1.本发明涉及数据处理领域,尤其是一种声音识别模型的训练方法、识别方法、设备及介质。
背景技术:
2.自然界存在各种各样的声音,如生物声(由鸟类和昆虫等动物产生的生物声音)、自然声(如风声和雨声)以及人类声(泛指人类活动产生的声音)。近年来,通过声音信息来研究生态环境日益受到重视,例如通过研究森林声信息的时空变化特征来揭示鸟类活动规律、通过动物鸣声来监测物种和种群密度等,针对不同的应用,经常需要从大量录音文件将感兴趣的声音识别出来。
3.目前,环境声识别任务仍然存在一些挑战。与语音和音乐信号不同,环境声在频谱和时域结构上更加复杂,这使得设计对应的识别系统更加困难。对于语音和音乐信号而言,由于两者都包含大量结构化的信息,比如音素等,通常可以使用统计模型进行建模,如隐马尔科夫模型等。然而对于环境声信号来说,其来源的复杂性导致其频谱结构也变化很大。同时,由于采集设备与环境的不同,现有的声音数据集中包含大量噪声和静音段,这也将对模型的训练造成影响。此外,由于人工对声音数据集进行标注的工作量很大,而现有声音数据集的规模普遍很小,如何在小数据集上实现泛化能力足够强的识别模型,也是一个挑战。最后,目前基于环境声研究的相关工作,大多还停留在理论阶段而没有实际落地的应用,这也限制了环境声识别相关研究的推动。
技术实现要素:
4.有鉴于此,为了解决上述技术问题,本发明的目的是提供一种声音识别模型的训练方法、识别方法、设备及介质。
5.本发明实施例采用的技术方案是:
6.一种声音识别模型的训练方法,包括:
7.获取声音数据集;
8.对所述声音数据集进行第一能量值计算,根据第一能量值计算结果进行第一筛选处理,得到第一数据;
9.对所述第一数据进行增益处理、滤波频域增强处理以及乱序合并处理,并对增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行组合,得到第二数据;所述滤波频域增强处理包括指向性衰减增强处理以及数据频域随机增强处理
10.对所述第二数据进行梅尔谱计算,得到训练样本;
11.将所述训练样本输入教师网络训练得到教师网络模型,将所述训练样本输入学生网络并根据所述教师网络模型对所述学生网络进行蒸馏学习,得到声音识别模型。
12.进一步,所述对所述声音数据集进行第一能量值计算,包括:
13.对所述声音数据集进行分帧、叠帧以及加窗操作,得到若干帧第一信号;
14.对所述第一信号进行第一离散傅里叶变换以确定每一帧所述第一信号的第一幅度谱;
15.根据预设频点数量分别计算每一所述第一幅度谱的能量值总和,得到第一能量值计算结果。
16.进一步,所述根据第一能量值计算结果进行第一筛选处理,得到第一数据,包括:
17.将预设帧数量的连续的所述第一信号作为一个能量块,根据所述第一能量值计算结果计算每一所述能量块对应的块能量值;
18.从最大的块能量值的能量块中确定目标帧序号;
19.将所述目标帧序号进行时域转换得到时域索引,根据所述时域索引以及预设采样范围确定采样点序号;
20.根据所述采样点序号以及预设数据长度对最大的块能量值的能量块进行切割筛选,得到第一数据。
21.进一步,所述对所述第一数据进行增益处理、滤波频域增强处理,包括:
22.对所述第一数据进行切片处理得到若干个切片数据,从第一预设增益范围中选取第一数值,根据所述第一数值以及预设偏移量确定第二数值,将所述第二数值分别与所述切片数据进行第一相乘,将第一相乘结果重新合成,得到增益处理结果;
23.所述指向性衰减增强处理为:从预设频率范围确定截止频率,通过所述截止频率对所述第一数据进行滤波处理,得到第一增强数据;
24.所述数据频域随机增强处理为:对所述第一数据进行第一分帧加窗处理,并对第一分帧加窗处理结果进行第二离散傅里叶变换,得到第二幅度谱以及相位谱,对所述第二幅度谱进行频带切分,得到若干个频带,根据第二预设增益范围确定增益值,将所述增益值分别与所述频带进行第二相乘,将第二相乘结果进行拼接,根据所述相位谱以及拼接后的第二相乘结果进行逆傅里叶变换转换,得到第二增强数据;所述滤波频域增强处理结果包括所述第一增强数据以及所述第二增强数据。
25.进一步,所述对所述第一数据进行乱序合并处理,并对增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行组合,得到第二数据,包括:
26.根据预设采样点数量以及所述第一数据的采样点总数,计算声音事件数量;
27.对所述第一数据进行第二能量值计算,根据第二能量值计算结果进行若个次数的第二筛选处理,得到所述声音事件数量个声音事件;
28.将所述声音事件进行随机排序和拼接,得到乱序合并处理结果;
29.将所述增益处理结果、所述滤波频域增强处理结果以及所述乱序合并处理结果中的至少之一进行随机组合,得到第二数据。
30.进一步,所述对所述第二数据进行梅尔谱计算,得到训练样本,包括:
31.对所述第二数据进行第二分帧加窗处理,对第二分帧加窗处理结果进行第三离散傅里叶变换,并根据第三离散傅里叶变换结果计算功率谱;
32.根据预设频率上限以及预设频率下限确定梅尔滤波器函数;
33.根据所述梅尔滤波器函数以及所述功率谱,得到梅尔谱;所述训练样包括所述梅尔谱。
34.进一步,所述训练样本具有真实标签;所述将所述训练样本输入学生网络并根据
所述教师网络模型对所述学生网络进行蒸馏学习,得到声音识别模型,包括:
35.将所述训练样本输入至所述教师网络模型,得到预测标签;
36.将所述训练样本输入至学生网络,以在第一温度下得到第一预测结果以及在第二温度下得到第二预测结果;
37.根据所述第一预测结果以及所述预测标签计算蒸馏损失,根据所述第二预测结果以及所述真实标签计算学生损失,计算所述蒸馏损失与第一权重的第一乘积并计算所述学生损失与第二权重的第二乘积,根据所述第一乘积以及所述第二乘积的和确定损失值;
38.返回所述将所述训练样本输入至所述教师网络模型的步骤,直至训练次数或者所述损失值满足预设条件,得到声音识别模型。
39.本发明实施例还提供一种识别方法,包括:
40.获取待识别数据,
41.将所述待识别数据输入至声音识别模型,得到识别结果;所述声音识别模型通过所述声音识别模型的训练方法训练得到。
42.本发明实施例还提供一种电子设备,所述电子设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现所述方法。
43.本发明实施例还提供一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现所述方法。
44.本发明的有益效果是:通过对声音数据集进行第一能量值计算,根据第一能量值计算结果进行第一筛选处理,得到第一数据,有利于尽可能地从弱标注的声音数据集中提取有效成分用于后续训练;对第一数据进行增益处理、滤波频域增强处理以及乱序合并处理,并对增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行组合,由于第二数据基于增益处理、滤波频域增强处理以及乱序合并处理之后组合得到,有利于增加声音识别模型训练过程中对可能携带各种噪声的数据的鲁棒性;对第二数据进行梅尔谱计算,得到训练样本,将训练样本输入教师网络训练得到教师网络模型,将训练样本输入学生网络并根据教师网络模型对学生网络进行蒸馏学习,得到声音识别模型,利用蒸馏技术使得声音识别模型轻量化且提升了识别能力。
附图说明
45.图1为本发明声音识别模型的训练方法的步骤流程示意图;
46.图2为本发明具体实施例教师网络训练以及蒸馏学习的示意图;
47.图3为本发明具体实施例学生网络的结构示意图;
48.图4为本发明具体实施例特征提取块的结构示意图;
49.图5为本发明具体实施例卷积块的结构示意图;
50.图6为本发明具体实施例空间注意力块的结构示意图;
51.图7为本发明识别方法的步骤流程示意图。
具体实施方式
52.为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分的实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本技术保护的范围。
53.本技术的说明书和权利要求书及所述附图中的术语“第一”、“第二”、“第三”和“第四”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
54.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
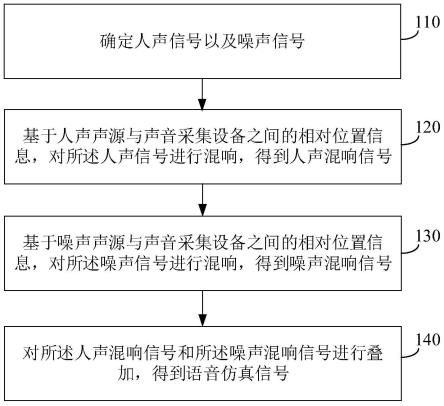
55.如图1所示,本发明实施例提供一种声音识别模型的训练方法,包括步骤s100-s500:
56.s100、获取声音数据集。
57.可选地,声音数据集可以包括包含生物声、人类声以及自然声的类别中的至少一种的音频文件,如表1所示为本发明实施例中所利用的音频文件,包括bird(鸟声)、insect(昆虫声)、bird-insect(鸟声、昆虫声混合)、human(人声)、human-insect(人声、昆虫声混合)、silence(无声)、bird-human(人声、鸟声混合),音频文件时长大于或等于10分钟,其他实施例中可以具有其他类别的音频文件不作具体限定。
[0058] 采样率格式量化比特数通道数bird22050hzwav161insect22050hzwav161bird-insect22050hzwav161human22050hzwav161human-insect22050hzwav161silence22050hzwav161bird-human22050hzwav161
[0059]
s200、对声音数据集进行第一能量值计算,根据第一能量值计算结果进行第一筛选处理,得到第一数据。
[0060]
本发明实施例中,通过步骤s200能够有效地从采集得到的音频文件中提取包含声音事件的环境声样本,达到筛选模型训练所需数据的效果。
[0061]
可选地,步骤s200中对声音数据集进行第一能量值计算,包括步骤s211-s213:
[0062]
s211、对声音数据集进行分帧、叠帧以及加窗操作,得到若干帧第一信号。
[0063]
可选地,记一个音频文件的数据采样点数n,设置分帧帧长为wlen(包括但不限于1024),设置帧移inc(包括但不限于256),由式(1)得到该音频文件的分帧帧数nf。记帧叠为
0(即inc=wlen时)的情况下,均匀分帧后每一帧为x
in
(n,λ),其中n为采样点编号,λ为帧编号。
[0064][0065]
将当前帧x
in
(n,λ)与上一帧x
in
(n,λ-1)进行长度为overlap=wlen-inc的帧叠(叠帧)得到x
on
(n,λ),帧叠后的总长度仍然为wlen,n=0,1,
…
,wlen-1。
[0066][0067]
对x
on
(n,λ)进行加窗,窗的类型为汉明窗w(n,α),其中α(包括但不限于0.46),窗长等于帧长点数wlen,由此得到所有加窗后的帧xw(n,λ),即若干帧第一信号。
[0068][0069]
xw(n,λ)=x
on
(n,λ)*w(n,α)0≤n≤wlen-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0070]
s212、对第一信号进行第一离散傅里叶变换以确定每一帧第一信号的第一幅度谱。
[0071]
对每一帧的第一信号xw(n,λ)进行n点(包括但不限于例如1024)的第一离散傅里叶变换(第一dft运算),取第一dft运算结果的模值得到每一帧第一信号的第一幅度谱x(λ,k),k表示频率点,λ为帧编号。可选地,由于傅里叶变换的对称性,可以只对频谱的前nf个频点进行分析,其中nf=n/2 1,j为虚数:
[0072][0073]
s213、根据预设频点数量分别计算每一第一幅度谱的能量值总和,得到第一能量值计算结果。
[0074]
可选地,对第一幅度谱x(k,λ)上每一帧内的目标频段的频率点幅度值求和,得到每一帧信号的能量总和en(λ)(每一第一幅度谱的能量值总和,即第一能量值计算结果),其中f
t
为底噪频率(包括但不限于200hz),n
t
为底噪频率对应的频点数(预设频点数量),fs为音频采样率(包括但不限于16000hz),表示向下取整,例如结果为3.5时,向下取整为3。
[0075][0076][0077]
可选地,步骤s200中根据第一能量值计算结果进行第一筛选处理,得到第一数据,包括步骤s221-s224:
[0078]
s221、将预设帧数量的连续的第一信号作为一个能量块,根据第一能量值计算结果计算每一能量块对应的块能量值。
[0079]
s222、从最大的块能量值的能量块中确定目标帧序号。
[0080]
可选地,以预设帧数量(block_frames)个连续的第一信号为一个能量块,计算每个能量块的能量值,并从最大的块能量值的能量块中确定目标帧序号,例如目标帧序号包括但不限于最大的能量块的中心帧的中心帧编号λ
t
(由式(11)计算得到)。其中frame_nums为第一信号的总帧数,blocks为分割后的能量块个数,en(λb)表示每一个能量块的能量,λb为能量块下标,λ
max_block
表示能量最大的能量块下标。
[0081][0082][0083][0084]
λ
t
=λ
max_block
*(block_frames-1) (block_frames/2)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0085]
s223、将目标帧序号进行时域转换得到时域索引,根据时域索引以及预设采样范围确定采样点序号。
[0086]
可选地,确定目标帧序号λ
t
后,通过式(12)进行时域转换,得到目标帧序号在时域的时域索引index
t
。
[0087][0088]
假设预设随机偏移采样点数为offset_nums(点数设置与采样率相关,例如在22050hz采样率情况下,可设置为offset_nums=22050*0.5=11025),因此预设采样范围可以为:
[0089]
[index
t-offset_nums,index
t
offset_nums],从该中预设采样范围中随机选取一个采样点序号得到采样点序号indexs。
[0090]
例如:假设每一帧的时间长度为2秒,然后通过公式(11)得到目标帧序号为3,那么目标帧序号在时域的时域索引即表示第5秒的采样点的序号,因为第3帧的时间范围为4到6秒,其中心的采样点即为5秒时的采样点位置。需要说明的是,当各帧之间没有互相重叠下的情况,即overlap=0按照上述例子计算,当分帧时各帧之间有重叠,则按照公式(12)计算。
[0091]
s224、根据采样点序号以及预设数据长度对最大的块能量值的能量块进行切割筛选,得到第一数据。
[0092]
可选地,设需要得到的预设数据长度为valid_len(包括但不限于22050*4=88200),则为以采样点序号indexs的点为中心,分别向左右扩展个采样点,从而得到起始位置和终止位置,根据起始位置和终止位置进行切割筛选,得到有效训练样本,即第一数据x
valid
。
[0093]
s300、对第一数据进行增益处理、滤波频域增强处理以及乱序合并处理,并对增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行组合,得到第二数据。其中,滤波频域增强处理包括指向性衰减增强处理以及数据频域随机增强处理。
[0094]
本发明实施例通过步骤s300生成第二数据,可以有效提高声音识别模型识别声音的鲁棒性,使得声音识别模型在复杂环境声场景下仍然能够实现高效识别。
[0095]
可选地,步骤s300中对第一数据进行增益处理、滤波频域增强处理,包括步骤s311-s313:
[0096]
s311、对第一数据进行切片处理得到若干个切片数据,从第一预设增益范围中选取第一数值,根据第一数值以及预设偏移量确定第二数值,将第二数值分别与切片数据进行第一相乘,将第一相乘结果重新合成,得到增益处理结果。
[0097]
可选地,假设第一数据x
valid
的采样点数为n
valid
,以n
clip
(包括但不限于22050)为每个切片的采样点数,对x
valid
进行切片得到多个切片数据x
clip
(λc),其中λc为切片序号。对每一个切片数据x
clip
(λc)进行随机的幅度增强或者衰减,具体地:从第一预设增益范围[rn_l,rn_h](包括但不限于[-10,10])中随机选取第一数值(增益值rn_s),然后在[rn_s-rn_o,rn_h rn_o]中随机选取第二数值用作最终的增益,与切片数据直接进行第一相乘得到增益处理后的数据(第一相乘结果),经过随机增益处理后的第一相乘结果重新合成为完整的音频数据,得到增益处理结果。需要说明的是,rn_l和rn_h分别是第一级随机增益的下限和上限,而rn_o(包括但不限于2)是第二级增益的预设偏移量。
[0098]
s312、指向性衰减增强处理为:从预设频率范围确定截止频率,通过截止频率对第一数据进行滤波处理,得到第一增强数据。
[0099]
可选地,从预设频率范围内(包括但不限于[200,1000])中随机取值得到截止频率f
cut
,对第一数据x
valid
进行滤波处理,例如一阶或者二阶巴特沃斯低通滤波,从而得到第一增强数据。
[0100]
s313、数据频域随机增强处理为:对第一数据进行第一分帧加窗处理,并对第一分帧加窗处理结果进行第二离散傅里叶变换,得到第二幅度谱以及相位谱,对第二幅度谱进行频带切分,得到若干个频带,根据第二预设增益范围确定增益值,将增益值分别与频带进行第二相乘,将第二相乘结果进行拼接,根据相位谱以及拼接后的第二相乘结果进行逆傅里叶变换转换,得到第二增强数据;滤波频域增强处理结果包括第一增强数据以及第二增强数据。
[0101]
可选地,对第一数据进行第一分帧加窗处理,原理与步骤s200中所描述的类似不再赘述,对第一分帧加窗处理结果进行第二离散傅里叶变换,得到第二幅度谱xa(k,λ)以及相位谱θ(k,λ)。假设频域切分带宽为band_width hz,对第二幅度谱xa(k,λ)进行频带切分。其中fre_resolution为频率分辨率,band_bins为切分后每个频带所占的频点数,bands为切分后的频带数,xs(s,λ)表示频带切分后的各个频带,s为频带索引。
[0102][0103][0104][0105]
xs(s,λ)=xa(k,λ),i*band_bins≤k≤(i 1)*band_bins,0≤i《bands
ꢀꢀꢀꢀꢀ
(16)
[0106]
本发明实施例中,根据第二预设增益范围确定增益值,例如通过步骤s311的方法通过二级随机方式确定bands个第二级数值作为最终的增益,即增益值,然后将该增益值分
别与频带xs(s,λ)进行第二相乘,得到增益后的频段幅度谱,即第二相乘结果,将第二相乘结果重新按频率维度拼接,拼接后的第二相乘结果与相位谱θ(k,λ)一并通过逆傅里叶变换转换回时域信号,得到最终的增强信号,即第二增强数据。
[0107]
可选地,步骤s300中对第一数据进行乱序合并处理,并对增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行组合,得到第二数据,包括步骤s321-s324:
[0108]
s321、根据预设采样点数量以及第一数据的采样点总数,计算声音事件数量。
[0109]
可选地,假设第一数据的其采样点数(采样点总数)为n
valid
,设事件长度(预设采样点数量)为n
event
(包括但不限于22050)个采样点,则可将第一数据x
valid
切分为个声音事件,即声音事件数量为event__nums。
[0110]
s322、对第一数据进行第二能量值计算,根据第二能量值计算结果进行若个次数的第二筛选处理,得到声音事件数量个声音事件。
[0111]
可选地,每个事件的切分的开始和终止位置通过与步骤s200相同的方法确定,对第一数据进行第二能量值计算,参照计算第一能量值的方法,第二筛选处理的参照s221-s224的方法,每次进行第二筛选处理可以得到一个声音事件,通过若干次(event__nums次)的第二筛选处理,可以得到event__nums个声音事件event1,event2,...,event
event_nums
。
[0112]
s323、将声音事件进行随机排序和拼接,得到乱序合并处理结果。
[0113]
可选地,将所有声音事件的顺序随机打乱排序得到重排后的声音事件列表,最后将其重新拼接,得到增强后的音频数据,即乱序合并处理结果。
[0114]
s324、将增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一进行随机组合,得到第二数据。
[0115]
可选地,将增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的至少之一通过随机化的方式进行随机组合,得到第二数据。可以理解的是,第二数据可以包括增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的其中之一,或者可以包括增益处理结果、滤波频域增强处理结果以及乱序合并处理结果中的其中两个或者其中三个。
[0116]
s400、对第二数据进行梅尔谱计算,得到训练样本。
[0117]
可选地,步骤s400包括步骤s411-s413:
[0118]
s411、对第二数据进行第二分帧加窗处理,对第二分帧加窗处理结果进行第三离散傅里叶变换,并根据第三离散傅里叶变换结果计算功率谱。
[0119]
可选地,第二分帧加窗处理参照第一分帧加窗处理的过程,不再赘述。本发明实施例中对第二分帧加窗处理结果进行第三离散傅里叶变换,取第三离散傅里叶变换结果的模值并求平方从而得到功率谱x
p2
(k,λ)。需要说明的是,由于傅里叶变换的对称性,可以用只对频谱的前nf个频点进行分析,其中nf=n/2 1,即可得到k∈[1,nf],分帧操作按式(1)得λ∈[1,nf]。
[0120]
s412、根据预设频率上限以及预设频率下限确定梅尔滤波器函数。
[0121]
s413、根据梅尔滤波器函数以及功率谱,得到梅尔谱。
[0122]
本发明实施例中,训练样本为梅尔谱。可选地,假设目标环境中具体的声音事件的
实际频率:如预设频率下限为f
l
、预设频率上限为fh(单位为hz),这里设置f
l
=200hz,fh=12000hz,根据梅尔频率与实际频率的转化关系:
[0123][0124]
其中,f为实际频率,f
mel
为梅尔频率,待计算的梅尔滤波器组的梅尔频率(单位为梅尔mel)的上限和下限分别为f
mel
(f
l
)与f
mel
(fh)。具体地,构建梅尔滤波器组,在目标频率范围[f
mel
(f
l
),f
mel
(fh)]内设置若干带通滤波器h(k,m),1≤m≤m,其中k表示频率点,m为滤波器的标号,m为待设滤波器的总数,这里m(例如取128,m取值越大,得出的梅尔谱图频率分辨率越好)。h(k,m)滤波器(梅尔滤波器函数)表达式见式(18),每个滤波器具有三角滤波特性,其中心频率为f(m),如式(19)所示。
[0125][0126][0127]
其中,f
l
为滤波器频率范围内的最低频率(单位为hz),fh为滤波器频率范围的最高频率,n1为fft的长度,fs为采样频率,为f
mel
(f)的逆函数。本发明实施例中,将数据切片的功率谱x
p2
(k,λ)通过梅尔滤波器函数h(k,m)得到该切片数据的梅尔谱见式(20)。
[0128][0129]
s500、将训练样本输入教师网络训练得到教师网络模型,将训练样本输入学生网络并根据教师网络模型对学生网络进行蒸馏学习,得到声音识别模型。
[0130]
本发明实施例中,训练样本具有真实标签,该真实标签可以实现通过人工标注,例如在训练样本中进行标注或者在声音数据集中进行事先标注,不作具体限定。
[0131]
如图2所示,本发明实施例中,先通过训练样本(traindata)输入至教师网络训练以得到教师网络模型。可选地,教师网络采用resnet18主干作为教师网络的特征提取器,按照环境声类别数设置全连接层(fc),可以输出labels(具体地分类的标签),训练所设置的小批次样本数为32,使用初始学习率为2x10-4的adam优化器进行优化,对模型训练若干个包括但不限于200个epoch后保存验证精度最高的模型参数,可得到教师网络的参数,根据教师网络的参数确定教师网络模型。
[0132]
可选地,步骤s500包括步骤s511-s514:
[0133]
s511、将训练样本输入至教师网络模型,得到预测标签。
[0134]
可选地,通过教师网络模型对学生网络进行蒸馏学习,在蒸馏学习过程中,将训练样本输入至教师网络模型,在高温t(例如t=10)下产生soft labels(预测标签),预测标签包含i类别在温度系数t下的softmax概率qi,计算过程如公式(21):
[0135][0136]
其中,i表示任一类别,zi表示类别i的logit输出,即全连接层后的输出。
[0137]
s512、将训练样本输入至学生网络,以在第一温度下得到第一预测结果以及在第二温度下得到第二预测结果。
[0138]
同时,在蒸馏学习过程中,将训练样本输入至学生网络,学生网络为轻量化模型light_envsound_model,使得在第一温度t=10下得到soft prediction(第一预测结果),以及使得在第二温度t=1下得到hard prediction(第二预测结果)。
[0139]
如图3所示,可选地,学生网络由4个特征提取块env_block和多个池化层以及全连接层组成,前3个env_block中,每一个后面都连接一个最大池化层(max_pooling),每个max_pooling的卷积核大小均设置为2*2,第4个env_block层后面连接一个全局平均池化层(global_avg_pooling)。其中,4个env_block特征提取块中的输出通道数分别设置为8、16、32、64,在经过特征块的提取之后,得到的特征输入到两个全连接层(full_connect),第一个全连接层的输出神经节点数为128,第二个全连接的输出神经节点数设置为具体的环境声类别数(class_nums),即输出soft prediction(第一预测结果)。
[0140]
可选地,特征提取块env_block的结构如图4所示,输入特征input分为左右两条支路流动,左支路的第一个部分是卷积核大小为1*1、输出通道数为输入通道数6倍的卷积层,连接一个批标准化层(bn)和激活函数(relu);第二部分为一个depth_block卷积块,第三部分是卷积核大小为1*1、输出通道数为目标输出通道数的卷积层,连接一个批标准化层(bn)和激活函数(relu)。而右支路为一个空间注意力块spaceatt_block。特征分别流经左右支路后分别得到两个相同尺寸的特征图,将它们逐点相乘之后的结果作为特征输出output。
[0141]
其中,depth_block卷积块的结构如图5所示,其分为两个部分,第一部分是卷积核大小为3*3、卷积核个数与输入通道数相等的分组卷积层,分组数与输入通道数相同,后面再接一个批标准化层(bn)和激活函数relu;第二部分是一个卷积核大小为1*1、卷积核个数为目标输出通道数的卷积层,后面同样接一个批标准化层(bn)和激活函数relu,输出output。空间注意力块spaceatt_block的结构如图6所示,输入数据分别经过左右支路处理后再沿着通道维度进行拼接,最后经由一个卷积核大小为7*7、卷积核个数为1的卷积层卷积后,在激活函数sigmoid的作用下输出,其中左右支路分别具有通道维度的最大池化层max_pooling和平均值化层avg_pooling。
[0142]
s513、根据第一预测结果以及预测标签计算蒸馏损失,根据第二预测结果以及真实标签计算学生损失,计算蒸馏损失与第一权重的第一乘积并计算学生损失与第二权重的第二乘积,根据第一乘积以及第二乘积的和确定损失值。
[0143]
可选地,根据第一预测结果以及预测标签计算交叉熵得到distillation loss(蒸馏损失)记为l
soft
,根据第二预测结果以及真实标签(hard labels)计算交叉熵,得到学生
可以表示:只存在a,只存在b以及同时存在a和b三种情况,其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”,其中a,b,c可以是单个,也可以是多个。
[0157]
在本技术所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0158]
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括多指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,简称rom)、随机存取存储器(random access memory,简称ram)、磁碟或者光盘等各种可以存储程序的介质。
[0159]
以上,以上实施例仅用以说明本技术的技术方案,而非对其限制;本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。