技术特征:
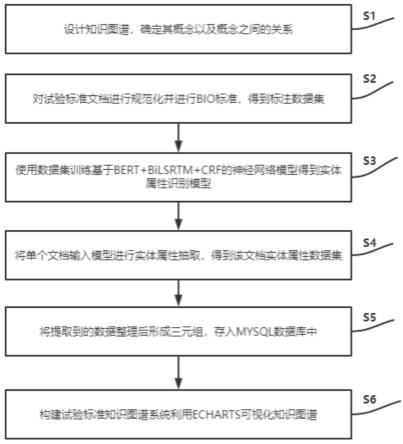
1.一种自动构建试验标准知识图谱的方法,其特征在于,具体包括以下步骤:s1,根据试验标准文档提取知识图谱概念,确定概念极其之间的关系;s2,对现有的试验标准文档进行规范处理和bio标注,得到标注数据集;s3,使用标注数据集训练基于bert bilstm crf的神经网络模型,得到标准文档实体-属性提取模型;s4,选取标准文档以提取内容,将文档中的文本数据进行整理得到较短的单个句子;将所得句子输入模型,得到单个字符的标注类别概率;经解码后得到每个字符的标注类别,对每个句子进行实体抽取,得到该文档实体-属性数据集;s5,对步骤s4中获取的实体-属性数据集,遍历数据集获取每条数据,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该位置为中心在句子中向左或向右查找该实体的所遵循的标准;将文档名称作为一个实体与提取的每个实体及文档与提取实体之间的关系整理并构成三元组,将每个实体与其标准编号及其引用关系整理后形成多个三元组;设计数据库将三元组存入mysql数据库中以供查询使用;s6,构建试验标准知识图谱系统,利用echarts可视化知识图谱。2.根据权利要求1所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述步骤s1中:构建知识图谱首先要明确知识图谱所拥有的概念、其次确定概念之间的关系,对于步骤s1中确定知识图谱概念及概念之间的关系,试验标准文档中关于一种试验的标准文档被分成八个部分它们分别为:适用范围、引用文件、方法原理、试剂和材料、仪器设备和实验装置、试验准备、试验程序、结果的说明,根据以上八个部分的内容,可以提取出知识图谱的几个概念:方法、性能、材料、标准、设备、公式。3.根据权利要求1所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述步骤s2中数据集形成与bio标注具体步骤包括:s2.1、对试验标准文档进行格式处理,将标题、图片等无用信息去除,将文本中的长句转化为单句,一行只保留一个单句;s2.2、根据bio标注规则,对每个单句中每个字符进行人工标注;标注的标签有“b-*”、“i-*”、“o”,其中,“b-*”表示该字符在一个实体的开头位置并且该实体属于“*”所代表的实体类型,“i-*”表明该字符在一个实体的中间或末尾位置并且该实体属于“*”所代表的实体类型,“o”代表与实体无关的字符;“*”代表实体的类型;在标准数据集文本中,一个条标准数据占用两行;第一行为句子中每个字的标签,第二行为该单句,其中每个字符和标签都用空格隔开,字符和标签一一对应。4.根据权利要求3所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述实体的类型包括设备、性能、材料或公式。5.根据权利要求1所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述步骤s3中基于bert bilstm crf的神经网络模型训练过程具体步骤包括:s3.1,将标准数据集划分为训练集、测试集和验证集,其划分比例为8:1:1;s3.2,建立基于bert bilstm crf的神经网络模型,其模型以训练集中每个句子作为输入,以每个字符最大概率标签为输出;bert为输入层,用于产生词向量,其过程为:读取每行数据得到token列表,token中需
要加入[cls]、[sep]等标志性符号,其最终结果为:tokens=[[cls],w1,w2,...,w
n
,[sep]]将分词列表中的每个字元素按照中文词表数据转换为词表编码向量,构成词表编码向量表,其结果为:tokenembe={e1,e2,...,e
n
};其中en为wn的词表编码向量;将分词列表中的每个字元素按照其索引采用独热编码转换为位置嵌入向量,构成位置嵌入向量表:positionembe={p1,p2,...p
n
};其中pn为wn的位置嵌入向量;对这些表示进行元素求和,最终的embedding向量是将上述词表编码向量直接做加和的结果,这是传递给bert的编码器层的输入表示,经过bert预处理后得到句子的嵌入表示;将位置嵌入向量输入bilstm编码层和crf输出层,最终得到输入句子中每个字符所属标签的最大概率;s3.3,对于bilstm编码层,其输出维度为标签个数,表明每个词w
i
映射到标签的发射概率,设bilstm的输出矩阵为p,其中p
ij
代表词w
i
映射到标签j的非归一化概率;对于crf输出层来说,假定存在一个转移矩阵a,则ai,j代表标签i转移到标签j的转移概率,对于输入序列x对应的输出标签序列y,定义其评分公式为:利用softmax函数,为每一个正确的标签序列y定义一个概率值,其中,y
x
代表所有的标签序列,公式为:将损失函数定义为-log(p(y|x)):s3.4,采用十则交叉验证训练模型,在得到的多个结果中选取f1值得分最高的模型作为标准文档实体-属性提取模型。6.根据权利要求1所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述步骤s5具体为:遍历s4中获取的实体-属性数据集,一条数据即为一个实体,其属性即为该实体的类型;在标准文档中定位实体出现在文本中的位置,以该位置为中心在句子中向左或向右查找该实体的所遵循的标准,在标准文档中出现的实体若存在遵循标准的情况,则在文本中实体出现位置前或后会明确指出;将文档名称作为一个实体设为de,提取的实体集合e={e1,e2,
…
,en},de与每个提取的实体的关系集合为r={r1,r2,
…
,rn},则构成的三元组为(de,ri,ei),其中i=1,2,3,..,n,r的可选关系为:“适用”、“使用”、“应用”;对于每个实体对应的标准集合se={se1,se2,
…
,sen},构建三元组为(ei,“引用”,sei),sei可以为空,表明该实体无遵循标准;设计数据库将三元组存入mysql数据库中以供查询使用。7.根据权利要求1所述的一种自动构建试验标准知识图谱的方法,其特征在于,所述步骤s6构建试验标准知识图谱系统,其工作流程如下:页面中上传标准文档;后台获取标准文档,提取文档文字内容,将内容转化为特定格式;将特定格式数据放入步骤s3所述标准文档
实体属性提取模型提取实体;根据提取结果,在标准文档中查找实体可能存在的引用标准;将数据构建成三元组并且存入数据库中;查询三元组并在页面可视化显示以供浏览、下载。
技术总结
本发明涉及一种自动构建试验标准知识图谱的方法,涉及试验标准规范审查技术领域,包括以下步骤:根据试验标准文档提取知识图谱概念,确定概念极其之间的关系;对现有的试验标准文档进行规范处理和BIO标注,得到标注数据集;使用标注数据集训练基于BERT BiLSTM CRF的神经网络模型,得到标准文档实体属性提取模型;将单个文档输入模型,经解码并进行实体属性抽取,得到该文档实体属性数据集;将提取的数据整理后形成三元组,存入MYSQL数据库中保存;构建试验标准知识图谱系统,利用ECHARTS可视化知识图谱。本发明能自动构建标准文档知识图谱,解决了试验标准文档中因文档相互引用不易查阅的问题,提高了相关工作人员查阅标准的效率。效率。效率。
技术研发人员:唐岳川 袁海 杨春明 张晖
受保护的技术使用者:西南科技大学
技术研发日:2022.08.31
技术公布日:2022/12/12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。