1.本发明涉及领域,尤其涉及一种北斗农机作业轨迹快速过滤分组方法。
背景技术:
2.高精度农机作业监测终端,为了运行稳定,都配备了内置电池供电,一般包含两种定位模式,分别是外置供电时采用高精度差分北斗定位和内置电池供电时普通北斗定位。农机作业过程中,机手基本上很难按作业规范要求,仅在地块作业期间开启北斗监测终端,所以,在传输回的平台的农机轨迹中,包含农机停机时的大量噪声轨迹,以及在作业地块之间转移时的道路行使轨迹等情况,这些多余的轨迹对于农机作业区域判断和作业面积的计算会带来很多的计算干扰。
3.而根据规划,在未来3-5年内,将北斗农机平台农机管理数量推广到100万台,届时按农忙作业季的高峰计算要求,平台需要至少每天能处理约10万台上的作业轨迹,因此对农机轨迹的快速过滤处理,是北斗农机管理自动化的一项重要处理技术。
技术实现要素:
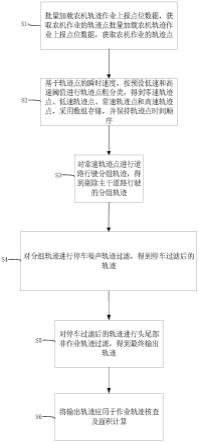
4.有鉴于此,针对现有农机作业轨迹面积计算的缺陷,如计算速度慢、非作业轨迹剔除效果差的问题,本发明供一种北斗农机作业轨迹快速过滤分组方法,具体包括以下步骤:
5.s1:批量加载农机轨迹作业上报点位数据,获取农机作业的轨迹点;
6.s2:基于轨迹点的瞬时速度,按预设低速和高速阈值进行轨迹点粗分类,得到零速轨迹点、低速轨迹点、常速轨迹点和高速轨迹点,采用数组存储,保持轨迹点时间顺序;
7.s3:对常速轨迹点进行道路行驶分组轨迹,得到剔除主干道路行驶的分组轨迹;
8.s4:对分组轨迹进行停车噪声轨迹过滤,得到停车过滤后的轨迹;
9.s5:对停车过滤后的轨迹进行头尾部非作业轨迹过滤,得到最终输出轨迹;
10.s6:将输出轨迹应用于作业轨迹核查及面积计算。
11.本发明提供的有益效果是:实现在不使用辅助数据的前提下,仅仅利用作业轨迹点上报的时间、经纬度和瞬时速度信息,以较小的计算量,对农机轨迹中的停车噪声轨迹、道路行使轨迹等进行剔除,并对最终作业轨迹进行分组,将分组后的轨迹提供给作业轨迹核查及面积计算等使用。
附图说明
12.图1是本发明方法流程示意图;
13.图2是正常加载20万农机轨迹点的轨迹连线实例图。
14.图3是农机轨迹点的轨迹连线局部放大的效果图。
15.图4是农机轨迹点经过速度分类提取的常速点分布图
16.图5是农机轨迹经过道路过滤分组后的效果图
17.图6是农机轨迹经过停车噪声轨迹过滤后的效果图
18.图7是农机轨迹经过轨迹头尾非作业轨迹过滤后的效果图。
具体实施方式
19.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述。
20.请参考图1,图1是本发明方法的流程图;本发明提供的一种北斗农机作业轨迹快速过滤分组方法,具体包括以下步骤:
21.s1:批量加载农机轨迹作业上报点位数据,获取农机作业的轨迹点;清参考图2-图3,图2是正常加载20万农机轨迹点的轨迹连线实例图,图3是农机轨迹点的轨迹连线局部放大的效果图。
22.s2:基于轨迹点的瞬时速度,按预设低速和高速阈值进行轨迹点粗分类,得到零速轨迹点、低速轨迹点、常速轨迹点和高速轨迹点,采用数组存储,保持轨迹点时间顺序;
23.请参考图4,图4是农机轨迹点经过速度分类提取的常速点分布图;
24.具体的,步骤s2的分类过程如下:
25.s21:根据对大量轨迹点的统计,设置低速域值v
min
和高速阈值v
max
,其中低速v
min
建议取值范围[0.2,0.5],默认值为0.2,高速v
max
建议取值范围[8.5,12],默认值为9.5,速度单位为km/h,依次对轨迹点进行瞬时速度比较,划定轨迹点分类。
[0026]
s22:对于轨迹点瞬时速度v=0的,归类到零速点组g
zero
,并保持各点的时间顺序。
[0027]
s23:对于轨迹点瞬时速度为v≤v
min
的,归类到低速点组g
low
,并保持各点的时间顺序。为减少计算量,低速点组不参与后续的计算,直接过滤掉。
[0028]
s24:对于轨迹点瞬时速度v≥v
min
且v≤v
max
的,归类到常速点组g
normal
,并保持各点的时间顺序。
[0029]
s25:对于轨迹点瞬时速度为v》v
max
的,归类到高速点组g
high
,并保持各点的时间顺序。为减少计算量,高速点组不参与后续的计算,直接过滤掉。
[0030]
因此,在后续计算过程中,只有常速轨迹点参与计算。
[0031]
s3:对常速轨迹点进行道路行驶分组轨迹,得到剔除主干道路的分组轨迹;请参考图5,图5是农机轨迹经过道路过滤分组后的效果图;
[0032]
需要说明的是,步骤s3中,所述道路行驶分组轨迹,包括三种分组方式,分别为:基于相邻点距离分组、基于时间间隔阈值分组和基于轨迹点周边点数量阈值分组。下面依次进行介绍。
[0033]
对常速轨迹点g
normal
进行道路行使轨迹剔除,实现分组轨迹;
[0034]
在具体实施时,可对分组轨迹中的轨迹点进行最小阈值设置,当然也可部设置,这里根据实际需求而定,本技术中,根据统计情况,在分组过程中,每个分组最少轨迹点数为ptnum
min
,默认值为30,对于轨迹点数量ptnumn《ptnum
min
,直接删除该组轨迹点。
[0035]
首先介绍基于相邻点距离分组:将常速轨迹点g
normal
进行相邻点空间距离阈值分割再分组。
[0036]
s311:计算轨迹点pn经纬度坐标(lonn,latn),在cgcs2000高斯投影坐标,取常速轨迹第一个点的经度lon1作为计算的中央经线,依次计算各轨迹点pn的高斯平面投影坐标(xn,yn)。
[0037]
s312:根据统计情况,设置同组内相邻点最大空间距离为d
max
,其中d
max
取值范围在上报频率为5秒时建议[70,200],默认值为80,单位为米。
[0038]
s313:通过轨迹点pn投影坐标(xn,yn)计算轨迹相邻点n空间距离dn。
[0039]
s314:依次对比计算,对于dn≥d
max
条件下,将点n设置新组g
new
起点,前一分组g
pre
,其点数量ptnum,执行步骤3.1判断,若不满足,就将分组g
pre
加入新的分组结果中;
[0040]
其次介绍基于时间间隔阈值分组:将分组轨迹点进行相邻点时间间隔阈值分割再分组;
[0041]
s321:根据统计情况,设置同组内相邻点最大时间间隔为δt
max
,δt
max
在实际统计数据中建议取值范围[600,7200],默认值为600,单位为秒,即10分钟到2小时。
[0042]
s322:计算轨迹相邻点n时间间隔δtn。
[0043]
s323:依次对比计算,对于δtn≥δt
max
条件下,将点n设置新组g
new
起点,前一分组g
pre
,其点数量ptnum,执行步骤3.1判断,若不满足,就将分组g
pre
加入新的分组结果中;
[0044]
最后介绍基于轨迹点周边点数量阈值分组:将分组轨迹点按相邻点数量进行阈值分割分组。
[0045]
s331:在分组轨迹gi中,设置以轨迹点pn(xn,yn)为中心,获取缓冲半径为d
buffer
的圆on,并求得该圆的外包矩形rn,统计该分组轨迹内,包含在矩形rn内的轨迹点数量
[0046]
s332:设置周边点数量分割阈值为默认值为5。
[0047]
s333:在条件下,将点n设置新组g
new
起点,前一分组g
pre
,其点数量ptnum
pre
,执行步骤3.2判断,若不满足,就将分组g
pre
加入新的分组结果中。
[0048]
s4:对分组轨迹进行停车噪声轨迹过滤,得到停车过滤后的轨迹;请参考图6,图6是农机轨迹经过停车噪声轨迹过滤后的效果图;
[0049]
需要说明的是,步骤s4中,所述停车噪声轨迹过滤,采用轨迹平均方向变化值和轨迹内零速点数量两个指标形成组合判断,对停车噪声轨迹进行过滤。
[0050]
首先介绍轨迹平均方向变化值的求解过程:
[0051]
s411:将分组轨迹gi内轨迹点pn(xn,yn)和轨迹点p
n 1
(x
n 1
,y
n 1
),计算线段pnp
n 1
的方向角αn,αn属于[0~2π],计算线段pnp
n 1
和p
n 1
p
n 2
的方向变化角δαn;
[0052]
s412:轨迹线最后一个点的方向变化值δα
end
,直接赋值为倒数第二个点的方向变化值δα
end-1
;
[0053]
s413:计算该组gi平均方向变化值
[0054]
其次介绍轨迹内零速点数量的计算过程。所述轨迹内零速点数量计算过程如下:
[0055]
s421:获取分组轨迹gi内第一个轨迹点p1的时间t1,以及最后一个轨迹点p
end
的时间t
end
;
[0056]
s422:遍历零速点组g
zero
中的点pn,获取其时间tn;
[0057]
s423:当条件tn≥t1且tn≤t
end
时,分组gi的零速点数量zi自增1;
[0058]
s424:当条件tn》t
end
时,针对分组gi的零速点组g
zero
遍历结束;此时获得分组gi的零速点数量为zi。
[0059]
最后介绍两个指标组合判断的过程,在本发明实施例中,通过各组轨迹的零速点数量和方向平均变化值,进行作业轨迹停车噪声轨迹过滤;通过对停车噪声数据的统计分析,存在如下执行情况。
[0060]
s431:分组轨迹gi的平均方向变化值且该分组的零点数量zi》z
threshold1
,其中δα
threshold1
阈值设定范围为[1.15,2.2],默认值为1.2,z
threshold1
阈值设定范围为[40, ∞],默认值为50,则该组轨迹有大概率为停车噪声轨迹,将分组轨迹gi加入停车噪声轨迹集合{g
noise
}。
[0061]
s432:分组轨迹gi的平均方向变化值且该分组的零点数量zi》z
threshold2
,其中δα
threshold2
阈值设定范围为[0.92,δα
threshold1
],默认值为0.95,z
threshold2
阈值设定范围为[800, ∞],默认值为800,则该组轨迹有大概率为停车噪声轨迹,将分组轨迹gi加入停车噪声轨迹集合{g
noise
}。
[0062]
s433:分组轨迹gi的平均方向变化值且该分组的零点数量zi》z
threshold3
,其中δα
threshold3
阈值设定范围为[0.78,δα
threshold2
],默认值为0.8,z
threshold2
阈值设定范围为[1300, ∞],默认值为1500,则该组轨迹有非常大概率为停车噪声轨迹,将分组轨迹gi加入停车噪声轨迹集合{g
noise
}。
[0063]
作为一种拓展,分组轨迹gi的外包矩形,与步骤4.3.1、步骤4.3.2、步骤4.3.3三种情况下判定的高概率停车噪声轨迹外包矩形重叠度为βi,若βi达到预设值,且平均方向变化值其中δα
threshold4
阈值设定范围为0.62,δα
threshold3
],默认值为0.65,则该组轨迹有大概率为停车噪声轨迹,将分组轨迹gi加入停车噪声轨迹集合{g
noise
}。
[0064]
在实际执行过程中,为了筛选处最有可能的停车噪声轨迹,建议通过外包矩形重叠度的操作要重复执行1-2次。
[0065]
s5:对停车过滤后的轨迹进行头尾部非作业轨迹过滤,得到最终输出轨迹;请参考图7,图7是农机轨迹经过轨迹头尾非作业轨迹过滤后的效果图。
[0066]
步骤s5具体为:
[0067]
s51:分组轨迹gi中,设置以轨迹点pn(xn,yn)为中心,获取缓冲半径为d
buffer
的圆on,并求得该圆的外包矩形rn,统计该分组轨迹内,包含在矩形rn内的轨迹点数量
[0068]
s52:分组轨迹gi中,利用所有的轨迹点p1~p
end
,构建轨迹的多段线polylinei;
[0069]
s53:计算轨迹gi中各轨迹点的法线段与轨迹线polylinei的交点数量;
[0070]
需要说明的是,交点数量计算如下:
[0071]
s531:循环遍历轨迹gi中各轨迹点pn,获取轨迹点pn在步骤5.1计算的结果
[0072]
s532:当该点其中参考取值[15,50],默认值为20,则该点的法线段与轨迹线polylinei的交点数量赋值可以参考取固定值[10, ∞],默认值为100。
[0073]
s533:当该点时,则求取以pn为中点,长度为2*d
buffer
,垂直于pnp
n 1
线段的法线段normallinen。
[0074]
s534:通过空间相交运算,计算法线段normallinen和轨迹折线polylinei的交点数
量
[0075]
s54:根据交点数量过滤头部非作业轨迹;
[0076]
需要说明的是,过滤头部非作业轨迹具体过程如下:
[0077]
s541:对轨迹gi中各轨迹点从起点开始循环,并取得步骤5.3计算的交点数量
[0078]
s542:当时,其中的建议取值[4,5],默认值为4,则将该点标记为分组轨迹开始部分非作业点。
[0079]
s543:当时,则直接停止循环进入下一步。
[0080]
s55:根据交点数量过滤尾部非作业轨迹,输出最终作业轨迹。
[0081]
需要说明的是,过滤尾部非作业轨迹的具体过程如下:
[0082]
s551:对轨迹gi中各轨迹点从结束开始反向循环,并取得步骤5.3计算的交点数量
[0083]
s552:当时,则将该点标记为分组轨迹结束部分非作业点。
[0084]
s553:当时,则直接停止循环进入下一步。
[0085]
根据轨迹组gi中标记的非作业点,进行剔除,生成新的轨迹组
[0086]
s6:将输出轨迹应用于作业轨迹核查及面积计算。
[0087]
作为一种实施例,在步骤s1中,通过数据加载接口,批量加载农机轨迹作业上报点位数据,点位数据一般包含时间、经度、纬度、速度等信息,批量加载的轨迹点数量为20万个,上报频率为5秒;
[0088]
作为一种实施例,,基于轨迹点瞬时速度进行轨迹点粗分类,包括零速点、低速点、常速点和高速点,设定的低速阈值为0.2km/h,设定高速阈值为9.5km/h,保留零速轨迹点和常速即[0.2,9.5]之间的轨迹点,其他分类轨迹结果剔除掉。
[0089]
这里需要说明的是:零速点一般代表农机停车点,低速点和常速点一般代表农机作业轨迹点,高速点一般代表农机公里行使轨迹点,常规作业中,农机行使的时速小于10km/h,剔除低速点是减少不必要的计算量,剔除高速点,实际上是剔除公路行使轨迹点。
[0090]
在步骤s3中,对常速轨迹点进行道路行使轨迹剔除,实现轨迹分组;
[0091]
在步骤3中,设置相邻轨迹点的距离阈值为80米,通过高斯投影后,计算相邻轨迹点之间的距离,两点间如果大于80米,就将该点设置为轨迹分组的中断点,如是判断分组下去。对最终所有分组中,组内轨迹点数量小于30个点,就将该组轨迹删除。
[0092]
这需要说明的是:在步骤2中,删除的高速点,以及不同时间点开机的两轨迹点之间,距离大于阈值,通过判断进行分组,可以有效实现过滤道路轨迹点后的轨迹分组。
[0093]
在步骤3中,设置相邻两点的最大时间间隔为600秒,即10分钟。
[0094]
在实施例中,可依次利用三种分组方式依次遍历,即三种方式组合,逐级进行分组,也可单独选取分组,本技术中,依次遍历步骤3.1产生的分组结果,对各组轨迹,利用时间间隔判断,进行再分组,如是判断分组下去。同样,对最终所有分组中,组内轨迹点数量小
于30个点,就将该组轨迹删除。
[0095]
这需要说明的是:由于一次取得20万个轨迹点,轨迹点集合中包含多日多块地的作业轨迹,轨迹点间包含真实的停止作业间隔。
[0096]
在步骤3中,设定轨迹点相邻点统计半径为10米,对每个分组内的轨迹点,当其相邻点数量小于5个时,将该点置为该组轨迹的分割点,进行再分组,如是判断分组下去。同样,对最终所有分组中,组内轨迹点数量小于30个点,就将该组轨迹删除。
[0097]
这需要说明的是:由于道路上轨迹点,因各机手驾驶行为不同,会存在介于时速5~9.5km/h之间的情况,在基于相邻点距离和基于时间间隔过滤结果后,还可能会保留大量的道路轨迹,同一轨迹分组内,由于道路轨迹周边只会有非常少的相邻轨迹点,此方法正是利用此原理进行进一步剔除道路轨迹点。
[0098]
在步骤s4中,对分组轨迹进行停车噪声轨迹过滤;
[0099]
在轨迹平均方向变化值的计算中,通过计算各轨迹点与下一轨迹点的方向变化,计算各分组内轨迹点的方向变化平均值,单位为弧度值,数值范围为[0~π]。
[0100]
在零速点数量计算中,取得各组轨迹的起始和结束时间,在步骤2取得的零速点集中,通过比较时间值,统计各组轨迹内的零速点数量。
[0101]
在两个指标组合判断中,标记轨迹组中
①
零速点数量大于50且平均方向变化大于1.2,
②
零速点数量大于1500且平均方向变化大于0.8,
③
零速点数量大于900且平均方向变化大于0.95的三类轨迹分组,标记为高可能性停车噪声轨迹。
[0102]
在获得高可能性停车噪声轨迹后,对其他轨迹分组,平均方向变化大于0.65,并与高可能性停车噪声轨迹的外包矩形重叠度大于0.15的,同样标记为高可能性停车噪声轨迹。重复上述循环判断一次。
[0103]
删除标记为停车噪声轨迹组,生成新的轨迹分组。
[0104]
这需要说明的是:在农机停车时,因北斗定位终端的持续工作,会产生大量的零速轨迹点,并且因为北斗信号的多路径等效应,导致轨迹点会围绕停车点随机变化,从而使连续的轨迹非常凌乱,在实际的农机生成作业中,轨迹的平均方向变化值一般小于0.45,停车时平均方向变化值一般大于0.8。
[0105]
在步骤s5中,完成对分组轨迹进行头尾部非作业轨迹过滤;
[0106]
这需要说明的是:当完成步骤s1至步骤s4后,轨迹分组中的道路行使轨迹和停车噪声轨迹基本被消除,但是在轨迹进入地块作业和作业出地块之间,还存在少量的非作业轨迹,需要被过滤掉。
[0107]
在步骤s51中,在各轨迹组中,对每个轨迹点,统计周边10米范围内的临近轨迹点数量。
[0108]
在步骤s52中,将各组轨迹内的点,通过时间顺序构建轨迹线。
[0109]
在步骤s53中,将各组轨迹中的轨迹点,且轨迹点临近轨迹点数量小于20个,就构建该点为中心、长度为20米的法线段,将该法线段与自身轨迹线求得交点数量。对临近轨迹点数量大于20个,直接将交点数量设置为100。
[0110]
这需要说明的是:这一步中,由于计算交点是非常耗时的操作,所以通过临近轨迹点进行筛选,减少不必要的计算量,默认轨迹临近点多的,其交点直接赋值为一个常熟100。
[0111]
在步骤s54中,依次从每组轨迹的开始进行判断,当交点数量少于4个,就标记该点
为非作业点,待删除。当交点数量大于等于4个时,停止判断。
[0112]
在步骤s55)中,依次从每组轨迹的结束反向进行判断,当交点数量少于4个,就标记该点为非作业点,待删除。当交点数量大于等于4个时,停止判断。
[0113]
依次遍历每组轨迹,删除非作业点,生成新的轨迹分组。对最终所有分组中,组内轨迹点数量小于10个点,就将该组轨迹删除。输出最终所有轨迹组,作为最终过滤结果,供作业轨迹核查及面积计算等使用。
[0114]
本发明最明显的特点是利用空间点位坐标、时间和速度三个信息,有别于常规的空间聚类分析方法,仅利用基本的数量统计和矩形空间范围判断,以及非常少量的线段相交计算,可以快速实现复杂轨迹的快速过滤分组,通过测算,对于常规20万个点的农机轨迹,处理时间优于10秒。
[0115]
综合来看,本发明的有益效果是:本发明能够快速的将高精度北斗农机作业轨迹数据进行道路行驶轨迹、停车噪声轨迹和其他非作业轨迹的过滤剔除,并且处理的效果良好,减少了作业轨迹有效性核查和作业面积计算的效率,提高北斗农机管理平台的自动化管理能力。
[0116]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。