1.本发明涉及稠密检索领域,特别涉及一种基于句法对比学习的稠密检索方法。
背景技术:
2.近年来提出的稠密检索方法在效果上明显超过了稀疏检索法,并逐渐成为相关段落检索的主流方法。大规模的预训练模型最近已经成为处理自然语言处理任务方法中的基石。基于复杂的transformer结构和模型内大量的参数,预训练的模型可以编码拥有丰富上下文信息的单词和句子表征,而这是因为其精心设计的掩码策略而达成的。
3.最近的研究表明,当需要考虑到语义信息时,稠密检索可以胜过传统的依赖精确词汇匹配的稀疏检索方法,如:tf-idf和bm25。然而,大多数基本的预训练模型并不适合用于句子的语义相似性搜索。研究发现,bert和其他预训练模型的语义表征空间是非光滑的各向异性空间,这不利于语义相似性任务的完成;两个相似的句子的句子向量可能有很大的距离,这会导致句子的向量空间映射任务的失败。因此,在稠密检索中有一个关键的步骤为了解决这些问题并提高稠密检索的性能,就是在表征学习过程中采用适当的对比学习方法。
4.稠密检索模型的性能和训练效果在很大程度上取决于对比性学习方法,然而,以前的方法不可避免地遇到以下问题:
5.批处理量过大的和过多的训练周期数会导致很大的硬件消耗:以前的研究集中在模型性能的提高上,所以在对比学习过程中,信息量大的硬负样本挖掘的成功已经被证明是有效的。不幸的是,得到复杂的硬负样本的代价是巨大的硬件资源消耗和冗长的计算,并且也因为在训练集中存在着未标记的正样本,在硬负样本中也存在着未标记的正样本,将正确的答案视为错误的答案无疑会损害模型;然而,像rocketqa那样挤出未标记的阳性样本,肯定可以挖掘出更复杂的硬负样本,其代价是要训练另一个交叉编码器来完成这一任务,此外,基于提高负样本质量的方法利用极其庞大的批处理量和过多的训练周期数训练来实现更好的表征映射能力,训练过程中也有大量的硬件消耗,例如必须使用多个gpu进行训练,并且需要超大的显存。
6.训练效率差:以前的研究大多是增加正确查询-段落对的相似度,减少错误查询-段落对的相似度;然而,问题和答案的匹配在人脑中是一个对象到对象的直观搜索过程,但对机器来说却是一个对象到集合的混乱的相似度计算过程。以往的大多数研究使用对比学习,通过dpr提出的损失函数来训练双编码器;在这种情况下,在批处理量大小和训练周期数有限的低数据情况下进行训练,糟糕的训练效率导致模型在遇到全新的查询时表现不佳,不确定能找得到正确的回答段落。
7.所以找到一个更好的方法来表征稠密向量,并且可以用更少的计算资源提高模型的性能和有效性,以及训练效率是当前急需解决的一个主要问题。
技术实现要素:
8.针对现有技术存在的上述问题,本发明要解决的技术问题是:如何提高稠密检索结果的准确性与训练效率。
9.为解决上述技术问题,本发明采用如下技术方案:一种基于句法对比学习的稠密检索方法,包括如下步骤:
10.s100:选用公开文档检索数据集,数据集包括查询query和正段落passage
,其中,query和正段落passage
一一对应,且将对应的一组query和passage
作为一个训练样本;
11.s200:从数据集中选取部分样本作为训练集c;
12.s300:构建稠密检索模型sync,sync包括一个双编码器模型和两个预训练模型,两个预训练模型分别为encoderq和encoder
p
;
13.所述双编码器模型包括编码器dualencoderq和编码器dualencoder
p
;
14.s310:随机从c中选取一个训练样本t,应用bm25方法对t进行处理,得到对应t的4个最相关的负段落,记为passage-;
15.对t中的query执行句法掩码策略得到掩码后的查询query
masked
;对t中的passage
执行句法掩码策略得到掩码后的正段落
16.s320:使用双编码器模型将t中的query映射到d维的表征空间,得到t的查询表征矩阵eq;使用双编码器模型将t中的passage
映射到d维的表征空间,得到t的正段落表征矩阵使用双编码器模型将t对应passage-映射到d维的表征空间,得到t的负段落表征矩阵
17.s330:使用encoderq对query
masked
执行编码和掩码策略得到掩码后的查询cq;使用encoder
p
对执行编码和掩码策略得到掩码后的正段落c
p
;
18.s400:重复s310-s330,计算得到训练集c中每个训练样本对应的eq、cq和c
p
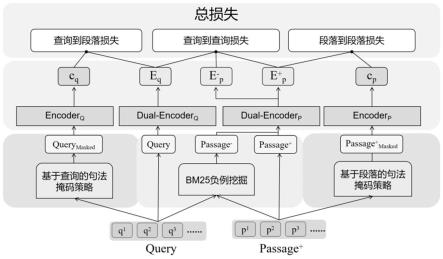
;s500:计算sync的总损失,表达式如下:
19.loss
total
=αloss
qp
βloss
γloss
pp;(1)
20.其中,loss
total
表示总损失函数,α、β、γ表示损失系数,loss
qp
表示查询-段落损失,loss
表示查询-查询损失,loss
pp
表示段落-段落损失;
21.s600:设置训练最大迭代次数并对sync进行训练,利用loss
total
损失函数通过梯度下降法反向更新sync参数,当训练达到最大迭代次数时停止训练,得到训练好的sync;
22.s700:将待预测查询q’作为训练好的sync的数据输入,输出为对查询q’的稠密检索结果。
23.作为优选,所述s320中得到t的查询表征矩阵eq、正段落表征矩阵和负段落表征矩阵e
p-的方法如下:
24.eq=dualencoderq(query);(2)
[0025][0026][0027]
应用bert和cocondenser这两种现有的预训练模型作为编码器类型,并进行两个
比较实验。原始的bert模型在稠密检索任务中具有较差的表征映射能力,而cocondenser是一个复杂的稠密检索预训练模型,具有最先进的表征映射能力。使用两个极端的模型进行测试,可以很好的检验本发明方法。
[0028]
作为优选,所述s330中得到掩码后的查询cq和掩码后的正段落c
p
的计算公式如下:
[0029]cq
=encoderq(query
masked
);(5)
[0030][0031]
编码过程将所有获得的数据映射成表征空间中的稠密向量,然后在编码后准备进行对比学习。
[0032]
作为优选,所述s500中计算sync的总损失的具体步骤如下:
[0033]
s510:计算sync的查询-段落损失loss
qp
,具体表达式如下:
[0034][0035]
其中,n表示一个训练批次中的负例总数,i表示第i个负例,sim(
·
)表示相似度计算,也就是向量的点积;
[0036]
s520:计算sync的查询-查询损失loss
,具体表达式如下:
[0037][0038]
其中,max(
·
)表示与0相比最大的作为输出,小于0的情况下loss为0,a表示超参数;
[0039]
s530:计算sync的段落-段落损失loss
pp
,具体表达式如下:
[0040][0041]
其中,b表示超参数。
[0042]
总损失函数被用来对双编码器进行微调。查询到查询损失和段落到段落损失作为辅助调整,迫使eq和摆脱句法干扰的影响,从而产生加强的句法隔离的表征,通过利用句法隔离表征对双重编码器进行微调,可以提高训练效率。
[0043]
相对于现有技术,本发明至少具有如下优点:
[0044]
1.通过基于查询的句法掩码策略,以及基于段落的句法掩码策略提高训练质量:当一个新的查询或具有不同句法的段落出现时,效率低下的模型有时会受句法的影响而将其编码为嵌入空间中的遥远的稠密表征。模型设计时首先将作为输入句子模板的句法与输入对象分开,本发明提出了基于查询和基于段落的掩码策略,在回答问题的过程中,名词始终是问题的关键询问对象,把它看作是目标,而查询中的语法是一种装饰,表达了提问者要收集什么类型的特定对象的信息。此外,由于句法和对象相似,不同查询之间的的稠密表征在嵌入空间中也有相对较小的距离,这将影响检索性能并损害表征空间,所以应用该方法去除句法的信息可以迫使对比学习过程集中在给定数据中有价值的部分,并会提高训练效
率与训练质量。
[0045]
2.采用句法对比学习法提高训练效率:通过提出的对比学习损失函数对双编码器进行微调,损失函数的总损失是由查询到查询损失、段落到段落损失和查询到段落损失按不同比例组合而成的。句法对比学习方法通过查询到查询损失和段落到段落损失对预训练的双编码器进行微调,降低问题与掩码后的问题的相似度,同时也降低给定查询批次中和其他查询的表征的相似性;降低正段落和掩码后的正段落之间的相似度,同时也降低给定查询批次中和其他正段落的表征的相似性。查询到段落损失将相关的查询-段落对的表征之间的距离被缩短,不相关的问题-回答对的表征被拉远。通过应用我们的方法有助于具有相似问答模板的查询和段落摆脱句法相似性的影响,并获得更好的表征空间映射能力,而且且训练效率更高。在效率提高的同时,我们可以在低数据的情况下训练模型而不需要过多的硬件消耗。
附图说明
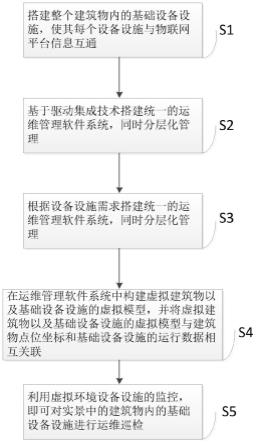
[0046]
图1为本发明sync模型的训练流程。
[0047]
图2为本发明中基于查询的句法掩码策略和基于段落的掩码策略对比。
[0048]
图3为本发明对比学习方法与传统对比学习方法之间的比较。
具体实施方式
[0049]
下面对本发明作进一步详细说明。
[0050]
本发明公开了稠密检索的句法对比学习方法,该方法是基于专门设计的掩码策略。该模型提出了一种基于查询的句法掩码策略和一种基于段落的句法掩码策略,以保留和突出待处理数据的句法信息;然后通过掩码的数据实施基于句法的对比学习方法,以获得查询和段落的句法隔离表征;这个模型减轻了查询和段落的句法对表征质量的影响,同时在不消耗巨大的训练周期和硬件资源的情况下取得了很好的效果;训练的效率和质量得到了的证明,并且有希望在没有低数据的情况下获得更好的性能,本发明改进了掩码策略并调整了模型结构获得了更好的表征。
[0051]
参见图1-图3,一种基于句法对比学习的稠密检索方法,包括如下步骤:
[0052]
s100:选用公开文档检索数据集,数据集包括查询query和正段落passage
,其中,query和正段落passage
一一对应,且将对应的一组query和passage
作为一个训练样本;
[0053]
s200:从数据集中选取部分样本作为训练集c;
[0054]
s300:构建稠密检索模型sync,sync包括一个双编码器模型和两个预训练模型,两个预训练模型分别为encoderq和encoder
p
,预训练模型为现有技术;
[0055]
所述双编码器模型包括编码器dualencoderq和编码器dualencoder
p
;
[0056]
s310:随机从c中选取一个训练样本t,应用bm25方法对t进行处理,得到对应t的4个最相关的负段落,记为passage-,bm25方法为现有技术;
[0057]
经过预处理的数据将形成查询-段落对,最后应用对比学习来增加正确的查询-段落对的相似度,并在最后一步减少错误的查询-段落对的相似度。
[0058]
对t中的query执行句法掩码策略得到掩码后的查询query
masked
;对t中的passage
执行句法掩码策略得到掩码后的正段落句法掩码策略为现有技术;
[0059]
句法掩码策略是为最终的对比学习过程进行的初步数据预处理,与基于bert的预训练模型预测随机掩码的词作为cloze任务不同,句法掩码策略不完成任何预测工作,它的最终目的是隐藏分散模型注意力的语义信息,并准备好对比学习所需的句法隔离表征。基于查询的句法掩码策略对查询中的所有名词进行掩码。如果名词没有达到总长度的25%,则随机掩码句子中的其他词语。由于查询是短的问题句子,名词很可能超过查询的25%。例如,被掩码的查询可以是:“where is[掩码][掩码]?which part of the[掩码]do[掩码]prefer?”在这种情况下,问题句的句法结构将被最大程度地保留和突出。
[0060]
对于基于段落的掩码策略,首先,查询中被掩码的标记的语义信息不能被泄露。否则,模型的注意力将被引向语义而不是语法,其训练效率也将受到损害。因此,掩码策略的一个关键步骤是掩码在相应查询中出现过的词。为了证明如何获得最具代表性的句法隔离表征,两种基于段落的策略被分为两个条件。第一个条件是,如果在查询中被掩码的词占到段落词的25%以上,则掩码段落中的所有查询词。第二种情况是,如果查询中显示的词占段落词的25%以下,则随机掩码其他词,直到25%的段落词被掩码。
[0061]
s320:使用双编码器模型将t中的query映射到d维的表征空间,得到t的查询表征矩阵eq;使用双编码器模型将t中的passage
映射到d维的表征空间,得到t的正段落表征矩阵使用双编码器模型将t对应passage-映射到d维的表征空间,得到t的负段落表征矩阵
[0062]
所述s320中得到t的查询表征矩阵eq、正段落表征矩阵和负段落表征矩阵的方法如下:
[0063]eq
=dualencoderq(query);(2)
[0064][0065][0066]
s330:使用encoderq对query
masked
执行编码和掩码策略得到掩码后的查询cq;使用encoder
p
对执行编码和掩码策略得到掩码后的正段落c
p
;
[0067]
所述s330中得到掩码后的查询cq和掩码后的正段落c
p
的计算公式如下:
[0068]cq
=encoderq(query
masked
);(5)
[0069][0070]
s400:重复s310-s330,计算得到训练集c中每个训练样本对应的eq、cq和c
p
;
[0071]
s500:计算sync的总损失,表达式如下:
[0072]
loss
total
=αloss
qp
βloss
γloss
pp;(1)
[0073]
其中,loss
total
表示总损失函数,α、β、γ表示损失系数,loss
qp
表示查询-段落损失,loss
表示查询-查询损失,loss
pp
表示段落-段落损失;
[0074]
所述s500中计算sync的总损失的具体步骤如下:
[0075]
s510:计算sync的查询-段落损失loss
qp
,具体表达式如下:
[0076][0077]
其中,n表示一个训练批次中的负例总数,i表示第i个负例,sim(
·
)表示相似度计算,也就是向量的点积;
[0078]
通过查询-段落损失对双编码器进行微调,相关的查询-段落对的表征之间的距离被缩短,不相关的问题-回答对的表征被拉远;这个损失函数是以前稠密检索中对比学习方法的核心,它将在表征空间中的微调效果显示出来,参见图3。
[0079]
s520:计算sync的查询-查询损失loss
,具体表达式如下:
[0080][0081]
其中,max(
·
)表示与0相比最大的作为输出,小于0的情况下loss为0,a表示超参数;
[0082]
loss
函数的程序是降低给定查询的表征eq和被掩码的句法模板query
masked
的表征cq的表征相似性,同时也降低给定查询和其他批次中查询的表征的相似性;它不仅减少了给定查询和其句法模板之间的距离,而且还减少了同一训练批次中不同查询样本之间的距离,从而充分利用了现有数据。
[0083]
s530:计算sync的段落-段落损失loss
pp
,具体表达式如下:
[0084][0085]
其中,b表示超参数。
[0086]
loss
pp
降低了给定passage
的表征和被掩码的句法模板的表征c
p
的表征相似度,并降低给定段落和其他批内段落的表征相似度,超参数a和b限制了损失函数,使其在查询-被掩码的一对和段落-被掩码的一对相似度过高的情况下过度分离句法信息,在这种情况下,损失函数将小于0,并自动转为0,以避免破坏表征空间。
[0087]
s600:设置训练最大迭代次数并对sync进行训练,利用loss
total
损失函数通过梯度下降法反向更新sync参数,梯度下降法为现有技术,当训练达到最大迭代次数时停止训练,得到训练好的sync;
[0088]
s700:将待预测查询q’作为训练好的sync的数据输入,输出为对查询q’的稠密检索结果。
[0089]
实验验证
[0090]
数据集
[0091]
在著名的文档检索基准数据集msmarco passage ranking上进行了实验。该数据集的详细统计数据见下表1,msmarco是一个大规模的阅读理解和问题回答数据集,在msmarco中,所有问题都是从真实的匿名用户那里挖掘出来的,并从bing搜索日志中收集,该数据集有超过880k个段落,每个查询的答案都有标签。这里,"p"和"q"分别是问题和段落
的缩写。长度以token为单位。
[0092]
表1 msmarco的详细统计数据
[0093]
数据集#q(训练)#q(开发)#q(测试)#pmsmarco502,9396,9806,8378,841,823
[0094]
评价指标
[0095]
按照主流的评价方法,使用mrr@10和recall@k作为本发明的评价指标。mrr被称为平均互换排名,这是一个评估搜索算法的通用机制,它是指在第一次检索到相关段落时,各测试问题的相互排名的平均值,召回率@k是指在前k位的召回率,它是指前k位检索到的段落包含正确答案的问题的比例。
[0096]
实施细节
[0097]
在四个nvida rtx3060 gpu(12g显存)上进行实验,并使用深度学习框架pytorch。在第一次实验中,所有编码器都由bert
base
初始化;每个设备的批处理量batchsize大小为8,因此总的批处理量大小为32,训练周期数设置为2,由于bert的表征映射能力较差,学习率设置为5e-5
,这比第二个实验要大;利用cocondenser来初始化第二个实验中的所有编码器,它是一个特别适合稠密检索任务的预训练模型;因此,为了避免大的学习率带来的性能损害,本发明将学习率设置为5e-6
,每个设备的批处理量大小为8,因此总批处理量大小为32,为了测试本发明方法是否能够改善专门设计的具有优秀表征能力的预训练模型,训练周期数被设置为1;在bm25负挖掘部分,每个查询将产生4个应用bm25的硬负例子,损失超参数a和b被设置为10,α被设置为0.75,β和γ被设置为0.25。本实验中利用faiss来索引段落的稠密表征,本发明实现了inxdexflatip来完成索引任务,查询是通过精确的最大内积搜索来进行。
[0098]
对比试验与结果
[0099]
将sync模型与之前的基准稀疏检索方法和稠密检索方法进行比较。对于稀疏检索模型,包括最经典的基于词法匹配的bm25,以及doc2qury、deepct和doctttttquery,它们都通过神经网络进行了强化;稠密检索模型的选择是ance、me-bert、rocketqa、pair和cocondenser,ance使用roberta来初始化双编码器,并使用synchronously更新的ann索引来从整个语料库中选择全局负样本;dpr实现了批量内随机抽样和bm25来获取硬负样本,然而dpr并没有在msmarco数据集上进行实验,同时进行的一项工作dpr-paq也被考虑在对比中;rocketqa引入了交叉批次负片采样策略,同时应用训练有素的交叉编码器对硬负片进行去噪;pair在进行对比学习时不仅考虑了以段落为中心的相似性,还考虑了以查询为中心的相似性;condenser和cocondenser通过调整transformer的结构和定义语料库感知的对比性损失来达到更好的表征空间,将他们的重点转移到预训练方法上。
[0100]
实验是通过两个极端的预训练模型来检验本发明方法的有效性,由于原始的bert模型在稠密检索任务中具有较差的表征映射能力,而cocondenser是一个复杂的稠密检索预训练模型,具有最先进的表征映射能力,利用bert和cocondenser预训练模型作为编码器类型进行了两次比较实验。
[0101]
由于本发明实验是在低数据量的情况下进行的,所以将上述模型的训练设置,特别是批处理量和训练周期数,与本发明提出的方法进行比较。详细设置见表2,表中没有显示condenser和cocondenser的预训练过程,它们的实际硬件消耗比较大:
[0102]
表2比较的dr模型的微调设置
[0103][0104][0105]
从表2中可以得出结论,由于所有的微调设置都是在最佳性能发生时获得的,而且模型condenser和cocondenser有额外的巨大的预训练硬件消耗没有出现在这个表中,与上述模型相比,sync的硬件消耗最小,批处理量相对较小,训练周期数量也最少。
[0106]
表3关于msmarco的实验结果
[0107][0108]
与基线模型相比,所提出的方法在msmarco数据集上的最佳性能见表3。结果按预训练模型分为三部分:稀疏检索、基于bert的稠密检索和通过更复杂的预训练模型进行的稠密检索;稠密段落检索方法明显优于所有的稀疏检索方法,甚至像doc2query、deepct和
doctttttquery这样被神经网络加强的稀疏检索;此外,应用更复杂的预训练模型来初始化编码器有明显的性能改进,其由于更多的参数、先进的训练策略或特别设计的结构获得了更好的表征映射能力。
[0109]
与基线相比,由bert
base
初始化的sync的mrr@10值达到35.0,r@1000值达到96.5。与最佳稀疏检索基线相比,mrr性能提高了7.3%(27.7/35.0);与最佳基于bert的稠密检索基线相比,mrr性能提高了1.2%(33.8/35.0);r@1000的性能比最佳稀疏检索基线高出1.8%(94.7/96.5);即使在数据量较少的情况下,sync仍能形成更好的表征空间,在基于bert的基线中表现最好,甚至优于基于更复杂的预训练模型roberta
base
的ance。
[0110]
由cocondenser初始化的sync在由更好的预训练过的语言模型初始化的稠密模型中也具有最高的性能。它的mrr@10值为35.0,r@1000值为96.5,由于cocondenser是专门为稠密检索任务设计的最先进的预训练模型,具有最好的表征映射能力,因此在低数据情况下,sync在r@1000上仍然有0.2%(98.4/98.6)的增益,而且只用了1个训练周期。
[0111]
模型性能与训练效率评价
[0112]
与基于bert的dr模型相比,sync在mrr和recall@1000上有最好的表现。dpr利用传统的对比学习方法,在不进行数据处理和结构调整的情况下,提高正确查询-段落对的相似度,降低错误查询-段落对的相似度;sync在不到1/4的批处理量和1/10的训练周期数下,在mrr上有超过7.3%(27.7/35.0)的增益;由于他们的训练方法是相同的,除了掩码策略和句法对比学习方法的改进,本实验通过极低的数据实现了显著的性能提升,因此,本发明提出的方法被证明对促进训练过程和提高训练质量是有效的,训练效率得到了验证,所提出的方法可以处理低数据设置。
[0113]
与基于bert的模型相比,使用更复杂的模型和数据处理方法的dr模型显著地提高了性能,然而,资源占用和训练消耗的代价是巨大的。rocketqa暴力地使用了4096的批处理量,有60个训练周期,这样的训练资源对大多数研究者来说是不可能达到的,然而,condensor和cocondenser模型旨在调整bert的transformer结构,以获得更好的句子表征;在8个epochs的预训练后,condensor只用64的批处理量和3个epochs进行微调;由于他们调整架构的最终目的是为了获得更好的表征,这是sync的主要贡献,而cocondenser在基线中具有最好的性能,所以sync在cocondenser模型上进行了测试,批次大小为24,历时1小时,以了解本发明方法是否对表征有贡献,sync将召回率@1000从98.4提高到98.6,证明了即使在低数据情况下,它仍然可以获得比强基线更好的表征。结合表2和表3的信息,sync具有最好的训练效率,同时在较小的批处理规模和历时中具有最小的硬件消耗。
[0114]
表4训练周期数对sync性能的影响
[0115][0116]
表4显示了训练周期对sync性能的影响。批处理量大小=32,α=0.75,β=0.25,学习率=5e-5
(基于bert的sync),学习率=5e-6
(基于cocondenser的sync)。sync是在低数据情况下测试的,所以3个训练周期是本发明进行的最大的训练设置,由于原始bert模型具有非光滑语义表征的各向异性空间,不利于语义相似性任务,所以性能比稀疏检索差。然而,经过sync的一次训练周期的训练,mrr结果为31.4,达到dpr的最佳性能。训练效果和效率大大超过了dpr。训练2个训练周期后,性能达到最佳,训练3个训练周期后性能略有下降。因此sync有一个很好的训练效率,它的最佳性能是在2个历时中。
[0117]
尽管在cocondenser上训练一个周期对r@1000只有很小的改善,但它仍然表明本发明提出的方法可以在现有的最先进的稠密检索预训练模型上形成更好的表征空间。实验时没有破坏这个预训练的模型,而是进一步提高模型的表征空间映射能力。
[0118]
表5超参数对sync性能的影响
[0119][0120]
表5显示了以前用于比较受超参数影响的性能的实验。在低数据情况下,本发明实验考虑在不同设置下获得的不同结果来评估超参数:从1和2实验中得到,在总损失函数中不把α和β设置为1,而是把三个损失按一定比例排列(α=0.75,β=0.25,γ=0.25)会有更好的结果;另外,应用低的学习率会降低训练效率,适当的学习率的最佳表现是5e-5
。而在这个高效的训练过程中,性能在第2个训练周期达到峰值。
[0121]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。