一种轻量型网络的2d人体姿态估计方法
技术领域
1.本发明涉及一种2d人体姿态估计方法,尤其是涉及一种轻量型网络的2d人体姿态估计方法。
背景技术:
2.2d人体姿态估计(human pose estimation,hpe)是计算机视觉领域中十分基础的一项任务,目的为检测二维图像中人的头、肩、手腕和膝盖等各个关节点位置信息,是很多其他视觉任务的辅助和铺垫性工作,当前已经在智能视频监控、人机交互、自动驾驶以及智能医疗等领域有着重要且广泛的应用。然而,由于人体关节点小,姿态多变,并且通常受到复杂背景和表观特征差异的影响,如人的衣着、身形、人体动作导致的自遮挡和遮挡等因素,使得准确估计人体关节点的位置成为一项具有挑战的任务。
3.近几年,深度学习方法在图像识别领域获得了极大成功,基于深度网络的方法已广泛应用于2d人体姿态估计中。深度卷积神经网络模型是当前2d人体姿态估计方法中最常用的一种深度网络。目前,基于深度卷积神经网络模型的2d人体姿态估计方法主要有两种:第一种方法是文献1(b.xiao,h.wu,y.wei.simple baselines for human pose estimation and tracking[c]//eccv.2018:472-487.)中公开的基于resnet主干网络的simplebaseline方法,该方法利用多分辨率图像进行监督,使得深度卷积神经网络模型能够看到不同分辨率图像下的信息。第二种方法是文献2(k.sun,b.xiao,d.liu,j.wang.deep high-resolution representation learning for human pose estimation[c]//cvpr.2019:5693-5703.)中公开的利用高分率保持多分辨率并行的深度卷积网络hrnet的方法,该方法通过多分辨率并行子网架构一直保持高分辨率图像信息的学习,加上重复多尺度特征融合,进一步精确了关节点的定位。
[0004]
但是,上述两种基于深度卷积神经网络模型的2d人体姿态估计方法均存在以下问题:一、两种深度卷积神经网络模型存在参数量大、计算速度慢和推理速度慢的问题,由此导致人体姿态估计速度慢;二、人体关节点在图像中占比小,属于小目标,对图像局部信息学习有需求,但是两种深度卷积神经网络模型均不具备高级局部信息学习的能力,由此导致人体姿态估计准确度不高。
技术实现要素:
[0005]
本发明所要解决的技术问题是提供一种人体姿态估计速度快,且准确度高的轻量型的2d人体姿态估计方法。
[0006]
本发明解决上述技术问题所采用的技术方案为:1.一种轻量型的2d人体姿态估计方法,其特征在于包括以下步骤:
[0007]
步骤1:从官方网站https://cocodataset.org/#keypoints-2019获取一个2d人体姿态估计任务的公共数据集ms coco,该公共数据集ms coco包含自然场景下的n张人的图像以及每张人的图像中人体的17个关节点的坐标,每张人的图像均为三通道彩色图像,其
中,n=175000,17个关节点包括左眼、右眼、鼻子、左耳、右耳、左肩、右肩、左手肘、右手肘、左手腕、右手腕、左胯、右胯、左膝盖、右膝盖、左脚踝和右脚踝,各个关节点的坐标基于其所处的人的图像的坐标系确定,坐标系由横坐标和纵坐标构成,每张人的图像的坐标系以该人的图像的左上角顶点为坐标原点,从坐标原点水平向右方向(即该人的图像的左上角顶点和右上角顶点的连线方向)为横坐标正轴方向,从坐标原点垂直向下方向(即人的图像左上角顶点和左下角顶点的连线方向)为纵坐标正轴方向;将公共数据集ms coco中的175000张人的图像随机划分为训练集、验证集和测试集三类,其中训练集有150000张人的图像,验证集有5000张人的图像,测试集有20000张人的图像;
[0008]
步骤2:从训练集和验证集中获取所有人的图像,然后分别制作每张人的图像对应的17张关节点热图,其中每张人的图像对应的第k张关节点热图的制作方法为:设计一张尺寸大小等于该张人的图像的空白图像,该张人的图像中每个像素点与该空白图像中相同位置处的像素点相对应,然后将该张人的图像中第k个关节点的坐标定义为中心坐标,将该中心坐标的横坐标记为纵坐标记为在与中心坐标处像素点对应的空白图像中的像素点处标注数值1,1表示是该张人的图像中第k个关节点的正确位置,接着以中心坐标为圆心,σ=3cm为半径在该张人的图像上确定一个圆形区域,分别利用二维高斯函数计算圆形区域中除中心坐标处像素点以外的其余每个像素点处的数值,将得到的每个像素点处的数值标注在空白图像中对应的像素点处,其中,e表示自然对数的底,mk表示圆形区域内除中心坐标处像素点以外的其余某个像素点的横坐标,nk表示圆形区域内除中心坐标处像素点以外的其余某个像素点的纵坐标,圆形区域内除中心坐标的像素点数值外,其余像素点的数值分别大于0且小于1,其数值表示与第k个关节点的正确位置相近,但不是第k个关节点的正确位置,最后,将空白图像中其余未标注的所有像素点处标记数值0,0表示不是第k个关节点的正确位置,空白图像中所有像素点对应标记完成后,即为该张人的图像对应的第k张关节点热图;
[0009]
对训练集和验证集中所有人的图像即这些人的图像对应的17张关节点热图分别进行拉伸,使其长均为256厘米,宽均为192厘米,即训练集和验证集中所有人的图像以及所有关节点热图的尺寸均为256
×
192,每张人的图像对应的17张关节点热图即为其对应的17个标签;
[0010]
步骤3:对现有的hrnet模型进行如下改进,得到ldnet模型:
[0011]
一、将hrne模型的第1个阶段的卷积块替换为shufflenetv2中的轻量特征提取头;
[0012]
二、将hrne模型的第3个阶段和第4个阶段的卷积均替换为轻量动态卷积模块,所述的轻量动态卷积模块包含池化层和全连接层,所述的轻量动态卷积模块将输入其内的大小为64
×
48
×
32的特征图,先通过一个池化层进行通道维度的平均池化,得到大小的1
×1×
32的向量,接着将该向量通过一个输入大小为32,输出大小为4的全连接层进行处理,得到大小的1
×1×
4的向量,将该大小为1
×1×
4的向量分别与随机初始化生成的4个大小为3
×3×
32的卷积核进行相乘,得到四个相乘结果,再将四个相乘结果进行相加,得到大小为3
×3×
32的卷积核参数,然后,将得到的大小为3
×3×
32的卷积核参数对输入所述的轻量动态卷积模块内的大小为64
×
48
×
32的特征图进行深度可分离卷积操作,生成大小为64
×
48
×
32的特征图输出;
[0013]
三、在hrne模型的第4个阶段的末尾增加一个动态空间关节点优化模块;所述的动态空间关节点优化模块包含3
×
3卷积层以及3个分支,分别称为第一分支、第二分支、第三分支;所述的动态空间关节点优化模块用于接收所述的ldnet模型的第4个阶段输出的大小为64
×
48
×
17的特征图,并将该特征图先通过一个3
×
3卷积层进行卷积处理,得到的大小为64
×
48
×
17的特征图,然后将得到的大小为64
×
48
×
17的特征图分别输出至三条分支处,将三条支路分别称为第一分支、第二分支和第三分支,其中所述的第一分支对输出至其处的大小为64
×
48
×
17的特征图不做任何操作,直接将该大小为64
×
48
×
17的特征图作为其输出特征图进行输出,输出,所述的第二分支先通过1
×
1卷积层对输出至其处的大小为64
×
48
×
17的特征图进行卷积处理,得到大小为64
×
48
×
17的特征图,然后采用sigmoid激活层对1
×
1卷积层输出的大小为64
×
48
×
17的特征图进行处理,得到大小为64
×
48
×
17的特征图作为第二分支的输出特征图进行输出,所述的第三分支先通过1
×
1卷积层对输出至其处的大小为64
×
48
×
17的特征图进行卷积处理,得到大小为64
×
48
×
1的特征图,再将此时得到的大小为64
×
48
×
1的特征图通过9
×
9的轻量动态卷积模块进行处理,得到大小为64
×
48
×
1的特征图,然后采用sigmoid激活层对9
×
9的轻量动态卷积模块得到的大小为64
×
48
×
1的特征图进行处理,得到大小为64
×
48
×
1的特征图作为第三分支的输出特征图进行输出,最后,先将所述的第二分支的输出特征图与所述的第三分支的输出特征图进行元素级相乘,得到大小为64
×
48
×
17的相乘特征图,再将大小为64
×
48
×
17的相乘特征图与所述的第一分支的输出特征图进行元素级相加,得到大小为64
×
48
×
17的特征图作为所述的动态空间关节点优化模块的输出特征图输出;
[0014]
此时得到的ldnet模型包括第1个阶段、第2个阶段、第3个阶段、第4个阶段以及动态空间关节点优化模块,所述的ldnet模型的第1个阶段用于输入大小为256
×
192
×
3的图像,并对该图像进行处理,生成大小为64
×
48
×
32的特征图输出至所述的ldnet模型的第2个阶段,所述的ldnet模型的第2个阶段用于输入所述的ldnet模型的第1个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至所述的ldnet模型的第3个阶段,所述的ldnet模型的第3个阶段用于输入所述的ldnet模型的第2个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至所述的ldnet模型的第4个阶段,所述的ldnet模型的第4个阶段用于输入所述的ldnet模型的第3个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至所述的动态空间关节点优化模块,所述的动态空间关节点优化模块用于接入所述的ldnet模型的第4个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行处理,生成大小为64
×
48
×
17的特征图输出,该大小为64
×
48
×
17的特征图包含17张大小为64
×
48的特征图,这17张大小为64
×
48的特征图即为所述的ldnet模型的第1个阶段输入的大小为256
×
192
×
3的图像对应的17张预测关节点热图;
[0015]
步骤4:对所述的ldnet模型进行训练,具体过程为:
[0016]
(1)对所述的ldnet模型采用he_normal参数初始化方法进行初始化;
[0017]
(2)将训练集中的人的图像随机分成多个batch,使每个batch中包含batchsize张人的图像,若训练集中的人的图像总数能被batchsize整除,则分成人的图像总数/batchsize个batch,若训练集中的人的图像总数不能被batchsize整除,则将剩余部分舍
去,得到|人的图像总数/batchsize︱个batch,其中batchsize=32,︱︱为取整符号;
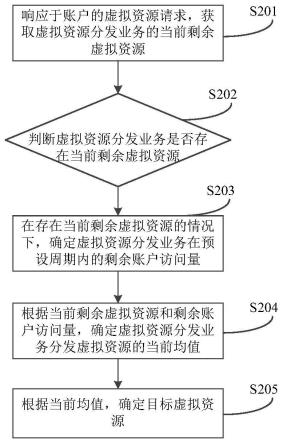
[0018]
(3)选取其中一个未被选取过的batch,对这个batch中所有人的图像均采用随机旋转进行数据增强处理,其中旋转度数范围为大于0
°
且小于等于45
°
;
[0019]
(4)将步骤(3)得到的所有人的图像作为所述的ldnet模型的输入,输入到所述的ldnet模型中,依次通过所述的ldnet模型的第1个阶段、第2个阶段、第3个阶段、第4个阶段和动态空间关节点优化模块进行识别处理,所述的ldnet模型得到该batch中每张人的图像对应的17张预测关节点热图输出;
[0020]
(5)对所选取batch中每张人的图像,分别根据其对应的17张预测关节点热图和其对应的17个标签,计算每张人的图像的人体姿态估计损失值,并计算得到所选取batch中所有人的图像的人体姿态估计损失值平均值作为最终损失值,其中,每张人的图像的人体姿态估计损失值计算如下所示:
[0021][0022]
其中,m=256
×
192
×
17,gheatj表示所取batch中一张人的图像对应的第j个关节点热图,heatj表示该张人的图像对应的第j个预测关节点热图,其中j=1,2,3,
…
,17;
[0023]
(6)根据步骤(5)中计算得到的所取batch中所有人的图像的人体姿态估计损失值,使用学习率为1e-3的adam优化器对所述的ldnet模型的参数进行训练,完成所选取batch对所述的ldnet模型的训练;
[0024]
(7)重复步骤(3)-(6),直至所有的batch都对所述的ldnet进行一次训练,然后将验证集中所有人的图像输入到此时训练后的ldnet模型中,并采用步骤(5)相同的方法得到验证集中每张人的图像的人体姿态估计损失值,计算并得到验证集中所有人的图像的人体姿态估计损失值平均值;
[0025]
(8)重复步骤(2)-(7)共num次,直至所述的ldnet模型在验证集上的损失收敛,最终得到训练好的ldnet模型,其中num≥210;
[0026]
步骤5:将需要人体姿态估计的人的图像进行拉伸,使其长为256厘米,宽为192厘米,然后将拉伸后的人的图像输入到训练好的ldnet模型中,训练好的ldnet模型生成17张预测关节点热图输出,该17张预测关节点热图即为人体姿态估计结果。
[0027]
与现有技术相比,本发明的优点在于通过对现有的hrne模型进行改进,将hrne模型的第1个阶段的卷积块替换为shufflenetv2中的轻量特征提取头,将hrne模型的第3个阶段和第4个阶段的卷积均替换为轻量动态卷积模块,在hrne模型的第4个阶段的末尾增加一个动态空间关节点优化模块,从而得到ldnet模型,得到的ldnet模型包括第1个阶段、第2个阶段、第3个阶段、第4个阶段以及动态空间关节点优化模块,ldnet模型的第1个阶段用于输入大小为256
×
192
×
3的图像,并对该图像进行处理,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第2个阶段,ldnet模型的第2个阶段用于输入ldnet模型的第1个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第3个阶段,ldnet模型的第3个阶段用于输入ldnet模型的第2个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第4个阶段,ldnet模型的第4个阶段用于输入ldnet模型的第3
个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至动态空间关节点优化模块,动态空间关节点优化模块用于接入ldnet模型的第4个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行处理,生成大小为64
×
48
×
17的特征图输出,该大小为64
×
48
×
17的特征图包含17张大小为64
×
48的特征图,这17张大小为64
×
48的特征图即为ldnet模型的第1个阶段输入的大小为256
×
192
×
3的图像对应的17张预测关节点热图,ldnet模型中,轻量动态卷积模块可以根据输入的特征来调整卷积的参数,一定程度上可以解决人体姿态多变的问题,另外,轻量动态卷积模块相比于普通的卷积,一定程度上减少了参数量和计算量,动态空间关节点优化模块后输出的预测关节点热图融合了精细化的图像空间信息和具有判别力的高级语义特征,增强卷积神经元的特征表达能力,ldnet模型相对于现有的hrne模型,不但减少了参数量和计算量,实现了更高效的新主干网络模型,而且识别能力得到较大的提升,由此,本发明采用ldnet模型进行人体姿态估计速度快,且准确度高。
附图说明
[0028]
图1为本发明的轻量型的2d人体姿态估计方法在coco数据集上的部分可视化预测结果。
具体实施方式
[0029]
以下结合附图实施例对本发明作进一步详细描述。
[0030]
实施例:一种轻量型的2d人体姿态估计方法,包括以下步骤:
[0031]
步骤1:从官方网站https://cocodataset.org/#keypoints-2019获取一个2d人体姿态估计任务的公共数据集ms coco,该公共数据集ms coco包含自然场景下的n张人的图像以及每张人的图像中人体的17个关节点的坐标,每张人的图像均为三通道彩色图像,其中,n=175000,17个关节点包括左眼、右眼、鼻子、左耳、右耳、左肩、右肩、左手肘、右手肘、左手腕、右手腕、左胯、右胯、左膝盖、右膝盖、左脚踝和右脚踝,各个关节点的坐标基于其所处的人的图像的坐标系确定,坐标系由横坐标和纵坐标构成,每张人的图像的坐标系以该人的图像的左上角顶点为坐标原点,从坐标原点水平向右方向(即该人的图像的左上角顶点和右上角顶点的连线方向)为横坐标正轴方向,从坐标原点垂直向下方向(即人的图像左上角顶点和左下角顶点的连线方向)为纵坐标正轴方向;将公共数据集ms coco中的175000张人的图像随机划分为训练集、验证集和测试集三类,其中训练集有150000张人的图像,验证集有5000张人的图像,测试集有20000张人的图像;
[0032]
步骤2:从训练集和验证集中获取所有人的图像,然后分别制作每张人的图像对应的17张关节点热图,其中每张人的图像对应的第k张关节点热图的制作方法为:设计一张尺寸大小等于该张人的图像的空白图像,该张人的图像中每个像素点与该空白图像中相同位置处的像素点相对应,然后将该张人的图像中第k个关节点的坐标定义为中心坐标,将该中心坐标的横坐标记为纵坐标记为在与中心坐标处像素点对应的空白图像中的像素点处标注数值1,1表示是该张人的图像中第k个关节点的正确位置,接着以中心坐标为圆心,σ=3cm为半径在该张人的图像上确定一个圆形区域,分别利用二维
高斯函数计算圆形区域中除中心坐标处像素点以外的其余每个像素点处的数值,将得到的每个像素点处的数值标注在空白图像中对应的像素点处,其中,e表示自然对数的底,mk表示圆形区域内除中心坐标处像素点以外的其余某个像素点的横坐标,nk表示圆形区域内除中心坐标处像素点以外的其余某个像素点的纵坐标,圆形区域内除中心坐标的像素点数值外,其余像素点的数值分别大于0且小于1,其数值表示与第k个关节点的正确位置相近,但不是第k个关节点的正确位置,最后,将空白图像中其余未标注的所有像素点处标记数值0,0表示不是第k个关节点的正确位置,空白图像中所有像素点对应标记完成后,即为该张人的图像对应的第k张关节点热图;
[0033]
对训练集和验证集中所有人的图像即这些人的图像对应的17张关节点热图分别进行拉伸,使其长均为256厘米,宽均为192厘米,即训练集和验证集中所有人的图像以及所有关节点热图的尺寸均为256
×
192,每张人的图像对应的17张关节点热图即为其对应的17个标签;
[0034]
步骤3:对现有的hrnet模型进行如下改进,得到ldnet模型:
[0035]
一、将hrne模型的第1个阶段的卷积块替换为shufflenetv2中的轻量特征提取头;
[0036]
二、将hrne模型的第3个阶段和第4个阶段的卷积均替换为轻量动态卷积模块,轻量动态卷积模块包含池化层和全连接层,轻量动态卷积模块将输入其内的大小为64
×
48
×
32的特征图,先通过一个池化层进行通道维度的平均池化,得到大小的1
×1×
32的向量,接着将该向量通过一个输入大小为32,输出大小为4的全连接层进行处理,得到大小的1
×1×
4的向量,将该大小为1
×1×
4的向量分别与随机初始化生成的4个大小为3
×3×
32的卷积核进行相乘,得到四个相乘结果,再将四个相乘结果进行相加,得到大小为3
×3×
32的卷积核参数,然后,将得到的大小为3
×3×
32的卷积核参数对输入轻量动态卷积模块内的大小为64
×
48
×
32的特征图进行深度可分离卷积操作,生成大小为64
×
48
×
32的特征图输出;
[0037]
三、在hrne模型的第4个阶段的末尾增加一个动态空间关节点优化模块;动态空间关节点优化模块包含3
×
3卷积层以及3个分支,分别称为第一分支、第二分支、第三分支;动态空间关节点优化模块用于接收ldnet模型的第4个阶段输出的大小为64
×
48
×
17的特征图,并将该特征图先通过一个3
×
3卷积层进行卷积处理,得到的大小为64
×
48
×
17的特征图,然后将得到的大小为64
×
48
×
17的特征图分别输出至三条分支处,将三条支路分别称为第一分支、第二分支和第三分支,其中第一分支对输出至其处的大小为64
×
48
×
17的特征图不做任何操作,直接将该大小为64
×
48
×
17的特征图作为其输出特征图进行输出,输出,第二分支先通过1
×
1卷积层对输出至其处的大小为64
×
48
×
17的特征图进行卷积处理,得到大小为64
×
48
×
17的特征图,然后采用sigmoid激活层对1
×
1卷积层输出的大小为64
×
48
×
17的特征图进行处理,得到大小为64
×
48
×
17的特征图作为第二分支的输出特征图进行输出,第三分支先通过1
×
1卷积层对输出至其处的大小为64
×
48
×
17的特征图进行卷积处理,得到大小为64
×
48
×
1的特征图,再将此时得到的大小为64
×
48
×
1的特征图通过9
×
9的轻量动态卷积模块进行处理,得到大小为64
×
48
×
1的特征图,然后采用sigmoid激活层对9
×
9的轻量动态卷积模块得到的大小为64
×
48
×
1的特征图进行处理,得到大小为64
×
48
×
1的特征图作为第三分支的输出特征图进行输出,最后,先将第二分支的输出特征图与第三分支的输出特征图进行元素级相乘,得到大小为64
×
48
×
17的相乘特征图,再
将大小为64
×
48
×
17的相乘特征图与第一分支的输出特征图进行元素级相加,得到大小为64
×
48
×
17的特征图作为动态空间关节点优化模块的输出特征图输出;
[0038]
此时得到的ldnet模型包括第1个阶段、第2个阶段、第3个阶段、第4个阶段以及动态空间关节点优化模块,ldnet模型的第1个阶段用于输入大小为256
×
192
×
3的图像,并对该图像进行处理,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第2个阶段,ldnet模型的第2个阶段用于输入ldnet模型的第1个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第3个阶段,ldnet模型的第3个阶段用于输入ldnet模型的第2个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至ldnet模型的第4个阶段,ldnet模型的第4个阶段用于输入ldnet模型的第3个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行特征提取,生成大小为64
×
48
×
32的特征图输出至动态空间关节点优化模块,动态空间关节点优化模块用于接入ldnet模型的第4个阶段输出的大小为64
×
48
×
32的特征图,并对该特征图进行处理,生成大小为64
×
48
×
17的特征图输出,该大小为64
×
48
×
17的特征图包含17张大小为64
×
48的特征图,这17张大小为64
×
48的特征图即为ldnet模型的第1个阶段输入的大小为256
×
192
×
3的图像对应的17张预测关节点热图;
[0039]
步骤4:对ldnet模型进行训练,具体过程为:
[0040]
(1)对ldnet模型采用he_normal参数初始化方法进行初始化;
[0041]
(2)将训练集中的人的图像随机分成多个batch,使每个batch中包含batchsize张人的图像,若训练集中的人的图像总数能被batchsize整除,则分成人的图像总数/batchsize个batch,若训练集中的人的图像总数不能被batchsize整除,则将剩余部分舍去,得到|人的图像总数/batchsize︱个batch,其中batchsize=32,︱︱为取整符号;
[0042]
(3)选取其中一个未被选取过的batch,对这个batch中所有人的图像均采用随机旋转进行数据增强处理,其中旋转度数范围为大于0
°
且小于等于45
°
;
[0043]
(4)将步骤(3)得到的所有人的图像作为ldnet模型的输入,输入到ldnet模型中,依次通过ldnet模型的第1个阶段、第2个阶段、第3个阶段、第4个阶段和动态空间关节点优化模块进行识别处理,ldnet模型得到该batch中每张人的图像对应的17张预测关节点热图输出;
[0044]
(5)对所选取batch中每张人的图像,分别根据其对应的17张预测关节点热图和其对应的17个标签,计算每张人的图像的人体姿态估计损失值,并计算得到所选取batch中所有人的图像的人体姿态估计损失值平均值作为最终损失值,其中,每张人的图像的人体姿态估计损失值计算如下所示:
[0045][0046]
其中,m=256
×
192
×
17,gheatj表示所取batch中一张人的图像对应的第j个关节点热图,heatj表示该张人的图像对应的第j个预测关节点热图,其中j=1,2,3,
…
,17;
[0047]
(6)根据步骤(5)中计算得到的所取batch中所有人的图像的人体姿态估计损失值,使用学习率为1e-3的adam优化器对ldnet模型的参数进行训练,完成所选取batch对
ldnet模型的训练;
[0048]
(7)重复步骤(3)-(6),直至所有的batch都对ldnet进行一次训练,然后将验证集中所有人的图像输入到此时训练后的ldnet模型中,并采用步骤(5)相同的方法得到验证集中每张人的图像的人体姿态估计损失值,计算并得到验证集中所有人的图像的人体姿态估计损失值平均值;
[0049]
(8)重复步骤(2)-(7)共num次,直至ldnet模型在验证集上的损失收敛,最终得到训练好的ldnet模型,其中num≥210;
[0050]
步骤5:将需要人体姿态估计的人的图像进行拉伸,使其长为256厘米,宽为192厘米,然后将拉伸后的人的图像输入到训练好的ldnet模型中,训练好的ldnet模型生成17张预测关节点热图输出,该17张预测关节点热图即为人体姿态估计结果。
[0051]
现有的hrnet模型是一个高分辨率从保持多分辨率并行的卷积神经网络,模型在垂直方向上分为不同尺度特征图并行子网学习,第一行为最高分辨率子网;在水平方向上加深网络层数,由于并行子网结构,在不同子网之间实行多尺度特征融合,并且在多尺度特征融合后产生一个新的阶段(stage)。现有的hrnet在最终实现时总共有4个阶段,即4个并行子网。现有的hrnet模型一直保持高分辨率特征图的学习以及重复的多尺度特征融合,使得其相比其他网络模型输出更精确的关节点热图,大大提高人体姿态估计的预测结果。但是,现有的hrnet模型存在参数量以及计算量大的问题。本发明通过对现有的hrne模型进行改进,将hrne模型的第1个阶段的卷积块替换为shufflenetv2中的轻量特征提取头,将hrne模型的第3个阶段和第4个阶段的卷积均替换为轻量动态卷积模块,在hrne模型的第4个阶段的末尾增加一个动态空间关节点优化模块,从而得到ldnet模型,ldnet模型中,轻量动态卷积模块可以根据输入的特征来调整卷积的参数,一定程度上可以解决人体姿态多变的问题,另外,轻量动态卷积模块相比于普通的卷积,一定程度上减少了参数量和计算量,动态空间关节点优化模块后输出的预测关节点热图融合了精细化的图像空间信息和具有判别力的高级语义特征,增强卷积神经元的特征表达能力,ldnet模型相对于现有的hrne模型,不但减少了参数量和计算量,实现了更高效的新主干网络模型,而且识别能力得到较大的提升,由此,本发明采用ldnet模型进行人体姿态估计速度快,且准确度高。
[0052]
步骤5:将需要人体姿态估计的人的图像进行拉伸,使其长为256厘米,宽为192厘米,然后将拉伸后的人的图像输入到训练好的ldnet中,生成17张预测关节点热图输出,该17张预测关节点热图即为人体姿态估计结果。
[0053]
为了验证本发明的轻量型的2d人体姿态估计方法的优异性,将采用ldnet模型的本发明的轻量型的2d人体姿态估计方法与采用现有主流的几种网络的人体姿态估计方法进行对比实验,基于本发明的测试集,使用平均准确率ap、ap
50
、ap
75
、和平均召回率ar作为评价指标,实验对比结果如表1所示:
[0054][0055]
注:加粗数字表示该列最优值。
[0056]
表1中,ipr为文献1(x.sun,b.xiao,f.wei,s.liang,and y.wei.integral human pose regression.in eccv,pages 536
–
553,2018.)中的方法,cpn为文献2(chen y,wang z,peng y,et al.cascaded pyramid network for multi-person pose estimation[c]//proceedings of the ieee conference on computer vision and pattern recognition.2018:7103-7112)中的方法,rpme为文献3(fang h s,xie s,tai y w,et al.rmpe:regional multi-person pose estimation[c]//proceedings of the ieee international conference on computer vision.2017:2334-2343.)中的方法,simplebaseline为文献4(xiao b,wu h,wei y.simple baselines for human pose estimation andtracking[c]//proceedings of the european conference on computer vision(eccv).2018:466-481.)中的方法,hrnet为文献5(sun k,xiao b,liu d,et al.deep high-resolution representation learning for human pose estimation[c].proceedings of the ieee conference on computer vision and pattern recognition.2019:5693-5703.)中的方法,shufflenetv2为文献6(ningning ma,xiangyu zhang,hai-tao zheng,and jian sun.shufflenet v2:practical guidelines for efficient cnn architecture design.in proc.european conference on computer vision(eccv),pages 116
–
131,2018.)中的方法,lite-hrnet为文献7(yu c,xiao b,gao c,et al.lite-hrnet:a lightweight high-resolution network[c]//proceedings of the ieee/cvf conference on computer vision and pattern recognition.2021:10440-10450.)中的方法,dspnet为文献8(zhong f,li m,zhang k,et al.dspnet:a low computational-cost network for human pose estimation[j].neurocomputing,2021,423:327-335.)中的方法。
[0057]
分析表1数据可知,本发明的方法在各种指标上人体姿态估计结果均优于采用现
有的主流的几种网络的人体姿态估计方法。这证明了本发明的轻量型的2d人体姿态估计方法的优越性。
[0058]
将本发明的的人体姿态估计方法在coco数据集上进行可视化实验,选取部分可视化结果如图1所示。分析图1可知:本发明的的人体姿态估计方法可以很好的检测二维图像中人的头、肩、手腕和膝盖等各个关节点位置信息。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。