一种基于vit的多视角3d重建方法及系统
技术领域
1.本发明涉及3d视觉重建技术领域,尤其是涉及一种基于vit的多视角3d重建方法及系统。
背景技术:
2.多视角重建(multi-view stereo,mvs)是通过多视角的2d图片来达成高精度的 3d重建任务。mvs一般包含多个步骤,例如相机位姿确定,深度估计,深度图融合,和点云稠密重建等。其中核心步骤则是在已知相机参数的情况下,估计出每张图片的深度图,为后续的深度图融合以及点云稠密重建做准备。
3.许多传统算法通过匹配2d图像的低层特征,难以处理遮挡和光照等问题。近年来深度学习方法在多视角深度估计中占据了越来越重要的地位。
4.基于深度学习的mvs的主要步骤包括:特征抽取、代价矩阵构建(cost volumeformulation)以及代价矩阵学习(cost volume regularization)。其中,目前大多数的研究在于代价矩阵cost volume的构建和学习,而对于基于深度学习的mvs而言,能否抽取到鲁棒的特征表示是决定算法最终泛化性的最重要条件。
5.然而,绝大部分mvs算法都使用特征金字塔网络(feature pyramid network, fpn)来抽取特征,仍然很难在反光、弱纹理等情况下学到鲁棒的特征表示。
6.在计算机视觉领域,cnn已经成为视觉任务的主导模型。随后出现了越来越高效的结构,计算机视觉和自然语言处理越来越收敛到一起,使用transformer来完成视觉任务成为了一个新的研究方向,以降低结构的复杂性,探索可扩展性和训练效率。而视觉transformer(vision transformer,vit)的出现,将transformer 巧妙的应用于图像分类任务。
技术实现要素:
7.本发明的目的就是为了克服上述现有技术存在的缺陷而提供了一种基于vit 的多视角3d重建方法及系统,可提升了mvs中特征抽取的鲁棒性,尤其可在反光、弱纹理等情况下得到鲁棒的特征表示。
8.本发明的目的可以通过以下技术方案来实现:
9.根据本发明的第一方面,提供了一种基于vit的多视角3d重建方法,该方法包括以下步骤:
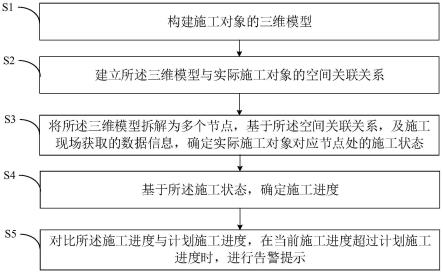
10.步骤s1、获取指定场景多视角2d图片以及对应的相机参数,并将其划分为训练集以及测试集;
11.步骤s2、从训练集中选取参考图片及其近邻作为源图片;构建融合vit与特征金字塔网络fpn的特征抽取模型,分别对参考图片及源图片进行特征抽取;
12.步骤s3、基于相机参数单应变化,将步骤s2中抽取到的源图片特征变换为源图片的位姿,构建代价矩阵,并基于分类损失函数,分层级优化不同层级的代价矩阵预测的深度
图;
13.步骤s4、采用动态多尺度策略对步骤s2~s3构建的基于vit的多视角重建 mvs模型进行训练;
14.步骤s5、从测试集中选取参考图片及对应的源图片,采用步骤s4预训练好的基于vit的多视角重建mvs模型,依次进行特征抽取、代价矩阵构建并学习,对深度图进行预测;并采用深度融合算法对预测得到的多视角深度图进行深度融合和点云重建。
15.优选地,所述步骤s1中的训练集为dtu数据集,测试集为tanks&temples 数据集;所述dtu数据集中的每张图片均配备有对应的深度图、相机内参和外参。
16.优选地,所述步骤s2包括以下子步骤:
17.步骤s21、从训练集中选择参考图片,并选取参考图的k张近邻图作为源图片;
18.步骤s22、对下采样后的参考图片和源图片分别进行vit特征提取和卷积神经网络cnn特征提取;其中,vit特征提取为基于mvsformer-p模型的单尺度vit 特征提取或基于mvsformer-h模型的多尺度vit特征提取,其对应输出的图像特征分别为f
(p)
和f
(h)
;采用卷积神经网络cnn提取的特征为f
(0)
;
19.步骤s23、在特征f
(0)
的基础上,叠加单尺度vit特征提取的特征f
(p)
或多尺度vit特征提取的特征f
(h)
,采用特征金字塔网络fpn融合得到多阶段特征f
(l)
。
20.优选地,所述步骤s2中的mvsformer-p模型包括基于自监督蒸馏的 transofrmer预训练dino模块和用于对dino模块输出的特征进行降维的注意力门控线性单元glu;
21.所述mvsformer-h模型包括基于多尺度注意力的transformer预训练twins 模块。
22.优选地,所述基于mvsformer-p模型的单尺度vit特征提取,其训练时固定其权重不训练;所述基于mvsformer-h模型的多尺度vit特征提取,训练时对mvsformer-h模型进行微调。
23.优选地,所述步骤s3中的包括以下子步骤:
24.1)初始化每个阶段模型的深度间隔其中,dj为候选平面j对应的图片深度;
25.2)将源图片的特征单应变化到参考视角下,变换表达式为:
[0026][0027]
式中,p为2d参考图片i0中的任一坐标点,p
′
为坐标点p点单应变换后的坐标点;k0,kj为相机内参,r0→i为旋转矩阵,t0→i为偏移向量,dj为图片深度;
[0028]
3)使用分组池化后的特征计算变换后的源特征与参考特征的相似度,得到对应的代价矩阵;其中,相似度计算表达式为:
[0029][0030]
其中,分别表示分组池化后的参考特征与源特征;
[0031]
4)对相似度使用2d cnn得到每个像素的权重并基于权重进行特征融合,表达式为:
[0032][0033]
式中,ci为相似度,wi为像素权重,dj为图片深度;
[0034]
5)将融合后的特征c输入至3d u-net,得到最终的输出特征
[0035]
6)使用交叉熵损失函数,分层级优化不同层级的代价矩阵预测的深度图,预测的深度图表达式为:
[0036][0037]
式中,dj为图片深度,为步骤5)得到的输出特征;d为候选的深度平面的数量。
[0038]
优选地,所述步骤s4具体为:使用基于梯度累计的动态batch结合动态分辨率训练,将大图片的输入分割为几个更小的子batch,并且累计各子batch的梯度结果,优化平均后的统一参数;其中,分辨率处于设定范围内,图片的高宽比从设定范围内随机选择。
[0039]
优选地,所述步骤s5中从测试集中选取参考图片及对应的源图片,采用按照步骤s2~s4预训练好的基于vit的多视角重建mvs模型,依次进行特征抽取、代价矩阵构建并学习,对深度图进行预测,具体包括以下子步骤:
[0040]
1)选择参考图片及源图片,采用步骤s2~s4预训练的多视角重建mvs模型,依次进行特征抽取、以及代价矩阵构建与学习;
[0041]
2)采用基于温度控制的深度估计算法预测最终的深度图,具体表达式为:
[0042][0043]
式中,softmax为归一化指数函数,t为温度系数,用于控制期望聚合程度;当t=1上式等价于回归期望,当t=∞上式等价于argmax;为步骤s3得到的输出特征;dj为图片深度。
[0044]
优选地,所述步骤s5中采用深度融合算法对预测得到的多视角深度图进行深度融合和点云重建,具体为:采用基于gipuma的深度融合算法对多视角深度图进行深度融合和点云重建,包括以下子步骤:
[0045]
1)获取每个视角的深度图后,以设定的置信度阈值对深度图进行过滤;
[0046]
2)根据参考视角的深度图d0将2d坐标点投影到3d空间,再根据目标视角的深度图di将其投影回来,计算重投影一致性系数;
[0047]
3)当重投影一致性系数小于设定值的视角达到设定数量时,保留该点云
[0048]
根据本发明的第二方面,提供了一种基于vit的多视角3d重建系统,采用任一项所述的方法,所述系统包括:
[0049]
特征抽取模块,用于采用融合vit与特征金字塔网络fpn的深度网络对图片进行特征抽取;
[0050]
代价矩阵模块,用于对抽取的特征进行单应变化,以及构建代价矩阵并分层级优化不同层级的代价矩阵预测的深度图;
[0051]
动态多尺度策略训练模块,用于特征抽取模块以及代价矩阵模块构建的多视角重建mvs模型进行动态多尺度训练;
[0052]
多视角3d重建模块,用于采用深度融合算法对预测得到的多视角深度图进行深度融合和点云重建。
[0053]
与现有技术相比,本发明具有以下优点:
[0054]
1)本发明提供一种基于vit的多视角3d重建方法,通过使用基于预训练的 vit来辅助进行特征编码和抽取,增强了2d特征的鲁棒性;
[0055]
2)采用高效的动态多尺度训练策略,加快了训练收敛;
[0056]
3)采用基于温度系数的深度估计方法,在得到精确深度估计结果的同时,保留可靠的置信度;
[0057]
4)本发明的方法在面对弱纹理和反光重建具有优势,并且在权威且具有挑战的3d重建数据集-tanks&temples数据集上获取了第一的成绩。
附图说明
[0058]
图1为本发明的深度图估计系统结构示意图;其中,图1(a)为特征抽取模块,图1(b)为代价矩阵模块;
[0059]
图2为多阶段深度估计中分类和回归结果示意图;其中,图2(a)为分类和回归多阶段置信度设置示意图;图2(b)为dtu scan77回归和分类结果示意图;
[0060]
图3为不同预训练模型对mvs深度估计结果示意图;其中,图3(a)~图3 (e)分别为baseline、baselin resnet50、mvsformer-p、mvsforemer-h和 ground-truth的深度估计结果示意图。
具体实施方式
[0061]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0062]
实施例
[0063]
步骤s1、获取指定场景多视角2d图片以及对应的相机参数,并将其划分为训练集以及测试集;
[0064]
其中,训练集采用dtu数据集,测试集采用tanks&temples数据集;
[0065]
dtu数据集:训练集包含79个场景,每个场景有49个不同角度,每个角度又有7种不同光照,即训练集共有27097张图片;测试集包含22个场景,每个场景有49个不同角度,每个角度又有7种不同光照,测试集则只使用最亮的一种光照,仅有1078张图片。每张图片均配备有对应的深度图和相机内参和外参。
[0066]
tanks&temples数据集:包括intermediate集和advanced集;其中,intermediate 集包括“family”,“francis”,“horse”,“lighthouse”,“m60”,“panther”,“playground”,“train”8个场景;advanced集包括“auditorium”,“ballroom”,“courtroom”,“museum”,“palace”,“temple”6个场景。每个场景有200~300张图片。每张图片没有对应的深度图。
[0067]
步骤s2、在训练集中分别选择1张图作为参考图,其4张近邻图作为源图,并且分别抽取其深度特征,具体为:
[0068]
1)分别选择1张图作为参考图片,4张近邻图作为源图片;
[0069]
源图挑选过程中尽可能挑选与参考图片角度差在5
°
左右的图片;其中,角度差通过相机外参计算所得;
[0070]
2)使用融合vit(vision transformer)和特征金字塔网络fpn的特征抽取模型对选取的参考图片和源图片进行特征抽取,如图1(a)所示,经过特征金字塔网络fpn后,得到4个阶段的图像特征
[0071]
vit(vision transformer)包括单尺度vit和多尺度vit;其中,单尺度vit 和多尺度vit分别使用基于自监督蒸馏的transofrmer预训练dino和基于多尺度注意力的transformer预训练twins作为预训练的vit,从而构建mvsformer-p和 mvsformer-h。
[0072]
对于mvsformer-p,输出特征为f(p);针对基于自监督蒸馏的transofrmer预训练dino,采用门控线性单元(gated linear unit,glu)进行特征降维,glu的计算过程如下:
[0073][0074]
式中,f
dino
表示dino输出的特征;a是dino的注意力特征,有g组,是 dino注意力特征拼接,对g组均值化;h、w代表图片的高和宽;convbn就是卷积 batchnorm层;swish表示激活函数swish(x)=x
·
sigmoid(x),
⊙
表示各元素相乘,[;]表示特征维度拼接,c
p
为降维后的特征;
[0075]
之后使用两层反卷积再进一步上采样特征后得到f
(p)
。
[0076]
对于mvsformer-h,输出特征为f
(h)
;由4层不同尺度的图像特征以特征金字塔网络fpn融合而成,其分辨率分别为图片原分辨率的(1/8,1/16,1/32,1/64),最终得到的f
(h)
可写为:
[0077][0078]
式中,h、w代表原图的高和宽;
[0079]
针对单尺度的vit占用显存较大的问题,通过固定其权重不训练的方式;而多尺度的vit由于占用显存较少,在训练的过程中同时微调mvsformer-h,以达到更好的效果。
[0080]
最终特征f
(0)
加上f
(p)
或f
(h)
,并进一步得到其他尺度的特征作为特征抽取的输出。
[0081]
步骤s3、基于相机参数单应变化,将步骤s2中抽取到的源图片特征变换为源图片的位姿,构建代价矩阵,并基于分类损失函数,分层级优化不同层级的代价矩阵预测的深度图;具体过程如下:
[0082]
1)对于每个阶段模型,初始化一组深度间隔
[0083]
此处省略了l层的上标以简化表述。
[0084]
2)将原图的特征单应变化到参考视角下;
[0085]
假设一个2d的参考图片i0中的一个坐标点p,已知相机内参k0,kj,旋转矩阵 r0→i和偏移向量t0→i,在深度为dj的平面上变化后的坐标点p
′
为:
[0086]
[0087]
3)使用分组池化后的特征来计算变换后的源特征与参考特征的相似度:
[0088][0089]
式中,分别表示分组池化后的参考特征与源特征。
[0090]
4)对相似度使用一组2d cnn得到每个像素的权重并基于权重融合特征,具体表达式为:
[0091][0092]
5)将融合后的结果将作为3d u-net的输入,并得到最终的输出
[0093]
6)使用分类损失,分层级优化不同层级的代价矩阵预测的深度图。
[0094]
分类损失使用交叉熵损失来优化最终的深度图,并通过argmax来得到最终的深度图输出,表达式为:
[0095][0096]
式中,dj为图片深度,为步骤s3得到的输出特征;d为候选的深度平面的数量。
[0097]
将深度估计视为一个d个深度平面的分类问题,每个像素从d个候选深度平面里选择一个目标类别进行分类。参考图2,这种方式能够获得更好的置信度,以过滤飞点。
[0098]
步骤s4、采用动态多尺度策略对mvs模型进行训练:
[0099]
vit模型对输入图片的分辨率很敏感,使用相同的分辨率训练会导致过拟合;而mvs的测试集一般都是不同的高分辨图片(1200x1600~1080x1920)。
[0100]
本发明动态地在使用分辨率范围为512~1280的图片进行训练,图片的高宽比从0.67~0.8随机选择;
[0101]
由于大的图片尺寸往往占用更多的显存,因此普通的动态尺寸训练需要以最大分辨率为基准,使用最小的batch来进行优化。但是,小的batch往往会造成优化的不稳定,收敛缓慢。
[0102]
本发明使用基于梯度累计的动态batch结合动态分辨率训练,以达成大batch 的优化,以及更快收敛的目的,具体过程为:通过将大图片输入分割为几个更小的子batch,累计各子batch的梯度结果,优化平均后的统一参数,以达到模拟大batch 优化的过程。
[0103]
步骤s5、从测试集中选取参考图片及对应的源图片,采用按照步骤s2~s3预训练好的基于vit的多视角重建mvs模型,依次进行特征抽取、代价矩阵构建并学习,对深度图进行预测;并采用深度融合算法对预测得到的多视角深度图进行深度融合和点云重建。
[0104]
与步骤s2~s3不同的是,本实施例中在dtu数据集中选取4张图片作为源图片,在tanks&temples数据集中,选取9张图片作为源图片;
[0105]
另一个不同点是,采用基于温度控制的深度估计算法对深度图进行预测,通过数学期望以获取更为精确的深度结果,兼顾了可靠的置信度;具体的深度估计表达式为:
[0106][0107]
式中,softmax为归一化指数函数,t为温度系数,用于控制期望聚合程度;当t=1上式等价于回归期望,当t=∞上式等价于argmax;为步骤s3得到的输出特征;dj为图片深度。
[0108]
在本实施例中,{t1,t2,t3,t4}={5,2.5,1.5,1}。即在早期的几个阶段,更倾向于分类,而在后期的几个阶段,更倾向于回归。
[0109]
本实施例中采用gipuma的深度融合方法对多视角深度图进行深度融合和点云生成,具体包括以下子步骤:
[0110]
1)以置信度阈值为0.5,对每个视角的深度图进行过滤;
[0111]
2)根据参考视角的深度图d0将2d坐标点投影到3d空间,再根据目标视角的深度图di将其投影回来,计算重投影一致度系数;
[0112]
3)当重投影一致度系数小于0.1的视角达到2个或以上,即可保留该点云;最终通过该深度融合方法得到目标点云。
[0113]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。