1.本发明属于计算机视觉领域,特别涉及一种基于可学习数据增强的小规模数据集扩增方法。
背景技术:
2.图像扩增最典型的方法是生成对抗网络,该方法包含两个模块,生成器和判别器。生成器网络的目标是尽量生成真实的图片去欺骗判别器,即让判别器无法判断出一张图像是真实的还是合成的。而判别器的目标就是尽量把生成器生成的图片和真实的图片分别开来,即增强自己的判别能力。通过不断训练生成器和判别器,最终该模型能够产生真实度很高的图像。
3.但是生成对抗网络要求大量的训练数据,对于小规模数据集来说,网络很容易过拟合,导致训练崩溃。
4.为了解决过拟合的问题,本发明设计了一系列的数据增强方法来增加图像的多样性,同时为了避免生成的图像受到增强数据的影响,这里使用一个可学习参数p作为各种增强方式使用的概率以达到令网络识别正确源图像的目的。
技术实现要素:
5.为解决上述技术问题,本发明提供了一种基于可学习数据增强的小规模数据集扩增方法,可以生成大量高质量图像,实现了小规模数据集的扩增,同时避免了生成的图像与原始数据不一致的情况。
6.为达到上述目的,本发明的技术方案如下:
7.一种基于可学习数据增强的小规模数据集扩增方法,包含以下步骤:
8.步骤一,数据增强:对小规模数据集中的原始图像以概率p进行数据增强,获得数据增强后的图像;
9.步骤二,生成对抗网络训练:将数据增强后的图像输入生成对抗网络的判别器中,同时,随机采样一个正态分布的噪声作为生成对抗网络中生成器的输入,由生成器生成一张图像,并输入判别器中,由判别器判断输入的图像是真实图像还是生成图像,生成器和判别器进行交替训练,优化目标函数;在训练过程中,概率p以及生成对抗网络的参数进行不断学习更新,重复步骤一和步骤二,完成生成对抗网络的训练;
10.步骤三,小规模数据集扩增:随机采样多个正态分布的噪声分别输入训练完成的生成对抗网络的生成器中,分别生成相应的图像,实现小规模数据集的扩增。
11.上述方案中,步骤一中,数据增强的方法包括几何变换、像素变换和图像滤波。
12.进一步的技术方案中,所述几何变换包括位移变换、等比缩放和非等比缩放。
13.进一步的技术方案中,所述像素变换包括亮度变化、对比度变化、饱和度变化、噪声添加和随机擦除。
14.优选地,步骤一的具体方法如下:将原始图像以概率p依次进行位移变换、等比缩
放、非等比缩放、亮度变化、对比度变化、饱和度变化、噪声添加、随机擦除以及图像滤波,获得数据增强后的图像。
15.更进一步的技术方案中,所述位移变换是以概率p对图像进行整体的位移,变换过程如下:
16.t
x
,ty~u(-0.1,0.1)
[0017][0018]
其中,概率p是一个初始值为0.5的可学习参数;t
x
,ty分别表示图像宽和高缩放的倍数;i
11
~u(0,1),是0到1的一个随机数,用于确定位移变换操作是否执行;u()表示均匀分布,translate表示位移变换操作,w和h表示图像的宽和高;round()表示取整;x0表示原始图像;x
11
为位移变换后的图像;
[0019]
所述等比缩放是以概率p将图像的宽和高按照相同的比例进行缩放,变换过程如下:
[0020]
s~u(0.5,2)
[0021][0022]
其中,i
12
~u(0,1),是0到1的一个随机数,用于确定等比缩放操作是否执行;scale表示缩放操作,s为图像宽和高的缩放倍数;crop是裁剪操作,用于将图像的宽和高重新变为w和h,以保持图像尺寸不变,x
12
是等比缩放后的图像;
[0023]
所述非等比缩放是以概率p将图像的宽和高按照不同的比例进行缩放缩,变换过程如下:
[0024]
s1~u(0.5,2),s2~u(0.5,2)
[0025][0026]
其中,i
13
~u(0,1),是0到1的一个随机数,用于确定非等比缩放操作是否执行,s1,s2分别为图像宽和高的缩放倍数,x
13
表示非等比缩放后的图像。
[0027]
更进一步的技术方案中,所述亮度变化是以概率p对图像的亮度进行变化,变化过程如下:
[0028]
b~u(0.5,1.5)
[0029][0030]
其中,i
21
~u(0,1),是0到1的一个随机数,用于确定亮度变化操作是否执行,u()表示均匀分布,bright表示亮度变化操作,b为亮度变化的倍数,x
13
表示非等比缩放后的图像,x
21
表示亮度变化后的图像;
[0031]
所述对比度变化是以概率p对图像的对比度进行变化,变化过程如下:
[0032]
c~u(0.7,1.2)
[0033][0034]
其中,i
22
~u(0,1),是0到1的一个随机数,用于确定对比度变化操作是否执行,
contrast表示对比度变化操作,c为对比度变化的倍数,x
22
表示对比度变化后的图像;
[0035]
所述饱和度变化是以概率p对图像的饱和度进行变化,变化过程如下:
[0036]
s~u(0.6,1.2)
[0037][0038]
其中,i
23
~u(0,1),是0到1的一个随机数,用于确定饱和度变化操作是否执行,saturation表示饱和度变化操作,s为饱和度变化的倍数,x
23
表示饱和度变化后的图像;
[0039]
所述噪声添加是以概率p为图像添加一个随机噪声,变化过程如下:
[0040]
r,g,b~n(0,1)
[0041][0042]
其中,i
24
~u(0,1),是0到1的一个随机数,用于确定是否添加噪声,(m,n)表示图像上的一个像素坐标,且0≤m<w,0≤n<h,w和h表示图像的宽和高,r,g,b是三个正态分布的随机数,分别对应像素的三个分量r,g,b;n()表示正态分布;x
24
表示噪声添加操作后的图像;
[0043]
所述随机擦除是以概率p随机选择图像中的一个区域将其去除,变化过程如下:
[0044]cx
,cy~u(0.3,0.6)
[0045]
left=round((c
x-0.25)
×
w)
[0046]
low=round((c
y-0.25)
×
h)
[0047]
right=round((c
x
0.25)
×
w)
[0048]
high=round((cy 0.25)
×
h)
[0049][0050][0051]
其中,i
25
~u(0,1),是0到1的一个随机数,用于确定是否进行随机擦除,(left,high)表示擦除区域的左上顶点的坐标,(right,low)表示擦除区域的右下顶点的坐标,round()表示取整;(c
x
,cy)表示擦除区域中心点的坐标,mask是擦除区域的掩码,
⊙
表示同或运算,x
25
表示随机擦除执行后的图像。
[0052]
进一步的技术方案中,所述图像滤波是以概率p对图像进行滤波操作,采用4种不同尺寸的滤波器,过程如下:
[0053]
size∈{(3,3),(5,5),(7,7),(9,9)}
[0054][0055]
其中,i
31
~u(0,1),是0到1的一个随机数,用于确定是否执行图像滤波操作,filter表示图像滤波操作,size表示四种滤波器的尺寸,x
25
表示随机擦除执行后的图像,x
31
是滤波增强后的图像,该操作从四种不同的滤波器中随机选择一个。
[0056]
优选地,步骤二中,所述生成对抗网络采用stylegan。
[0057]
进一步的技术方案中,步骤二中,在生成器训练时,判别器的参数固定,此时最小化目标函数:
[0058][0059]
当判别器训练时,生成器的参数固定,此时最大化目标函数:
[0060][0061]
其中,v(d,g)是包含概率p和生成对抗网络参数的训练函数,x是经过数据增强的真实图像,z是随机采样的噪声,d和g分别代表判别器和生成器,d()和g()分别代表判别器和生成器的输出,e表示取期望值。
[0062]
通过上述技术方案,本发明提供的基于可学习数据增强的小规模数据集扩增方法具有如下有益效果:
[0063]
(1)本发明通过对小规模数据集的图像进行一系列的数据增强,解决了使用小规模数据集训练网络时的过拟合问题,成功生成了大量高质量图像,实现了数据集扩增的目的。
[0064]
(2)本发明通过利用一个可学习参数p来作为数据增强的概率,使得网络在训练过程中能够学到原始数据(未经数据增强)的分布,避免了生成的图像与原始数据不一致的情况。
[0065]
(3)本发明通过在训练的不同阶段最大化或最小化目标函数,实现了生成对抗网络的训练,然后利用训练后的生成对抗网络,将小规模数据生成了大量真实度较高的数据,实现了小规模数据集的扩增。
附图说明
[0066]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
[0067]
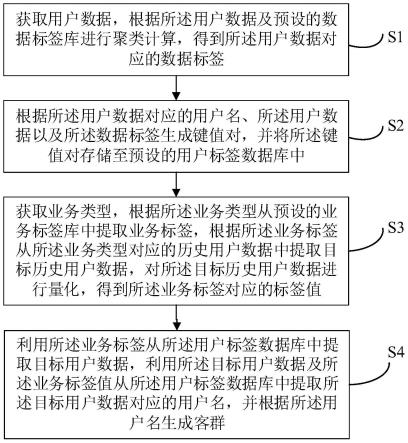
图1为本发明实施例所公开的一种基于可学习数据增强的小规模数据集扩增方法流程示意图。
具体实施方式
[0068]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0069]
本发明提供了一种基于可学习数据增强的小规模数据集扩增方法,如图1所示,包含以下步骤:
[0070]
步骤一,数据增强:对小规模数据集中的原始图像以概率p进行数据增强,获得数据增强后的图像。
[0071]
数据增强的方法包括几何变换、像素变换和图像滤波,几何变换包括位移变换、等比缩放和非等比缩放,像素变换包括亮度变化、对比度变化、饱和度变化、噪声添加和随机擦除。上述方法顺序不固定,可进行调整。
[0072]
本实施例中,采用鲜花数据集作为训练图像,该数据集是一个小规模数据集。它包含17类花卉,每个类别有80个图像,数据集中的花有明显的姿势和光线变化。按照如下顺序进行数据增强:将原始图像以概率p依次进行位移变换、等比缩放、非等比缩放、亮度变化、对比度变化、饱和度变化、噪声添加、随机擦除以及图像滤波,获得数据增强后的图像。
[0073]
具体的数据增强过程如下:
[0074]
1、位移变换
[0075]
位移变换是以概率p对图像进行整体的位移,变换过程如下:
[0076]
t
x
,ty~u(-0.1,0.1)
[0077][0078]
其中,概率p是一个初始值为0.5的可学习参数;t
x
,ty分别表示图像宽和高缩放的倍数;i
11
~u(0,1),是0到1的一个随机数,用于确定位移变换操作是否执行;u()表示均匀分布,translate表示位移变换操作,w和h表示图像的宽和高;round()表示取整;x0表示原始图像;x
11
为位移变换后的图像。
[0079]
2、等比缩放
[0080]
等比缩放是以概率p将图像的宽和高按照相同的比例进行缩放,变换过程如下:
[0081]
s~u(0.5,2)
[0082][0083]
其中,i
12
~u(0,1),是0到1的一个随机数,用于确定等比缩放操作是否执行;scale表示缩放操作,s为图像宽和高的缩放倍数;crop是裁剪操作,用于将图像的宽和高重新变为w和h,以保持图像尺寸不变,x
12
是等比缩放后的图像。
[0084]
3、非等比缩放
[0085]
非等比缩放是以概率p将图像的宽和高按照不同的比例进行缩放缩,变换过程如下:
[0086]
s1~u(0.5,2),s2~u(0.5,2)
[0087][0088]
其中,i
13
~u(0,1),是0到1的一个随机数,用于确定非等比缩放操作是否执行,s1,s2分别为图像宽和高的缩放倍数,x
13
表示非等比缩放后的图像。
[0089]
4、亮度变化
[0090]
亮度变化是以概率p对图像的亮度进行变化,变化过程如下:
[0091]
b~u(0.5,1.5)
[0092][0093]
其中,i
21
~u(0,1),是0到1的一个随机数,用于确定亮度变化操作是否执行,u()表示均匀分布,bright表示亮度变化操作,b为亮度变化的倍数,x
13
表示非等比缩放后的图像,x
21
表示亮度变化后的图像。
[0094]
5、对比度变化
[0095]
对比度变化是以概率p对图像的对比度进行变化,变化过程如下:
[0096]
c~u(0.7,1.2)
[0097][0098]
其中,i
22
~u(0,1),是0到1的一个随机数,用于确定对比度变化操作是否执行,
contrast表示对比度变化操作,c为对比度变化的倍数,x
22
表示对比度变化后的图像。
[0099]
6、饱和度变化
[0100]
饱和度变化是以概率p对图像的饱和度进行变化,变化过程如下:
[0101]
s~u(0.6,1.2)
[0102][0103]
其中,i
23
~u(0,1),是0到1的一个随机数,用于确定饱和度变化操作是否执行,saturation表示饱和度变化操作,s为饱和度变化的倍数,x
23
表示饱和度变化后的图像。
[0104]
7、噪声添加
[0105]
噪声添加是以概率p为图像添加一个随机噪声,变化过程如下:
[0106]
r,g,b~n(0,1)
[0107][0108]
其中,i
24
~u(0,1),是0到1的一个随机数,用于确定是否添加噪声,(m,n)表示图像上的一个像素坐标,且0≤m<w,0≤n<h,w和h表示图像的宽和高,r,g,b是三个正态分布的随机数,分别对应像素的三个分量r,g,b;n()表示正态分布;x
24
表示噪声添加操作后的图像。
[0109]
8、随机擦除
[0110]
随机擦除是以概率p随机选择图像中的一个区域将其去除,变化过程如下:
[0111]cx
,cy~u(0.3,0.6)
[0112]
left=round((c
x-0.25)
×
w)
[0113]
low=round((c
y-0.25)
×
h)
[0114]
right=round((c
x
0.25)
×
w)
[0115]
high=round((cy 0.25)
×
h)
[0116][0117][0118]
其中,i
25
~u(0,1),是0到1的一个随机数,用于确定是否进行随机擦除,(left,high)表示擦除区域的左上顶点的坐标,(right,low)表示擦除区域的右下顶点的坐标,round()表示取整;(c
x
,cy)表示擦除区域中心点的坐标,mask是擦除区域的掩码,
⊙
表示同或运算,x
25
表示随机擦除执行后的图像。
[0119]
9、图像滤波
[0120]
图像滤波是以概率p对图像进行滤波操作,采用4种不同尺寸的滤波器,过程如下:
[0121]
size∈{(3,3),(5,5),(7,7),(9,9)}
[0122][0123]
其中,i
31
~u(0,1),是0到1的一个随机数,用于确定是否执行图像滤波操作,filter表示图像滤波操作,size表示四种滤波器的尺寸,x
25
表示随机擦除执行后的图像,x
31
是滤波增强后的图像。该操作从四种不同的滤波器中随机选择一个。
[0124]
步骤二,生成对抗网络训练:将数据增强后的图像输入生成对抗网络的判别器中,同时,随机采样一个正态分布的噪声作为生成对抗网络中生成器的输入,由生成器生成一张图像,并输入判别器中,由判别器判断输入的图像是真实图像还是生成图像,生成器和判别器进行交替训练,优化目标函数;在训练过程中,概率p以及生成对抗网络的参数进行不断学习更新,重复步骤一和步骤二,完成生成对抗网络的训练;
[0125]
本实施例中,生成对抗网络采用stylegan,它采用渐进式增长的网络作为生成器和判别器,即网络的浅层生成分辨率较低的图像,随着网络不断加深,生成图像的分辨率会逐渐增大,最终获得较高分辨率的合成图像。具体过程如下:
[0126]
(1)将经过数据增强的图像x
31
放入判别器d中,通过判别器判断该图像的类别class是真实图像或者合成图像,即class=d(x
31
);
[0127]
(2)随机采样一个噪声z作为生成器g的输入,将其放入生成器中,生成一张图像即
[0128]
(3)将生成的图像输入判别器中,判断该图像是真实图像或者合成图像,即
[0129]
不断重复步骤(1)-(3),使得生成器尽可能生成与真实图像相似的图像,判别器尽可能辨别出输入的图像是合成的还是真实的,最终使得判别器无法辨别出图像的来源。
[0130]
其整体训练目标为:
[0131][0132]
在生成器训练时,判别器的参数固定,此时最小化目标函数:
[0133][0134]
当判别器训练时,生成器的参数固定,此时最大化目标函数:
[0135][0136]
其中,v(d,g)是包含概率p和生成对抗网络参数的训练函数,x是经过数据增强的真实图像,z是随机采样的噪声,d和g分别代表判别器和生成器,d()和g()分别代表判别器和生成器的输出,e表示取期望值。
[0137]
可学习概率p在判别器训练阶段进行更新,初始训练时,由于训练数据过小,判别器过拟合严重,此时判别器判别能力较强,无论生成器如何优化,判别器都能够辨别出图像的真假,导致后面的生成器无法有效训练,因此p会不断增大以增强训练数据的多样性。在模型训练后期,p由于过大导致生成器生成的图像更接近数据增强后的图像而不是原始图像,此时p会开始缓慢减小。模型训练结束后,p的值会在0.8到0.9之间。
[0138]
步骤三,小规模数据集扩增:随机采样多个正态分布的噪声分别输入训练完成的生成对抗网络的生成器中,分别生成相应的图像,实现小规模数据集的扩增。
[0139]
具体为:
[0140]
(1)加载上一步训练好的生成器g;
[0141]
(2)从一个正态分布中随机采样一个噪声z,输入到生成器g中,生成相应的图像image。
[0142]
image=g(z)
[0143]
随机采样多个噪声,可以分别生成相应的多幅图像,实现图像的扩增。
[0144]
本实施例中,经过上述过程,最终利用该方法生成了10000张图像,实现了该数据集的扩增。
[0145]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。