1.本发明涉及企业用地领域的指标评价体系,涉及一种面向开发区企业的用地评价模型
背景技术:
2.在社会经济转型阶段,发展中不平衡、不协调、不持续的问题突出,随着我国工业化与城市化的快速发展,社会经济发展对土地资源的需求不断增加,与此同时,工业用地闲置、低效利用、环境污染严重等现象普遍存在,人地矛盾日益凸显。开发区作为城镇发展和土地利用的重点区域,是促进区域产业发展的有效方式,在带动区域产业发展和城市化方面发挥着极其重要的作用。
3.目前,国内整体上侧重于对城市土地利用的研究,针对企业用地的研究较少,且主要集中于企业用地的集约利用,研究内容主要为从省域、经济区、地级市等相对宏观的尺度对企业用地利用效率及其时空差异进行分析和评价;中观尺度的探讨基于部分具体城市的实证研究,主要是对城市企业用地的集约利用水平进行测度;而基于开发区、宗地等微观尺度的研究较少,主要从企业视角探讨工业用地的集约利用水平,对土地集约利用进行定量评价。现有企业用地评价通常为构建评价指标体系,研究视角逐渐由单项效益评价转为综合效益评价。
4.企业是市场的微观主体,企业用地评价是定性与定量结合的研究,评价指标要选择具有显著的主观性特征。在指标权重确定阶段,当前学界主要采用两种方法:第一是专家咨询法,第二是统计分析法。专家咨询法指有关专家基于工作、研究经验的基础为评价指标赋值的方法。专家咨询法具有快捷、简便的操作优点,但是主观性强、适用范围有限的缺点也是显而易见,专家咨询法只适用于专家熟悉的领域,因此评价结果不具有普遍性统计分析法通过对样本数据的分布统计、分类拟合等方法确定评价指标权重。基于数据分析的统计分析方法具有较强的科学性和适用性,说服力较高,但是该方法需要依据大量的数据统计,对数据收集的要求较高。
5.利用统计分析法确定指标权重,熵权法的应用有很多,如结合四种股票指数的周度和月度数据,对资本的动荡程度进行比较,再如对银行绩效开展综合评价时使用熵权法等。具体办法是通过对所有指标的矩阵进行运算获得各指标的信息熵,对各个指标赋权。当某个指标的信息熵越小时,表明其指标值的变异程度越大,提供的信息量越大,在综合评价中所起的作用也相应越大,体现为权重较高。反之,当某个指标的信息熵越大时,就表明其指标值的变异程度越小,提供的信息量越小,在综合评价中所起的作用也相应越小,体现为权重较低。因此,在具体分析中,可以根据各指标值的变异程度,利用熵来计算出指标权重,再对所有指标进行加权,从而得出较为客观、科学的综合评价结果。设企业综合评价得分为s,四类指标和各自权重分别为ci、wi,i=1,2,...,4,各用熵权法确定权重wi后,即可计算某企业综合评分,具体计算公式为:s=w1c1 w2c2 w3c3 w4c4,并根据s值大小对企业效益等情况进行排序。
6.k-means聚类算法,作为一种经典的聚类算法,目前已有许多应用。k-means算法的核心思想是将数据分为多个类,使得每个聚类中的数据与类簇中心之间的距离之和最小。k-means算法是一种基于点的快速迭代聚类算法,最初将类簇中心放置在任意位置开始,然后在每一步迭代过程中,通过移动类簇中心以最大程度地减少聚类错误。该方法的主要缺点在于其对类簇中心初始位置的敏感性。因此,为了k-means算法能够获得接近最佳的解决方案,可能需要运行多次,而每次运行的类簇中心的初始位置将有所不同。
7.利用聚类算法,对综合评价得分进行聚类,划分不同等级,供开发区决策者,开发区企业用地利用评价工作的开展对提高开发区用地管理水平、建立健全开发区土地节约集约利用考核制度与长效机制、增强土地参与宏观调控的能力、构建资源节约型社会具有重要意义。
8.对开发区土地利用进行评价的指标体系和方法已经有多位国内学者做了研究,而对开发区中的企业土地利用情况进行专门的评价还比较少,因此本发明结合以上研究方法的分析,为开发区内的企业建立独立的用地评价系统,能够清楚的反映开发区内各企业的用地情况,全面、系统的保存企业每年的信息,方便管理者进行迅速的查询与综合,并及时为决策提供信息支持。
技术实现要素:
9.本发明是对企业用地数据进行分析,构建企业用地指标评价体系。
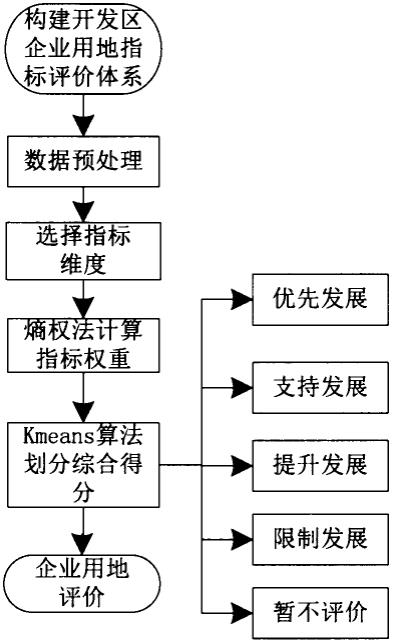
10.通过查阅文献,参考相关指标评价办法,结合实际情况,初步确定开发区企业用地指标评价体系。考虑到企业的原始数据,需要进行数据预处理工作,主要是缺失值,异常值(离群点),去重处理以及噪音数据的处理;针对不同性质的数据,运用“最大值-最小值法”将数据标准化。经初步处理过的数据输出到excel表格。根据数据预处理的结果,选择参与计算的不同维度,最终选用企业销售,企业税收,企业能耗,企业占地以及职工人数五个维度指标,确定指标权重值时采用熵权法。利用得到的权重值与实际数据计算企业综合评价得分,将企业的综合得分利用kmeans算法划分成五大类,最终对分类的结果进行评价。
11.一种面向开发区企业的用地评价模型,包含以下步骤:
12.步骤1:确定企业用地指标评价体系。
13.步骤2:数据预处理,选择用于评价的指标维度。
14.步骤3:采用熵权法确定指标权重,计算各单项指标的权重。
15.步骤4:计算企业综合评价得分。首先计算出每一块工业企业用地的最终得分,然后利用kmeans算法将企业用地的综合得分分类到优先发展类、支持发展类、提升发展类、限制发展类以及暂不评价类五大水平。
16.步骤5:分析企业用地评价结果。从资源利用、综合效益等方面分析企业,对综合评价分类企业在城镇土地使用税征收、供地、用电、用水、排污权和价格核定、信贷,以及其他相关服务管理等实施差别化政策。
附图说明
17.图1企业用地评价分析流程图
18.图2开发区企业用地指标评价体系
19.图3指标及指标权重值
20.图4企业综合得分聚类结果散点图
21.图5企业用地综合评价得分聚类结果统计表
具体实施方式
22.步骤1:确定开发区企业用地指标评价体系。
23.本发明结合初步数据预处理的结果,确定一级指标分别为企业能耗、企业税收、企业销售、能耗降低率、企业占地、职工人数、年增长率、污染物排放以及综合素质。二级指标中,企业能耗分为2项,为用电量、用水量、用煤量;企业税收细分为2项,为国税、地税,企业占地分为用地面积和持证面积,年增长率包含税收增长率、销售增长率以及职工增长率,综合素质的评价看企业的研发机构、品牌以及安全生产等级。
24.步骤2:对企业用地的原始数据进行预处理操作,选择参与计算的维度。
25.在本实例中,采用的数据为某经济开发区2019年的企业数据,共2162条有效数据。首先对缺失值、冗余数据、重复数据进行清洗。数据缺失情况可采用就近原则或中位数、平均数进行填充,若缺失值占比较小且不影响整体,可直接删除缺失字段;对于冗余数据,基于业务逻辑对冗余字段进行合并或删减。对于重复数据,只保留第一条数据。数据标准化用到的是min-max标准化也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间。
[0026]
由于清洗得到的数据中用电量、用水量的数据为0,综合素质、污染物排放的数据为空,所以在选择维度上,淘汰掉上述数据。涉及到年增长率,能耗降低率没有历史数据,所以不参与运算。选择企业销售,企业税收,企业能耗,企业占地以及职工人数五个指标参与计算。具体的计算公式如下:
[0027]
亩均税收=企业税收/企业占地
ꢀꢀꢀꢀ
式(1)
[0028]
亩均销售收入=企业销售/企业占地
ꢀꢀꢀ
式(2)
[0029]
单位能耗税收=企业税收/企业能耗
ꢀꢀꢀꢀ
式(3)
[0030]
单位能耗销售收入=企业销售/企业能耗
ꢀꢀꢀꢀ
式(4)
[0031]
平均职工人数=职工人数/企业占地
ꢀꢀꢀꢀ
式(5)
[0032]
步骤3:一级指标权重参考相关指标评价办法,二级指标采用熵权法确定指标权重。计算各单项指标以及综合指标权重。
[0033]
本发明采用熵权法计算权重值,具体计算过程如下:
[0034]
(1)数据标准化
[0035]
对每个指标的数据进行标准化处理。假设给定了k个指标行x1,x2,x3,...xk,其中xi={x1,x2,x3,...xk},假设对各指标数据标准化后的值为y1,y2,y3,...yk,那么:
[0036][0037]
(2)求个指标的熵值
[0038]
根据信息论中信息熵的定义,一组数据的信息熵计算为:
[0039][0040]
其中,
[0041][0042]
(3)确定个指标权重
[0043]
根据信息熵的计算公式,各指标权重为:
[0044][0045]
步骤4:计算企业综合评价得分。首先计算出每一块工业企业用地的最终得分,然后利用kmeans算法将企业用地的综合得分按照区间分类到优先发展类、支持发展类、提升发展类、限制发展类以及暂不评价类五大水平。
[0046]
企业综合评价得分为:
[0047][0048]
a类为优先发展类,指资源占用产出高、经营效益好、税收贡献大的企业。
[0049]
b类为支持发展类,指资源占用产出较高、经营效益较好,但转型升级发展水平有待进一步提升的企业。
[0050]
c类为提升发展类,指资源利用效率偏低、综合效益不佳,需要进行重点帮扶、倒逼提升的企业。
[0051]
d类为限制发展类,指发展水平落后、综合效益差、需要重点整治的企业。
[0052]
e类为暂不评价类,主要为新投产企业和初创期高新技术企业,以及电厂、燃气、给排水、垃圾焚烧、污水处理等其他特殊类型企业。
[0053]
将获取到的综合得分排序,选用前46%的综合得分数据作为训练集用于kmeans算法聚类,第一步确定要划分的聚类个数(k),从数据集d中任意选出k个点作为聚类中心,第二步计算所有点到各个聚类中心的距离,把各个点归类到距离最近的那个聚类集中,第三步计算第二步所产生的k个聚类集的中心,将该中心作为数据集d新的k个聚类中心,第四步重复第二步、第三步直到中心点不再变化或迭代次数达到设定的最大迭代值或中心点的变化收敛于某个预定值。由于综合得分是一维数据,距离算法采用的是曼哈顿距离,即样本值,直接相减得到的值取绝对值。
[0054]
由于部分企业的综合得分较高,聚类时形成独立点,聚类效果不明显,因此聚类时将其去掉。得分较高的企业直接成为重点扶植对象。
[0055]
步骤5:分析企业用地评价结果。从资源利用、综合效益以及税收贡献等方面分析企业,对综合评价分类企业在城镇土地使用税征收、供地、用电、用水、排污权和价格核定、信贷,以及其他相关服务管理等实施差别化政策。
[0056]
对a类企业:加大扶持力度,在政策扶持、要素资源需求方面给予优先支持。在用地、用电、新增用能指标、信贷支持、政府扶持项目申报、城镇土地使用税减免等方面给予优先。
[0057]
对b类企业:加大服务力度,在政策扶持、要素资源需求上给予适当支持。在用地、用电、新增用能指标、信贷支持、政府扶持项目申报等方面给予支持。
[0058]
对c类企业:加大帮扶力度,不推荐申报省级以上扶持项目,限制新增用地,要求有
序用电时可作为限电对象,要求区域污染物限排时可作为限排对象。要求开展提档升级、节能减排、清洁生产等技术改造。
[0059]
对d类企业:加大重点调控和监管力度,依法依规提高资源要素使用成本。限制与c类及d类企业之间土地使用权转让;限制用能需求,提高用水用电价格;区域污染物限排时作为限排对象;加强能耗排污、税收稽查、“打非治违”、产品质量等专项执法力度。
[0060]
对e类企业:e类企业中的新投产企业或初期发展企业,要每年进行评估,对其投入和产出情况进行跟踪反馈。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
