1.本发明属于医学病理学行业中的医学图像处理技术领域,具体涉及一种低成本高效的细胞核图像分割方法。
背景技术:
2.细胞核分割任务,是指标记出病理图像中每一个属于细胞核的像素,细胞核分割是计算机辅助诊疗系统中关键的一个环节分割出来的细胞核不仅有助于病理图像的进一步处理,也有助于病理医生诊断分析病情的发展。
3.细胞核分割的结果可以提供基本的细胞核视觉信息和形态学特征例如尺寸,形状或者颜色[1][2]。这些信息和特征不仅有助于病理图像的进一步处理(例如分类或者组织分割),也有助于病理医生诊断分析病情的发展(例如癌症的诊断评估和预后)。因此,细胞核分割在计算机辅助诊疗系统中是至关重要的一环。然而,病理图像复杂的背景,细胞核杂乱的分布都极大地增加了精确分割细胞核的难度。同时,训练一个精确分割细胞核的模型通常需要大量的有标注数据(细胞核的数量达到数万级别),这也显著地增加了病理医生标注的负担和时间经济成本。
[0004]
目前,主流的方法[3][4]大多为全监督方法,它们能够达到较高的分割精度但是却需要大量的细胞核像素级别的标注,这既耗时又昂贵,限制了这类方法的应用范围。一些基于域适应的无监督方法[5][6]使用无标签数据利用生成模型去构建一个有标签数据集,这种方法对无标签数据的种类和形态都有一定的限制,还存在精度不高的问题。半监督方法们[7][8]利用部分有标注的图片加上大量的无标注图片参与训练能够提升模型的性能,但他们很少考虑如何高效选择样本来进行标注的问题。主动学习方法[9][10]迭代地选择一些高价值的样本进行标注。在主动学习方法中,无标签图片会被随机初始化或者预训练的模型进行不确定性的预测,随后病理学家会针对不确定性高的图片进行有针对性的标注,标注后的图片又可以参与模型的训练来预测需要标注的无标签图片,整个过程反复迭代循环。它们的效果依赖于迭代训练的模型,由于需要配合多轮模型的训练加上人工标注,时间成本也较高。
[0005]
因此在模型训练之前,通过挑选有价值的样本能够最大程度地减少花费和提升效率。
[0006]
基于对抗生成模型(gans)[11][12]的方法可以进行样本生成,并且被广泛地应用在数据扩增领域;gans可以训练一个判别器去分辨生成器生成图像的真假,进而优化生成器的性能。传统的gans一般直接从噪声生成和目标图像类似的图片;而有条件的对抗生成模型(conditional gans)则可以通过输入的条件来生成和条件对应的图片,例如构建和输入文本相关的图片,或者和输入掩膜标签对应的图片。同时singan[13]是一种传统的gan,可以利用单张训练图片从噪声生成大量的相似图像。
[0007]
现有技术中缺少一种利用上述理论基础,通过有条件的singan(conditional singan)来生成与构造的细胞核掩膜对应的图片,以达到数据扩增目的的一种方法。
generative model from a single natural image.
”ꢀ
in iccv. ieee, 2019, pp. 4570
–
4580。
技术实现要素:
[0009]
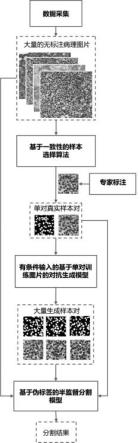
为了解决现有技术存在的上述问题,本发明目的在于提供一种低成本高效的细胞核图像分割方法,在尽可能减少标注成本的前提下,通过基于一致性的图像样本块选择算法达到和大量标注相当的分割性能。
[0010]
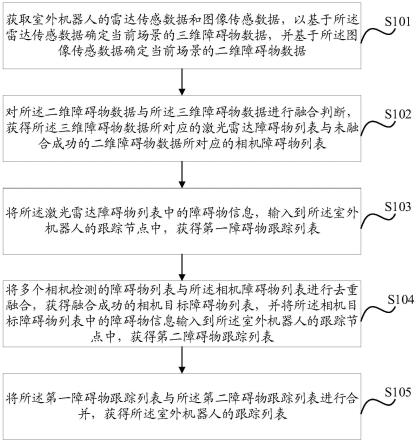
一种低成本高效的细胞核图像分割方法,包括有以下步骤:s1,采集原始的病理图像数据集,生成原始病理图像;s2,将原始病理图像裁切为若干小尺寸的病理图像样本块,构成小尺寸样本块;s3,筛选出少量的小尺寸样本块,由病理医生标注生成标注掩膜,并将筛选出的少量的小尺寸样本块定义为标注样本块;s4,每一张标注掩膜和相对应的标注样本块组成标注样本对;得到少量的标注样本对;s5,创建一个伪掩膜构造模块,根据每一张标注掩膜生成大量的伪掩膜;s6,将每一对标注样本对作为初始输入条件,分别创建一个有条件输入的基于单对训练图片的对抗生成网络模型——即csingan模型,每个csingan模型包含一个csingan模型生成器,每个csingan模型生成器使用一对标注好的标注样本对;s7,将每张伪掩膜作为csingan模型生成器的输入条件,生成与伪掩膜相对应的伪病理图片;s8,根据大量的伪掩膜训练csingan模型生成器,用csingan模型生成器生成大量的伪病理图片;s9,将每张伪病理图片与相对应的伪掩膜组成伪样本对;s10,将大量的伪样本对和标注样本对组成有标注分割训练集;标注样本对为真实样本对;s11,使用有标注分割训练集和大量的无标注病理图像对对基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型。
[0011]
进一步地,所述步骤s3的筛选出少量小尺寸样本块的操作中,包括以下操作内容:s31,采样;s32,双层聚类;s33,分数计算:计算每一个聚类簇中所有小尺寸样本块的代表性和内部一致性分数;筛选出每个聚类簇中分数最小的一个小尺寸样本块。
[0012]
进一步地,所述步骤s31中,包括以下操作内容:从原始病理图像利用滑动窗口均匀地采样大小为的小尺寸样本块,其中s为4的倍数。
[0013]
进一步地,所述步骤s32中,将小尺寸样本块聚集成聚类簇,按照小尺寸样本块与聚类簇中心的特征距离大小来选择代表性样本块,按照聚类簇内部各区域的小尺寸样本块的纹理和细胞核形态的相似程度来选择内部一致性样本块;所述双层聚类共执行两次k-means聚类,即k均值聚类算法。
[0014]
进一步地,所述步骤s32的双层聚类操作步骤中包括以下操作内容:s321,第一次聚类为粗聚类,将小尺寸样本块聚类成个聚类簇;s322,将每一个聚类簇中的每一个小尺寸样本块再裁切成四个子区域;s323,进行第二次聚类,得到个聚类簇,即细聚类;s324,经过两次聚类,最终得到个聚类簇。
[0015]
进一步地,每一次聚类使用的特征向量均为将样本块或子区域输入imagenet预训练的resnet50模型得到的特征。
[0016]
进一步地,所述步骤s33中,包括以下操作内容:s3301,将粗聚类得到的每一个聚类簇定义为,每个聚类簇中的每一个小尺寸样本块定义为;s3302,将第个聚类簇中分数最小的一个小尺寸样本块定义为;个聚类簇中筛选出个;s3303,计算聚类簇聚类中心的特征向量,即该聚类簇所有特征向量的均值,定义为;s3304,筛选出第二轮聚类――即细聚类中拥有最多的子区域数量的聚类簇,将细聚类中拥有子区域数量最多的聚类簇定义为;s3305,计算聚类簇的聚类中心c;s3306,计算粗每一个小尺寸样本块的代表性距离、细代表性距离以及内部一致性距离;粗代表性距离为每一个小尺寸样本块离其所属的粗分割聚类簇中心的距离;细代表性距离为每一个小尺寸样本块的四个子区域与拥有的子区域数量最多的聚类簇中心之间的距离之和内部一致性距离为每一个小尺寸样本块的任意两个子区域特征距离的最大值;s3307,按照公式(1)计算每一个聚类簇中所有小尺寸样本块的代表性和内部一致性分数;其中指的是特征提取器,即预训练的resnet50模型;都是属于小尺寸样本块的一个子区域;s3308,筛选出分数最小的一个小尺寸样本块;s3309,对粗聚类的个聚类簇筛选出个小尺寸样本块,即筛选出个标注样本块;s3310,针对个标注样本块标注生成出个标注掩膜,得到对标注样本对。
[0017]
再进一步地,所述s6的模型训练操作步骤中,包括以下内容:s61,创建一个伪掩膜构造模块,通过伪掩膜构造模块大量生成伪掩膜;
s611,对每一个真实掩膜,进行多种数据扩增,包括旋转、裁剪、翻转操作,得到一个扩充的细胞核掩膜集合e;s612,对每一个真实掩膜,迭代次生成个伪掩膜,每次迭代生成一个伪掩膜,每次迭代包括以下内容:s6121,另外打开一张空白图片,定义为;s6122,迭代q次,从真实细胞核掩膜集合中随机挑选q个细胞核掩膜,填充进空白图片中,每次迭代包括以下内容:s61221,从真实细胞核掩膜集合中随机挑选到第q个细胞核掩膜时,前q-1个细胞核掩膜填充后的中间结果为;s61222,对已得到的中间结果进行膨胀操作,膨胀半径为的最大半径;s61223,在膨胀之后的上随机找到一个没有细胞核的位置,将新细胞核摆放在该位置上,得到中间结果;s61224,当选择出第q个细胞核掩膜放到图片上时,迭代结束,得到一张包含q个细胞核掩膜的伪掩膜;s62,将每一张伪掩膜输入csingan模型生成器,生成一张伪病理图片。
[0018]
再进一步地,所述步骤s62中的csingan模型生成器,包括以下内容:s621,创建新的有条件输入的基于单对训练图片的对抗生成模型,每个csingan模型分别设置一个多尺度的有条件的生成器和一个多组件的判别器;多尺度的生成器定义为,多组件的判别器定义为;s622,多尺度的有条件的生成器表示为公式(2):(2)其中,表示真实的标注掩膜,表示伪掩膜;计算最终生成图像时,所有的()均通过改变的尺寸得到;和表示三通道的高斯噪声图像;操作表示按通道维度拼接矩阵;每一个生成器的网络结构和原始singan模型的模块相同;s623,对每个尺度的生成器和判别器都分别计算重建损失和判别损失,从而优化模型,如公式(3)所示:) (3)其中,第二项为重建损失,为生成图像,为真实图像;s623,多组件的判别器包括有三个子网络,多组件的判别器将输入图像分离为前景,背景和原图三类图像,通过三个子网络对三类图像分别进行判别;三个子网络的参数互相不共享;s624,判别器的判别过程按照如下公式(4)表示:(4)其中,为第n个尺度下的伪掩膜,为真实掩膜;
表示按元素相乘操作,即:为提取的背景区域和前景区域;不同的子网络关注不同的生成区域的真实程度,从而生成和伪掩膜中细胞核位置精确对应的生成图像,即得到大量生成的伪病理图片;为wgan-gp 损失函数,如公式(5)所示: (5)其中,y为生成图像,x为真实图像;为分别从x和y的分布的抽样的两点连成的直线上均匀采样;为判别器,为数学期望,为惩罚系数。
[0019]
最后,所述步骤s11中,包括以下操作内容:s111,通过标注样本对和伪样本对训练得到mask-rcnn模型;s112,将mask-rcnn模型在无标签的原始病理图像上进行第一轮预测,得到预测掩膜;s113,将预测掩膜作为原始图像的标签加入第二轮训练;s114,重复s112~s113,直到基于伪标签的半监督训练方法达到性能上限;s115,停止训练;s116,得到最终的分割模型。
[0020]
本发明的有益效果为:一种低成本高效的细胞核图像分割方法,采集无标签病理图像数据,通过基于一致性的图像样本块选择算法,筛选出少量的小尺寸的病理图像样本块由病理医生进行标注,标注之后的掩膜和选择的样本块组成样本对,作为有条件输入的基于单对训练图片的对抗生成模型的训练样本,经过模型训练,生成大量的伪样本对并加入分割训练集,所有的标注的真实样本对加上模型生成的伪样本对输入基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型;在尽可能减少标注成本的前提下,通过基于一致性的图像样本块选择算法达到和大量标注相当的分割性能。
附图说明
[0021]
图1是本发明实施例一低成本高效的细胞核图像分割方法流程示意图;图2是本发明实施例一低成本高效的细胞核图像分割方法的基于一致性的图像样本块选择算法的流程示意图;图3是本发明实施例一低成本高效的细胞核图像分割方法的基于一致性的图像样本块选择算法的计算过程示意图;图4是图3的左半部分放大示意图;图5是图3的右半部分放大示意图;图6是本发明实施例一低成本高效的细胞核图像分割方法中的伪掩膜构造流程示意图;图7是本发明实施例一低成本高效的细胞核图像分割方法中的有条件输入的基于单对训练图片的对抗生成模型;图8是本发明实施例一低成本高效的细胞核图像分割方法生成的伪掩膜构造模块与传统方法生成的伪掩膜构造模块对比图;(a)为传统方法生成的伪掩膜构造模块,(b)为本发明实施例一低成本高效的细胞核图像分割方法生成的伪掩膜构造模块;
图9是本发明模型(5%~7%标注)与先前全监督分割方法(100%标注)定量性能比较记录;图10是本发明各组成部件在tcga-kumar数据集上的效果示意。
具体实施方式
[0022]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0023]
如图1~10所示,本发明提供一种低成本高效的细胞核图像分割方法,整体策划方案为:从医院或者病理研究机构获取的大尺寸的病理图像中采集无标签病理图像数据,通过基于一致性的图像样本块选择算法,筛选出少量的小尺寸的病理图像样本块由病理医生进行标注,标注之后的标注掩膜和选择出的样本块组成样本对,作为有条件输入的基于单对训练图片的对抗生成模型的输入条件,经过模型训练,生成大量的伪样本对并加入分割训练集,所有的标注的真实样本对加上模型生成的伪样本对输入基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型;在尽可能减少标注成本的前提下,通过基于一致性的图像样本块选择算法达到和大量标注相当的分割性能。
[0024]
具体操作步骤如下:s1,采集原始的病理图像数据集,生成原始病理图像;s2,将原始病理图像裁切为若干小尺寸的病理图像样本块,构成小尺寸样本块;s3,筛选出少量的小尺寸样本块,由病理医生标注生成标注掩膜,并将筛选出的少量的小尺寸样本块定义为标注样本块;s31,采样;从原始病理图像利用滑动窗口均匀地采样大小为的小尺寸样本块,其中s为4的倍数。
[0025]
s32,双层聚类;将小尺寸样本块聚集成聚类簇,按照小尺寸样本块与聚类簇中心的特征距离大小来选择代表性样本块,按照聚类簇内部各区域的小尺寸样本块的纹理和细胞核形态的相似程度来选择内部一致性样本块;所述双层聚类共执行两次k-means聚类,即k均值聚类算法。
[0026]
s321,第一次聚类为粗聚类,将小尺寸样本块聚类成个聚类簇;s322,将每一个聚类簇中的每一个小尺寸样本块再裁切成四个子区域;s323,进行第二次聚类,得到个聚类簇,即细聚类;s324,经过两次聚类,最终得到个聚类簇。
[0027]
每一次聚类使用的特征向量均为将样本块或子区域输入imagenet预训练的resnet50模型得到的特征。
[0028]
s33,分数计算:计算每一个聚类簇中所有小尺寸样本块的代表性和内部一致性分数;筛选出每个聚类簇中分数最小的一个小尺寸样本块。
[0029]
s3301,将粗聚类得到的每一个聚类簇定义为,每个聚类簇中的每一个小尺
寸样本块定义为;s3302,将第个聚类簇中分数最小的一个小尺寸样本块定义为;个聚类簇中筛选出个;s3303,计算聚类簇聚类中心的特征向量,即该聚类簇所有特征向量的均值,定义为;s3304,筛选出第二轮聚类――即细聚类中拥有最多的子区域数量的聚类簇,将细聚类中拥有子区域数量最多的聚类簇定义为;s3305,计算聚类簇的聚类中心c;s3306,计算粗每一个小尺寸样本块的代表性距离、细代表性距离以及内部一致性距离;粗代表性距离为每一个小尺寸样本块离其所属的粗分割聚类簇中心的距离;细代表性距离为每一个小尺寸样本块的四个子区域与拥有的子区域数量最多的聚类簇中心之间的距离之和内部一致性距离为每一个小尺寸样本块的任意两个子区域特征距离的最大值;s3307,按照公式(1)计算每一个聚类簇中所有小尺寸样本块的代表性和内部一致性分数;其中指的是特征提取器,即预训练的resnet50模型;都是属于小尺寸样本块的一个子区域;s3308,筛选出分数最小的一个小尺寸样本块;s3309,对粗聚类的个聚类簇筛选出个小尺寸样本块,即筛选出个标注样本块;s3310,针对个标注样本块标注生成出个标注掩膜,得到对标注样本对。
[0030]
s4,每一张标注掩膜和相对应的标注样本块组成标注样本对;得到少量的标注样本对;s5,创建一个伪掩膜构造模块,根据每一张标注掩膜生成大量的伪掩膜;s6,将每一对标注样本对作为初始输入条件,分别创建一个有条件输入的基于单对训练图片的对抗生成网络模型——即csingan模型,每个csingan模型包含一个csingan模型生成器,每个csingan模型生成器使用一对标注好的标注样本对;s61,创建一个伪掩膜构造模块,通过伪掩膜构造模块大量生成伪掩膜;s611,对每一个真实掩膜,进行多种数据扩增,包括旋转、裁剪、翻转操作,得到一个扩充的细胞核掩膜集合e;s612,对每一个真实掩膜,迭代次生成个伪掩膜,每次迭代生成一个伪掩膜,每次迭代包括以下内容:s6121,另外打开一张空白图片,定义为;
s6122,迭代q次,从真实细胞核掩膜集合中随机挑选q个细胞核掩膜,填充进空白图片中,每次迭代包括以下内容:s61221,从真实细胞核掩膜集合中随机挑选到第q个细胞核掩膜时,前q-1个细胞核掩膜填充后的中间结果为;s61222,对已得到的中间结果进行膨胀操作,膨胀半径为的最大半径;s61223,在膨胀之后的上随机找到一个没有细胞核的位置,将新细胞核摆放在该位置上,得到中间结果;s61224,当选择出第q个细胞核掩膜放到图片上时,迭代结束,得到一张包含q个细胞核掩膜的伪掩膜;s62,将每一张伪掩膜输入csingan模型生成器,生成一张伪病理图片。
[0031]
csingan模型生成器包括以下内容:s621,创建新的有条件输入的基于单对训练图片的对抗生成模型,每个csingan模型分别设置一个多尺度的有条件的生成器和一个多组件的判别器;多尺度的生成器定义为,多组件的判别器定义为;s622,多尺度的有条件的生成器表示为公式(2):(2)其中,表示真实的标注掩膜,表示伪掩膜;计算最终生成图像时,所有的()均通过改变的尺寸得到;和表示三通道的高斯噪声图像;操作表示按通道维度拼接矩阵;每一个生成器的网络结构和原始singan模型的模块相同;s623,对每个尺度的生成器和判别器都分别计算重建损失和判别损失,从而优化模型,如公式(3)所示:) (3)其中,第二项为重建损失,为生成图像,为真实图像;s623,多组件的判别器包括有三个子网络,多组件的判别器将输入图像分离为前景,背景和原图三类图像,通过三个子网络对三类图像分别进行判别;三个子网络的参数互相不共享;s624,判别器的判别过程按照如下公式(4)表示:(4)其中,为第n个尺度下的伪掩膜,为真实掩膜;表示按元素相乘操作,即:为提取的背景区域和前景区域;不同的子网络关注不同的生成区域的真实程度,从而生成和伪掩膜中细胞核位置精确对应的生成图像,即得到大量生成的伪病理图片;为wgan-gp 损失函数,如公式(5)所示:
ꢀ
(5)其中,y为生成图像,x为真实图像;为分别从x和y的分布的抽样的两点连成的直线上均匀采样;为判别器,为数学期望,为惩罚系数。
[0032]
s7,将每张伪掩膜作为csingan模型生成器的输入条件,生成与伪掩膜相对应的伪病理图片;s8,根据大量的伪掩膜训练csingan模型生成器,用csingan模型生成器生成大量的伪病理图片;s9,将每张伪病理图片与相对应的伪掩膜组成伪样本对;s10,将大量的伪样本对和标注样本对组成有标注分割训练集;标注样本对为真实样本对;s11,使用有标注分割训练集和大量的无标注病理图像对对基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型;s111,通过标注样本对和伪样本对训练得到mask-rcnn模型;s112,将mask-rcnn模型在无标签的原始病理图像上进行第一轮预测,得到预测掩膜;s113,将预测掩膜作为原始图像的标签加入第二轮训练;s114,重复s112~s113,直到基于伪标签的半监督训练方法达到性能上限;s115,停止训练;s116,得到最终的分割模型。
[0033]
本发明提出了一种高效利用标签的细胞核分割框架,在尽可能减少标注成本的前提下,达到和大量标注相当的分割性能:(1)为了解决现有技术需要大量标注数据的问题,本发明提出了一种基于一致性的图像样本块选择算法。该算法挑选极少量的具有高代表性和内部纹理一致性的无标签样本块进行标注。高代表性是为了使挑选出来的样本块能够尽可能代表某一类或几类具有类似纹理的病理图片,内部纹理一致性是为了减少样本生成的难度,避免复杂多变的纹理信息误导生成模型。(2)为了解决现有技术在标注较少时分割性能较差的问题,本发明提出了有条件输入的基于单对训练图片的对抗生成模型conditional single-image gan (csingan)来对训练数据进行扩增。该模型在现有模型singan[13]的基础之上,加入了伪造的分割标签图作为模型条件输入,并且构造了三个独立的针对原图,背景,前景的判别器来优化生成器。(3)为了充分利用大量的无标签数据,本发明通过和半监督方法-伪标签生成[14]的结合来利用无标签数据。实验证明本发明提出的框架利用不到百分之五的标注,在三个公开数据集上达到了接近全监督方法的性能。
[0034]
[14] d.-h. lee et al.,
ꢀ“
pseudo-label: the simple and efficient semi-supervised learning method for deep neural networks,
”ꢀ
in workshop on challenges in representation learning, icml, vol. 3, no. 2, 2013, p. 896.本发明提出的标签高效式的细胞核图像分割框架的流程如图1所示。从上到下,首先进行无标签病理图像数据的采集从医院或者病理研究机构获取的大尺寸的病理图像中采集无标签病理图像数据,生成原始病理图像。其次,通过本发明提出的基于一致性的图像样本块选择算法,少量的小尺寸的病理图像样本块将会被选择并且由病理医生进行标注,标注之后的标注掩膜和选择的标注样本块将会组成标注样本对,即真实样本对。每一对标
注样本对作为初始输入条件,将会作为本发明提出的有条件输入的基于单对训练图片的对抗生成型csingan模型生成器的训练样本。经过对抗生成模型csingan模型生成器的训练,得到大量的伪病理图片与伪掩膜配对构成大量的伪样本对;大量的伪样本对将会被csingan模型生成器生成并且加入分割训练集。最后,所有的标注的真实样本对加上模型生成的伪样本对将会输入基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型。
[0035]
核心技术内容:1、一种基于一致性的图像样本块选择算法。
[0036]
2、一种伪掩膜构造方法。
[0037]
3、一个有条件输入的基于单对训练图片的对抗生成网络。
[0038]
4、一个针对全图,前景,背景的多组件判别器。
[0039]
基于一致性的图像样本块选择算法(consistency-based patch selection, cps):为了定位最有益于细胞核分割任务的病理图像样本块区域,我们定义两种挑选参数。一种叫做代表性,另一种叫做内部一致性。代表性指的是被挑选样本块与整个数据集中的其他的样本块之间的关系。考虑到因为病理图像本身存在大量冗余纹理信息的原因,在将原始图像裁切为小尺寸的样本块之后,在隐空间中,一些样本块会聚集成聚类簇,我们定义离聚类簇中心特征距离越小的样本块比同簇中其他的样本块越具代表性,所述距离为欧氏距离,是选择的一般标准。这个距离越小,就最有可能能更好地代表整个聚类簇。这个与聚类中心的欧氏距离是最终选择的标准之一,最终用一个总的距离公式来取样本。
[0040]
标注这些更具代表性的样本块可以有效地减少原始大数据集中的冗余现象。为了减轻对抗生成模型生成伪样本的复杂程度,我们还考虑选择内部一致性更高的样本块。内部一致性是指样本块内部各区域具有相似的纹理和细胞核形态。高内部一致性有助于减少对抗生成模型学习的难度,减少干扰,有助于模型的收敛,也能够更有效生成高质量的图片。
[0041]
如图2、图3、图4、图5所示,为了挑选具有更高代表性和内部一致性的样本块,我们的样本选择算法可以分成三部分:1)小尺寸样本块采样;2)双层聚类;3)分数计算。
[0042]
1)在小尺寸样本块采样部分,我们从原始的无标签病理图像数据集――原始病理图像集中利用滑动窗口均匀地采样大小为的小尺寸样本块。最终算法会从采样出来的这些小尺寸样本块中选择需要标注的样本块。
[0043]
用正方形的滑动窗口以固定大小的间距裁切出正方形的图像样本块,图像样本块的边长大小为256像素或者512像素,间距一般小于裁切尺寸即可。一般取256像素或者512像素。最好是四的倍数,方便基于一致性的图像样本块选择算法进一步裁切。
[0044]
2)在双层聚类部分执行了两次k-means[15]聚类,即两次k均值聚类算法。
[0045]
第一次聚类为粗聚类,将小尺寸样本块聚类成个聚类簇。
[0046]
为了计算内部一致性,每一个聚类簇中的小尺寸样本块又会被再裁切成四个更小
的子区域进行第二次聚类得到个聚类簇,也叫作细聚类。
[0047]
每一次聚类使用的特征向量为样本块或子区域输入imagenet[16]预训练的resnet50模型[17]得到的特征。经过两次聚类,最终可以得到个聚类簇。
[0048]
3)在分数计算部分,对每一个粗聚类得到的聚类簇,k指代和个聚类簇中的某个,就是指第k个聚类簇,我们会计算该簇中所有的小尺寸样本块的代表性和内部一致性分数,最终选择一个分数最小的样本块。
[0049]
计算公式如图3的右半部分以及公式(1)所示。代表聚类簇中一个小尺寸样本块,代表第个聚类簇中最终被选择的小尺寸样本块。指的是特征提取器也就是预训练的resnet50模型。都是属于的一个子区域。
[0050]
计算聚类簇聚类中心的特征向量,也就是该聚类簇所有特征向量的均值。
[0051]
在第二轮聚类――细聚类中,指的是拥有最多的子区域数量的聚类簇。c计算聚类簇的聚类中心。
[0052]
图3右半部分的三个距离公式分别代表了粗代表性(离其所属的粗分割聚类簇中心的距离),细代表性(的子区域离数量最大的细分割聚类簇中心的距离之和)以及内部一致性(的任意两个子区域特征距离的最大值)。最终越小的分数表示样本块越具有代表性以及内部一致性。本发明的样本选择算法会为粗聚类的每一类挑选一个样本块,最终得到个样本块。
[0053]
有条件输入的基于单对训练图片的对抗生成网络(conditional single-image generative adversarial network, csingan):在得到标注好的对小尺寸样本块之后,本发明提出了一个有条件输入的基于单对训练图片的对抗生成模型(csingan模型生成器)对每一对样本块分别进行数据增强。每个csingan模型生成器会使用一对标注好的样本块。
[0054]
在模型训练之前,本发明还设计了一个简单高效的伪掩膜构造模块,来大量生成伪掩膜,作为csingan模型生成器的条件输入。本发明提出了新的一种细胞核伪掩膜构造的模块,细胞核掩膜就是每一个细胞核对应的标签。如图6所示,得到张标注掩膜之后,首先对所有的真实掩膜――即标注掩膜进行多种数据扩增,包括旋转,裁剪,翻转,这样得到一个扩充的细胞核掩膜集合。接下来,算法会迭代地从真实细胞核掩膜集合――扩充的细胞核掩膜集合中随机挑选一定数量的细胞核掩膜,填充进一个空白的图片中来构建伪掩膜。
[0055]
定义选择数量为q个,具体需要用户根据其病理图片的特点设定,细胞核密集的图像可以设大一些,稀疏的可以设小一些。
[0056]
是挑选到的其中第q个,这是一个循环挑选的过程,最终挑选q个,如图4伪掩膜构造方法所示。
[0057]
将空白图片可以视为,放了一个细胞核掩膜就是,放了q-1个就是;采用迭代加入新细胞核的过程,指的就是加入到第q个细胞核掩膜时,之前已加入q-1个细胞核掩膜的结果。对进行膨胀,这样剩下的空白区域内放置,确保新的和之前的q-1个细胞核掩膜不会重叠。
[0058]
为了防止构造的细胞核相互之间产生重叠,该模块在选择新细胞核摆放位置时,会对已得到的中间结果进行膨胀操作,膨胀半径为的最大半径。然后,在膨胀之后的上随机找到一个位置,将新细胞核摆放在该位置上。
[0059]
伪掩膜具体构建过程: 是一个循环随机放置标注掩膜中的真实细胞核掩膜到一张空白图片的过程。循环次数为q,也就是最终可以放q个细胞核掩膜到一张空白图片上。q轮迭代后可以得到一张伪掩膜图片。
[0060]
为了生成对应于伪掩膜的伪病理图片,同时利用尽可能少的训练标注,本发明提出了新的有条件输入的基于单对训练图片的对抗生成模型。该模型的目的在于,生成和输入掩膜中细胞核标签对应的伪病理图像。其结构如图7所示,该模型包含一个多尺度的有条件的生成器和一个多组件的判别器,为了解释公式,指的是最大尺度的生成图像,指的是第n个尺度的生成图像。生成器和判别器分别表示为和。多尺度的有条件的生成器可以表示为公式(2):(2)其中,和表示真实的标注掩膜和伪掩膜。当计算最终生成图像时,所有的()都是通过改变的尺寸得到的。m是掩膜,可以是真实掩膜也可是伪掩膜,每一层的生成器判别器都需要尺寸不同的m,从0~n尺寸增大,就是对进行resize得到的。
[0061]
和表示三通道的高斯噪声图像。操作表示按通道维度拼接矩阵。每一个生成器的网络结构和原始singan 模型[13]的模块相同,原始singan 模型即引用的singan文章中所述singan 模型,其具体网络结构为五个(卷积层 正则化层 leakyrelu激活函数)。每个尺度的生成器和判别器都会计算一个重建损失和判别损失来优化模型,如公式(3)所示:) (3)其中,第二项为重建损失,为生成图像,则为真实图像。对于判别损失,本发明设计了一种新型的多组件的判别器。该判别器将输入图像分离为前景,背景和原图三类图像分别进行判断,即在生成器生成图像之后,输入判别器之前。判别器的输入为真实样本对(真实样本和标注掩膜)和生成样本对(生成样本和伪掩膜),判别器的目的是为了判断生成样本块是否与真实样本块相似。这里把真实样本块和生成样本块都分离成三类图像(通过其掩膜可以进行前景,背景的分离)来分别计算判别损失。判别器包含三个子网络,分别对三类图像进行判别,彼此(三个子网络)之间互不参数共享。整个判别过程可以用如下公式(4)表示:
(4)其中,指第n个尺度下的伪掩膜,指真实掩膜。指按元素相乘操作,指的就是提取的背景区域和前景区域。这样不同的子网络就会关注于不同的生成区域的真实程度。这有助于生成和伪掩膜中细胞核位置精确对应的生成图像。指的是wgan-gp 损失函数[18],是一种在判别器中常用的损失函数,如公式(5)所示: (5)其中,y和x指生成图像和真实图像。指在分别从x和y的分布的抽样的两点连成的直线上均匀采样。指的是判别器,表示数学期望,为惩罚系数。
[0062]
基于伪标签的半监督训练方法:在得到大量的生成的伪病理图片对之后,每张伪病理图片分别与相应的伪掩膜组成伪样本对。
[0063]
本发明引入了基于伪标签的半监督训练方法来充分利用无标签数据。伪标签[19]方法通常使用一个预训练的模型来对无标签数据进行预测。预测出来的结果可以和原始数据结合作为一种标签参与新一轮的训练来提升模型的性能。本发明以mask-rcnn(mrcnn)[20]为例,首先一个预训练的mask-rcnn模型可以通过在真实样本对(标注样本对)和生成样本对(伪样本对)上训练得到mask-rcnn模型。然后,该预训练的mask-rcnn模型会在无标签的数据――无标签的原始病理图像上进行第一轮预测,这些预测的掩膜会作为原始图像的标签加入第二轮训练。经过几轮训练,基于伪标签的方法会达到分割性能上限,则可停止训练,得到最终的分割模型。分割性能可以描述为分割精度。分割性能上限就是指无法通过进一步的伪标签训练来提升,继续使用伪标签分割精度会不变甚至下降。
[0064]
实验证明,本发明可以结合其他的半监督方法或细胞核分割模型使用来提升性能。
[0065]
[15] b. gao, y. yang, h. gouk, and t. m. hospedales,
ꢀ“
deep clustering with concrete k-means,
”ꢀ
in international conference on acoustics, speech and signal processing (icassp). ieee, 2020, pp. 4252
–
4256.[16] j. deng, w. dong, r. socher, l.-j. li, k. li, and l. fei-fei,
ꢀ“
imagenet: a large-scale hierarchical image database,
”ꢀ
in ieee computer vision and pattern recognition conference, 2009, pp. 248
–
255.[17] k. he, x. zhang, s. ren, and j. sun,
ꢀ“
deep residual learning for image recognition,
”ꢀ
in ieee computer vision and pattern recognition conference, 2016, pp. 770
–
778.[18] i. gulrajani, f. ahmed, m. arjovsky, v. dumoulin, and a. courville,
ꢀ“
improved training of wasserstein gans,
”ꢀ
in advances in neural information processing systems, 2017.[19] d.-h. lee et al.,
ꢀ“
pseudo-label: the simple and efficient semi-supervisedlearning method for deep neural networks,
”ꢀ
in workshop on challenges in representation learning, icml, vol. 3, no. 2, 2013, p. 896.
[20] k. he, g. gkioxari, p. doll
´
ar, and r. girshick,
ꢀ“
mask r-cnn,
”ꢀ
in iccv. ieee, 2017, pp. 2961
–
2969.伪掩膜构造方法:之前的伪掩膜构造方法[21]尝试从基于统计预定义的细胞核形态分布直接生成伪掩膜,例如利用统计好的半径,不规则度,刺突数来构造多边形。然而这种方法需要大量的细胞核标注来进行统计,在标注数量很少的情况下,它的伪掩膜构造效果不佳。如图8所示,本方法构造的掩膜接近真实掩膜。
[0066]
[21] l. hou, a. agarwal, d. samaras, t. m. kurc, r. r. gupta, and j. h. saltz,
ꢀ“
robust histopathology image analysis: to label or to synthesize
”ꢀ
in ieee computer vision and pattern recognition conference, 2019, pp. 8533
–
8542如图9 所示,本发明整体框架结合先前分割方法[20][27]在使用约5%标注的情况下,在tcga-kumar数据集上[28]和最强的全监督方法hover-net[27]仅差距0.2%分割指标aji,在tnbc数据集[22]上达到了和超过hover-net的效果。在使用7%标注的情况下,在monuseg数据集[29]上得到了略低于hover-net约1.17% aji的结果。这充分显示了本发明在缺少标签的病理图片分割应用场景的优势,即极大了减少了标注成本。
[0067]
如图10所示,本发明各组成部件在本发明提出的细胞核分割框架中起到了至关重要的作用。cps表示基于一致性的样本选择算法,mrcnn指的是分割模型mask-rcnn,csingan指的是有条件输入的基于单对训练图片的对抗生成模型,plabel表示伪标签训练方法。对比a)和b),csingan方法使分割模型在tcga-kumar数据集上提升了1.34% aji。比较b)和c),本发明提出的样本选择算法cps相较随机采样方法提升了约2.83% aji。通过d)和b)的对比实验,加入基于伪标签的半监督训练方法之后,本发明的分割性能可以进一步提升4.54% aji。
[0068]
[22] p. naylor, m. la
´
e, f. reyal, and t. walter,
ꢀ“
segmentation of nuclei in histopathology images by deep regression of the distance map,
”ꢀ
ieee transactions on medical imaging, vol. 38, no. 2, pp. 448
–
459, 2018.[23] s. e. a. raza, l. cheung, m. shaban, s. graham, d. epstein, s. pelengaris, m. khan, and n. m. rajpoot,
ꢀ“
micro-net : a unified model forsegmentation of various objects in microscopy images,
”ꢀ
medical imageanalysis, vol. 52, pp. 160
–
173, 2019.[24] x. liu, z. guo, j. cao, and j. tang,
ꢀ“
mdc-net : a new convolutional neural network for nucleus segmentation in histopathology images with distance maps and contour information,
”ꢀ
computers in biology and medicine, p. 104543, 2021.[25] d. liu, d. zhang, y. song, c. zhang, f. zhang, l. o’donnell, and w. cai,
ꢀ“
nuclei segmentation via a deep panoptic model with semantic feature fusion,
”ꢀ
in ijcai, 2019, pp. 861
–
868.[26] d. liu, d. zhang, y. song, h. huang, and w. cai,
ꢀ“
panoptic feature fusion net: a novel instance segmentation paradigm for biomedical and biological images,
”ꢀ
ieee transactions on image processing, vol. 30, pp. 2045
–
2059, 2021.[27] s. graham, q. d. vu, s. e. a. raza, a. azam, y. w. tsang, j. t.kwak, and n. rajpoot,
ꢀ“
hover-net:simultaneous segmentation andclassification of nuclei in multi-tissue histology images,
”ꢀ
medical imageanalysis, vol. 58, p. 101563, 2019.[28] n. kumar, r. verma, s. sharma, s. bhargava, a. vahadane, and a. sethi,
ꢀ“
a dataset and a technique for generalized nuclear segmentation for computational pathology,
”ꢀ
ieee transactions on medical imaging, vol. 36, no. 7, pp. 1550
–
1560, 2017.[29] n. kumar, r. verma, d. anand, y. zhou, o. f. onder, e. tsougenis, h. chen, p.-a. heng, j. li, z. hu et al.,
ꢀ“
a multi-organ nucleus segmentation challenge,
”ꢀ
ieee transactions on medical imaging, vol. 39, no. 5, pp. 1380
–
1391, 2019.应用前景推广:细胞核分割是计算机辅助诊疗系统中关键的一个环节。分割出来的细胞核不仅有助于病理图像的进一步处理,也有助于病理医生诊断分析病情的发展。
[0069]
本发明可以大幅度减少病理图像细胞核分割相关的诊断研究和商业诊疗系统生产所需要的标注成本。
[0070]
本发明可以挑选病理图像中有价值样本块为医学诊疗提供参考。
[0071]
本发明可以为病理图像的细胞核分类和组织分割提供帮助。
[0072]
本发明不局限于上述可选实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是落入本发明权利要求界定范围内的技术方案,均落在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。