1.本发明属于网络拓扑估计领域,具体涉及一种基于多类型特征融合的拓扑估计方法。
背景技术:
2.随着现代计算机与通信网络技术的快速发展,互联网系统中包含越来越多的节点,网络规模变得更加庞大,拓扑结构也更复杂,加大了网络监管的难度,资源的有效利用和安全防御都面临极大的挑战。加强网络监管的有效途径是获取网络的拓扑结构,因为网络拓扑结构准确地反映了网络内部节点之间的连接关系,准确的网络拓扑有利于快速定位网络故障、排查网络的拥塞情况、测量网络内部参数、优化网络结构设计以及增强网络防御能力。因此,获取准确的网络拓扑信息是网络探测领域的重要目标。
3.传统的网络拓扑估计方法是基于内部节点互相协作的测量方法,以网络内部节点反馈的信息(常见的有路由信息、icmp数据包)为基础来构建网络拓扑。但是,传统的基于内部节点协作的方法存在很多问题:首先,网络中的一些节点出于安全防御角度会拒绝协作而不反馈任何信息。其次,网络中的防火墙会对数据信息进行过滤,比如:路由器防火墙对icmp数据包的过滤,中间的部分节点不会反馈数据包信息,信息获取不全面从而导致网络拓扑估计失败。此外,网络内部节点之间的探测数据包会占用网络带宽,加重网络负载,严重的情况会造成网络拥塞而导致测量失败。
4.为了解决传统网络拓扑估计方法的弊端,研究人员将层析成像技术引入到网络测量当中,在不需要网络内部节点协作的情况下通过端到端的探测获取网络的性能参数,如链路时延、链路丢包率、带宽利用率等,再利用统计学方法计算出网络的内部参数,最后结合拓扑估计算法恢复出网络的拓扑结构。网络层析成像技术具有测量范围广、效率高、不依赖内部节点的紧密协作等优点,成为了网络拓扑测量领域的研究热点。
5.网络层析成像技术,由ct(computerized tomography)技术衍生而来。网络层析成像技术具体可以分为多播层析成像技术和单播层析成像技术。
6.多播网络层析成像方法在树状拓扑的根节点(探测主机)向所有的叶子节点(目的主机)发送多播探测包,多播数据包每一条网络链路上只会被传递一次,只有当数据包到达网络链路分叉点的时候,消息才会被复制一次,由此来获取根节点到目的节点的丢包率、链路时延等丰富的探测数据,用于后续统计分析。初期的多播探测方法利用链路时延、丢包率等网络性能参数作为网络拓扑估计的依据。以minc(multicast-based inference of network characteristics)项目为基础,学者们又相继提出了更多的多播网络层析成像的模型与方法。
7.基于单播探测的网络层析成像方法最早由castro等人提出。该方法主要通过发送背靠背探测包来获取链路性能参数,只要保证背靠背探测包之间有较高的相关性,此方法估计出的网络拓扑的准确性就相对较高。在此基础之上,castro等人又提出利用“三明治”包作为单播探测包进行端到端测量,利用最大似然法对共享路径上时延差的增量进行估
计,最后通过alt(agglomerative likelihood tree)算法推断出网络的拓扑结构。alt算法只能用于二叉树网络拓扑的估计,为了估计更一般的树状拓扑,提出了mcmc(markov chain monte carlo)算法,该算法通过加入或者删除某一节点得到一系列的候选树,然后利用最大似然方法从候选树中搜索出所要估计的一般树状拓扑。针对随着目标探测网络规模增大带来的网络负载增大和资源消耗过大等问题,santos等提出了一种基于分治思想的层析成像法来探测大型的目标网络。每一轮探测只收集一部分节点的信息来推断出小型的网络拓扑结构,然后使用pac(patch and catch)算法合并小型网络最终得到完整的大型目标网络的拓扑结构。
8.现有成熟的网络拓扑估计方法通过发送探测数据包的方式进行端到端测量,然后获取网络性能参数(链路时延、链路丢包率、网络拥塞状况等)进行拓扑恢复,而且大多只利用了一个维度的信息来完成网络拓扑估计,会导致存在以下问题:首先主动发探测包的测量方式获取网络性能参数时要求网络状况良好,不能存在严重的网络拥塞状况,对探测环境的要求比较严格。其次随着探测网络规模的增大,主动探测方式会对原本网络的状态产生严重影响,增加网络负载和资源消耗,而且还需要在网络中的不同的位置部署很多探测节点,导致探测的难度大大增加。另外单一的端到端的网络参数并不能充分反映出网络内部特征信息,网络流量特征信息提取不充分影响了拓扑恢复的准确率,单一维度的信息无法满足复杂网络拓扑估计的要求,需要融合更丰富的网络特征信息。
技术实现要素:
9.为解决上述技术问题,本发明提出了一种基于多类型特征融合的拓扑估计方法,通过被动探测方式(不需要探测主机主动发送探测数据包),在网络的网关路由处部署流量采集服务,提取网络流量中的多维特征信息用于拓扑估计,融合网络中多类型的特征信息来恢复路由器节点与目标主机节点之间的网络拓扑,提高拓扑估计准确率,不会给现有网络增加额外的流量负载。
10.本发明的技术方案为:一种基于多类型特征融合的拓扑估计方法,具体步骤如下:
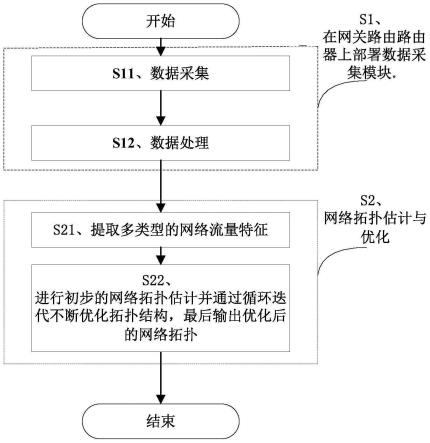
11.s1、在网关路由路由器上部署数据采集模块,具体子步骤如下,
12.s11、数据采集,
13.基于主动探测的网络拓扑估计会给现有网络带来严重的网络负载,对发包大小和间隔都有一定要求,本发明的方法采用被动探测的方式,通过在网关路由器上部署数据采集模块,抓取上行及下行的流量数据。
14.s12、数据处理,
15.对发包序列进行统一维度处理,得到数据包从源节点到不同目的节点的往返时延时序图以及平均往返时延,同时获取数据包到达不同目的节点的跳数,数据包返回到探测源节点的时间间隔序列、数据包大小序列以及流速率序列等多类型特征信息。
16.s2、网络拓扑估计与优化,
17.将网络拓扑抽象为树状逻辑拓扑以便于描述网络结构,现做如下符号规定:t=(v,e),其中,v表示该树状逻辑拓扑的所有节点集合,e表示所有链路集合,定义s为源节点(本发明中指网关路由节点),d={1,2,3...,m}为所有叶子节点(目的节点)集合,m为目的节点个数,对于树t,除源节点s之外的任一节点c均有一个父节点,用f(c)表示,对于任意目
的节点对{i,j},用f(i,j)表示离这两个节点最近的公共父节点。
18.网络拓扑估计算法具体内容如下:
19.s21、提取多类型的网络流量特征,
20.本发明的方法基于网络流量中的多类型特征提出了多维距离向量的概念,来表示不同目标节点之间的相似性。节点之间的距离向量越接近(相似性距离越小),相似性就越高,拓扑估计的时候也就越可能被融合到同一路由节点之下。以目的节点对{i,j}为例,主要包括以下几个特征:
21.(1)往返时延序列的小波变换特征
22.(2)往返时延均值特征
23.(3)跳数特征
24.(4)ip地址特征
25.(5)数据包到达时间间隔特征
26.(6)流速率特征
27.(7)数据包大小序列特征
28.对于目的节点对{i,j},联合由7种类型特征计算出的相似性距离组成距离向量dis(i,j),dis(i,j)=[d1(i,j),d2(i,j),....,d7(i,j)]
′
,'表示矩阵的转置,然后对距离向量dis(i,j)进行z-score标准化,以降低数据不均衡带来的影响。
[0029]
同时定义系数向量β,β=[λ1,λ2,....,λ7],向量中的数值表示不同维度的距离特征所代表的权重,7个维度的权重值之和为1,系数向量与距离向量的乘积代表目的节点对{i,j}之间的最终距离ρ(i,j),ρ(i,j)=β
×
dis(i,j)。
[0030]
s22、进行初步的网络拓扑估计并通过循环迭代不断优化拓扑结构,最后输出优化后的网络拓扑,
[0031]
在所述多类型特征提取的基础之上,提出基于分层聚类思想的树状网络拓扑估计算法,该算法主要包含两部分内容:基于分层聚类算法融合节点对,迭代优化权重向量。具体步骤如下:
[0032]
s221、初始化:以步骤s21为基础,根据给定的系数向量β(初始时每个维度的权重均相等),计算出目的节点对之间的距离ρ(i,j)=β
×
dis(i,j)(i,j∈d),
[0033]
s222、分层聚类的融合过程,具体步骤如下:
[0034]
1.输入数据:源节点s,目的节点集d,节点对两两之间的距离集合ρ(d2),系数向量β,最小距离阈值δ>0。
[0035]
2.初始化数据:节点集v={s},链路集合e=φ。
[0036]
3.在目的节点集d中查找彼此之间欧式距离ρ(i,j)最小的目的节点对{i,j},并构建新节点f作为它们的父节点。
[0037]
4.更新数据集:d=d\{i,j},v=v∪{i,j},e=e∪{(f,i),(f,j)}。
[0038]
5.查找节点集d中是否存在步骤3中选择的节点对的兄弟节点,即判断是否存在c∈d,满足:|ρ(i,c)-ρ(i,j)|≤δ或者|ρ(j,c)-ρ(i,j)|≤δ,如果存在,更新输出数据:d=d\c,v=v∪c,e=e∪(f,c),如果不存在,跳过该步骤,继续下一步。
[0039]
6.更新节点f与d中其他节点的距离数据:chil(f)表示步骤4与步骤5中融合的所有子节点的集合,m表示节点f的所有子节点的个数,遍历d中所有节点,对于任意c∈d,计
算:最后更新d=d∪f。
[0040]
7.判断融合过程是否结束。如果|d|=1,即仅剩一个目的节点c,更新v:v=v∪c,e=e∪(s,c);否则,重复第3-6步。
[0041]
8.估计树输出:估计出的树状拓扑
[0042]
算法中的最小距离阈值δ是判断已融合的目的节点对是否还有兄弟节点的依据,其中α为经验取值(α>1),需根据不同的探测目标取不同的值。
[0043]
s223、迭代优化过程:
[0044]
对于估计出的树状拓扑,结合系数向量β构造一个二次规划问题:即让估计树中同一路由节点下的目标节点对之间的距离达到最小,用公式表述为:
[0045][0046][0047]
其中,u表示估计出的树中,有公共父节点的目的节点对的集合,为u中的节点对,是求解二次规划问题所得出的新的权重系数向量,用于下一轮的拓扑估计。迭代到一定次数或者系数向量的变化值小于某一个阈值即可停止迭代,输出最终的估计树。
[0048]
本发明的有益效果:本发明的方法首先在网关路由器上部署数据采集模块,进行数据采集,通过数据处理,提取多种类型的网络流量特征,接着进行初步的网络拓扑估计并通过循环迭代不断优化拓扑结构,最终估计出目标网络的树状拓扑结构。本发明的方法采用被动探测的方式进行拓扑估计,不会给现有网络增加任何额外的流量和负载,大大降低资源消耗和探测难度,简化探测的部署工作,同时设计了新的抓包模块,只抓取数据包头部的重要信息,降低数据的存储量及cpu的负载,保护网络用户隐私信息,本发明的方法相比利用单一的度量框架,能达到更高的拓扑恢复准确率,在实际网络条件下,能够得到较为准确的拓扑结构,加强网络的监管。
附图说明
[0049]
图1为本发明的目标网络抽象图。
[0050]
图2为本发明的一种基于多类型特征融合的拓扑估计方法的流程图。
[0051]
图3为本发明实施例中系数特征向量提取流程图。
[0052]
图4为本发明实施例中基于分层聚类思想的树状网络拓扑估计算法整体流程图。
具体实施方式
[0053]
下面结合附图进一步说明本发明的技术方案:
[0054]
本发明中的探测目标如图1所示,目的在于恢复网关路由器与目标主机之间的网络拓扑结构(图中的虚线框部分)。
[0055]
如图2所示,本发明的一种基于多类型特征融合的拓扑估计方法流程图,具体步骤
如下:
[0056]
s1、在网关路由路由器上部署数据采集模块,具体子步骤如下,
[0057]
s11、数据采集,
[0058]
基于主动探测的网络拓扑估计会给现有网络带来严重的网络负载,对发包大小和间隔都有一定要求,本发明的方法采用被动探测的方式,通过在网关路由器上部署数据采集模块,抓取上行及下行的流量数据。
[0059]
目前常见的抓包工具有tcpdump、wireshark,由于需要采集的数据量比较大,为了便于存储和处理,本发明的方法基于libcap设计了新的抓包模块,只抓取数据包的头部信息作为多类型特征的基础信息,大大降低了采集的数据量,同时又记录了每个数据包的重要特征信息。此外,数据包的数据负载部分通常涉及网络用户的隐私,本发明的方法只采集数据包头部的信息,对用户数据的隐私信息起到了一定的保护作用。
[0060]
本发明中讨论的网络流是根据源ip地址、目的ip地址、源端口号、目的端口号以及传输层网络协议的五元组信息进行确定,数据包的顺序则由数据包被捕获的时间确定。对抓取的数据包头部信息进行过滤,得到抓包时间、数据包大小、ip地址、端口号、序列号、应答号、ttl等重要信息。
[0061]
s12、数据处理,
[0062]
对发包序列进行统一维度处理,得到数据包源节点到不同目的节点的往返时延时序图以及平均往返时延,同时获取数据包到达不同目的节点的跳数,数据包返回到探测源节点的时间间隔序列、数据包大小序列以及流速率序列等多类型特征信息。
[0063]
对于网络中的不同目的主机来说,其彼此距离越接近,从源节点到这些目的主机经过的公共路由器越多,数据包在路由器上的排队行为以及传输行为也就越接近,所以数据包往返时延、数据包的大小可以作为区分目标主机之间距离的重要特征。如果数据包来自同一个子网的目的主机,则数据包从源节点到目的主机经过的路由器跳数比较接近,所以跳数信息可以作为区分目标主机之间距离的重要特征。统计从目标节点发往网关路由器的网络流的行为特征信息,主要包括数据包的到达时间间隔序列,到达数据包的大小,以及网络流速率序列(每秒内该网络流传输的字节数的序列)。另外为了排除不同应用服务的网络流之间的差异性,本发明中仅仅分析web应用的网络流,即目的节点的web应用服务(端口是80、443)与网关路由器之间的网络流。
[0064]
s2、网络拓扑估计与优化,
[0065]
将网络拓扑抽象为树状逻辑拓扑以便于描述网络结构,现做如下符号规定:t=(v,e),其中,v表示该树状逻辑拓扑的所有节点集合,e表示所有链路集合,定义s为源节点(本发明中指网关路由节点),d={1,2,3...,m}为所有叶子节点(目的节点)集合,m为目的节点个数,对于树t,除源节点s之外的任一节点c均有一个父节点,用f(c)表示,对于任意目的节点对{i,j},用f(i,j)表示离这两个节点最近的公共父节点。
[0066]
网络拓扑估计算法具体内容如下:
[0067]
s21、提取多类型的网络流量特征,
[0068]
本发明的方法基于网络流量中的多类型特征提出了多维距离向量的概念,来表示不同目标节点之间的相似性。节点之间的距离向量越接近(相似性距离越小),相似性就越高,拓扑估计的时候也就越可能被融合到同一路由节点之下。以目的节点对{i,j}为例,主
要包括以下几个特征:
[0069]
(1)往返时延序列的小波变换特征
[0070]
由往返时延序列小波变换系数组成的特征向量计算相似性距离d1(i,j),现实网络中的网络流量往往具有很高的时变性和突发性,因此往返时延曲线中会有较多的中高频分量出现。小波包分解技术可以对复杂信号的高频分量逐步分解,提取出高频分量的特征,因此本发明的方法采用小波包分解的方式提取实际网络中端到端往返时延序列信号的高频分量特征,提取流程如图3所示。
[0071]
本发明采用dbn小波作为小波包分解的小波基,其中n=5。dbn小波在时域上具有有限性特点,适合对复杂信号进行逐步地分解。本发明的方法采用db5小波进行小波包分解,为了得到相对详细的信号频段,分解层次定为6层,对于目的节点i和j,对其往返时延序列做小波包变换最终得到小波系数组成的特征向量pi和pj。
[0072]
由于小波包分解的系数值可以反映非平稳网络中不同目的节点端到端时延的非平稳特征,特征向量之间的距离越小代表不同目的节点之间时延非平稳特征越相似,在拓扑结构中也就越可能位于同一个路由节点之下。对于目的节点对{i,j},采用特征向量pi,pj之间的欧式距离作为d1(i,j),即:
[0073][0074]
其中,p
iw
表示特征向量pi中的第w个维度上的数值,p
jw
表示特征向量pj中的第w个维度上的数值,l表示小波变换后提取的特征向量的总维度。
[0075]
(2)往返时延均值特征
[0076]
由往返时延的均值计算相似性距离d2(i,j),目的节点对{i,j}之间的距离越接近,数据包到达目的主机的平均往返时延就越接近,由此计算出的距离d2(i,j)也就越小。对于目的节点i和j,对往返时延序列中的时延值取平均值得到ti和tj,则:
[0077]
d2(i,j)=|t
i-tj|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0078]
(3)跳数特征
[0079]
由数据包的ttl字段计算出到达目的节点对{i,j}的跳数,并由此计算出跳数之间的相似性距离d3(i,j)。如果数据包来自同一个子网中的目的主机,则它们的ttl字段值比较接近,也即数据包到达目的主机所经过的跳数比较接近,所以跳数可以作为区分目标主机之间距离的重要特征。对于目的节点i和j由抓取的数据包头部的ttl字段可以计算得出网关路由源节点到目的节点i和j的跳数hi和hj,则:
[0080]
d3(i,j)=|h
i-hj|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0081]
(4)ip地址特征
[0082]
由ip地址特征计算ip地址之间的相似性距离d4(i,j),同一个子网内的目的主机之间的ip地址比较相似,所以彼此之间的相似性距离也就越小。对于目的节点对{i,j},将其ip地址转化为二进制字符串bi,bj,设x为bi与bj最长相同前缀的长度,则:
[0083][0084]
(5)数据包到达时间间隔特征
[0085]
由数据包到达时间间隔计算相似性距离d5(i,j),目标主机之间的距离越接近,数据包从目的主机到达源节点经过的公共路由器越多,其在路由器上的排队、传输、处理等行为就越相似,所以数据包到达源节点的时间间隔序列特征也就越相似。对于目的节点i和j,用si和sj表示数据包到达时间间隔序列信号的统计特征向量(到达时间指的是在网关路由器上被捕获的时间),即均值、方差、最小值、第一四分位数、中值、第三四分位数与最大值。对于目的节点对{i,j},采用特征向量si,sj之间的欧式距离作为d5(i,j),即:
[0086][0087]
其中,s
ik
表示特征向量si的第k个维度上的数值,s
jk
表示特征向量sj中的第k个维度上的数值,n表示特征向量的总维度。
[0088]
(6)流速率特征
[0089]
由流速率特征计算相似性距离d6(i,j),目标主机之间的距离越接近,数据包从目的主机到达源节点经过的公共路由器越多,其在路由器上的排队、传输时间就越接近,到达目的主机的流速率也就越接近。对于目的节点i和j,流速率序列信号指的是每秒内该网络流传输的字节数的序列,序列中的各部分值按照时间发生的先后顺序进行排列。用vi和vj表示流速率序列的统计特征向量,即均值、方差、最小值、第一四分位数、中值、第三四分位数与最大值。采用特征向量vi,vj之间的欧式距离作为d6(i,j),即:
[0090][0091]
其中,v
ik
表示特征向量vi的第k个维度上的数值,v
jk
表示特征向量vj中的第k个维度上的数值,n表示特征向量的总维度。
[0092]
(7)数据包大小序列特征
[0093]
由到达数据包的大小序列特征计算相似性距离d7(i,j),目标主机之间的距离越接近,数据包从目的主机到达源节点经过的公共路由器越多,数据包在路由器上的拆分等处理行为越相似,所以数据包最终到达源节点的大小序列特征也就越相似。对于目的节点i和j,li和lj表示到达数据包大小的序列的统计特征向量(以字节为单位),采用特征向量li,lj之间的欧式距离作为节点对{i,j}之间的相似性距离d7(i,j),即:
[0094][0095]
其中,l
ik
表示特征向量li的第k个维度上的数值,l
jk
表示特征向量lj中的第k个维度上的数值,n表示特征向量的总维度。
[0096]
由上述多类型特征计算出的相似性距离均可以作为判断目的主机之间相似性的重要指标。目的主机之间的距离越接近,源节点到目的主机的共享路径就越长,即数据包到目的主机经过的公共路由器就越多,进一步的,数据包在路由器上的排队、传输、处理等行为就越相似,反映到多类型特征上就是数据包的往返时延序列、数据包的大小、到达时间间隔序列、流速率序列等特征就越相似。其中,静态特征即跳数之间的相似性距离和ip地址之间的相似性距离,可解释为:来自同一个子网的目的主机的ip相似性很高,并且源节点到这些目的主机的跳数基本相同。
[0097]
对于目的节点对{i,j},联合上述由7种类型特征计算出的相似性距离组成距离向量dis(i,j),dis(i,j)=[d1(i,j),d2(i,j),....,d7(i,j)]
′
,'表示矩阵的转置,然后对距离向量dis(i,j)进行z-score标准化,以降低数据不均衡带来的影响。
[0098]
同时定义系数向量β,β=[λ1,λ2,....,λ7],向量中的数值表示不同维度的距离所代表的权重,7个维度的权重值之和为1,系数向量与距离向量的乘积代表目的节点对{i,j}之间的最终距离ρ(i,j),ρ(i,j)=β
×
dis(i,j)。系数向量主要是给不同维度的信息赋予不同的权重,即进行拓扑恢复的时候优先考虑比较重要的信息。比如一般情况下小波分解的特征系数、跳数、ip之间的相似性在拓扑恢复的时候要优先考虑,相应的权重值应该更大,通过综合考虑不同维度的信息来提高拓扑估计的准确性。
[0099]
s22、进行初步的网络拓扑估计并通过循环迭代不断优化拓扑结构,最后输出优化后的网络拓扑,
[0100]
在所述多类型特征提取的基础之上,提出基于分层聚类思想的树状网络拓扑估计算法,该算法主要包含两部分内容:基于分层聚类算法融合节点对,迭代优化权重向量,算法流程如图4所示,具体步骤如下:
[0101]
s221、初始化:以步骤s21为基础,根据给定的系数向量β(初始时每个维度的权重均相等),计算出目的节点对之间的距离ρ(i,j)=β
×
dis(i,j)(i,j∈d)。
[0102]
s222、分层聚类的融合过程:
[0103]
1.输入数据:源节点s,目的节点集d,节点对两两之间的距离集合ρ(d2),系数向量β,最小距离阈值δ>0。
[0104]
2.初始化数据:节点集v={s},链路集合e=φ。
[0105]
3.在目标节点集d中查找彼此之间欧式距离ρ(i,j)最小的目的节点对{i,j},并构建新节点f作为它们的父节点。
[0106]
4.更新数据集:d=d\{i,j},v=v∪{i,j},e=e∪{(f,i),(f,j)}。
[0107]
5.查找节点集d中是否存在步骤3中选择的节点对的兄弟节点,即判断是否存在c∈d,满足:|ρ(i,c)-ρ(i,j)|≤δ或者|ρ(j,c)-ρ(i,j)|≤δ,如果存在,更新输出数据:d=d\c,v=v∪c,e=e∪(f,c),如果不存在,跳过该步骤,继续下一步。
[0108]
6.更新节点f与d中其他节点的距离数据:chil(f)表示步骤4与步骤5中融合的所有子节点的集合,m表示节点f的所有子节点的个数,遍历d中所有节点,对于任意c∈d,计算:最后更新d=d∪f。
[0109]
7.判断融合过程是否结束。如果|d|=1,即仅剩一个目的节点c,更新v:v=v∪c,e=e∪(s,c);否则,重复第3-6步。
[0110]
8.估计树输出:估计出的树状拓扑
[0111]
算法中的最小距离阈值δ是判断已融合的目的节点对是否还有兄弟节点的依据,其中α为经验取值(α>1),需根据不同的探测目标取不同的值。
[0112]
s223、迭代优化过程:
[0113]
对于估计出的树状拓扑,结合系数向量β构造一个二次规划问题:即让估计树中同一路由节点下的目的节点对之间的距离达到最小,用公式表述为:
[0114][0115][0116]
其中,u表示估计出的树中,有公共父节点的目的节点对的集合,为u中的节点对,是求解二次规划问题所得出的新的权重系数向量,用于下一轮的拓扑估计。迭代到一定次数或者系数向量的变化值小于某一个阈值即可停止迭代,输出最终的估计树。具体步骤如下:
[0117]
1.给定系数向量的初始值β0(每个维度的权重值都相等),由初步的拓扑估计算法得到一棵初始的估计树t0。
[0118]
2.通过迭代更新权重系数和估计树。对于第τ 1(τ>0)次迭代,利用第τ次迭代的估计树t
τ
来最小化目标函数σ(t
τ
,β)进而更新系数向量β
τ 1
。其中,最小化σ(t
τ
,β)是一个标准的二次规划问题,可以通过很多已知的有效方法求解,如内点法和积极集法,本发明的方法采用python的cvxopt模块构造并求解此二次规划问题。基于更新的系数向量β
τ 1
进行新一轮的拓扑估计,得到新的估计树t
τ 1
。
[0119]
3.重复执行步骤2直到满足迭代的收敛条件。收敛条件可以定义为迭代到一定的次数、系数向量的变化值小于给定的阈值或者估计树的结构连续几次迭代都没有明显变化,迭代收敛后输出优化后的估计树。
[0120]
由于初始给定的系数向量β0没有考虑到不同维度信息的优先级,导致初始的估计树与真实网络拓扑相比误差会比较大,后续的迭代过程通过不断调整权重值,使得比较重要的维度的信息所占的权重增大,最终对估计树起到了优化效果。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。