1.本发明涉及药物推荐领域,尤其是一种肿瘤靶向药物推荐方法及系统。
背景技术:
2.癌症作为目前对于人类健康威胁最为严重的疾病之一,众多的医务工作者们都在想方设法将这一问题攻克。目前临床上对于肿瘤的治疗方式主要有手术、放疗、化疗等,但由于肿瘤发病机制复杂,个体差异因素大,所以治疗效果也因人而异,整体效果不容乐观。近年来,随着“靶向药物”技术的进步,越来越多的病人开始从中获益,不仅有效地延长了整体生存期,生活质量也得到了明显的改善。而这几年,随着“精准医疗”的概念被越来越多的倡导,以基因检测技术为指导的使用靶向药物的治疗方式正在被更多的临床医生所接受和使用,并为患者带去更合适的治疗方式以及更好的治疗效果。
3.肾盂癌(renal pelvis carcinoma,rpc)是指发生于肾盂部位的恶性肿瘤,在泌尿系统肿瘤中发病率相对较低,占所有尿路上皮肿瘤的10%左右。由于肾盂位置较深,所以很难在术前进行活体检查,因此ct尿路成像(ctu rography,ctu)已成为术前临床医生确诊肾盂癌患者最重要的依据。对于术前诊断为肾盂癌的患者,将会进行肾输尿管切除术(radical nephroureterectomy,rnu)并给予术后辅助化疗。另一方面,目前许多医生提倡对于身体情况允许的患者使用新辅助化疗疗法,即在术前对患者进行化疗处理,然后根据具体情况决定维持治疗或继而进行手术。总体来讲,无论是手术还是化疗,都会对患者身体造成较大创伤或非特异性损伤,并且由于肾盂位置较深,也无法取出肿瘤样本进行活体检查。因此,如何在无法获取肿瘤活体样本的情况下,精准判定出适合患者个体化病情的肿瘤靶向药物是当前肾盂癌治疗中难以解决的问题。
技术实现要素:
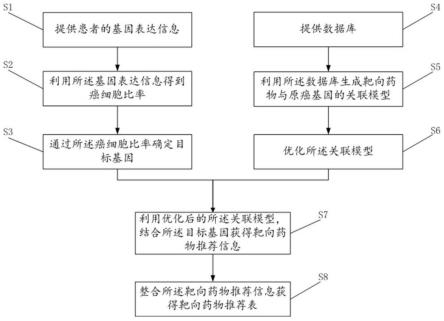
4.针对现有技术中存在的问题,第一方面,本发明提供了一种肿瘤靶向药物推荐方法,包括如下步骤:提供患者的基因表达信息,所述基因表达信息包括基因表达数据和基因表达类别,所述基因表达数据包括不同的原癌基因及其表达值;利用所述基因表达信息得到癌细胞比率;通过所述癌细胞比率确定目标基因;提供数据库,所述数据库包括靶向药物信息;利用所述数据库生成靶向药物与原癌基因的关联模型;优化所述关联模型;利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息,所述靶向药物推荐信息包括所述靶向药物的推荐强度;整合所述靶向药物推荐信息获得靶向药物推荐表。本方法将肾盂癌患者自身的基因表达信息作为基础,通过计算获得癌细胞比率进而确定目标基因,再通过目标基因与当下的靶向药物的精准匹配,能够在无法获取癌变组织活体样本的情况下,精准判定并推荐出适合肾盂癌患者个体化病情的肿瘤靶向药物。同时,本方法不仅适用于肾盂癌的无创检查,也可为其它无法或较难活检的癌种的术前新辅助疗法的探索提供参考和依据。
5.可选地,所述利用所述基因表达信息得到癌细胞比率,包括如下步骤:在不同的所
述原癌基因的基因表达数据中随机选取n个数据作为初始中心点;将所述基因表达数据与所述初始中心点进行比较;根据比较的结果,结合所述基因表达类别,将所述基因表达数据分为过度表达组和正常表达组;分别利用在所述过度表达组和所述正常表达组中的所述基因表达数据,通过求取均值重新定义初始中心;利用重新定义的初始中心,结合所述基因表达数据再次对所述基因表达数据进行分类,获得唯一满足误差阈值的所述原癌基因的过度表达组n1和正常表达组n2;通过所述过度表达组n1和所述正常表达组n2,获得由所述原癌基因致使的癌细胞比率。本方法以同一终止条件筛选出不同原癌基因的过度表达组n1和正常表达组n2,提升了计算效率。
6.可选地,所述误差阈值满足如下公式:
[0007][0008]
其中,i=1,2;k=2,k表示分类表达的分类数目,即过度表达组n1和正常表达组n2;μi表示ni中所述基因表达数据的均值;σ表示所述基因表达数据的标准差。
[0009]
可选地,所述癌细胞比率满足如下公式:
[0010][0011]
其中,η表示所述癌细胞比率,num(n2)表示所述过度表达组n2的组别中的细胞数目,num(n1 n2)表示所述正常表达组n1和所述过度表达组n2中细胞数目总和。
[0012]
可选地,所述利用所述数据库生成靶向药物与原癌基因的关联模型,包括如下步骤:从所述数据库中提取特征词;定义关联属性,所述关联属性包括靶向药物的名称、靶基因和药理作用方式;利用所述关联属性分类并标记所述特征词;设计统一化规则;利用所述统一化规则对分类后的所述特征词进行统一化;依据统一化后的所述特征词和所述关联属性构建关联结构;设定筛选条件;利用所述关联结构,结合所述筛选条件生成关联模型。本方法利用包括有靶向药物信息的数据库,通过提取特征值生成关联模型,从而精准地得到靶基因过度表达时对应的靶向药物。
[0013]
可选地,所述关联结构包括:a
t
b ci,其中,a表示癌症类型,t=1,2,
…
,n,不同角标t对应着不同的所述癌症类型,b表示目标基因,ci表示针对a
t
的靶向药物,i=1,2,
…
,n,不同角标i对应着不同的所述靶向药物。
[0014]
可选地,所述筛选条件包括:所述癌症类型a是由于所述目标基因b过度表达导致;所述靶向药物c用于抑制所述目标基因b过度表达所导致的非生理活性。通过设定筛选条件从而针对性地获得药用机理为抑制基因过度表达所导致的非生理活性的靶向药物。
[0015]
可选地,所述关联模型包括:a
t
b’ c
′i和a
t
b’ na,其中, a表示癌症类型,t=1,2,
…
,n,不同角标t对应着不同的所述癌症类型,b’表示过度表达的目标基因;c
′i表示抑制所述目标基因b过度表达所导致的非生理活性的靶向药物,i=1,2,
…
,n,不同角标i对应着不同的所述靶向药物,na表示针对于目标基因b过度表达没有对应的靶向药物。
[0016]
可选地,所述优化所述关联模型,包括如下步骤:统计所述特征词的词频;利用所述词频设计所述统一化规则;所述统一化规则包括:当不同的特征词代表相同含义时,提取词频最高的特征词作为统一化后的特征词;将剩余特征词映射为词频最高的所述特征词。通过规整特征词消除了相同含义的特征词的表达多样性,降低错误匹配概率,从而缩减整体运算的误差并优化关联模型,使得本方法更具实用性。
[0017]
可选地,所述利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息,包括如下步骤:通过所述统一化规则获得特征词相似度;结合所述特征词相似度,将所述目标基因统一化;利用统一化后的所述目标基因,通过所述关联模型匹配获得推荐靶向药物的名称;根据所述推荐靶向药物的名称在所述数据库中提取靶向药物推荐信息。利用特征词相似度消除了由于目标基因名称多样性导致匹配错误的概率,同时利用统一化后的所述目标基因结合所述关联模型进行匹配,提升了匹配效率与精准度。
[0018]
可选地,所述整合所述靶向药物推荐信息获得靶向药物推荐表,包括如下步骤:利用所述癌细胞比率对所述目标基因排序,获得第一排序结果;利用所述推荐强度对所述推荐靶向药物排序,获得第二排序结果;结合第一排序结果和第二排序结果生成靶向药物推荐表。通过整合靶向药物推荐信息获得靶向药物推荐表,有助于靶向药物推荐信息的可视化显示。
[0019]
第二方面,本发明还提供一种肿瘤靶向药物推荐系统,所述系统适用于所述肿瘤靶向药物推荐方法,包括:第一单元、第二单元、第三单元和第四单元;所述第一单元用于提供患者的基因表达信息,利用所述基因表达信息得到癌细胞比率,并通过所述癌细胞比率确定目标基因;所述第二单元用于提供数据库,所述数据库包括靶向药物信息,利用所述数据库生成靶向药物与原癌基因的关联模型,并优化所述关联模型;所述第三单元用于利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息,所述靶向药物推荐信息包括所述靶向药物的推荐强度;所述第四单元用于整合所述靶向药物推荐信息获得靶向药物推荐表。本系统通过四个功能单元相互作用,结合所述肿瘤靶向药物推荐方法,能够快速、精准地判定并推荐出适合患者个体化病情的肿瘤靶向药物。
[0020]
第三方面,本发明还提供一种肿瘤靶向药物推荐系统,包括输入设备、处理器、存储器和输出设备,所述输入设备、所述处理器、所述存储器和所述输出设备相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行所述肿瘤靶向药物推荐方法。本系统结构紧凑,适用性强,极大程度地提高了运行效率,为结合所述肿瘤靶向药物推荐方法,实现适合患者个体化病情的肿瘤靶向药物推荐提供了一个实体系统模型。
附图说明
[0021]
图1为本发明肿瘤靶向药物推荐方法流程图;
[0022]
图2为本发明混合尿路上皮细胞亚群的原癌基因表达散点图;
[0023]
图3为本发明混合尿路上皮细胞亚群中不同原癌基因分类结果示意图;
[0024]
图4为本发明混合尿路上皮细胞亚群中癌细胞比率示意图。
具体实施方式
[0025]
下面将详细描述本发明的具体实施例,应当注意,这里描述的实施例只用于举例说明,并不用于限制本发明。在以下描述中,为了提供对本发明的透彻理解,阐述了大量特定细节。然而,对于本领域普通技术人员显而易见的是:不必采用这些特定细节来实行本发明。在其他实例中,为了避免混淆本发明,未具体描述公知的电路,软件或方法。
[0026]
在整个说明书中,对“一个实施例”、“实施例”、“一个示例”或“示例”的提及意味
着:结合该实施例或示例描述的特定特征、结构或特性被包含在本发明至少一个实施例中。因此,在整个说明书的各个地方出现的短语“在一个实施例中”、“在实施例中”、“一个示例”或“示例”不一定都指同一实施例或示例。此外,可以以任何适当的组合和、或子组合将特定的特征、结构或特性组合在一个或多个实施例或示例中。此外,本领域普通技术人员应当理解,在此提供的示图都是为了说明的目的,并且示图不一定是按比例绘制的。
[0027]
请参阅图1,在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,包括如下步骤:s1、提供患者的基因表达信息;详细地,所述基因表达信息包括基因表达数据和基因表达类别,所述基因表达数据包括不同的原癌基因及其表达值。
[0028]
在本实施例中,以肾盂癌患者为例,所述提供患者的基因表达信息,包括如下步骤:采集肾盂癌患者的晨尿样本;利用uf-5000尿液分析仪对晨尿样本中细胞进行分类;统计细胞群体,获得细胞群体的数目和每个细胞群体中的细胞总数;将细胞群体的数目和细胞群体中的细胞总数与检测标准进行比较,当满足检测标准时获得检测样本,其中,检测标准根据实际情况确定;对检测样本测序,从而获得检测样本的细胞表达谱,具体可以采用单细胞rna测序技术获得检测样本的细胞表达谱;利用细胞表达谱,获得混合尿路上皮细胞亚群的细胞表达谱数据,混合尿路上皮细胞亚群包括正常尿路上皮细胞和癌变尿路上皮细胞;从混合尿路上皮细胞亚群的细胞表达谱数据中提取不同的原癌基因的基因表达数据,请参见图2,图2为混合尿路上皮细胞亚群的原癌基因表达散点图,其中,原癌基因包括alk、egfr、 fgfr2、flt3、her2、insr、kit、ntrk1、pdgfra、pd-l1、 pik3ca和src,纵坐标表示对应基因的表达值,横坐标表示细胞数目。
[0029]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s2、利用所述基因表达信息得到癌细胞比率。
[0030]
详细地,在本实施例中,所述利用所述基因表达信息得到癌细胞比率,包括如下步骤:在不同的所述原癌基因的基因表达数据中随机选取n个数据作为初始中心点;将所述基因表达数据与所述初始中心点进行比较;根据比较的结果,结合所述基因表达类别,将所述基因表达数据分为过度表达组和正常表达组分别利用在所述过度表达组和所述正常表达组中的所述基因表达数据,通过求取均值重新定义初始中心;利用重新定义的初始中心,结合所述基因表达类别再次对所述基因表达数据进行分类,获得唯一满足误差阈值的所述原癌基因的过度表达组n1和正常表达组n2,详细地,所述误差阈值满足如下公式:
[0031][0032]
其中,i=1,2;k=2,k表示分类表达的分类数目,即过度表达组n1和正常表达组n2;μi表示ni中所述基因表达数据的均值;σ表示所述基因表达数据的标准差;再通过所述过度表达组n1和所述正常表达组n2,获得由所述原癌基因致使的癌细胞比率,其中,所述癌细胞比率满足如下公式:
[0033][0034]
其中,η表示所述癌细胞比率,num(n2)表示所述过度表达组n2的组别中的细胞数目,num(n1 n2)表示所述正常表达组n1和所述过度表达组n2中细胞数目总和。本方法以同一终止条件筛选出不同原癌基因的过度表达组n1和正常表达组n2提升了计算效率。
[0035]
请参见图3和图4,在又一个可选的实施例中,利用上述混合尿路上皮细胞亚群的
原癌基因表达信息,结合s2步骤,获得了混合尿路上皮细胞亚群中不同原癌基因的癌细胞比率,其中图3为混合尿路上皮细胞亚群中不同原癌基因分类结果示意图,其中,标题为基因名称,横坐标表示细胞数目,纵坐标表示表达值,a线为总体最高表达值,b线为总体最低表达值,c线为总体截取线,c线上方为n1类别,下方为n2类别。当c线循环至最优位置时,总体拥有全局“最小的误差平方和”,即其中,|n1|、|n2|为类别所含样本的数目,σ2n1、σ2n2为类别所含样本的标准差的平方;图4表示混合尿路上皮细胞亚群的insr、met、braf、src、igf1r、egfr、 her2、pik3ca、ezh2、cdk6、bcl2、mst1r、pd-l1和fgfr1 的癌细胞比率示意图,其横坐标表示原癌基因类型,纵坐标表示原癌基因对应的癌细胞比率。
[0036]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s3、通过所述癌细胞比率确定目标基因。详细地,在本实施例中,根据原癌基因致使的癌细胞比率设定阈值范围,将癌细胞比率超过该阈值的原癌基因设定为目标基因。其中,根据实际情况,阈值范围的设定与癌症的类型以及原癌基因的致使的细胞突变速率相关,可根据相关实验的具体测试值进行针对性设定。
[0037]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s4、提供数据库,所述数据库包括靶向药物信息。详细地,所述数据库是通过已上市的靶向药物信息集合构建的,所述靶向药物信息包括靶向药物针对的目标基因、药品说明和药理作用,所述药品说明包括治疗靶基因过度表达,所述药理作用包括抑制靶基因过度表达所导致的非生理活性。具体地,her2的蛋白分子量约为 185kd,是一种定位于细胞膜的跨膜蛋白。her2属于酪氨酸激酶偶联型受体,由胞外的配体p结合结构域、单链跨膜结构域及胞内的酪氨酸激酶结构域三部分组成。正常生理状态下,her2胞外的配体p 结合结构域能够结合外环境中的配体p(生长因子),继而导致胞内的酪氨酸激酶结构域发生构象的改变,这种情况下,酪氨酸激酶结构域会结合细胞内的atp,然后以atp为磷酸基团供体,使其下游底物蛋白(ras)的酪氨酸位点发生磷酸化修饰,通过蛋白的相互作用激活底物蛋白的功能,使得胞外的生长信号传递到细胞内部,再通过下游不同信号因子的逐级传递,最终调控细胞的增殖(cell proliferation) 过程。而在病理状态下,细胞由于未知原因发生her2的过度表达,这些蛋白会在配体p的作用下过度传递生长信号,使得细胞非受控的大量增殖,最终导致肿瘤的发生与发展。曲妥珠单抗q是her2的人源化单克隆抗体,它对her2具有非常强的结合能力,它能够在 her2配体p存在的情况下,竞争性地结合到her2胞外的配体结合结构域,即封闭了her2的配体结合位点。而结合有曲妥珠单抗q 的her2的胞内酪氨酸激酶结构域不会发生构象上的改变,继而无法完成生长信号的传递过程,细胞的增殖受到抑制,最终使得肿瘤患者受益。
[0038]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s5、利用所述数据库生成靶向药物与原癌基因的关联模型;详细地,所述原癌基因包括但不限于目标基因。
[0039]
详细地,在本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,包括如下步骤:从所述数据库中提取特征词。具体地,在数据库中提取特征词为现有技术,此处不具体展开解释。
[0040]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:定义关联属性,所述关联属性包括靶向药物的名称、靶基因和药理作
用方式。在本实施例中,关联属性用于对特征词进行分类的,在任意一个关联属性下包括一个或者多个特征词。具体地,在本实施例中,如靶向药物的名称包括阿法替尼、奥西替尼、西妥昔单抗、帕尼单抗、耐昔妥珠单抗等特征词;靶基因包括insr、met、braf、src、igf1r、egfr、her2、pik3ca、 ezh2、cdk6、bcl2等特征词;药理作用方式包括抑制靶基因表达、抑制insr活性等特征词。
[0041]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:利用所述关联属性分类并标记所述特征词。在本实施例中,任意一个特征词对应唯一一个关联属性,具体地,如他泽司他的关联属性为靶向药物的名称,肾盂癌、乳腺癌、前列腺癌、结直肠癌的关联属性为癌症类型。
[0042]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:设计统一化规则,并利用所述统一化规则对分类后的所述特征词进行统一化。在本实施例中,即 fgfr1、fgfr2、fgfr3和fgfr4统一化为fgfr,即统一化规则消除了相同含义的特征词的表达多样性,降低错误匹配概率,从而缩减整体运算的误差并优化关联模型,使得本方法更具实用性。
[0043]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:依据统一化后的所述特征词和所述关联属性构建关联结构,其中,所述关联结构包括:a
t
b ci,其中,a表示癌症类型,t=1,2,
…
,n,不同角标t对应着不同的所述癌症类型,b表示目标基因,ci表示针对a的靶向药物,i=1,2,
…
,n,不同角标i对应着不同的所述靶向药物。具体地,在本实施例中,所述关联结构可以为:胃癌 egfr 阿法替尼;胃癌 egfr 奥西替尼;胃癌 egfr 西妥昔单抗;肺癌 egfr 阿法替尼;肺癌 egfr 帕尼单抗等,相当于特征词的随机匹配。
[0044]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:设定筛选条件,在本实施例中,所述筛选条件包括:所述癌症类型a是由于所述目标基因b过度表达导致;所述靶向药物c用于抑制所述目标基因b过度表达所导致的非生理活性。通过设定筛选条件,即设定匹配的规则,从而针对性地获得药用机理为抑制基因过度表达所导致的非生理活性的靶向药物。
[0045]
在又一个本实施例中,所述利用所述数据库生成靶向药物与原癌基因的关联模型,还包括如下步骤:利用所述关联结构,结合所述筛选条件生成关联模型;详细地,所述关联模型包括:a
t
b’ c
′i和 a
t
b’ na,其中,a表示癌症类型,t=1,2,
…
,n,不同角标t对应着不同的所述癌症类型,b’表示过度表达的目标基因;c
′i表示抑制所述目标基因b过度表达所导致的非生理活性的靶向药物, i=1,2,
…
,n,不同角标i对应着不同的所述靶向药物,na表示针对于目标基因b的过度表达没有对应的靶向药物。具体地,在本实施例中,所述关联模型可以为:肾盂癌 egfr 阿法替尼,肾盂癌 aeg1 na等,相当于获得了符合匹配规则的关联模型。
[0046]
综上,本方法的s5步骤利用装载有靶向药物信息的数据库,通过提取特征词生成关联模型,通过设定筛选条件从而针对性筛选出药用机理为抑制基因过度表达所导致的非生理活性的靶向药物。
[0047]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s6、优化所述关联模型。
[0048]
详细地,所述优化所述关联模型,包括如下步骤:统计所述特征词的词频;利用所述词频设计所述统一化规则;所述统一化规则包括:当不同的特征词代表相同含义时,提取词频最高的特征词作为统一化后的特征词;将剩余特征词映射为词频最高的所述特征词。具体地,在本实施例中,所述词频表征特征词在数据库中被出现的频率;通过规整特征词消除了相同含义的特征词的表达多样性,降低错误匹配概率,从而缩减整体运算的误差并优化关联模型,使得本方法更具实用性。
[0049]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s7、利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息。
[0050]
详细地,所述利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息,包括如下步骤:通过所述统一化规则获得特征词相似度,即s6步骤中,其余的特征词与词频最高的特征词之间的相似程度,具体地,所述相似程度可以通过字符的一致程度和/或字符序列的一致程度来表征,如fgfr1、fgfr2、fgfr3和fgfr4统一称为fgfr,其中可通过fgfr1与fgfr字符的一致程度和/或字符序列的一致程度来判定,具体的表征参数根据实际情况进行设定;结合所述特征词相似度,将所述目标基因的统一化;利用统一化后的所述目标基因,通过所述关联模型匹配获得推荐靶向药物的名称;根据所述推荐靶向药物的名称在所述数据库中提取靶向药物推荐信息,详细地,所述靶向药物推荐信息包括所述靶向药物的推荐强度,该推荐强度正相关于癌细胞比率的大小。利用特征词相似度消除了由于目标基因名称多样性导致匹配错误的概率,同时利用统一化后的所述目标基因结合所述关联模型进行匹配,提升了匹配效率与精准度。
[0051]
在一个可选地实施例中,本发明的一种肿瘤靶向药物推荐方法,还包括如下步骤:s8、整合所述靶向药物推荐信息获得靶向药物推荐表。详细地,所述整合所述靶向药物推荐信息获得靶向药物推荐表,包括如下步骤:利用所述癌细胞比率对所述目标基因排序,获得第一排序结果;利用所述推荐强度对所述推荐靶向药物排序,获得第二排序结果;结合第一排序结果和第二排序结果生成靶向药物推荐表。通过整合靶向药物推荐信息获得靶向药物推荐表,有助于靶向药物推荐信息的可视化显示。
[0052]
请参见表1,在一个可选地实施例中,利用上述混合尿路上皮细胞亚群的原癌基因表达信息,结合步骤s2-s8获得了该肾盂癌患者个性化用药参考列表,具体内容如表1所示:
[0053][0054]
表1中依据原癌基因的排序结果,将原癌基因与对应的靶向药物作为整体,重新依次列表,并将推荐强度最高的靶向药物判定为该肾盂癌患者采取新辅助治疗策略时的首选
靶药,表1中显示针对该肾盂癌患者排名前6位的推荐靶向药物。
[0055]
综上,本方法通过患者自身的基因表达信息,计算获得癌细胞比率从而确定目标基因,通过目标基因与对当下靶向药物的精准匹配,实现了在无法获取癌变组织活体样本的情况下,精准判定并推荐出适合患者个体化病情的肿瘤靶向药物。另一方面,本方法不仅适用于肾盂癌的无创检查,同时也可以为其他由于原癌基因过度表达而致使的癌症的术前新辅助治疗策略提供参考和依据,降低了对患者身体造成较大创伤或非特异性损伤的风险。
[0056]
本发明还提供一种肿瘤靶向药物推荐系统,所述系统适用于所述肿瘤靶向药物推荐方法,包括:第一单元、第二单元、第三单元和第四单元;所述第一单元用于提供患者的基因表达信息,利用所述基因表达信息得到癌细胞比率,并通过所述癌细胞比率确定目标基因;所述第二单元用于提供数据库,所述数据库包括靶向药物信息,利用所述数据库生成靶向药物与原癌基因的关联模型,并优化所述关联模型;所述第三单元用于利用优化后的所述关联模型,结合所述目标基因获得靶向药物推荐信息,所述靶向药物推荐信息包括所述靶向药物的推荐强度;所述第四单元用于整合所述靶向药物推荐信息获得靶向药物推荐表。本系统通过四个功能单元相互作用,结合所述肿瘤靶向药物推荐方法,快速、精准地判定并推荐出适合患者个体化病情的肿瘤靶向药物。
[0057]
本发明还提供一种肿瘤靶向药物推荐系统,包括输入设备、处理器、存储器和输出设备,所述输入设备、所述处理器、所述存储器和所述输出设备相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行所述肿瘤靶向药物推荐方法。本系统结构紧凑,适用性强,不仅为结合所述肿瘤靶向药物推荐方法、实现适合患者个体化病情的肿瘤靶向药物推荐提供了一个实体系统模型,在保证了运行速度与效率地同时,也提升了本发明的实用性和扩展性。
[0058]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
