为概念漂移检测的流程图;
39.图3为分类模型批量更新的流程图;
40.图4为批量更新方法与一次性更新方法的分类模型micro f1分数对比图;
41.图5为批量更新方法与一次性更新方法的聚类结果更新时间对比图;
42.图6为批量更新方法与一次性更新方法的分类模型再训练时间对比图。
具体实施方式
43.以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
44.具体实施例:本发明提供的基于批量更新的网络流概念漂移解决方法,可在主干网场景中实现对网络流概念漂移的检测与分类模型更新,其总体架构如图1所示,包括以下步骤:
45.步骤(1)构建流经主干网的包含漂移样本的流量数据集;
46.步骤(2)以步骤(1)构建的流量数据集作为输入,使用流量分类模型对新到达的流量特征进行预测和分类;
47.步骤(3)基于步骤(2)的分类结果,使用概念漂移检测器判断数据集中的流量是否发生概念漂移;
48.步骤(4)若数据集中的流量发生概念漂移,使用批量更新器对漂移样本和保存在本地的已聚类历史样本进行批量更新,获得更新后的聚类样本;
49.步骤(5)基于步骤(4)更新后的聚类样本中已标记的流量特征,使用有监督的机器学习算法构建新的分类模型;
50.步骤(6)使用步骤(5)中更新后的分类模型对后续到达的主干网流量进行分类。
51.本发明的一个实施例中,步骤(1)中,构建流经主干网的包含漂移样本的流量数据集具体包括如下过程:
52.(1.1)本案例使用两台主机搭建ddos流量的采集环境,两台主机中的一台作为攻击的发起方,另一台作为被攻击方。使用hping3工具构建ddos flood攻击,共采集了包含141,059,271个数据包的ddos流量数据,用于构建真实主干网中的漂移样本;
53.(1.2)使用10gbps链路上收集的453,043,378个数据包,将所有数据包按照时间顺序从中取出1/3作为测试集dtest,共包含153,043,379个数据包;
54.(1.3)混合ddos流量和在10gbps链路上收集的流量,用于构建流经主干网的包含漂移样本的流量数据集。
55.(1.3.1)本案例首先计算dtest中流量的持续时间t0,也就是dtest中最后一个数据包的时间减去dtest中第一个数据包的时间。同样地,计算得ddos流量数据集的流量持续时间为td。如果t0》td,就在(0,t
0-td)数值区间内产生一个随机初始值t
init
。反之,在(0,σ*t0)数值区间中构建一个随机值作为初始值t
init
。本案例中,σ被设置为0.05。在确定时间的初始值t
init
后,ddos流量数据集中每个数据包的时间与初始时间t
init
之间的差值被视作该数据包的新时间。
56.(1.3.2)根据更新后的时间,将ddos流量按时间顺序混入dtest,本案例将ddos流量和测试集dtest的混合数据集称为dataset2,dataset2共包含294,102,650个数据包。
57.本发明的一个实施例中,步骤(2)中,对新到达流量进行预测和分类的过程如下:
58.(2.1)由于tcp协议和udp协议的消息格式不同,可将流量先划分为四大类:双向tcp流、单向tcp流、双向udp流和单向udp流。针对tcp协议和udp协议分别设计了相应的流量分类模型,每一大类流量有一个对应的分类模型。
59.(2.2)fi表示第i个流量特征向量,对于每个特征向量fi=(x1,x2,
…
,xm),分类模型会给出该特征向量对应的三元组key、预测的类别标签li和预测为该类别的概率值pi等。在
概念漂移检测中需要用到fi中记录的三元组key以及被预测为第li类的概率值pi。
60.本发明的一个实施例中,步骤(3)中,判断数据集中的流量是否发生概念漂移的过程如下:
61.(3.1)如图2,首先需要检测特征样本是否为漂移样本。本案例中lowthred设为0.6。步骤(2.2)给出了每个特征向量fi=(x1,x2,
…
,xm)对应的预测的类别标签li和预测为该类别的概率值pi。如果pi大于0.6,说明这个特征向量fi与用于训练分类模型的历史特征向量相似,即该特征向量对应的样本符合历史数据的正常模式。反之,如果pi小于0.6,说明这个特征向量对应的样本是一个漂移样本。
62.(3.2)本案例将keythred设为0.9,计算某三元组中漂移样本数量占该三元组总样本数量的比值pk,如果pk≥0.9,就将该三元组判定为漂移三元组,否则将该三元组视作正常三元组。
63.(3.3)本案例将updatethred设为0.3,计算所有漂移三元组中的样本数量占全部流量样本总数的比值pu,如果pu≥0.3,说明主干网流量中漂移样本较多,数据集中的流量发生概念漂移。
64.本发明的一个实施例中,步骤(4)中,更新聚类样本的过程如下:
65.(4.1)如图3,本案例综合考虑漂移样本和保存在本地的已聚类历史样本,以包含ddos流量的测试集(漂移样本)和训练集(保存在本地的已聚类历史样本)作为输入,使用批量更新器完成对所有输入数据的批量聚类,输出更新后的聚类样本。
66.本发明的一个实施例中,步骤(5)中,更新分类模型的过程如下:
67.(5.1)如图3,本案例使用随机森林算法训练更新后聚类结果中已标记的流量特征,从而构建一个新的分类模型。
68.本发明的一个实施例中,步骤(6)中,使用更新后的分类模型对后续到达的主干网流量进行分类的方法如下:
69.(6.1)使用步骤(5)中更新后的分类模型对后续到达的主干网流量进行分类。
70.(6.1.1)本案例将该模型部署在xeon(r)gold 5218 cpu@2.30ghzx64以及nvidia公司的tu102上,使用的操作系统版本为ubuntu 20.04.1 lts,内存容量为25.4gb。本案例用随机森林算法来训练更新后的聚类结果,以获得新的流量分类模型。
71.(6.1.2)概念漂移检测性能。本案例定义漂移样本的判定准确度(the accuracy in judging drifted samples,ads)并将其作为概念漂移检测的性能评价指标。ads的计算方法如公式1所示,其中n
ddos
表示被检测样本中实际混入的ddos特征样本的数量,n
drift
表示被判定为漂移的三元组中包含的样本数量。
[0072][0073]
概念漂移的检测结果如表1所示:从各类待检测流量组成的整体来看,由于检测得的漂移样本数(44294)超过了检测样本总数(122421)的0.3(updatethred的值),所以此次概念漂移检测将自适应地触发分类模型的更新流程。但此次更新流程只会更新双向tcp流和单向udp流所对应的分类模型,这是因为双向tcp流和单向udp流中检测得的漂移样本数达到了检测样本总数的0.3,而单向tcp流和双向udp流中检测得的漂移样本数较少,没有达到检测样本总数的0.3。此外,流量整体的漂移样本的判定准确度ads达到了99.3%,表明检
测到的漂移样本和实际混入测试集dataset2的ddos流量样本基本是一致的,能够准确检测网络流概念漂移。
[0074]
表1概念漂移的检测结果(*表示该类流量数据中没有混入的ddos流量)
[0075][0076]
(6.1.3)批量更新性能。本案例使用聚类结果的更新时间(the update time of the clustering results,utcr)、分类模型的再训练时间(the retraining time of the classification model,rtcm)和分类模型的micro f1分数(the micro f1 score of the classification model,mfcm)作为分类模型批量更新的性能评价指标。utcr表示从漂移样本和历史聚类样本被输入批量更新器,到批量更新器输出新的聚类结果所经过的时间。rtcm表示使用有监督机器学习算法对新的聚类结果中已标记的特征数据进行训练,得到新的分类模型所需要的时间。micro f1分数通过对所有样本实例的精确率和召回率进行平均获得。分类模型批量更新的性能如表2所示,只需104.1秒就可以完成所有流量数据的批量聚类,只需要55.7秒就可以根据更新后聚类样本训练得一个新的分类模型。总的来说,经过159.8秒就可以完成分类模型的批量更新,更新后的分类模型的平均准确率为96%,这证实了本发明提出的方法在实际网络环境下具有可用性和有效性,能够及时解决网络流概念漂移问题。
[0077]
表2分类模型批量更新的性能
[0078][0079]
此外,本文将批量更新方法与一次性更新方法进行了对比。一次性更新方法是指一次性地训练所有的历史数据和新到达漂移数据以获得新分类模型的一种模型更新方法。两种分类模型更新方法的比较指标为utcr、rtcm和mfcm。本案例中批量更新方法完成模型更新所需的总时间为所有流量数据的utcr和rtcm的总和。如图3所示,两种更新方法得到的分类模型的准确性是相似的。如图4、5所示,本文批量更新方法完成模型更新所需的总时间仅为一次性更新方法的52.5%。这是因为与一次性更新历史数据和漂移数据相比,本文批量更新器基于以空间换时间的思想,将已标记的历史聚类结果保存在本地,省略了相应历史数据的第一次聚类,所以批量更新方法比一次性更新方法节省了不少时间。此外,由于批
量更新器不仅考虑了漂移样本,还对已聚类的历史样本进行了迭代更新,因此不会遗忘历史数据所包含的信息,从而缓解了一次性更新遇到的灾难性遗忘问题。
[0080]
(6.1.4)实时性能。本案例对dataset2进行三次特征提取。而每个特征提取的平均时间为184.6秒。分类模型被用于预测dataset2中的流量特征,然后进行概念漂移检测,整个过程共耗时145.4秒。如表2所示,dataset2的批量更新需要159.8秒。从流量特征提取到完成更新模型总共需要489.8秒,这比数据采集时间593.079秒要短。事实上,概念漂移并不持久,没有必要持续更新分类模型。当不触发模型更新时,只需要330秒,这比数据捕获时间要短。本案例使用公开的10g主干网数据集进行测试,因此可以认为该方法能够在10g主干网上进行实时分类。此外,特征提取和模型预测可以并行进行,表明本发明所提出的方法可以实现主干网流量的实时识别与分类模型及时更新,有效缓解了网络流概念漂移问题。
[0081]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。