用于急性髓系白血病(aml)的新型肿瘤特异性抗原及其用途
1.相关申请的交叉引用
2.本技术要求于2020年4月14日提交的美国临时专利申请号63/009,853的权益,其通过引用以其全文并入本文。
3.序列表
4.n/a。
技术领域
5.本发明一般地涉及癌症,并且更具体地涉及可用于基于t细胞的癌症免疫疗法的急性髓系白血病的特异性肿瘤抗原。
背景技术:
6.急性髓系白血病(aml)是最具侵袭性的血液系统恶性肿瘤,是异质性疾病,其特征在于异常的表观遗传模式、线粒体蛋白质稳态紊乱和相对较少的突变(li等人,2016;ntziachristos等人,2016;ishizawa等人,2019;fennell等人,2019)。值得注意的是,aml的遗传和表观遗传变化可能先于诊断很多年(abelson等人,2018;desai等人,2018)。此外,治愈不仅需要消除大量肿瘤细胞,还需要消除白血病干细胞(shlush等人,2017;boyd等人,2018)。目前,大多数患者在化疗后复发,《60岁患者的5年总体生存率为40%,而年龄≥60岁的患者(占aml病例的大多数)仅为10-20%(vasu等人,2018)。
7.在过去几年中,对癌症免疫疗法的热情主要受到两项重大突破的推动:i)用于治疗黑素瘤和选定类型实体瘤的免疫检查点疗法,和ii)用于治疗淋巴恶性肿瘤的嵌合抗原受体。然而,aml尚未从这些创新中获益,主要是因为缺乏可操作的免疫靶标。根据t细胞识别的主要组织相容性复合体mhc相关肽(map)是抗癌反应的核心的观点(coulie等人,2014),有证据表明aml细胞应该向cd8 t细胞呈递免疫原性map:i)aml细胞表达高密度mhc i类分子(berlin等人,2015)和ii)aml患者的骨髓含有具有耗竭的表型和转录特征(因此具有抗原识别)的cd8 t细胞(knaus等人,2018)。然而,能够引发保护性免疫应答的aml抗原的性质仍难以捉摸。
8.引起癌症免疫学家注意的第一类map是肿瘤相关抗原(taa),相对于正常细胞,taa在肿瘤细胞中过表达。由于识别自身抗原的高亲和力t细胞被胸腺选择的中心耐受过程消除,taa基本上由低亲和力t细胞识别。因此,基于taa的疫苗对aml进化没有令人信服的影响。研究最多的aml taa:wilms肿瘤1(wt1)尤其获得了令人失望的结果(di stasi等人,2015;maslak等人,2018;rashidi和walter,2016)。重要的是,最近的报道显示,靶向wt1衍生肽的tcr基因疗法(其中t细胞经工程化表达对选定抗原具有高亲和力的tcr)可以持久地防止同种异体造血干细胞移植接受者的复发(chapuis等人,2019)。总体上,这些研究表明wt1衍生肽的免疫原性较差,并且需要以工程化t细胞为靶点才能充分发挥其治疗潜力。
9.与taa相比,肿瘤特异性抗原(tsa)是仅由肿瘤细胞呈递的map。迄今为止,突变的tsa(mtsa),也称为新抗原,最近在寻求针对实体瘤的疫苗方面引起了广泛关注。事实上,
mtsa可以具有高免疫原性,因为在诱导中枢耐受的髓质胸腺细胞(mtec)中未发现它们。然而,mtsa提示了两个警告。首先,它们通常对每名患者的肿瘤(私人新抗原)是独特的。其次,它们不像最初预测的那样普遍(knaus等人,2018)。与aml细胞的低突变负担一致,仅有一种mtsa已通过对原代aml细胞的质谱(ms)分析得到验证(van der lee等人,2019)。尚未对这种源自npm1基因移码的mtsa的治疗潜力进行评价,但根据现有证据,它未引发aml患者的自发免疫应答(van der lee等人,2019)。
10.有鉴于此,迫切需要确定可再次引发针对aml的治疗性免疫应答的抗原。此类抗原可用作疫苗(
±
免疫检查点抑制剂)或作为基于t细胞受体的方法(细胞疗法、双特异性生物制剂)的靶标。
11.本说明书参考了许多文献,其内容通过引用以其全文并入本文。
技术实现要素:
12.本公开提供了以下1至67项:
13.1.一种白血病肿瘤抗原肽(tap),包含以下氨基酸序列中的一个:
14.15.[0016][0017]
2.如项1所述的白血病tap,其包含seq id no:97-154中列出的所述氨基酸序列中的一个。
[0018]
3.如项1或2所述的白血病tap,其中所述白血病tap与hla-a*01:01分子结合并且包含氨基酸序列ntshlpliy(seq id no:48)、htddienaky(seq id no:67)、yshhsgley(seq id no:89)、ildlesry(seq id no:134)、vtdllaltv(seq id no:151)或lsdrqlsl(seq id no:164),优选ildlesry(seq id no:134)或vtdllaltv(seq id no:151)。
[0019]
4.如项1或2所述的白血病tap,其中所述白血病tap与hla-a*02:01分子结合并且包含氨基酸序列fllefkpvs(seq id no:7)、llsrgllfri(seq id no:11)、lldnilqsi(seq id no:27)、flasfvektvl(seq id no:32)、ilashnltv(seq id no:33)、iqltsvhll(seq id no:34)、lelisflpvl(seq id no:35)、lllpespsi(seq id no:43)、alashliea(seq id no:51)、aldditiql(seq id no:52)、algntvpav(seq id no:53)、allpavpsl(seq id no:54)、glyyklhnv(seq id no:61)、hllsetpql(seq id no:65)、kllekafsi(seq id no:72)、slwgqpaea(seq id no:77)、svfagvvgv(seq id no:82)、vlvpyeppqv(seq id no:86)、vlfggkvsga(seq id no:104)、klqdkeigl(seq id no:108)、tlnqginvyi(seq id no:119)、alpvalpsl(seq id no:123)、aldplllri(seq id no:130)、kildvnlri(seq id no:132)、sllsgllra(seq id no:146)、sldllplsi(seq id no:150)、illeeqsli(seq id no:167)、ltsisirpv(seq id no:168)、tisecplli(seq id no:169)、illsnfssl(seq id no:171)、rmvaylqql(seq id no:183)或klnqaflvl(seq id no:188),优选vlfggkvsga(seq id no:104)、klqdkeigl(seq id no:108)、tlnqginvyi(seq id no:119)、alpvalpsl(seq id no:123)、aldplllri(seq id no:130)、kildvnlri(seq id no:132)、sllsgllra(seq id no:146)或sldllplsi(seq id no:150)。
[0020]
5.如项1或2所述的白血病tap,其中所述白血病tap与hla-a*03:01分子结合并且包含氨基酸序列rsassatqvhk(seq id no:5)、ivatgsllk(seq id no:18)、kiknktknk(seq id no:19)、kllsltiyk(seq id no:20)、itssavttalk(seq id no:42)、viliplppk(seq id no:44)、nvnrpltmk(seq id no:74)、svykylkak(seq id no:91)、vvfpfpvnk(seq id no:105)、ilfqnsalk(seq id no:113)、tviriaivnk(seq id no:126)、islivtglk(seq id no:
no:153)。
[0037]
22.如项1或2所述的白血病tap,其中所述白血病tap与hla-b*57:03分子结合并且包含氨基酸序列ggslihpqw(seq id no:60)或lggawkavf(seq id no:172)。
[0038]
23.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*03:03分子结合并且包含氨基酸序列parpagpl(seq id no:37)、iaspiall(seq id no:112)或hslisivyl(seq id no:140),优选iaspiall(seq id no:112)或hslisivyl(seq id no:140)。
[0039]
24.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*05:01分子结合并且包含氨基酸序列sldllplsi(seq id no:150)。
[0040]
25.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*06:02分子结合并且包含氨基酸序列irmkaqal(seq id no:9)、kateyvhsl(seq id no:70)、vsfpdvrkv(seq id no:87)、ignpilrvl(seq id no:142)、lstghlstv(seq id no:154)或lrkavdpil(seq id no:166),优选ignpilrvl(seq id no:142)或lstghlstv(seq id no:154)。
[0041]
26.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*07:01分子结合并且包含氨基酸序列ignpilrvl(seq id no:142)、iyaphirls(seq id no:143)、tveeylvni(seq id no:155)、lhnekglsl(seq id no:178)或vsrnyvlli(seq id no:186),优选ignpilrvl(seq id no:142)或iyaphirls(seq id no:143)。
[0042]
27.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*07:02分子结合并且包含氨基酸序列tilpriltl(seq id no:30)、syspaharl(seq id no:83)、tqappnvvl(seq id no:85)、yyldwihhy(seq id no:90)、slrepqpal(seq id no:109)、papphpaal(seq id no:117)或clrigpvtl(seq id no:158),优选slrepqpal(seq id no:109)或papphpaal(seq id no:117)。
[0043]
28.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*08:02分子结合并且包含氨基酸序列aqdiilqav(seq id no:97)、ltdriyltl(seq id no:102)或agdiiarli(seq id no:174),优选aqdiilqav(seq id no:97)或ltdriyltl(seq id no:102)。
[0044]
29.如项1或2所述的白血病tap,其中所述白血病tap与hla-c*12:03分子结合并且包含氨基酸序列lsashlssl(seq id no:173)。
[0045]
30.如项1-29中任一项所述的白血病tap,其由位于基因组的非蛋白质编码区的序列编码。
[0046]
31.如项30所述的白血病tap,其中所述基因组的非蛋白质编码区是非翻译转录区(utr)。
[0047]
32.如项30所述的白血病tap,其中所述基因组的非蛋白质编码区是内含子。
[0048]
33.如项30所述的白血病tap,其中所述基因组的非蛋白质编码区是基因间区。
[0049]
34.一种包含项1-33中任一项所限定的白血病tap中的至少两种的组合。
[0050]
35.一种编码项1-33中任一项所述的白血病tap或项34所述的组合的核酸。
[0051]
36.如项35所述的核酸,其为mrna或病毒载体。
[0052]
37.一种脂质体,其包含项1-33中任一项所述的白血病tap、项34所述的组合或者项35或36所述的核酸。
[0053]
38.一种组合物,其包含项1-33中任一项所述的白血病tap、项34所述的组合、项35或36所述的核酸或者项37所述的脂质体,以及药学上可接受的载体。
[0054]
39.一种疫苗,其包含项1-33中任一项所述的白血病tap、项34所述的组合、项35或36所述的核酸、项37所述的脂质体或者项38所述的组合物,以及佐剂。
[0055]
40.一种分离的主要组织相容性复合体(mhc)i类分子,在其肽结合槽中包含项1-33中任一项所述的白血病tap。
[0056]
41.如项40所述的分离的mhc i类分子,其为多聚体形式。
[0057]
42.如项41所述的分离的mhc i类分子,其中,所述多聚体是四聚体。
[0058]
43.一种分离的细胞,其包含(i)项1-33中任一项所述的白血病tap、(ii)项34所述的组合或(iii)包含编码项1-33任一项的tap或项34所述的组合的核苷酸序列的载体。
[0059]
44.一种分离的细胞,所述分离的细胞在其表面表达主要组织相容性复合体(mhc)i类分子,所述mhc i类分子在其肽结合槽中包含项1-33中任一项所述的白血病tap或项34所述的组合。
[0060]
45.如项44所述的细胞,其是抗原呈递细胞(apc)。
[0061]
46.如项45所述的细胞,其中所述apc是树突状细胞。
[0062]
47.一种t细胞受体(tcr),其特异性识别项40-42中任一项所述的分离的mhc i类分子和/或在项44-46中任一项所述的细胞的表面表达的mhc i类分子。
[0063]
48.如项47所述的tcr,其中所述tcr包含包含tcrβ(tcrβ)链,所述tcrβ链包含互补决定区3(cdr3),所述cdr3包含seq id no:191-219中列出的氨基酸序列中的一个。
[0064]
49.一种分离的细胞,所述分离的细胞在其细胞表面表达项47或48所述的tcr。
[0065]
50.如项49所述的分离的细胞,其是cd8
t淋巴细胞。
[0066]
51.一种细胞群,其包含至少0.5%的如项49或50所限定的分离的细胞。
[0067]
52.一种治疗受试者的白血病的方法,所述方法包括向所述受试者施用有效量的:(i)项1-33中任一项所述的白血病tap;(ii)项34所述的组合;(iii)项35或36所述的核酸;(iv)项37所述的脂质体;(v)项38所述的组合物;(vi)项39所述的疫苗;(vii)项43-46、49和50中任一项所述的细胞;或(viii)项51所述的细胞群。
[0068]
53.如项52所述的方法,其中所述白血病是髓系白血病。
[0069]
54.如项53所述的方法,其中所述髓系白血病是急性髓系白血病(aml)。
[0070]
55.如项52-54中任一项所述的方法,进一步包括向所述受试者施用至少一种另外的抗肿瘤剂或疗法。
[0071]
56.如项55所述的方法,其中所述至少一种另外的抗肿瘤剂或疗法是化疗剂、免疫疗法、免疫检查点抑制剂、放射疗法或手术。
[0072]
57.(i)项1-33中任一项所述的白血病tap;(ii)项34所述的组合;(iii)项35或36所述的核酸;(iv)项37所述的脂质体;(v)项38所述的组合物;(vi)项39所述的疫苗;(vii)项43-46、49和50中任一项所述的细胞;或(viii)项51所述的细胞群用于治疗受试者的白血病的用途。
[0073]
58.(i)项1-33中任一项所述的白血病tap;(ii)项34所述的组合;(iii)项35或36所述的核酸;(iv)项37所述的脂质体;(v)项38所述的组合物;(vi)项39所述的疫苗;(vii)项43-46、49和50中任一项所述的细胞;或(viii)项51所述的细胞群用于制造用于治疗受试者的白血病的药物的用途。
[0074]
59.如项57或58所述的用途,其中所述白血病是髓系白血病。
[0075]
60.如项59所述的用途,其中所述髓系白血病是急性髓系白血病(aml)。
[0076]
61.如项57-60中任一项所述的用途,进一步包括使用至少一种另外的抗肿瘤剂或疗法。
[0077]
62.如项61所述的用途,其中所述至少一种另外的抗肿瘤剂或疗法是化疗剂、免疫疗法、免疫检查点抑制剂、放射疗法或手术。
[0078]
63.(i)项1-33中任一项所述的白血病tap;(ii)项34所述的组合;(iii)项35或36所述的核酸;(iv)项37所述的脂质体;(v)项38所述的组合物;(vi)项39所述的疫苗;(vii)项43-46、49和50中任一项所述的细胞;或(viii)项51所述的细胞群,用于治疗受试者的白血病的用途。
[0079]
64.根据项63的用于用途的白血病tap、组合、核酸、脂质体、组合物、疫苗、细胞或细胞群,其中所述白血病是髓系白血病。
[0080]
65.根据项64的用于用途的白血病tap、组合、核酸、脂质体、组合物、疫苗、细胞或细胞群,其中所述髓系白血病是急性髓系白血病(aml)。
[0081]
66.据项63-65中任一项的用于用途的白血病tap、组合、核酸、脂质体、组合物、疫苗、细胞或细胞群,其用于与至少一种另外的抗肿瘤剂或疗法组合使用。
[0082]
67.根据项66的用于用途的白血病tap、组合、核酸、脂质体、组合物、疫苗、细胞或细胞群,其中所述至少一种另外的抗肿瘤剂或疗法是化疗剂、免疫疗法、免疫检查点抑制剂、放射疗法或手术。
[0083]
本发明的其他目的、优点和特征将在阅读以下仅以实例的方式参考附图给出的其具体实施方式的非限制性描述之后变得更加显而易见。
附图说明
[0084]
在附图中:
[0085]
图1a-d是显示造血祖细胞在发现aml中的tsa方面是比mtec更好的对照的图表。图1a:通过来自6个mtec或来自6个mpc样本的任一组合k-mer,比较19个aml试样中每一个的k-mer组中k-mer耗竭的有效性。发生率《2的k-mer被忽略,并且以典型模式生成水母数据库以进行此比较。图1b:所有aml试样的组合k-mer与来自6个mtec和来自图1a中使用的6个mpc样本的k-mer之间的重叠。此处重新应用了图1a中使用的数据库构建参数。图1c:对来自指定组织的纯化细胞群中表达(tpm≥1)的蛋白质编码基因进行t分布随机邻域嵌入(t-sne)分析。图1d:比较用于绘制小图c的指定组织和细胞群中表达的蛋白质编码基因(tpm≥1)的总数。pluri_stem:多能干细胞;ery:红细胞;precu:前体;lympho:淋巴细胞;granulo:粒细胞;mono:单核细胞。mann whitney u检验用于比较mtec与其他组织(****p《0.0001),柱状图显示平均值和标准偏差。
[0086]
图2描绘了基于mpc的tsa发现方法的示意图。(a)基于mtec k-mer耗竭的tsa发现的工作流程示意图。(b)ere衍生的map发现的工作流程示意图。(c)mtecs mpcs k-mer耗竭tsa发现方法的工作流程示意图。(d)dke方法的工作流程示意图。此处示出的是aml#1样本的工作流程。使用10倍变化作为最小值,以将k-mer视为过表达(还应用了其他过滤器,参见方法)。至于其他三种方法,在对从用于进行rna测序的相同aml样本洗脱的map进行ms识别之前,将获得的计算机全框翻译重叠群数据库与个性化的典型蛋白质组连接。
[0087]
图3a-h显示了基于mpc的方法识别aml中的大部分tsa
hi
。给出σ)的分布(以黑色绘制)。图3a:每个aml试样(n=19)的map比例,得自基于tpm表达分为10个不同组(十分位)的转录物。十分位10具有表达最高的转录物,而十分位1的表达最低。方框显示分布的中位值、第25个和第75个百分位数,须线延伸至最小值和最大值。图3b:map(点)的累积频率的正态分布,与ms识别的aml试样中能够编码它们的rna-seq读数(rphm)总数的对数关系。给出了分布的平均值(μ)和标准偏差(σ)(以黑色绘制)。图3c:基于图3b的正态分布参数计算rna序列在不同指示的倍数变化(fc,原始rphm
×
fc)后生成map的概率。图3d:用于将目的map(moi)分成taa、hsa、tsa
hi
的决策树。“正常组织”是指所有组织(gtex、纯化的造血细胞和mtec),以及血液/bm仅指纯化的造血细胞。图3e:通过每种指定的蛋白质组学方法获得的moi计数的比较。图3f:比较指定方法之间的tsa
hi
同一性的venn图。图3g:保留时间观察值与保留时间预测值(左)或疏水性指数(右)之间的pearson相关性。图3h:使用comet成功重新识别指示的map的中位值和四分位数范围频率。
[0088]
图4a-k显示了tsa
hi
主要源自内含子翻译并且在许多患者中共享。图4a:热图描绘了来自gtex的总正常组织(n=12-50,取决于可获得的样本)中、正常分选的造血细胞群(n=3-16,取决于可获得的样本)中或mtec(n=11)中每个识别的tsa
hi
的平均rna表达(rphm 1的对数)。还报告了在临床试验中被评价为具有安全性的taa。prec:前体。图4b:比较19个aml试样和mpc(n=16)中平均rphm表达之间的tsa
hi
倍数变化。点显示每个moi,方框显示分布的中位值、第25个和第75个百分位数,须线延伸至最小值和最大值。图4c:生成指示的moi的生物型(基因组区域或事件)的分布。外显子-内含子:与外显子-内含子连接重叠的肽(保留内含子);ncrna:非编码rna;oof翻译:框外翻译。图4d:19个aml样本和437个leucegene患者中的tsa
hi
rna表达。图4e:能够呈递tsa
hi
的hla同种异型的群体覆盖率(呈递tsa
hi
的19个aml试样等位基因 由mhccluster计算的混杂结合物)。这是使用iedb群体覆盖工具(www.iedb.org)计算的。柱状图表示世界人群中携带多达六种同种异型的个体的频率(x轴),并且群体覆盖的累积百分比显示为点。图4f:基于tsa
hi
rna表达(如果rphm≥2,则认为表达)、患者的hla等位基因(optitype)和混杂结合物,leucegene队列中hla-tsa
hi
复合物分布。显示了高(上四分位数)和低(所有其他患者)tsa
hi
表达者之间的区别。图4g:leucegene患者在诊断和复发时的#
pred
hla-tsa
hi
复合物。图4h:可以由aml母细胞(blasts)的hla等位基因呈递的tsa
hi
的rna表达在诊断时和复发时从15名患者成对纯化(数据来自(toffalori等人,2019))。使用wilcoxon配对符号秩检验进行比较。图4i:另报道,tsa
hi
样本间共有(如果rphm》0,则认为表达)在分选的母细胞(n=12)或白血病干细胞(lsc,n=8)中的比较(corces等人,2016)。图4j:图4i中所示的样本中hla-abc分子的rna表达。显示平均值 sd。图4k:比较表达(rphm》0)≥tsa
hi
中位数(n=207)的leucegene患者相比于其他(n=230)的指示的lsc特征基因集的gsea分析(eppert等人,2011)。nes,归一化富集评分。
[0089]
图5a-f显示了大量tsa
hi
的呈递与更好的生存率相关。图5a:表达高数量(n=98,图5b中的上四分位数)相比于低数量(n=275,所有其他患者)的hla-tsa
hi
复合物的leucegene患者之间的kaplan-meier生存分析。统计学显著性由对数秩检验确定。图5b:用于5年总体生存率的多变量分析的森林图。hr,校正风险比;ci,置信区间;adv,不利的;fav,有利的;int,中间。npm1/flt3相互作用=存在npm1
mut
和flt3-itd。图5c:从(a)中进行的分析中移除指示数量的tsa
hi
后计算的对数秩p值;对每个数值进行1000次排列,并报告平均值 sd。图
5d:在图5c中获得的显著性p值的百分比。图5e:在从图5a中的分析中可选地移除每个tsa
hi
之后重新计算的对数秩p值的比较。图5f:在从图5a中的分析中可选地移除每个hla等位基因之后重新计算的对数秩p值的比较。
[0090]
图6a-o显示了tsa
hi
呈递触发细胞毒性t细胞应答。图6a:moi、来自胸腺基质细胞的map和hiv map之间的免疫原性评分(repitope)的比较。图6b:moi的11个可获得的mtec样本、5112个非免疫原性map和1411个免疫原性map(来自iedb并在(ogishi和yotsuyanagi,2019)中展出)的平均rna表达的中位值和四分位数范围。图6c:用指示肽脉冲的dc刺激后健康pbmc的ifn-γelispot测定。将2项独立实验的结果合并。图6d:指示tsa
hi
(单一供体)的elispot测定。图6e:在指示肽存在下扩增的t细胞的细胞因子分泌的流式细胞术分析。图6f:在指示肽存在下扩增的t细胞之间指示的右旋体频率的代表性流式细胞术图。图6g:fest测定:用3个不同tsa
hi
池(5种肽/池)刺激10天后显著t细胞克隆型的扩增。图6h:在具有高计数相比于低计数的指示
pred
hla-moi的leucegene患者中每千个tcr读数的tcr cdr3(cpk,作为克隆型多样性的量度)(与图4f和11d相关)。图6i:ergo预测的针对leucegene中tsa
hi
(n=66-164/组)反应的克隆型频率。图6j:ergo预测的针对leucegene中taa(n=74-207/组)反应的克隆型频率。图6k:在所有抗moi克隆型中,识别在所考虑的样本中
pred
呈递的moi的克隆型的频率,由
pred
呈递的moi的数量(与i和j相关)归一化。具有抗
pres
moi克隆型计数=0的患者被忽略。图6l:cd8a和cd8b基因的rna表达与leucegene中高于2rphm表达的tsa
hi
数量之间的相关性。图6m:cd8a和cd8b基因的rna表达与leucegene中
pred
hla-tsa
hi
数量之间的相关性。图6n:比较归一化tsa
hipred
呈递高于中位值相比于低于中位值的患者的差异基因表达分析的火山图。点显示在高于中位值的患者中上调的基因。图6o:图6n中上调基因的go term分析。
[0091]
图7a-g显示了tsa
hi
表达与免疫编辑、aml驱动突变和表观遗传畸变相关。图7a:he-tsa
hi
数量与整个leucegene队列(n=437)中指示基因的表达之间的pearson相关性。第一个图的hla-a、hla-b和hla-c的表达值相加。图7b:比较表达≥he-tsa
hi
中位数的leucegene患者相比于其他患者的pd-l1(cd274)基因表达,分层为npm1突变状态的函数。图7c:与he-tsa
hi
数量呈负相关的基因间go term富集的网络分析。节点大小与基因集大小成正比。图7d:与he-tsa
hi
数量呈正相关的基因间go term富集的网络分析。图7e:对于指示的基因,在wt和突变患者中表达≥he-tsa
hi
中位数的患者数量相比于其他患者的比较。统计学显著性使用fisher精确检验确定(**p《0.01,****p《0.0001)。图7f:在npm1、flt3或dnmt3a中具有0至3个突变的患者之间的he-tsa
hi
数量比较。图7g:由irfinder确定的leucegene患者(n=437,列)的内含子保留率的无监督一致性聚类。行代表1211个排名靠前的内含子,对于一致性聚类这些内含子具有最高可变性和显著性,按分层聚类。患者的fab类型显示在热图下方,p值(fisher精确检验,*p《0.05,**p《0.01,***p《0,001,****p《0.0001)显示与指示的一致性聚类显著相关。
[0092]
图8a是k-mer出现的概念说明。
[0093]
图8b是描绘在样本05h143中作为发生函数的k-mer频率分布的实例的图。
[0094]
图8c是描绘在仅mtec和mtec mpc k-mer耗竭方法之间使用的阈值发生比较的图(每个点是不同的aml样本)。
[0095]
图8d是描绘从在mtec或mtec mpc k-mer耗竭后获得的所有19个aml试样获得的独
特k-mer组合之间k-mer同一性重叠的图。
[0096]
图9a是提供差异k-mer表达分析和ms数据库构建的详情的示意图。样本aml#1的ms数据库的构建作为实例提供。fc,倍数变化。是显示差异k-mer表达分析和ms数据库构建的详情的图表。样本aml#1的ms数据库的构建作为实例提供。fc,倍数变化。
[0097]
图9b是描述典型肽识别的累积数量(衍生自个性化典型蛋白质组的肽,单独(canon.)或在四种指示的方法中与重叠群序列连接)相对于平均数据库大小(线)的图。
[0098]
图9c描绘了比较基于每种方法识别的典型肽的同一性与仅基于典型个性化蛋白质组识别的肽的重叠的venn图。
[0099]
图10a是描绘了通过每种tsa识别方法识别的目的mhc-i相关肽(map)(moi)的比例的比较的图。
[0100]
图10b是描绘了用mtec mpc k-mer耗竭或用差异k-mer表达方法识别的表达(rphm》0)tsa
hi
的(在本研究中用于识别tsa的19个中的)aml试样总数的比较的图。
[0101]
图11a是显示在leucegene队列(n=437)中具有等于或高于2rphm的rna表达的tsa
hi
数量分布的图。
[0102]
图11b是显示呈递以等于或高于2rphm的水平表达的大量tsa
hi
的leucegene队列(n=372,在诊断时测序并且可获得生存数据)的患者(左图中分布的上四分位数)相比于呈递低水平的患者(队列的其余部分)之间的生存比较的图。
[0103]
图11c-e是显示对于hsa(图11c)、taa(图11d)和tsa
lo
(图11e),基于rna表达(如果rphm≥2,则认为表达)、每名患者的hla等位基因和hsa的混杂结合物预测(optitype和mhccluster)获得的整个leucegene队列的hla-moi复合物分布的图。
[0104]
图11f-h是显示对于hsa(图11f)、taa(图11g)和tsa
lo
(图11h),呈递大量hla-moi复合物的leucegene队列(n=372,在诊断时测序并且可获得生存数据)的患者(上图中分布的上四分位数)相比于呈递低水平的患者(队列的其余部分)之间的生存比较的图。
[0105]
图12a描绘了he-tsa
hi
数量与整个leucegene队列(n=437)中指示基因的表达之间的pearson相关性。
[0106]
图12b描绘了显示具有高
pred
呈递水平的tsa
hi
的患者相比于其余患者的指示基因表达的比较的图(与图4f相关)。
[0107]
图12c描绘了znf445的表达与leucegene队列中保留的内含子数量之间的pearson相关性(用irfinder分析,并且如果在超过10%的转录物中保留,则定义为保留)。
[0108]
图12d是显示对于指示的基因,在wt和突变患者中表达≥he-tsa
hi
中位数的患者相比于其他患者的比较的图。统计学显著性使用fisher精确检验建立。
[0109]
图12e是显示在接受或未接受allo-hsct的患者中表达≥he-tsa
hi
中位数的患者相比于其他患者的比较的图。统计学显著性使用fisher精确检验建立。
[0110]
图12f是显示he-tsa
hi
计数高于或低于整个leucegene队列中he-tsa
hi
计数中位值的患者的fab类型分布的图。
[0111]
图12g是显示he-tsa
hi
计数高于或低于整个leucegene队列中he-tsa
hi
计数中位值的患者的who 2008分类分布的图。
[0112]
图12h是显示he-tsa
hi
计数高于或低于整个leucegene队列中he-tsa
hi
计数中位值的患者的细胞遗传学谱分布的图。
具体实施方式
[0113]
本文使用的遗传学、分子生物学、生物化学和核酸的术语和符号遵循该领域的标准论文和文献的术语和符号,例如kornberg和baker,dna replication,第二版(w.h.freeman,new york,1992);lehninger,biochemistry,第二版(worth publishers,new york,1975);strachan和read,human molecular genetics,第二版(wiley-liss,new york,1999);eckstein,编辑,oligonucleotides and analogs:a practical approach(oxford university press,new york,1991);gait,编辑,oligonucleotide synthesis:a practical approach(irl press,oxford,1984)等。所有术语应以其在相关领域中确立的典型含义来理解。
[0114]
冠词“一个”和“一种”在本文中用于指代冠词的一个或多于一个(即至少一个)语法对象。例如,“元素”是指一个元素或一个以上的元素。在本说明书中,除非上下文另有要求,否则词语“包含(comprise)”、“包含(comprises)”和“包含(comprising)”将被理解为暗示包括所陈述的步骤或元素或步骤或元素的组,但不排除任何其他步骤或元素或步骤或元素的组。
[0115]
除非在本文中另有说明,否则本文对数值范围的引用仅旨在用作单独提及落入该范围内的每个单独值的速记方法,并且将每个单独值并入说明书中,就好像其在本文中单独引用一样。范围内的值的所有子集也被并入到说明书中,就好像它们在本文中被单独引用一样。
[0116]
除非本文另有说明或与上下文明显矛盾,否则本文所述的所有方法都可以任何合适的顺序进行。
[0117]
除非另有声明,否则本文提供的任何和所有实例或示例性语言(例如,“诸如”)的使用仅旨在更好地说明本发明并且不对本发明的范围构成限制。
[0118]
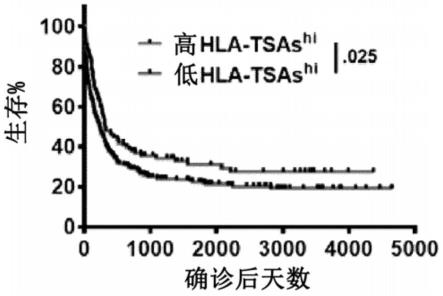
说明书中的任何语言都不应被解释为表明任何未要求保护的元素对于本发明的实践是必不可少的。
[0119]
在本文中,术语“约”具有其普通含义。术语“约”用于表示值包括用于确定该值的设备或方法的固有误差变化,或包括接近所述值的值,例如在所述值(或值范围)的10%或5%以内。
[0120]
在本文所述的研究中,发明人使用基于蛋白质基因组学的方法从19个aml试样中识别了tsa候选者。这些tsa中有很大一部分源自异常表达的未突变基因组序列,这些序列在正常组织中不表达,诸如非外显子序列(例如,内含子和基因间序列)。这些aml tsa候选者的表达显示与表观遗传修饰因子(例如,dnmt3a)的突变和znf445(基因组印记的调节因子)的表达相关。研究还表明,aml tsa候选者在患者中高度共享,在母细胞和白血病干细胞中均有表达,它们的hla表达与免疫编辑标志物和更好的总体生存率相关。因此,本文识别的新型aml tsa候选者可用于基于白血病t细胞的免疫疗法。
[0121]
因此,在一方面,本公开涉及白血病tap(或白血病肿瘤特异性肽),其包含以下氨基酸序列中的一个或由其组成:
[0122]
[0123]
[0124][0125]
通常,在hla i类上下文中呈递的肽(诸如tap)的长度在约7或8至约15个,或优选8至14个氨基酸残基之间变化。在本公开的方法的一些实施方式中,包含本文限定的tap序列的更长的肽被人工负载至细胞(诸如抗原呈递细胞(apc))中,由细胞处理并且tap由apc表面处的mhc i类分子呈递。在该方法中,可以将长度超过15个氨基酸残基的肽/多肽负载至apc中,通过apc胞质溶胶中的蛋白酶进行处理,提供本文限定的相应tap用于呈递。在一些实施方式中,用于产生本文限定的tap的前体肽/多肽是例如1000、500、400、300、200、150、100、75、50、45、40、35、30、25、20或15个氨基酸或更少。因此,使用本文所述的tap的所有方法和过程包括使用更长的肽或多肽(包括天然蛋白质),即肿瘤抗原前体肽/多肽,以诱导在由细胞(apc)处理后呈递“最终”8-14个tap。在一些实施方式中,本文提及的tap为约8至14、8至13或8至12个氨基酸长(例如,8、9、10、11、12或13个氨基酸长),足够小用于直接配合hla i类分子。在一种实施方式中,tap包含20个氨基酸或更少,优选15个氨基酸或更少,更优选14个氨基酸或更少。在一种实施方式中tap包含至少7个氨基酸,优选至少8个氨基酸或更少,更优选至少9个氨基酸。
[0126]
如本文所用,术语“氨基酸”包括天然存在的氨基酸以及其他氨基酸(例如,天然存在的氨基酸、非天然存在的氨基酸、不由核酸序列编码的氨基酸等)的l-和d-异构体,用于肽化学以制备tap的合成类似物。天然存在的氨基酸的实例是甘氨酸、丙氨酸、缬氨酸、亮氨酸、异亮氨酸、丝氨酸、苏氨酸等。其他氨基酸包括例如氨基酸的非遗传编码形式,以及l-氨基酸的保守置换。天然存在的非遗传编码氨基酸包括例如β-丙氨酸、3-氨基-丙酸、2,3-二氨基丙酸、α-氨基异丁酸(aib)、4-氨基-丁酸、n-甲基甘氨酸(肌氨酸)、羟脯氨酸、鸟氨酸(例如,l-鸟氨酸)、瓜氨酸、叔丁基丙氨酸、叔丁基甘氨酸、n-甲基异亮氨酸、苯基甘氨酸、环己基丙氨酸、正亮氨酸(nle)、正缬氨酸、2-萘基丙氨酸、吡啶丙氨酸、3-苯并噻吩丙氨酸、4-氯苯丙氨酸、2-氟苯丙氨酸、3-氟苯丙氨酸、4-氟苯丙氨酸、青霉胺、1,2,3,4-四氢-异喹啉-3-羧酸、β-2-噻吩丙氨酸、甲硫氨酸亚砜、l-高精氨酸(hoarg)、n-乙酰赖氨酸、2-氨基丁酸、2-氨基丁酸、2,4,-二氨基丁酸(d-或l-)、对氨基苯丙氨酸、n-甲基缬氨酸、高半胱氨酸、高丝氨酸(hoser)、磺基丙氨酸、ε-氨基己酸、δ-氨基戊酸或2,3-二氨基丁酸(d-或l-)等。这些氨基酸是生物化学/肽化学领域所熟知的。在一种实施方式中,tap仅包含天然存在的氨基酸。
[0127]
在实施方式中,本文所述的tap包括具有改变的序列的肽,所述改变的序列含有相对于本文提及的序列的功能等效氨基酸残基的置换。例如,序列内的一个或多个氨基酸残
基可以被具有相似极性(具有相似物理化学性质)的其他氨基酸置换,其充当功能等效物,导致沉默改变。序列内氨基酸的置换可以选自该氨基酸所属类别的其他成员。例如,带正电荷的(碱性)氨基酸包括精氨酸、赖氨酸和组氨酸(以及高精氨酸和鸟氨酸)。非极性(疏水)氨基酸包括亮氨酸、异亮氨酸、丙氨酸、苯丙氨酸、缬氨酸、脯氨酸、色氨酸和甲硫氨酸。不带电荷的极性氨基酸包括丝氨酸、苏氨酸、半胱氨酸、酪氨酸、天冬酰胺和谷氨酰胺。带负电荷的(酸性)氨基酸包括谷氨酸和天冬氨酸。氨基酸甘氨酸可以包括在非极性氨基酸家族或不带电(中性)极性氨基酸家族中。在氨基酸家族内进行的置换通常被理解为保守置换。本文提及的tap可以包含所有l-氨基酸、所有d-氨基酸或l-氨基酸和d-氨基酸的混合物。在一种实施方式中,本文提及的tap包含所有l-氨基酸。
[0128]
在一种实施方式中,在包含seq id no:1-190,优选seq id no:97-154的序列中的一个或由其组成的tap的序列中,可以通过替换为其他氨基酸来改性基本上不有助于与t细胞受体相互作用的氨基酸残基,所述其他氨基酸的并入基本上不影响t细胞反应性并且不消除与相关mhc的结合。
[0129]
tap还可以是n-末端和/或c-末端封端的或改性的以防止降解,增加稳定性、亲和力和/或摄取。因此,在另一方面,本公开提供了式z
1-x-z2的改性tap,其中x是包含以下氨基酸序列中的一个或由其组成的tap:seq id no:1-190,优选seq id no:97-154。
[0130]
在一种实施方式中,tap的氨基末端残基(即,n-末端处的游离氨基基团)被改性(例如,为了防止降解),例如通过部分/化学基团(z1)的共价连接。z1可以是一至八个碳的直链或支链烷基基团、或酰基基团(r-co-)(其中r为疏水部分(例如,乙酰基、丙酰基、丁酰基、异丙酰基或异丁酰基))、或芳酰基基团(ar-co-)(其中ar是芳基基团)。在一种实施方式中,酰基基团是c
1-c
16
或c
3-c
16
酰基基团(直链或支链、饱和或不饱和的),在另一实施方式中,是饱和的c
1-c6酰基基团(直链或支链)或不饱和的c
3-c6酰基基团(直链或支链),例如乙酰基基团(ch
3-co-,ac)。在一种实施方式中,z1不存在。tap的羧基末端残基(即tap的c-末端处的游离羧基基团)可以被改性(例如,为了防止降解),例如通过酰胺化(oh基团被nh2基团取代),因此在这种情况下z2是nh2基团。在一种实施方式中,z2可以是异羟肟酸基团、腈基团、酰胺(伯、仲或叔)基团、具有一至十个碳的脂肪族胺(诸如甲胺、异丁胺、异戊胺或环己胺)、芳族或芳烷基胺(诸如苯胺、萘胺、苄胺、肉桂胺或苯乙胺)、醇或ch2oh。在一种实施方式中,z2不存在。在一种实施方式中,tap包含以下氨基酸序列中的一个:seq id no:1-190,优选seq id no:97-154。在一种实施方式中,tap由以下氨基酸序列中的一个组成:seq id no:1-190,优选seq id no:97-154,即其中z1和z2不存在。
[0131]
在另一方面,本公开提供了与hla-a*01:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:48、67、89、134、151或164,seq id no:134或151。
[0132]
在另一方面,本公开提供了与hla-a*02:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:7、11、27、32、33、34、35、4351、52、53、54、61、65、72、77、82、86、104、108、119、123、130、132、146、150、167、168、169、171、183或188,优选seq id no:104、108、119、123、130、132、146或150。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*02:05、hla-a*02:06和/或hla-a*02:07分子结合。
[0133]
在另一方面,本公开提供了与hla-a*03:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:5、18、19、20、42、44、74、91、105、113、126、131、159、160、180或189,优选seq id no:105、113、126或131。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*11:01分子结合。
[0134]
在另一方面,本公开提供了与hla-a*11:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:6、45、96、106、121、149或152,优选seq id no:106、121、149或152。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*03:01、hla-a*31:01和/或hla-a*68:01分子结合。
[0135]
在另一方面,本公开提供了与hla-a*24:02分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:13、36、71、92、95或145,优选seq id no:145。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*23:01分子结合。
[0136]
在另一方面,本公开提供了与hla-a*26:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:59或seq id no:185的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*25:01和/或hla-a*66:01分子结合。
[0137]
在另一方面,本公开提供了与hla-a*29:02分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:88、99或138,优选seq id no:99或138。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*30:02和/或hla-b*15:02分子结合。
[0138]
在另一方面,本公开提供了与hla-a*30:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:26、29或165的序列或由其组成。
[0139]
在另一方面,本公开提供了与hla-a*68:02分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:50或seq id no:148,优选seq id no:148。
[0140]
在另一方面,本公开提供了与hla-b*07:02分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:8、25、40、55、56、73、78、79、80、81、98、100、107、110、111、118、120、128、129、157、161、163、179或184,优选seq id no:98、100、107、110、111、118、120、128或129。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*35:02、hla-b*35:03、hla-b*55:01和/或hla-b*56:01分子结合。
[0141]
在另一方面,本公开提供了与hla-b*08:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:4、14、15、17、seq id no:21、22、23、28、31、47、49、101、103、114、137、139、147、156、170、181或182,优选地seq id no:101、103、114、137、139或147。
[0142]
在另一方面,本公开提供了与hla-b*14:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:2、39、58、66、124、133、136、
141、162、175、176或177,优选seq id no:124、133、136或141。
[0143]
在另一方面,本公开提供了与hla-b*15:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:10、57、62或94的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*15:02、hla-b*15:03和/或hla-b*46:01分子结合。
[0144]
在另一方面,本公开提供了与hla-b*27:05分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:1或144,优选seq id no:144的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*27:02分子结合。
[0145]
在另一方面,本公开提供了与hla-b*38:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:4、64或84的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*39:01分子结合。
[0146]
在另一方面,本公开提供了与hla-b*40:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:75或76的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*18:01、hla-b*40:02、hla-b*41:02、hla-b*44:02、hla-b*44:03和/或hla-b*45:01分子结合。
[0147]
在另一方面,本公开提供了与hla-b*44:03分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:127的序列或由其组成。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*18:01、hla-b*40:01、hla-b*40:02、hla-b*41:02、hla-b*44:02和/或hla-b*45:01分子结合。
[0148]
在另一方面,本公开提供了与hla-b*51:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:12、24、38、68、115、116或190,优选seq id no:115或116。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*35:02、hla-b*35:03、hla-b*52:01、hla-b*53:01、hla-b*55:01和/或hla-b*56:01分子结合。
[0149]
在另一方面,本公开提供了与hla-b*57:01分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:3、16、41、63、69、93、122、125、135、153或183,优选122、125、135或153。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-a*32:01和/或hla-b*58:01分子结合。
[0150]
在另一方面,本公开提供了与hla-b*57:03分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含seq id no:60或172的序列或由其组成。
[0151]
在另一方面,本公开提供了与hla-c*03:03分子结合的白血病tap(或肿瘤特异性肽),优选aml tap,其包含以下序列或由其组成:seq id no:37、112或140,优选seq id no:112或140。由于hla等位基因表现出混杂性(某些hla等位基因存在相似的表位,见表4),上面识别的tap可以进一步与hla-b*46:01、hla-c*03:02、hla-c*03:04、hla-c*08:01、hla-c*08:02、hla-c*12:02、hla-c*12:03、hla-c*15:02和/或hla-c*16:01分子结合。
1887,1995;tam等人,int.j.peptide protein res.45:209-216,1995;schnolzer和kent,science 256:221-225,1992;liu和tam,j.am.chem.soc.116:4149-4153,1994;liu和tam,proc.natl.acad.sci.usa 91:6584-6588,1994;以及yamashiro和li,int.j.peptide protein res.31:322-334,1988)。其他可用于合成tap的方法描述于nakagawa等人,j.am.chem.soc.107:7087-7092,1985。在一种实施方式中,tap是化学合成的(合成肽)。本公开的另一实施方式涉及非天然存在的肽,其中所述肽由本文限定的氨基酸序列组成或基本上由本文限定的氨基酸序列组成并且已经合成产生(例如合成)为药学上可接受的盐。根据本公开的tap的盐与处于其体内状态的肽显著不同,因为体内产生的肽不是盐。肽的非天然盐形式可以调节肽的溶解度,特别是在包含肽的药物组合物的情况下,例如如本文公开的肽疫苗。优选地,盐是肽的药学上可接受的盐。
[0160]
在一种实施方式中,本文提及的tap是基本上纯的。当化合物与自然伴随它的组分分离时,它是“基本上纯的”。通常,当化合物按重量计占样本中总材料的至少60%,更通常75%、80%或85%,优选超过90%,且更优选超过95%时,该化合物是基本上纯的。因此,例如,化学合成或通过重组技术产生的多肽通常基本上不含其天然相关组分,例如其来源大分子的组分。当核酸分子不与编码序列紧密接邻(即共价连接)时,核酸分子是基本上纯的,在该核酸分子源自的生物体的天然存在的基因组中,该编码序列通常与该核酸分子接邻。例如,可以通过从天然来源中提取;通过表达编码肽化合物的重组核酸分子;或通过化学合成来获得基本上纯的化合物。纯度可以使用任何合适的方法测量,例如柱色谱、凝胶电泳、hplc等。在一种实施方式中,tap在溶液中。在另一实施方式中,tap是固体形式,例如冻干的。
[0161]
在另一方面,本公开进一步提供了编码本文提及的tap或肿瘤抗原前体-肽的核酸(分离的)。在一种实施方式中,核酸包含约21个核苷酸至约45个核苷酸,约24个至约45个核苷酸,例如24、27、30、33、36、39、42或45个核苷酸。如本文所用,“分离的”是指与存在于该分子的天然环境中的其他组分或天然存在的来源大分子(例如,包括其他核酸、蛋白质、脂质、糖等)分离的肽或核酸分子。如本文所用,“合成的”是指未从其天然来源中分离的肽或核酸分子,例如,通过重组技术或使用化学合成产生的。本公开的核酸可用于重组表达本公开的tap,并且可以被包含在载体或质粒中,诸如克隆载体或表达载体,其可以被转染到宿主细胞中。在一种实施方式中,本公开提供了包含编码本公开的tap的核酸序列的克隆、表达或病毒载体或质粒。可选地,可以将编码本公开的tap的核酸掺入宿主细胞的基因组中。在任一情况下,宿主细胞表达由核酸编码的tap或蛋白质。如本文所用,术语“宿主细胞”不仅指特定的受试者细胞,而且还指此类细胞的后代或潜在后代。宿主细胞可以是能够表达本文所述的tap的任何原核细胞(例如,大肠杆菌)或真核细胞(例如,昆虫细胞、酵母或哺乳动物细胞)。载体或质粒含有插入的编码序列转录和翻译所必需的元件,也可以含有其他组分(诸如,抗性基因、克隆位点等)。可以使用本领域技术人员熟知的方法构建表达载体,该表达载体包含编码肽或多肽的序列以及与其可操作地连接的合适的转录和翻译控制/调控元件。这些方法包括体外重组dna技术、合成技术和体内基因重组。此类技术描述于sambrook.等人(1989)molecular cloning,a laboratory manual,cold spring harbor press,plainview,n.y.,和ausubel,f.m.等人(1989)current protocols in molecular biology,john wiley&sons,new york,n.y.。“可操作地连接”是指组分的并列,特别是核苷酸序列,使得可以进行组分的正常功能。因此,与调控序列可操作地连接的编码序列是指核
苷酸序列的构型,其中编码序列可以在调控序列的调控控制下,即转录和/或翻译控制下表达。如本文所用,“调控/控制区”或“调控/控制序列”是指参与调控编码核酸的表达的非编码核苷酸序列。因此,术语调控区包括启动子序列、调控蛋白结合位点、上游激活序列等。载体(例如,表达载体)可以具有必需的5'上游和3'下游调节元件(诸如启动子序列,诸如cmv、pgk和efia启动子)、核糖体识别和结合tata盒以及3'utr aauaaa转录终止序列,用于在其各自的宿主细胞中进行有效的基因转录和翻译。其他合适的启动子包括以下的组成型启动子:猿猴病毒40(sv40)早期启动子、小鼠乳腺肿瘤病毒(mmtv)、hiv ltr启动子、momulv启动子、禽白血病病毒启动子、ebv立即早期启动子和劳斯肉瘤病毒启动子。还可以使用人基因启动子,包括但不限于肌动蛋白启动子、肌球蛋白启动子、血红蛋白启动子和肌酸激酶启动子。在某些实施方式中,诱导型启动子也被认为是表达tap的载体的一部分。这提供了能够打开目的多核苷酸序列的表达或关闭表达的分子开关。诱导型启动子的实例包括,但不限于金属硫蛋白启动子、糖皮质激素启动子、孕酮启动子或四环素启动子。载体的实例是质粒、自主复制序列和转座元件。其他示例性载体包括,但不限于质粒、噬菌粒、粘粒、人工染色体(诸如酵母人工染色体(yac)、细菌人工染色体(bac)或pi来源的人工染色体(pac))、噬菌体(诸如λ噬菌体或m13噬菌体)和动物病毒。可用作载体的动物病毒类别的实例包括,但不限于逆转录病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(例如,单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒和乳多空病毒(例如,sv40)。表达载体的实例是用于在哺乳动物细胞中表达的lenti-x
tm
双顺反子表达系统(neo)载体(clontrch)、pclneo载体(promega);plenti4/v5-dest
tm
、plenti6/v5-dest
tm
和plenti6.2n5-gw/lacz(invitrogen),用于哺乳动物细胞中慢病毒介导的基因转移和表达。本文公开的tap的编码序列可以连接至此类表达载体中,用于在哺乳动物细胞中表达tap。
[0162]
在某些实施方式中,编码本公开的tap的核酸在病毒载体中提供。病毒载体可以是源自逆转录病毒、慢病毒或泡沫病毒的那些。如本文所用,术语“病毒载体”是指核酸载体构建体,其包括至少一种病毒来源的元件并且具有被包装至病毒载体颗粒中的能力。病毒载体可以含有本文所述的各种蛋白质的编码序列来代替非必需的病毒基因。载体和/或颗粒可用于在体外或体内将dna、rna或其他核酸转移至细胞中。许多形式的病毒载体是本领域已知的。
[0163]
在实施方式中,编码本公开的tap的核酸(dna、rna)包含在脂质体或任何其他合适的载体中。
[0164]
在另一方面,本公开提供了一种mhc i类分子,其包含(即呈递或结合至)一个或多个seq id no:1-190,优选seq id no:97-154的tap。在一种实施方式中,mhc i类分子是hla-a1分子,在进一步的实施方式中是hla-a*01:01分子。在另一实施方式中,mhc i类分子是hla-a2分子,在进一步的实施方式中是hla-a*02:01分子。在另一实施方式中,mhc i类分子是hla-a3分子,在进一步的实施方式中是hla-a*03:01分子。在另一实施方式中,mhc i类分子是hla-a11分子,在进一步的实施方式中是hla-a*11:01分子。在另一实施方式中,mhc i类分子是hla-a24分子,在进一步的实施方式中是hla-a*24:02分子。在另一实施方式中,mhc i类分子是hla-a26分子,在进一步的实施方式中是hla-a*26:01分子。在另一实施方式中,mhc i类分子是hla-a29分子,在进一步的实施方式中是hla-a*29:02分子。在另一实施方式中,mhc i类分子是hla-a30分子,在进一步的实施方式中是hla-a*30:01分子。在另一实施方式中,mhc i类分子是hla-a68分子,在进一步的实施方式中是hla-a*68:02分子。在
另一实施方式中,mhc i类分子是hla-b07分子,在进一步的实施方式中是hla-b*07:02分子。在另一实施方式中,mhc i类分子是hla-b08分子,在进一步的实施方式中是hla-b*08:01分子。在另一实施方式中,mhc i类分子是hla-b14分子,在进一步的实施方式中是hla-b*14:01分子。在另一实施方式中,mhc i类分子是hla-b15分子,在进一步的实施方式中是hla-b*15:01分子。在另一实施方式中,mhc i类分子是hla-b27分子,在进一步的实施方式中是hla-b*27:05分子。在另一实施方式中,mhc i类分子是hla-b38分子,在进一步的实施方式中是hla-b*38:01分子。在另一实施方式中,mhc i类分子是hla-b40分子,在进一步的实施方式中是hla-b*40:01分子。在另一实施方式中,mhc i类分子是hla-b44分子,在进一步的实施方式中是hla-b*44:02或hla-b*44:03分子。在另一实施方式中,mhc i类分子是hla-b57分子,在进一步的实施方式中是hla-b*57:01或hla-b*57:03分子。在另一实施方式中,mhc i类分子是hla-co3分子,在进一步的实施方式中是hla-c*03:03分子。在另一实施方式中,mhc i类分子是hla-co4分子,在进一步的实施方式中是hla-c*04:01分子。在另一实施方式中,mhc i类分子是hla-c05分子,在进一步的实施方式中是hla-c*05:01分子。在另一实施方式中,mhc i类分子是hla-c06分子,在进一步的实施方式中是hla-c*06:02分子。在另一实施方式中,mhc i类分子是hla-c07分子,在进一步的实施方式中是hla-c*07:01或hla-c*07:02分子。在另一实施方式中,mhc i类分子是hla-c08分子,在进一步的实施方式中是hla-c*08:02分子。在另一实施方式中,mhc i类分子是hla-c12分子,在进一步的实施方式中是hla-c*12:03分子。
[0165]
在一种实施方式中,tap与mhc i类分子非共价结合(即,tap被负载至或非共价结合至mhc i类分子的肽结合槽/袋)。在另一实施方式中,tap与mhc i类分子(α链)共价附接/结合。在此类构建体中,tap和mhc i类分子(α链)作为合成融合蛋白产生,通常具有短的(例如,5至20个残基,优选约8-12个,例如,10个)柔性接头或间隔子(例如,聚甘氨酸接头)。在另一方面,本公开提供了编码融合蛋白的核酸,该融合蛋白包含与mhc i类分子(α链)融合的本文限定的tap。在一种实施方式中,mhc i类分子(α链)-肽复合物是多聚化的。因此,在另一方面,本公开提供了(共价或非共价地)负载有本文提及的tap的mhc i类分子的多聚体。此类多聚体可以附接至标签,例如荧光标签,其允许检测多聚体。已经开发了大量用于产生mhc多聚体的策略,该mhc多聚体包括mhc二聚体、四聚体、五聚体、八聚体等(综述于bakker和schumacher,current opinion in immunology2005,17:428-433)。例如,mhc多聚体可用于检测和纯化抗原特异性t细胞。因此,在另一方面,本公开提供了用于检测或纯化(分离、富集)对本文限定的tap具有特异性的cd8
t淋巴细胞的方法,该方法包括将细胞群与(共价或非共价地)负载有tap的mhc i类分子的多聚体接触;以及检测或分离被mhc i类多聚体结合的cd8
t淋巴细胞。可以使用已知方法分离被mhc i类多聚体结合的cd8
t淋巴细胞,例如荧光激活细胞分选(facs)或磁激活细胞分选(macs)。
[0166]
在又一方面,本公开提供了一种细胞(例如,宿主细胞),在实施方式中是一种分离的细胞,其包含本文提及的本公开的核酸、载体或质粒,即编码一种或多种tap。在另一方面,本公开提供了在其表面表达结合或呈递根据本公开的tap的mhc i类分子(例如,上文公开的等位基因中的一个的mhc i类分子)的细胞。在一种实施方式中,宿主细胞是真核细胞,诸如哺乳动物细胞,优选人细胞,细胞系或永生化细胞。在另一实施方式中,细胞是抗原呈递细胞(apc)。在一种实施方式中,宿主细胞是原代细胞、细胞系或永生化细胞。在另一实施
方式中,细胞是抗原呈递细胞(apc)。可以通过常规转化或转染技术将核酸和载体引入细胞中。术语“转化”和“转染”是指将外源核酸引入宿主细胞的技术,包括磷酸钙或氯化钙共沉淀、deae-葡聚糖介导的转染、脂质转染、电穿孔、显微注射和病毒介导的转染。转化或转染宿主细胞的合适方法可见于例如sambrook等人(同上)和其他实验室手册。在体内将核酸引入哺乳动物细胞的方法也是已知的,并且可用于将本公开的载体或质粒递送至受试者以进行基因治疗。
[0167]
可以使用本领域已知的多种方法将一种或多种tap负载至细胞(诸如apc)。如本文所用,用tap“负载细胞”是指将编码tap的rna或dna或者或tap转染至细胞中,或可选地,用编码tap的核酸转化apc。还可以通过将细胞与可以直接结合存在于细胞表面的mhc i类分子(例如,肽冲击细胞)的外源性tap接触来负载细胞。还可以将tap融合至促进其被mhc i类分子呈递的结构域或基序,例如融合至内质网(er)回收信号、c端lys-asp-glu-leu序列(参见wang等人,eur j immunol.2004dec;34(12):3582-94)。
[0168]
在另一方面,本公开提供了一种组合物或肽组合/池,其包含本文限定的tap(或编码所述肽的核酸)中的任一种或其任何组合。在一种实施方式中,组合物包含本文限定的tap的任何组合(2、3、4、5、6、7、8、9、10种或更多种tap的任何组合),或编码所述tap的核酸的组合)。本公开涵盖包含本文限定的tap的任何组合/亚组合的组合物。在另一实施方式中,组合或池可以包含一种或多种已知的肿瘤抗原。
[0169]
因此,在另一方面,本公开提供了一种组合物,其包含本文限定的tap中的任一种或其任何组合和表达mhc i类分子(例如,上文公开的等位基因中的一个的mhc i类分子)的细胞。用于本公开的apc不限于特定类型的细胞并且包括专职性apc,诸如树突状细胞(dc)、朗格汉斯细胞、巨噬细胞和b细胞,已知它们在其细胞表面呈递蛋白质抗原以被cd8
t淋巴细胞识别。例如,可以通过从外周血单核细胞中诱导dc,然后在体外、离体或体内接触(刺激)tap来获得apc。apc还可以被激活以在体内呈递tap,其中向受试者施用一种或多种本公开的tap并且在受试者体内诱导呈递tap的apc。短语“诱导apc”或“刺激apc”包括用一种或多种tap或编码tap的核酸接触或负载细胞,使得由mhc i类分子在其表面呈递tap。如本文所述,根据本公开,可以间接负载tap,例如使用包含tap序列的较长肽/多肽(包括天然蛋白质),然后在apc内对其进行处理(例如,通过蛋白酶)以在细胞表面产生tap/mhc i类复合物。在用tap负载apc并允许apc呈递tap后,apc可以作为疫苗被施用于受试者。例如,离体施用可以包括以下步骤:(a)从第一受试者收集apc,(b)将步骤(a)的apc与tap接触/负载,以在apc表面形成mhc i类/tap复合物;以及(c)向需要治疗的第二受试者施用负载有肽的apc。
[0170]
第一受试者和第二受试者可以是相同受试者(例如,自体疫苗),或者可以是不同受试者(例如,同种异体疫苗)。可选地,根据本公开,提供了本文所述的tap(或其组合)用于制造用于诱导抗原呈递细胞的组合物(例如,药物组合物)的用途。此外,本公开提供了生产用于诱导抗原呈递细胞的药物组合物的方法或工艺,其中该方法或工艺包括将tap或其组合与药学上可接受的载体混合或配制的步骤。表达负载有本文限定的tap中的任一种或任何组合的mhc i类分子(例如,hla-a1、hla-a2、hla-a3、hla-a11、hla-a24、hla-a25、hla-a29、hla-a32、hla-b07、hla-b08、hla-b14、hla-b15、hla-b18、hla-b39、hla-b40、hla-b44、hla-c03、hla-c04、hla-c05、hla-c06、hla-c07、hla-c12或hla-c14分子)的细胞,诸如apc,可用于刺激/扩增cd8
t淋巴细胞,例如自体cd8
t淋巴细胞。因此,在另一方面,本公开提供
了组合物,其包含本文限定的tap中的任一种或任何组合(或编码其的核酸或载体);表达mhc i类分子的细胞,以及t淋巴细胞,更特别地cd8
t淋巴细胞(例如,包含cd8
t淋巴细胞的细胞群)。
[0171]
在一种实施方式中,组合物还包含缓冲剂、赋形剂、载体、稀释剂和/或介质(例如,培养基)。在进一步的实施方式中,缓冲剂、赋形剂、载体、稀释剂和/或介质是药学上可接受的缓冲剂、赋形剂、载体、稀释剂和/或介质((多种)介质)。如本文所用,“药学上可接受的缓冲剂、赋形剂、载体、稀释剂和/或介质”包括任何和所有溶剂、缓冲剂、粘合剂、润滑剂、填充剂、增稠剂、崩解剂、增塑剂、包衣、阻隔层制剂、润滑剂、稳定剂、缓释剂、分散介质、包衣、抗细菌和抗真菌剂、等渗剂等,它们是生理学相容的,不干扰活性成分的生物活性的有效性并且对受试者无毒。此类基质和试剂用于药物活性物质的用途是本领域熟知的(rowe等人,handbook of pharmaceutical excipients,2003,第4版,pharmaceutical press,london uk)。除非任何常规基质或试剂与活性化合物(肽、细胞)不相容,否则预期将其用于本公开的组合物中。在一种实施方式中,缓冲液、赋形剂、载体和/或介质是非天然存在的缓冲液、赋形剂、载体和/或介质。在一种实施方式中,本文限定的一种或多种tap,或编码所述一种或多种tap的核酸(例如,mrna)包含在脂质体(例如阳离子脂质体)或其他合适的载体内或与其复合(参见,例如,vitor mt等人,recent pat drug deliv formul.2013aug;7(2):99-110)。
[0172]
在另一方面,本公开提供了组合物,其包含本文限定的tap中的任一种或任何组合(或编码所述肽的核酸)以及缓冲剂、赋形剂、载体、稀释剂和/或介质中的一种或多种。对于包含细胞(例如,apc、t淋巴细胞)的组合物,该组合物包含实现维持活细胞的合适介质。此类介质的典型实例包括盐溶液、earl’s平衡盐溶液(life )或(baxter)。在一种实施方式中,组合物(例如药物组合物)是“免疫原性组合物”、“疫苗组合物”或“疫苗”。如本文所用,术语“免疫原性组合物”、“疫苗组合物”或“疫苗”是指包含一种或多种tap或疫苗载体的组合物或制剂,并且当施用于受试者时,其能够诱导针对其中存在的一种或多种tap的免疫应答。用于在哺乳动物中诱导免疫应答的疫苗接种方法包括使用疫苗或疫苗载体通过疫苗领域已知的任何常规途径施用,例如通过粘膜(例如,眼、鼻、肺、口腔、胃、肠、直肠、阴道或泌尿道)表面,通过肠胃外(例如,皮下、皮内、肌内、静脉内或腹腔)途径,或外用(例如,通过经皮递送系统,诸如贴剂)。在一种实施方式中,tap(或其组合)与载体蛋白缀合(缀合疫苗)以增加tap的免疫原性。因此,本公开提供了包含tap(或其组合)、或编码tap或其组合的核酸以及载体蛋白的组合物(缀合物)。例如,tap或核酸可以与toll样受体(tlr)配体(参见,例如,zom等人,adv immunol.2012,114:177-201)或聚合物/树枝状聚合物(参见,例如,liu等人,biomacromolecules.2013aug 12;14(8):2798-806)缀合或复合。在一种实施方式中,免疫原性组合物或疫苗还包含佐剂。“佐剂”是指当添加至免疫原性试剂诸如抗原(根据本公开的tap、核酸和/或细胞)时,在暴露于混合物后非特异性地增强或加强宿主中对该试剂的免疫应答的物质。目前用于疫苗领域的佐剂的实例包括(1)矿物盐(铝盐诸如磷酸铝和氢氧化铝、磷酸钙凝胶)、角鲨烯,(2)油基佐剂,诸如基于油乳剂和表面活性剂的制剂,例如mf59(微流化洗涤剂稳定的水包油乳液)、qs21(纯化皂苷)、as02[sbas2](水包油乳液 mpl qs-21),(3)颗粒佐剂,例如病毒微体(包含流感血凝素的单层脂质体负载体)、as04([sbas4]铝盐与mpl)、iscoms(皂苷和脂质的结构化复合物)、聚丙交酯co-乙交酯(plg),(4)微生物衍生物(天然的和合成的),例如,单磷酰脂
质a(mpl)、detox(mpl 草分枝杆菌(m.phlei)细胞壁骨架)、agp[rc-529](合成的酰化单糖)、dc_chol(能够自组织成脂质体的类脂免疫刺激剂)、om-174(脂质a衍生物)、cpg基序(含有免疫刺激性cpg基序的合成寡核苷酸)、改性lt和ct(基因改性的细菌毒素以提供无毒佐剂效果),(5)内源性人免疫调节剂,例如hgm-csf或hil-12(可以作为蛋白质或编码质粒施用的细胞因子)、immudaptin(c3d串联阵列),和/或(6)惰性负载体,诸如金颗粒等。
[0173]
在一种实施方式中,tap或包含其的组合物是冻干形式。在另一实施方式中,tap或包含其的组合物在液体组合物中。在进一步的实施方式中,在组合物中tap的浓度为约0.01μg/ml至约100μg/ml。在进一步的实施方式中,组合物中tap的浓度为约0.2μg/ml至约50μg/ml,约0.5μg/ml至约10、20、30、40或50μg/ml,约1μg/ml至约10μg/ml,或约2μg/ml。
[0174]
如本文所述,表达负载有或结合本文限定的tap中的任一种或任何组合的mhc i类分子的细胞,诸如apc,可用于体内或离体刺激/扩增cd8
t淋巴细胞。因此,在另一方面,本公开提供了能够与本文提及的mhc i类分子/tap复合物相互作用或结合的t细胞受体(tcr)分子,以及编码此类tcr分子的核酸分子,以及包含此类核酸分子的载体。根据本公开的tcr能够特异性地与tap相互作用或结合,该tap负载于mhc i类分子上或由mhc i类分子呈递,优选地在体外或体内活细胞表面上。
[0175]
在一种实施方式中,根据本公开的抗白血病(例如,抗aml)tcr包含包含互补决定区3(cdr3)的tcrβ(β)链,该互补决定区3(cdr3)包含seq id no:191-219中列出的氨基酸序列中的一个。
[0176]
在一种实施方式中,tcr对以下tap中的一个或多个具有特异性:sllsgllra、alpvalpsl、aldplllri iaspiall和/或sldllplsi,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap sllsgllra具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap alpvalpsl具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap aldplllri具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap iaspiall具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap sldllplsi具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:191-199中列出的氨基酸序列中的一个。
[0177]
在另一实施方式中,tcr对以下tap中的一个或多个具有特异性:ltdriyltl、vlfggkvsga、lgisltlky、fnvalnary和/或tlnqginvyi,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap ltdriyltl具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap vlfggkvsga具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap lgisltlky具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap fnvalnary具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap tlnqginvyi具有特异性,并且包
含包含cdr3的tcrβ链,该cdr3包含seq id no:200-209中列出的氨基酸序列中的一个。
[0178]
在另一实施方式中,tcr对以下tap中的一个或多个具有特异性:lrsqilsy、kildvnlri、hslisivyl、klqdkeigl和/或aqdiilqav,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap lrsqilsy具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap kildvnlri具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap hslisivyl具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap klqdkeigl具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。在一种实施方式中,tcr对tap aqdiilqav具有特异性,并且包含包含cdr3的tcrβ链,该cdr3包含seq id no:210-219中列出的氨基酸序列中的一个。
[0179]
在一种实施方式中,根据本公开的tcr识别与hla-a*02:01、hla-a*29:02、hla-b*15:01、hla-b27:05、hla-c*01:02和/或hla-c*03:04分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-a*02:01分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-a*29:02分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-b*15:01分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-b27:05分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-c*01:02分子结合的上述tap中的一种或多种。在一种实施方式中,根据本公开的tcr识别与hla-c*03:04分子结合的上述tap中的一种或多种。
[0180]
如本文所用,术语tcr是指具有可变结合结构域、恒定结构域、跨膜区和短胞质尾的免疫球蛋白超家族成员;参见,例如,janeway等人,immunobiology:the immune system in health and disease,第3版,current biology publications,p.4:33,1997),其能够特异性结合与mhc受体结合的抗原肽。tcr可见于细胞表面上,通常由具有α和β链的异二聚体(也分别称为tcrα和tcrβ)组成。如免疫球蛋白,tcr链的细胞外部分(例如,α-链、β-链)含有两个免疫球蛋白区、可变区(例如,tcr可变α区或vα和tcr可变β区或vβ;通常基于n-末端处的rabat编号的氨基酸1至116),和与细胞膜相邻的一个恒定区(例如,tcr恒定结构域α或cα和通常基于rabat的氨基酸117至259,tcr恒定结构域β或cβ,通常基于rabat的氨基酸117至295)。此外,如免疫球蛋白,可变结构域含有由框架区(fr)分隔的互补决定区(cdr,每条链中3个)。在某些实施方式中,tcr可见于t细胞(或t淋巴细胞)的表面上并且与cd3复合物缔合。
[0181]
tcr,且特别是编码本公开的tcr的核酸可以例如应用于基因转化/改性t淋巴细胞(例如,cd8
t淋巴细胞)或其他类型的淋巴细胞,产生特异性识别mhc i类/tap肽复合物的新t淋巴细胞克隆。在具体实施方式中,从患者获得的t淋巴细胞(例如,cd8
t淋巴细胞)被转化以表达一种或多种识别tap的tcr,并将转化的细胞施用于患者(自体细胞输血)。在具体实施方式中,从供体获得的t淋巴细胞(例如cd8
t淋巴细胞)被转化以表达一种或多种识别tap的tcr,并将转化的细胞施用于接受者(同种异体细胞输血)。在另一实施方式中,本公开提供了t淋巴细胞,例如,被编码tap特异性tcr的载体或质粒转化/转染的cd8
t淋巴细胞。在另一实施方式中,本公开提供了使用用tap特异性tcr转化的自体或同种异体细胞治
疗患者的方法。在某些实施方式中,通过使用例如crispr、talen、锌指或其他靶向破坏系统替换内源性基因座(例如内源性trac和/或trbc基因座),tcr在原代t细胞(例如,细胞毒性t细胞)中表达。
[0182]
在另一实施方式中,本公开提供了编码上述tcr的核酸。在进一步的实施方式中,核酸存在于载体(诸如上述载体)中。
[0183]
在又一实施方式中,提供了肿瘤抗原特异性tcr在制造用于治疗癌症(白血病,诸如aml)的自体或同种异体细胞中的用途。
[0184]
在一些实施方式中,在用同种异体干细胞移植(ascl)、同种异体淋巴细胞输注或自体淋巴细胞输注治疗之前或之后治疗用本公开的组合物(例如,药物组合物)治疗的患者。本公开的组合物包括:针对tap离体激活的同种异体t淋巴细胞(例如,cd8
t淋巴细胞);负载有tap的同种异体或自体apc疫苗;tap疫苗以及用肿瘤抗原特异性tcr转化的同种异体或自体t淋巴细胞(例如,cd8
t淋巴细胞)或淋巴细胞。根据本公开的提供能够识别tap的t淋巴细胞克隆的方法可以特异性靶向受试者(例如,移植接受者),例如asct和/或供体淋巴细胞输注(dli)接受者中表达tap的肿瘤细胞并且可以针对其产生。因此,本公开提供了编码和表达能够特异性识别或结合tap/mhc i类分子复合物的t细胞受体的cd8
t淋巴细胞。所述t淋巴细胞(例如,cd8
t淋巴细胞)可以是重组的(工程化的)或天然选择的t淋巴细胞。因此,本说明书提供了至少两种用于产生本公开的cd8
t淋巴细胞的方法,其包括在有利于触发t细胞激活和扩增的条件下使未分化的淋巴细胞与tap/mhc i类分子复合物(通常在细胞诸如apc表面表达)接触的步骤,这可以在体外或体内(即在施用了apc疫苗的患者中,其中apc负载有tap,或在用tap疫苗治疗的患者中)进行。使用与mhc i类分子结合的tap的组合或池,可能产生能够识别多种tap的cd8
t淋巴细胞群。可选地,肿瘤抗原特异性或靶向肿瘤抗原的t淋巴细胞可以通过克隆编码与mhc i类分子/tap复合物特异性结合的tcr(更特别地α和β链)的一种或多种核酸(基因)在体外或离体生产/产生(即工程化的或重组的cd8
t淋巴细胞)。编码本公开的tap特异性tcr的核酸可以使用本领域已知的方法从针对tap离体激活的t淋巴细胞(例如,用负载有tap的apc)获得;或从对肽/mhc分子复合物表现出免疫应答的个体获得。本公开的tap特异性tcr可以在从移植接受者或移植供体获得的宿主细胞和/或宿主淋巴细胞中重组表达,并且任选地在体外分化以提供细胞毒性t淋巴细胞(ctl)。可以使用任何合适的方法诸如转染(例如,电穿孔)或转导(例如,使用病毒载体),诸如磷酸钙-dna共沉淀、deae-葡聚糖介导的转染、聚凝胺介导的转染、电穿孔、显微注射、脂质体融合、脂质转染、原生质体融合、逆转录病毒感染和基因枪法,将编码tcrα和β链的核酸(转基因)引入到t细胞(例如,来自待治疗的受试者或其他个体)中。可以使用熟知的培养方法在体外扩增表达对tap具有特异性的tcr的工程化cd8
t淋巴细胞。
[0185]
本公开提供了制备表达如本文所述的tcr的免疫效应细胞的方法。在一种实施方式中,该方法包括转染或转导免疫效应细胞,例如,从受试者,诸如患有白血病(例如,aml)的受试者分离的免疫效应细胞,使得免疫效应细胞表达一种或多种如本文所述的tcr。在某些实施方式中,免疫效应细胞分离自个体并且在体外没有进一步操作的情况下进行基因修饰。然后可以将此类细胞直接重新施用于个体中。在进一步的实施方式中,免疫效应细胞在经基因修饰以表达tcr之前首先在体外被激活和刺激以增殖。在这方面,免疫效应细胞可以在经遗传修饰(即,如本文所述被转导或转染以表达tcr)之前或之后培养。
[0186]
在本文所述的免疫效应细胞的体外操作或遗传修饰之前,细胞来源可以获自受试者。特别地,与本文所述的tcr一起使用的免疫效应细胞包括t细胞。t细胞可以获自多种来源,包括外周血单个核细胞(pbmc)、骨髓、淋巴结组织、脐带血、胸腺组织、感染部位的组织、腹水、胸腔积液、脾组织和肿瘤。在某些实施方式中,使用本领域技术人员已知的任何数量的技术,诸如ficoll
tm
分离,t细胞可以获自从受试者收集的单位血液。在一种实施方式中,来自个体循环血液的细胞通过单采术获得。单采产物通常含有淋巴细胞,包括t细胞、单核细胞、粒细胞、b细胞、其他有核白细胞、红细胞和血小板。在一种实施方式中,可以洗涤通过单采术收集的细胞以移除血浆级分并将细胞置于适当的缓冲液或介质中用于后续处理。在本发明的一种实施方式中,细胞用pbs洗涤。在可选的实施方式中,洗涤后的溶液缺乏钙并且可能缺乏镁或可能缺乏许多(如果并非全部)二价阳离子。如本领域普通技术人员将理解的,洗涤步骤可以通过本领域技术人员已知的方法来完成,诸如通过使用半自动流通式离心机。洗涤后,可以将细胞重悬于各种生物相容性缓冲液或其他含或不含缓冲液的盐水溶液中。在某些实施方式中,可以在细胞直接重悬培养基中移除单采样本的非期望组分。在某些实施方式中,通过裂解红细胞并耗竭单核细胞,例如通过percoll
tm
梯度离心,从外周血单核细胞(pbmc)分离t细胞。可以通过阳性或阴性选择技术进一步分离特定的t细胞亚群,诸如cd28 、cd4 、cd8 、cd45ra 和cd45ro t细胞。例如,通过负选择的t细胞群的富集可以用针对负选择细胞特有的表面标志物的抗体组合来完成。一种用于本文的方法是通过负磁免疫粘附或流式细胞术的细胞分选和/或选择,其使用针对存在于负选择的细胞上的细胞表面标志物的单克隆抗体混合物。例如,为了通过负选择富集cd8 细胞,单克隆抗体混合物通常包括针对cd14、cd20、cd11b、cd16、hla-dr和cd4的抗体。流式细胞术和细胞分选也可用于分离目的细胞群以用于本公开。pbmc可以直接用于使用本文所述的方法用tcr进行遗传修饰。在某些实施方式中,在分离pbmc后,进一步分离t淋巴细胞,并且在某些实施方式中,细胞毒性和辅助t淋巴细胞可在遗传修饰和/或扩增之前或之后分选成幼稚、记忆和效应t细胞亚群。
[0187]
本公开提供了分离的免疫细胞,诸如cd8
t淋巴细胞,其被tap(即与在细胞表面表达的mhc i类分子结合的tap)或tap的组合特异性诱导、激活和/或扩增(扩大)。本公开还提供了组合物,其包含能够识别根据本公开的tap或其组合(即,一种或多种与mhc i类分子结合的tap)的cd8
t淋巴细胞和所述tap。在另一方面,本公开提供了细胞群或细胞培养物(例如,cd8
t淋巴细胞群),其富集特异性识别如本文所述的一种或多种mhc i类分子/tap复合物的cd8
t淋巴细胞。这种富集的群体可以通过使用细胞诸如表达负载有(例如呈递)本文公开的一种或多种tap的mhc i类分子的apc进行特异性t淋巴细胞的离体扩增来获得。如本文所用,“富集”是指群体中肿瘤抗原特异性cd8
t淋巴细胞的比例相对于天然细胞群(即未经历特异性t淋巴细胞的离体扩增步骤)显著更高。在进一步的实施方式中,细胞群中tap特异性cd8
t淋巴细胞的比例为至少约0.5%,例如至少约1%、1.5%、2%或3%。在一些实施方式中,细胞群中tap特异性cd8
t淋巴细胞的比例为约0.5至约10%、约0.5至约8%、约0.5至约5%、约0.5至约4%、约0.5至约3%、约1%至约5%、约1%至约4%、约1%至约3%、约2%至约5%、约2%至约4%、约2%至约3%、约3%至约5%或约3%至约4%。这种富集特异性识别一种或多种目的mhc i类分子/肽(tap)复合物的cd8
t淋巴细胞的细胞群或培养物(例如,cd8
t淋巴细胞群)可用于基于肿瘤抗原的癌症免疫疗法,如下详述。在一些实施方式中,进一步富集tap特异性cd8
t淋巴细胞群,例如使用基于亲和力的系统,诸如(共价或
非共价地)负载有本文限定的tap的mhc i类分子的多聚体。因此,本公开提供了纯化或分离的tap特异性cd8
t淋巴细胞群,例如,其中tap特异性cd8
t淋巴细胞的比例为至少约50%、60%、70%、80%、85%、90%、95%、96%、97%、98%、99%或100%。
[0188]
本公开进一步涉及包含上述免疫细胞(cd8
t淋巴细胞)或tap特异性cd8
t淋巴细胞群的药物组合物或疫苗。此类药物组合物或疫苗可以包含一种或多种药学上可接受的赋形剂和/或佐剂,如上所述。
[0189]
本公开进一步涉及根据本公开的任何tap、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或组合物或其任何组合作为药物或在药物制造中的用途。在一种实施方式中,药物用于治疗癌症,例如,癌症疫苗。本公开涉及根据本公开的任何tap、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或组合物(例如,疫苗组合物)或其任何组合,用于治疗癌症的用途,例如,作为癌症疫苗。本文识别的tap序列可用于产生合成肽,以用于i)体外引发和扩增肿瘤抗原特异性t细胞以注射到肿瘤患者,和/或ii)作为疫苗以诱导或增强癌症患者的抗肿瘤t细胞应答。
[0190]
在另一方面,本公开提供了本文所述的tap(seq id no:1-190,优选seq id no:97-154)或其组合(例如肽池)作为用于治疗受试者的癌症的疫苗的用途。本公开还提供了本文所述的tap或其组合(例如肽池),用作用于治疗受试者癌症的疫苗。在一种实施方式中,受试者是tap特异性cd8
t淋巴细胞的接受者。因此,在另一方面,本公开提供了治疗癌症的方法(例如,减少肿瘤细胞的数量、杀死肿瘤细胞),所述方法包括向有需要的受试者施用(输注)有效量的识别(即表达结合其的tcr)一种或多种mhc i类分子/tap复合物(在细胞(诸如apc)的表面表达)的cd8
t淋巴细胞。在一种实施方式中,该方法进一步包括,在施用/输注所述cd8
t淋巴细胞之后,向所述受试者施用有效量的tap或其组合和/或表达负载有tap的mhc i类分子的细胞(例如,apc,诸如树突状细胞)。在又一实施方式中,该方法包括向有需要的受试者施用治疗有效量的负载有一种或多种tap的树突状细胞。在又一实施方式中,该方法包括向有需要的患者施用治疗有效量的同种异体或自体细胞,该细胞表达与mhc i类分子呈递的tap结合的重组tcr。
[0191]
在另一方面,本公开提供了识别一种或多种负载有(呈递)tap或其组合的mhc i类分子的cd8
t淋巴细胞用于治疗受试者的癌症(例如,减少肿瘤细胞数量、杀死肿瘤细胞)的用途。在另一方面,本公开提供了识别一种或多种负载有(呈递)tap或其组合的mhc i类分子的cd8
t淋巴细胞用于制备/制造用于治疗受试者的癌症(例如,减少肿瘤细胞数量、杀死肿瘤细胞)的药物的用途。在另一方面,本公开提供了识别一种或多种负载有(呈递)tap或其组合的mhc i类分子的cd8 t淋巴细胞(细胞毒性t淋巴细胞),用于治疗受试者的癌症(例如,减少肿瘤细胞数量、杀死肿瘤细胞)的用途。在进一步的实施方式中,该用途还包括,在使用所述tap特异性cd8
t淋巴细胞之后,使用有效量的tap(或其组合)和/或表达一种或多种负载有(呈递)tap的mhc i类分子的细胞(例如,apc)。
[0192]
本公开还提供了在受试者中产生针对表达负载有本文公开的任何tap或其组合的人i类mhc分子的肿瘤细胞(白血病细胞,aml细胞)的免疫应答的方法,该方法包括施用特异性识别负载有tap或tap的组合的i类mhc分子的细胞毒性t淋巴细胞。本公开还提供了特异性识别负载有本文公开的任何tap或tap的组合的i类mhc分子的细胞毒性t淋巴细胞用于产生针对表达负载有tap或其组合的人i类mhc分子的肿瘤细胞的免疫应答的用途。
[0193]
在一种实施方式中,本文所述的方法或用途进一步包括在治疗/使用之前确定由患者表达的hla i类等位基因,并施用或使用与由患者表达的一种或多种hla i类等位基因结合的tap。例如,如果确定患者表达hla-a1*01和hla-c05*01,则可以在患者中施用或使用以下tap的任何组合:(i)seq id no:48、67、89、134、151和/或164(结合hla-a1*01),和/或(iii)seq id no:150(结合hla-c05*01)。
[0194]
在一种实施方式中,癌症是血液癌症,优选白血病,诸如急性淋巴细胞白血病(all)、急性髓系白血病(aml)、慢性髓系白血病(cml)、毛细胞白血病(hcl)和骨髓增生异常综合征(mds)。在一种实施方式中,白血病是aml。通过本文所述的方法和用途治疗的aml可以是任何类型或亚型(例如,低风险、中风险或高风险aml),例如aml伴有遗传异常,诸如aml伴有8号和21号染色体之间易位t(8;21)]、aml伴有16号染色体易位或倒位[t(16;16)或inv(16)]、aml伴有pml-rara融合基因、aml伴有9号和11号染色体之间易位[t(9;11)]、aml伴有6号和9号染色体之间易位[t(6:9)]、aml伴有3号染色体易位或倒位[t(3;3)或inv(3)]、aml(巨核细胞)伴有1号和22号染色体之间易位[t(1:22)]、aml伴有bcr-abl1(bcr-abl)融合基因、aml伴有npm1基因突变、aml伴有cebpa基因双等位基因突变、aml伴有runx1基因突变、aml伴有asx1基因突变、aml伴有idh1和/或idh2基因突变、aml伴有flt3基因突变、aml伴有骨髓增生异常相关变化以及与既往化疗或放射疗法相关的aml。
[0195]
在一种实施方式中,根据本公开的tap、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或组合物或其任何组合,可以与一种或多种另外的活性剂或治疗癌症的疗法组合使用以治疗癌症,诸如化疗(例如,长春花生物碱、破坏微管形成的剂(诸如秋水仙碱及其衍生物)、抗血管生成剂、治疗性抗体、egfr靶向剂、酪氨酸激酶靶向剂(诸如酪氨酸激酶抑制剂)、过渡金属配合物、蛋白酶体抑制剂、抗代谢物(诸如核苷类似物)、烷化剂、铂类药物、蒽环类抗生素、拓扑异构酶抑制剂、大环内酯类、类视黄醇类(诸如全反式视黄酸或其衍生物)、格尔德霉素或其衍生物(诸如17-aag)、手术、放射疗法、免疫检查点抑制剂(免疫治疗剂(例如,pd-1/pd-l1抑制剂(诸如抗pd-1/pd-l1抗体)、ctla-4抑制剂(诸如抗ctla-4抗体)、b7-1/b7-2抑制剂(诸如抗b7-1/b7-2抗体)、tim3抑制剂(诸如抗tim3抗体)、btla抑制剂(诸如抗btla抗体)、cd47抑制剂(诸如抗cd47抗体)、gitr抑制剂(诸如抗gitr抗体)、针对肿瘤抗原的抗体、基于细胞的疗法(例如,car t细胞、car nk细胞)、细胞因子(诸如il-2、il-7、il-21和il-15)。在一种实施方式中,根据本公开的tap肽、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或组合物与免疫检查点抑制剂组合施用/使用。在一种实施方式中,tap、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或根据本公开的组合物与一种或多种用于治疗aml的化疗药物组合施用/使用,或与其他aml疗法(例如干细胞/骨髓移植)组合施用/使用。
[0196]
可以在施用根据本公开的tap、核酸、表达载体、t细胞受体、细胞(例如,t淋巴细胞、apc)和/或组合物之前、同时或之后施用另外的疗法。
[0197]
实施本发明的方式
[0198]
通过以下非限制性实施例进一步详细说明本发明。
[0199]
实施例1:材料和方法
[0200]
aml试样
[0201]
诊断性aml样本(dmso冷冻白血病母细胞冷冻管)获自banque de cellules leuc
é
miques du qu
é
bec计划(bclq,bclq.org)。样本技术和临床特征在表1中提供。将每个aml样本的一亿个细胞(14h124除外,见下文)解冻(在37℃水浴中1min)并重悬于48ml的4℃ pbs中。将200万个细胞(1ml)沉淀并重悬于1ml trizol中用于rna测序,而将剩余的9800万个细胞沉淀并在液氮中速冻用于质谱分析。
[0202]
表1:本研究中用于识别tsa的19个aml试样的生物学和临床特征。
[0203]
[0204]
[0205]
[0206]
[0207][0208]
nc:无法按fab标准分类。基于每个样本的rna-seq数据通过optitype确定hla。临床数据由banque de cellules leuc
é
miques du qu
é
bec计划(bclq,bclq.org)提供。
[0209]
其他数据来源
[0210]
人mtec样本已根据我们团队先前研究的需要进行制备和测序(#gse127825和#gse127826)(larouche等人,2020;laumont等人,2018),或已由其他人公开(e-mtab-7383)(fergusson等人,2018)。只有我们小组先前用于tsa发现的六个mtec样本已用于k-mer耗竭方法(laumont等人,2018)。用作主要正常对照的11个mpc样本已由iric基因组平台测序,并由leucegene小组先前公开(#gse98310,#gse51984)。本研究中使用的所有其他正常样本均
已从dbgap(www.ncbi.nlm.nih.gov/gap/),arrayexpress(www.ebi.ac.uk/arrayexpress/)或geo(www.ncbi.nlm.nih.gov/geo/)下载。leucegene全队列437个rna测序的aml样本用于研究发现的tsa
hi
的临床意义。rna测序数据之前已公开,并可单独获得(#gse49642、#gse52656、#gse62190、#gse66917、#gse67039)(lavallee等人,2015;macrae等人,2013;pabst等人,2016)。分类的lsc和母细胞的rna-seq数据已在其他地方公开,并从#gse74246(corces等人,2016)获得。复发前和复发后aml母细胞的rna-seq数据(匹配样本)已在其他地方公开(toffalori等人,2019),这些样本的hla类型由luca vago博士友情提供。从外部来源获得的所有数据均使用star v2.5.1b在grch38基因组上进行比对。
[0211]
nsg小鼠中14h124 aml细胞的扩增
[0212]
由于该患者仅可获得2000万个细胞,因此已将患者14h124的母细胞解冻,在pbs中洗涤,并在亚致死全身辐照(2.5gy,137cs-γ源)后24h静脉内注射至10只nod-scid il-2rγnull
(nsg)
小鼠(2
×
106/小鼠)。在第122天通过流式细胞术在外周血中评估人aml细胞移植。简言之,通过尾静脉取血收集100μl血液,使用rbc裂解缓冲液(ebioscience)移除红细胞,在染色缓冲液(pbs 3%fbs)中洗涤,用抗人cd45-pacificblue(hi30,biolegend)和抗小鼠cd45-pecy5(30-f11,bd)在4℃下染色20min并在pbs中洗涤。在facs canto ii流式细胞仪(becton dickinson)上采集数据并使用软件7.0(tree star inc.,ashland,or)进行分析。
[0213]
在8/10小鼠中发现高于1%的人细胞嵌合体。移植后第188-264天,在出现疾病体征(贫血、体重减轻》20%或明显肿瘤)时处死小鼠,并收集骨髓、脾和实体瘤(可见于肩胛间、颈部和臀部区域或肾脏、肝脏和淋巴结)。肿瘤在液氮中快速冷冻,用于未来通过质谱进行处理。通过粉碎脾并用4℃ pbs冲洗股骨和胫骨(收集骨髓)来收集aml细胞。移除细胞中的红细胞,过滤(100μm)以移除碎片,计数并按上述方法进行流式细胞术(5
×
105个细胞)处理以评估其纯度,或者在(invitrogen)中裂解和冷冻保存用于未来的rna测序(所有剩余的细胞)。选择一个大小》1cm3且具有600万个纯度》99%的骨髓来源的母细胞(图14a-b)可用于rna测序的肿瘤进行处理,以通过质谱识别map。在第122天外周血中没有人嵌合体(移植失败)的两只小鼠没有出现任何疾病体征,并在实验结束时(第264天)处死。所有处死均通过co2窒息和颈脱位人道地进行。每周三次评估小鼠的疾病体征,并在实验期间每天监测。
[0214]
rna提取、文库制备和测序
[0215]
使用/氯仿提取和在mini提取柱(qiagen)上的纯化完成rna提取。400ng的总rna用于文库制备。使用bioanalyzer nano(agilent)评估总rna的质量,所有样本的rin均高于8。使用kapa mrnaseq hyperprep试剂盒(kapa,货号kk8581)进行文库制备。使用终浓度为51nm的illumina truseq index进行连接,扩增cdna文库需要12个pcr循环。样本14h124分别使用4m细胞、1ug的总rna进行。除了扩增使用10个pcr循环而不是12个循环完成之外,文库制备如先前样本进行。通过qubit和bioanalyzer dna1000对文库进行定量。所有文库均稀释至10nm,并使用kapa文库定量试剂盒(kapa;货号kk4973)通过qpcr归一化。将文库合并为等摩尔浓度。用illumina nextseq500使用nextseq high output kit150个循环(2x80bp)使用2.8pm的合并文库进行测序。每个样本产生约120-200m双末端pf读数。文库制备和测序在免疫学和癌症研究所的基因组学平台(iric)进行。
[0216]
用于鸟枪质谱识别的数据库生成
[0217]
1)个性化典型蛋白质组的生成。如前所述开展(laumont等人,2018)。简言之,使用trimmomatic v0.35修剪rna-seq读数,并使用star v2.5.1b与grch38.88比对(dobin等人,2013),使用除了
‑‑
alignsjoverhangmin、
‑‑
alignmatesgapmax、
‑‑
alignintronmax和
‑‑
alignsjstitchmismatchnmax参数之外的默认参数运行,其默认值分别替换为10、200,000、200,000和“5
ꢀ‑
1 55”,以生成bam文件。使用freebayes 1.0.2-16-gd466dde(arxiv:1207.3907)识别最小交替计数设置为5的单碱基突变。使用默认参数,用kallisto v0.43.0(bray等人,2016)以每百万转录物(tpm)定量转录表达。最后,使用pygeno在参考外显子组中插入高质量的样本特异性单碱基突变(freeebayes质量》20),并导出由表达的转录物(tpm》0)生成的已知蛋白质的样本特异性序列,以生成个性化的经典蛋白质组。
[0218]
2)通过mtec k-mer耗竭生成aml特异性蛋白质组(图2a)。如前所述开展(laumont等人,2018)。简言之,每个样本的r1和r2 fastq文件按照上述报告进行修剪,并使用fastx-toolkit v0.0.14的fastx_reverse_complement函数对r1读数进行反向补充。使用jellyfish v2.2.3(marcais and kingsford,2011)生成k-mer数据库(24或33长)。针对每个aml样本生成单个数据库,而6个mtec样本通过连接它们的fastq文件组合在唯一的数据库中。由于k-mer组装的持续时间(见下文)在超过3000万k-mer时呈指数增长,因此每个aml 33个核苷酸长的k-mer数据库基于发生时的样本特定阈值(给定k-mer在数据库中出现的次数)过滤,以在组装步骤中达到最多3000万个k-mer(表1)。在此过滤之后,从每个样本数据库中移除mtec k-mer数据库中至少存在一次的k-mer,并使用内部开发的软件nektar将剩余的k-mer组装成重叠群。简言之,随机选择提交的33个核苷酸长的k-mer中的一个作为种子,该种子从两端延伸,连续的k-mer在同一条链上重叠32个核苷酸(禁用-r选项,作为k-mers的链集使用)。当无法组装k-mer或有多于一个k-mer符合时(
–
a线性组装的1个选项),组装过程将停止。如果是这样,则选择新种子并继续组装过程,直到提交列表中的所有k-mers均已使用一次。最后,使用内部python脚本对重叠群进行3框翻译,在内部终止密码子处拆分氨基酸序列,并将得到的子序列与每个样本各自的个性化典型蛋白质组连接。
[0219]
3)ere特异性蛋白质组的生成(图2b)。对于每个样本,用star(dobin等人,2013)使用默认参数在人参考基因组(grch38.88)上比对rna-seq读数。使用bedtools(pmid 20110278)的intersect函数,读取在两个读取数据集中分离,完全映射到ere序列或典型基因中。如果它们的序列也存在于典型读数数据集中,则弃去ere读数数据集的读数。然后使用samtools视图(pmid 19505943)从ere读数数据集中弃去未映射的读取、二级比对和低质量读数。然后将剩余的ere读数在计算机上翻译成所有可能阅读框中的ere多肽。ere多肽在终止密码子位置剪接,弃去下游序列,仅保留≥8个氨基酸的上游序列(即map的最小长度)。然后将得到的ere蛋白质组与相应样本的个性化典型蛋白质组连接。
[0220]
4)通过mtec mpc k-mer耗竭生成aml特异性蛋白质组(图2c)。为了进行这种方法,使用与mtec k-mer耗竭相同的方法,并进行以下修改:(i)使用jellyfish生成另外的正常k-mer数据库,结合11个用作k-mer对照的mpc样本的fastq文件。因为这些样本没有以链模式测序,所以k-mer数据库是使用-c选项生成的,并且r1 fastq文件未反向补充。(ii)移除mtec或mpc k-mer数据库中存在的aml k-mer,因此通过此步骤过滤的k-mer的数量大于mtec k-mer耗竭方法中的数量。(iii)由于正常样本的k-mer耗竭效率较高,因此可以使用
较低的发生阈值来预过滤aml k-mer(表1和图7c),与仅mtec k-mer耗竭相比,这些数据库中存在的k-mer的同一性发生了显著变化(图7d)。重要的是,没有使用低于3的发生阈值来排除可能的测序错误。所有其他程序均按照“通过mtec k-mer耗竭生成aml特异性蛋白质组”部分中报告的进行。
[0221]
5)通过差异k-mer表达生成aml特异性蛋白质组(图2d)。差异k-mer分析基于de-kupl的定制使用进行,de-kupl是一种计算流程,用于从fastq文件生成k-mer数据库、k-mer丰度的标准化、基于k-mer的过滤它们的发生及其样本间共享、通过使用统计测试比较两种不同条件下样本之间的k-mer丰度、将差异表达的k-mer组装成重叠群、基因组上重叠群的比对和基于其基因组比对的重叠群注释(图8)(audoux等人,2017)。具体地,首先使用以下参数diff_method ttest、kmer_length 33、gene_diff_method limma-voom,data_type wgs、lib_type unstranded、min_recurrence 6、min_recurrence_abundance 3、pvalue_threshold 0.05和log2fc_threshold 0.1进行de-kupl运行,以将aml样本与11个mpc对照进行比较。这返回diff-counts.tsv文件,其中包含aml和mpc样本之间显著差异表达的33个核苷酸长k-mes(fdr《0.05)的序列和归一化计数,并且在至少6个样本中最少出现3个样本(mpc或aml)。由于需要自定义k-mer过滤规则,因此对de-kupl(log2fc_threshold 0.1)中的k-mer倍数变化没有应用任何限制,并且手动过滤diff-counts.tsv文件中提供的k-mer列表以保持所有k-mer(i)在所有mpc样本中完全不存在(计数=0)(因此存在于至少6个aml样本中);或(ii)存在于至少6个aml样本中(》30%的样本)并且倍数变化≥10倍;或(iii)存在于单个mpc样本中,其丰度低于aml样本中的最低丰度;或(iv)存在于至少6个aml样本中,倍数变化≥5倍且fdr≤0.000001。基于这些规则,生成含有~41
×
106k-mer的新diff-counts.tsv文件,并用于通过de-kupl执行k-mer组装,以及获得含有~2.1
×
106重叠群的merge-diff-counts.tsv文件。最后,使用de-kupl的annot函数对grch38人类基因组上生成的重叠群进行映射和注释。
[0222]
为了获得每个aml样本的个性化重叠群序列,de-kupl annot的diffcontigsinfos.tsv输出用于构建长度≥34个核苷酸(源自至少2k-mer的组装)的所有重叠群的bed文件,并且其对齐没有空位、插入或缺失(没有n/d/i的cigar)。接下来,使用此bed文件以及bedtools、samtools和bcftools套件从每个aml样本(samtools mpileup-c50-uf ref_genome.fasta sample.bam|bcftools call-c|vcfutils.pl vcf2fq-d 8-d 100|awk'/^@chr.$|^chr..$|^@gl........$|^@ki........$/,/^ $/'|sed'/^ /d'|tr"@""》"》consensus.fasta)的bam文件(用星号表示映射到grch38上的读数,参见“个性化典型蛋白质组的生成。”部分)生成的共有基因组中提取个性化重叠群序列(bedtools getfasta-fi consensus.fasta-bed contigs.bed-name》》output.fasta)。
[0223]
使用sed(sed-e"s/nnn /\n/g")移除读数(n)未覆盖的部分重叠群,并将所有重叠群写入fasta文件。将具有空位、插入或缺失比对(并且无法从共有基因组中检索到)并在diffcontigsinfos.tsv中的相关样本中报告为表达的重叠群序列添加到此fasta文件中。最后,通过使用内部python脚本(先前公开或包括在pygeno中(daouda等人,2016;laumont等人,2018)),重叠群被6框翻译,不明确的氨基酸序列被转化为所有可能的序列(因为重叠群重叠的单碱基突变可以编码多个不同的氨基酸序列),氨基酸序列在内部终止密码子处分裂,并将得到的子序列与每个样本各自的个性化典型蛋白质组连接。
[0224]
6)数据库大小的验证-图9b-c。鉴于与典型(个性化)蛋白质组数据库相比,本研究中使用的四种蛋白质组学方法中使用的ms数据库呈现出可变膨胀的大小,因此检查这些更大的大小如何影响ms识别。首先,在19个aml样本中比较用每种方法识别的肽的累积数量(图9b)。这表明,尽管两种方法之间的数据库大小存在显著差异,但与典型蛋白质组相比,识别的肽数量变化不大(ere方法高达~9%)。接下来,当每个数据库与每个样本中各自的典型个性化蛋白质组连接时,推断适当大小的数据库应该允许识别相比于单独的典型蛋白质组具有相似同一性的典型蛋白质来源肽。如图9c所示,在所有aml样本的每种方法中识别的被注释为蛋白质编码的肽的绝大多数(88.2%-96.2%)与仅基于典型蛋白质组识别的那些肽相同。基于这些观察,可以得出结论,各种数据库的大小均适合可靠的ms识别。
[0225]
mhc相关肽的分离
[0226]
将w6/32抗体(bioxcell)在pbs中与pureproteome蛋白a磁珠(millipore)以1mg抗体/ml浆液的比在室温下孵育60分钟。如所述,使用二甲基庚二酸将抗体与磁珠共价交联。将珠粒在4℃下储存在pbs ph 7.2和0.02%nan3中。对于冷冻细胞沉淀样本(9800万个细胞/沉淀),将细胞解冻并重悬于1ml pbs ph 7.2中,并通过添加1ml含有pbs ph 7.2、1%(w/v)chaps(sigma)的洗涤剂缓冲液溶解蛋白酶抑制剂混合物(sigma)。对于肿瘤样本,将组织切成小块(立方体,~3mm大小),并添加5ml含有蛋白酶抑制剂混合物的冰冷pbs。首先使用设定为速度20000rpm的ultra turrax t25均质器(ika-labortechnik)将组织块均质两次,持续20秒,然后使用设定为25000rpm的ultra turrax t8均质器(ika-labortechnik)均质20秒。然后,将550μl冰冷的10x裂解缓冲液(5%w/v chaps)添加到样本中。将细胞沉淀和肿瘤样本在4℃下翻滚孵育60分钟,然后在4℃下以10000g离心20分钟。将上清液转移到每个样本含有1mg w6/32抗体共价交联蛋白a磁珠的新试管中,并在4℃下翻滚孵育180分钟。将样本置于磁铁上以将结合的mhc i复合物回收到磁珠上。首先用8
×
1ml pbs清洗磁珠,然后用1
×
1ml的0.1x pbs清洗,最后用1
×
1ml水清洗。mhc i复合物通过使用0.2%甲酸(fa)的酸性处理从磁珠上洗脱。为了移除任何残留的磁珠,将洗脱液转移到2.0ml costar ml spin-x离心管过滤器(0.45μm,corning)中并以855g离心2分钟。使用装有20个直径为1mm的十八烷基(c-18)固相萃取盘(empore)的自制载物台尖端将含有肽的滤液与mhc i亚基(hla分子和β-2巨球蛋白)分离。先用甲醇预洗载物台吸头,然后用0.2%三氟乙酸(tfa)中的80%乙腈(acn),最后用0.2% fa。将样本装载至载物台尖端并用0.2%fa洗涤。肽用0.1% tfa中的30% acn洗脱,使用真空离心干燥,然后储存在-20℃直至ms分析。
[0227]
质谱分析
[0228]
将干燥的肽提取物重悬于4%甲酸中,并上样至自制c18分析柱(15cm x 150μm i.d.,填充c18 jupiter phenomenex),在easynlc ii系统上使用56-min梯度(10h005)或106-分钟梯度(所有其他样本),0%至30%的乙腈(0.2%甲酸)和600nl/min的流速。使用q-exactive hf质谱仪(thermo fisher scientific)在正离子模式下使用1.6kv的nanospray 2源对样本进行分析。每个完整的ms谱,以60,000分辨率采集,然后是20个ms/ms谱,其中选择最丰富的多电荷离子进行ms/ms测序,分辨率为30,000,自动增益控制目标为5x104(10h005)或2x104(所有其他样本),进样时间为100ms(10h005)或500ms(15h023、15h063、15h080、05h149)或800ms(所有其他样本),以及碰撞能量为25%。
[0229]
合成肽
[0230]
当可获得足够量的材料时,tsa
hi
的氨基酸序列用合成肽进一步验证,如前所述(zhao等人,cancer immunol res.2020feb 11doi:10.1158/2326-6066.cir-19-0541.[epub ahead of print])。
[0231]
生物信息学分析
[0232]
所有分析均对修剪后的数据进行,除非另有说明,否则所有比对均使用之前部分中所述的星号进行,并且所有比对均在grch38.88上进行。
[0233]
使用peaks x(bioinformatics solution inc.)针对相关数据库搜索所有液相色谱(lc)-ms/ms(lc-ms/ms)数据。对于肽识别,前体离子和碎片离子的容差分别设定为10ppm和0.01da。氧化(m)和脱酰胺(nq)的发生被设定为可变修饰。
[0234]
1)map的识别。肽识别后,获得每个样本的独特肽列表,并将5%的错误发现率(fdr)应用于肽评分。使用netmhc 4.0(andreatta和nielsen,2016)预测与样本hla等位基因的结合亲和力,并且仅有8至11个氨基酸长度的百分位数≤2%的肽用于进一步注释。
[0235]
2)目的map(moi)的识别和验证。对于这两种k-mer耗竭方法,使用与先前描述的类似方法进行(laumont等人,2018)。简言之,分别搜索每个map及其编码序列的相关aml和正常典型蛋白质组(针对所有mtec和mpc构建,如上所述)或癌症和正常24个核苷酸长度的k-mer数据库(由组合mtec或组合的mpc,如上文所述)。无论其编码序列检测状态如何,在正常典型蛋白质组中检测到的map均被排除。在正常典型蛋白质组和正常k-mer中均未检测到的map被标记为moi。与正常样本相比,两个典型蛋白质组中均不存在但存在于两个k-mer数据库中的map需要使其rna编码序列在aml中过表达至少10倍,才能被标记为moi。最后,只有当它们各自的编码序列始终将它们标记为moi时,对应于几个rna序列(源自不同蛋白质)的map才能被标记为moi。
[0236]
对于ere方法,基于其在ere中的氨基酸序列和个性化典型蛋白质组的存在,针对每个单独的map提供“是”、“可能”或“否”的ere状态。对于“可能”候选者,计算ere读数和典型读数数据集中肽编码序列的表达水平(即肽的24个核苷酸长度的k-mer集的最小出现)。只有在ere读数数据集中表达至少高10倍的“可能”候选者才被视为ere map。然后在igv中手动验证剩余的ere map候选者(robinson等人,nat biotechnol.2011jan;29(1):24-6),以确定肽的编码序列是否包含种系多态性,并且与ere序列和典型注释序列(如适用)相比具有适当的方向。
[0237]
对于差异k-mer方法,搜索map的完整列表的aml特定蛋白质组以标记为moi候选者。接下来,在19个aml样本和11个用作de-kupl中的对照的mpc中评估每个map的rna表达(按照下一部分中描述的程序),并标记为moi,所有map在正常和癌症样本之间的最小倍数变化为5。由于map rna表达评估程序基于参考基因组进行定量,因此无法正确定量源自突变的候选moi,并系统地将其标记为候选moi。为了明确地验证每个moi在每个被识别的aml样本中存在的rna水平,从de-kupl的diffcontigsinfos.tsv输出中检索moi编码序列并搜索相关fastq文件(正向r2 fastq中的序列和反向r1 fastq中的反向补充)。弃去未通过该检查的moi。
[0238]
对于所有moi候选者列表(四种不同的方法),由于标准ms方法无法区分亮氨酸和异亮氨酸变体,因此检查了每个列表并弃去被标记为非moi的现有变体,除非它比变体呈现更高的rna表达。手动检查所有moi的ms/ms谱以移除任何错误识别。最后,通过使用blat
(ucsc基因组浏览器的工具)在参考基因组上映射包含其编码序列的读数,将基因组位置分配给所有moi。排除读数与一致基因组位置不匹配或与高变区(诸如mhc、ig或tcr基因)匹配的moi。对于具有一致基因组位置的那些,igv用于排除具有与已知种系多态性(dbsnp149)重叠的编码序列的moi。
[0239]
3)rna-seq数据中map编码序列的定量。为了明确评价每个map的rna表达,将所有map氨基酸序列反向翻译成所有可能的核苷酸序列。接下来,使用gsnap(wu等人,2016)在基因组上映射所有这些可能的序列,并使用-n 1000000选项来定位能够编码给定map的所有基因组区域。为了可靠地捕获由重叠剪接位点的序列编码的map,还在转录组映射可能的map编码序列(cdna和非编码rna)以提取(具有
‑‑
长度80选项的samtools faidx)大部分(80个核苷酸)参考转录组序列,其然后在参考基因组上映射(gsnap,具有
‑‑
use-splicing和
‑‑
novelsplicing=1选项)。对于由不同tsa发现管道生成的moi,还进行包含其编码序列的所有读数的基因组比对。过滤gsnap的输出以仅保持序列和参考之间的完美匹配,以生成包含所有可能的基因组区域的bed文件,这些区域易受给定map编码的影响。通过使用samtools view(-f256选项)、grep和wc(-l选项),每个期望rna-seq样本(诸如aml、gtex或正常样本)中各自基因组位置包含map编码序列的读取数被计数,在参考基因组上比对,用星号表示(bam文件)。最后,对给定map的所有读数计数(来自不同区域和编码序列)进行求和,并根据每个评估样本中测序的读数总数进行归一化,以获得每亿读数(rphm)计数。
[0240]
4)免疫原性评估。使用repitope进行moi的免疫原性预测(ogishi和yotsuyanagi,2019)。使用预定义的mhci_human_minimumfeatureset变量进行特征计算并更新(2019年7月12日)featuredf_mhci和fragmentlibrary文件在文件包的mendeley存储库(https://data.mendeley.com/datasets/sydw5xnxpt/1)上提供。
[0241]
5)aml患者的moi呈递和表达。为了识别能够呈递给定map(混杂结合物)的所有可能的hla等位基因,使用mhccluster在线工具(http://www.cbs.dtu.dk/services/mhccluster/)(thomsen等人,2013)。聚类值≤0.4的hla等位基因被认为能够呈递相同的map。为了评价leucegene队列中aml患者的moi呈递,首先用optitype确定他们的hla类型,如果其在rna水平的表达高于2rphm(而不是0rphm,以最大化呈递的概率)以及患者是否表达能够呈递moi的hla等位基因(如netmhc4.0所预测的,用于对每个发现的moi的呈递分子进行原始识别,而mhccluster用于识别混杂结合物)。如果患者表达能够呈递相同moi的两个不同hla等位基因,则认为moi呈递两次。
[0242]
为了评价与高tsa
高
表达相关的分子特征,如果tsa
高
在该患者中的表达高于其在整个队列中的中位表达(仅基于非空值计算),则认为tsa
高
在给定患者中表达。对每名患者的高表达tsa
高
(#he-tsa
hi
)总数进行计数,并用于进行与基因表达的相关性分析以及与突变或其他临床特征的关联(见下一部分)。
[0243]
6)生存分析。leucegene队列中374名患者的生存数据由leucegene团队(https://leucegene.ca)的友情馈赠。进行生存分析以评估如上所述计算的高计数hla-tsa
hi
复合物(hla-tsa
hi
的hla限制性呈递)与临床结局(总体生存率)之间的关联。根据他们可能存在的tsa
hi
总数将患者分为两组:高表达者(hla-tsa
hi
计数的上四分位数)和低表达者(所有其他患者)。使用kaplan-meier曲线比较两组之间的生存率,并通过graphpad prism v7.0中的对数秩检验评估显著性。在多变量分析中,使用r中的生存分析v0.1.1包进行,年龄被纳入
作为连续变量,突变被编码为存在/不存在(1/0),细胞遗传学风险的评估被视为单独的组,并针对中间相对于有利风险和不利相对于有利风险进行。
[0244]
7)突变分析。npm1、flt3-itd、flt3-tkd、idh1(r132)和双等位基因cebpa的突变数据检索自先前发表的leucegene队列数据(audemard等人,2019;lavallee等人,2016)。用freebayes检测asxl1、tp53、dnmt3a、idh2(仅r140和r172)、wt1、runx1和tet2中的突变并过滤以移除突变:(i)变异等位基因频率(vaf)《20%;(ii)在cosmic数据库(https://cancer.sanger.ac.uk/cosmic)中标记为snp;(iii)具有低推定影响(5'utr提前起始密码子获得变体;剪接区变体和同义变体;终止保留变体;同义变体);(iv)如fathmm-xf(http://fathmm.biocompute.org.uk/fathmm-xf/)所预测的,错义snp对蛋白质结构和功能具有良性影响(rogers等人,2018);(iv)涉及aaaaa 或ttttt 的插入和缺失;(v)在cosmic数据库中仅标记为种系的突变(tate等人,2018)。
[0245]
8)基因表达分析。所有转录物表达定量均使用默认参数的kallisto v0.43.0进行。kallisto的转录水平计数估计值使用r包tximport转换为基因水平计数。edger用于使用tmm算法对计数进行归一化,并输出每百万计数(cpm)值。只有蛋白质编码基因(如ensembl的biomart工具中所报告的那样,useast.ensembl.org/biomart)被保留用于进一步分析。每个基因表达和he-tsa
hi
计数之间的系统pearson相关性使用r中的cor.test函数进行。对所有非npm1/flt3-itd/dnmt3a突变和非fab-m1患者进行相关性。使用benjamini&hochberg方法(r中p校正)对p值进行校正,并且在三个相关分析中的至少一个中,只有fdr《0.00001的基因,在三个分析中的fdr《0.001,在三个分析中一致的相关系数(正或负),以及在至少一个分析中的相关系数》0.3或《-0.3被保留用于下游处理。
[0246]
使用rtsne包对从kallisto的转录水平丰度估计聚合到通过tximport的基因丰度估计获得的表达基因的同一性进行t分布随机邻域嵌入(t-sne)分析(如果tpm≥1,则表达=1,并且如果tpm《1,则=0)。此分析仅使用蛋白质编码基因(最容易产生map)。
[0247]
9)go term和富集图分析。使用cytoscape v3.7.2中的bingo v3.0.3(maere等人,2005)进行生物过程基因本体论(go)term过度表示,使用超几何检验并应用fdr校正的p值的显著性临界值≤0.005。将bingo的输出导入cytoscape中的enrichmentmap v3.2.1(merico等人,2010)中,以对冗余go terms进行聚类并可视化结果。使用jaccard相似性系数临界值0.25、p值临界值0.001和fdr校正临界值0.005生成enrichmentmap。在cytoscape中使用默认设定和600次迭代使用默认的“prefuse force-directed layout”可视化网络。手动圈出相似的go terms组。
[0248]
10)内含子保留和nmf聚类。已使用irfinder v1.2.5(middleton等人,2017)对整个leucegene队列和11个主要mpc样本进行内含子保留(ir)分析。具有iratio≥10%的内含子(内含子保留在≥10%的转录物中)和3个读数的最小覆盖率被认为是保留的。过滤内含子以仅保留那些保留在至少2个aml样本中而不保留在任何mpc样本中的内含子。选择10%变化最大的内含子(通过它们在整个队列中的iratio变异系数)进行进一步分析(6988个内含子)。无监督一致性聚类结果使用r中的nmf v0.21.0(gaujoux和seoighe,2010)包在选定内含子的iratio上生成,使用默认brunet算法,以及200次迭代用于排名调查和聚类运行。聚类结果是通过考虑共有成员矩阵的共同评分和平均轮廓宽度来选择的,用于具有3至15个聚类的聚类解决方案。
[0249]
通过识别nmf元基因(w矩阵)输出文件中排名靠前的2%内含子来生成丰度热图。移除重复名称产生1211个内含子的列表。针对每个leucegene样本生成这些内含子iratios的矩阵,重新排序以匹配nmf聚类输出,并使用r中的heatmap.3包进行具有中心相关距离度量和完整连接的内含子的分层聚类。
[0250]
elispot测定
[0251]
1)单核细胞来源的树突状细胞的产生。如前所述,由冷冻pbmc产生单核细胞来源的树突状细胞(vincent等人,biology of blood and marrow transplantation:journal of the american society for blood and marrow transplantation,22oct 2013,20(1):37-45;laumont等人,nat commun.2016jan 5;7:10238)。简言之,通过在补充有5%人血清(sigma-aldrich)、丙酮酸钠(1mm)、il-4(100ng/ml,peprotech)和gm-csf(100ng/ml,peprotech)的x-vivo
tm
15培养基(lonza bioscience)中培养8天,从贴壁的pbmc部分制备dc。培养7天后,用ifn-γ(1000iu/ml,gibco)和lps(100ng/ml,sigma aldrich)过夜使dc成熟。在成熟过程后的2h内,dc被负载2μg/ml的肽,然后在它们用作t-dc培养中的apc之前进行辐照(40gy)。对于对照组,用含有melana、ns3和gag-a2肽(所有三种结合hla-a*02:01)的混合物对dc进行脉冲处理。
[0252]
2)体外肽特异性t细胞扩增。解冻的pbmc首先使用人cd8
t细胞分离试剂盒(miltenyi biotech)富集cd8
t细胞,并以1:10的apc:t细胞比与自体肽脉冲dc共同孵育。在补充有8%人血清(sigma-aldrich)、l-谷氨酰胺(gibco)和细胞因子的高级rpmi培养基(gibco)中培养扩增的t细胞4周(每7天进行一次脉冲dc再刺激)。在第一个共培养周,将il-12(10ng/ml)和il-21(30ng/ml)添加到培养基中。两天后,il-2(100ui/ml)也被添加到细胞因子混合物中。第二周,向培养基中添加il-2(100ui/ml)、il-7(10ng/ml)、il-15(5ng/ml)和il-21(30ng/ml)。对于共培养的最后两周,使用il-2(100ui/ml)、il-7(10ng/ml)和il-15(5ng/ml)。每两天将补充有适当细胞因子混合物的培养基添加到共培养物中。在共培养的第四周结束时,收获细胞以进行elispot测定。
[0253]
3)ifnγelispot测定。根据生产商的建议使用elispot人ifnγ(r&dsystems,usa)试剂盒进行实验。然后将收获的cd8
t细胞铺板并在37℃下在用作刺激细胞的辐照肽脉冲pbmc(40gy)存在下孵育24小时。作为阴性对照,将分选的cd8
t细胞与辐照的未脉冲pbmc一起孵育。如生产商方案中所述显示斑点,并使用immunospot s5 uv分析仪(cellular technology ltd,shaker heights,oh)计数。在从阴性对照孔中减去斑点计数后,ifn-γ的产生表示为每106个cd8
t细胞中肽特异性斑点形成细胞(sfc)的数量。
[0254]
免疫原性预测
[0255]
使用repitope进行moi的免疫原性预测(ogishi和yotsuyanagi,2019)。使用预定义的mhci_human_minimumfeatureset变量进行特征计算并更新(2019年7月12日)featuredf_mhci和fragmentlibrary文件在文件包的mendeley存储库(https://data.mendeley.com/datasets/sydw5xnxpt/1)上提供。
[0256]
tcr和细胞毒性t细胞特征分析
[0257]
使用trust4软件(li等人,2017)和默认参数对437名leucegene患者的rna-seq数据进行tcr库分析。通过归一化每千克tcr读数(cpk)的tcr cdr3(完整和部分)数量来估计t细胞的克隆型多样性。通过免费门户网站(http://tcr.cs.biu.ac.il/)使用基于自动编码
apps.onc.jhmi.edu/fest)进行处理,没有最少数量的模板和“忽略基线阈值”参数。
[0263]
定量和统计分析
[0264]
除非在图例中明确提及,否则所有比较两种情况的统计检验均使用mann-whitney u检验进行。所有相关性均使用pearson相关系数进行评估。除非另有说明,否则箱线图中的所有方框均显示分布的中位值、第25和第75个百分位数,并且须线延伸至第10个和第90个百分位数。除非另有说明,否则所有柱状图均显示具有标准偏差(sd)的平均值。绘图和统计检验主要使用graphpad prism v7.00进行。对于所有统计检验,****表示p《0.0001,***表示p《0.001,**表示p《0.01,以及*表示p《0.05。
[0265]
实施例2:纯化的造血祖细胞是aml中tsa发现的有价值对照。
[0266]
ms是唯一可以直接识别map的可获得技术(ehx和perreault,2019;shao等人,2018)。通常,基于ms的map识别通过使用将获得的串联ms谱与用户提供的蛋白质序列数据库相匹配的软件工具进行。然而,参考蛋白质数据库仅包含典型蛋白质序列,因此不能实现识别源自突变和异常表达的非典型基因组区域(其是aetsa的主要来源)的map(laumont等人,2018)。先前已经描述了构建针对全球tsa识别定制的ms数据库的蛋白质组学策略。针对每个肿瘤样本构建定制的数据库,并且必须满足两个标准:足够全面以包含所有潜在的tsa,但规模有限,因为膨胀的参考数据库增加错误发现的风险(nesvizhskii等人,2014;chong等人,2020)。数据库构建开始于(i)肿瘤样本的rna测序,数据的关键,(ii)rna-seq的计算机切片读取到33个核苷酸长度的子序列(k-mer),以及(iii)减去正常k-mer以创建仅包含癌症特异性k-mer的模块。如癌症研究的许多方面,棘手的问题是阴性对照的选择(此处,正常k-mer的来源)。在先前的研究中,来自mtec的k-mer被用作正常对照。然而,在aml的情况下,测试另一种类型的阴性对照:分选的骨髓前体细胞(mpc,包括粒细胞/单核细胞祖细胞和各种类型的粒细胞前体)。
[0267]
为了比较mtec和mpc作为阴性对照的价值,首先比较19个靶aml样本(特征见表1)、6个mtec样本和6个mpc样本之间的相似性,这些样本先前已进行高覆盖率rna-seq(maiga等人,2016)。值得注意的是,与mtec相比,mpc从aml中耗竭的k-mer平均多16.4%,这表明mpc和aml之间的转录组重叠比mtec和aml之间更大(图1a)。因此,虽然mtec和mpc获得了相似的k-mer计数(~8.7vs~9.9
×
108),但与mtec(~1.9
×
108,~22%)相比,mpc与aml共享更多的专有k-mer(~3.3
×
108,~33%)(图1b)。为了确定谱系差异是这种更高相似性的起源,基于表达的蛋白质编码基因的同一性,对aml样本以及从各种来源下载的一系列分选的上皮细胞和造血细胞rna-seq进行了t-sne聚类(参见方法)。这表明aml样本与造血细胞聚类在一起,而mtec与上皮细胞聚类在一起(图1c)。重要的是,mtec表达的基因多样性最高,与其生物学功能一致(图1d)。总之,这些结果表明,尽管mtec转录组的多样性具有多样性,但对于在aml中发现tsa,mpc是比mtec更好的正常对照。作为推论,当减去mpc k-mer而不是mtec k-mer时,aml特定k-mer数据库的大小更小。
[0268]
实施例3:开发基于mpc的tsa发现方法
[0269]
除了捕获整个aml tsa环境外,还评估了四种策略以构建参考数据库。前两种策略先前已报道(图2a,b),其他两种是新的(图2c,d)。重要的是,aml样本的ms分析仅进行一次,因此四种不同的tsa发现方法中的每一种均在每个aml样本的相同ms谱上进行。第一个策略取决于mtec减法(图2a)(laumont等人,2018)。第二个特别关注由ere编码的map,它们可能
是tsa的丰富来源(图2b)(larouche等人,2020)。
[0270]
在第三种策略中,来自mtec和mpc的k-mer被耗竭(图2c)。值得注意的是,耗竭步骤之前是基于k-mer的发生(k-mers在同一样本中发生的次数,图8a,b)的过滤,以限制k-mer的最终数量至~3000万用于重叠群组装(更k-mer的组装在计算时间方面要求太高)。因此,与仅mtec相比,mtec mpc k-mer耗竭从aml样本移除更多k-mer,降低了~2-3倍发生阈值,从而能够发现mtec k-mer耗竭方法数据库遗漏的map(图8c,d)。
[0271]
第四种策略旨在规避k-mer耗竭策略的主要警告:正常和癌症样本中k-mer丰度之间缺乏比较。具体地,在k-mer耗竭策略中,给定k-mer的存在,即使发生一个,在正常对照中也导致在癌症样本中过滤该k-mer,即使它在癌症中的频率是正常对照组的100倍。简言之,差异k-mer表达(dke)分析使用de-kupl计算协议(audoux等人,2017)进行,并进行了一些内部校正,并且可以总结如下(图2d和图9a):(i)对至少30%的aml样本中存在(发生率≥3)的k-mer进行预过滤;(ii)k-mer丰度的归一化;(iii)通过用户定义的算法对k-mer丰度进行统计比较;(iv)将显著差异过表达的k-mer(最小倍数变化为10)组装成重叠群和(v)在基因组上比对重叠群以确定它们的起源区域。因为它们是最密切相关的正常样本,所以在本研究中选择mpc作为正常对照,并将19个aml样本与11个可获得的高覆盖mpc样本进行比较。接下来,针对每个aml样本生成个性化的重叠群序列(基于读取覆盖率和差异表达重叠群的基因组位置中的snp调用),翻译成所有可能的阅读框并与个性化典型蛋白质组相结合以进行map识别(图2)。
[0272]
实施例4:基于mpc的方法识别aml中的大部分tsa
hi
。
[0273]
四种tsa发现方法中的每一种均在19个aml样本中识别出数千个map(表2)。为了被认为是可操作的tsa,map需要由aml细胞大量呈递,并且不能由正常细胞呈递,或者以低至足以不触发t细胞识别的水平呈递,因为表位密度在cd8 t细胞消除靶标中起关键作用(cosma和eisenlohr,2019)。因为map优先来自高度丰富的转录物(图3a和pearson等人,2016),所以确定两个重要的阈值:(i)rna表达水平,低于该水平在正常组织中产生map的概率可以被认为是低的,以及(ii)rna表达倍数变化(fc)是显著增加呈递map的概率所必需的。为了实现这一点,评估它们各自的aml样本中所有识别的map的rna表达,发现它遵循绘制为累积频率分布的正态分布(图3b)。这证明,当表达低于8.55个读数/亿(rphm)时,生成map的概率为《5%。鉴于与正常粒细胞相比,aml细胞表达的mhc分子水平相似,并且粒细胞在正常组织中表达的mhc-i水平最高(berlin等人,2015;boegel等人,2018),8.55rphm被确定为所有组织的第一阈值。基于相同的分布,还可以评估不同fc对生成map概率的影响(图3c)。这表明从2至5的fc往往比更大的fc对概率的影响更大。因此采用五(5)作为最低fc阈值。
[0274]
基于这两个阈值,建立决策树以基于它们在aml、mpc、其他正常造血细胞和广泛正常成人组织(包括mtec)中的rna表达来分离map(图3d)。简言之,所有在正常组织中表达低于8.55rphm并且在aml中表达水平高于mpc的map均被标记为tsa,因为它们的检测是它们在aml细胞表面呈递的证据,而它们被正常组织呈递的概率很低。此外,aml和mpc之间的fc至少为5的tsa被标记为tsa
hi
,因为它们最有可能被aml细胞专门呈递。相对于其他组织在造血细胞中过表达但不满足这些标准的其他map被分类为taa或造血特异性抗原(hsa)(图3d)。
[0275]
在每个管道的预过滤步骤(见方法)和基于决策树的分类之后,获得了四个目的map(moi)列表(表2)。mtec耗竭方法产生了最高比例的hsa,而绝大多数tsa
hi
通过基于mpc的方法识别(图3e、f和10a)。由于dke方法预过滤了在最少患者中发生最少的k-mer,因此两种
基于mpc的方法之间的重叠很低。因此,与通过dke方法确定的那些相比,通过耗竭方法识别的大多数tsa
hi
呈现出较低的患者间共享(图9b)。总之,这些结果表明,dke方法最适合识别aml中的tsa
hi
,并且可以补充基于mpc的k-mer耗竭方法来识别另外的较少共享的tsa
hi
。
[0276]
表2:通过四种蛋白质组学方法识别的moi的详细信息。
[0277][0278]
[0279]
[0280]
[0281]
[0282]
[0283]
[0284]
[0285]
[0286][0287]
[0288]
[0289]
[0290]
[0291]
[0292]
[0293]
[0294]
[0295]
[0296]
[0297][0298]
在检查指定基因组位置的肽编码序列后,手动分配生物型。使用repitope计算免疫原性评分。如netmhc4.0所预测,hla等位基因对应于给定样本中最有可能呈递肽的基因。合成肽验证仅在tsa
hi
上进行。
[0299]
为了评估moi识别的稳健性,观察到的给定肽的平均保留时间(rt)与用于验证用高通量ms识别的map的两个同类最佳指标相关:由deeplc算法计算的rt(bouwmeester等人,2020)和用ssrcalc评估的疏水性指数(krokhin,2006),均基于肽序列进行预测。这表明非经典moi的rt分布与预测非常相关,并且与经典蛋白质组来源肽的分布没有显著差异(f检验),支持它们的正确识别(图3g)。最后,使用comet算法重复所有ms数据库搜索(最初使用peaks软件进行)。重新识别的百分比显示非典型moi和典型肽之间没有显著差异(图3h,左图)。在moi中,重新识别58个tsa
hi
中的52个(90%)(图3h,右图)。由两个不同的搜索引擎识别的map之间的这种主要重叠进一步支持了非典型moi识别的稳健性。
[0300]
实施例5:tsa
hi
是主要来源于内含子翻译的免疫原性map。
[0301]
四种tsa发现方法结果的组合产生总共47个hsa、49个taa、36个tsa
lo
和58个tsa
hi
(没有冗余)。表2中列出了所有moi的主要特征。根据定义,tsa在所有器官(来自gtex)以及mtec和正常造血细胞(图4a)中的表达低于阈值。重要的是,正常组织中tsa
hi
编码rna的表达系统性低于先前在临床试验中使用的taa的表达,而没有脱靶毒性(chapuis等人,2019;he等人,2020;legat等人,2016;qazilbash等人,2017)。与此一致,hla ligand atlas中不存在任何tsa
hi
,其中包含在29个非恶性组织中识别的人map(https://www.biorxiv.org/content/10.1101/778944v1)。这支持靶向tsa
lo
和58tsa
hi
(无冗余)的安全性。taa在至少一种正常组织中表达升高,而hsa表达仅限于造血区室。aml样本和mpc之间的fc比较表明,tsa
hi
与taa一起呈递最高的过表达(中位值为22倍),而hsa在健康细胞中以最高水平表达(中位值为0.6倍)(图4b)。总之,这些结果表明tsa
hi
结合了两方面的优势:tsa的特异性/安全性和taa的过表达。
[0302]
识别的tsa主要来源于据称基因组的非编码区,因为它们中仅有13%来源于典型蛋白质外显子,其中58%来源于内含子(图4c)。没有一个源自突变,与aml低突变负担一致(lawrence等人,2013)。taa主要来源于蛋白质编码外显子,而hsa起源也主要由非编码区主导,这与先前报道组织特异性内含子保留和ere表达模式的研究一致(middleton等人,2017;larouche等人,2020)。虽然八个tsa
hi
源自典型蛋白质编码基因,但鉴于它们在正常组织中相对于安全taa的低表达,它们可被视为安全靶标(图4a)。支持它们作为治疗靶标的相关性,其中三个来自已知的aml生物标志物(ltbp1、mycn和plppr3),其他五个具有未知功能或参与增殖、分化或耐药性(表3)。
[0303]
表3:已识别tsa
hi
来源的典型蛋白质编码基因的特征
[0304][0305][0306]
tsa的治疗价值部分取决于患者共享它的程度。为了评价原发性aml之间的tsa
hi
共享,分析leucegene队列,其中包括来自437名患者的纯化aml母细胞的rna-seq数据(lavallee等人,2015;macrae等人,2013;pabst等人,2016)。因为大多数map可以由不同的hla同种异型呈递,所以首先通过考虑混杂结合物来评价已识别的tsa
hi
的呈递。通过使用mhccluster工具,它将呈递相似表位的hla等位基因聚类在一起(thomsen等人,2013),可以推断出能够呈递单个tsa
hi
的全套hla同种异型(表4)。基于这些数据,表明在世界人群中,99.92%的个体携带≥1种hla-i同种异型,能够呈递一种tsa
hi
。接下来,认为只有当tsa编码转录物表达并且患者具有可以呈递该tsa的hla同种异型时,单个tsa
hi
才存在于给定的aml样本中。基于这些标准,可以预测在leucegene队列中,每名患者tsa
hi
的中位值为4,并且93.6%的患者出现至少一种tsa
hi
(图4f)。
[0307]
表4:能够呈递mhccluster预测的类似肽(混杂结合物)的hla等位基因列表。
[0308]
[0309]
[0310][0311]
当比较在初始诊断时与复发时分析的aml样本中tsa
hi
的数量(不匹配的样本)时,发现两组之间没有差异(图4g)。在另一项研究中比较诊断时和异基因造血细胞移植后复发时获得的aml母细胞匹配样本中患者hla等位基因可能呈递的tsa
hi
的rna表达时,也没有发现差异(toffalori等人,2019)(图4h)。由于白血病干细胞(lsc)是复发的主要介体(shlush等人,2017),tsa
hi
和hla rna表达也在从另一项研究获得的分类lsc相对于母细胞rna-seq数据中进行评价(corces等人,2016),并且发现两个细胞群之间没有差异(图4i-j)。尽管如此,通过使用基因集富集分析(gsea),发现表达大量tsa
hi
的患者也表达了更高水平的成熟lsc基因特征(eppert等人,2011)(图4k)。总之,这些结果进一步支持了tsa
hi
的高免疫原性,并证明它们可以针对几乎所有aml患者,无论是在诊断时还是复发时。因此可以得出结论,
可以在疾病的任何阶段设想tsa
hi
的免疫靶向,并且将具有消除lsc的潜力。
[0312]
实施例6:大量tsa
hi
的呈递与更好的生存率相关。
[0313]
接下来,检查了诊断时tsa
hi
呈递对患者生存率的影响。值得注意的是,表达最高数量(上四分位数)的tsa
hi
的患者比队列中的其余患者表现出明显更好的生存率(图5a)。在多变量分析中,与多个tsa
hi
的呈递相关的生存优势以及其他已知的预后因素(诸如年龄)、细胞遗传学风险、npm1和flt3-itd突变仍然显著(图5b)。重要的是,独立于hla
pred
呈递进行的相同比较显示高表达和低表达之间没有差异(图11a,b),这表示tsa
hi
的保护作用是hla限制的。对taa、hsa或tsa
lo
进行的相同分析显示对生存率没有显著影响(图11c-h)。这些数据表明tsa
hi
具有足够的免疫原性来引发自发的抗aml免疫应答。
[0314]
为了证明tsa
hi
提供的生存优势是由于其累积的hla
pred
呈递,在随机移除越来越多的tsa
hi
(58个中的1至29个)后,从分析(1000个随机排列/数值)中计算高相对于低tsa
hi
患者的对数秩p值。相对于低表达者(所有其他患者),增加数量的tsa
hi
的随机移除迅速导致高表达者(hla-tsa
hi
计数的上四分位数)缺少显著的生存优势(图5c-d)。随着个体tsa
hi
的减少,生存优势的逐渐下降表明大多数tsa
hi
有助于这种生存优势。更大比例的患者呈递的tsa
hi
对p值的影响最大(图5e)。同样,从对数秩分析中移除常见hla等位基因(超过5%的患者共享)对p值的影响大于移除低频等位基因(图5f)。总之,这些数据证明了tsa
hi
呈递对患者生存率的hla限制性益处。在接下来的实验中,研究了与tsa
hi
呈递相关的生存优势的最简洁的解释:tsa
hi
引发自发的保护性抗aml免疫应答。
[0315]
实施例7:tsa
hi
呈递引发细胞毒性t细胞应答
[0316]
作为评价tsa
hi
和其他moi的免疫原性(即它们诱导免疫应答的能力)的前奏,使用repitope,其是机器学习算法,它依赖于公共tcr数据库来预测t细胞应答的概率(ogishi和yotsuyanagi,2019)。使用胸腺上皮细胞(adamopoulou等人,2013)或源自hiv的map分别作为阴性和阳性对照,repitope预测表明taa大多是非免疫原性的,而其他三组moi与hiv肽一样具有免疫原性(图6a)。因此,相对于其他三个组和相对于在iedb中报告为免疫原性的一组1411map,taa在mtec(~12.1rphm)中呈递高表达(图6b)。即使相对于其他免疫原性肽,非taa moi在mtec中的rna表达均非常低,这支持了它们的免疫原性。为了验证repitope预测,以预期具有最高的免疫原性的hla-a*02:01呈递的tsa
hi
:alpvalpsl开始进行体外t细胞测定。作为ifn-γelispot的阳性对照,使用elagigiltv表位是因为它是最具免疫原性的人map之一(dutoit等人,2002;hesnard等人,2016)。alpvalpsl的免疫原性与elagigiltv相似(图6c)。两个其他有前景的tsa
hi
的elispot也支持它们的免疫原性(图6d)。对于这些tsa
hi
,还进行了细胞因子分泌测定和右旋体染色,这证实了elispot结果并支持了免疫应答的特异性(图6e-f)。为了进一步证明tsa
hi
可以诱导自发和特异性t细胞克隆型扩增,进行特异性t细胞的功能扩增(fest)测定,其中通过tcr测序分析用不同tsa
hi
池刺激的外周血t细胞的短期培养(danilova等人,2018)。5个测试的tsa
hi
的每个池诱导9-10种不同克隆型的特异性扩增,支持它们的自发免疫原性(图6g和表5)。
[0317]
表5:响应tsa
hi
池的特异性t细胞(fest)测定的功能扩展。
[0318]
[0319][0320][0321]
可以由hla-a*02:01、-a*29:02、-b*15:01、-b27:05、-c*01:02、-c*03:04健康供体的hla等位基因呈递的所有tsa
hi
。tcr-seq由adaptive biotechnologies进行,原始数据使用fest分析工具http://www.stat-apps.onc.jhmi.edu/fest处理。此处报告了池的数量、每个池中存在的tsa
hi
、每个池中显著扩增的每个克隆型的序列以及fest分析工具提供的
fdr和比值比。
[0322]
接下来,由于“体内验证”,对来自437名leucegene患者的转录组数据进行了深入分析,以评价t细胞对tsa
hi
的体内识别潜力。首先,使用trust4算法(zhang等人,2019)评价t细胞的tcr库多样性。与taa(此处用作非免疫原性对照)相比,tsa
hi
数量升高的
pred
呈递与tcr库多样性降低有关,这表明抗tsa
hi
克隆型的扩展(图6h)。为了证明这种扩展的特异性,使用ergo算法来预测moi-tcr相互作用(springer等人,2020)。在识别抗moi克隆型的ergo概率》80%时,具有大量tsa
hi
的患者在所有检测到的cdr3中也具有更高频率的抗tsa
hi
克隆型(图6i)。对于taa,未见类似的相关性(图6j)。接下来,计算能够识别由各个aml样本
pred
呈递的moi的抗moi克隆型的比例(即同源tcr
─
moi相互作用的频率)。该比例根据
pred
呈递的moi的数量进行归一化,因为否则呈递更多的moi将自动导致检测到更高比例的抗
pred
呈递的moi克隆型。这表明tsa
hipred
呈递与特异性t细胞识别频率显著高于taa相关(图6k)。
[0323]
鉴于抗tsa
hi
t细胞识别,推测tsa
hipred
呈递应该与激活的cd8 t细胞的浸润有关。有意思的是,tsa
hi
转录物的多样性与aml样本中的cd8a cd8b表达呈负相关,而它们的
pred
呈递的多样性不呈负相关(图6l-m)。这表明tsa
hi
转录物的高度多样性反映了aml样本中略高的母细胞纯度(如tsa所预期)。为了避免这种可能的偏差,并且由于hla-tsa
hi
的数量在数学上与表达的tsa
hi
的数量相关,将
pred
呈递的tsa
hi
的数量归一化为表达的tsa
hi
转录物的数量,并在归一化
pred
呈递为的患者中分析差异基因表达高于中位值相比于低于中位值。值得注意的是,在与tsa
hipred
呈正相关的123个基因中,有几个与t细胞激活和细胞溶解相关,包括cd8a、cd8b、gzma、gzmb、il2rb、prf1和zap70(图6n)。值得注意的是,与这123个基因相关的go terms仅与t细胞激活和分化相关(图6o)。cd4基因没有差异表达,并且没有go term可能与下调基因显著相关。因此,得出的结论是,tsa
hipred
呈递与较高丰度的激活cd8 t细胞有关。
[0324]
实施例8:tsa
hi rna表达与免疫编辑、aml驱动突变和表观遗传畸变的体征有关
[0325]
鉴于tsa
hi
的潜在治疗价值,有必要深入了解它们的生物发生。对于该分析,将高表达tsa
hi
(he-tsa
hi
)的计数分配给每名leucegene患者,即在所有具有给定tsa
hi
非空表达的患者中,他们的tsa
hi
计数表达水平高于其中位表达。然后通过在每个蛋白质编码基因的表达和he-tsa
hi
计数之间进行成对pearson相关来评估特定基因的表达是否可以与tsa
hi
表达相关联。这表明参与map呈递的基因(hla-a、hla-b、hla-c、b2m和nlrc5)的表达与he-tsa
hi
的数量之间存在一致的负相关,这表明免疫编辑响应于tsa
hi
升高而发生表达(图7a和12a-b)。免疫编辑还得到了与cd47和cd84呈正相关的支持,cd47是免疫检查点分子,参与抑制树突状细胞吞噬作用(majeti等人,2009),cd84促进白血病细胞表达pd-l1(lewinsky等人,2018)。由于npm1突变可以调节pd-l1(cd274)表达(greiner等人,2017),因此分别分析了npm1
mut
和npm1
wt
患者。该分析显示,具有高于中位he-tsa
hi
计数的npm1
wt
患者表达的pd-l1水平显著高于具有较差he-tsa
hi
计数的患者(图7b)。
[0326]
接下来,分析与he-tsa计数相关的基因途径(图7c和表6)。负相关途径包括参与细胞增殖(也包括转运和细胞组织)、线粒体oxphos和蛋白酶体介导的蛋白质分解代谢的生物过程。有意思的是,已显示抑制线粒体活性可降低mhc-i表达,并可用作癌细胞的免疫逃逸机制(charni等人,2010)。类似地,抑制蛋白质降解可能导致mhc-i分子呈递的肽量减少,因此降低呈递tsa
hi
的可能性(tripathi等人,2016)。最后,有丝分裂相关过程的减少可能是
mhc-i下调的副作用,因为这两个过程均受nlrc5的调节(wang等人,2019)。总之,这些数据表明tsa
hi
表达与可能充当aml细胞免疫编辑机制的各种应答有关。
[0327]
与负相关途径相反,正相关途径仅限于调节过程(图7d)。因此,16.1%(相比于负相关的2.5%)的正相关基因是转录因子,可直接负责tsa
hi
的转录。其中,相关性最好的基因是znf445(图7a),它是基因组印记的调节因子,即与dna甲基化相关的表观遗传过程(takahashi等人,2019)。由于znf445功能依赖于dna甲基化,因此检查了tsa
hi
表达与通常与dna甲基化异常相关的aml突变之间的可能关联。首先测试了三种最常见的aml驱动突变(npm1
mut
、flt3-itd和dnmt3a
mut
),发现这三种突变在表达高he-tsa
hi
计数(高于中位值)的患者中均显著富集(图7e)。此外,呈递两种或三种伴随突变的患者比呈递一种或没有一种突变的患者具有更高数量的he-tsa
hi
(图7f)。在ms分析中使用的19个aml试样中,12个呈递flt3-itd或npm1突变。关于其他常见的aml突变,发现idh2和双等位基因cebpa突变也与he-tsa
hi
计数升高呈正相关,而asxl1、srsf2和u2af1突变呈负相关,并且flt3-tkd、idh1、runx1、tet2、tp53和wt1不相关(图12d)。由于npm1、dnmt3a、idh2和cebpa
bi
突变与异常甲基化谱相关(figueroa等人,2010a;figueroa等人,2010b;ley等人,2013),它们与he-tsa
hi
计数升高的相关性支持tsa
hi
表达的表观遗传失调。
[0328]
表6:与leucegene队列中的he-tsahi计数呈正或负相关的go terms列表。
[0329]
[0330]
[0331]
[0332]
[0333]
peptide matrix of central tolerance in the human thymus.nat commun 4,2039.
[0339]
andreatta,m.,and nielsen,m.(2016).gapped sequence alignment using artificial neural networks:application to the mhc class i system.bioinformatics32,511-517.
[0340]
audemard,e.o.,gendron,p.,feghaly,a.,lavall
é
e,v.p.,h
é
bert,j.,sauvageau,g.,and lemieux,s.(2019).targeted variant detection using unaligned rna-seq reads.life sci alliance 2.
[0341]
audoux,j.,philippe,n.,chikhi,r.,salson,m.,gallopin,m.,gabriel,m.,le coz,j.,drouineau,e.,commes,t.,and gautheret,d.(2017).de-kupl:exhaustive capture of biological variation in rna-seq data through k-mer decomposition.genome biology 18,243.
[0342]
avigan,d.,and rosenblatt,j.(2018).vaccine therapy in hematologic malignancies.blood 131,2640-2650.
[0343]
bamezai,s.,rawat,v.p.,and buske,c.(2012).concise review:the piwi-pirna axis:pivotal beyond transposon silencing.stem cells 30,2603-2611.
[0344]
berlin,c.,kowalewski,d.j.,schuster,h.,mirza,n.,walz,s.,handel,m.,schmid-horch,b.,salih,h.r.,kanz,l.,rammensee,h.g.,et al.(2015).mapping the hla ligandome landscape of acute myeloid leukemia:a targeted approach toward peptide-based immunotherapy.leukemia 29,647-659.
[0345]
boegel,s.,lower,m.,bukur,t.,sorn,p.,castle,j.c.,and sahin,u.(2018).hla and proteasome expression body map.bmc med genomics 11,36.
[0346]
bouwmeester,r.,gabriels,r.,hulstaert,n.,martens,l.,and degroeve,s.(2020).deeplc can predict retention times for peptides that carry as-yet unseen modifications.biorxiv,2020.2003.2028.013003.
[0347]
bray,n.l.,pimentel,h.,melsted,p.,and pachter,l.(2016).near-optimal probabilistic rna-seq quantification.nature biotechnology 34,525-527.
[0348]
chapuis,a.g.,egan,d.n.,bar,m.,schmitt,t.m.,mcafee,m.s.,paulson,k.g.,voillet,v.,gottardo,r.,ragnarsson,g.b.,bleakley,m.,et al.(2019).t cell receptor gene therapy targeting wt1 prevents acute myeloid leukemia relapse post-transplant.nat med 25,1064-1072.
[0349]
charni,s.,de bettignies,g.,rathore,m.g.,aguil
ó
,j.i.,van den elsen,p.j.,haouzi,d.,hipskind,r.a.,enriquez,j.a.,sanchez-beato,m.,pardo,j.,etal.(2010).oxidative phosphorylation induces de novo expression of the mhc class i in tumor cells through the erk5 pathway.the journal of immunology 185,3498-3503.
[0350]
chen,j.,brunner,a.d.,cogan,j.z.,nunez,j.k.,fields,a.p.,adamson,b.,itzhak,d.n.,li,j.y.,mann,m.,leonetti,m.d.,and weissman,j.s.(2020).pervasive functional translation of noncanonical human open reading frames.science 367,1140-1146.
sequencing.haematologica 105,e290-e293.
[0376]
gutierrez,s.e.,and romero-oliva,f.a.(2013).epigenetic changes:a common theme in acute myelogenous leukemogenesis.j hematol oncol 6,57.
[0377]
hardy,m.-p.,vincent,k.,and perreault,c.(2019).the genomic landscape of antigenic targets for t cell-based leukemia immunotherapy.frontiers in immunology 10,2934.
[0378]
he,h.,kondo,y.,ishiyama,k.,alatrash,g.,lu,s.,cox,k.,qiao,n.,clise-dwyer,k.,st john,l.,sukhumalchandra,p.,et al.(2020).two unique hla-a*0201 restricted peptides derived from cyclin e as immunotherapeutic targets in leukemia.leukemia.
[0379]
hesnard,l.,legoux,f.,gautreau,l.,moyon,m.,baron,o.,devilder,m.c.,bonneville,m.,and saulquin,x.(2016).role of the mhc restriction during maturation of antigen-specific human t cells in the thymus.eur j immunol 46,560-569.
[0380]
janelle,v.,carli,c.,taillefer,j.,orio,j.,and delisle,j.s.(2015).defining novel parameters for the optimal priming and expansion of minor histocompatibility antigen-specific t cells in culture.j transl med 13,123.
[0381]
jung,n.,dai,b.,gentles,a.j.,majeti,r.,and feinberg,a.p.(2015).an lsc epigenetic signature is largely mutation independent and implicates the hoxa cluster in aml pathogenesis.nature communications 6,8489.
[0382]
knaus,h.a.,berglund,s.,hackl,h.,blackford,a.l.,zeidner,j.f.,montiel-esparza,r.,mukhopadhyay,r.,vanura,k.,blazar,b.r.,karp,j.e.,et al.(2018).signatures of cd8 t cell dysfunction in aml patients and their reversibility with response to chemotherapy.jci insight 3.
[0383]
krokhin,o.v.(2006).sequence-specific retention calculator.algorithm for peptide retention prediction in ion-pair rp-hplc:application to 300-and 100-a pore size c18 sorbents.anal chem 78,7785-7795.
[0384]
lamoliatte,f.,mcmanus,f.p.,maarifi,g.,chelbi-alix,m.k.,and thibault,p.(2017).uncovering the sumoylation and ubiquitylation crosstalk in human cells using sequential peptide immunopurification.nat commun 8,14109.
[0385]
larouche,j.d.,trofimov,a.,hesnard,l.,ehx,g.,zhao,q.,vincent,k.,durette,c.,gendron,p.,laverdure,j.p.,bonneil,e.,et al.(2020).widespread and tissue-specific expression of endogenous retroelements in human somatic tissues.genome med 12,40.
[0386]
laumont,c.m.,daouda,t.,laverdure,j.p.,bonneil,e.,caron-lizotte,o.,hardy,m.p.,granados,d.p.,durette,c.,lemieux,s.,thibault,p.,and perreault,c.(2016).global proteogenomic analysis of human mhc class i-associated peptides derived from non-canonical reading frames.nat commun7,10238.
[0387]
laumont,c.m.,vincent,k.,hesnard,l.,audemard,e.,bonneil,e.,laverdure,
endogenous human retroelements in health and disease.curr top microbiol immunol 310,211-250.
[0422]
shannon,p.,markiel,a.,ozier,o.,baliga,n.s.,wang,j.t.,ramage,d.,amin,n.,schwikowski,b.,and ideker,t.(2003).cytoscape:a software environment for integrated models of biomolecular interaction networks.genome res 13,2498-2504.
[0423]
shao,w.,pedrioli,p.g.a.,wolski,w.,scurtescu,c.,schmid,e.,vizcaino,j.a.,courcelles,m.,schuster,h.,kowalewski,d.,marino,f.,et al.(2018).the systemhc atlas project.nucleic acids res 46,d1237-d1247.
[0424]
shlush,l.i.,mitchell,a.,heisler,l.,abelson,s.,ng,s.w.k.,trotman-grant,a.,medeiros,j.j.f.,rao-bhatia,a.,jaciw-zurakowsky,i.,marke,r.,et al.(2017).tracing the origins of relapse in acute myeloid leukaemia to stem cells.nature 547,104-108.
[0425]
smart,a.c.,margolis,c.a.,pimentel,h.,he,m.x.,miao,d.,adeegbe,d.,fugmann,t.,wong,k.-k.,and van allen,e.m.(2018).intron retention is a source of neoepitopes in cancer.nature biotechnology 36,1056-1058.
[0426]
smith,c.c.,selitsky,s.r.,chai,s.,armistead,p.m.,vincent,b.g.,and serody,j.s.(2019).alternative tumour-specific antigens.nat rev cancer 19,465-478.
[0427]
springer,i.,besser,h.,tickotsky-moskovitz,n.,dvorkin,s.,and louzoun,y.(2020).prediction of specific tcr-peptide binding from large dictionaries of tcr-peptide pairs.front immunol 11,1803.
[0428]
szolek,a.,schubert,b.,mohr,c.,sturm,m.,feldhahn,m.,and kohlbacher,o.(2014).optitype:precision hla typing from next-generation sequencing data.bioinformatics 30,3310-3316.
[0429]
takahashi,n.,coluccio,a.,thorball,c.w.,planet,e.,shi,h.,offner,s.,turelli,p.,imbeault,m.,ferguson-smith,a.c.,and trono,d.(2019).znf445 is a primary regulator of genomic imprinting.genes dev 33,49-54.
[0430]
tamura,h.,dan,k.,tamada,k.,nakamura,k.,shioi,y.,hyodo,h.,wang,s.d.,dong,h.,chen,l.,and ogata,k.(2005).expression of functional b7-h2 and b7.2 costimulatory molecules and their prognostic implications in de novo acute myeloid leukemia.clin cancer res 11,5708-5717.
[0431]
tate,j.g.,bamford,s.,jubb,h.c.,sondka,z.,beare,d.m.,bindal,n.,boutselakis,h.,cole,c.g.,creatore,c.,dawson,e.,et al.(2018).cosmic:the catalogue of somatic mutations in cancer.nucleic acids research 47,d941-d947.
[0432]
thomsen,m.,lundegaard,c.,buus,s.,lund,o.,and nielsen,m.(2013).mhccluster,a method for functional clustering of mhc molecules.immunogenetics 65,655-665.
[0433]
toffalori,c.,zito,l.,gambacorta,v.,riba,m.,oliveira,g.,bucci,g.,
barcella,m.,spinelli,o.,greco,r.,crucitti,l.,et al.(2019).immune signature drives leukemia escape and relapse after hematopoietic cell transplantation.nat med 25,603-611.
[0434]
tripathi,s.c.,peters,h.l.,taguchi,a.,katayama,h.,wang,h.,momin,a.,jolly,m.k.,celiktas,m.,rodriguez-canales,j.,liu,h.,et al.(2016).immunoproteasome deficiency is a feature of non-small cell lung cancer with a mesenchymal phenotype and is associated with a poor outcome.proc natl acad sci u s a 113,e1555-1564.
[0435]
van der lee,d.i.,reijmers,r.m.,honders,m.w.,hagedoorn,r.s.,de jong,r.c.,kester,m.g.,van der steen,d.m.,de ru,a.h.,kweekel,c.,bijen,h.m.,et al.(2019).mutated nucleophosmin 1 as immunotherapy target in acute myeloid leukemia.j clin invest 129,774-785.
[0436]
vasu,s.,kohlschmidt,j.,mrozek,k.,eisfeld,a.k.,nicolet,d.,sterling,l.j.,becker,h.,metzeler,k.h.,papaioannou,d.,powell,b.l.,et al.(2018).ten-year outcome of patients with acute myeloid leukemia not treated with allogeneic transplantation in first complete remission.blood adv 2,1645-1650.
[0437]
vizcaino,j.a.,csordas,a.,del-toro,n.,dianes,j.a.,griss,j.,lavidas,i.,mayer,g.,perez-riverol,y.,reisinger,f.,ternent,t.,et al.(2016).2016update of the pride database and its related tools.nucleic acids res 44,d447-456.
[0438]
wang,e.,lu,s.x.,pastore,a.,chen,x.,imig,j.,chun-wei lee,s.,hockemeyer,k.,ghebrechristos,y.e.,yoshimi,a.,inoue,d.,et al.(2019a).targeting an rna-binding protein network in acute myeloid leukemia.cancer cell 35,369-384.e367.
[0439]
wang,q.,ding,h.,he,y.,li,x.,cheng,y.,xu,q.,yang,y.,liao,g.,meng,x.,huang,c.,and li,j.(2019b).nlrc5 mediates cell proliferation,migration,and invasion by regulating the wnt/beta-catenin signalling pathway in clear cell renal cell carcinoma.cancer lett 444,9-19.
[0440]
whiteway,a.,corbett,t.,anderson,r.,macdonald,i.,and prentice,h.g.(2003).expression of co-stimulatory molecules on acute myeloid leukaemia blasts may effect duration of first remission.br j haematol 120,442-451.
[0441]
wong,j.j.l.,gao,d.,nguyen,t.v.,kwok,c.-t.,van geldermalsen,m.,middleton,r.,pinello,n.,thoeng,a.,nagarajah,r.,holst,j.,et al.(2017).intron retention is regulated by altered mecp2-mediated splicing factor recruitment.nature communications 8,15134.
[0442]
wu,t.d.,and nacu,s.(2010).fast and snp-tolerant detection of complex variants and splicing in short reads.bioinformatics 26,873-881.
[0443]
yang,l.,rau,r.,and goodell,m.a.(2015).dnmt3a in haematological malignancies.nat rev cancer 15,152-165.
[0444]
zhang,j.,hu,x.,wang,j.,sahu,a.d.,cohen,d.,song,l.,ouyang,z.,fan,j.,
advances 2015;1(8):e1500503-e1500503。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。