1.本技术涉及食品质量控制领域,具体涉及一种基于长短期记忆神经网络的红酒质量评价方法及系统。
背景技术:
2.红酒,是以葡萄、蓝莓等水果为原料,经过发酵的而生产制作的果酒。可分为红葡萄酒、白葡萄酒及粉红葡萄酒三大类。红酒中含有多种维生素,氨基酸,多酚等物质,在防止肌肤老化方面作用显著,起到抗衰老,美容,助眠能功效。深受全世界消费者的喜爱。
3.红酒成分中含有80%以上的葡萄汁,其次是糖份自然发酵产生的酒精,一般在10%至30%,剩余的成分有酒石酸,果胶,矿物质和单宁酸等。总数超过1000种,其中对于风味影响较大的物质有300多种,虽然这些物质所占的比重较低,却是酒质优劣的决定性因素。质优味美的红酒,是因为它们能呈现一种组织结构的平衡,使人在味觉上有无穷的享受。随之而来的是红酒消费量及市场规模日益增大,消费者对于红酒的了解不足,红酒信息不对等而造成种种损失。
4.目前对于红酒的质量控制一直是世界范围内的难题,以产地年份,葡萄树树龄等级划分无法做到精准分级,同一批次或同一产地不同批次酿造的葡萄酒差异较大。
技术实现要素:
5.本技术提供了基于长短期记忆神经网络的红酒质量预测方法及系统,利用lstm模型在挖掘和利用隐藏信息并传递有效信息方面有着优秀效果的特点,对红酒质量进行精准分析和评价。
6.为达到上述目的,本技术提供了以下方案:
7.基于长短期记忆神经网络的红酒质量评价方法,包括以下步骤:
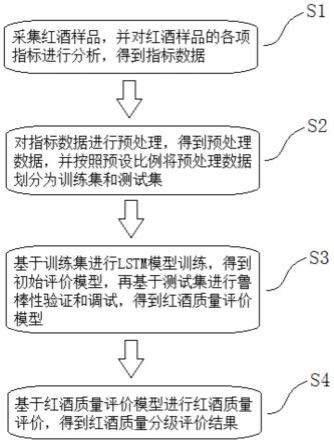
8.s1.采集红酒样品,并对所述红酒样品的各项指标进行分析,得到指标数据;
9.s2.对所述指标数据进行预处理,得到预处理数据,并按照预设比例将所述预处理数据划分为训练集和测试集;
10.s3.基于所述训练集进行lstm模型训练,得到初始评价模型,再基于所述测试集进行鲁棒性验证和调试,得到红酒质量评价模型;
11.s4.基于所述红酒质量评价模型进行红酒质量评价,得到红酒质量分级评价结果。
12.优选的,所述指标数据包括:挥发性酸、柠檬酸、ph值和酒精度。
13.优选的,所述预处理方法包括:
14.采用平均值替代法对所述指标数据中的异常值进行修正,得到修正后数据;通过小数定标归一化方法将所述修正后数据进行归一化处理,得到预处理数据。
15.优选的,所述训练集和所述测试集的所述预设比例为8:2。
16.优选的,所述初始评价模型的训练方法包括:
17.设置所述lstm模型的训练迭代次数、lstm层数、优化器、输入批次大小以及模型学
习率,初始化网络内部参数,并将所述训练集输入至所述lstm模型中进行训练,得到所述初始评价模型。
18.优选的,所述红酒质量评价模型的训练方法包括:
19.将所述测试集输入至所述初始评价模型进行处理分析,得到分析结果;
20.将所述分析结果与所述指标数据进行对比,得到对比结果,并根据所述对比结果进行调试,得到所述红酒质量评价模型。
21.优选的,所述红酒质量评价方法包括:
22.基于所述红酒质量评价模型,输入待评价红酒各项指标数据,得到红酒质量评价结果。
23.本技术还提供了基于长短期记忆神经网络的红酒质量评价系统,包括:数据采集模块、预处理模块、训练模块和评价模块;
24.所述数据采集模块与所述预处理模块连接,所述数据采集模块用于采集红酒样品,并对所述红酒样品的各项指标进行分析,得到指标数据;
25.所述预处理模块还与所述训练模块连接,所述预处理模块用于对所述指标数据进行预处理,得到预处理数据,并按照预设比例将所述预处理数据划分为训练集和测试集;
26.所述训练模块还与所述评价模块连接,所述训练模块用于基于所述训练集进行lstm模型训练,得到初始评价模型,再基于所述测试集进行鲁棒性验证和调试,得到红酒质量评价模型;
27.所述评价模块用于基于所述红酒质量评价模型进行红酒质量评价,得到红酒质量分级评价结果。
28.本技术具有以下有益效果:
29.本技术采用了lstm模型的深度学习预测方法,解决了长序列训练过程中存在的梯度消失和梯度爆炸的问题,运行更稳定,结果更准确,实现简单,并具有长时记忆功能,利用lstm模型在挖掘和利用隐藏信息并传递有效信息方面有着优秀效果的特点,能够对红酒质量进行精准分析和评价。
附图说明
30.为了更清楚地说明本技术的技术方案,下面对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
31.图1为本技术基于长短期记忆神经网络的红酒质量预测方法的流程示意图;
32.图2为本技术中lstm模型示意图;
33.图3为本技术基于长短期记忆神经网络的红酒质量预测系统的结构示意图。
具体实施方式
34.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
35.为使本技术的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本技术作进一步详细的说明。
36.实施例一
37.在本实施例一中,如图1所示,基于长短期记忆神经网络的红酒质量预测方法,包括以下步骤:
38.s1.采集红酒样品,并对红酒样品的各项指标进行分析,得到指标数据;其中,指标数据包括:挥发性酸、柠檬酸、ph值和酒精度。
39.s2.对指标数据进行预处理,得到预处理数据,并按照预设比例将预处理数据划分为训练集和测试集;预处理方法包括:采用平均值替代法对指标数据中的异常值进行修正,得到修正后数据,其中,异常值为数据收集过程中因实验误差导致数据存在缺失值的情况等,如挥发性酸、柠檬酸、ph值和酒精度指标测量误差等问题,通过平均值替代法将数据中的缺失值或测量误差使用该缺失数据紧邻的数据的平均值作为替代,或将输入数据与训练集数据进行对比,将与缺失值数据紧邻的训练集数据的平均值作为替代,进而得到修正后数据;通过小数定标归一化方法将修正后数据进行归一化处理,得到预处理数据;将预处理数据划分为训练集和测试集,其中,训练集和测试集的比例为8:2。
40.其中,归一化处理过程包括:采集挥发性酸、柠檬酸、ph值和酒精度数据后,通过移动小数点的位置来进行数据的归一化,把数据映射到0~1范围之内。
41.s3.基于训练集进行lstm模型训练,得到初始评价模型,再基于测试集进行鲁棒性验证和调试,得到红酒质量评价模型;其中,鲁棒性验证过程包括:使用测试集或其他更新的实验数据输入模型,对比模型的预测输出与真实值之间的差距,采用评价指标进行评价。如果此时模型的预测评价指标与训练阶段的评价指标差距仍较小,没有剧烈的波动,就表示训练的模型在应对新的数据时有良好的鲁棒性。
42.本技术中lstm模型如图2所示,包含三个部分:遗忘门、输入门和输出门。遗忘门是对前一时刻的历史信息进行选择性遗忘。其遗忘门读取上一时刻的输出h
t-1
和当前时刻的输入x
t
,通过sigmoid激活函数对结果进行非线性激活,得到遗忘门的输出f
t
。
43.f
t
=σ(wf(h
t-1
,x
t
) bf)
44.其中x
t
表示t时刻的输入,wf表示遗忘门权重,bf表示遗忘门的偏置项,σ表示sigmoid激活函数,其计算方法为:σ(x)=1/(1-e-x
),f
t
为遗忘门衰减系数,控制细胞状态中对于历史时刻信息的遗忘程度,其计算结果在0~1之间。当f
t
=1时,历史信息完全保留;f
t
=0时代表完全遗忘历史信息。
45.输入门用于对当前时刻的输入信息进行有选择的记忆,并将信息存储于细胞状态中。
46.a
t
=σ(wa(h
t-1
,x
t
) ba)
47.c
t
=tan h(wc(h
t-1
,x
t
) be)
[0048][0049]
其中,a
t
是使用sigmoid函数对数据信息进行选择,c
t
是使用tanh函数获得的选择输入信息。wa、wc表示输入门权重,ba、bc分别表示输入门偏置项。代表hadamard积。i
t
表示输入门衰减系数,控制细胞状态中对于当前输入时刻信息的记忆程度。
[0050]
依据遗忘门及输入门的衰减系数对细胞状态进行更新,细胞状态的更新公式为:
[0051]ct
=f
tct-1
i
t
[0052]
其中,c
t-1
表示上一时刻的细胞状态。lstm的输出门根据当前细胞状态决定当前的输出,该结构使用tanh函数对当前细胞状态进行处理,并与sigmoid函数相结合,构成当前状态的输出h
t
。
[0053]
oi=σ(wo(h
t-1
,x
t
) bo)
[0054][0055]
其中,w0表示输出门权重,bo表示偏置项,o
t
表示输出门衰减系数。
[0056]
初始评价模型的训练方法包括:
[0057]
设置lstm模型的训练迭代次数、lstm层数、优化器、输入批次大小以及模型学习率,初始化网络内部参数,并将训练集输入至lstm模型中进行训练,得到初始评价模型。
[0058]
红酒质量评价模型的训练方法包括:
[0059]
将测试集输入至初始评价模型进行处理分析,得到分析结果;将分析结果与指标数据进行对比,得到对比结果,并根据对比结果进行调试,得到红酒质量评价模型。
[0060]
s4.基于红酒质量评价模型,采用国标法测定挥发性酸、柠檬酸、ph值和酒精度的数值,将上述数值输入至系统进行运算并输出运算结果,将运算结果与训练集信息进行鲁棒性对比,如果此时模型的预测评价指标与训练数据集的评价指标对应,没有剧烈的波动,则输出评价值。
[0061]
实施例二
[0062]
在本实施例二中,如图3所示,基于长短期记忆神经网络的红酒质量预测系统,包括:数据采集模块、预处理模块、训练模块和评价模块。
[0063]
数据采集模块与预处理模块连接,数据采集模块用于采集红酒样品,并对红酒样品的各项指标进行分析,得到指标数据;指标数据包括:挥发性酸、柠檬酸、ph值和酒精度。
[0064]
预处理模块还与训练模块连接,预处理模块用于对指标数据进行预处理,得到预处理数据,并按照预设比例将预处理数据划分为训练集和测试集;预处理方法包括:采用平均值替代法对指标数据中的异常值进行修正,得到修正后数据,其中,异常值为数据收集过程中因实验误差导致数据存在缺失值的情况等,如挥发性酸、柠檬酸、ph值和酒精度指标测量误差等问题,通过平均值替代法将数据中的缺失值或测量误差使用该缺失数据紧邻的数据的平均值作为替代,或将输入数据与训练集数据进行对比,将与缺失值数据紧邻的训练集数据的平均值作为替代,进而得到修正后数据,通过小数定标归一化方法将修正后数据进行归一化处理,得到预处理数据;将预处理数据划分为训练集和测试集,其中,训练集和测试集的比例为8:2。
[0065]
其中,归一化处理过程包括:采集挥发性酸、柠檬酸、ph值和酒精度数据后,通过移动小数点的位置来进行数据的归一化,把数据映射到0~1范围之内。
[0066]
训练模块还与评价模块连接,训练模块用于基于训练集进行lstm模型训练,得到初始评价模型,再基于测试集进行鲁棒性验证和调试,得到红酒质量评价模型;设置lstm模型的训练迭代次数、lstm层数、优化器、输入批次大小以及模型学习率,初始化网络内部参数,并将训练集输入至lstm模型中进行训练,得到初始评价模型;将测试集输入至初始评价模型进行处理分析,得到分析结果;将分析结果与指标数据进行对比,得到对比结果,并根
据对比结果进行调试,得到红酒质量评价模型。
[0067]
基于红酒质量评价模型,采用国标法测定挥发性酸、柠檬酸、ph值和酒精度的数值,将上述数值输入至系统进行运算并输出运算结果,将运算结果与训练集信息进行鲁棒性对比,如果此时模型的预测评价指标与训练数据集的评价指标对应,没有剧烈的波动,则输出评价值。
[0068]
以上所述的实施例仅是对本技术优选方式进行的描述,并非对本技术的范围进行限定,在不脱离本技术设计精神的前提下,本领域普通技术人员对本技术的技术方案做出的各种变形和改进,均应落入本技术权利要求书确定的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
