基于uc-flat的交通肇事案件法律文书命名实体识别方法
技术领域
1.本发明涉及人工智能技术领域,具体涉及基于uc-flat的交通肇事案件法律文书命名实体识别方法。
背景技术:
2.文本中的人名,地名,时间等即为实体,将文本中实体提取出来的技术就是命名实体识别(named entity recognition,ner)。命名实体识别是信息提取、问答系统、句法分析、机器翻译等众多自然语言处理(natural language processing,nlp)任务的重要基础工具。
3.现有ner模型主要存在以下问题:1.只标注了时间,地点,人物等通用型的实体,无法提取特定实体。比如:有期徒刑、终审判决等法律类型的实体。2.ner底层分词逻辑是通用的,在法律专业性较强的领域,分词结果往往不好。3.大多数是针对开放数据集的通用ner模型,只能识别开放数据集中的时间,地点,人物等实体,对于不同领域需求的特定实体,识别效果较差。4.ner模型在法律领域的f1分数为80%左右,存在准确率很高,但是召回率很低的情况,召回率用来衡量模型能够识别多少实体;在法律领域,ner模型很难识别到有期徒刑,终审判决等实体。
技术实现要素:
4.本发明的目的在于,提供一种基于uc-flat的交通肇事案件法律文书命名实体识别方法,其减少了分词错误,能够精准提取出文本中出现的法律相关实体,提高了召回率和准确率。
5.为实现上述目的,本技术提出基于uc-flat的交通肇事案件法律文书命名实体识别方法,包括:
6.获取多个交通肇事案件法律文书的标注数据;
7.在标注数据中采用非监督方式提取法律关键词,构建预训练词典;
8.构建uc-flat模型,对交通肇事案件法律文书中的实体进行识别。
9.进一步的,在标注数据中采用非监督方式提取法律关键词,构建预训练词典,具体为:
10.对多个交通肇事案件法律文书的标注数据进行清洗:去除法律文书中多余的空格,然后将标点符号进行替换和删除,只保留逗号,句号,问号;
11.通过textrank算法对清洗后的交通肇事案件法律文书进行处理并提取关键词:将法律文书先进行分词,然后将每个词语作为一个无向图的节点,通过词语之间的投票得出权重:
[0012][0013]
其中,s(vi)是第i个词语的价值,in(vi)是包含第i个词语的集合,out(vj)是第j
个词语子集中的词语集合;
[0014]
分词后,加入法律自定义常用词词典及法律停用词词典;
[0015]
将法律文书中名词wn,动词wv,动名词wnv赋予相应的权重,如下式:
[0016][0017]
式(2)与式(1)相结合后,得:
[0018][0019]
其中,d是阻尼因子;将法律文书输入到提取函数式(3)中获取关键词,所述关键词写入词典dic,进而得到预训练词典。
[0020]
进一步的,构建uc-flat模型,对交通肇事案件法律文书中的实体进行识别,具体为:
[0021]
将flat模型作为预训练模型,并加入预训练词典;
[0022]
所述预训练词典中词语相关的字向量进行双向拼接操作,然后再降维处理;
[0023]
所述flat模型将法律文书切分为字符和分词后的词语,对于每一个字符和词语构建两个位置编码head、tail,其head记录起始位置,tail记录结束位置,对于词语,其head记录词语第一个字符出现的位置,tail记录词语最后一个字符出现的位置;单个字符head和tail是相同的;
[0024]
将字向量记为v0输入到cnn层,所述cnn层对输入的字向量作卷积操作获取字形信息v1,将v0与v1进行拼接得到向量v2,所述向量v2作为flat模型的编码层输入;
[0025]
所述编码层使用非缩放的注意力机制,把每个字符的输入序列都编码成统一的语义特征再解码,得到特征向量v3;
[0026]
所述特征向量v3经过残差模块add处理和标准化norm操作后,得到中间过程值v4,v4经过多层前馈神经网络ffn处理,得到特征向量v5;
[0027]
所述特征向量v5多次重复输入子结构中得到特征向量v6,所述子结构包括残差模块add、标准化norm操作和多层前馈神经网络ffn;
[0028]
将特征向量v6输入至线性层处理,并且经过分类器softmax和条件随机场crf后输出带标签的实体。
[0029]
进一步的,预训练词典中词语相关的字向量进行双向拼接操作,具体为:
[0030][0031]
其中,h为字向量;
[0032]
对拼接后的字符向量xi进行降维处理,如式5所示:
[0033]
[0034]
其中,m为输入的字符总数,为字符向量的平均量;a为词语的协方差矩阵,w'是协方差矩阵前k个词语最大特征值,w为每列字符向量组成的矩阵,w
t
为w的转置矩阵;output为数据降维的结果,由原始维度降到了k维。
[0035]
进一步的,所述flat模型中的词语有四种相对位置信息,如下所示:
[0036][0037]
其中,为词语间的相对位置信息;
[0038]
将所述相对位置信息进行cat操作,即将这四种信息拼接到一起,然后再通过一个线性层以及激活函数relu得到参数r:
[0039][0040]
参数r能够反应法律文书中的字符和词语重要性,r数值越大越重要,越有可能是所需识别的实体。
[0041]
更进一步的,所述cnn层对输入的字向量作卷积操作获取字形信息v1,具体为:
[0042][0043]
其中,sample为输入的字符数量,词向量和字向量的维度都记为width,height
width
为卷积核的高度,widrh
width
为卷积核的宽度,padding为0,padding会增加卷积中数值为0的部分,保留了所有字符向量包含的信息;stride是卷积核的移动步长,为了尽可能多保留字符向量的信息,步长取1;height
out
为法律文书中的字符总数,width
out
为单个字符的字向量维度,故字形信息v1为height
ou
t*width
out
;
[0044]
将v0与v1进行拼接得到向量v2,如下式所示:
[0045]
v2=[v1;v0]
ꢀꢀꢀ
(9)。
[0046]
更进一步的,所述编码层使用非缩放的注意力机制,把每个字符的输入序列都编码成统一的语义特征再解码,具体为:
[0047][0048]
其中,hm为隐状态,是字符向量在模型中获取的中间数值,它记录着当前时间步的信息,一个时间步对应一个字符;c
tm
是编码encoder中所有的隐状态hm和对应权重的加权求和,这里权重是用来衡量编码encoder中位置m的隐状态hm对解码decoder中当前t位置的隐状态s
t
影响,也就是隐状态hm和隐状态s
t
的相关性,e
ij
是编码i处隐状态和解码j处隐状态;e
tm
为隐状态hm和隐状态s
t
的对齐程度:
[0049][0050]
更新当前隐状态s
t
:
[0051]st
=f(s
t-1
,y
t-1
,c
t
)
ꢀꢀꢀ
(12)
[0052]
其中,s
t-1
为前一个隐状态,y
t-1
为预测的前一个实体标签,c
t
为当前位置的上下文向量
t
;
[0053]
根据当前隐状态s
t
,预测的前一个实体标签y
t-1
,当前位置的上下文语义特征向量c
t
,得到当前实体标签y
t
:
[0054]yt
=g(s
t
,y
t-1
,c
t
)
ꢀꢀꢀ
(13)
[0055]
通过每个输入字符的语义特征向量c
t
,关注到法律文书中的字符与当前字符最相关的部分,即为“注意力”,则编码层输出的特征向量v3为:
[0056][0057]
其中,dk为比例因子;v为字符向量的矩阵。
[0058]
更进一步的,所述标准化norm操作为:
[0059][0060]
其中,u是法律文书的字符总数乘以输入神经元的个数,x是法律文书的字符总数乘以输出神经元的个数,m是法律文书的字符总数,σ2是方差;δ是一个很小的数字,防止分母为0;
[0061]
v4经过多层前馈神经网络处理:
[0062]
v5=f(w*v4 b)
ꢀꢀꢀ
(16)
[0063]
其中,f是激活函数,w为权重矩阵,该权重矩阵能影响每个字符和词语的得分,所述得分反应的是概率,最后输出概率最高的词语,即为实体识别的结果;b是偏置量。
[0064]
更进一步的,将特征向量v6输入至线性层处理,具体为:
[0065]
an=w
n1
*x1 w
n2
*x2 w
n3
*x3 .... w
nn
*xn bn
ꢀꢀꢀ
(17)
[0066]
其中,x1-xn是特征向量v6中字符x1到字符xn对应的向量,w
ni
是线性层的参数,an是线性层输出。
[0067]
an经过分类器softmax和条件随机场crf后输出实体,具体为:
[0068][0069]
所述分类器softmax使最后一维向量中数字缩放到0-1的概率值域内;条件随机场crf得到每个字符和词语的标签得分,得分最高的标签即为该字符和词语的标签:
[0070][0071]
其中,y是标签的概率值,e是输入的字向量。
[0072]
本发明采用的以上技术方案,与现有技术相比,具有的优点是:本发明在法律文书方面的命名实体识别能力更好,可以识别到法律文书中如“交通肇事罪”“交通事故”等专有名词,及“事故类型”,“罪名”,“主次责任”,“减刑因素”,“加刑因素”,“判决结果”等多个实
体;使用改进的非监督方法构造词典,减少了分词错误,有更好的词粒度,提高了实体识别的准确性。法律文书文本很长,本发明增加了非缩放的注意力机制,可以更好捕捉句子语义和长距离依赖,设置了cnn层获得字符的字形信息和位置信息,提高命名实体识别过程中的准确率。
附图说明
[0073]
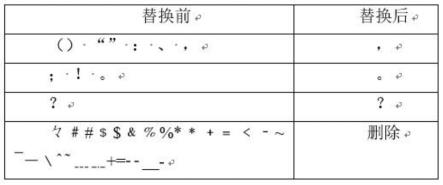
图1为标点符号替换图;
[0074]
图2为textrank算法预处理关键词过程图;
[0075]
图3为flat模型结构图;
[0076]
图4为特征向量v0与v1拼接图;
[0077]
图5为注意力机制原理图;
[0078]
图6为构建uc-flat模型流程图;
[0079]
图7为法律文书命名实体识别结果图;
[0080]
图8为bilstm的识别结果图;
[0081]
图9为分词细粒度展示图;
[0082]
图10为模型鲁棒性分析图。
具体实施方式
[0083]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术,即所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。
[0084]
实施例1
[0085]
本实施例提供一种基于uc-flat的交通肇事案件法律文书命名实体识别方法,包括:
[0086]
步骤1.获取多个交通肇事案件法律文书的标注数据;
[0087]
具体的,数据来源可以是哈工大语言技术平台(language technology plantform,ltp)标注的交通肇事案件法律文书,涉及到的实体包括人名、地名、各类犯罪情节、判决结果等。采取bioes标记模式,b是begin,代表实体的开始,i是inside,代表实体的中间,o是outside,即非实体,不做关注的词,e是end,代表实体的结束,s是single,代表单个字符,本身就是一个实体。本实施例一共有700多条交通肇事案件的标注数据。
[0088]
步骤2.在标注数据中采用非监督方式提取法律关键词,构建预训练词典,包括:
[0089]
步骤2.1相比英文ner,中文要更难,因为中文还需要分词,而中文分词的边界划分一直是难题,所以为了使法律文书的数据更简单,提高非监督方法分词的准确率,先进行数据的清洗:去除法律文书中多余的空格,然后将标点符号进行替换和删除,只保留逗号,句号,问号;其余标点符号按照图1所示替换和删除。
[0090]
步骤2.2通过textrank算法对清洗后的交通肇事案件法律文书进行处理并提取关键词:将法律文书先进行分词,然后将每个词语作为一个无向图的节点,通过词语之间的投票得出权重:
[0091][0092]
其中,s(vi)是第i个词语的价值,in(vi)是包含第i个词语的集合,out(vj)是第j个词语子集中的词语集合;
[0093]
分词后,加入法律自定义常用词词典及法律停用词词典;其着眼于法律的关键词,减少不相关的关键词,过程如图2所示。法律自定义常用词词典中包含“民事违法”,“诉讼中止”等专业词汇,提高关键词提取的准确性和专业性。
[0094]
在法律文书中名词、动词、动名词的比例加起来占据了71%,所以在提取关键词时更关注这三类词给出的信息,使用textrank函数提取关键词,给予这三种词性更大的权重,名词权重(wn)乘3,动词权重(wv)*2.5,动名词(wnv)*1.5,如式2所示,其余词性的词不做改变,这样做也可以提高程序运行效率。
[0095][0096]
式(2)与式(1)相结合后,得:
[0097][0098]
其中,d是阻尼因子;将法律文书输入到提取函数式(3)中获取关键词,所述关键词写入词典dic,进而得到预训练词典。
[0099]
步骤3.构建uc-flat模型,对交通肇事案件法律文书中的实体进行识别,包括:
[0100]
步骤31.将flat模型作为预训练模型,并加入预训练词典;
[0101]
步骤32.所述预训练词典中词语相关的字向量进行双向拼接操作,然后再降维处理;
[0102][0103]
其中,h为字向量;
[0104]
对拼接后的字符向量xi进行降维处理,如式(5)所示:
[0105][0106]
其中,m为输入的字符总数,为字符向量的平均量;a为词语的协方差矩阵,w'是协方差矩阵前k个词语最大特征值,w为每列字符向量组成的矩阵,w
t
为w的转置矩阵;output为数据降维的结果,由原始维度降到了k维。
[0107]
传统的随机初始化方法,如one-hot,cbow,skip-gram,会丢失词典中的词和flat模型字向量之间的联系,故本发明使用随机初始化方法,给词典dic中的每一个词一个初始词向量。把dic词典加入flat模型,在flat模型的分词阶段,会和词典中的词进行匹配,得到更好的分词结果。
[0108]
步骤33.所述flat模型将法律文书切分为字符和分词后的词语,对于每一个字符和词语构建两个位置编码head、tail,其head记录起始位置,tail记录结束位置,对于词语,其head记录词语第一个字符出现的位置,tail记录词语最后一个字符出现的位置;单个字符head和tail是相同的;如图3所示。
[0109]
对于ner任务来说,相对位置和方向信息是十分重要的,flat模型提出相对位置编码,用四种相对距离,根据起始位置来表示它们之间有三种关系:相交、包含、相离。如式(6)所示,flat模型中设置了四种不同的相对位置信息,分别是开始减开始,开始减结束,结束减开始,结束减结束,这一部分增强了位置编码信息,在ner任务中取得了较好的效果;这种方式引入了词语信息,也弥补了模型无法捕捉长距离依赖的缺点。
[0110][0111]
其中,为词语间的相对位置信息;
[0112]
将所述相对位置信息进行cat操作,即将这四种信息拼接到一起,然后再通过一个线性层以及激活函数relu得到参数r:
[0113][0114]
参数r能够反应法律文书中的字符和词语重要性,r数值越大越重要,越有可能是所需识别的实体。
[0115]
步骤34.将字向量记为v0输入到cnn层,所述cnn层对输入的字向量作卷积操作获取字形信息v1,将v0与v1进行拼接得到向量v2,所述向量v2作为flat模型的编码层输入;
[0116]
需要说明的是:汉字作为一种象形文字,汉字字形本身就包含着隐藏信息,例如火名称中的字符,“火焰”,“燃烧”和“火炎焱”都有相同的根字符“火”,相同领域的字符通常具有相似根字符特征,因此在flat模型加入cnn层来提取文字字形包含的信息。所述cnn层对输入的字向量作卷积操作,获取字形的信息,如式(8)所示,
[0117][0118]
其中,sample为输入的字符数量,词向量和字向量的维度都记为width,height
width
为卷积核的高度,widrh
width
为卷积核的宽度,padding为0,padding会增加卷积中数值为0的部分,保留了所有字符向量包含的信息;stride是卷积核的移动步长,为了尽可能多保留字符向量的信息,步长取1;height
out
为法律文书中的字符总数,width
out
为单个字符的字向量维度,故字形信息v1为height
ou
t*width
out
;
[0119]
如图4所示,将v0与v1进行拼接得到向量v2,如下式所示:
[0120]
v2=[v1;v0]
ꢀꢀꢀ
(9)
[0121]
步骤35.所述编码层使用非缩放的注意力机制,如式(10)所示,把每个字符的输入序列都编码成统一的语义特征再解码,得到特征向量v3;
[0122][0123]
其中,hm为隐状态,是字符向量在模型中获取的中间数值,它记录着当前时间步的信息,一个时间步对应一个字符;c
tm
是编码encoder中所有的隐状态hm和对应权重的加权求和,这里权重是用来衡量编码encoder中位置m的隐状态hm对解码decoder中当前t位置的隐状态s
t
影响,也就是隐状态hm和隐状态s
t
的相关性,e
ij
是编码i处隐状态和解码j处隐状态;e
tm
为隐状态hm和隐状态s
t
的对齐程度:
[0124][0125]
更新当前隐状态s
t
:
[0126]st
=f(s
t-1
,y
t-1
,c
t
)
ꢀꢀꢀ
(12)
[0127]
其中,s
t-1
为前一个隐状态,y
t-1
为预测的前一个实体标签,c
t
为当前位置的上下文向量
t
;
[0128]
如图5所示,根据当前隐状态s
t
,预测的前一个实体标签y
t-1
,当前位置的上下文语义特征向量c
t
,得到当前实体标签y
t
:
[0129]yt
=g(s
t
,y
t-1
,c
t
)
ꢀꢀꢀ
(13)
[0130]
通过每个输入字符的语义特征向量c
t
,关注到法律文书中的字符与当前字符最相关的部分,即为“注意力”,则编码层输出的特征向量v3为:
[0131][0132]
其中,dk为比例因子;v为字符向量的矩阵。
[0133]
步骤36.所述特征向量v3经过残差模块add处理和标准化norm操作后,得到中间过程值v4,v4经过多层前馈神经网络ffn处理,得到特征向量v5;
[0134]
具体的,残差模块add是为了解决多层神经网络训练困难的问题,通过将一部分的前一层信息无差的传递到下一层,有效提升模型性能;标准化norm操作这里使用的是layer norm,能对所有特征进行缩放,如式(15)所示:
[0135][0136]
其中,u是法律文书的字符总数乘以输入神经元的个数,x是法律文书的字符总数乘以输出神经元的个数,m是法律文书的字符总数,σ2是方差;δ是一个很小的数字,防止分母为0;
[0137]
v4经过多层前馈神经网络处理:
[0138]
v5=f(w*v4 b)
ꢀꢀꢀ
(16)
[0139]
其中,f是激活函数,w为权重矩阵,该权重矩阵能影响每个字符和词语的得分,所述得分反应的是概率,最后输出概率最高的词语,即为实体识别的结果;b是偏置量。
[0140]
步骤37.所述特征向量v5多次重复输入子结构中得到特征向量v6,所述子结构包括残差模块add、标准化norm操作和多层前馈神经网络ffn;
[0141]
步骤38.将特征向量v6输入至线性层处理,如式(17)所示,并且经过分类器softmax和条件随机场crf后输出带标签的实体,如式(18)所示:
[0142]
an=w
n1
*x1 w
n2
*x2 w
n3
*x3 .... w
nn
*xn bn
ꢀꢀꢀ
(17)
[0143]
其中,x1-xn是特征向量v6中字符x1到字符xn对应的向量,w
ni
是线性层的参数,an是线性层输出。
[0144]
an经过分类器softmax和条件随机场crf后输出实体,如图6所示,具体为:
[0145][0146]
所述分类器softmax使最后一维向量中数字缩放到0-1的概率值域内;条件随机场crf得到每个字符和词语的标签得分,得分最高的标签即为该字符和词语的标签:
[0147][0148]
其中,y是标签的概率值,e是输入的字向量。
[0149]
本发明在法律文书方面的命名实体识别能力更好,抽取结果如图7所示,可以识别到法律文书中专有名词,如图8所示。有更好的词粒度,提高了实体识别的准确性,如图9所示。增加了非缩放的注意力机制,可以更好捕捉句子语义和长距离依赖,随着句子长度的增加,f1降低较少,有更好的鲁棒性。如图10所示。
[0150]
用本发明uc-flat模型和其他命名实体识别的经典模型作了对比实验,使用相同的数据集,将p,r,f1值作为评价标注,对比结果表1所示。f1值是最泛用的kpi,结合了准确率和召回率,f1值越大说明模型越成功,本发明模型f1值达到87.31%,是最高的,与flat模型相比,f1值提高了5.83%,准确率提高了0.79%,召回率提高了11.52%。
[0151]
表1 uc-flat模型和其他命名实体识别的经典模型对比实验
[0152][0153]
为了分析单一改进策略对模型评价结果的影响,实行逐一排除改进策略的方式,结果表2所示,证明改进措施是有效的。
[0154]
表2 排除改进策略的结果比较
[0155][0156]
表3为本模型不同实体抽取结果展示,对六类专有名词识别的表现都较好。
[0157]
表3 各实体抽取结果展示
[0158]
实体类别准确率p召回率rf1事故类型0.85260.86330.8580罪名0.87660.89370.8852主次责任0.80840.83250.8205减刑因素0.83260.84230.8375加刑因素0.85120.88130.8663判决结果0.88210.89450.8883
[0159]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。