1.本发明涉及医学检测领域,更为具体的,本发明涉及一种鉴定人类胚胎细胞染色体变异的方法及应用。
背景技术:
2.不到一半的人类受精卵能够存活到出生,并且还有一些胎儿出生即带有遗传性疾病,这主要是由于减数分裂或有丝分裂起源的染色体缺失或者重复。目前,选择胚胎进行子宫移植的过程使用形态学标准,发育动力学和非整倍性基因检测的临时组合。然而,没有一个单一的标准可以确保选择一个有活力的胚胎。转录组可得到高发育潜能胚胎,但是在得到发育潜能的同时,也需要知道胚胎的染色体拷贝数变异(cnv, copy number variation)。虽然已有一些方法可以通过基于批量dna测定或对少数胚胎细胞的多次活检的比较得到染色体cnv,但是这些方法都基于基因组测序,无法同时获得转录组的信息。
3.目前,关于单细胞转录组技术鉴定植入前人类胚胎细胞染色体变异的现有技术有如下两种:(1)通过从滋养外胚层活检和剩余的整个胚胎中生成 rna-seq 文库。具体而言,基于每个样本的rna表达值,该方法用z 分数作为标准化方式,对一批样本的每条常染色体分别建立了rna 数字核型,并划分阈值,将z分数大于2或者小于-2的染色体作为异常值,报染色体变异。
4.(2)通过转录组数据来分胚胎核型,但需要更加深度的rna-seq测序,基于snp 基因分型,通过整合等位基因失衡的特征,检测与剂量相关的基因表达变化来推断非整倍性。
5.前述现有技术对染色体的方法去除了最嘈杂的基因(那些在所有样本中表达 《1 rpkm的基因),然后将每个整个染色体视为一个转录单位,针对每条染色体上的基因表达量总量,做一个z 分数标准化。z分数大于2或者小于-2的染色体作为异常值。从而判断胚胎的染色体核型。但该方法有两个缺点:首先,基因表达不稳定,会影响对染色体拷贝数的判断。有些基因的表达量非常高,rpkm高达万级别,而有些基因的表达量却只有个位数。因此,高表达的基因对该基因所在的染色体转录本总量影响很大。尤其是,当一些高表达的基因本身表达不稳定时,这些基因会为染色体核型的判断带来过大的内在噪音。但该方法只筛除了不表达的基因,却没有对高表达的基因做任何处理。导致一些基因数量较少的染色体,比如21号染色体,其核型的计算易被高表达基因所影响。
6.其次,系统误差的存在。对于二倍体的人类胚胎滋养层细胞,往往个体之间基因的表达异质性较强,因此,直接以基因的表达量来衡量染色体倍型会带来较大的误差。而该方法仅仅在染色体层面上进行了标准化,并未在样本层面上进行任何矫正或者标准化,因此,样本间的表达总量差异本身就会带来偏差,导致低表达量(或低样本细胞数)的样本的染色体更容易被判定为缺失;反之亦然。
7.最后,对染色体拷贝数的计算建立在一批样本同时进行标准化之后的相对值,该
方法需要一定数量的样本同时进行对比,前提假设是,大部分样本都是正常二倍体,从而找到标准化之后的异常值,这对样本的要求较高,临床上有时候较难达到。
8.因此目前对于通过转录组检测单细胞染色体拷贝数变异仍然没有一个有效的方法。
技术实现要素:
9.为了克服现有技术中存在的缺陷,我们开发了一种转录组分析方法。通过”单细胞转录组测序数据鉴定人类胚胎细胞各条染色体中基因表达量是否与正常二倍体胚胎相符”来推断非整倍性,从而用于评估胚胎发育能力的。本发明主要解决两个问题:第一是通过变异系数筛除表达不稳定的基因,且建立正常人类胚胎二倍体基因表达参考系,消除内部噪音。二是通过在样本层面将染色体表达量用二倍体基因表达参考系进行矫正,再将样本染色体表达量同步乘以一个系数,并将每个样本的染色体表达量中位数都调整至2,以此消除样本差异引起的核型判断系统偏差。
10.具体而言,我们通过建立正常二倍体基因表达矩阵,得到以基因为单位的可以用来作为表达量参照的参考系。计算待测胚胎染色体表达量的相对值即可以表明该胚胎染色体倍型。胚胎的活检可以捕获整个胚胎中可用的信息,来确保转录组测序作为植入前筛选的有效的工具。结果表明该技术可用于生成基于rna表达变化的染色体核型,并且该结果与现有的全基因组测序计算cnv的结果基本一致。
11.为了实现上述技术效果,我们具体提供如下的技术方案:本发明的第一个方面,提供一种通过转录组检测单细胞染色体拷贝数变异(cnv)的方法,所述方法包括如下步骤:(1)稳定表达的基因的筛选。
12.删除在所有二倍体样本中表达量平均值 《 1的基因后,余下基因的表达量计算变异系数(cv),变异系数的计算如下:sd是基因在各个样本中表达的标准差,mean为基因的平均表达量根据根据变异系数的分布情况,由高到低排列cv值,挑选cv值位于前25%的基因,视为表达不稳定的基因,并将这些基因筛除,剩下基因即为稳定表达的基因,可以保留,用作下一步的计算;(1)计算每一个稳定表达基因在二倍体标准样本中的平均表达量,与基因共同形成一个新的矩阵,该矩阵就是人类正常二倍体胚胎基因表达参考系:(3)相对表达量矩阵的制作
得到二倍体基因表达参考系后,可以根据转录本开始计算临床样本的cnv,首先制作相对表达量矩阵,具体来说,先在上述生成的矩阵中,挑选出与参考系重合的基因,形成新的矩阵,新的矩阵中的每个基因,均除以参考系中相对应基因的平均表达量,从而生成相对表达量矩阵,相对表达矩阵中,表达量高于4的限制为4,避免单个基因的波动过高,影响整体。假设一个基因x,在参考系中的表达量为 ,基因x在待检测的所有样本中的表达量矩阵为:基因x的相对表达矩阵则为:同理,则所有基因的相对表达量矩阵则为:(4)以染色体为单位的相对表达矩阵的生成、矫正和cnv的判断得到相对表达矩阵后,接下来以染色体为单位,计算染色体基因平均相对表达量,具体而言,利用从ucsc基因组数据库中下载的比对文件,每个相对表达矩阵中的基因都被对应到其所在的染色体上,每个染色体计算其所包含的基因的平均表达量:,其中n为二倍体参考系中属于i号染色体的基因数量,为这些基因的相对表达量,每个染色体都做一次计算,得到一个以染色体为单位的相对表达矩阵,矩阵中的每一行即为某个样本每一条染色体的相对表达量,相对表达量矩阵为:由于每个样本之间的个体差异,导致样本的表达量相对于参考系会有偏移,而大部分样本的大部分染色体都是正常的二倍体,因此,将每个样本的22条染色体的表达量乘以一个以样本为单位的系数 ,令每个样本染色体表达量的中位数都等于2,表示其为正常二倍体,用该步骤将染色体相对表达矩阵进行归一化之后,再用来做cnv的判断;即,拷贝数大于2.7的记为三体,拷贝数小于1.3的记为单体。
13.在一种实施方式中,所述cnv的判断的步骤为:
每个样品中22条常染色体的表达量为 ,其染色体表达量的中位数的数值记为;其染色体表达系数则为:得到的值后,就可以计算该样本的22条染色体分别表达量为:示例:得到的最终染色体相对表达矩阵中的值,便可以代表染色体拷贝数变异的值,即cnv(copy number variation)。
14.本发明相对于现有技术具有如下显著的进步:(1)对于基因表达不稳定的问题。筛除样本中不表达的基因(rpkm平均值 《 1的基因)后,首先计算剩下的每个基因在所有样本中的变异系数(cv,coefficient of variation),即用标准差除以平均值。那些表达越不稳定的基因,其变异系数就会越大。筛去 cv 值前25%的基因后,余下基因便是稳定表达的基因,用于生成二倍体表达量参考系。这种方法基本排除了不稳定的基因表达及其初始表达量差异带来的内在噪音,确保计算所得的cnv变异来源于染色体本身的拷贝数变异;相比以往的文章仅仅将低表达基因筛去,本发明技术关注到基因表达稳定性对cnv的影响,挑选了稳定表达的基因作为染色体拷贝数的判断依据,因此结果的准确性远远高于以往的技术;(2)针对系统误差的影响,本发明计算了基因的真实表达量,并且建立了人类二倍体胚胎基因表达参考系。用参考系校准真实表达量,消除了基因之间表达基线的差异对结果产生的影响。具体为,本方法在得到二倍体的人类胚胎滋养层细胞转录组矩阵后,计算样本的基因的表达值(rpkm),再用人类胚胎二倍体基因表达量参考系矫正,得到一个相对表达量矩阵。该相对表达矩阵消除了不同基因之间的差异性,将所有基因拉到同一个水平上进行统计。然后以染色体为单位,计算每条染色体基因平均表达量,最后将每个样本的所有染色体表达量统一上调或者下调至中位数为2,最后得到的矩阵,便为染色体倍型。
附图说明
15.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1为每个基因的变异系数的分布;图2为本次方法判断的cnv结果。
具体实施方式
16.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
17.实施例1 模型的构建人类胚胎二倍体基因表达量参考系:正常人类二倍体胚胎的稳定表达的基因的表达量平均值,用于作为标准对照。
18.1. 单细胞转录组测序活检获得囊胚外滋养层细胞。提取1个、3个或者5个细胞进行单细胞转录组测序。
19.2. 测序数据清洗、比对及比对后处理首先用trim_galore (version 0.6.6) 对数据质量进行清洗, 默认参数去除二代测序接头序列、低质量碱基, 仅保留处理后序列长度大于36 bp的序列。其次用rsem(version 1.3.3),以hg38作为参考基因组进行比对。使用rsem计算每个样本每个基因的表达水平。
20.3. 样本的筛选和基因表达矩阵的生成得到每个样本的基因表达水平后,对样本进行质量过滤。以rpkm》1的基因数大于5000的样本为质量合格的样本。
21.挑选合适的样本,得到每个样本的每个基因的表达量(rpkm)之后,制作一个列名为样本名,行名为基因名的矩阵。
22.4. 人类正常二倍体胚胎基因表达参考系的制作得到基因表达矩阵后,挑选合适的样本及其适用的基因,用于建立基因表达参考系。首先通过入选样本的全基因组pgd结果,来判断胚胎样本的滋养层细胞是否为正常二倍体(金标准)。其次,挑选这些正常二倍体样本,做转录组测序,而后进行基因的筛选和参考系的制作。
23.由于每个样本的细胞数量不一样,样本个体也有差异,导致每个样本基因表达总量不一样,为使样本间具有可比性,首先计算正常二倍体样本的表达总量的平均值 ,然后将每一个样本的每个基因的表达量都同步上调/下调,使得基因表达总值和基因表达总量的平均值齐平:,其中n为样本量;将基因表达量矫正后,再删除在所有二倍体样本中表达量平均值 《 1的基因,因为这些基因视为不表达,不会影响对染色体核型的判断;然后,余下基因的表达量计算变异系数(cv),变异系数的计算如下:sd是基因在各个样本中表达的标准差,mean为基因的平均表达量
变异系数越大,视为该基因的表达越不稳定。
24.根据根据变异系数的分布情况,由高到低排列cv值,挑选cv值位于前25%的基因,视为表达不稳定的基因并将这些基因筛除,剩下基因即为稳定表达的基因,可以保留,用作下一步的计算。
25.接下来,计算每一个基因在二倍体标准样本中的平均表达量,与基因共同形成一个新的矩阵,该矩阵就是人类正常二倍体胚胎基因表达参考系:5. 相对表达量矩阵的制作得到二倍体基因表达参考系后,可以根据转录本开始计算临床样本的cnv。首先制作相对表达量矩阵。具体来说,先在上述第3步生成的矩阵中,挑选出与参考系重合的基因,形成新的矩阵。新的矩阵中的每个基因,均除以参考系中相对应基因的平均表达量,从而生成相对表达量矩阵。
26.具体来说,假设一个基因x,在参考系中的表达量为。基因x在待检测的所有样本中的表达量矩阵为:基因x的相对表达矩阵则为:同理,则所有基因的相对表达量矩阵则为:6. 以染色体为单位的相对表达矩阵的生成、矫正和cnv的判断得到相对表达矩阵后,接下来以染色体为单位,计算染色体基因平均相对表达量。具体而言,利用从ucsc基因组数据库中下载的比对文件,每个相对表达矩阵中的基因都被对应到其所在的染色体上。每个染色体计算其所包含的基因的平均表达量:,其中n为二倍体参考系中属于i号染色体的基因数量,为这些基因的相对表
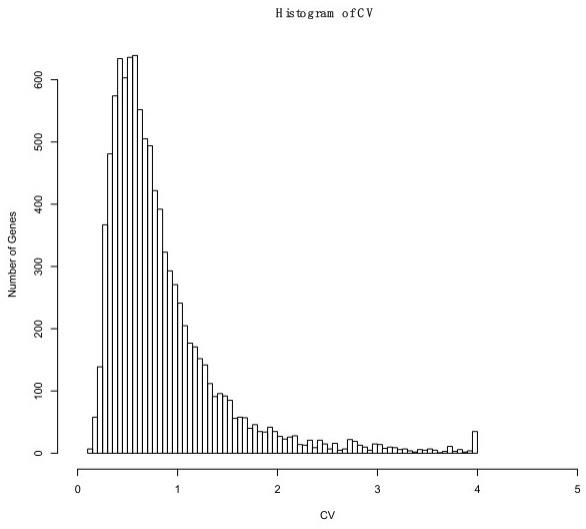
达量。每个染色体都做一次计算,得到一个以染色体为单位的相对表达矩阵,矩阵中的每一行即为某个样本每一条染色体的相对表达量,相对表达量矩阵为:由于每个样本之间的个体差异,导致样本的表达量相对于参考系会有偏移。而大部分样本的大部分染色体都是正常的二倍体。因此,将每个样本的22条染色体的表达量乘以一个以样本为单位的系数 ,令每个样本染色体表达量的中位数都等于2,表示其为正常二倍体。用该步骤将染色体相对表达矩阵进行归一化之后,再用来做cnv的判断。
27.举例来说,对于样本a,其22条常染色体的表达量为 ,其染色体表达量的中位数的数值记为;其染色体表达系数则为:得到的值后,就可以计算该样本的22条染色体分别表达量为:即:得到的最终染色体相对表达矩阵中的值,便可以代表染色体拷贝数变异的值,即我们通常所说的cnv(copy number variation)。
28.7. 阈值划分和单细胞染色体拷贝数可视化将染色体拷贝数用一定的阈值划分,进行临床判断。临床中,拷贝数为1代表染色体缺失,拷贝数为3代表染色体重复。但嵌合胚的存在(即胚胎中有些细胞是正常二倍体,有些细胞为单体或三体,目前的组学测序会将两种细胞混到一起)导致测得的cnv经常不是整数。因此基于dna检测染色体拷贝数的阈值,将0-1.3的划分为缺失(单体),1.3-1.7划分为嵌合缺失,1.7-2.3为正常二倍体,2.3-2.7为嵌合重复,2.7以上即为重复(三体)。
29.实施例 2使用囊胚活检单细胞rna测序数据构建鉴定单细胞染色体拷贝数1. 样本的筛选和基因表达矩阵的生成得到每个样本的基因表达水平后,对样本进行质量过滤。在基因水平上,将rpkm》1
定义为表达;在样本水平上,以rpkm》1的基因数大于5000的样本为质量合格的样本。
30.经过筛选后共得到39个样本用于接下来的计算。其中有16个样本是dna测序(金标准)显示染色体数量正常的二倍体样本,留这16个用于做参考系,另外23个用于验证。得到每个样本的每个基因的表达量(rpkm)之后,参考样本和验证样本分别制作一个列名为样本名,行名为基因名的矩阵。
31.2. 人类正常二倍体胚胎基因表达参考系的制作用参考样本矩阵进行基因的筛选和参考系的制作。
32.首先挑选用于制作参考系的基因,用于建立基因表达参考系。计算每个样本表达总量的平均值,然后将每一个样本的基因表达总量都同步上调/下调至平均值。
33.其次删除表达量平均值 rpkm 《 1的基因,因为这些基因视为不表达,不会影响对染色体核型的判断;然后,余下基因的表达量计算变异系数(cv)。变异系数越大,视为该基因的表达越不稳定。
34.本次16个样本中,每个基因的变异系数的分布如图1所示。
35.根据图示,纵轴为基因数量,75%的基因变异系数集中在0-1之间,因此,将cv 》 1的基因视为表达不稳定的基因筛除,剩下7390个稳定表达的基因。
36.筛去不稳定基因后,剩下的基因就是用于制作参考系、并且用于之后的计算的所有基因。如下所示:计算每一个基因在16个标准样本中的平均表达量,与基因共同形成一个新的矩阵,该矩阵就是人类正常二倍体胚胎基因表达参考系。如下图所示:3. 相对表达量矩阵的制作得到二倍体基因表达参考系后,可以用于检测23个验证样本的染色体拷贝数。
37.首先制作相对于参考系的相对表达量矩阵。具体而言,先在上述第1步生成的矩阵中,挑选出与参考系重合的7390个基因,形成新的矩阵。新的矩阵中的每个基因,均除以二倍体胚胎基因表达参考系中相对应基因的平均表达量,从而生成相对表达量矩阵。如下图:
4. 以染色体为单位的相对表达矩阵的生成、矫正和cnv的判断得到相对表达矩阵后,接下来以染色体为单位,计算染色体基因平均相对表达量。具体而言,利用从ucsc基因组数据库中下载的比对文件,每个相对表达矩阵中的基因都被对应到其所在的染色体上。每个染色体循环计算其所包含的基因的平均表达量。得到一个染色体相对表达矩阵:由于每个样本之间的个体差异,导致样本的表达量相对于参考系会有偏移。大部分样本的大部分染色体都是正常的二倍体。因此,将每个样本的22条染色体的表达量乘以一个以样本为单位的系数 ,令每个样本染色体表达量的中位数都等于2,表示其为正常二倍体。用该步骤将染色体相对表达矩阵进行归一化之后,进一步做cnv的判断。
38.23个待检测样本的系数为:得到的值后,用weight校准染色体相对表达量,得到每个样本22条染色体最终的相对表达量:该矩阵中的值,即为染色体cnv(copy number variation)计算值。
39.5. 阈值划分和单细胞染色体拷贝数可视化本次将染色体拷贝数用一定的阈值划分,进行临床判断。将0-1.3的划分为缺失
(单体),1.3-2.7为正常二倍体或者嵌合, 2.7以上即为重复(三体)。按照此阈值,本次方法判断的cnv结果如图2所示。
40.6. 结果的验证。
41.使用基于单细胞转录组测序数据及其基因表达参考系鉴定人类胚胎细胞染色体变异的结果如上图2所示。将这批样本的金标准(使用dna全基因组测序所测得的拷贝数变异结果)及用本发明上述方法(rna全转录组测序构建鉴定单细胞染色体拷贝数的方法)所得到的结果对比如下表格所示:
由上表可见,本次23个样本案例所示,基于全转录组测序构建鉴定单细胞染色体拷贝数的方法与基于全基因组测序的胚胎结果完全一致,以往方法获得诊断准确率仅为43.4%,而本发明诊断准确率高达100%。
42.显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。