1.本发明涉及计算机、编译器、以及深度学习神经网络等技术领域,具体涉及一种基于精简算子集的深度学习图算一体优化器。
背景技术:
2.目前深度学习神经网络被应用在众多场景中解决问题,如图像分类、目标检测、语音识别、机器翻译、故障识别等等。深度神经网络(dnn)框架管理深度学习应用所需的大规模数据和模型,负责计算设备的调度和资源申请。深度神经网络框架将神经结构表示为一个计算图,其中每个节点称之为一个张量算子,例如,矩阵乘法、卷积等。通过优化算子可以改进深度神经网络的计算效率,提高计算图运行性能。为了提高计算图的运行时性能,最常见对深度神经网络框架的优化形式是代数优化和算子融合。代数优化是将匹配特定模式的子图替换为具有改进性能的功能等效子图。算子融合是将前后相邻的几个算子融合成一个算子,减少中间变量传递带来的耗时。现有的dnn框架是由领域专家手动设计的算子级别的模式匹配规则来进行代数优化和算子融合,也有例如tvm将算子分类然后根据算子类别进行算子融合的方法。
3.以开放神经网络交换onnx为例,深度学习的算子有接近200个,而且算子的计算方式和接口会产生变化或者算子产生不同的变种,例如卷积已经有深度卷积,分组卷积,转置卷积,逐点卷积等,同时算子的数量随着深度学习的发展也会不断增加。由此,基于算子级别的模式匹配规则也需要针对每个算子及其变种增加规则,增加了大量的工程工作,可维护性差,对于新算子和算子新的变种扩展性也比较差;同时这些手工设计的算子级别的模式匹配规则形式上比较复杂,也容易出错。最后,图优化之后一般需要再对算子进行循环优化之类的算子优化,将图优化和算子优化分开考虑可能会丧失一些协同优化的优化机会。
4.另一方面,深度学习算子虽然数量很多,但是可以从逻辑上将算子分为更小单元的组合。现有深度学习框架和深度学习编译框架中有类似将算子分为更小单元的技术,例如jittor中的元算子概念,mindspore中的图算融合技术,但是这些框架大多将拆解的更小单元进行循环融合等算子优化技术,而这种算子优化技术仍存在工程量大、可维护性差、扩展性差、易出错等问题。
技术实现要素:
5.目前,深度神经网络框架中提高计算图性能,对张量算子进行优化时存在工程量大、可维护性差、扩展性差、易出错等问题;而深度学习的算子可以从逻辑层表示为基本算子集的组合,执行层不会执行完一个子算子才去执行下一个,而是会做一定的并行化调度;由此,计算图的节点变成子算子,进行代数优化时,只需要设计基于子算子的模式匹配规则,而子算子的数量以及增长数量都是远少于算子数量的,由此带来的基于子算子的模式匹配规则也是远少于基于算子的。同时,由于子算子的数学形式要比算子简单,所以模式匹配规则也不容易出错。因此,本发明提供了一种基于精简算子集的深度学习图算一体优化
器,将这些更小的单元称为精简算子集,每一个元素称为子算子,例如包括基本运算:加法add,乘法multiply,规约运算min max sum,数据搬运类等等,通过设计子算子的模式匹配规则,利用图算一体进行图优化,从而可以直接对接到算子优化的后端,解决了现有问题。
6.本发明实现的一种基于精简算子集的深度学习图算一体优化器,包括如下部分:
7.(1)引入子算子,构建子算子的集合——精简算子集;子算子的输入张量和输出张量均用索引变量来表示;子算子对应一个嵌套循环结构,输出张量的索引变量代表嵌套循环结构的循环变量;不允许一个张量的索引变量重复。
8.(2)将算子采用子算子表示;根据算子的性质进行计算描述,表示为子算子序列的集合。
9.(3)基于子算子的代数优化方法实现算子优化模块;算子优化模块中存储子算子之间的模式匹配规则,模式匹配规则是子算子间的代数优化表示;算子优化模块对计算图中的每个子算子搜索匹配规则,对子算子申请所有的模式匹配规则,如果有规则得到应用,继续在新的计算图上搜索匹配规则,直到计算图中的所有子算子都没有搜索匹配到规则,则搜索过程结束,得到经代数优化的简化的计算图。
10.(4)基于子算子的算子融合技术实现算子融合模块;算子融合模块将前后相邻的多个子算子进行融合,在一个cpu或者gpu上,融合算子只包含一个规约类型的子算子,将规约类型的子算子作为融合算子的边界。
11.(5)将经过算子优化模块和算子融合模块优化后的计算图转化为后端代码。
12.所述(1)的精简算子集中,子算子的输入张量的个数为一个或两个,输出张量的个数固定为一个;其中,除assign外的子算子的输出张量的索引变量由输入张量的索引变量自动推导得到:一元子算子的输出张量的索引变量就是输入张量的索引变量;二元子算子的输出张量的索引变量需要两个输入张量的索引变量的超集,同时满足两个输入张量的索引变量的顺序关系;一元plus子算子中规约类型的子算子的输出张量的索引变量由输入张量的索引变量减去规约轴得到;cond的输出张量的索引变量为输入张量在对应的拼接轴拼接后的索引变量。
13.所述(2)中,对无法继续做下一次子算子运算的输出张量的索引变量进行调整,调整前后的索引变量的上下界相同,调整后的输出张量能继续做下一次子算子运算;记录索引变量的调整替换过程。
14.所述(3)中,对计算图中的常量,在编译时进行预计算;若子算子的所有输入都是常量,则该子算子的输出也是常量;采用递归算法对计算图进行预计算,从计算图的最上层子算子开始,若子算子是可计算的且所有输入变量已经计算完毕,则按照计算描述将子算子展开成for循环进行计算;若输入变量没有计算,则先计算该输入变量的值,由此递归下去;当子算子的输入为模型参数时,递归过程终止;由此计算到计算图中的所有常量。
15.本发明的优点与积极效果在于:
16.(1)本发明实现的优化器通过将算子lower到子算子,将算子表示为子算子序列集合,可以隐藏算子层级的变化,减少图优化的模式匹配规则数目,并且通过子算子可以使上层模型在部署时相对稳定。
17.(2)本发明的优化器采用基于索引变量的子算子,以及基于子算子的模式匹配规则以及子算子融合方法进行计算图优化,相对于常规的图优化技术有更好的优化效果,尤
其在一些复杂的网络结构中。
18.(3)本发明的优化器进行基于子算子的算子融合就是确定一个交给硬件执行单元的边界,确定边界后将两个边界之间的子算子交给算子调优模块并且生成代码,相较于现有的算子融合实现简单,能有效对计算图进行优化。
附图说明
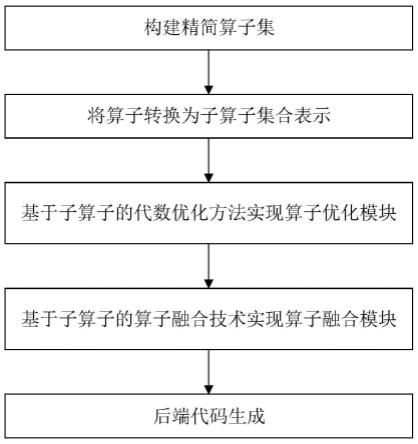
19.图1是本发明的基于精简算子集的深度学习图算一体优化器的实现框架图。
具体实施方式
20.下面将结合附图和实施例对本发明作进一步的详细说明。
21.本发明实施例实现的基于精简算子集的深度学习图算一体优化器,实现包括五部分,如图1所示,具体为:(1)构建精简算子集;(2)将算子转换为子算子集合表示;(3)基于子算子的代数优化方法实现算子优化模块;(4)基于子算子的算子融合技术实现算子融合模块;(5)后端代码生成。下面分别说明各部分的实现。
22.第一部分,首先说明本发明引入的子算子。子算子是从逻辑上将算子分成的更小单元。
23.本发明引入的子算子与现有方法的一个主要区别是,使用索引变量shape来表示子算子的输入和输出的张量,输出张量的索引变量本身指代的是循环结构的循环变量,也就是说每个子算子可以对应一个嵌套循环,所以不允许一个张量的索引变量重复。
24.子算子的输入张量的个数为一个或两个,输出张量的个数固定为一个。
25.为了表示的一致性,本发明将标量表示为0d的张量。
26.子算子表示形式如t[m,l,n]=multiply(a[m,l],b[l,n]),等式左端为子算子的输出张量t[m,l,n],右端为子算子名称multiply以及子算子的输入张量a[m,l],b[l,n],每一个张量都用索引变量来表示,索引变量要求在一个张量中不重复,具体名称如m,l,n无所谓,只要求满足索引变量shape推导。索引变量包含的上下界信息没有在等式中展示。
[0027]
子算子的分类可以从两个角度进行分类,一个是按照输入变量的数量可以分为一元,二元,一元plus,二元plus。子算子除了输入的张量之外还需要一些额外的信息,这些额外的信息作为plus的信息。
[0028]
(1)一元子算子包括:neg,rec,log,exp,nop,reshape。
[0029]
一元算子的输入张量为一个,输出张量为一个。其中,neg为对张量逐元素取反;rec为对张量逐元素取倒数;log和exp分别对张量逐个元素求对数和求幂,一般不会直接对应底层指令,但一般可以对应到函数库log和exp;nop表示什么操作都不做,设置这个算子的原因是一些模式匹配规则可能会生成nop,nop同时继续匹配对应的模式匹配规则消去,所以最终得到的子算子序列是不包含nop的;reshape对输入张量的索引变量shape进行重赋值,这一过程并不涉及张量元素的搬运以及计算,所以这一子算子不会对应任何的硬件指令。
[0030]
(2)二元的子算子有add,multiply,smax。
[0031]
add和multiply(可以简写为mul)分别表示加法和乘法,既可以表示逐元素(elementwise)的加法、乘法,也可以表示扩展(broadcast)的加法、乘法,例如t[m,l,n]=
multiply(a[m,l],b[l,n])即表示一个扩展乘法,从子算子角度,张量并没进行扩展,只是在循环中重复读取一些元素进行数据复用。
[0032]
同时为了减少指令集的个数以及对应的模式匹配规则数量,不设置减法和除法子算子,可以通过加法和取反操作得到减法,通过乘法和取倒数操作得到除法。
[0033]
smax表示从两个张量中对应的两个元素中取一个较大的值,同样子算子的两个输入张量既可以是element wise类型也可以是broadcast类型的。在深度学习算子中取最大值的操作较多,而取最小值的操作较少,所以目前的系统没有取最小值的子算子smin,当然增加一个smin算子并不困难,而且其对应的模式匹配规则也与取最大值的子算子smax一致。
[0034]
(3)一元plus子算子包括sum,max和assign。
[0035]
sum和max都是规约类型(reduce type)的子算子,即将输入张量在一个或多个轴上进行累积操作,所累积的具体操作可以是add、smax或multiply。如果具体操作是add,规约类型即为sum;如果是smax,则规约类型为max;如果是multiply,规约类型是product,这一操作在深度学习算子中并不常见,所以在目前的系统中未实现。规约类型的子算子,输出张量相对于输入张量来说减少了一个或几个维度,需要的额外信息就是规约轴(reduce axis)。
[0036]
assign子算子代表的含义是:从输入张量中取出一部分或者全部,按照一定的方式写入到输出张量。所以assign输入张量的每个维度都需要一个映射表达式(mapping expression)来表明输入张量中的元素是写入到输出张量的哪一个位置。assign子算子可以表达转置transpose,深度到空间(dense2space,将数据从深度重新排列为空间数据块),空间到深度(space2dense,将数据从空间重新排列为深度数据块)等,同时本发明扩展了assign的语义,如果映射表达式不合法,例如填充算子pad,也可以使用assign表示,不合法的部分默认为0。综上,assign需要的额外信息plus是输入张量的维度的映射表达式。
[0037]
(4)二元plus子算子只有一个cond。
[0038]
cond可以认为是连接算子concatenate的二元形式,表示将两个输入张量在对应的拼接轴(concat axis)进行拼接,算子cond要求两个张量除拼接轴的大小可以不一样外其他维度大小都需要一样。cond需要的额外信息plus就是拼接轴。当对多个输入张量进行拼接时,先拼接两个张量,得到的张量再和第三个张量进行拼接,以此类推下去。实际执行时这种执行方式可能不如直接对多个张量进行拼接,本发明将利用算子优化模块进行优化,还原到多个张量直接进行拼接。
[0039]
另一方面,子算子也可以按照实际进行的操作划分为:基本运算类,包含add,multiply,neg,smax;规约运算类,包含sum,max;内存搬运类,包含assign,cond;非线性类,包含rec,log,exp,smax;伪子算子类,包含nop,reshape。值得注意的是,smax执行的操作是做比较选择较大者,这通常是通过做减法实现的,所以smax视为基本运算类,另一方面,smax可以被用来描述relu,其一个输入张量为零维张量零,所以smax也可以视为非线性类。
[0040]
所有子算子组成精简算子集。上述子算子组合成本发明实施例目前实现的精简算子集,实际上,可以根据需要增加如smin子算子,或者出现新的子算子时,将其加入精简算子集。
[0041]
子算子的输出结果的索引变量shape除assign之外都可以自动推导。shape推导具
体如下:
[0042]
一元子算子一般来说是elementwise的,所以输出shape即为输入shape。二元子算子可以表示elementwise,也可以表示broadcast,所以结果shape需要两个输入shape的超集,同时满足两个输入shape的顺序关系。例如子算子multiply,两个输入张量为a[i,k],b[k,j],则推导的结果变量shape为[i,k,j]。对于规约类型如sum、max,将输入shape减去规约轴即是输出shape。对于cond,拼接轴替换为拼接之后的轴,即输入张量在对应的拼接轴拼接后的索引变量就是输出结果shape。
[0043]
assign的输出张量shape是手工指定的,这是由assign本身的逻辑确定的。
[0044]
随着神经网络的发展,经常会增加一些新算子或者算子的变体,新算子如果用现有的子算子可以表达则不需要增加任何人力成本,否则需要增加子算子,但是可以确定的是子算子增加的速度要远低于算子增加的速度。
[0045]
第二部分,设置算子转换模块,将算子转换为子算子集合表示。
[0046]
这个过程需要用户根据算子的性质进行计算描述,包括输入输出算子的属性等信息,例如:
[0047]
卷积convolution2d可以理解为先按照滑动窗口进行取数,然后与参数做逐元素的乘法,最后累加到一起,所以表示的子算子序列为assign,multiply,sum;
[0048]
矩阵乘matmul可以理解为两个矩阵做broadcast的乘法然后在一个轴上做累加,对应表示的子算子序列可以指定为multiply,sum;
[0049]
最大池化maxpooling2d可以理解为按照滑动窗口取数,然后取最大值;对应的子算子序列可以指定为assign,max。
[0050]
需要注意的是,本发明将子算子的输入输出用索引变量表示,输出张量的索引变量有可能无法继续做下一次子算子运算,于是需要对输出张量的索引变量进行微调,例如,对输入数据data[n,c,h,w]卷积,权重为weight[oc,c,kh,kw],卷积输出shape为[n,oc,h,w]的张量,假设oc和c上下界相同,此时就需要将oc调整为c,因此得到一个结果shape为[n,c,h,w]的张量,这个张量可以继续进行运算。同时需要记录索引变量的替换过程,为后续的优化和代码生成提供信息。
[0051]
如表1所示为一个卷积的子算子表示。
[0052]
表1卷积的子算子表示
[0053][0054]
其中,输入数据为data[n,c,h,w],n,c,h,w为输入张量的索引变量;
[0055]
算子中权重为weight[oc,c,kh,kw],oc,c,kh,kw为张量的索引变量;
[0056]
sh和sw为两个方向上的stride(步幅),ph和pw为两个方向上的padding(填充量)。
[0057]
卷积输出索引变量为n,oc,h,w的张量。
[0058]
如下表2所示为矩阵乘的子算子表示。
[0059]
表2矩阵乘的子算子表示
[0060][0061]
上述两个输入分别为data[n,l]和weight[l,m]。n,l为第一个输入的索引变量,可对应为矩阵的行和列。l,m为第二个输入的索引变量。两个输入有一个索引变量相同,这是矩阵乘法的限制。此处的l为字符l的小写形式。矩阵乘输出索引变量为n,m的张量。
[0062]
如下表3所述为最大池化的子算子表示。
[0063]
表3最大池化的子算子表示
[0064][0065]
输入为data[n,c,h,w],sh和sw为两个方向上的stride,ph和pw为两个方向上的padding。最大池化输出索引变量为n,c,oh,ow的张量。kh和kw为最大池化的核大小(kernel size)在两个维度上的变量。
[0066]
第三步,基于子算子的代数优化实现算子优化模块。
[0067]
代数优化是基于子算子之间的模式匹配规则。子算子本身的含义是表示一个嵌套的循环,最内层可以认为只有一个语句,所以可以从代数角度得到这些模式匹配规则,目前的规则大多数是两层的规则,基本可以分为交换律(指两个子算子的顺序可以交换),结合律,分配律,几何律。例如乘法对加法的分配律,乘法、加法自身的结合律等。同时为解决深度学习中一些特有的优化,本发明还提出多层的模式匹配规则,解决这些特有的优化规则无法全部用子算子的规则组合表示的问题,例如添加单位卷积(identity convolution)的优化。对模式匹配规则的命名上,上层的子算子在前面,下一层的子算子在其后,并根据下层的数量和位置添加后缀_both,_single,_left。其中,both代表上层有两个输入张量,其都是由下层子算子产生的;single代表上层有一个输入张量,其是由下层子算子产生的;left代表上层有两个输入张量,但只有第一个输入张量是由下层子算子产生的,第二个输入张量的类型不受限制。以下表4为子算子之间的模式匹配规则的示例,值得注意的是,模式匹配规则是有其限制条件的,只有满足限制条件,才会适用此条规则,具体限制不在本发明中描述。
[0068]
表4子算子之间的模式匹配规则示例
[0069][0070][0071]
由表4,本发明增加了多层规则的模式匹配规则,以解决如在加法、乘法、拼接操作中添加单位卷积的情况。
[0072]
代数优化的核心思路就是找到一个规则的序列,对由子算子构成的计算图进行变换,使得得到的计算图能够得到简化。
[0073]
首先规则本身大部分是有可逆的规则与之对应的,对所有的规则进行搜索时,可能在两个可逆的规则中不断变换,无法停止。为此,本发明根据规则本身的特点将规则分为三类,cost上升,cost下降,cost不变。衡量标准主要是变换前后的子算子数目以及子算子类型的变换。例如,乘法对加法的分配律和逆分配律,分配律由两个子算子变为三个子算子,认为是cost上升,逆分配律则相反,认为是cost下降。对于cost下降的优化,本发明认为一定可以执行这条规则,而对于cost不变或者上升的,需要在满足一定条件下才可以执行,例如规则可以将常量部分合在一起。本发明的算子优化模块中预先存储cost下降的模式匹配规则,也可以存储上附带执行条件的cost不变或者上升的模式匹配规则。
[0074]
解决完这个问题之后,本发明就可以对计算图中的每个子算子搜索匹配规则,对
每个子算子申请(apply)所有的规则,如果规则得到应用(applied),就在新的计算图上继续这个搜索匹配规则过程,所以这个搜索过程是不回溯的、不记录之前状态的一种搜索方式。当所有子算子都没有apply到任何一条规则时就认为搜索过程结束,结束之后就可以得到简化之后的计算图。
[0075]
计算图中往往包含常量的部分,所以本发明可以在编译时计算常量,而不是将其发射到后端中去。当子算子的所有输入都是常量时,就认为此时的子算子的输出也是常量,可以在编译时进行预计算,预计算的过程主要是将子算子按照子算子的计算描述展开成for循环,然后在cpu端,编译时进行计算。
[0076]
为了保证所有常量都会被计算,这里采用一个递归算法进行计算。从计算图的最上层子算子开始,如果它是可计算的(常量)并且所有输入都已经计算完毕,则取出输入和计算描述展开成for循环进行计算。如果输入变量没有计算,则先计算这个输入变量的值,由此递归下去。当子算子的输入为模型的参数(初始常量)时,递归过程终止。由此可以计算到所有常量,在接下来的融合中不再考虑常量部分的子算子,将它们的结果视为一个常量交给算子融合模块。
[0077]
第四步,基于子算子的算子融合实现算子融合模块。
[0078]
经过代数优化之后,常量被组合到一起,就可以在编译期对常量进行预计算,对于常量预计算完之后的计算图(由子算子构成),本发明可以将若干个子算子合在一起交给后端做进一步处理,在cpu或者gpu上可以认为一个融合算子不会包含两个规约(reduce)类型的子算子,因为会带来程序局部性的降低,所以采用基于贪心的融合策略即可以将若干个子算子融合成只包含一个reduce类型的算子。可以将reduce类型的子算子作为融合算子的边界,因为reduce类型的输出张量的shape是较小的,将其作为边界,其数据交换量是最少的。而对于不同架构的npu(神经网络处理器)来说,情况可能不一致,可以包含两个及以上的reduce类型,本发明可以根据硬件的体系结构修改融合策略,或者使用自动调优的方式来自动搜索融合算子的大小。
[0079]
第五步,后端代码生成。
[0080]
由于子算子表示的是嵌套的for循环结构,在自动融合之后得到的算子是子算子的组合,所以融合算子中只包含算子的计算描述而不包含其他信息,如卷积的stride和padding等,所以不能调用硬件厂商提供的深度学习加速库如cudnn和mkl-dnn等。目前后端选择有三个,一是tvm的tensor expression特定域语言,简称te,也称为halide ir,利用tvm中的auto-scheduler(也称为ansor)不需要写调度模板就可以进行自动调优,自动选择出最佳的调度生成代码并执行,同时akg(automatic kernel generator,自动内核生成器)也是支持te输入的,本发明方法可以利用akg做算子调度优化和代码生成。二是利用现有的多面体模型提取工具pet,本发明方法生成c语言代码,由pet生成多面体模型,并利用mlir(multi-level intermediate representation,多级中间表示)或者ppcg(polyhedral parallel code generator,源到源的并行代码生成器)做调度优化和代码生成。三是本发明直接利用多面体模型的库isl生成多面体模型,然后进行调度优化,生成ast(抽象语法树),最后由ast进行代码生成。由于tvm接受度高而且社区比较活跃,所以本发明实施例将tvm方案作为衡量性能的主要方案。
[0081]
表5 对网络resnet50优化的试验结果
[0082] time(ms)本发明优化器(ansor)5.11relay(topi)6.18relay(ansor)6.16relay(autotvm)4.62
[0083]
表5中relay是tvm的图优化工具,括号内部为tvm算子调优的后端,topi是默认的手写的调度,autotvm是手写的调度模板进行自动调优,ansor是自动生成调度模板并进行自动调优。由表5可以看出,采用本发明优化器进行计算图优化能取得较好的优化效果,尽管比relay(autotvm)略慢,但是明显优于relay(ansor)和relay(topi),由于relay(autotvm)采用了手写算子模板加上算子自动调优的机制,实际上要比本机制花费更多的人力成本和时间代价,而与本机制都采用一样的ansor自动调度模板的relay(ansor)比较,本机制有约20%的性能提升。
[0084]
表6 对transformer网络优化的试验结果
[0085]
类别time(ms)本发明优化器(ansor)0.263relay(topi)1.171relay(ansor)1.200relay(autotvm)0.947taso(cudnn)0.575
[0086]
其中taso是另外一种图优化工具,适用gpu的深度学习库cudnn作为后端。由表6可以看出,采用本发明优化器能取得最好的试验效果。
[0087]
除说明书所述的技术特征外,均为本专业技术人员的已知技术。本发明省略了对公知组件和公知技术的描述,以避免赘述和不必要地限制本发明。上述实施例中所描述的实施方式也并不代表与本技术相一致的所有实施方式,在本发明技术方案的基础上,本领域技术人员不需要付出创造性的劳动即可做出的各种修改或变形仍在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。