用于聚糖唾液酸化的酶
1.优先权要求
2.本技术要求2020年2月25日提交的美国临时申请序列号62/981,293和2020年5月19日提交的美国临时申请序列号63/026,927的权益。上述临时申请的全部内容以引用方式并入本文。
技术领域
3.本公开涉及融合蛋白,例如包含st6gal1或b4galt1的酶活性部分的融合蛋白,以及用于产生该融合蛋白的方法、编码该融合蛋白的核酸分子、包含该核酸分子的载体和包含该载体的宿主细胞。本文还描述了使免疫球蛋白g(igg)抗体唾液酸化的方法。
背景技术:
4.由人供体的混合血浆(例如,来自至少1,000个供体的混合血浆)制备的静脉内免疫球蛋白(ivig)用于治疗各种炎性疾病。然而,ivig制剂具有不同的限制,诸如功效可变、临床风险、高成本和供给有限。不同的ivig制剂在临床上经常被当作可互换的产品,但众所周知,存在产品制剂的显著差异,这可影响在所选临床应用中的耐受性和活性。在当前的最大给药方案中,在许多情况下仅获得部分且不持续性的响应。此外,与高体积ivig治疗相关联的长输注时间(4小时至6小时)会消耗输注中心的大量资源,并且不利地影响患者报告的结果,诸如生活的便利性和质量。
5.对fc结构域唾液酸化的重要抗炎作用的鉴定已经呈现出开发更有效的免疫球蛋白疗法的机会。可商购获得的ivig制剂通常在所存在的抗体的fc结构域上表现出低水平的唾液酸化。具体地讲,它们在fc区上表现出支链聚糖的低水平二唾液酸化。
6.washburn等人(《美国国家科学院院刊》(proceedings of the national academy of sciences),usa 112:e1297-e1306(2015))描述了一种受控的唾液酸化工艺,以生成高度四-fc-唾液酸化的ivig,并且表明该工艺得到具有一致增强的抗炎活性的产物。
技术实现要素:
7.本文描述了用于制备具有非常高的fc唾液酸化水平的免疫球蛋白g(igg)的方法。本文描述的方法可以提供高唾液酸化igg(hsigg),其中fc结构域上大于70%的支链聚糖在两个分支上(即,在α1,3分支和α1,6分支上)均被唾液酸化。hsigg含有igg抗体亚型的多样性混合物,其中igg1抗体是最普遍的,接着是igg2。抗体的多样性非常高,因为原材料是从数百个或几千个供体混合的igg抗体。用于制备hsigg的igg抗体可以例如从人类混合血浆(例如,来自至少1,000至30,000个供体的混合血浆)获得。另选地,可以使用ivig,包括可商购获得的ivig来制备hsigg。hsigg在fc区上的支链聚糖上的唾液酸水平远高于ivig。这产生在结构和活性两方面不同于ivig的组合物。hsigg可如wo2014/179601或washburn等人(《美国国家科学院院刊》(proceedings of the national academy of sciences),usa 112:e1297-e1306(2015))中所述制备,两者均据此以引用方式并入。
8.本文描述了用于制备hsigg的改进方法。
9.在高唾液酸化igg中,fc区上至少60%(例如,65%、70%、75%、80%、82%、85%、87%、90%、92%、94%、95%、97%、98%至100%且包括100%)的支链聚糖通过neuac-α2,6-gal末端键进行二唾液酸化(即,在α1,3分支和α1,6臂两者上)。在一些实施方案中,fc区上少于50%(例如,少于40%、30%、20%、15%、10%、5%、4%、3%、2%、1%)的支链聚糖通过neuac-α2,6-gal末端键进行单唾液酸化(即,仅在α1,3分支上或仅在α1,6分支上唾液酸化)。
10.在一些实施方案中,多肽源自血浆,例如人血浆。在某些实施方案中,多肽绝大多数是igg多肽(例如,igg1、igg2、igg3或igg4或它们的混合物),但是可存在痕量的其它多肽,含有痕量的其它免疫球蛋白亚类。
11.如本文所用,术语“抗体”是指包括至少一个免疫球蛋白可变区,例如,提供免疫球蛋白可变结构域或免疫球蛋白可变结构域序列的氨基酸序列的多肽。例如,抗体可以包括重(h)链可变区(在本文中缩写为vh)和轻(l)链可变区(在本文中缩写为v
l
)。在另一个示例中,抗体包括两个重(h)链可变区和两个轻(l)链可变区。术语“抗体”涵盖抗体的抗原结合片段(例如,单链抗体、fab、f(ab')2、fd、fv和dab片段)以及完整抗体,例如,iga、igg、ige、igd、igm类型(以及它们的亚型)的完整免疫球蛋白。免疫球蛋白的轻链可以是κ型或λ型。
12.如本文所用,术语“恒定区”是指对应于或源自抗体的一个或多个恒定区免疫球蛋白结构域的多肽。恒定区可以包括以下免疫球蛋白结构域中的任何或所有免疫球蛋白结构域:ch1结构域、铰链区、ch2结构域、ch3结构域(源自iga、igd、igg、ige或igm)和ch4结构域(源自ige或igm)。
13.如本文所用,术语“fc区”是指两个“fc多肽”的二聚体,每个“fc多肽”包括除第一恒定区免疫球蛋白结构域之外的抗体恒定区。在一些实施方案中,“fc区”包括通过一个或多个二硫键、化学接头或肽接头连接的两个fc多肽。“fc多肽”是指iga、igd和igg的最后两个恒定区免疫球蛋白结构域,以及ige和igm的最后三个恒定区免疫球蛋白结构域,并且还可包括这些结构域的柔性铰链n-末端的部分或全部。对于igg,“fc多肽”包含免疫球蛋白结构域cgamma2(cγ2)和cgamma3(cγ3)以及cgamma1(cγ1)与cγ2之间的铰链的下部。虽然fc多肽的边界可以变化,但通常将人igg重链fc多肽定义为包含从t223或c226或p230开始至其羧基末端的残基,其中根据如kabat等人(1991,国家卫生研究院出版(nih publication)91-3242,弗吉尼亚州斯普林菲尔德国家技术信息服务中心(national technical information services,springfield,va))的eu索引进行编号。对于iga,fc多肽包含免疫球蛋白结构域calpha2(cα2)和calpha3(cα3)以及calpha1(cα1)与cα2之间的铰链的下部。fc区可以是合成的、重组的或由天然来源诸如ivig生成。
14.如本文所用,“聚糖”是糖,其可以是糖残基的单体或聚合物,诸如至少三种糖,并且可以是直链或支链的。“聚糖”可包括天然糖残基(例如,葡萄糖、n-乙酰葡糖胺、n-乙酰神经氨酸、半乳糖、甘露糖、岩藻糖、己糖、阿拉伯糖、核糖、木糖等)和/或改性糖(例如,2'-氟核糖、2'-脱氧核糖、磷酸甘露糖、6'磺基n-乙酰葡糖胺等)。术语“聚糖”包括糖残基的均聚物和杂聚物。术语“聚糖”还涵盖糖缀合物(例如多肽、糖脂、蛋白聚糖等)的聚糖组分。该术语还涵盖游离聚糖,包括已从糖缀合物裂解或以其他方式释放的聚糖。
15.如本文所用,术语“糖蛋白类”是指含有共价连接到一个或多个糖部分(即,聚糖)
的肽主链的蛋白质。糖部分可为单糖、二糖、低聚糖和/或多糖的形式。糖部分可包含糖残基的单条非支链,或者可包含一条或多条支链。糖蛋白可包含o连接的糖部分和/或n连接的糖部分。
16.如本文所用,“ivig”是从至少1,000个人供体的血浆中提取的混合的多价igg(包括所有四种igg亚组)的制剂。ivig被批准作为免疫缺陷患者的血浆蛋白替代疗法。ivig fc聚糖唾液酸化的水平在ivig制剂之间有所不同,但通常小于20%。二唾液酸化水平通常低得多。如本文所用,术语“源自ivig”是指通过操纵ivig产生的多肽。例如,从ivig纯化多肽(例如,富集唾液酸化igg或经修饰的igg(例如,酶促唾液酸化的ivig igg))。
17.如本文所用,“fc多肽的n-糖基化位点”是指聚糖与之n-连接的fc多肽内的氨基酸残基。在一些实施方案中,fc区包含fc多肽的二聚体,并且fc区包含两个n-糖基化位点,每个fc多肽上一个。
18.如本文所用,“支链聚糖的百分比(%)”是指聚糖x相对于所存在的聚糖总摩尔数的摩尔数,其中x表示感兴趣的聚糖。
19.术语“药物有效量”或“治疗有效量”是指在治疗患有本文所述的疾病或病症的患者有效的量(例如,剂量)。本文还应当理解,“药物有效量”可解释为赋予所需治疗效果的量,以单剂量或任何剂量或途径单独服用或与其他治疗剂组合服用。
[0020]“药物制剂”和“药物产品”可包括在含有该制剂或产品以及使用说明的试剂盒中。
[0021]“药物制剂”和“药物产品”通常是指其中已经实现最终预定水平的唾液酸化并且不含工艺杂质的组合物。为此,“药物制剂”和“药物产品”基本上不含st6gal唾液酸转移酶和/或唾液酸供体(例如,胞苷5'-单磷酸-n-乙酰神经氨酸)或其副产物(例如,胞苷5'-单磷酸)。
[0022]“药物制剂”和“药物产品”通常基本上不含其中产生糖蛋白的细胞的其他组分(例如内质网或细胞质蛋白和rna,如果是重组的话)。
[0023]
所谓“纯化的”(或“分离的”)是指多核苷酸或多肽从存在于其天然环境中的其他组分中去除或分离。例如,分离的多肽是与产生其的细胞的其他组分(例如,内质网或细胞质蛋白和rna)分离的多肽。分离的多核苷酸是与其他核组分(例如,组蛋白)和/或与上游或下游核酸分离的多核苷酸。分离的多核苷酸或多肽可至少60%不含、或至少75%不含、或至少90%不含、或至少95%不含所指出的多核苷酸或多肽的天然环境中存在的其他组分。
[0024]
如本文所用,术语“唾液酸化”是指具有末端唾液酸的聚糖。术语“单唾液酸化”是指例如在α1,3分支或α1,6分支上具有一个末端唾液酸的支链聚糖。术语“二唾液酸化”是指在两个臂(例如α1,3臂和α1,6臂两者)上具有末端唾液酸的支链聚糖。
[0025]
这里提供了一种融合蛋白,该融合蛋白包含:n端信号序列;和人α-2,6-唾液酸转移酶1(st6gal1)的酶活性部分。
[0026]
在一些实施方案中,st6gal1的酶活性部分包含seq id no:4。在一些实施方案中,st6gal1的酶活性部分由seq id no:4组成。
[0027]
在一些实施方案中,信号序列是n端天青杀素信号序列。在一些实施方案中,天青杀素信号序列包含mtrltvlallagllassra(seq id no:30)。在一些实施方案中,天青杀素信号序列由mtrltvlallagllassra(seq id no:30)组成。
[0028]
在一些实施方案中,融合蛋白还包含亲和标签。
[0029]
在一些实施方案中,亲和标签选自由以下组成的组:聚组氨酸、谷胱甘肽s-转移酶(gst)、麦芽糖结合蛋白(mbp)、几丁质结合蛋白、链霉亲和素标签(例如,trp-ser-his-pro-gln-phe-glu-lys(seq id no:31))、flag标签(例如,dykddddk(seq id no:32))、生物素标签以及它们的组合。
[0030]
在一些实施方案中,聚组氨酸标签选自由以下组成的组:hhhh(seq id no:11)、hhhhh(seq id no:12)、hhhhhh(seq id no:13)、hhhhhhh(seq id no:14)、hhhhhhhh(seq id no:15)、hhhhhhhhh(seq id no:16)和hhhhhhhhhh(seq id no:17)。
[0031]
在一些实施方案中,亲和标签位于朝向st6gal1的酶活性部分的n端侧的位置。
[0032]
在一些实施方案中,n端信号序列包含mtrltvlallagllassra(seq id no:30),并且st6gal1的酶活性部分包含seq id no:4。
[0033]
在一些实施方案中,融合蛋白还包含六聚组氨酸标签。在一些实施方案中,六聚组氨酸标签介于n端信号序列与st6gal1的酶活性部分之间。在一些实施方案中,融合蛋白由seq id no:6组成。
[0034]
本文还提供了编码融合蛋白的核酸分子、包含该核酸分子的载体和优选用该载体稳定转化的宿主细胞。
[0035]
在一些实施方案中,载体还包含可操作地连接到编码融合蛋白的核酸的启动子。在一些实施方案中,启动子是巨细胞病毒(cmv)启动子。
[0036]
在一些实施方案中,宿主细胞是人胚肾(hek)细胞或其衍生物。在一些实施方案中,宿主细胞是hek衍生物hek293。
[0037]
本文还提供了一种用于产生多肽的方法,该方法包括:在容许融合蛋白的表达的条件下在培养基中培养如本文所述的宿主细胞;并且从该培养基中分离该融合蛋白。
[0038]
本文还提供了一种融合蛋白,该融合蛋白包含:n端信号序列;和人β-1,4-半乳糖基转移酶(b4galt1)的酶活性部分。
[0039]
在一些实施方案中,b4galt1的酶活性部分包含seq id no:43。在一些实施方案中,b4galt1的酶活性部分由seq id no:43组成。
[0040]
在一些实施方案中,信号序列是n端天青杀素信号序列。在一些实施方案中,天青杀素信号序列包含mtrltvlallagllassra(seq id no:30)。在一些实施方案中,天青杀素信号序列由mtrltvlallagllassra(seq id no:30)组成。
[0041]
在一些实施方案中,融合蛋白还包含亲和标签。
[0042]
在一些实施方案中,亲和标签选自由以下组成的组:聚组氨酸、谷胱甘肽s-转移酶(gst)、麦芽糖结合蛋白(mbp)、几丁质结合蛋白、链霉亲和素标签(例如,trp-ser-his-pro-gln-phe-glu-lys(seq id no:31))、flag标签(例如,dykddddk(seq id no:32))、生物素标签以及它们的组合。
[0043]
在一些实施方案中,聚组氨酸标签选自由以下组成的组:hhhh(seq id no:11)、hhhhh(seq id no:12)、hhhhhh(seq id no:13)、hhhhhhh(seq id no:14)、hhhhhhhh(seq id no:15)、hhhhhhhhh(seq id no:16)和hhhhhhhhhh(seq id no:17)。
[0044]
在一些实施方案中,亲和标签位于朝向b4galt1的酶活性部分的c端侧的位置。
[0045]
在一些实施方案中,n端信号序列包含mtrltvlallagllassra(seq id no:30),并且b4galt1的酶活性部分包含seq id no:43。
[0046]
在一些实施方案中,该融合蛋白还包含七聚组氨酸标签。在一些实施方案中,该七聚组氨酸标签是c端的。
[0047]
在一些实施方案中,该融合蛋白由seq id no:45组成。
[0048]
本文还提供了编码融合蛋白的核酸分子、包含该核酸分子的载体和优选用该载体稳定转化的宿主细胞。
[0049]
在一些实施方案中,载体还包含可操作地连接到编码融合蛋白的核酸的启动子。在一些实施方案中,启动子是巨细胞病毒(cmv)启动子。
[0050]
在一些实施方案中,宿主细胞是人胚肾(hek)细胞或其衍生物。在一些实施方案中,宿主细胞是hek衍生物hek293。
[0051]
本文还提供了一种用于产生多肽的方法,该方法包括:在容许融合蛋白的表达的条件下在培养基中培养如本文所述的宿主细胞;并且从该培养基中分离该融合蛋白。
[0052]
本文还提供了一种用于使免疫球蛋白g(igg)抗体唾液酸化的方法,该方法包括:a)提供包含igg抗体的组合物;
[0053]
b)在udp-gal和cmp-nana的存在下使该组合物暴露于β1,4-半乳糖基转移酶1和包含seq id no:4的st6gal1的酶活性部分,从而产生包含唾液酸化igg(sigg)的组合物。
[0054]
本文还提供了一种用于使免疫球蛋白g(igg)抗体唾液酸化的方法,该方法包括:a)提供包含igg抗体的组合物;b)在udp-gal的存在下使该igg抗体暴露于β1,4-半乳糖基转移酶1,从而产生包含半乳糖基化igg抗体的组合物;以及c)在cmp-nana的存在下使包含半乳糖基化igg抗体的组合物暴露于包含seq id no:4的st6gal1的酶活性部分,从而产生包含唾液酸化igg(sigg)的组合物。
[0055]
在一些实施方案中,包含半乳糖基化igg抗体的组合物在步骤(c)之前未纯化。
[0056]
在一些实施方案中,该方法还包括为该组合物中的一种或多种组合物补充cmp-nana。
[0057]
在一些实施方案中,igg抗体的混合物选自由以下组成的组:igg1、igg2、igg3、igg4以及它们的组合。
[0058]
在一些实施方案中,包含sigg的组合物中抗体的fc区上至少60%的支链聚糖是二唾液酸化的。
[0059]
在一些实施方案中,包含sigg的组合物中抗体的fc区上少于50%的支链聚糖是单唾液酸化的。
[0060]
本文提供了用核酸分子稳定转化的人胚肾(hek)细胞,该核酸分子包含编码融合蛋白的核酸序列,该融合蛋白包含天青杀素信号序列和由seq id no:4组成的人st6唾液酸转移酶的一部分。
[0061]
在一些实施方案中,融合蛋白包含选自hhhhh(seq id no:12)、hhhhhh(seq id no:13)、hhhhhhh(seq id no:14)、hhhhhhhh(seq id no:15)、hhhhhhhhh(seq id no:16)、hhhhhhhhhh(seq id no:17)、hhhhhm(seq id no:18)、hhhhhhm(seq id no:19)、hhhhhhm(seq id no:20)、hhhhhhhhm(seq id no:21)、hhhhhhhhhm(seq id no:22)和hhhhhhhhhhm(seq id no:23)的序列,该序列位于天青杀素信号序列与由seq id no:4组成的人st6唾液酸转移酶的一部分之间。
[0062]
在一些实施方案中,该融合蛋白缺乏在seq id no:4氨基末端的人st6唾液酸转移
酶的一部分。
[0063]
在一些实施方案中,该融合蛋白包含seq id no:4,但缺乏在seq id no:4氨基末端的人st6唾液酸转移酶的一部分。
[0064]
在一些实施方案中,融合蛋白包含seq id no:6的氨基酸序列。在一些实施方案中,融合蛋白包含seq id no:3的氨基酸序列。
[0065]
在一些实施方案中,核酸分子包含可操作地连接到编码融合蛋白的核酸序列的启动子。在一些实施方案中,启动子是巨细胞病毒启动子。
[0066]
本文还提供了一种用于制备包含seq id no:3的多肽的方法,该方法包括在容许融合蛋白的表达的条件下在培养基中培养hek细胞并从培养基中分离包含seq id no:3的多肽。
[0067]
在一些实施方案中,该方法还包括将分离的多肽纯化至少95%w/w。
[0068]
本文还提供了一种包含seq id no:3或seq id no:6的多肽。
[0069]
除非另有定义,否则本文所用的所有技术和科学术语具有与本发明所属领域的普通技术人员通常理解的相同的含义。本文描述了用于本发明的方法和材料;也可使用本领域已知的其他合适的方法和材料。另外,材料、方法和示例仅为例示性的,而非旨在进行限制。本文提到的所有出版物、专利申请、专利、序列、数据库条目及其他参考文献均全文以引用方式并入。若有矛盾,应以本说明书及其定义为准。
[0070]
根据如下具体实施方式和附图以及权利要求书,本发明的其他特征和优点将显而易见。
附图说明
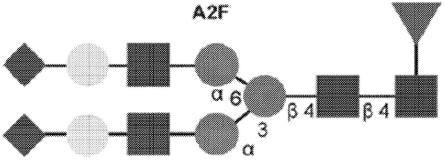
[0071]
图1示出了包含两个n-乙酰氨基葡萄糖和三个甘露糖残基的短的支链核心低聚糖。分支之一在本领域中被称为“α1,3臂”,并且第二分支被称为“α1,6臂”。正方形:n-乙酰氨基葡萄糖;深灰色圆圈:甘露糖;浅灰色圆圈:半乳糖;菱形:n-乙酰神经氨酸;三角形:岩藻糖。
[0072]
图2示出了ivig中存在的常见fc聚糖。正方形:n-乙酰氨基葡萄糖;深灰色圆圈:甘露糖;浅灰色圆圈:半乳糖;菱形:n-乙酰神经氨酸;三角形:岩藻糖。
[0073]
图3示出了免疫球蛋白(例如igg抗体)如何通过进行半乳糖基化步骤,接着进行唾液酸化步骤而被唾液酸化。正方形:n-乙酰氨基葡萄糖;深灰色圆圈:甘露糖;浅灰色圆圈:半乳糖;菱形:n-乙酰神经氨酸;三角形:岩藻糖。
[0074]
图4示出了对于以ivig开始的反应,igg-fc聚糖图谱的代表性示例的反应产物。左图是用以将igg转化为hsigg的酶促唾液酸化反应的示意图;右图是起始ivig和hsigg的igg fc聚糖图谱。从左至右的条形分别对应于igg1、igg2/3和igg3/4。
具体实施方式
[0075]
抗体在其重链恒定区中和fab内的保守位置处被糖基化。例如,在fc结构域内,人igg抗体在ch2结构域的asn297处具有单个n连接的糖基化位点。每种抗体同种型在恒定区中具有不同种类的n-连接的碳水化合物结构。对于人igg,核心低聚糖通常由具有不同数目的外部残基的glcnac2man3glcnac组成。各个igg之间的差异可经由半乳糖和/或半乳糖-唾
液酸在一个或两个末端glcnac处的连接或经由第三glcnac臂的连接(平分glcnac)而发生。
[0076]
本公开部分地涵盖用于制备具有fc区的免疫球蛋白的方法,该fc区具有特定水平的支链聚糖,支链聚糖在支链聚糖的两个臂上被唾液酸化(例如,通过neuac-α2,6-gal末端键)。水平可基于单个fc区测量(例如,在fc区中的支链聚糖的α1,3臂、α1,6臂或两者上唾液酸化的支链聚糖数目),或基于多肽制剂的总体组成测量(例如,在多肽制剂的fc区中的支链聚糖的α1,3臂、α1,6臂或两者上唾液酸化的支链聚糖的数目或百分比)。
[0077]
可以用于制备高唾液酸化igg的天然来源的多肽包括例如人血清中的igg(特别是混合自超过1,000个供体的人血清)、静脉内免疫球蛋白(ivig)和源自ivig的多肽(例如,从ivig纯化的多肽(例如,富集唾液酸化igg)或经修饰的ivig(例如,酶促唾液酸化ivig igg))。
[0078]
将n连接的低聚糖链添加到内质网的内腔中的蛋白质。具体地,将初始低聚糖(通常为14-糖)添加至asn-x-ser/thr的靶共有序列内包含的天冬酰胺残基的侧链上的氨基,其中x可以是除脯氨酸之外的任何氨基酸。该初始低聚糖的结构是大多数真核生物共有的,并且含有三个葡萄糖残基、九个甘露糖残基和两个n-乙酰葡糖胺残基。该初始低聚糖链可被内质网中的特定糖苷酶修剪,从而得到由两个n-乙酰葡糖胺残基和三个甘露糖残基构成的短支链核心低聚糖。分支之一在本领域中被称为“α1,3臂”,并且第二分支被称为“α1,6臂”,如图1所示。
[0079]
n-聚糖可细分成被称为“高甘露糖型”、“杂合型”和“复杂型”的三个不同组,其中在所有三个组中出现共同的五糖核心(man(α1,6)-(man(α1,3))-man(β1,4)-glcpnac(β1,4)-glcpnac(β1,n)-asn)。
[0080]
ivig中存在的更常见的fc聚糖示于图2中。
[0081]
除此之外或另选地,可将n-乙酰葡糖胺的一个或多个单糖单元添加至核心甘露糖亚基以形成“复杂聚糖”。可将半乳糖添加至n-乙酰葡糖胺亚基,并且可将唾液酸亚基添加至半乳糖亚基,从而得到以唾液酸、半乳糖或n-乙酰葡糖胺残基中的任一者封端的链。另外,可将岩藻糖残基添加至核心低聚糖的n-乙酰葡糖胺残基。这些添加中的每一者均由特定糖基转移酶催化。
[0082]“杂合聚糖”包含高甘露糖和复杂聚糖两者的特征。例如,杂合聚糖的一个分支可主要包含或仅包含甘露糖残基,而另一个分支可包含n-乙酰葡糖胺、唾液酸、半乳糖和/或岩藻糖。
[0083]
唾液酸是具有杂环结构的9碳单糖家族。它们经由连接到环的羧酸基团以及包括n-乙酰基和n-乙醇酰基基团在内的其他化学修饰而带有负电荷。存在于哺乳动物表达系统中产生的多肽中的两种主要类型的唾液酸残基是n-乙酰神经氨酸(neuac)和n-羟乙酰神经氨酸(neugc)。它们通常作为在n-连接的聚糖和o-连接的聚糖两者的非还原末端处附接到半乳糖(gal)残基的末端结构出现。这些唾液酸基团的糖苷键构型可为α2,3或α2,6。
[0084]
fc区在保守的n连接糖基化位点处被糖基化。例如,igg抗体的每条重链在ch2结构域的asn297处具有单个n连接糖基化位点。iga抗体在ch2和ch3结构域内具有n连接的糖基化位点,ige抗体在ch3结构域内具有n连接的糖基化位点,并且igm抗体在ch1、ch2、ch3和ch4结构域内具有n连接的糖基化位点。
[0085]
每种抗体同种型在恒定区中具有不同种类的n-连接的碳水化合物结构。例如,igg
在fc区的每个fc多肽中在ch2结构域的asn297处具有单个n连接的双触角碳水化合物,其还包含c1q和fcγr的结合位点。对于人igg,核心低聚糖通常由具有不同数目的外部残基的glcnac2man3glcnac组成。各个igg之间的差异可经由半乳糖和/或半乳糖-唾液酸在一个或两个末端glcnac处的连接或经由第三glcnac臂的连接(平分glcnac)而发生。
[0086]
免疫球蛋白(例如igg抗体)可以通过进行半乳糖基化步骤,接着进行唾液酸化步骤而被唾液酸化。β-1,4-半乳糖基转移酶1(b4galt)是ii型高尔基体膜结合糖蛋白,其将半乳糖从尿苷5'-二磷酸半乳糖([[(2r,3s,4r,5r)-5-(2,4-二氧代嘧啶-1-基)-3,4二羟基氧杂环戊烷-2-基]甲氧基-羟基磷酰基][(2r,3r,4s,5r,6r)-3,4,5-三羟基-6-(羟甲基)环氧乙烷-2-基]磷酸氢盐;udp-gal)转移到glcnac作为β-1,4键。α-2,6-唾液酸转移酶1(st6)是ii型高尔基体膜结合糖蛋白,其将唾液酸从胞苷5'-单磷酸-n乙酰神经氨酸((2r,4s,5r,6r)-5-乙酰胺基-2-[[(2r,3s,4r,5r)-5-(4-氨基-2-氧代嘧啶-1-基)-3,4-二羟基氧杂环戊烷-2-基]甲氧基-羟基磷酰基]氧基-4-羟基-6-(1,2,3-三羟基丙基)环氧乙烷-2-羧酸;cmp-nana或cmp-唾液酸)转移到gal作为α-2,6键。示意性地,反应如图3所示进行。
[0087]
多肽的聚糖可使用本领域已知的任何方法进行评估。例如,聚糖组合物的唾液酸化(例如,在α1,3分支和/或α1,6分支上唾液酸化的支链聚糖的水平)可使用wo2014/179601中所述的方法来表征。
[0088]
在通过本文所述的方法制备的hsigg组合物的一些实施方案中,fc结构域上的支链聚糖的至少60%、65%、70%、75%、80%、85%或90%在α1,3臂和α1,6臂两者上具有通过neuac-α2,6-gal末端键连接的唾液酸。另外,在一些实施方案中,fab结构域上的支链聚糖的至少40%、50%、60%、65%、70%、75%、80%或85%在α1,3臂和α1,6臂两者上具有通过neuac-α2,6-gal末端键连接的唾液酸。总的来说,在一些实施方案中,支链聚糖的至少60%、65%、70%、75%、80%、85%或90%在α1,3臂和α1,6臂两者上具有通过neuac-α2,6-gal末端键连接的唾液酸。
[0089]
酶
[0090]
β-1,4-半乳糖基转移酶(b4galt)(例如人b4galt,例如人b4galt1)及其直系同源物、突变体和变体,包括β-1,4-半乳糖基转移酶(b4galt)(例如人b4galt,例如人b4galt1)以及其直系同源物、突变体和变体的酶活性部分,以及包含它们的融合蛋白适合用于本文所述的方法。b4galt1是七种β-1,4-半乳糖基转移酶(β4galt)基因之一,每个基因编码似乎对供体底物udp-半乳糖具有排他特异性的ii型膜结合糖蛋白;将β1,4键中的半乳糖全部转移到类似的受体糖:glcnac、glc和xyl。b4galt1将半乳糖添加到为单糖或糖蛋白碳水化合物链的非还原末端的n-乙酰氨基葡萄糖残基上。b4galt1也称为ggtb2。编码b4galt1的四种同工型的四种替代转录物(ncbi基因id 2683)在表1中有所描述。
[0091]
表1.人b4galt1同工型
[0092][0093]
》np_001488.2b4galt1[生物体=智人][基因id=2683][同工型=1](seq id no:
37)
[0094]
mrlrepllsgsaampgaslqracrllvavcalhlgvtlvyylagrdlsrlpqlvgvstplqggsnsaaaigqssgelrtggarpppplgassqprpggdsspvvdsgpgpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfslpyvqyfggvsalskqqfltingfpnnywgwggedddifnrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigtps
[0095]
》np_001365424.1b4galt1[生物体=智人][基因id=2683][同工型=2](seq id no:38)
[0096]
mpgaslqracrllvavcalhlgvtlvyylagrdlsrlpqlvgvstplqggsnsaaaigqssgelrtggarpppplgassqprpggdsspvvdsgpgpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfslpyvqyfggvsalskqqfltingfpnnywgwggedddifnrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigtps
[0097]
》np_001365425.1b4galt1[生物体=智人][基因id=2683][同工型=3](seq id no:39)
[0098]
mrlrepllsgsaampgaslqracrllvavcalhlgvtlvyylagrdlsrlpqlvgvstplqggsnsaaaigqssgelrtggarpppplgassqprpggdsspvvdsgpgpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigtps
[0099]
》np_001365426.1b4galt1[生物体=智人][基因id=2683][同工型=4](seq id no:40)
[0100]
mrlrepllsgsaampgaslqracrllvavcalhlgvtlvyylagrdlsrlpqlvgvstplqggsnsaaaigqssgelrtggarpppplgassqprpggdsspvvdsgpgpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqyekirrllw
[0101]
表2.b4galt1同工型1(seq id no:37)的拓扑结构
[0102][0103]
表3.b4galt1同工型1(seq id no:1)的结合位点
[0104][0105]
表4.b4galt1同工型1(seq id no:37)的翻译后氨基酸修饰
[0106][0107][0108]
b4galt1的可溶形式通过蛋白水解加工源自膜形式。裂解位点位于b4galt1同工型1(seq id no:37)的位置77-78处。
[0109]
在一些实施方案中,对应于b4galt1同工型1(seq id no:37)的氨基酸113、130、172、243、250、262、310、343或355的b4galt1氨基酸中的一个或多个氨基酸与(seq id no:37)相比是保守的。
[0110]
本文提供了例如b4galt1的酶活性部分。在一些实施方案中,酶是b4galt1同工型1(seq id no:37),或seq id no:37的直系同源物、突变体或变体的酶活性部分。在一些实施方案中,酶是b4galt1同工型2(seq id no:38),或seq id no:38的直系同源物、突变体或变体的酶活性部分。在一些实施方案中,酶是b4galt1同工型3(seq id no:39),或seq id no:39的直系同源物、突变体或变体的酶活性部分。在一些实施方案中,酶是b4galt1同工型4(seq id no:40),或seq id no:40的直系同源物、突变体或变体的酶活性部分。
[0111]
在一些实施方案中,b4galt1的酶活性部分不包含细胞质结构域,例如seq id no:41。在一些实施方案中,b4galt1的酶活性部分不包含跨膜结构域,例如seq id no:42。在一些实施方案中,b4galt1的酶活性部分不包含细胞质结构域,例如seq id no:41,或跨膜结构域,例如seq id no:42。
[0112]
在一些实施方案中,b4galt1的酶活性部分包含内腔结构域的全部或一部分,例如seq id no:43或其直系同源物、突变体或变体。
[0113]
在一些实施方案中,b4galt1的酶活性部分包含seq id no:37的氨基酸109-398或其直系同源物、突变体或变体。在一些实施方案中,b4galt1的酶活性部分由seq id no:37或seq id no:37的直系同源物、突变体或变体组成。
[0114]
b4galt1的合适的功能部分可以包含与seq id no:43具有至少80%(85%、90%、95%、98%或100%)同一性的氨基酸序列或由该氨基酸序列组成。
[0115]
seq id no:43
[0116]
gpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphk
vaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfslpyvqyfggvsalskqqfltingfpnnywgwggedddifnrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigtps
[0117]
st6gal1(例如人st6gal1)以及其直系同源物、突变体和变体包括st6gal1(例如人st6gal1)以及其直系同源物、突变体和变体的酶活性部分,和包含它们的融合蛋白,适合用于本文所述的方法。st6gal1,β-半乳糖苷α-2,6-唾液酸转移酶1将唾液酸从cmp-唾液酸转移到糖蛋白(诸如去唾液酸胎球蛋白和脱唾液酸-a1-酸性糖蛋白)上的galβ1
→
4glcnac结构。st6gal1也称为st6n或siat1。编码st6gal1的两种同工型的四种替代转录物(ncbi基因id 6480)在表1中有所描述。
[0118]
表1.人st6gal1同工型
[0119][0120]
》np_001340845.1(np_003023.1,np_775323.1)st6gal1[生物体=智人][基因id=6480][同工型=a](seq id no:28)
[0121]
mihtnlkkkfsccvlvfllfavicvwkekkkgsyydsfklqtkefqvlkslgklamgsdsqsvsssstqdphrgrqtlgslrglakakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0122]
》np_775324.1st6gal1[生物体=智人][基因id=6480][同工型=b](seq id no:29)
[0123]
mnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0124]
表2.st6gal1同工型a(seq id no:28)的拓扑结构
[0125][0126]
表3.st6gal1同工型a(seq id no:28)的结合位点
[0127][0128][0129]
表4.st6gal1同工型a(seq id no:28)的翻译后氨基酸修饰
[0130][0131][0132]
st6gal1的可溶形式通过蛋白水解加工源自膜形式。
[0133]
在一些实施方案中,对应于st6gal1同工型a(seq id no:28)的氨基酸142、149、161、184、189、212、233、335、353、354、364、365、369、370、376或406的st6gal1氨基酸中的一个或多个氨基酸与seq id no:28相比是保守的。
[0134]
本文还提供了例如st6gal1的酶活性部分。在一些实施方案中,酶是stg6gal1同工型a(seq id no:28),或seq id no:28的直系同源物、突变体或变体的酶活性部分。在一些实施方案中,酶是stg6gal1同工型b(seq id no:29),或seq id no:29的直系同源物、突变
id no:55)或由其组成。在一些实施方案中,信号序列是天冬氨酸蛋白酶nepenthesin-1信号序列。在一些实施方案中,天冬氨酸蛋白酶nepenthesin-1信号序列包含masslysfllalsivyifvapths(seq id no:56)或由其组成。在一些实施方案中,信号序列是酸性几丁质酶信号序列。在一些实施方案中,酸性几丁质酶信号序列包含mkthyssailpiltlfvflsinpshg(seq id no:57)或由其组成。在一些实施方案中,信号序列是k28前毒素原(prepro-toxin)信号序列。在一些实施方案中,k28前毒素原信号序列包含mesvsslfnifstimvnykslvlallsvsnlkyarg(seq id no:58)或由其组成。在一些实施方案中,信号序列是杀手毒素zygocin前体信号序列。在一些实施方案中,杀手毒素zygocin前体信号序列包含mkaaqiltasivsllpiytsa(seq id no:59)或由其组成。在一些实施方案中,信号序列是霍乱毒素信号序列。在一些实施方案中,霍乱毒素信号序列包含miklkfgvfftvllssaya(seq id no:60)或由其组成。在一些实施方案中,信号序列是人生长激素信号序列。在一些实施方案中,人生长激素信号序列包含matgsrtslllafgllclpwlqegsa(seq id no:61或由其组成。
[0154]
在一些实施方案中,融合蛋白包含一个或多个亲和标签。在一些实施方案中,纯化标签选自由以下组成的组:聚组氨酸、谷胱甘肽s-转移酶(gst)、麦芽糖结合蛋白(mbp)、几丁质结合蛋白、链霉亲和素标签(例如,strep-例如trp-ser-his-pro-gln-phe-glu-lys(seq id no:31))、flag标签(例如,dykddddk(seq id no:32))、生物素标签(例如,avitag
tm
)以及它们的组合。
[0155]
在一些实施方案中,亲和标签位于朝向酶或其部分的n端侧的位置。在一些实施方案中,亲和标签是n端的。
[0156]
在一些实施方案中,亲和标签位于朝向酶或其部分的c端侧的位置。在一些实施方案中,亲和标签是c端的。
[0157]
在一些实施方案中,亲和标签是聚组氨酸标签。在一些实施方案中,聚组氨酸标签选自由以下组成的组:hhhh(seq id no:11)、hhhhh(seq id no:12)、hhhhhh(seq id no:13)、hhhhhhh(seq id no:14)、hhhhhhhh(seq id no:15)、hhhhhhhhh(seq id no:16)和hhhhhhhhhh(seq id no:17)。在一些实施方案中,聚氨酸标签是六聚组氨酸标签(例如hhhhhh(seq id no:13))。
[0158]
在一些实施方案中,融合蛋白包含以下或由以下组成:seq id no:43、seq id no:44或seq id no:45。
[0159]
seq id no:44
[0160]
gpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfslpyvqyfggvsalskqqfltingfpnnywgwggedddifnrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigtpsprd
[0161]
seq id no:45
[0162]
gssplldmgpasnltsvpvphttalslpacpeespllvgpmliefnmpvdlelvakqnpnvkmggryaprdcvsphkvaiiipfrnrqehlkywlyylhpvlqrqqldygiyvinqagdtifnrakllnvgfqealkdydytcfvfsdvdlipmndhnayrcfsqprhisvamdkfgfslpyvqyfggvsalskqqfltingfpnnywgwggedddifnrlvfrgmsisrpnavvgrcrmirhsrdkknepnpqrfdriahtketmlsdglnsltyqvldvqryplytqitvdigt
psprdhhhhhhh
[0163]
在一些实施方案中,融合蛋白包含以下或由以下组成:seq id no:3或seq id no:5。
[0164]
seq id no:3
[0165]
gssplldmlehhhhhhhhmakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0166]
seq id no:5
[0167]
hhhhhhhhmakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0168]
表达系统
[0169]
为了使用本文所述的酶和/或融合蛋白,可能期望从编码它们的核酸表达它们。这可以多种方式进行。例如,可以将编码酶和/或融合蛋白的核酸克隆到中间载体中以转化到原核或真核细胞中进行复制和/或表达。中间载体通常是原核生物载体,例如质粒或穿梭载体,或昆虫载体,用于储存或操纵编码酶和/或融合蛋白的核酸。还可以将编码酶和/或融合蛋白的核酸克隆到表达载体中以施用于植物细胞、动物细胞(优选哺乳动物细胞或人细胞)、真菌细胞、细菌细胞或原生动物细胞。
[0170]
为了获得表达,通常将编码酶和/或融合蛋白的序列亚克隆到含有指导转录的启动子的表达载体中。合适的细菌和真核启动子是本领域中众所周知的并且描述于例如sambrook等人,分子克隆(molecular cloning),《实验室手册》(a laboratory manual)(2001年第3版);kriegler,基因转移和表达:《实验室手册》(gene transfer and expression:a laboratory manual)(1990);和《分子生物学实验室指南》(current protocols in molecular biology)(ausubel等人编辑,2010)。用于表达工程化蛋白质的细菌表达系统可用于例如大肠杆菌(e.coli)、芽孢杆菌属(bacillus sp.)和沙门氏菌(salmonella)(palva等人,1983,《基因》(gene)22:229-235)。用于此类表达系统的试剂盒是可商购获得的。哺乳动物细胞、酵母和昆虫细胞的真核表达系统是本领域众所周知的并且也可商购获得。
[0171]
用于指导核酸表达的启动子取决于特定应用。例如,强组成型启动子通常用于融合蛋白的表达和纯化。
[0172]
在一些实施方案中,启动子选自由以下组成的组:人巨细胞病毒(cmv)、ef-1α(ef1a)、短延伸因子1α(efs)、cmv增强子鸡β-肌动蛋白启动子和兔β-珠蛋白剪接受体位点(cag)、杂交cba(cbh)、脾病灶形成病毒(sffv)、鼠干细胞病毒(mscv)、猿猴病毒40(sv40)、小鼠磷酸甘油酸激酶1(mpgk)、人磷酸甘油酸激酶1(hpgk)和泛素c(ubc)启动子。在一些实施方案中,该启动子是人巨细胞病毒启动子(cmv)。
[0173]
除启动子外,表达载体通常含有转录单元或表达盒,该转录单元或表达盒含有核酸在原核或真核的宿主细胞中表达所需的所有附加元件。典型的表达盒因此含有可操作地连接(例如)至编码酶和/或融合蛋白的核酸序列的启动子以及(例如)转录物有效聚腺苷酸化、转录终止、核糖体结合位点或翻译终止所需的任何信号。盒的附加元件可以包括例如增强子和异源剪接内含子信号。
[0174]
在一些实施方案中,表达载体包括土拨鼠肝炎病毒转录后调控元件(wpre)。参见,例如zufferey等人,“woodchuck hepatitis virus posttranscriptional regulatory element enhances expression of transgenes delivered by retroviral vectors,”《病毒学杂志》(journal of virology)73(4):2886
–
92(1999)。
[0175]
用于将遗传信息转运到细胞中的特定表达载体是对于酶和/或融合蛋白的预期用途,例如在植物、动物、细菌、真菌、原生动物等中表达进行选择的。
[0176]
使用标准转染方法产生表达大量蛋白质的细菌、哺乳动物、酵母或昆虫细胞系,然后使用标准技术纯化蛋白质(参见例如,colley等人,1989,《生物化学杂志》(j.biol.chem.),264:17619-22;蛋白质纯化指南(guide to protein purification),在《酶学方法》(methods in enzymology),第182卷中(deutscher编辑,1990))。根据标准技术进行真核细胞和原核细胞的转化(参见例如,morrison,1977,《细菌学杂志》(j.bacteriol.)132:349-351;clark-curtiss和curtiss,《酶学方法》(methods in enzymology)101:347-362(wu等人编辑,1983)。
[0177]
可以使用用于将外来核苷酸序列引入宿主细胞中的任何已知程序。这些包括使用磷酸钙转染、聚凝胺、原生质体融合、电穿孔、核转染、脂质体、显微注射、裸dna、质粒载体、病毒载体(附加型和整合型两者),以及用于将克隆的基因组dna、cdna、合成dna或其它外来遗传物质引入宿主细胞中的任何其它众所周知的方法(参见例如,sambrook等人,同上)。仅需要使用的特定基因工程程序能够成功地将至少一个基因引入能够表达酶和/或融合蛋白的宿主细胞中。
[0178]
在一些实施方案中,稳定地转化宿主细胞。
[0179]
在一些实施方案中,宿主细胞在非缺氧条件下生长。
[0180]
本文所述的酶和/或融合蛋白可以通过本领域已知的任何蛋白质产生系统产生,诸如基于宿主细胞的表达系统、合成生物学平台或无细胞蛋白质产生平台。在一些实施方案中,蛋白质产生系统能够进行翻译后修饰,包括但不限于糖基化(例如n-糖基化蛋白质)、二硫键形成和酪氨酸磷酸化中的一种或多种。参见例如,boh和ng,“宿主细胞系选择对聚糖图谱的影响(impact of host cell line choice on glycan profile)”,《生物技术评论》(critical reviews in biotechnology)38(6):851
–
67(2018))。
[0181]
在一些实施方案中,宿主细胞是哺乳动物宿主细胞。在一些实施方案中,哺乳动物细胞选自由以下组成的组:中国仓鼠卵巢(cho)细胞、幼仓鼠肾(bhk)细胞、ns0骨髓瘤细胞、sp2/0杂交瘤小鼠细胞、人胚肾(hek)细胞、ht-1080人细胞以及它们的衍生物。
[0182]
在一些实施方案中,宿主细胞是非人哺乳动物宿主细胞。在一些实施方案中,非人哺乳动物宿主细胞选自cho细胞、bhk-21细胞、鼠ns0骨髓瘤细胞、sp2/0杂交瘤细胞以及它们的衍生物。
[0183]
在一些实施方案中,宿主细胞是人哺乳动物宿主细胞。在一些实施方案中,人细胞
选自由以下组成的组:hek、per.c6、cevec的羊水细胞产生(cap)、age1.hm、hkb-11、ht-1080细胞以及它们的衍生物。
[0184]
在一些实施方案中,宿主细胞是人胚肾细胞(hek,crl-1573
tm
)或其衍生物。
[0185]
在一些实施方案中,hek细胞表达sv40 t抗原的温度敏感等位基因。在一些实施方案中,hek细胞在甲磺酸乙酯(ems)诱变之后对篦麻蛋白毒素有抗性,并且缺乏例如由mgat1基因编码的n-乙酰葡糖氨基转移酶i活性。在一些实施方案中,hek细胞主要用man5glcnac2 n-聚糖修饰糖蛋白。在一些实施方案中,hek细胞表达tetr阻遏子,从而实现四环素诱导蛋白表达。
[0186]
在一些实施方案中,hek衍生物选自由以下组成的组:hek293、hek293t(293tsa1609neo,crl-3216
tm
)、hek293t/17(crl-11268
tm
)、hek293t/17sf(acs-4500
tm
)、hek293s、hek293sg、hek293ftm、hek293sggd、hek293ftm、hek293e和hkb-11。
[0187]
合成生物学平台,诸如kightlinger等人,“合成糖生物学:部分、系统和应用(synthetic glycobiology:parts,systems,and applications)”,《acs合成生物学》(acs synth.biol.)9:1534
–
62(2020)中描述的那些,也适于产生本文所述的酶和/或融合蛋白。
[0188]
本文还提供了载体和包含载体的细胞,以及包含本文所述的蛋白质和核酸的试剂盒,该试剂盒例如用于本文所述的方法中。
[0189]
实施例
[0190]
在以下实施例中进一步描述本发明,实施例不限制权利要求中描述的本发明的范围。
[0191]
实施例1:高唾液酸化igg制剂
[0192]
可以如下制备其中总支链聚糖的超过60%是二唾液酸化的igg。
[0193]
简言之,使igg抗体的混合物暴露于使用β1,4半乳糖基转移酶1(b4-galt)和α2,6-唾液酸转移酶(st6-gal1)的顺序酶促反应。不需要在添加st6-gal1之前从反应中去除b4-galt,并且在酶促反应之间不需要部分或完全纯化产物。
[0194]
半乳糖基转移酶选择性地将半乳糖残基添加到预先存在的天冬酰胺连接的聚糖。所得的半乳糖基化聚糖用作唾液酸转移酶的底物,其选择性地添加唾液酸残基以封端连接到其上的天冬酰胺连接的聚糖结构。因此,总唾液酸化反应采用两种糖核苷酸(尿苷5
′‑
二磷酸半乳糖(udpgal)和胞苷-5
′‑
单磷酸-n-乙酰神经氨酸(cmp-nana))。定期补充后者以相对于单唾液酸化产物增加二唾液酸化产物。该反应包括辅因子氯化锰。
[0195]
以ivig开始的此类反应和反应产物的igg-fc聚糖图谱的代表性示例示于图4中。在图4中,左侧是用以将igg转化为hsigg的酶促唾液酸化反应的示意图;右侧是起始ivig和hsigg的igg fc聚糖图谱。在该研究中,经由糖肽质谱分析得出不同的igg亚类的聚糖图谱。用于定量不同igg亚类的糖肽的肽序列是:igg1=eeqynstyr(seq id no:7)、igg2/3eeqfnstfr(seq id no:8)、igg3/4eeqynstfr(seq id no:9)和eeqfnstyr(seq id no:10)。
[0196]
聚糖数据按igg亚类示出。来自igg3和igg4亚类的聚糖不能单独定量。如所示,对
于ivig,所有未唾液酸化聚糖的总和大于80%,并且所有唾液酸化聚糖的总和小于20%。对于反应产物,所有未唾液酸化聚糖的总和小于20%,并且所有唾液酸化聚糖的总和大于80%。糖图谱中列出的不同聚糖的命名使用n连接的聚糖的oxford符号。
[0197]
实施例2:替代性唾液酸化条件
[0198]
用于半乳糖基化和唾液酸化以在例如50mm bis-tris ph 6.9中产生hsigg的替代性合适反应条件包括:igg抗体(例如,混合的igg抗体、混合的免疫球蛋白或ivig)的半乳糖基化如下:7.4mm mncl2;38μmol udp-gal/g igg抗体;和7.5个单位的b4galt/g igg抗体,在37℃下温育16小时-24小时,接着在7.4mm mncl2中进行唾液酸化;220μmol cmp-nana/g igg抗体(添加两次:在反应开始时添加一次,在9小时-10小时之后再添加一次);和15个单位的st6-gal1/g igg抗体,在37
°
下温育30小时-33小时。可以通过将st6-gal1和cmp-nana添加到半乳糖基化反应中来进行该反应。另选地,可以在开始时将所有反应物组合并补充cmp-nana。
[0199]
实施例3:st6gal的产生
[0200]
包括st6gal的酶活性部分的融合蛋白被设计用于在hek细胞中高水平表达和容易地纯化。seq id no:6是未成熟的融合蛋白,其包括人st6gal的一部分(seq id no:4)、6his标签、来自天青杀素的信号序列(mtrltvlall agllassragssplld(seq id no:31);作为信号序列的19个氨基酸带下划线)和由克隆过程产生的氨基酸。seq id no:3是分泌形式,并且seq id no:5包括6his标签和st6galt部分。
[0201]
seq id no:6
[0202]
mtrltvlallagllassragssplldmlehhhhhhhhmakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssgslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0203]
seq id no:3
[0204]
gssplldmlehhhhhhhhmakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0205]
seq id no:4
[0206]
akpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqdvgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0207]
seq id no:5
[0208]
hhhhhhhhmakpeasfqvwnkdsssknliprlqkiwknylsmnkykvsykgpgpgikfsaealrchlrdhvnvsmvevtdfpfntsewegylpkesirtkagpwgrcavvssagslkssqlgreiddhdavlrfngaptanfqqd
vgtkttirlmnsqlvttekrflkdslynegilivwdpsvyhsdipkwyqnpdynffnnyktyrklhpnqpfyilkpqmpwelwdilqeispeeiqpnppssgmlgiiimmtlcdqvdiyeflpskrktdvcyyyqkffdsactmgayhpllyeknlvkhlnqgtdediyllgkatlpgfrtihc
[0209]
将hek293细胞(细胞;life technologies)用在cmv启动子的控制下表达具有seq id no:6的多肽的载体稳定地转染。为了产生st6galt融合蛋白,对稳定转染的和克隆选择的细胞进行计数并且在第0天以0.4e6个细胞/ml的细胞密度接种,使其在37℃、5%co2、130rpm-150rpm下生长。第4天,向细胞中添加10%葡萄糖/培养基进料。每天监测生长情况。第7天,收获细胞上清液,将其通过0.45微米过滤器无菌过滤,然后通过0.2微米过滤器无菌过滤。
[0210]
其它实施方案
[0211]
应当理解,虽然已结合本发明的具体实施方式描述了本发明,但是前述描述旨在说明而非限制由随附权利要求书所限定的本发明的范围。其他方面、优点和修改均在以下权利要求书的范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。