1.本发明涉及婴儿肢体动作训练及收集的技术领域,具体为一种基于婴儿肢体动作数据的分类器训练方法。
背景技术:
2.随着社会的发展进步,越来越多的科研机构对于婴幼儿的健康发育投入更多的关注,一些智能化、前沿化的技术投入其中,以为了更准确、直观、预测到儿童的健康发展,运动发育是婴幼儿早期综合发展的重要内容之一,婴幼儿运动发育主要体现在抗重力移动能力和直立体位能力的演变和成熟中,运动技能的展示不是静止的,而是随年龄顺序的改变而改变,婴幼儿的运动发育有着连续性,也存在关键期,根据运动发育的神经成熟理论、运动的多系统理论和认知运动理论,运动发育的落后或异常通常预示着神经系统发育的异常或认知功能的偏离以及肌肉、骨骼、运动等重要器官的异常。
3.目前,当进行婴儿肢体动作数据的在线学习时,每个训练样本逐一的更新弱分类器集合中的每个弱分类器,包括调整正负样本的分类阈值以及该分类器的权重,使好的弱分类器权重越来越高,而较差的弱分类器权重越来越低,从而每次婴儿肢体动作数据的在线学习一个样本时就可以挑选出一个当前权重最高的弱分类器加入强分类器中使最终训练出来的分类器有较强的分类能力。
4.但是,在线boosting算法的弱分类器集合中每个弱分类器都要对新样本进行婴儿肢体动作数据的在线学习,当弱分类器个数较多时,婴儿肢体动作数据的在线学习速度必然会变慢。
5.传统的在线adaboost用特征选择算子代替一般的弱分类器合成强分类器,特征选择算子数以及特征选择算子对应的弱分类器数都是固定的,相应的婴儿肢体动作数据的在线学习分类器结构比较僵化,当发现其分类能力无法满足检测性能的要求时,即使持续的婴儿肢体动作数据的在线学习下去也无法提高检测精度。
技术实现要素:
6.本发明的目的在于提供一种基于婴儿肢体动作数据的分类器训练方法,以解决上述背景技术中提出的问题。
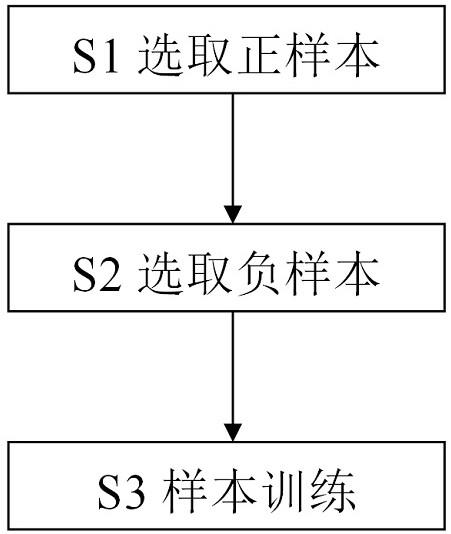
7.为实现上述目的,本发明提供如下技术方案:一种基于婴儿肢体动作数据的分类器训练方法,其特征在于:包括以下步骤:s1:选取正样本;s2:选取负样本;s3:将选取的正、负样本导入分类器内进行样本训练。
8.作为本发明的进一步优选实施方式,所述步骤s1中选取正样本包括以下步骤:s11:基于正样本选取规则采集正样本图片并保存于正样本文件夹中;s12:获取正样本文件夹中所有正样本图片的图片路径数据信息;
s13:生成正样本文件夹中所有正样本图片的图片路径矢量数据信息;s14:创建正样本文件。
9.作为本发明的进一步优选实施方式,所述步骤s11中,所述正样本选取规则包括:1)每个正样本图片的尺寸不须保持一致;2)判断每个正样本图片的尺寸比例与生成的正样本图片的图片路径矢量集数据信息中的尺寸比例是否一致;若一致,则进入下一步骤;若不一致,则根据正样本图片的图片路径矢量集数据信息中预设的尺寸比例,自动对正样本图片的尺寸比例进行缩放;3)正样本图片中的背景信息只选择最有效正样本图片的一个局部特征,使得特征值的计算包含干扰信息。
10.作为本发明的进一步优选实施方式,所述步骤s11中,所述采集正样本图片包括:裁剪并保存图片原图,使其尺寸比例与经过归一化处理后的尺寸比例一致,并保留其框个数和框位置信息;其中,所述归一化处理包括:通过遍历正样本图片中的每一条图片信息,并分别记录每一条图片信息的max和min值,以min=0,max=1作为基数,进行归一化处理:其中,x
nor
为每一条图片信息经过归一化处理后的值;x为每一条图片信息的初始值;min为每一条图片信息的最小值;max为每一条图片信息的最大值;框作为裁剪图片时显示的区域标记。
11.作为本发明的进一步优选实施方式,所述步骤s12中,所述获取正样本文件夹中所有正样本图片的图片路径数据信息包括以下步骤:s121:在正样本文件夹里,编写批处理程序;s122:运行所述批处理程序,生成与每一正样本图片对应的数据信息;s123:删除所述数据信息中所有非图片路径的数据信息,再将每一正样本图片对应的数据信息中的文件格式由bmp替换成jpg 1 0 0 64 64,其中,数字1代表个数;第一位数字0对应表示left;第二位数字0对应top;第三位数字64对应width;第四位数字64对应height。
12.作为本发明的进一步优选实施方式,所述步骤s13中,所述生成正样本文件夹中所有正样本图片的图片路径矢量数据信息包括:利用图像处理软件将正样本文件夹里每一正样本图片对应的图片路径的数据信息生成新的正样本图片的图片路径矢量数据信息。
13.作为本发明的进一步优选实施方式,所述步骤s14中,所述创建正样本文件的命令行参数包括以下步骤:s141:将输入图像沿着三个轴随机旋转;s142:对旋转的角度进行限定,并将输入图像中亮度值位于预设范围的像素设置为透明像素,将白噪声加到前景图像上;s143:任选背景图像,将获得的前景图像放到背景图像上形成组合图像,并将组合图像调整到预设的尺寸比例;s144:最后将组合图像存储以形成正样本vec文件。
14.作为本发明的进一步优选实施方式,所述步骤s2中选取负样本包括以下步骤:s21:基于负样本选取规则采集负样本图片并保存于负样本文件夹中;s22:获取负样本文件夹中所有负样本图片的图片路径数据信息;s23:生成负样本文件夹中所有负样本图片的图片路径矢量数据信息;s24:创建负样本文件。
15.作为本发明的进一步优选实施方式,所述步骤s21中,所述负样本选取规则包括:1)不包含正样本图片;2)每个负样本图片各不相同;3)每个负样本图片的尺寸不必相同,但任一负样本图片的尺寸不能小于正样本图片的尺寸。
16.作为本发明的进一步优选实施方式,所述步骤s3中将选取的正、负样本导入分类器内进行样本训练包括以下步骤:s31:设置最大虚警率和最小命中率的关联性;s32:根据提供的正负样本的数量设置训练阶数;s33:在每阶训练中,根据样本的命中率进行分类,计算样本的虚警率,如果虚警率高于最大虚警率,则认定训练不合格,系统就抛弃该分类器,建立下一个分类器;如果虚警率不高于最大虚警率,则认定该阶训练合格,系统进入下一阶训练;s34:当所有训练阶数均训练合格后,认定该分类器合格。
17.与现有技术相比,本发明实现的有益效果是:1)本发明提供一种基于婴儿肢体动作数据的分类器训练方法,将级联分类器算法引入到婴儿肢体动作数据的在线学习中,获得自适应级联分类器;通过级联分类器使检测模型能够容纳更多的特征,有更强的分类能力,提高了婴儿肢体动作数据的在线学习分类器的智能化程度,大大减轻了人工标注样本类别的工作量,使得研究婴儿肢体动作数据的分析工作更为精准和高效率。
附图说明
18.图1为本发明的步骤流程图。
19.图2为本发明步骤s122的示意图。
20.图3为本发明步骤s123的示意图。
21.图4为本发明步骤s14的示意图。
具体实施方式
22.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
23.在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
24.在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
25.如图1所示,本发明提供一种基于婴儿肢体动作数据的分类器训练方法,包括以下步骤:s1:选取正样本;s2:选取负样本;s3:将选取的正、负样本导入分类器内进行样本训练。
26.在本实施例中,步骤s1中选取正样本包括以下步骤:s11:基于正样本选取规则采集正样本图片并保存于正样本文件夹中;其中,正样本选取规则包括:1)每个正样本图片的尺寸不须保持一致;2)判断每个正样本图片的尺寸比例与生成的正样本图片的图片路径矢量集数据信息中的尺寸比例是否一致;若一致,则进入下一步骤;若不一致,则根据正样本图片的图片路径矢量集数据信息中预设的尺寸比例,自动对正样本图片的尺寸比例进行缩放;3)正样本图片中的背景信息只选择最有效正样本图片的一个局部特征,使得特征值的计算包含干扰信息。在本实施例中,该规则中的局部特征,可以是例如颜色鲜艳强烈、图形特殊等,但不能有过多干扰元素,否则会影响计算精度。
27.而采集正样本图片包括:裁剪并保存图片原图,使其尺寸比例与经过归一化处理后的尺寸比例一致,并保留其框个数和框位置信息;其中,所述归一化处理包括:通过遍历正样本图片中的每一条图片信息,并分别记录每一条图片信息的max和min值,以min=0,max=1作为基数,进行归一化处理:其中,x
nor
为每一条图片信息经过归一化处理后的值;
x为每一条图片信息的初始值;min为每一条图片信息的最小值;max为每一条图片信息的最大值;框作为裁剪图片时显示的区域标记。
28.在本实施例中,框个数和框位置信息属于隐含公开的内容,提前对其进行框个数和位置的处理,后续在进行图片信息计算(尤其是关键特征)的时候,可以提高效率,框作为裁剪图片时添加的区域标记,便于后期的运算,能够快速、准确的找到标记点。
29.s12:获取正样本文件夹中所有正样本图片的图片路径数据信息;包括以下步骤:s121:在正样本文件夹里,编写例如包括bat程序在内的等批处理程序;s122:运行所述批处理程序,生成与每一正样本图片对应的数据信息,数据信息可以存储于dat文件中;如图2所示,在正样本文件夹里,编写一个bat程序,运行bat文件,就会生成如图所示dat文件,dat文件中包含与每一正样本图片对应的数据信息;s123:删除所述数据信息中所有非图片路径的数据信息,再将每一正样本图片对应的数据信息中的文件格式由bmp替换成jpg 1 0 0 64 64,其中,数字1代表个数;第一位数字0对应表示left;第二位数字0对应top;第三位数字64对应width;第四位数字64对应height。
30.如图3所示,删除图2中的前2行,再将每一正样本图片对应的数据信息中的文件格式由bmp替换成jpg 1 0 0 64 64,即获得图3中所示内容;s13:生成正样本文件夹中所有正样本图片的图片路径矢量数据信息;即利用图像处理软件将正样本文件夹里每一正样本图片对应的图片路径的数据信息生成新的正样本图片的图片路径矢量数据信息。
31.s14:创建正样本文件;如图4所示,可以利用opencv_createsamples.exe进行拷贝,命令输入写成bat文件,运行bat,在pos文件夹里生成心底vec文件。在该步骤中,创建正样本文件的命令行参数包括以下步骤:s141:将输入图像沿着三个轴随机旋转;s142:对旋转的角度进行限定,并将输入图像中亮度值位于预设范围的像素设置为透明像素,将白噪声加到前景图像上;s143:任选背景图像,将获得的前景图像放到背景图像上形成组合图像,并将组合图像调整到预设的尺寸比例;s144:最后将组合图像存储以形成正样本vec文件。
32.本实施例形成的正样本vec文件的命令行参数至少包括有:-vec 输出文件,内含有用于训练的正样本。
[0033]-img 输入图片文件名(例如,婴儿肢体动作数据中的其中一个信息序列)。
[0034]-bg 背景描述文件,文件中包含一系列的图像文件名,这些图像将被随机选作物体的背景。
[0035]-num 生成正样本的数目。
[0036]
bgcolor 背景颜色(目前为灰度图),背景颜色表示透明颜色。因为图像压缩可造成颜色偏差,颜色的容差可以由
ꢀ‑
bgthresh 指定。所有处于 bgcolor-bgthresh 和bgcolor bgthresh 之间的像素都被设置为透明像素。
[0037]-inv 如果指定该标志,前景图像的颜色将翻转。
[0038]-randinv 如果指定该标志,颜色将随机地翻转。
[0039]-maxidev 前景样本里像素的亮度梯度的最大值。
[0040]-maxxangle x轴最大旋转角度,必须以弧度为单位。
[0041]-maxyangle y轴最大旋转角度,必须以弧度为单位。
[0042]-maxzangle z轴最大旋转角度,必须以弧度为单位。
[0043]-show 很有用的调试选项。如果指定该选项,每个样本都将被显示。如果按下 esc 键,程序将继续创建样本但不再显示。
[0044]-w 输出样本的宽度(以像素为单位)。
[0045]-h 输出样本的高度(以像素为单位)。
[0046]
在本实施例中,步骤s2中选取负样本包括以下步骤:s21:基于负样本选取规则采集负样本图片并保存于负样本文件夹中;其中负样本选取规则包括:1)不包含正样本图片;2)每个负样本图片各不相同以确保负样本的多样性;3)每个负样本图片的尺寸不必相同,但任一负样本图片的尺寸不能小于正样本图片的尺寸。
[0047]
s22:获取负样本文件夹中所有负样本图片的图片路径数据信息;s23:生成负样本文件夹中所有负样本图片的图片路径矢量数据信息;s24:创建负样本文件。
[0048]
在本实施例中,步骤s3中将选取的正、负样本导入分类器内进行样本训练包括以下步骤:s31:设置最大虚警率和最小命中率的关联性;在本实施例中,不需要在每阶训练中重新更新关联性,因为提前设置的关联性是固定值,相当于一个给定的标准,这时最大虚警率和最小命中率是固定的标准,其关联性也是固定的标准,与后续样本训练中产生的虚警率和命中率不是相同的值。
[0049]
s32:根据提供的正负样本的数量设置训练阶数;s33:在每阶训练中,根据样本的命中率进行分类,计算样本的虚警率,如果虚警率高于最大虚警率,则认定训练不合格,系统就抛弃该分类器,建立下一个分类器;如果虚警率不高于最大虚警率,则认定该阶训练合格,系统进入下一阶训练;s34:当所有训练阶数均训练合格后,认定该分类器合格。
[0050]
虚警率和命中率是每阶训练产生的相应值级联,每阶训练结束后虚警率和命中率都会进行更新。其中,命中率=正样本预测为正样本/(正样本预测为正样本 正样本预测为负样本);命中率用于反映分类器正确预测正样本纯度的能力,值越大,则性能越好;因此,通过设置最
小命中率可以用来判定分类器强弱。
[0051]
虚警率=负样本预测为正样本/(负样本预测为正样本 负样本预测为负样本);虚警率用于反映分类器正确预测负样本纯度的能力,值越小,则性能越好。因此,通过设置最大虚警率可以用来判定分类器训练是否合格。
[0052]
如果正负样本较少,则阶数设置不能过大。
[0053]
正负样本比例设置为 1:3,其训练出来的分类器要优于1:1或者1:9,原因是正负样本比例接近(比如1:1)时,对负样本的命中程度低(实际中负样本肯定远远多于正样本),正负样本比例差距较大(比如1:9)时,重视负样本的统计特性而忽略了正样本的统计特性,造成正样本权重总和小,当权重小于一定程度的时候可能很大一部分正样本都不参与训练了(在weighttrimrate=0.95时)。
[0054]
作为优选,本实施例分类器还包括以下参数:minhitrate:分类器的每一级希望得到的最小检测率,即本实施例中的最小命中率。
[0055]
根据训练的级数可以得到如下公式:numpos (numstages-1)*numpos*(1-minhitrate)≤需要准备的训练正样本的数目,其中numpos正样本的数目,numstages为训练分类器的级数;maxfalsealarm:分类器的每一级希望得到的最大误检率,即本实施例中的最大虚警率。
[0056]
weighttrimrate:影响参与训练的样本(不管是正样本还是负样本),当更新完样本权重之后,将样本权重按照从小到大的顺序排列,从后面开始累加样本权重大于weighttrimrate时,前面的样本就不参与后面的训练了。其是0-1之间的阈值,一般默认为0.95,0.95是训练结果最好的取值参数,故一般选取该值时即停止。
[0057]
maxweakcount:决定每级强分类器中弱分类器的最大个数,当fa(即虚警率)降不到指定的maxfalsealarm时可以通过指定最大弱分类器个数停止单个强分类器。只有当每一层训练的fa低于命令中设置的maxfalsealarm数值,才会进入下一级训练。
[0058]
boost参数(maxdepth、bt):影响决策树构建的法则以及权重更新策略。
[0059]
其中,maxdepth:每一个弱分类器决策树的深度,默认是1,是二叉树,只使用1个特征。
[0060]
bt:训练分类器采用的adaboost类型。
[0061]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。