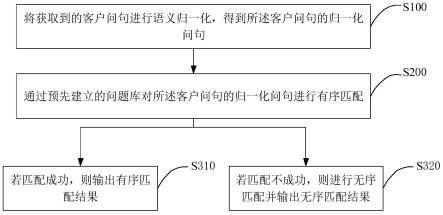
1.本发明涉及数据库
技术领域:
:,特别涉及一种数据库迁移的方法、系统、设备和存储介质。
背景技术:
::2.数据库是目前在金融以及其他领域中广泛使用的数据管理技术。当前市面上存在多种基于不同的底层技术架构实现的数据库,比如oracl数据库和opengauss数据库,这些技术架构不同的数据库称为异构数据库。3.在数据库的应用过程中,有时会需要在异构数据库之间进行数据迁移,例如由于系统升级的需要,要将oracl数据库迁移到opengauss数据库。而目前的自动数据迁移方案主要适用于同构数据库(即具有相同技术架构的数据库)之间的数据迁移,而无法实现异构数据库之间的自动数据迁移。技术实现要素:4.针对上述现有技术的缺点,本发明提供一种数据库迁移的方法、系统、设备和存储介质,以提供一种异构数据库之间的数据迁移方案。5.本技术第一方面提供一种数据库迁移的方法,应用于数据库迁移的系统,所述系统包括多个生产线程和多个消费线程,所述方法包括:6.每个所述生产线程从参数队列中读取迁移参数;其中,所述参数队列根据预设的配置文件确定;7.每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列;8.每个所述消费线程将所述数据队列内的数据移入目标数据库。9.可选的,所述每个所述生产线程从参数队列中读取迁移参数之前,还包括:10.所述系统从将所述配置文件内预设的迁移参数集合移入所述参数队列;11.所述每个所述消费线程将所述数据队列内的数据移入目标数据库之后,还包括:12.所述源数据库中和所述参数队列内的迁移参数匹配的数据全部转移至所述目标数据库后,所述系统将所述配置文件内未被移入所述参数队列的迁移参数集合移入所述参数队列。13.可选的,还包括:14.当所述系统检测到预设的异常状态时,恢复已移入所述目标数据库的数据和已读取的迁移参数,返回执行所述每个所述生产线程从参数队列中读取迁移参数步骤;所述异常状态包括所述参数队列和所述数据队列均为空和所述消费线程未正常结束中至少一项;15.当所述系统检测到所述异常状态的次数达到预设的次数阈值时,关闭所述系统。16.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列,包括:17.每个所述生产线程将源数据库内和所述迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。18.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列之后,还包括:19.检验移入所述数据队列的数据是否符合预设的数据内容检验条件。20.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列,包括:21.每个所述生产线程将源数据库内和所述迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列;其中,所述迁移表结构根据所述源数据库的表结构和/或目标数据库的表结构确定。22.可选的,所述源数据库为oracle数据库;所述目标数据库为opengauss数据库。23.本技术第二方面提供一种数据库迁移的系统,包括多个生成线程和多个消费线程;24.每个所述生产线程用于:25.从参数队列中读取迁移参数;其中,所述参数队列根据预设的配置文件确定;26.每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列;27.每个所述消费线程用于:28.将所述数据队列内的数据移入目标数据库。29.本技术第三方面提供一种电子设备,包括存储器和处理器;30.其中,所述存储器用于存储计算机程序;31.所述处理器用于执行所述计算机程序,所述计算机程序被执行时,具体用于实现本技术第一方面任意一项所提供的数据库迁移的方法。32.本技术第四方面提供一种计算机存储介质,用于存储计算机程序,所述计算机程序被执行时,具体用于实现本技术第一方面任意一项所提供的数据库迁移的方法。33.本技术提供一种数据库迁移的方法、系统、设备和存储介质,方法应用于数据库迁移的系统,系统包括多个生产线程和多个消费线程,方法包括:每个生产线程从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。附图说明34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。35.图1为本技术实施例提供的一种数据库迁移的方法的流程图;36.图2为本技术实施例提供的一种数据库迁移的系统的结构示意图;37.图3为本技术实施例提供的一种电子设备的结构示意图。具体实施方式38.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。39.首先对本发明可能涉及的部分术语进行说明。40.同构迁移,指同一类型(相同技术架构)数据库之间进行迁移,例如oracle到oracle,opengauss到opengauss。41.异构迁移,不同类型(不同技术架构)数据库之间进行数据迁移,例如oracle到opengauss。42.jython语言。jython是一种完整的语言,而不是一个java翻译器或仅仅是一个python编译器,它是python语言在java中的完全实现,所以jython不仅仅提供了python的库,同时也提供了所有的java类,既和python一样,具有代码的简明性和易读性,也可以编译成java字节码,具有java的“写一次,处处可用”的特点。本技术中的数据迁移工具即可跨平台运行,在x86与arm架构上,只需要有jdk软件即可。本技术所述的数据库迁移的方法,具体可以通过用jython语言编写的计算机程序来实现。43.请参见图1,为本技术实施例提供的一种数据库迁移的方法的流程图,应用于数据库迁移的系统(以下简称系统),系统包括多个生产线程和多个消费线程,该方法可以包括如下步骤。44.定义两个队列,分别为参数队列a与数据队列b,a中包含tablename、index等参数信息,其中index是为了定位迁移的范围,a队列没有边界,一次性写入,最后几个元素记为none,用于生产者退出;b为数据队列,用于存储数据,需要定义大小,当多个生产者从a中获取参数,读取源数据库,数据存入b,当b被写满时,生产者暂停,即b队列充当调节作用;多个消费者从b队列读取数据,然后写入目标数据库。具体流程如下图所示:45.s101,每个生产线程从参数队列中读取迁移参数。46.参数队列根据预设的配置文件确定。配置文件具体可以是技术人员预先编写的json文件。47.具体的,参数队列中的迁移参数,可以在系统启动时由系统从配置文件移入参数队列。48.系统一次可以向参数队列移入一批(包含多条)迁移参数,每一条迁移参数都至少包括数据表名(tablename)和索引(index)。49.可选的,参数队列可以是一个无边界的队列,每次系统向参数队列写入多条迁移参数后,可以在这些迁移参数的最后添加几条空数据(即none元素),用于表示参数队列中的迁移参数已读取完毕,当生产线程在参数队列读取到空数据时,就可以确定本次系统写入的一批迁移参数已经读取完毕。50.可选的,每个生产线程每读取一条迁移参数,就从参数队列中移除被读取的迁移参数,或者将被读取的迁移参数标记为已读,避免其他生产线程重复读取。51.在步骤s101中,多个生产线程可以从参数队列的第一条迁移参数开始逐一往后读取,直至读取到上述空数据为止。例如,生产线程1读取第一条迁移数据,然后执行s102,随后生产线程2读取第二条迁移数据并执行s102,生产线程3读取第三条迁移数据并执行s102,以此类推,直至每一生产线程都读取了一条迁移数据后,生产线程1再从参数队列读取第二条迁移参数。52.可以理解的,在执行本实施例的方法之前,生产线程需要和源数据库建立连接,消费线程需要和目标数据库建立连接,建立连接时所需的参数,如数据库地址,类型等可以从配置文件中获取。示例性的,配置文件中可以记录有,源数据库的类型为oracle,地址为xxx,目标数据库的类型为opengauss,地址为yyy,由此,生产线程和消费线程可以按源数据库和目标数据库的类型所对应的连接方式与源数据库和目标数据库建立连接。53.s102,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列。54.数据队列为一个有边界的队列,也就是说,数据队列一次可容纳的数据量有限,不妨假设数据队列最多可容纳k条数据,k为预设的正整数,由配置文件确定。55.可选的,为了避免数据队列中尚未被消费线程移入目标数据库的数据被生产线程新写入的数据覆盖,每个生产线程每次执行步骤s102时,可以先判断数据队列是否可容纳当前要移入的数据,如果可以容纳则执行步骤s102,如果不可以容纳则暂停,等待消费线程将数据队列当前的数据移走,直至数据队列可容纳要移入的数据时,再执行s102。56.如前所述,一条迁移参数包括数据表名和索引,因此,步骤s102中和迁移参数匹配的数据,实质就是,源数据库中,迁移参数的数据表名和索引所指向的数据。57.示例性的,一条迁移参数的数据表名为表a,索引为第1行至第5行,和这条迁移参数匹配的数据,就是源数据库的表a的第1至5行的数据。58.每一生产线程在执行s102时,可以根据自身读取的迁移参数,在源数据库中查找得到匹配的数据,然后读取匹配的数据,读取完成后再将读取到的数据按前述方法写入到数据队列中。59.s103,每个消费线程将数据队列内的数据移入目标数据库。60.消费线程的一种可选启动方式是,系统启动后,每个消费线程处于轮询状态。在轮询状态下的消费线程会实时地检测数据队列中有无数据,当任一消费线程检测到数据队列中有数据时,该消费线程就进入工作状态,执行s103,将数据队列中的数据移入目标数据库。处于工作状态下的消费线程也会实时检测数据队列有无数据,若有数据,则保持工作状态继续将数据队列的数据移入目标数据库,若没有数据,则恢复轮询状态。61.消费线程的另一种可选启动方式是,消费线程保持待机,不实时检测数据队列有无数据,当任一生产线程将数据移入数据队列时,该生产线程向每一消费线程发送数据移入通知,收到数据移入通知后,每个消费线程就开始执行步骤s103,直至数据队列中没有数据时,消费线程再次待机,直到再次收到数据移入通知时则再次执行s103。62.可选的,消费线程首次从数据队列将数据移入目标数据库时,可以判断目标数据库有没有目标端表,即有没有存放要移入的数据的数据表,如果有,就将数据移入目标端表,如果没有,就先创建目标端表,然后将数据移入目标端表。63.其中,目标数据库有无目标端表可以根据配置文件确定,配置文件可以包括一个目标端表配置项,该配置项的值可以是false或true,若为false,表示目标数据库没有目标端表,若为true,表示目标数据库有目标端表。该配置项的默认值可以为false,即默认不存在目标端表。64.可选的,s103中多个消费线程的工作方式可以是,每个消费线程每次从数据队列转移一条数据到目标数据库。65.例如,假设有3个消费线程,其中消费线程1发现数据队列有数据后,进入工作状态,读取数据队列的第1条数据将其移入目标数据库,然后消费线程2发现数据队列还有数据,也进入工作状态,将数据队列的第2条数据移入目标数据库,同理消费线程3将数据队列的第3条数据(如果有)移入目标数据库,之后,消费线程1移入第1条数据结束,发现数据队列还有第4条数据,于是继续保持在工作状态,将第4条数据移入目标数据库,以此类推。66.需要说明,每一条数据从数据队列移入目标数据库后,数据队列中即不存在这条数据。例如,消费线程1将数据队列的数据a移入目标数据库,相当于从数据队列取出数据a,然后将数据a存入目标数据库,移入结束后,数据a相当于从数据队列被移除。67.上述多个生产线程和多个消费线程可以在系统启动时创建,具体的生产线程的数量n和消费线程的数量m可以在前述配置文件中预先设定。68.在一些可选的实施例中,当源数据库有大量数据需要迁移到目标数据库时,可以进行分批次的迁移。具体的,每个生产线程从参数队列中读取迁移参数之前,还包括:69.系统从将配置文件内预设的迁移参数集合移入参数队列;70.每个消费线程将数据队列内的数据移入目标数据库之后,还包括:71.源数据库中和参数队列内的迁移参数匹配的数据全部转移至目标数据库后,系统将配置文件内未被移入参数队列的迁移参数集合移入参数队列。72.也就是说,配置文件中可以按批次记录迁移参数,每一批次对应多条迁移参数,系统启动后,先将第一批次对应的迁移参数写入参数队列,然后生产线程和消费线程基于第一批次对应的迁移参数执行本实施例的迁移方法,在第一批次的迁移任务完成,也就是当第一批次对应的迁移参数所匹配的数据全部移入目标数据库后,系统再将配置文件中第二批次对应的迁移参数移入参数队列,然后生产线程和消费线程根据第二批次的迁移参数再次进行迁移,直至第二批次的迁移任务完成,以此类推,直至完成配置文件中记录的每一批次的迁移任务。73.可选的,当生产线程在参数队列中读取到前述空数据,数据队列中没有数据(或者说数据队列的数据已经全部移入目标数据库),并且每一生产线程和每一消费线程都停止工作时,可以认为当前批次的数据迁移任务完成。74.在分批次迁移时,具体的批次划分,以及每一批次迁移的数据量和数据表的个数等,可以在配置文件中预先设定。75.在一些可选的实施例中,考虑到每一批次的迁移任务进行过程中,可能发生错误,可以设置针对每一批次的重试机制。76.也就是说,图1所示的实施例还可以包括:77.当系统检测到预设的异常状态时,恢复已移入目标数据库的数据和已读取的迁移参数,返回执行每个生产线程从参数队列中读取迁移参数步骤。该步骤在每一批次的迁移任务执行过程中和结束后执行。78.异常状态包括参数队列和数据队列均为空,生产任务数量和消费任务数量不相等和消费线程未正常结束中至少一项。79.参数队列和数据队列均为空,是指,参数队列中没有迁移参数且没有前述空数据,数据队列中没有生产线程移入的数据。这种情况表示系统出现卡死状态。80.消费线程未正常结束,是指,每个消费线程均处于轮询状态,但数据队列中还有数据。81.每一批次的迁移任务开始时,也就是系统将一批次对应的迁移参数写入参数队列时,可以对生产任务数量和消费任务数量进行初始化,生产任务数量的初始值为0,每次生产线程向数据队列移入一条数据,就将生产任务数量增加1,同理消费任务数量的初始值为0,每次消费线程向数据队列移入一条数据,就将消费任务数量增加1,因此,如果某一批次的迁移任务正常结束,此时的生产任务数量应该和消费任务数量相等,如两者不等,说明迁移过程出现异常。82.上述恢复已移入目标数据库的数据和已读取的迁移参数,具体可以是,从目标数据库中将当前批次内已经移入的数据全部删除,然后系统将配置文件中当前批次对应的迁移参数再次写入参数队列,使得生产线程和消费线程重新执行当前批次的迁移任务。83.当系统检测到异常状态的次数达到预设的次数阈值时,关闭系统。84.上述次数阈值可以在配置文件中预先设定。示例性的,次数阈值可以为3,也就是说,若系统连续3次检测到异常状态,则自动关闭(退出)。可选的,自动关闭可以在连续3次(或其他次数阈值)检测到异常状态时,等待15秒后执行。85.在一些可选的实施例中,本实施例在进行数据迁移时,支持以源数据库的表结构,或者目标数据库的表结构,或者目标数据库和源数据库的表结构的交集为准来确定迁移的数据的结构。86.也就是说,可选的,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:87.每个生产线程将源数据库内和迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列。88.其中,迁移表结构根据源数据库的表结构和/或目标数据库的表结构确定。89.在一些可选的实施例中,基于本实施例的方法进行数据迁移时,还可以支持分库分表,具体的划分范围可以根据配置文件中预先设定的basketrange参数来确定。90.具体的,在进行数据迁移时,消费线程可以将索引位于basketrange参数指定的第一索引范围内的数据迁移到目标数据库的数据表1,将索引位于basketrange参数指定的第二索引范围内的数据迁移到目标数据库的数据表2,从而实现分表。91.另外,消费线程可以将索引位于basketrange参数指定的第一索引范围内的数据迁移到目标数据库1,将索引位于basketrange参数指定的第二索引范围内的数据迁移到目标数据库2,从而实现分库。92.在一些可选的实施例中,本实施例的方法还可以支持在数据迁移过程中对源数据库的数据进行条件过滤。93.具体的,配置文件中预先设定有至少一条过滤条件。94.基于配置文件中设定的过滤条件,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:95.每个生产线程将源数据库内和迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。96.也就是说,每个生产线程被创建后可以先从配置文件加载设定好的过滤条件,然后在执行步骤s102时,可以先从源数据库读取和迁移参数匹配的数据,检验读取的每一条数据是否符合加载的过滤条件,将其中符合过滤条件的数据写入到数据队列,将其中不符合过滤条件的数据移除,由此,就可以将源数据库中符合过滤条件的数据移入到目标数据库。97.在一些可选的实施例中,本实施例的方法还可以支持排除特定数据表,被排除的数据表的表名可以在配置文件中记录,当有多个被排除的数据表时,多个表名之间可以用逗号隔开。98.示例性的,配置文件可以包括一个被排除表配置项,该配置项的值可以是表a,表b,表c。通过设定该配置项,可以在将源数据库的数据迁移到目标数据库时,排除源数据库中的表a,表b和表c三个数据表,即这三个数据表中的数据不会被迁移到目标数据库。99.在一些可选的实施例中,本实施例的方法可以在进行数据迁移的同时,进一步进行表数据条数校验和表数据内容校验。100.其中,用于表数据内容校验时,图1所示实施例的步骤s102,即每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列之后,还包括:101.检验移入数据队列的数据是否符合预设的数据内容检验条件。102.上述数据内容检验条件可以在配置文件中预先设定。103.示例性的,数据内容检验条件可以是,数据中特定字段的数值不大于条件阈值(比如年龄不大于20),基于该数据内容检验条件,生产线程可以在将数据移入数据队列后校验其中每一条数据的年龄字段是否大于20,然后统计其中年龄大于20的数据量和年龄不大于20的数据量,或者可以对这两类数据分别标记。104.可选的,生产线程也可以在将数据移入数据队列前校验数据是否符合数据内容检验条件,然后仅将符合数据内容检验条件的数据移入数据队列。105.用于表数据条数校验时,系统中可以预先设定源数据库中被迁移的每一个数据表的迁移条数变量,迁移条数变量在系统启动时被初始化为0。106.比如要对数据表a进行迁移,则系统中创建一个数据表a的迁移条数变量。107.此后每个生产线程将源数据库的数据移入数据队列时,就将移入的数据条数,加到移入的数据所属数据表的迁移条数变量上,由此,当数据迁移结束后,就可以通过数据表的迁移条数变量确定该数据表具体有多少条数据,然后将该数据表的迁移条数变量和配置文件中预设的该数据表的数据量进行比对,从而实现表数据条数校验。108.比如,每次将数据表a的数据移入数据队列时,生产线程就将移入的数据条数加到数据表a的迁移条数变量上,在数据迁移结束后,将数据表a的迁移条数变量和配置文件中预先记录的数据表a的总数据条数比对,从而校验预先获得的数据表a的总数据条数是否正确。109.在一些可选的实施例中,本实施例的数据库迁移的方法还支持在数据迁移之前对需要迁移的数据表进行截断(truncate)和删除(delete)操作,其中删除操作就是按照一定的过滤条件删除数据表中不符合过滤条件的数据,具体实施方式可以参见前述条件过滤的实施例,不再赘述。110.对数据表进行截断,是指,将数据表中超过预设的条数上限的数据删除,仅保留预设的条数上限的数据量。其中条数上限在配置文件中预先设定。111.本技术提供一种数据库迁移的方法,方法应用于数据库迁移的系统,系统包括多个生产线程和多个消费线程,方法包括:每个生产线程从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。112.另外,本发明所提出的数据迁移方法,通过jython编写,不仅具有python的代码简洁性、可读性,还具有java可供跨平台的能力,只要具有jdk环境,在x86架构与arm架构上均可以执行。该数据迁移方法通过json配置文件导入数据迁移参数,参数包括源端数据库、目标端数据库、生产者与消费者进程数量登信息,该数据迁移工具支持分库分表,支持对表进行条件过滤。而现有的基于opengauss国产数据库本身的迁移工具,只能进行同构的迁移,即从opengauss到opengauss,这个无法满足国产化改造时在异构数据库之间的数据迁移需求。113.除此之外,可以看到,本实施例支持使用json文件导入迁移配置参数,使得迁移过程可以更方便。114.本技术实施例还提供一种数据库迁移的系统,请参见图2,该系统包括多个生成线程201和多个消费线程202。115.每个生产线程201用于:116.从参数队列中读取迁移参数;其中,参数队列根据预设的配置文件确定;117.每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列;118.每个消费线程202用于:119.将数据队列内的数据移入目标数据库。120.可选的,每个生产线程201从参数队列中读取迁移参数之前,还包括:121.系统从将配置文件内预设的迁移参数集合移入参数队列;122.每个消费线程202将数据队列内的数据移入目标数据库之后,还包括:123.源数据库中和参数队列内的迁移参数匹配的数据全部转移至目标数据库后,系统将配置文件内未被移入参数队列的迁移参数集合移入参数队列。124.可选的,还包括:125.当系统检测到预设的异常状态时,恢复已移入目标数据库的数据和已读取的迁移参数,返回执行每个生产线程201从参数队列中读取迁移参数步骤;异常状态包括参数队列和数据队列均为空和消费线程202未正常结束中至少一项;126.当系统检测到异常状态的次数达到预设的次数阈值时,关闭系统。127.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:128.每个生产线程201将源数据库内和迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。129.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列之后,还包括:130.检验移入数据队列的数据是否符合预设的数据内容检验条件。131.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:132.每个生产线程201将源数据库内和迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列;其中,迁移表结构根据源数据库的表结构和/或目标数据库的表结构确定。133.可选的,源数据库为oracle数据库;目标数据库为opengauss数据库。134.本技术实施例提供的数据库迁移的系统,其具体工作原理可以参见本技术任一实施例所提供的数据库迁移的方法中的相关步骤,此处不再赘述。135.本技术提供一种数据库迁移的系统,系统包括多个生产线程201和多个消费线程202,每个生产线程201从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程202将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。136.本技术实施例还提供一种电子设备,请参见图3,包括存储器301和处理器302。137.其中,存储器301用于存储计算机程序。138.处理器302用于执行计算机程序,计算机程序被执行时,具体用于实现本技术任一实施例所提供的数据库迁移的方法。139.本技术实施例还提供一种计算机存储介质,用于存储计算机程序,计算机程序被执行时,具体用于实现本技术任一实施例所提供的数据库迁移的方法。140.最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。141.需要注意,本发明中提及的“第一”、“第二”等概念仅用于对不同的系统、模块或单元进行区分,并非用于限定这些系统、模块或单元所执行的功能的顺序或者相互依存关系。142.专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12当前第1页12
技术领域:
:,特别涉及一种数据库迁移的方法、系统、设备和存储介质。
背景技术:
::2.数据库是目前在金融以及其他领域中广泛使用的数据管理技术。当前市面上存在多种基于不同的底层技术架构实现的数据库,比如oracl数据库和opengauss数据库,这些技术架构不同的数据库称为异构数据库。3.在数据库的应用过程中,有时会需要在异构数据库之间进行数据迁移,例如由于系统升级的需要,要将oracl数据库迁移到opengauss数据库。而目前的自动数据迁移方案主要适用于同构数据库(即具有相同技术架构的数据库)之间的数据迁移,而无法实现异构数据库之间的自动数据迁移。技术实现要素:4.针对上述现有技术的缺点,本发明提供一种数据库迁移的方法、系统、设备和存储介质,以提供一种异构数据库之间的数据迁移方案。5.本技术第一方面提供一种数据库迁移的方法,应用于数据库迁移的系统,所述系统包括多个生产线程和多个消费线程,所述方法包括:6.每个所述生产线程从参数队列中读取迁移参数;其中,所述参数队列根据预设的配置文件确定;7.每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列;8.每个所述消费线程将所述数据队列内的数据移入目标数据库。9.可选的,所述每个所述生产线程从参数队列中读取迁移参数之前,还包括:10.所述系统从将所述配置文件内预设的迁移参数集合移入所述参数队列;11.所述每个所述消费线程将所述数据队列内的数据移入目标数据库之后,还包括:12.所述源数据库中和所述参数队列内的迁移参数匹配的数据全部转移至所述目标数据库后,所述系统将所述配置文件内未被移入所述参数队列的迁移参数集合移入所述参数队列。13.可选的,还包括:14.当所述系统检测到预设的异常状态时,恢复已移入所述目标数据库的数据和已读取的迁移参数,返回执行所述每个所述生产线程从参数队列中读取迁移参数步骤;所述异常状态包括所述参数队列和所述数据队列均为空和所述消费线程未正常结束中至少一项;15.当所述系统检测到所述异常状态的次数达到预设的次数阈值时,关闭所述系统。16.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列,包括:17.每个所述生产线程将源数据库内和所述迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。18.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列之后,还包括:19.检验移入所述数据队列的数据是否符合预设的数据内容检验条件。20.可选的,所述每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列,包括:21.每个所述生产线程将源数据库内和所述迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列;其中,所述迁移表结构根据所述源数据库的表结构和/或目标数据库的表结构确定。22.可选的,所述源数据库为oracle数据库;所述目标数据库为opengauss数据库。23.本技术第二方面提供一种数据库迁移的系统,包括多个生成线程和多个消费线程;24.每个所述生产线程用于:25.从参数队列中读取迁移参数;其中,所述参数队列根据预设的配置文件确定;26.每个所述生产线程将源数据库内和所述迁移参数匹配的数据移入预设的数据队列;27.每个所述消费线程用于:28.将所述数据队列内的数据移入目标数据库。29.本技术第三方面提供一种电子设备,包括存储器和处理器;30.其中,所述存储器用于存储计算机程序;31.所述处理器用于执行所述计算机程序,所述计算机程序被执行时,具体用于实现本技术第一方面任意一项所提供的数据库迁移的方法。32.本技术第四方面提供一种计算机存储介质,用于存储计算机程序,所述计算机程序被执行时,具体用于实现本技术第一方面任意一项所提供的数据库迁移的方法。33.本技术提供一种数据库迁移的方法、系统、设备和存储介质,方法应用于数据库迁移的系统,系统包括多个生产线程和多个消费线程,方法包括:每个生产线程从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。附图说明34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。35.图1为本技术实施例提供的一种数据库迁移的方法的流程图;36.图2为本技术实施例提供的一种数据库迁移的系统的结构示意图;37.图3为本技术实施例提供的一种电子设备的结构示意图。具体实施方式38.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。39.首先对本发明可能涉及的部分术语进行说明。40.同构迁移,指同一类型(相同技术架构)数据库之间进行迁移,例如oracle到oracle,opengauss到opengauss。41.异构迁移,不同类型(不同技术架构)数据库之间进行数据迁移,例如oracle到opengauss。42.jython语言。jython是一种完整的语言,而不是一个java翻译器或仅仅是一个python编译器,它是python语言在java中的完全实现,所以jython不仅仅提供了python的库,同时也提供了所有的java类,既和python一样,具有代码的简明性和易读性,也可以编译成java字节码,具有java的“写一次,处处可用”的特点。本技术中的数据迁移工具即可跨平台运行,在x86与arm架构上,只需要有jdk软件即可。本技术所述的数据库迁移的方法,具体可以通过用jython语言编写的计算机程序来实现。43.请参见图1,为本技术实施例提供的一种数据库迁移的方法的流程图,应用于数据库迁移的系统(以下简称系统),系统包括多个生产线程和多个消费线程,该方法可以包括如下步骤。44.定义两个队列,分别为参数队列a与数据队列b,a中包含tablename、index等参数信息,其中index是为了定位迁移的范围,a队列没有边界,一次性写入,最后几个元素记为none,用于生产者退出;b为数据队列,用于存储数据,需要定义大小,当多个生产者从a中获取参数,读取源数据库,数据存入b,当b被写满时,生产者暂停,即b队列充当调节作用;多个消费者从b队列读取数据,然后写入目标数据库。具体流程如下图所示:45.s101,每个生产线程从参数队列中读取迁移参数。46.参数队列根据预设的配置文件确定。配置文件具体可以是技术人员预先编写的json文件。47.具体的,参数队列中的迁移参数,可以在系统启动时由系统从配置文件移入参数队列。48.系统一次可以向参数队列移入一批(包含多条)迁移参数,每一条迁移参数都至少包括数据表名(tablename)和索引(index)。49.可选的,参数队列可以是一个无边界的队列,每次系统向参数队列写入多条迁移参数后,可以在这些迁移参数的最后添加几条空数据(即none元素),用于表示参数队列中的迁移参数已读取完毕,当生产线程在参数队列读取到空数据时,就可以确定本次系统写入的一批迁移参数已经读取完毕。50.可选的,每个生产线程每读取一条迁移参数,就从参数队列中移除被读取的迁移参数,或者将被读取的迁移参数标记为已读,避免其他生产线程重复读取。51.在步骤s101中,多个生产线程可以从参数队列的第一条迁移参数开始逐一往后读取,直至读取到上述空数据为止。例如,生产线程1读取第一条迁移数据,然后执行s102,随后生产线程2读取第二条迁移数据并执行s102,生产线程3读取第三条迁移数据并执行s102,以此类推,直至每一生产线程都读取了一条迁移数据后,生产线程1再从参数队列读取第二条迁移参数。52.可以理解的,在执行本实施例的方法之前,生产线程需要和源数据库建立连接,消费线程需要和目标数据库建立连接,建立连接时所需的参数,如数据库地址,类型等可以从配置文件中获取。示例性的,配置文件中可以记录有,源数据库的类型为oracle,地址为xxx,目标数据库的类型为opengauss,地址为yyy,由此,生产线程和消费线程可以按源数据库和目标数据库的类型所对应的连接方式与源数据库和目标数据库建立连接。53.s102,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列。54.数据队列为一个有边界的队列,也就是说,数据队列一次可容纳的数据量有限,不妨假设数据队列最多可容纳k条数据,k为预设的正整数,由配置文件确定。55.可选的,为了避免数据队列中尚未被消费线程移入目标数据库的数据被生产线程新写入的数据覆盖,每个生产线程每次执行步骤s102时,可以先判断数据队列是否可容纳当前要移入的数据,如果可以容纳则执行步骤s102,如果不可以容纳则暂停,等待消费线程将数据队列当前的数据移走,直至数据队列可容纳要移入的数据时,再执行s102。56.如前所述,一条迁移参数包括数据表名和索引,因此,步骤s102中和迁移参数匹配的数据,实质就是,源数据库中,迁移参数的数据表名和索引所指向的数据。57.示例性的,一条迁移参数的数据表名为表a,索引为第1行至第5行,和这条迁移参数匹配的数据,就是源数据库的表a的第1至5行的数据。58.每一生产线程在执行s102时,可以根据自身读取的迁移参数,在源数据库中查找得到匹配的数据,然后读取匹配的数据,读取完成后再将读取到的数据按前述方法写入到数据队列中。59.s103,每个消费线程将数据队列内的数据移入目标数据库。60.消费线程的一种可选启动方式是,系统启动后,每个消费线程处于轮询状态。在轮询状态下的消费线程会实时地检测数据队列中有无数据,当任一消费线程检测到数据队列中有数据时,该消费线程就进入工作状态,执行s103,将数据队列中的数据移入目标数据库。处于工作状态下的消费线程也会实时检测数据队列有无数据,若有数据,则保持工作状态继续将数据队列的数据移入目标数据库,若没有数据,则恢复轮询状态。61.消费线程的另一种可选启动方式是,消费线程保持待机,不实时检测数据队列有无数据,当任一生产线程将数据移入数据队列时,该生产线程向每一消费线程发送数据移入通知,收到数据移入通知后,每个消费线程就开始执行步骤s103,直至数据队列中没有数据时,消费线程再次待机,直到再次收到数据移入通知时则再次执行s103。62.可选的,消费线程首次从数据队列将数据移入目标数据库时,可以判断目标数据库有没有目标端表,即有没有存放要移入的数据的数据表,如果有,就将数据移入目标端表,如果没有,就先创建目标端表,然后将数据移入目标端表。63.其中,目标数据库有无目标端表可以根据配置文件确定,配置文件可以包括一个目标端表配置项,该配置项的值可以是false或true,若为false,表示目标数据库没有目标端表,若为true,表示目标数据库有目标端表。该配置项的默认值可以为false,即默认不存在目标端表。64.可选的,s103中多个消费线程的工作方式可以是,每个消费线程每次从数据队列转移一条数据到目标数据库。65.例如,假设有3个消费线程,其中消费线程1发现数据队列有数据后,进入工作状态,读取数据队列的第1条数据将其移入目标数据库,然后消费线程2发现数据队列还有数据,也进入工作状态,将数据队列的第2条数据移入目标数据库,同理消费线程3将数据队列的第3条数据(如果有)移入目标数据库,之后,消费线程1移入第1条数据结束,发现数据队列还有第4条数据,于是继续保持在工作状态,将第4条数据移入目标数据库,以此类推。66.需要说明,每一条数据从数据队列移入目标数据库后,数据队列中即不存在这条数据。例如,消费线程1将数据队列的数据a移入目标数据库,相当于从数据队列取出数据a,然后将数据a存入目标数据库,移入结束后,数据a相当于从数据队列被移除。67.上述多个生产线程和多个消费线程可以在系统启动时创建,具体的生产线程的数量n和消费线程的数量m可以在前述配置文件中预先设定。68.在一些可选的实施例中,当源数据库有大量数据需要迁移到目标数据库时,可以进行分批次的迁移。具体的,每个生产线程从参数队列中读取迁移参数之前,还包括:69.系统从将配置文件内预设的迁移参数集合移入参数队列;70.每个消费线程将数据队列内的数据移入目标数据库之后,还包括:71.源数据库中和参数队列内的迁移参数匹配的数据全部转移至目标数据库后,系统将配置文件内未被移入参数队列的迁移参数集合移入参数队列。72.也就是说,配置文件中可以按批次记录迁移参数,每一批次对应多条迁移参数,系统启动后,先将第一批次对应的迁移参数写入参数队列,然后生产线程和消费线程基于第一批次对应的迁移参数执行本实施例的迁移方法,在第一批次的迁移任务完成,也就是当第一批次对应的迁移参数所匹配的数据全部移入目标数据库后,系统再将配置文件中第二批次对应的迁移参数移入参数队列,然后生产线程和消费线程根据第二批次的迁移参数再次进行迁移,直至第二批次的迁移任务完成,以此类推,直至完成配置文件中记录的每一批次的迁移任务。73.可选的,当生产线程在参数队列中读取到前述空数据,数据队列中没有数据(或者说数据队列的数据已经全部移入目标数据库),并且每一生产线程和每一消费线程都停止工作时,可以认为当前批次的数据迁移任务完成。74.在分批次迁移时,具体的批次划分,以及每一批次迁移的数据量和数据表的个数等,可以在配置文件中预先设定。75.在一些可选的实施例中,考虑到每一批次的迁移任务进行过程中,可能发生错误,可以设置针对每一批次的重试机制。76.也就是说,图1所示的实施例还可以包括:77.当系统检测到预设的异常状态时,恢复已移入目标数据库的数据和已读取的迁移参数,返回执行每个生产线程从参数队列中读取迁移参数步骤。该步骤在每一批次的迁移任务执行过程中和结束后执行。78.异常状态包括参数队列和数据队列均为空,生产任务数量和消费任务数量不相等和消费线程未正常结束中至少一项。79.参数队列和数据队列均为空,是指,参数队列中没有迁移参数且没有前述空数据,数据队列中没有生产线程移入的数据。这种情况表示系统出现卡死状态。80.消费线程未正常结束,是指,每个消费线程均处于轮询状态,但数据队列中还有数据。81.每一批次的迁移任务开始时,也就是系统将一批次对应的迁移参数写入参数队列时,可以对生产任务数量和消费任务数量进行初始化,生产任务数量的初始值为0,每次生产线程向数据队列移入一条数据,就将生产任务数量增加1,同理消费任务数量的初始值为0,每次消费线程向数据队列移入一条数据,就将消费任务数量增加1,因此,如果某一批次的迁移任务正常结束,此时的生产任务数量应该和消费任务数量相等,如两者不等,说明迁移过程出现异常。82.上述恢复已移入目标数据库的数据和已读取的迁移参数,具体可以是,从目标数据库中将当前批次内已经移入的数据全部删除,然后系统将配置文件中当前批次对应的迁移参数再次写入参数队列,使得生产线程和消费线程重新执行当前批次的迁移任务。83.当系统检测到异常状态的次数达到预设的次数阈值时,关闭系统。84.上述次数阈值可以在配置文件中预先设定。示例性的,次数阈值可以为3,也就是说,若系统连续3次检测到异常状态,则自动关闭(退出)。可选的,自动关闭可以在连续3次(或其他次数阈值)检测到异常状态时,等待15秒后执行。85.在一些可选的实施例中,本实施例在进行数据迁移时,支持以源数据库的表结构,或者目标数据库的表结构,或者目标数据库和源数据库的表结构的交集为准来确定迁移的数据的结构。86.也就是说,可选的,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:87.每个生产线程将源数据库内和迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列。88.其中,迁移表结构根据源数据库的表结构和/或目标数据库的表结构确定。89.在一些可选的实施例中,基于本实施例的方法进行数据迁移时,还可以支持分库分表,具体的划分范围可以根据配置文件中预先设定的basketrange参数来确定。90.具体的,在进行数据迁移时,消费线程可以将索引位于basketrange参数指定的第一索引范围内的数据迁移到目标数据库的数据表1,将索引位于basketrange参数指定的第二索引范围内的数据迁移到目标数据库的数据表2,从而实现分表。91.另外,消费线程可以将索引位于basketrange参数指定的第一索引范围内的数据迁移到目标数据库1,将索引位于basketrange参数指定的第二索引范围内的数据迁移到目标数据库2,从而实现分库。92.在一些可选的实施例中,本实施例的方法还可以支持在数据迁移过程中对源数据库的数据进行条件过滤。93.具体的,配置文件中预先设定有至少一条过滤条件。94.基于配置文件中设定的过滤条件,每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:95.每个生产线程将源数据库内和迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。96.也就是说,每个生产线程被创建后可以先从配置文件加载设定好的过滤条件,然后在执行步骤s102时,可以先从源数据库读取和迁移参数匹配的数据,检验读取的每一条数据是否符合加载的过滤条件,将其中符合过滤条件的数据写入到数据队列,将其中不符合过滤条件的数据移除,由此,就可以将源数据库中符合过滤条件的数据移入到目标数据库。97.在一些可选的实施例中,本实施例的方法还可以支持排除特定数据表,被排除的数据表的表名可以在配置文件中记录,当有多个被排除的数据表时,多个表名之间可以用逗号隔开。98.示例性的,配置文件可以包括一个被排除表配置项,该配置项的值可以是表a,表b,表c。通过设定该配置项,可以在将源数据库的数据迁移到目标数据库时,排除源数据库中的表a,表b和表c三个数据表,即这三个数据表中的数据不会被迁移到目标数据库。99.在一些可选的实施例中,本实施例的方法可以在进行数据迁移的同时,进一步进行表数据条数校验和表数据内容校验。100.其中,用于表数据内容校验时,图1所示实施例的步骤s102,即每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列之后,还包括:101.检验移入数据队列的数据是否符合预设的数据内容检验条件。102.上述数据内容检验条件可以在配置文件中预先设定。103.示例性的,数据内容检验条件可以是,数据中特定字段的数值不大于条件阈值(比如年龄不大于20),基于该数据内容检验条件,生产线程可以在将数据移入数据队列后校验其中每一条数据的年龄字段是否大于20,然后统计其中年龄大于20的数据量和年龄不大于20的数据量,或者可以对这两类数据分别标记。104.可选的,生产线程也可以在将数据移入数据队列前校验数据是否符合数据内容检验条件,然后仅将符合数据内容检验条件的数据移入数据队列。105.用于表数据条数校验时,系统中可以预先设定源数据库中被迁移的每一个数据表的迁移条数变量,迁移条数变量在系统启动时被初始化为0。106.比如要对数据表a进行迁移,则系统中创建一个数据表a的迁移条数变量。107.此后每个生产线程将源数据库的数据移入数据队列时,就将移入的数据条数,加到移入的数据所属数据表的迁移条数变量上,由此,当数据迁移结束后,就可以通过数据表的迁移条数变量确定该数据表具体有多少条数据,然后将该数据表的迁移条数变量和配置文件中预设的该数据表的数据量进行比对,从而实现表数据条数校验。108.比如,每次将数据表a的数据移入数据队列时,生产线程就将移入的数据条数加到数据表a的迁移条数变量上,在数据迁移结束后,将数据表a的迁移条数变量和配置文件中预先记录的数据表a的总数据条数比对,从而校验预先获得的数据表a的总数据条数是否正确。109.在一些可选的实施例中,本实施例的数据库迁移的方法还支持在数据迁移之前对需要迁移的数据表进行截断(truncate)和删除(delete)操作,其中删除操作就是按照一定的过滤条件删除数据表中不符合过滤条件的数据,具体实施方式可以参见前述条件过滤的实施例,不再赘述。110.对数据表进行截断,是指,将数据表中超过预设的条数上限的数据删除,仅保留预设的条数上限的数据量。其中条数上限在配置文件中预先设定。111.本技术提供一种数据库迁移的方法,方法应用于数据库迁移的系统,系统包括多个生产线程和多个消费线程,方法包括:每个生产线程从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。112.另外,本发明所提出的数据迁移方法,通过jython编写,不仅具有python的代码简洁性、可读性,还具有java可供跨平台的能力,只要具有jdk环境,在x86架构与arm架构上均可以执行。该数据迁移方法通过json配置文件导入数据迁移参数,参数包括源端数据库、目标端数据库、生产者与消费者进程数量登信息,该数据迁移工具支持分库分表,支持对表进行条件过滤。而现有的基于opengauss国产数据库本身的迁移工具,只能进行同构的迁移,即从opengauss到opengauss,这个无法满足国产化改造时在异构数据库之间的数据迁移需求。113.除此之外,可以看到,本实施例支持使用json文件导入迁移配置参数,使得迁移过程可以更方便。114.本技术实施例还提供一种数据库迁移的系统,请参见图2,该系统包括多个生成线程201和多个消费线程202。115.每个生产线程201用于:116.从参数队列中读取迁移参数;其中,参数队列根据预设的配置文件确定;117.每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列;118.每个消费线程202用于:119.将数据队列内的数据移入目标数据库。120.可选的,每个生产线程201从参数队列中读取迁移参数之前,还包括:121.系统从将配置文件内预设的迁移参数集合移入参数队列;122.每个消费线程202将数据队列内的数据移入目标数据库之后,还包括:123.源数据库中和参数队列内的迁移参数匹配的数据全部转移至目标数据库后,系统将配置文件内未被移入参数队列的迁移参数集合移入参数队列。124.可选的,还包括:125.当系统检测到预设的异常状态时,恢复已移入目标数据库的数据和已读取的迁移参数,返回执行每个生产线程201从参数队列中读取迁移参数步骤;异常状态包括参数队列和数据队列均为空和消费线程202未正常结束中至少一项;126.当系统检测到异常状态的次数达到预设的次数阈值时,关闭系统。127.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:128.每个生产线程201将源数据库内和迁移参数匹配,且符合配置文件中预设的过滤条件的数据移入预设的数据队列。129.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列之后,还包括:130.检验移入数据队列的数据是否符合预设的数据内容检验条件。131.可选的,每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列,包括:132.每个生产线程201将源数据库内和迁移参数匹配的数据,按照预设的迁移表结构移入预设的数据队列;其中,迁移表结构根据源数据库的表结构和/或目标数据库的表结构确定。133.可选的,源数据库为oracle数据库;目标数据库为opengauss数据库。134.本技术实施例提供的数据库迁移的系统,其具体工作原理可以参见本技术任一实施例所提供的数据库迁移的方法中的相关步骤,此处不再赘述。135.本技术提供一种数据库迁移的系统,系统包括多个生产线程201和多个消费线程202,每个生产线程201从参数队列中读取迁移参数;参数队列根据预设的配置文件确定;每个生产线程201将源数据库内和迁移参数匹配的数据移入预设的数据队列;每个消费线程202将数据队列内的数据移入目标数据库。本方案通过生产线程和消费线程对数据队列的读写完成数据迁移,即使源数据库和目标数据库的类型不同,生产线程和消费线程也可以分别进行适配,因而本方案能够实现异构数据库之间的数据迁移。136.本技术实施例还提供一种电子设备,请参见图3,包括存储器301和处理器302。137.其中,存储器301用于存储计算机程序。138.处理器302用于执行计算机程序,计算机程序被执行时,具体用于实现本技术任一实施例所提供的数据库迁移的方法。139.本技术实施例还提供一种计算机存储介质,用于存储计算机程序,计算机程序被执行时,具体用于实现本技术任一实施例所提供的数据库迁移的方法。140.最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。141.需要注意,本发明中提及的“第一”、“第二”等概念仅用于对不同的系统、模块或单元进行区分,并非用于限定这些系统、模块或单元所执行的功能的顺序或者相互依存关系。142.专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12当前第1页12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。