1.本发明涉及试验标准规范审查技术领域,具体涉及一种自动构建试验标准知识图谱的方法。
背景技术:
2.在力热实验室中,每次试验都需要按照特定的方法和标准进行,试验所用的试剂材料、设备仪器都有特定的标准,这些标准均由国家标准或军用标准给出。
3.标准之间存在着相互引用。实验中,试验标准引用的试剂材料、设备仪器只列出了相应标准的标准编号,如果要查阅材料或设备标准的具体内容,则需要查阅相应的标准文档。查阅一种试验标准文档需要附带查阅多篇该试验引用的其他标准文档,这种相互引用关系增加了查阅试验标准的繁琐度。同时,某中试剂或设备存在被多种试验引用的情况,这种在文档中查阅的方式不能直观的将它们之间的引用关系显示出来。在标准文档中查阅试验标准、试剂标准、设备标准及其引用关系存在着很大的局限性。
技术实现要素:
4.本发明的目的在于:提出一种自动构建试验标准知识图谱的方法,根据试验标准文档内容提取知识图谱的概念及其关系并人工标注数据集训练出用于实体属性提取的神经网络模型;将提取出的实体与从文档中提取出的标准编号整理形成三元组,将其存放数据库中,最后编程实现试验标准知识图谱系统,解决了原有查阅文档方式的局限性。
5.本发明采用的技术方案如下:
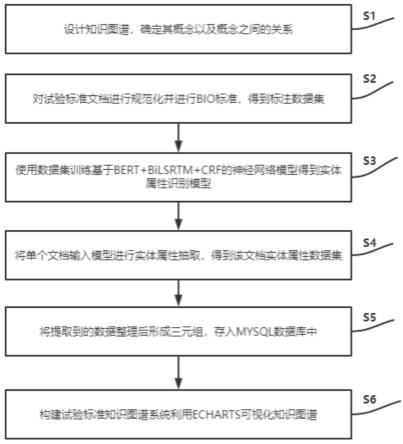
6.本发明是一种自动构建试验标准知识图谱的方法,具体包括以下步骤:
7.s1,根据试验标准文档提取知识图谱概念,确定概念极其之间的关系;
8.s2,对现有的试验标准文档进行规范处理和bio标注,得到标注数据集;
9.s3,使用标注数据集训练基于bert bilstm crf的神经网络模型,得到标准文档实体-属性提取模型;
10.s4、选取标准文档以提取内容,将文档中的文本数据进行整理得到较短的单个句子;将所得句子输入模型,得到单个字符的标注类别概率;经解码后得到每个字符的标注类别,对每个句子进行实体抽取,得到该文档实体-属性数据集;
11.s5,对步骤s4中获取的实体-属性数据集,遍历数据集获取每条数据,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该位置为中心在句子中向左或向右查找该实体的所遵循的标准;将文档名称作为一个实体与提取的每个实体及文档与提取实体之间的关系整理并构成三元组,将每个实体与其标准编号及其引用关系整理后形成多个三元组;设计数据库将三元组存入mysql数据库中以供查询使用;
12.s6、构建试验标准知识图谱系统,利用echarts可视化知识图谱。
13.进一步的,所述步骤s1中:构建知识图谱首先要明确知识图谱所拥有的概念、其次
确定概念之间的关系,对于步骤s1中确定知识图谱概念及概念之间的关系,试验标准文档中关于一种试验的标准文档被分成八个部分它们分别为:适用范围、引用文件、方法原理、试剂和材料、仪器设备和实验装置、试验准备、试验程序、结果的说明,根据以上八个部分的内容,可以提取出知识图谱的几个概念:方法、性能、材料、标准、设备、公式。
14.进一步的,所述步骤s2中数据集形成与bio标注具体步骤包括:
15.s2.1、对试验标准文档进行格式处理,将标题、图片等无用信息去除,将文本中的长句转化为单句,一行只保留一个单句;
16.s2.2、根据bio标注规则,对每个单句中每个字符进行人工标注;标注的标签有“b-*”、“i-*”、“o”,其中,“b-*”表示该字符在一个实体的开头位置并且该实体属于“*”所代表的实体类型,“i-*”表明该字符在一个实体的中间或末尾位置并且该实体属于“*”所代表的实体类型,“o”代表与实体无关的字符;“*”代表实体的类型;
17.在标准数据集文本中,一个条标准数据占用两行;第一行为句子中每个字的标签,第二行为该单句,其中每个字符和标签都用空格隔开,字符和标签一一对应。
18.进一步的,所述实体的类型包括设备、性能、材料或公式。
19.进一步的,所述步骤s3中基于bert bilstm crf的神经网络模型训练过程具体步骤包括:
20.s3.1,将标准数据集划分为训练集、测试集和验证集,其划分比例为8:1:1;
21.s3.2,建立基于bert bilstm crf的神经网络模型,其模型以训练集中每个句子作为输入,以每个字符最大概率标签为输出;
22.bert为输入层,用于产生词向量,其过程为:读取每行数据得到token列表,token中需要加入[cls]、[sep]等标志性符号,其最终结果为:
[0023]
tokens=[[cls],w1,w2,...,wn,[sep]]
[0024]
将分词列表中的每个字元素按照中文词表数据转换为词表编码向量,构成词表编码向量表,其结果为:tokenembe={e1,e2,...,en};其中en为wn的词表编码向量;
[0025]
将分词列表中的每个字元素按照其索引采用独热编码转换为位置嵌入向量,构成位置嵌入向量表:positionembe={p1,p2,...pn};其中pn为wn的位置嵌入向量;
[0026]
对这些表示进行元素求和,最终的embedding向量是将上述词表编码向量直接做加和的结果,这是传递给bert的编码器层的输入表示,经过bert预处理后得到句子的嵌入表示;
[0027]
将位置嵌入向量输入bilstm编码层和crf输出层,最终得到输入句子中每个字符所属标签的最大概率;
[0028]
s3.3,对于bilstm编码层,其输出维度为标签个数,表明每个词wi映射到标签的发射概率,设bilstm的输出矩阵为p,其中p
ij
代表词wi映射到标签j的非归一化概率;
[0029]
对于crf输出层来说,假定存在一个转移矩阵a,则ai,j代表标签i转移到标签j的转移概率,对于输入序列x对应的输出标签序列y,定义其评分公式为:
[0030][0031]
利用softmax函数,为每一个正确的标签序列y定义一个概率值,其中,y
x
代表所有
的标签序列,公式为:
[0032][0033]
将损失函数定义为-log(p(y|x)):
[0034][0035]
s3.4,采用十则交叉验证训练模型,在得到的多个结果中选取f1值得分最高的模型作为标准文档实体-属性提取模型。
[0036]
进一步的,所述步骤s5具体为:遍历s4中获取的实体-属性数据集,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该位置为中心在句子中向左或向右查找该实体的所遵循的标准,在标准文档中出现的实体若存在遵循标准的情况,则在文本中实体出现位置前或后会明确指出;将文档名称作为一个实体设为de,提取的实体集合e={e1,e2,
…
,en},de与每个提取的实体的关系集合为r={r1,r2,
…
,rn},则构成的三元组为(de,ri,ei),其中i=1,2,3,..,n,r的可选关系为:“适用”、“使用”、“应用”;对于每个实体对应的标准集合se={se1,se2,
…
,sen},构建三元组为(ei,“引用”,sei),sei可以为空,表明该实体无遵循标准;设计数据库将三元组存入mysql数据库中以供查询使用。
[0037]
进一步的,所述步骤s6构建试验标准知识图谱系统,其工作流程如下:页面中上传标准文档;后台获取标准文档,提取文档文字内容,将内容转化为特定格式;将特定格式数据放入步骤s3所述标准文档实体属性提取模型提取实体;根据提取结果,在标准文档中查找实体可能存在的引用标准;将数据构建成三元组并且存入数据库中;查询三元组并在页面可视化显示以供浏览、下载。
[0038]
综上所述,由于采用了本技术方案,本发明的有益效果是:
[0039]
本发明是一种自动构建试验标准知识图谱的方法,根据试验标准文档内容提取知识图谱的概念及其关系并人工标注数据集训练出用于实体属性提取的神经网络模型;将提取出的实体与从文档中提取出的标准编号整理形成三元组,将其存放数据库中,最后编程实现试验标准知识图谱系统,本发明能自动构建标准文档知识图谱,解决了试验标准文档中因文档相互引用不易查阅的问题,以及原有查阅文档方式的局限性,提高了相关工作人员查阅标准的效率。
附图说明
[0040]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图,本说明书附图中的各个部件的比例关系不代表实际选材设计时的比例关系,其仅仅为结构或者位置的示意图,其中:
[0041]
图1是本发明的试验标准知识图谱构建流程图;
[0042]
图2为标准文档实体-属性提取模型的结构示意图;
[0043]
图3是本发明构建的知识图谱所有概念及其关系的示意图;
[0044]
图4是本发明试验标准知识图谱数据库模型;
[0045]
图5是发明试验标准知识图谱系统模块图。
具体实施方式
[0046]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0047]
需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
[0048]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0049]
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0050]
下面结合附图对本发明作详细说明。
[0051]
具体实施例实施如下:
[0052]
本发明是一种自动构建试验标准知识图谱的方法,图1为本发明的试验标准知识图谱构建流程图,具体操作步骤如下:
[0053]
s1,根据试验标准文档提取知识图谱概念,确定概念极其之间的关系;
[0054]
构建知识图谱首先要明确知识图谱所拥有的概念、其次确定概念之间的关系,对于步骤s1中确定知识图谱概念及概念之间的关系,其具体如图3所示,试验标准文档中关于一种试验的标准文档被分成八个部分它们分别为:适用范围、引用文件、方法原理、试剂和材料、仪器设备和实验装置、试验准备、试验程序、结果的说明,根据以上八个部分的内容,可以提取出知识图谱的几个概念:方法、性能、材料、标准、设备、公式。
[0055]
s2,对现有的试验标准文档进行规范处理和bio标注,得到标注数据集;
[0056]
所述步骤s2中数据集形成与bio标注具体步骤包括:
[0057]
s2.1、对试验标准文档进行格式处理,将标题、图片等无用信息去除,将文本中的长句转化为单句,一行只保留一个单句;
[0058]
s2.2、根据bio标注规则,对每个单句中每个字符进行人工标注;标注的标签有“b-*”、“i-*”、“o”,其中,“b-*”表示该字符在一个实体的开头位置并且该实体属于“*”所代表的实体类型,“i-*”表明该字符在一个实体的中间或末尾位置并且该实体属于“*”所代表的实体类型,“o”代表与实体无关的字符;“*”代表实体的类型,所述实体的类型包括设备、性能、材料或公式;
[0059]
在标准数据集文本中,一个条标准数据占用两行;第一行为句子中每个字的标签,第二行为该单句,其中每个字符和标签都用空格隔开,字符和标签一一对应。
[0060]
s3,使用标注数据集训练基于bert bilstm crf的神经网络模型,得到标准文档实
体-属性提取模型,如图2所示;
[0061]
所述步骤s3中基于bert bilstm crf的神经网络模型训练过程具体步骤包括:
[0062]
s3.1,将标准数据集划分为训练集、测试集和验证集,其划分比例为8:1:1;
[0063]
s3.2,建立基于bert bilstm crf的神经网络模型,其模型以训练集中每个句子作为输入,以每个字符最大概率标签为输出;
[0064]
bert为输入层,用于产生词向量,其过程为:读取每行数据得到token列表,token中需要加入[cls]、[sep]等标志性符号,其最终结果为:
[0065]
tokens=[[cls],w1,w2,...,wn,[sep]]
[0066]
将分词列表中的每个字元素按照中文词表数据转换为词表编码向量,构成词表编码向量表,其结果为:tokenembe={e1,e2,...,en};其中en为wn的词表编码向量;
[0067]
将分词列表中的每个字元素按照其索引采用独热编码转换为位置嵌入向量,构成位置嵌入向量表:positionembe={p1,p2,...pn};其中pn为wn的位置嵌入向量;
[0068]
对这些表示进行元素求和,最终的embedding向量是将上述词表编码向量直接做加和的结果,这是传递给bert的编码器层的输入表示,经过bert预处理后得到句子的嵌入表示;
[0069]
将位置嵌入向量输入bilstm编码层和crf输出层,最终得到输入句子中每个字符所属标签的最大概率;
[0070]
s3.3,对于bilstm编码层,其输出维度为标签个数,表明每个词wi映射到标签的发射概率,设bilstm的输出矩阵为p,其中p
ij
代表词wi映射到标签j的非归一化概率;
[0071]
对于crf输出层来说,假定存在一个转移矩阵a,则ai,j代表标签i转移到标签j的转移概率,对于输入序列x对应的输出标签序列y,定义其评分公式为:
[0072][0073]
利用softmax函数,为每一个正确的标签序列y定义一个概率值,其中,y
x
代表所有的标签序列,公式为:
[0074][0075]
将损失函数定义为-log(p(y|x)):
[0076][0077]
s3.4,采用十则交叉验证训练模型,在得到的多个结果中选取f1值得分最高的模型作为标准文档实体-属性提取模型。
[0078]
s4,选取标准文档以提取内容,将文档中的文本数据进行整理得到较短的单个句子;将所得句子输入模型,得到单个字符的标注类别概率;经解码后得到每个字符的标注类别,对每个句子进行实体抽取,得到该文档实体-属性数据集;
[0079]
s5,对步骤s4中获取的实体-属性数据集,遍历数据集获取每条数据,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该
位置为中心在句子中向左或向右查找该实体的所遵循的标准;将文档名称作为一个实体与提取的每个实体及文档与提取实体之间的关系整理并构成三元组,将每个实体与其标准编号及其引用关系整理后形成多个三元组;设计数据库将三元组存入mysql数据库中以供查询使用;
[0080]
所述步骤s5具体为:遍历s4中获取的实体-属性数据集,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该位置为中心在句子中向左或向右查找该实体的所遵循的标准,在标准文档中出现的实体若存在遵循标准的情况,则在文本中实体出现位置前或后会明确指出;将文档名称作为一个实体设为de,提取的实体集合e={e1,e2,
…
,en},de与每个提取的实体的关系集合为r={r1,r2,
…
,rn},则构成的三元组为(de,ri,ei),其中i=1,2,3,..,n,r的可选关系为:“适用”、“使用”、“应用”;对于每个实体对应的标准集合se={se1,se2,
…
,sen},构建三元组为(ei,“引用”,sei),sei可以为空,表明该实体无遵循标准;设计数据库将三元组存入mysql数据库中以供查询使用。
[0081]
s6,构建试验标准知识图谱系统,利用echarts可视化知识图谱。
[0082]
所述步骤s6构建试验标准知识图谱系统,其工作流程如下:页面中上传标准文档;后台获取标准文档,提取文档文字内容,将内容转化为特定格式;将特定格式数据放入步骤s3所述标准文档实体属性提取模型提取实体;根据提取结果,在标准文档中查找实体可能存在的引用标准;将数据构建成三元组并且存入数据库中;查询三元组并在页面可视化显示以供浏览、下载。
[0083]
系统在若依框架中进行二次开发,它是基于java的开源的后台管理系统。知识图谱展示使用echarts,它是一款基于javascript的数据可视化图表库。系统提供直观,生动,可交互,可个性化定制的数据可视化图表。
[0084]
具体的,对于步骤s6中所涉及的数据库,其设计如下:
[0085]
根据试验标准知识图谱系统所涉及的内容,系统设计了概念表、实体表、公式表、关系表、公式-实体表、概念-关系表,它们具体的关系如图4所示。各表说明如下:
[0086]
概念表:存放了从文档中提取的概念;
[0087]
实体表:存放从文档中抽取的具体的试验名称、材料、设备等,每个实体都是某个概念的实例;
[0088]
公式表:存放获取的公式;
[0089]
公式-实体表:存放实体与公式的引用关系,一个实体存在使用多个公式的情况,是多对一的关系;
[0090]
关系表:存放着概念之间关系的种类;
[0091]
概念-关系表:确定两个概念之间的关系,以此确定概念之下所属实体的关系。
[0092]
具体的,对于步骤s6中所涉及试验标准知识图谱系统,主要由知识浏览、知识图谱浏览、知识图谱管理、知识管理、公式管理、知识组织六个模块组成,如图5所示。其具体功能如下:
[0093]
知识图谱浏览:本模块显示了本系统知识图谱所涉及的所有概念和概念之间的关系。浏览本模块可快速了解知识图谱整体结构。
[0094]
知识浏览:对实体及其关系的可视化。依据实体使用量来设置节点大小,直观的显
示了试验、材料、设备的使用频率。
[0095]
知识图谱管理:设定概念及其关系,以此确定实体之间的关系;
[0096]
知识管理:对实体的管理模块,包括输入标准文档提取实体、增加实体编辑实体等功能;
[0097]
公式管理:公式管理模块,包括公式的新增、编辑等基本功能,同时提供公式计算的功能;
[0098]
知识组织:针对知识图谱中实体之间所显示的关系及其共同特点,将其整理归纳形成知识组织构成专栏,便于知识查阅。
[0099]
本发明根据试验标准文档内容提取知识图谱的概念及其关系并人工标注数据集训练出用于实体属性提取的神经网络模型;将提取出的实体与从文档中提取出的标准编号整理形成三元组,将其存放数据库中,最后编程实现试验标准知识图谱系统。该系统解决了原有查阅文档方式的局限性。
[0100]
以上所述,仅为本发明的优选实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书所限定的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。