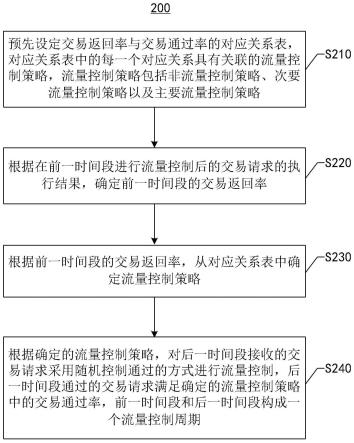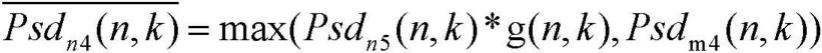
1.本发明涉及音频处理技术领域,特别是涉及一种无盲区的多麦克风环境噪声抑制方法。
背景技术:
2.带通话的耳机可能面临来自各个方向的噪声,人头带着话务耳机,如图1所示,噪声源可能来自左边,也可能来自右边。市面上有带环境噪声降噪功能的通话耳机有单麦以及双麦降噪的两种模式,通常主麦克风20是人嘴附近的咪杆中,用于采集人说话的声音,辅助麦克风10放在其中一个耳包的外侧用于采集环境噪声。
3.常规双麦降噪方案里的主麦克风采用方向性的麦克风,以尽可能的采集人嘴发出的声音,减少采集的噪声量来提高主麦信噪比,辅助麦克风通常为全指向性麦克风,采集来自各个方向的噪声。双麦降噪算法用辅麦采集到的环境噪声来估算主麦中环境噪声,从而用常规单麦克风的降噪算法(如维纳滤波、基于最小均方误差的统计算法、基于信噪比的神经网络模型等)实现双麦降噪。
4.辅助麦克风用于主麦克风中的噪声功率谱,即通过辅助麦克风的功率谱来估计主麦的功率谱,通常噪声来源较远,噪声到达主辅麦时的功率谱基本相同,因而只要计算出辅麦到主麦的频率响应,即可以通过简单的频谱映射,用辅助麦克风的功率谱来估计主麦的功率谱。
5.现实生活中的噪声可能是稳态的空调声,也可能是如键盘敲击等瞬态噪声,因而使用稳态噪声的方法来估计辅助麦克风的噪声功率谱并不是好办法,通常是直接拿辅助麦克风的功率谱来作为当前辅助麦克风的噪声功率谱的估计。
6.实际测试看,如果噪声源来自于辅助麦克风一侧,双麦降噪算法效果较好,而且噪声源越靠近辅助麦克风,整体降噪算法性能越好。但若噪声源来自辅助麦克风另一侧,因为噪声源不能直达辅助麦克风,而可直达主麦克风,一方面降低了主麦克风的信噪比,一方面降低了辅助麦克风的噪信比,使得整体降噪算法性能大幅下降。
7.如上所述,在话务、考试等应用中,噪声源可能来自各个方向,采用传统的主麦克风 强侧辅助麦克风的方式能提高噪声源来自辅助麦克风一侧的整体降噪效果,而往往对于来自辅助麦克风另一侧的噪声源降噪效果不佳。
技术实现要素:
8.本发明的目的是针对现有技术中的问题,而提供一种无盲区的多麦克风环境噪声抑制方法,通过增加话务式耳机的辅助麦的数量,每侧通过一个或者以上的辅助麦形成合成的辅助麦信号,抑制辅麦中的人嘴发出的声音,尽可能地提高辅麦采集的噪声信号,从而提高辅助麦克风噪信,进而使得估计的辅麦噪声更准确,从而提高整体的环境噪声降噪效果。
9.为实现本发明的目的所采用的技术方案是:
10.一种无盲区的多麦克风环境噪声抑制方法,用于配置有一个主麦克风及n个辅助麦克风的话务式耳机的环境噪声抑制,n为大于等于2的偶数,每个耳机侧配置至少一个辅助麦克风,每个耳机侧通过配置的至少一个辅助麦克风合成得到辅助麦克风合成信号;
11.计算辅助麦克风合成信号的噪声功率谱,并通过频域的映射计算出主麦克风的噪声功率谱;
12.根据主麦克风的噪声功率谱以及带噪信号功率谱,利用基于噪声功率谱和带噪信号功率谱的降噪算法去除主麦克风的噪声信号,得到降噪的频谱信号转换为时域信号输出。
13.优选的,所述辅助麦克风合成信号通过波束形成法形成或是通过平滑合成法形成。
14.优选的,所述的通过平滑合成法形成时,是先计算辅助麦克风信号的幅度均方差,然后通过各自的幅度均方差,确定计算各自的混音比例,反相混合形成。
15.优选的,所述的通过波束形成法形成时,是根据辅麦的噪声源定位结果,利用匹配对应的二阶锥规划的波束形成滤波器对两个辅助麦采集的信号滤波处理,输出最终的辅助麦的合成信号。
16.优选的,对辅助麦克风,使用主麦克风的分频点语音存在概率,更新辅助麦克风合成信号的噪声功率谱,对辅助麦克风合成信号噪声功率谱进行调整,设置辅助麦克风合成信号噪声功率谱的下限值并以此进行主麦风的噪声功率谱的估计的下限值。
17.其中,所述对辅助麦噪声功率谱进行调整包括:
18.将辅助麦克风的平均信号的噪声功率谱psd
n5
(n,k)乘以增益因子g(n,k)视为合成辅助麦克风合成信号的噪声功率谱的下限,获得经过下限调整的辅助麦克合成信号的噪声功率谱表示为;
[0019][0020]
g(n,k)=1.0-0.5*spp
m1
(n,k)
[0021]
上式中,spp
m1
(n,k)为主麦克风的分频点语音存在概率,psd
m4
(n,k)为辅助麦克风合成信号的带噪信号功率谱,psd
n5
(n,k)为辅助麦克风平均信号的噪声功率谱。
[0022]
其中,所述的计算辅助麦克风合成信号的噪声功率谱,并通过频域的映射计算出主麦克风的噪声功率谱后,再将主麦克风的噪声功率谱乘以增益因子g(n,k)作为最终的主麦克风的噪声功率谱psd
n1-final
(n,k)的下限,获得经过下限调整的主麦克风的噪声功率谱psd
n1-final
(n,k):
[0023]
psd
n1-final
(n,k)=max(psd
n4-map
(n,k),psd
n1
(n,k)*g(n,k))
[0024][0025][0026]
其中,psd
n4-map
(n,k)是映射到主麦克风噪声功率谱的辅助麦克风的合成信号的噪
声功率谱,psd
n1
(n,k)是主麦克风的噪声功率谱,psd
m1
(n,k)是主麦克风的带噪信号功率谱估计,psd
m4
(n,k)是辅助麦克风的合成信号的带噪信号功率谱估计,β是介于0和1之间的一个参数,代表映射增益因子的平滑系数,映射增益因子η(n,k)只在主麦克风语音检测为没有语音的情况下进行。
[0027]
本发无盲区的多麦克风环境噪声抑制方法,通过话务式耳机的多个辅助麦形成合成的辅助麦信号,抑制辅麦中的人嘴发出的声音,提高辅麦采集的噪声信号,从而提高辅助麦克风噪信比,进而使得估计的辅麦噪声更准确,从而提高整体的环境噪声降噪效果。
附图说明
[0028]
图1是现有技术中双麦降噪麦克风的麦克风布置示意图。
[0029]
图2是本发明的无盲区的多麦克风环境噪声抑制系统的辅助麦克风布置示意图。
[0030]
图3是本发明的无盲区的多麦克风环境噪声抑制系统的环境噪声抑制流程图。
[0031]
图4是多辅麦合成的波束成型算法示意图。
具体实施方式
[0032]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0033]
本技术中,主麦与主麦克风同义,辅助麦、辅麦以及辅助麦克风同义。
[0034]
针对配置一个主麦克风以及一个辅助麦克风的话务式耳机而言,假设人嘴发出信号为s(t),环境噪声为n(t),人嘴到主麦克风的传输函数为h1(t),人嘴到辅麦的传输函数为h2(t),则主麦克风和辅助麦克风信号表示为:
[0035][0036][0037]
表示卷积操作
[0038]
把主麦克风和辅助麦克风的时域信号经过短时傅里叶变换到频域得到:
[0039]
m1(n,k)=h1(n,k)*s(n,k) n1(n,k)=s1(n,k) n1(n,k)
ꢀꢀꢀ
(3)
[0040]
m2(n,k)=h2(n,k)*s(n,k) n2(n,k)=s2(n,k) n2(n,k)
ꢀꢀꢀ
(4)
[0041]
其中,m1(n,k)、h1(n,k)、s(n,k)、n1(n,k)、s1(n,k)、m2(n,k)、h2(n,k)、n2(n,k)、s2(n,k)分别是时域信号m1(t)、h1(t)、s(t)、n1(t)、s1(t)、m2(t)、h2(t)、n2(t)、s2(t)的短时傅里叶变换频域表达形式,*表示相乘操作。
[0042]
根据短时傅里叶变换结果,计算主麦克风和辅助麦克风的带噪信号功率谱psd;
[0043]
psd
m1
(n,k)=||m1(n,k)||2=||s1(n,k) n1(n,k)||2ꢀꢀꢀ
(5)
[0044]
psd
m2
(n,k)=||m2(n,k)||2=||s2(n,k) n2(n,k)||2ꢀꢀꢀ
(6)
[0045]
辅助麦克风用于主麦克风中的噪声功率谱,即通过辅助麦克风环境噪声n2(n,k)的功率谱来估计主麦克风环境噪声n1(n,k)的功率谱,通常噪声来源较远,噪声到达主辅麦时的功率谱基本相同,因而只要计算出辅麦到主麦的频率响应,即可通过简单的频谱映射用辅助麦克风环境噪声n2(n,k)的功率谱来估计环境噪声n1(n,k)的功率谱。
[0046]
对于环境噪声信号n(t)而言,现实生活中的噪声可能是稳态的空调声,也可能是
如键盘敲击等瞬态噪声,因而使用稳态噪声的方法来估计辅助麦克风的噪声功率谱并不是好办法,通常是直接拿辅助麦克风的带噪信号功率谱来作为当前辅助麦克风的噪声功率谱的估计,即:
[0047][0048]
因此,辅助麦克风里的噪信比,即将成为整个降噪算法的关键。
[0049]
同时,从实际测试看,如果噪声源来自于辅助麦克风一侧,双麦降噪算法效果较好,而且噪声源越靠近辅助麦克风,整体降噪算法性能越好。但若噪声源来自辅助麦克风另一侧,因为噪声源不能直达辅助麦克风,而可直达主麦克风,一方面降低了主麦克风的信噪比,一方面降低了辅助麦克风的噪信比,使得整体降噪算法性能大幅下降。
[0050]
因此,本发明实施例提出的无盲区的多麦克风环境噪声抑制方法,在辅助麦克风侧,增加辅助麦克风,配置成对称的一对辅助麦克风,如图2所示,通过两个辅助麦克风合成信号,以克服辅助麦克风的强弱侧噪声估计问题,无论噪声来自哪个方向,两个辅助麦克风合成得到的辅助麦克风信号,将有效降低合成信号中人嘴发出的语音信号的频谱,而不会降低合成信号中的噪声功率谱,从而提高了合成辅助麦克风信号的噪信比。
[0051]
当然本发明也可以自然的扩展到多于2个辅助麦克风的场景。
[0052]
本发明实施例,将用于主麦克风噪声功率谱估计的辅助麦克风信号通过两个辅助麦克风信号进行合成而得到,使得来自左右两侧耳罩的辅助麦克风让噪声的采集没有盲区。通过两个辅助麦克风可以通过如波束成型等信号处理方法抑制来自人嘴方向的纯净语音往辅助麦克风的泄露。
[0053]
其中,整个辅助麦克风的信号合成既可以通过软件算法实现,又可以通过简单的硬件电路滤波和混音实现,硬件实现中除了多余的辅助麦克风,额外的辅助电路复杂度低,易于实现。
[0054]
需要说明的是,本发明实施例中,在得到辅助麦克风合成信号的噪声功率谱后,通过频域的映射就可以综合出主麦的噪声功率谱,获得精确的主麦噪声功率谱。通过获得精确的主麦噪声功率谱,使得基于信噪比的各类算法能很好的去除主麦克风的噪声信号。
[0055]
其中,获得该主麦噪声功率谱可以用于常规的单麦克降噪算法,如谱减法、维纳滤波法、基于最小均方误差的各种谱域统计算法等以及最新的基于神经网络的单麦降噪算法,进行主麦的降噪处理,此为现有技术,不再赘述。
[0056]
其中,所这的在得到辅助麦克风的噪声功率谱,通过频域的映射就可以综合出主麦的噪声功率谱中,所述频谱的映射的映射因子可以通过在语音不活动时,主麦的功率谱和辅助麦的功率谱映射因子平滑得出,见式(15)所示,将在后面详细说明。
[0057]
其中,精确的主麦噪声功率谱也为主麦的语音活动检测提供了很好的信噪比参考,可以设计简单的基于信噪比的语音检测算法,从而降低整体算法的实现复杂度。由于常规的双麦降噪算法以及单麦降噪算法多处已涉及,对此降噪算法不再赘述。
[0058]
本发明以下部分,将重点说明如何实现多辅麦的噪声功率谱合成,不失一般性,以每个耳机侧安装一个辅助麦的实现为例。
[0059]
由于安装有多个辅助麦,而麦克风出厂时的标准不同,通常麦克风的灵敏度误差在
±
2db,可以通过分拣提高灵敏度误差到
±
1db,但即便如此,安装到辅麦上的麦克风仍然有灵敏度误差,因而在出厂时,可以通过在耳机正前方的信号进行灵敏度校准,这个可以包含在出厂检测程序里,直接把校准值更新到出厂版本的固件参数。
[0060]
设另一个耳机侧的第二个辅麦信号采集的信号表示为:
[0061][0062]
式中n3(t)为第二个辅麦信号采集到的环境噪声信号,s3(t)为第二个辅麦采集到的人嘴发出信号,s(t)为人嘴发出信号,h3(t)为人嘴到第二个辅麦的传输函数。
[0063]
经过麦克风校准之后,辅助麦克风信号的幅度,就可大致判断噪声源的方向,因而通过麦克风信号的幅度均方差可计算两个辅助麦克风的混音比例。进而,通过平滑合成算法可以合成辅助麦克风的合成信号,计算如下:
[0064][0065]
其中,α是介于0和1之间的一个参数,代表幅度均方差rms(root mean square)的统计时隙的平滑因子,n为计算幅度均方差rms的窗长,i为用窗分帧的帧序号,rms2(b),rms3(b)分别为每一个耳机侧的辅助麦采集的信号的幅度均方差,。
[0066]
则由两个辅助麦所合成的辅助麦克风信号为:
[0067][0068]
式中,m2(t),m3(t)分别为一个耳机左右侧的辅麦采集的带噪信号;
[0069]
通常,人嘴泄露到两个辅麦的信号基本一致,即s2(t)和s3(t)高度相关,而对应的噪声信号n2(t)和n3(t)则相对独立,所以以上混音时做了一个反相。
[0070]
示例性的,所述的辅助麦的合成信号,除了前面所述的采用平滑合成算法形成外,还可以是通过波束形成算法实现形成,如图4所示。根据两个辅麦的噪声源定位结果(若没有合适的噪声源位置,使用0度方向),在对90度人嘴方向进行波束抑制的情况下,对噪声源位置进行波束成型,这种多目标约束的波束成型可以用常规的二阶锥规划实现。
[0071]
本发明实施例中,其声源定位精度不需要很高,比如10度左右,提前使用二阶锥规划设计出要求角度的波束形成滤波器,即可在辅麦信号合成时,根据噪声源位置进行合适的滤波器选择;最终合成的综合的辅麦信号为:
[0072]
[0073]
其中f3(t)和f2(t)为根据噪声源角度选择的预存二阶锥规划的波束形成滤波器。
[0074]
由于当人嘴说话时,语音信号会泄露到辅助麦克风的问题,因此,为了提高估计噪声功率谱的准确性,在通过平滑合成法形成辅麦的合成信号时,采用反相混音,以进一步的提升合成信号噪声功率谱的准确性。同理,在通过波束形成法形成辅麦的合成信号时,在波束成型实现时,在滤波器设计时,选择抑制90度人嘴方向的信号到某个范围作为二阶锥目标,这样就能有效减少语音信号往辅助麦克风的泄露,从而减少辅助麦克风里的有用信号成分。
[0075]
对于话务式耳机的辅助麦,无论是波束形成算法,还是平滑合成算法,它们所得到的合成噪声功率谱都趋近于两个辅助麦克风反相混音的结果,如果噪声是低频分量,波长较长,则反相混音得到的噪声信号大幅减少,因而就需要处理多辅助麦合成导致的噪声功率谱下降的问题。
[0076]
为解决前述的多辅助麦合成导致的噪声功率谱下降,本发明提出以下的技术:
[0077]
使用主麦的语音存在概率spp,更新整体辅助麦的算法平均输出的噪声功率谱,设定辅助麦克风的合成信号的噪声功率谱的下限值,并在辅助麦克风的合成信号的噪声功率谱低于该下限值时,以此下限值作为其噪声功率谱,进行主麦克风的噪声功率谱的估计。
[0078]
设定平均辅麦信号为:
[0079][0080]
其中,主麦的分频点语音存在概率(spp,speech presence probability)由主麦里的噪声估计功率谱和当前频点功率谱,由公式(14)计算得出。
[0081][0082]
其中,ξ为预设的标定为语音的snr值(如15db),π为180度对应弧度。
[0083]
辅助麦平均信号的估计噪声功率谱psd
n5
(n,k)和主麦的噪声功率谱psd
n1
(n,k)可经由常规的基于spp的噪声功率谱算法得出,即估计出麦克风的主麦的分频点语音存在概率spp后,利用基于spp的贝叶斯估计得出噪声功率谱,相关的算法有很多,这里不赘述。当然其他的单麦克风噪声功率谱算法也可。
[0084]
其中,辅助麦平均信号的估计噪声功率谱psd
n5
(n,k)乘以增益因子g(n,k)视为合成辅助麦合成信号的噪声功率谱的下限,即经过下限调整的辅助麦合成信号噪声功率谱表示为:
[0085][0086][0087][0088]
g(n,k)=1.0-0.5*spp
m1
(n,k)
[0089]
同理,在辅助麦的合成信号噪声功率谱映射到主麦噪声功率谱(psd
n4-map
(n,k))之
后,最终主麦里的噪声功率谱psd
n1
(n,k)乘以增益因子g(n,k)也可以作为最终的主麦的噪声功率谱psd
n1-final
(n,k)的下限,如公式(15)所示:
[0090][0091]
其中β是介于0和1之间的一个参数,代表映射增益因子的平滑系数,需要注意的是,映射增益因子η(n,k)只在主麦语音检测为没有语音的情况下进行的。
[0092]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。