1.本发明涉及数据处理技术领域,特别涉及一种全文检索的方法及系统。
背景技术:
2.在当前项目中,云文档存储的文件数据可分为两部分:结构化数据和非结构化数据。
3.其中,结构化数据部分包括所有者、所在的用户组、文件的大小、文件的类型和文件的md5值等。针对这部分是已实现搜索,当前使用postgresql数据库进行管理。
4.至于非结构化数据,这里特指各种文档的内容,比如doc、pdf、text等格式的文档中的文本内容。针对非结构化数据,由于关系型数据库(rdbms)底层结构的缘故使得它管理大量非结构化数据显得有些先天不足,特别是查询这些海量非结构化数据的速度较慢。所以,当前项目中,未支持对文档内容的检索。
技术实现要素:
5.本发明所要解决的技术问题是:提供一种全文检索的方法及系统,实现对非结构化数据的全文检索。
6.为了解决上述技术问题,本发明采用的技术方案为:
7.一种全文检索的方法,包括步骤:
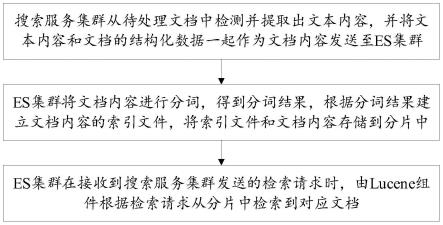
8.搜索服务集群从待处理文档中检测并提取出文本内容,并将所述文本内容和所述文档的结构化数据一起作为文档内容发送至es集群;
9.es集群将所述文档内容进行分词,得到分词结果,根据所述分词结果建立所述文档内容的索引文件,将所述索引文件和所述文档内容存储到分片中;
10.es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据所述检索请求从所述分片中检索到对应文档。
11.为了解决上述技术问题,本发明采用的另一种技术方案为:
12.一种全文检索的系统,包括:
13.搜索服务集群,用于从待处理文档中检测并提取出文本内容,并将所述文本内容和所述文档的结构化数据一起作为文档内容发送至es集群;
14.es集群,用于将所述文档内容进行分词,得到分词结果,根据所述分词结果建立所述文档内容的索引文件,将所述索引文件和所述文档内容存储到分片中;用于在接收到搜索服务集群发送的检索请求时,由lucene组件根据所述检索请求从所述分片中检索到对应文档。
15.本发明的有益效果在于:一种全文检索的方法及系统,由搜索服务集群从待处理文档中检测并提取出文本内容,并将文本内容和文档的结构化数据一起作为文档内容发送至es集群,es集群将文档内容进行分词、建立索引以及存储到分片之后。当用户发起检索时,es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据检索请求从分片
中检索到对应文档,实现了对非结构化数据的全文检索,从而使得用户可以在线对文档的文本内容进行全文检索,提高用户体验。
附图说明
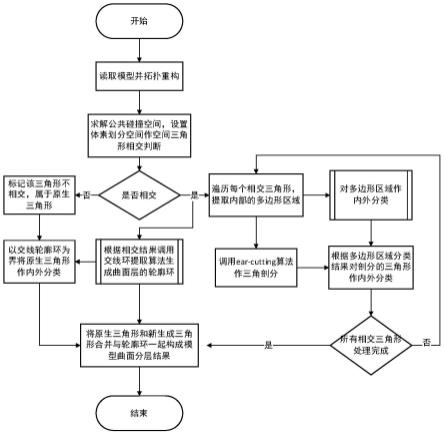
16.图1为本发明实施例的一种全文检索的方法的流程示意图;
17.图2为本发明实施例的一种全文检索的系统的架构示意图;
18.图3为本发明实施例的一种全文检索的系统集成到云文档之后的架构示意图。
19.图4为本发明实施例涉及的manageweb与search的关系示意图;
20.图5为本发明实施例涉及的docengine调用search的关系示意图;
21.图6为本发明实施例涉及的search调用docengine的关系示意图。
具体实施方式
22.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
23.在本发明中涉及到的缩略语和关键术语定义如下表1:
24.表1.缩略语和关键术语定义
[0025][0026]
请参照图1,一种全文检索的方法,包括步骤:
[0027]
搜索服务集群从待处理文档中检测并提取出文本内容,并将所述文本内容和所述文档的结构化数据一起作为文档内容发送至es集群;
[0028]
es集群将所述文档内容进行分词,得到分词结果,根据所述分词结果建立所述文档内容的索引文件,将所述索引文件和所述文档内容存储到分片中;
[0029]
es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据所述检索请
求从所述分片中检索到对应文档。
[0030]
从上述描述可知,本发明的有益效果在于:由搜索服务集群从待处理文档中检测并提取出文本内容,并将文本内容和文档的结构化数据一起作为文档内容发送至es集群,es集群将文档内容进行分词、建立索引以及存储到分片之后。当用户发起检索时,es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据检索请求从分片中检索到对应文档,实现了对非结构化数据的全文检索,从而使得用户可以在线对文档的文本内容进行全文检索,提高用户体验。
[0031]
进一步地,还包括以下步骤:
[0032]
nginx服务器通过负载均衡技术将用户请求分发至搜索服务集群中的搜索服务器上,所述搜索服务集群包括至少两个搜索服务器。
[0033]
从上述描述可知,nginx服务器通过负载均衡技术将用户请求进行分发,从而减轻了各个服务器的压力。
[0034]
进一步地,所述将所述索引文件和所述文档内容存储到分片中具体为:
[0035]
将所述索引文件和所述文档内容分布式存储分片上,所述es集群包括有至少两个es节点,每一个es节点上至少包括一个主分片和一个副分片。
[0036]
从上述描述可知,es的分片机制保证了索引的高可用,也实现了索引的分布式存储和分布式搜索,es的集群化,提供了高性能的搜索。
[0037]
进一步地,所述es集群将所述文档内容进行分词具体为:
[0038]
所述es集群通过集成的ik中文分词器将所述文档内容进行分词。
[0039]
从上述描述可知,es的标准分词器(standard analyzer)对中文的支持不友好,集成ik中文分词器,可以更好的处理中文文本,以达到更好的分词效果。
[0040]
进一步地,所述搜索服务集群中的搜索服务器和所述es集群中的es节点均采用docker容器化部署。
[0041]
从上述描述可知,本发明采用了docker容器化技术,整体作为一个子系统,可以稍微做少量的修改就能嵌套到其他项目中,可移植性强。
[0042]
请参照图2至图6,一种全文检索的系统,包括:
[0043]
搜索服务集群,用于从待处理文档中检测并提取出文本内容,并将所述文本内容和所述文档的结构化数据一起作为文档内容发送至es集群;
[0044]
es集群,用于将所述文档内容进行分词,得到分词结果,根据所述分词结果建立所述文档内容的索引文件,将所述索引文件和所述文档内容存储到分片中;用于在接收到搜索服务集群发送的检索请求时,由lucene组件根据所述检索请求从所述分片中检索到对应文档。
[0045]
从上述描述可知,本发明的有益效果在于:由搜索服务集群从待处理文档中检测并提取出文本内容,并将文本内容和文档的结构化数据一起作为文档内容发送至es集群,es集群将文档内容进行分词、建立索引以及存储到分片之后。当用户发起检索时,es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据检索请求从分片中检索到对应文档,实现了对非结构化数据的全文检索,从而使得用户可以在线对文档的文本内容进行全文检索,提高用户体验。
[0046]
进一步地,还包括nginx服务器,所述搜索服务集群包括至少两个搜索服务器;
[0047]
所述nginx服务器,用于通过负载均衡技术将用户请求分发至搜索服务集群中的搜索服务器上。
[0048]
从上述描述可知,nginx服务器通过负载均衡技术将用户请求进行分发,从而减轻了各个服务器的压力。
[0049]
进一步地,所述es集群包括有至少两个es节点,每一个es节点上至少包括一个主分片和一个副分片;
[0050]
所述es集群,用于将所述索引文件和所述文档内容分布式存储分片上。
[0051]
从上述描述可知,es的分片机制保证了索引的高可用,也实现了索引的分布式存储和分布式搜索,es的集群化,提供了高性能的搜索。
[0052]
进一步地,所述es集群集成有ik中文分词器;
[0053]
所述ik中文分词器,用于将所述文档内容进行分词。
[0054]
从上述描述可知,es的标准分词器(standard analyzer)对中文的支持不友好,集成ik中文分词器,可以更好的处理中文文本,以达到更好的分词效果。
[0055]
进一步地,所述搜索服务集群中的搜索服务器和所述es集群中的es节点均采用docker容器化部署。
[0056]
从上述描述可知,本发明采用了docker容器化技术,整体作为一个子系统,可以稍微做少量的修改就能嵌套到其他项目中,可移植性强。
[0057]
本发明的一种全文检索的方法及系统能够适用需要全文检索的场景,以下通过具体的实施方式进行说明:
[0058]
请参照图1,本发明的实施例一为:
[0059]
一种全文检索的方法,包括步骤:
[0060]
s1、nginx服务器通过负载均衡技术将用户请求分发至搜索服务集群中的搜索服务器上,搜索服务集群包括至少两个搜索服务器。
[0061]
即本实施例采用nginx服务器作为文档系统的入口,既承担着代理服务器的作用,还提供了负载均衡技术,采用负载均衡采用轮询策略,将用户的请求分发到后端的搜索服务集群(search service cluster),减轻了各个服务器的压力。
[0062]
s2、搜索服务集群从待处理文档中检测并提取出文本内容,并将文本内容和文档的结构化数据一起作为文档内容发送至es集群;
[0063]
其中,全文检索可以分为索引和搜索,其中索引步骤包含:文档预处理,分词,创建索引。文档预处理功能由搜索服务集群提供,即步骤s2,分词、创建索引和搜索由es集群(es db cluster)提供,即步骤s3至步骤s4。
[0064]
对于步骤s2来说,搜索服务是核心组件,是一个java应用程序,采用docker容器化部署。
[0065]
其主要功能有两点:
[0066]
一是文档预处理功能,提供解析文档功能,由tika组件来实现,将文档中的文本内容检测并提取出来,并将文本内容和文档的结构化数据一起存储到es集群中。其中,文档的结构化数据包括所有者、所在的用户组、文件的大小、文件的类型和文件的md5值(md5 message-digest algorithm,一种被广泛使用的密码散列函数)等。
[0067]
二是对外部提供全文检索功能,通过查询es集群实现。
[0068]
s3、es集群将文档内容进行分词,得到分词结果,根据分词结果建立文档内容的索引文件,将索引文件和文档内容存储到分片中;
[0069]
其中,分词即为把全文本转换一系列词的过程,它是全文检索功能的重要组成部分。在本实施例中,es集群将文档内容进行分词具体为:
[0070]
es集群通过集成的ik中文分词器将文档内容进行分词。
[0071]
由此,由于es的标准分词器(standard analyzer)对中文的支持不友好,集成ik中文分词器,可以更好的处理中文文本。
[0072]
在本实施例中,将索引文件和文档内容存储到分片中具体为:
[0073]
将索引文件和文档内容分布式存储分片上,es集群包括有至少两个es节点,每一个es节点上至少包括一个主分片和一个副分片。
[0074]
具体而言,es集群的索引数据结构采用的是lucene倒排序索引。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
[0075]
举个例子,用户搜索的时候先找到关键词,也就找到了含有该关键词的相关文章。其中,分词是索引步骤中的第一步。分片是索引步骤中的第三步建立索引中相关的概念,在添加数据时需要用到索引。索引是保存相关数据的地方,它实际上是指向一个或者多个物理分片的逻辑命名空间,而其中一个分片是一个底层的工作单元它仅保存了全部数据中的一部分。
[0076]
一个分片(shard)是一个lucene的实例,它本身就是一个完整的搜索引擎。文档内容被存储和索引到分片内。一个分片可以是主分片或者副分片。分片机制实现了分布式存储,分布式检索的功能,分片的副本机制实现了横向动态扩容的功能。
[0077]
es集群是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时,es会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
[0078]
结合图2可知,在本实施例中,索引的分片设置采用三主(primary shard)三副(replica shard),三主在图2中表示为主分片1、主分片2和主分片3,三副在图2中表示为副分片1、副分片2和副分片3。es集群的分片机制保证了索引的高可用,也实现了索引的分布式存储和分布式搜索。
[0079]
结合图2可知,es集群采用小规模集群,三节点模式,一主节点(master node)两从节点(slave node),它们都是数据节点(data node),都设置为备选主节点(backup node),都可以参与选举,实现节点的高可用。
[0080]
s4、es集群在接收到搜索服务集群发送的检索请求时,由lucene组件根据检索请求从分片中检索到对应文档。
[0081]
在本实施例中,es集群中的es节点也采用docker容器化部署。
[0082]
请参照图2至图6,本发明的实施例二为:
[0083]
一种全文检索的系统,包括种全文检索的系统,包括搜索服务集群、es集群和nginx服务器,其各自实现的步骤参照实施例一种均可。
[0084]
如图3至图6,本实施例中,以一种全文检索的系统应用到云文档中进行进一步的说明如下:
[0085]
其中,云文档(clouddoc-server)是基于vip(very important person,重要人物)
的keepalived高可用集群架构,外部访问都是通过vip。vip在云文档角色服务器一和云文档角色服务二之间漂移。
[0086]
如图3所示,一种全文检索的系统对应到云文档中具体有:2个搜索服务器(图中以search表示)、2个nginx服务器(图中以nginx负载均衡表示)以及包括3个es节点(图中以es slave表示)的es集群,其中,3个es节点为一主两从。搜索服务器和es节点都是采用docker容器化部署。
[0087]
在本实施例中,一种全文检索的系统所对应的三个组件与其他的组件之间的关系,对原有的云文档组件之间关系不描述,且图3至图6以及后续说明中涉及到原有的云文档组件adminweb、manageweb、docengine,docupdate、auth、license、hodoop、postgresql以及redis均参照现有定义即可。
[0088]
1)search组件与其他组件的关系:
[0089]
如图4所示,search组件与manageweb组件的关系为:search组件作为具体的业务处理服务,对manageweb提供全文检索服务相关的接口,目前已经提供了如下的接口:个人文档搜索,群组文档搜索,共享文档搜索。
[0090]
如图5和6所示,search组件与docengine组件的关系为:docengine组件作为云文档中处理云文档的核心组件。search组件与docengine组件的关系为互相调用。在创建文档解析任务时两者的具体时序图如图5所示,docengine组件将带解析的文档的标识提交到search组件,search组件再创建解析任务,并创建完后返回结果给docengine。在执行文档解析任务时时两者的具体时序图如图6所示,由此,docengine组件需要实现指定的方法供search组件调用,具体为2个方法,一个获取文件信息的,另一个是获取文件流。
[0091]
2)es组件与其他组件的关系:
[0092]
es组件作为搜索引擎数据库,只与search组件存在关系,只能被search组件调用。
[0093]
即本实施例至少需要3台服务器,其中两台服务器需要部署keepalived,用来实现基于vip的keepalived服务集群的高可用,并且这两台服务器需要部署nginx,用来实现服务的负载均衡。
[0094]
其中adminweb、manageweb、docengine,docupdate、auth、license、search服务,服务都是采用双活实现高可用,部署模式都是采用docker容器化部署。
[0095]
postgresql和redis不采用容器化部署,都采用一主一备的高可用模式。
[0096]
hadoop采用一主两从的集群模式,来实现高可用,并且也采用容器化部署。
[0097]
es集群采用一主两从的集群模式,实现节点的高可用,es的索引采用三主分片三副本分片来实现索引的高可用,并且也采用容器化部署,具体可得表2。
[0098]
表2云文档部署方案
[0099]
[0100][0101]
综上所述,本发明提供的一种全文检索的方法及系统,实现了对非结构化数据的全文检索,从而使得用户可以在线对文档的文本内容进行全文检索,提高用户体验,且具有高可用性,高搜索性能以及强可移植性。
[0102]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。