1.本发明涉及大数据挖掘领域,具体的,涉及一种政务服务流程优化方法、系统及电子设备。
背景技术:
2.现阶段主要通过人工的方式对群众需要办理的业务进行梳理,根据群众办理的业务推荐其他的相关业务,主要依靠的是工作人员的专业知识以及业务熟悉能力,受到工作人员的主观影响较大,并且人工很难对所有的相关的业务进行筛选。通过人工的方式效率较低,并且不能完全满足要求,如何能够针对大量的群众业务信息挖掘其中的关联信息,并为群众办理业务提供一个合理有效的流程方案是当前需要解决的问题。
技术实现要素:
3.本发明旨在克服上述现有技术的至少一种缺陷,提供一种政务服务流程优化方法、系统及电子设,用于优化政务的服务流程,提供一个有效合理的服务流程。
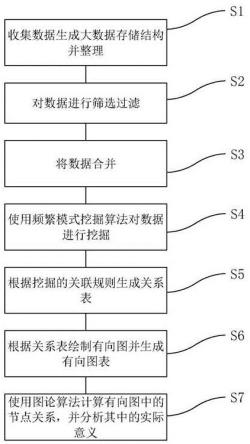
4.本发明采取的技术方案为:本发明提供一种政务服务流程优化方法,所述方法的步骤为:s1:收集业务数据并将业务数据形成大数据存储结构,然后对大数据存储结构中的业务数据进行整理;s2:对s1中的业务数据进行筛选过滤;s3:将s2中筛选后的业务数据进行合并;s4:挖掘合并后的业务数据的关联规则,并根据关联规则生成前件集合d1和后件集合d2;s5:将s4中获得的关联规则的前件集合d1和后件集合d2,计算其每个关联关系的笛卡尔积并生成二维表,将所有二维表纵向合并生成一张关系表;s6:根据s5中生成的关系表,以前件事项,后件事项为节点,前件事项指向后件事项为有向边,绘制事项关系有向图并生成事项关系有向图表;s7:使用图论的算法计算s6中事项关系有向图中各节点的关系,并分析其在实际业务流程中的应用。
5.由于政务的业务数据数量非常多,采用大数据存储结构来对业务数据进行存储,能够更好的存储业务数据,同时还能方便使用很多兼容大数据存储结构的数据整理工具来整理,提取和筛选符合要求的业务数据;然后对业务数据进行挖掘,挖掘业务数据之间的关联规则,从关联规则中可以简单的了解到各个业务数据之间的关联,这就可以简单反映出各个业务数据与其他业务数据的关联性,这些业务数据可以同时向群众推荐办理;在获得关联规则之后根据关联规则绘制有向图表,然后使用图论算法进行计算,可以直观的了解到业务之间的实际的物理意义,即业务的优先级,强关联性。通过对数据的挖掘分析,使业务之间到的关联关系更加直接清晰,可以根据分析结果对政务的办理进行更好的优化,提
高政务业务的办理效率。
6.进一步的,所述步骤s1中的收集业务数据并将业务数据形成大数据存储结构,具体为:使用hive收集业务数据并将业务数据存储到hdfs中。
7.hive是一套基于hadoop构建的仓库管理工具,能够很好的兼容大数据存储结构,提供了丰富的sql的方式对hadoop分布式文件系统(dfs)进行整理查询,同时能够使用大数据分析引擎中的库来对数据进行分析,所以使用hive来收集业务数据,并将数据收集存储在hdfs中,能够方便使用相应的工具来对数据进行整理和分析。
8.进一步的,所述步骤s1中的对大数据存储结构中业务数据进行整理,具体为:根据“办事人类型”将数据分为“个人办事记录”和“企业办事记录”;所述“个人办事记录”以个人身份证号作为个人主码;所述“企业办事记录”以企业代码作为企业主码;分别生成对应的“个人办事记录表”和“企业办事记录表”,分别记录所有个人主码和企业主码的“办理事项”以及对应的“办理时间”。
9.在政务办理业务中主要分为两类,即个人业务与企业业务,所以在分析时也将办事人类型分为“个人办事记录”和“企业办事记录”,并对应生成个人主码和企业主码,用于根据主码建立对应的“个人办事记录表”和“企业办事记录表”两个数据集,生成数据集后可以对数据进行更好的管理。
10.进一步的,所述步骤s2中的对业务数据进行筛选过滤,具体为:将s1中的业务数据以主码聚合统计每个主码在时间窗口内的“办理事项”及对应的“办理时间”,删除其中“办理事项”项数不大于1的业务数据;所述时间窗口为截止至当前时间点,近一年之内的时间段。
11.关联规则是对两事项之间关联性的描述。如果一个人在时间窗口内的办件次数小于等于1,则无法在该个体上讨论事项之间的关联性。该用户的办事记录对于之后的频繁模式挖掘没有贡献,提前删除可提高后续算法的计算效率。
12.进一步的,所述步骤s3中将业务数据合并,具体为:将s2中经过主码聚合后的数据以主码为单位,将每个主码的“办理事项”合并为事项集。
13.以数据集中的主码为关键词,使用hive中的group by进行分组,并使用collect_set()函数将同一分组中的“办理事项”的业务记录聚集成一个事项集。
14.进一步的,所述步骤s4中挖掘合并后的业务数据的关联规则,并根据关联规则生成前件集合d1和后件集合d2,具体为:使用spark中的mllib库的fp-growth频繁模式挖掘算法挖掘业务数据的关联规则,并根据关联规则生成关联规则表;所述关联规则表记录各关联规则的前件集合d1,后件集合d2,置信度和提升度。
15.进一步的,设置fp-growth频繁模式挖掘的最小支持度为0.002,最小置信度为0.5。
16.spark计算引擎和hive都以hdfs作为存储基础,所以可以直接使用mllib库中的fp-growth频繁模式挖掘,来挖掘业务数据之间的关联规则,设置最小支持度为0.002,最小
置信度为0.5,即在挖掘分析过程中,将支持度小于0.002或执行度小于0.5的事项关系筛除,提取具有更高关联度的事项其中最小支持度和最小置信度的设置为根据实际情况设置,该实际情况为收集数据的地区或时间以及其他影响数据量及内容的因素;此关联规则描述了几个业务事项之间的相关关系,具体可以理解为,办理了前项集合d1中的业务后,基于置信度作为百分比概率办理后项集合d2中的业务。可以直观的了解到业务之间的关系并以此来为群众推荐相关业务的办理。
17.进一步的,所述s7中使用图论的算法计算s6中事项关系有向图中各节点的关系,具体为:使用sparkgraphx中的pagerank算法,计算s6中事项关系有向图表中每个节点的中心值;使用sparkgraphx中的强连通分量算法,计算s6中事项关系有向图表中各个节点的强连通分量;使用neo4j中的louvain模块化算法,计算s6中事项关系有向图表中的聚集社区。
18.具体的,使用pagerank算法计算得到每个节点的中心值,可以根据该中心值来表现每个节点所代表的业务事项的影响度,即中心值较高对应事项具有更高的影响度,那么相应的该事项对应的业务对其他业务的影响较大,需重点关注优化;使用强连通分量算法,获得各节点之间的强连通分量,强连通分量中的各个节点具有更高的相关性,在业务办理时可以同时办理;使用neo4j的louvain算法,获得有向图中的聚集社区,具体为,通过调整louvain模块化算法的训练“轮数”超参数,通过调整训练的“轮数”,可以调整聚集社区的粒度,即密集度,然后结合专业的知识,选择合适粒度下的聚集社区,由于相同聚集社区下的业务事项节点具有更高的相似度,所以可以将其设定到同一实际场景下一同办理。
19.本发明还提供一种政务服务系统,基于上述优化方法,包括:数据采集模块,数据存储模块,数据分析模块;所述数据采集模块用于对业务数据进行采集;所述数据存储模块用于生成大数据存储结构,并将数据采集模块中的数据进行存储;所述数据分析模块用于对数据存储模块中的业务数据进行分析。
20.所述数据采集模块能够采集历史上足够多的政务业务数据,还能收集实时更新的业务数据,并将数据存储到数据存储模块中,所述数据存储模块中设置有大数据引擎单元,采用现有技术的大数据框架,优选的为spark框架;还设置有图计算单元,采用现有的图论算法对数据进行分析;所述数据分析模块采用数据仓库工具,优选的为hive数据仓库工具,对业务数据使用频繁挖掘以及图论分析,并生成相应的分析结果。
21.本发明还提供一种电子设备,包括:处理器以及存储器;所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器时上述一种政务服务流程优化方法或一种政务服务系统。
22.与现有技术相比,本发明的有益效果为:提供一种政务流程优化方法,通过对业务数据进行收集,并使用频繁挖掘方式和图论分析,获得业务事项的相关性规则,根据该相关性规则来调整和优化政务服务的流程,简化政务服务流程,提高政务办事效率,合理的为人
民群众解决办事问题,提高人民群众的满意度。
附图说明
23.图1为本发明的政务服务流程优化方法的步骤图。
具体实施方式
24.本发明附图仅用于示例性说明,不能理解为对本发明的限制。为了更好说明以下实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
25.实施例1本实施例提供一种政务服务流程优化方法,如图1所示,该优化方法的具体步骤包括:s1:收集业务数据并将业务数据形成大数据存储结构,然后对大数据存储结构中的业务数据进行整理;具体的为使用hive收集足够多的业务数据存储到hdfs中,由于hive为数据仓库工具,并且其基于hadoop,所以能够对大数据存储结构中的数据进行管理,并且使用大数据框架下的库,方便对数据的整理和分析;在具体的实施过程中,使用hive对数据进行收集,收集近一年之内的所有政务的办事记录数据,收集数据的时间段根据实际情况具体设定,该实际情况包括收集数据的地区等会影响数据数量及数据内容的因素,将数据存储到hdfs,然后根据办事人的类型,把数据分为“个人办事记录”和“企业办事记录”,并分别形成个人主码和企业主码,以个人身份证号作为个人主码,以企业代码作为企业主码,使用个人主码和企业主码分别建立对应的索引表,记录主码对应的“办理事项”及办理事项的“办理时间”,分别形成“个人办事记录表”和“企业办事记录表”两个数据集,具体的办事记录表形式示例如下:上表为个人办事记录表的部分内容,企业办事记录表内容类似,使用主码聚合,然后将该记录表的内容进行筛选,由于本实施例收集的为近一年之内的办理记录数据,可能会出现在一年之内,某人只办理过一次政务业务,但是仍然会有数据记录,所以将这些少量数据筛选出去,删除同一主码下,办事记录少于或等于1的数据记录,因为只有一项记录所以不能与其他记录进行后续的关联分析,所以将其删除,减少数据量,减少干扰,提高了后续算法的计算效率。
26.在对数据筛选完毕之后,将使用hive的group by将主码进行分组,同一主码分为一组,并使用collect_set()函数将同一主码下的“办理事项”中的数据聚集成一个事项集,具体的形式示例如下:合并事项集之后,使用spark中的mllib库的fp-growth频发模式挖掘算法挖掘事项集中的业务数据的关联规则,具体的,设置fp-growth频发模式挖掘算法的最小支持度为0.002,最小置信度为0.5,即将支持度小于0.002或置信度小于0.5的数据删除,进一步去除冗余数据,提高算法的计算效率,同时能够提取更高关联度的数据,其中最小支持度和最小置信度的设置为根据实际情况设置,该实际情况为收集数据的地区或时间以及其他影响数据量及内容的因素;使用fp-growth进行数据挖掘之后,将事项集分为前件集合d1和后件集合d2,并获得前件集合d1和后件集合d2各个业务之间的关联规则,具体示例如下:根据上表的内容可以理解为:办理了“人才入户准入资格”和“租房提取(住房公积金)”事项的人,73.5%(置信度)的概率还办理了“市外迁入-人才引进”事项,通过置信度了解到,前件事项和后件事项之间事项的关联度,在具体实施过程中,当群众办理前件事项中的业务时,可以同时推荐其办理对应具有高置信度的后件事项的业务,方便用户的办理,减少多次办理的情况。
27.然后根据前件集合d1和后件集合d2绘制有向图标表,具体的,计算前件集合d1和后件集合d2中每个关联关系的笛卡尔积,并生成二维表,然后将所有的二维表纵向合并生成一张关系表,以关系表中的前件事项和后件事项为节点,以前件事项指向后件事项为有向边,绘制事项关系有向图并生成事项关系有向图表。
28.对有向图表中的有向图使用图论算法进行分析。具体的,使用pagerank算法计算得到每个节点的中心值,可以根据该中心值来表现每个节点所代表的业务事项的影响度,即中心值较高对应事项具有更高的影响度,那么相应的该事项对应的业务对其他业务的影响较大,在业务流程上,对于这些具有更大影响力的业务可以进行办理流程的优化,如开设快捷办理通道方便其业务的办理,并优化与其相关的业务的办理过程;使用强连通分量算法,获得各节点之间的强连通分量,强连通分量中的各个节点互相具有相关性,在具体实施
过程中,在业务办理时可以打包同时办理;使用neo4j的louvain算法,获得有向图中的聚集社区,具体为,通过调整louvain模块化算法的训练“轮数”超参数,通过调整训练的“轮数”,可以调整聚集社区的粒度,即密集度,然后结合专业的知识,选择合适粒度下的聚集社区,由于相同聚集社区下的业务事项节点具有更高的相似度,所以可以将其设定到同一实际场景下一同办理,在具体的实施过程中,将相同聚集社区下的业务事项整合成为一个办理业务,例如,假设事项a与事项b在同一聚集社区下,可以考虑a、b两事项组合后是否是一种新的场景需求,如果是,则可将a、b事项场景化整合办理。
29.实施例2本实施例提供了一种政务服务系统,基于实施例1中的优化方法,具体包括:数据采集模块,数据存储模块,数据分析模块;所述数据采集模块用于对业务数据进行采集,具体的,使用hive工具来对数据进行收集,收集历史上足够长的时间内的业务数据,可以根据内容具体设置;还可以实时收集最新办理的业务数据,因为社会生活在不断的变化,每天都会有新的政务业务办理,不断的在有新的政务业务推出,将这些数据一并收集能够更好的优化政务的服务流程,提高政务的业务的办理效率。
30.所述数据存储模块用于生成大数据存储结构,并将数据采集模块中的数据进行存储,具体的,该存储结构能够使用hive提供的数据进行管理,能够很好的对数据进行整理;所述数据分析模块用于对数据存储模块中的业务数据进行分析,具体的,数据分析模块设置有大数据引擎单元与图计算单元,大数据引擎单元采用spark框架,可以使用spark中mllib库的fp-growth频繁模式挖掘算法对数据存储模块中的业务数据进行关联性挖掘,并生成有向图;图计算单元对大数据引擎单元生成的有向图采用pagerank算法,强连通分量算法以及louvain模块化算法进行计算,分别计算各节点的中心值,节点之间的强连通关系以及聚集社区,并将其输出。
31.实施例3本实施例提供一种电子设备,包括:处理器以及存储器;所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器时上述实施例1中的一种政务服务流程优化方法或实施例2中的一种政务服务系统。
32.显然,本发明的上述实施例仅仅是为清楚地说明本发明技术方案所作的举例,而并非是对本发明的具体实施方式的限定。凡在本发明权利要求书的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
