1.本发明新型属于工业故障诊断技术领域,具体涉及一种多变量加权集成学习的工业故障诊断方法。
背景技术:
2.工业设备的健康运行在工业过程中具有重要意义。设备故障给企业带来了难以置信的经济损失和不必要的停机时间。企业通常对设备运行的连续性和稳定性有严格的要求。因此,故障诊断是监控工业设备运行的一项重要任务。随着大数据的出现,探索监测数据用于工业故障诊断的热点话题。
3.传统的机器学习方法已被广泛研究用于工业故障诊断,例如决策树、神经网络和支持向量机。深度学习方法,例如卷积神经网络、深度神经网络和深度信念网络,已成功应用于工业故障诊断。尽管这些方法取得了不错的成绩,但仍然存在一些缺点。传统方法的性能在很大程度上受限于监测数据的特征提取。工业过程是一个高度复杂的动态非线性系统, 不同故障模式下的监测数据表现出更多的模糊性、不确定性和高维性。因此,单一的传统或深度模型往往无法完美地识别出如此复杂的工业故障。也就是说,来自单个模型的诊断结果通常不可靠且不稳定。
4.如今,结合几种不同学习算法的集成学习被认为是工业故障诊断的一个有前途的趋势。投票方法通常用于集成学习,例如多数投票和加权投票。多数投票没有考虑各种诊断信息的显着性差异,从而阻碍了其诊断性能。加权投票的关键是如何设计权重。在加权投票方法中,权重是通过使用各种技巧来设计的,但有一个严重的缺点。每个基本模型的权重保持不变,用于预测任何类别的故障样本,权重可能不合理。设置恒定权重的策略忽略了基模型在不同类别样本上的性能差异。实际上,基本模型通常对各种类别的样本进行有区别的故障诊断。性能差异要求基础模型的权重可变,权重应随其对各类故障样本的诊断性能而变化。此外,多样性通常与基础模型的性能不一致。性能较好的基础模型之间的多样性往往会降低,这会降低集成学习的性能。我们需要权衡基础模型的多样性和性能以提高集成性能。
5.因此,本发明提出了一种多变量加权集成学习的工业故障诊断方法。在提出的多变量加权集成学习的工业故障诊断方法中,我们采用具有不同性能的多种基础模型来提高集成性能;每个基模型的权重不是恒定的,而是可变的,并且赋予每个基模型可变的权重,用于识别不同类别的故障样本。
6.发明新型内容(1)要解决的技术问题针对现有技术的不足,本发明新型的目的在于提供基本模型通常对各种类别的样本进行有区别的故障诊断,性能差异要求基础模型的权重可变,权重应随其对各类故障样本的诊断性能而变化,此外,多样性通常与基础模型的性能不一致,性能较好的基础模型之间的多样性往往会降低,这会降低集成学习的性能,我们需要权衡基础模型的多样性和性
能以提高集成性能的技术问题。
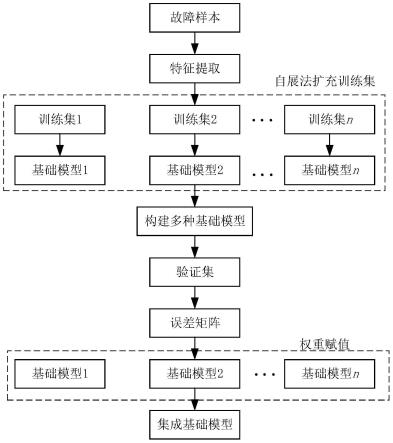
7.(2)技术方案为了解决上述技术问题,本发明新型提供了这样一种多变量加权集成学习的工业故障诊断方法,该工业故障诊断方法包括集成学习中每个基础模型被赋予可变的权重,用于识别不同类别的工业故障样本;所提多变量加权集成学习的工业故障诊断方法在使用过程中的步骤为:步骤(1):生成多个基础模型;从收集到的工业故障样本中提取特征;具有多维特征的实验数据集被分成三个数据集:训练集、验证集和测试集;验证集用于生成每个基础模型的可变权重,通过自展法对主要训练集进行采样,生成了多个不同的训练集,通过从不同的训练集中学习构建了不同的基础模型;每个基础模型都可以为测试集输出一个预测的标签集;基于预测的标签集和真实标签集,使用kw方差评估基础模型之间的多样性,相应kw方差计算公式如下:步骤(2):为每个基础模型设置可变权重;假设集成学习方法包含n个基础模型{z1,zj,
…
,zn},样本的标签集为{c1,c2,
…
,cn},每个不同的基础模型的性能都在验证集上进行了测试,每个基础模型zj对验证集的测试错误率为;{e1j,eij,
…
,emj},并使用所有基础模型的测试错误率形成一个错误矩阵,表示为e=[eij];使用误差矩阵,设置权重矩阵w;权重wij与测试错误率eij成反比;测试错误率eij越低,权重wij越高;这意味着如果基础模型充分识别了某一类的故障样本,则对该类的预测结果赋予更大的权重;每个基础模型的权重值不是恒定的,而是随着不同类别样本的测试错误率而变化;其中矩阵中的元素wij计算公式如下:步骤(3):集成每个基础模型;一种基于类概率的软投票方法被用来整合基础模型进行故障诊断;假设基础模型zj对样本x的预测概率分布为{p1j,pij,
…
,pmj};多个不同的基础模型与可变权重相结合,用于识别测试集,集成模型用h表示;样本x在类别标签ci上的综合概率分布pi计算公式如下:
共为3个步骤,从而首先实现使用自展法从主要训练集产生多个不同的训练集,提高了训练样本的多样性,并且使用不同的基础模型和不同的超参数,在不同的训练集上构建集成学习方法,提高了集成性能,以及根据其在验证集中各种故障模式的性能,为每个基础模型设计可变权重,提高了故障样本识别准确率的目的。
[0008]
首先工业设备的故障信号由加速度传感器采集,从信号中提取多维特征,具有多维特征的实验数据集被分成三个数据集:训练集、验证集和测试集,验证集用于生成每个基本模型的可变权重,然后通过自展法对主要训练集进行采样,生成了多个不同的训练集,通过从不同的训练集中学习构建了不同的基础模型;在验证集上测试了每个基础模型的性能,得到了在各个类样本上的测试错误率列表,通过组合所有测试错误率列表来构建错误矩阵,对于每个基本模型,使用误差矩阵确定可变权重,并将其分组到权重列表中,最后多个不同的基础模型与可变权重相结合;集成每个基础模型,然后实时监测系统状态,当系统监测到故障信号时,输入到多变量集成学习中模型,然后保存故障样本并进行故障诊断;多变量集成学习中模型输出故障类型并实时更新模型,最后,确认故障进行故障检修,继续进行故障监测。
[0009]
优选地,所述步骤(1)中,n为样本的数量;为学习第j个样本的基础模型;表示能够正确识别样本的基础模型的数量,能够便于人员更加清楚的了解步骤(1)的各个变量。
[0010]
进一步的,所述步骤(1)中l为基础模型的总数,使得人员能够清晰的连接基础模型的总个数。
[0011]
更进一步的,所述步骤(2)中wij表示类标签ci上样本的基础模型hj的权重,其中eij是hj在类标签ci上的测试错误率,其中主要能够使得测试的错误率更加直观的快速的得出,进而完成快速判断的显示。
[0012]
更进一步的,所述步骤(3)中pij是类别标签ci上zj的预测概率,预防概率可以降低故障出现的概率和次数进而增加设备的准确性和本方法的使用效果。
[0013]
(3)有益效果与现有技术相比,本发明新型的有益效果在于:1、本发明使用自展法从主要训练集产生多个不同的训练集,提高了训练样本的多样性;2、本发明使用不同的基础模型和不同的超参数,在不同的训练集上构建集成学习方法,提高了集成性能;3、本发明根据其在验证集中各种故障模式的性能,为每个基础模型设计可变权重,提高了故障样本识别准确率。
附图说明
[0014]
图1是本发明方法的多变量加权集成学习框架图;图2是本发明方法的工业故障诊断流程图流程图。
具体实施方式
[0015]
本具体实施方式是一种多变量加权集成学习的工业故障诊断方法,其结构示意图
如图1和2所示,该工业故障诊断方法包括集成学习中每个基础模型被赋予可变的权重,用于识别不同类别的工业故障样本;所提多变量加权集成学习的工业故障诊断方法在使用过程中的步骤为:步骤(1):生成多个基础模型;从收集到的工业故障样本中提取特征;具有多维特征的实验数据集被分成三个数据集:训练集、验证集和测试集,验证集用于生成每个基础模型的可变权重,通过自展法对主要训练集进行采样,生成了多个不同的训练集,通过从不同的训练集中学习构建了不同的基础模型,每个基础模型都可以为测试集输出一个预测的标签集;基于预测的标签集和真实标签集,使用kw方差评估基础模型之间的多样性;相应kw方差计算公式如下:其中步骤(1)中,n为样本的数量;为学习第j个样本的基础模型;表示能够正确识别样本的基础模型的数量,且l为基础模型的总数;步骤(2):为每个基础模型设置可变权重;假设集成学习方法包含n个基础模型{z1,zj,
…
,zn},样本的标签集为{c1,c2,
…
,cn},每个不同的基础模型的性能都在验证集上进行了测试,每个基础模型zj对验证集的测试错误率为{e1j,eij,
…
,emj},并使用所有基础模型的测试错误率形成一个错误矩阵,表示为e=[eij];使用误差矩阵,设置权重矩阵w,权重wij与测试错误率eij成反比;测试错误率eij越低,权重wij越高,这意味着如果基础模型充分识别了某一类的故障样本,则对该类的预测结果赋予更大的权重,每个基础模型的权重值不是恒定的,而是随着不同类别样本的测试错误率而变化,其中矩阵中的元素wij计算公式如下:其中步骤(2)中wij表示类标签ci上样本的基础模型hj的权重。其中eij是hj在类标签ci上的测试错误率;步骤(3):集成每个基础模型;一种基于类概率的软投票方法被用来整合基础模型进行故障诊断;假设基础模型zj对样本x的预测概率分布为{p1j,pij,
…
,pmj};多个不同的基础模型与可变权重相结合,用于识别测试集,集成模型用h表示;样本x在类别标签ci上的综合概率分布pi计算公式如下:
其中步骤(3)中pij是类别标签ci上zj的预测概率;以上共为3个步骤。
[0016]
如图1发明方法的多变量加权集成学习框架图所示,首先工业设备的故障信号由加速度传感器采集,从信号中提取多维特征,具有多维特征的实验数据集被分成三个数据集:训练集、验证集和测试集,验证集用于生成每个基本模型的可变权重,然后通过自展法对主要训练集进行采样,生成了多个不同的训练集,通过从不同的训练集中学习构建了不同的基础模型;在验证集上测试了每个基础模型的性能,得到了在各个类样本上的测试错误率列表,通过组合所有测试错误率列表来构建错误矩阵,对于每个基本模型,使用误差矩阵确定可变权重,并将其分组到权重列表中,最后多个不同的基础模型与可变权重相结合,集成每个基础模型;如图2的本发明方法的工业故障诊断流程图流程图所示,实时监测系统状态,当系统监测到故障信号时,输入到多变量集成学习中模型;然后保存故障样本并进行故障诊断,多变量集成学习中模型输出故障类型并实时更新模型,最后确认故障进行故障检修,继续进行故障监。
[0017]
本实施例中的所有技术特征均可根据实际需要而进行自由组合。
[0018]
上述实施例为本发明新型较佳的实现方案,除此之外,本发明新型还可以其它方式实现,在不脱离本技术方案构思的前提下任何显而易见的替换均在本发明新型的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。