1.本发明属于电子对抗技术领域,尤其涉及一种基于深度强化学习的联合跳频和脉宽分配的雷达抗干扰决策方法。
背景技术:
2.雷达对抗作为电子对抗领域中重要的一部分,是现代信息化战争的重要环节,敌方可以采用扫频干扰、梳状谱干扰等干扰方式对雷达使用的电磁波谱进行干扰。在这种情况下,雷达无法接收信息信号或者可能被欺骗性信息误导。此外,干扰机还可能通过感知环境分析雷达的抗干扰策略,发动更加复杂多样的智能干扰。因此,智能自适应雷达抗干扰技术的研究在电子战领域具有重要的意义。
3.频率捷变和增加脉冲宽度是两种常用的雷达抗干扰技术。雷达可以在多个发射脉冲之间改变载波频率,从而在不同频率点之间跳变。由于干扰信号的功率有限,且主要集中在某些频率点,雷达可以通过改变脉冲频率来有效对抗干扰机。以外,雷达还可以通过产生更宽的发射脉冲来增加平均发射功率,提高回波能量,增大信干噪比。随着人工智能的发展,干扰器的多样性、动态性、智能化等新趋势对雷达抗干扰技术提出了更高的要求。
技术实现要素:
4.发明目的:针对上述现有的雷达抗干扰决策存在的不足,本发明提供一种基于深度强化学习的联合自适应跳频和脉宽分配的雷达抗干扰智能决策方法,以得到最优的决策结果。频率捷变雷达携带一个智能体,使用深度强化学习算法做出抗干扰决策,根据决策选择最优的发射频率和脉冲宽度,可以有效地应对多样性的干扰,并提高了回波处理的积分效率和多普勒频率分辨率。
5.技术方案:为达到上述目的,本发明提供一种基于深度强化学习的联合自适应跳频和脉宽分配的雷达抗干扰智能决策方法,该方法包括如下步骤:
6.步骤1)构建雷达抗干扰系统模型;
7.步骤2)基于系统模型中的雷达发射频率和脉冲宽度参数,计算雷达接收回波信号的信干噪比;
8.步骤3)使用深度强化学习实现抗干扰策略,根据雷达接收回波信号的信干噪比信息确定雷达状态、动作选择、立即奖励值,通过计算深度强化学习算法中的损失函数更新神经网络的参数;
9.步骤4)使用动态ε贪婪算法进行动作选择,迭代训练不断更新神经网络的参数,判断学习机制是否满足预设的停止条件,若满足,则停止学习得到最后抗干扰策略。
10.进一步的,步骤1)的具体方法如下:
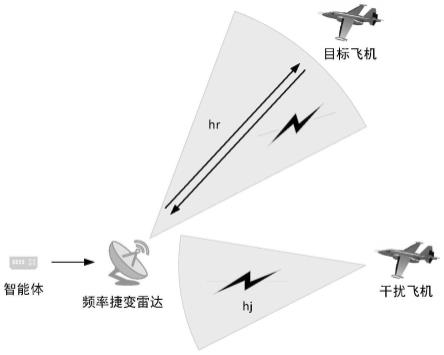
11.步骤1.1)构建一个雷达抗干扰系统模型,该模型包括一个频率捷变雷达、一架目标飞机和一架干扰机,雷达以固定的脉冲重复间隔发射脉冲序列对目标飞机进行探测,每
个脉冲序列中包含n个脉冲,脉冲序列的持续时间由若干个相干处理间隔组成,每个相干处理间隔中脉冲的载波频率和脉宽保持不变,雷达的每个脉冲可以在不同的频率点之间跳变,在m个可用频率中任意选择频率跳变点,雷达频率集表示为f={f1,f2,...,fm},频率集f中的第i个频率点表示为fi=f
i-1
δf,i∈{2,3,...m},其中,δf为固定频率步长,雷达有w个不同的发射脉冲宽度,脉宽集合表示为γ={τ1,τ2,...,τw},τ1<τ2<
…
<τw,其中,脉宽τn对应的脉冲功率为pn∈p={p1,p2,...,pw},p1<p2<
…
<pw,脉宽越宽对应的脉冲功率越高;
12.步骤1.2)雷达以中心频率fn向目标飞机发射脉宽为τn的脉冲信号进行探测,干扰机和目标飞机采取不同的干扰方式对雷达进行干扰,雷达设置有智能体,智能体根据雷达当前的状态信息,使用深度强化学习算法做出抗干扰决策,并指导雷达选择最优的发射频率和脉冲宽度。
13.进一步的,步骤2)的具体方法如下:
14.步骤2.1)处理雷达回波信号时,使用多个子匹配滤波器实现相干处理,利用快速傅里叶变换对一组相干脉冲回波进行相干积分,在第i个子匹配滤波器获得的雷达多普勒频率分辨率为:
[0015][0016]
其中,λi为雷达信号的波长,t
cp
为相干积分器的积分时间,当雷达的跳频率低于预设阈值时,每个相干处理间隔中包含更多的脉冲,从而可以提高积分效率和多普勒频率分辨率;
[0017]
步骤2.2)雷达的接收信号中包括脉冲回波信号、两种干扰信号以及高斯白噪声,频率捷变雷达接收的第n个脉冲的信干噪比定义如下:
[0018][0019]
其中,pn表示雷达发射脉冲的功率,hr表示雷达到目标飞机的信道增益,σ表示雷达散射截面,表示噪声的功率,p
t
表示目标飞机产生的干扰信号的功率,pj表示干扰机产生的干扰信号的功率,hj表示干扰机到雷达的信道增益,fn表示雷达脉冲的中心频率,f
t
表示目标飞机产生的干扰信号的中心频率,fj表示干扰机产生的干扰信号的中心频率,fn,f
t
,fj∈f={f1,f2,...,fm},f
t
=fn表示雷达脉冲的中心频率与干扰信号的中心频率相同,i(x)为指示函数,如果x为真则为1,否则为0;设置阈值μ,当雷达接收的第n个脉冲的信干噪比sinrn大于μ时,表示探测成功,否则探测失败。
[0020]
进一步的,步骤3)的具体方法如下:
[0021]
步骤3.1)使用深度强化学习算法实现抗干扰策略,雷达状态sn包括两个分量,表示为一个1
×
2的二维矩阵sn=[a
n-1
,r
n-1
],其中,a
n-1
表示上一个子脉冲的动作选择,r
n-1
表示上一时隙的动作奖励值,动作an也包括两个分量,表示为一个1
×
2的二维矩阵an=[fn,pn],其中,fn表示雷达脉冲的中心频率,fn∈f={f1,f2,...,fm},pn为脉冲功率,pn∈p={p1,p2,...,pw},状态转移概率表示为p:(sn,an)
→sn 1
,指的是雷达在状态sn下执行动作an后转移到状态s
n 1
的转移概率,立即奖励值定义为rn=r
(n)
·
i(sinrn≥μ)-c
·
i(f
n-1
≠fn),其中,
c为跳频成本,r
(n)
为雷达发射脉宽τn时获得的奖励值,sinrn为信干噪比,μ为设定的阈值;
[0022]
步骤3.2)建立两个神经网络,一个是权值参数为θ的策略神经网络,另一个是权值参数为θ-的目标神经网络,并初始化权值参数,将雷达状态sn作为神经网络的输入,经过三个全连接层得到最终的输出值,即动作an,q函数表示为:
[0023][0024]
其中,rn为立即奖励值,γ是折扣因子,s
n 1
是雷达在状态sn下采取动作an的下一个状态,a
′
为目标网络所选动作,每个时间步长n的经验en=(sn,an,rn,s
n 1
)被存储在经验回放池dn=(e1,...,en)中,即将数组en存放入集合dn中,且通过随机选择均匀分布e~u(dn)中的元素,得到机器学习的目标值:
[0025][0026]
其中,rn为立即奖励值,是第i次迭代时目标q网络的参数,当输入为sn时,目标q网络的输出为ηi,第i次迭代时策略q网络的参数为θi,目标值与策略q网络的实际输出的均方误差作为损失函数:
[0027][0028]
其中,为目标网络的q函数,为策略网络的q函数,为目标网络的参数,θi为策略网络的参数,损失函数的梯度为:
[0029][0030]
其中,ηi为机器学习的目标值,使用梯度下降法对策略网络的参数进行更新。
[0031]
进一步的,步骤4的具体方法如下:
[0032]
步骤4.1)在训练阶段,根据状态sn,智能体采用动态ε-greedy算法选择动作an,即在每次迭代时随机选择动作an的概率为ε,而选择令策略网络q
policy
最大的动作an=argmaxaq
policy
(sn,a;θi)的概率为1-ε,其中,ε0为初始概率,i为迭代次数,decay为衰减参数,概率ε随着迭代次数的增加以指数级别降低,并将样本en=(sn,an,rn,s
n 1
)存入经验回放池dn,经验回放池dn满了之后,用新的样本根据先进先出的原则更新经验回放池;
[0033]
步骤4.2)在经验回放池dn中元素数量大于预设值后,从dn中随机选择个样本其中ek~u(dn)表示随机变量ek服从dn上的均匀分布。通过梯度下降算法进行策略网络的参数θi迭代更新,每迭代设定值c次后,将策略网络的参数复制用来更新目标网络的参数重复以上过程直到达到最大迭代次数;
[0034]
步骤4.3)训练结束后,将状态sn输入策略网络计算得到输出q(sn,a;θ),选取最大q值对应的动作,执行该动作即可,不需要再继续迭代更新网络参数。
[0035]
有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果:
[0036]
(1)联合自适应跳频和脉宽分配,提高了雷达系统的抗干扰性能。雷达选择受干扰可能性较小的频段进行探测,抗干扰性能优于传统的随机跳频方式。雷达还可以通过产生
更宽的发射脉冲增加平均发射功率,从而增加目标回波能量和信干噪比,提高回波处理的积分效率和多普勒频率分辨率。
[0037]
(2)雷达系统可以通过与环境交互学习抗干扰策略,并且只需要很少的先验信息。提出的深度强化学习算法不需要对干扰模式进行建模,自然具有探索未知环境的能力,可广泛用于对抗复杂的干扰方式。
[0038]
(3)使用了深度强化学习,同时采用了动态ε-greedy策略进行动作选择,相比于传统强化学习中固定ε值的贪婪算法,提升了学习速率,加快了算法的收敛速度。
附图说明
[0039]
图1为本发明的雷达抗干扰系统模型;
[0040]
图2为本发明深度强化学习的神经网络结构;
[0041]
图3为本发明的系统流程图;
[0042]
图4为本发明的dqn算法流程图;
[0043]
图5为本发明实施例中三种不同干扰模式下抗干扰模型的时频图;
[0044]
图6为本发明实施例中四种不同算法雷达探测成功率的对比图;
[0045]
图7为本发明实施例中三种不同层数神经网络的性能对比图;
[0046]
图8为本发明实施例中三种不同策略平均奖励值的对比图。
具体实施方式
[0047]
本发明提出一种基于深度强化学习的联合自适应跳频和脉宽分配的雷达抗干扰智能决策方法,将抗干扰问题建模为马尔可夫决策过程,携带智能体的雷达能够智能选择最优的发射频率和脉冲宽度,可以有效地应对多样性的干扰,具体包括以下步骤:
[0048]
步骤1)构建雷达抗干扰系统模型;
[0049]
步骤1.1)构建一个雷达抗干扰系统模型,该模型包括一个频率捷变雷达、一架目标飞机和一架干扰机,雷达以固定的脉冲重复间隔发射脉冲序列对目标飞机进行探测,每个脉冲序列中包含n个脉冲,脉冲序列的持续时间由若干个相干处理间隔组成,每个相干处理间隔中脉冲的载波频率和脉宽保持不变,雷达的每个脉冲可以在不同的频率点之间跳变,在m个可用频率中任意选择频率跳变点,雷达频率集表示为f={f1,f2,...,fm},频率集f中的第i个频率点表示为fi=f
i-1
δf,i∈{2,3,...m},其中,δf为固定频率步长,雷达有w个不同的发射脉冲宽度,脉宽集合表示为γ={τ1,τ2,...,τw},τ1<τ2<
…
<τw,其中,脉宽τn对应的脉冲功率为pn∈p={p1,p2,...,pw},p1<p2<
…
<pw,脉宽越宽对应的脉冲功率越高;
[0050]
步骤1.2)雷达以中心频率fn向目标飞机发射脉宽为τn的脉冲信号进行探测,干扰机和目标飞机采取不同的干扰方式对雷达进行干扰,雷达设置有智能体,智能体根据雷达当前的状态信息,使用深度强化学习算法做出抗干扰决策,并指导雷达选择最优的发射频率和脉冲宽度。
[0051]
步骤2)基于系统模型中的雷达发射频率和脉冲宽度参数,计算雷达接收回波信号的信干噪比;
[0052]
步骤2.1)处理雷达回波信号时,使用多个子匹配滤波器实现相干处理,利用快速
傅里叶变换对一组相干脉冲回波进行相干积分,在第i个子匹配滤波器获得的雷达多普勒频率分辨率为:
[0053][0054]
其中,λi为雷达信号的波长,t
cp
为相干积分器的积分时间,当雷达的跳频率低于预设阈值时,每个相干处理间隔中包含更多的脉冲,从而可以提高积分效率和多普勒频率分辨率;
[0055]
步骤2.2)雷达的接收信号中包括脉冲回波信号、两种干扰信号以及高斯白噪声,频率捷变雷达接收的第n个脉冲的信干噪比定义如下:
[0056][0057]
其中,pn表示雷达发射脉冲的功率,hr表示雷达到目标飞机的信道增益,σ表示雷达散射截面,表示噪声的功率,p
t
表示目标飞机产生的干扰信号的功率,pj表示干扰机产生的干扰信号的功率,hj表示干扰机到雷达的信道增益,fn表示雷达脉冲的中心频率,f
t
表示目标飞机产生的干扰信号的中心频率,fj表示干扰机产生的干扰信号的中心频率,fn,f
t
,fj∈f={f1,f2,...,fm},f
t
=fn表示雷达脉冲的中心频率与干扰信号的中心频率相同,i(x)为指示函数,如果x为真则为1,否则为0;设置阈值μ,当雷达接收的第n个脉冲的信干噪比sinrn大于μ时,表示探测成功,否则探测失败。
[0058]
步骤3)使用深度强化学习实现抗干扰策略,根据雷达接收回波信号的信干噪比信息确定雷达状态、动作选择、立即奖励值,通过计算深度强化学习算法中的损失函数更新神经网络的参数;
[0059]
步骤3.1)使用深度强化学习算法实现抗干扰策略,雷达状态sn包括两个分量,表示为一个1
×
2的二维矩阵sn=[a
n-1
,r
n-1
],其中,a
n-1
表示上一个子脉冲的动作选择,r
n-1
表示上一时隙的动作奖励值,动作an也包括两个分量,表示为一个1
×
2的二维矩阵an=[fn,pn],其中,fn表示雷达脉冲的中心频率,fn∈f={f1,f2,...,fm},pn为脉冲功率,pn∈p={p1,p2,...,pw},状态转移概率表示为p:(sn,an)
→sn 1
,指的是雷达在状态sn下执行动作an后转移到状态s
n 1
的转移概率,立即奖励值定义为rn=r
(n)
·
i(sinrn≥μ)-c
·
i(f
n-1
≠fn),其中,c为跳频成本,r
(n)
为雷达发射脉宽τn时获得的奖励值,sinrn为信干噪比,μ为设定的阈值;
[0060]
步骤3.2)建立两个神经网络,一个是权值参数为θ的策略神经网络,另一个是权值参数为θ-的目标神经网络,并初始化权值参数,将雷达状态sn作为神经网络的输入,经过三个全连接层得到最终的输出值,即动作an,q函数表示为:
[0061][0062]
其中,rn为立即奖励值,γ是折扣因子,s
n 1
是雷达在状态sn下采取动作an的下一个状态,a
′
为目标网络所选动作,每个时间步长n的经验en=(sn,an,rn,s
n 1
)被存储在经验回放池dn=(e1,...,en)中,即将数组en存放入集合dn中,且通过随机选择均匀分布e~u(dn)中的元素,得到机器学习的目标值:
[0063]
[0064]
其中,rn为立即奖励值,是第i次迭代时目标q网络的参数,当输入为sn时,目标q网络的输出为ηi,第i次迭代时策略q网络的参数为θi,目标值与策略q网络的实际输出的均方误差作为损失函数:
[0065][0066]
其中,为目标网络的q函数,为策略网络的q函数,为目标网络的参数,θi为策略网络的参数,损失函数的梯度为:
[0067][0068]
其中,ηi为机器学习的目标值,使用梯度下降法对策略网络的参数进行更新。
[0069]
步骤4)使用动态ε贪婪算法进行动作选择,迭代训练不断更新神经网络的参数,判断学习机制是否满足预设的停止条件,若满足,则停止学习得到最后抗干扰策略。
[0070]
步骤4.1)在训练阶段,根据状态sn,智能体采用动态ε-gteedy算法选择动作an,即在每次迭代时随机选择动作an的概率为ε,而选择令策略网络q
policy
最大的动作an=argmaxaq
policy
(sn,a;θi)的概率为1-ε,其中,ε0为初始概率,i为迭代次数,decay为衰减参数,概率ε随着迭代次数的增加以指数级别降低,并将样本en=(sn,an,rn,s
n 1
)存入经验回放池dn,经验回放池dn满了之后,用新的样本根据先进先出的原则更新经验回放池;
[0071]
步骤4.2)在经验回放池dn中元素数量大于预设值后,从dn中随机选择个样本其中ek~u(dn)表示随机变量ek服从dn上的均匀分布。通过梯度下降算法进行策略网络的参数θi迭代更新,每迭代设定值c次后,将策略网络的参数复制用来更新目标网络的参数重复以上过程直到达到最大迭代次数;
[0072]
步骤4.3)训练结束后,将状态sn输入策略网络计算得到输出q(sn,a;θ),选取最大q值对应的动作,执行该动作即可,不需要再继续迭代更新网络参数。
[0073]
实施例1
[0074]
本发明的实施例具体描述如下,系统仿真采用python的pytorch框架,系统模型包含一个频率捷变雷达、一架目标飞机和一架干扰机。雷达与干扰机的工作频段设定为3ghz~3.35ghz,信号带宽设置为20mhz,中心频率可以以δf=50mhz的步长变化。当脉冲宽度设置为τ1=40μs,τ2=80μs时,对应的脉冲功率分别为p1=10kw,p2=20kw,脉冲宽度对应的奖励值为r
(1)
=10,r
(2)
=5。雷达在一个脉冲序列内传输n=20个脉冲,可用载频数m=8。目标飞机的干扰信号功率为250w,干扰机的干扰信号功率为500w,噪声功率设置为1w,回波检测阈值设置为μ=7,信道增益设置为hr=hj=0.1,雷达散射截面σ=1,雷达跳频成本设置为c=2。其中,当雷达选择脉宽为τ2=80μs且雷达只受到目标飞机的干扰时,接收回波的信干噪比大于检测阈值,这种情况下雷达不受干扰。
[0075]
该实施例中我们考虑3种干扰模式,具体如下:
[0076]
(1)梳状干扰:干扰信号的中心频率固定为3ghz、3.1ghz和3.3ghz,干扰信号带宽为20mhz。
[0077]
(2)随机干扰:从频率集的m个频率中随机选择一个作为干扰信号的中心频率,干扰信号带宽为20mhz。
[0078]
(3)跟踪干扰:干扰机能够在一个脉冲内精准、迅速地复制雷达发射波形,并快速转发形成与目标类似的干扰信号,并在下一脉冲时向雷达发射干扰信号。
[0079]
图5是本发明实施例中三种干扰模式下抗干扰模型的时频图,图中横坐标表示时间(单位为一个脉冲重复间隔),纵坐标表示中心频率(单位为ghz)。图中干扰信号1是目标飞机向雷达发射的干扰信号,是随机干扰和跟踪干扰信号的组合,干扰信号2是干扰机向雷达发射的梳状干扰信号。可以看出经过迭代训练之后,智能体能够学习到干扰机的干扰策略,根据当前状态帮助雷达选择发射频率和脉宽,有效地实现了抗干扰的目的。
[0080]
图6为本发明实施例中三种干扰模式下雷达探测成功率的对比图,从图中可以看出,随着迭代次数的增加,雷达探测的成功率逐渐变大最后趋于收敛。相比于随机跳频、q学习算法和固定ε值的深度强化学习算法,本发明提出的dqn算法抗干扰效果明显更优,迭代训练2000次之后收敛,探测成功率达到0.9以上。
[0081]
图7为本发明实施例中三种不同层数神经网络的性能对比图,两层全连接神经网络最终的收敛值低于另外两种神经网络,而四层全连接神经网络的收敛速度慢于另外两种神经网络。所以,综合考虑收敛速度以及最终的收敛值,三层全连接神经网络的性能最好。
[0082]
图8为本发明实施例中不同跳频代价c的情况下,本发明提出的dqn算法、q学习算法和随机跳频算法的平均奖励值的对比图。从图中可以看出,尤其当跳频代价较高时,本发明提出的算法优于其它算法。这是因为本算法的抗干扰能力优于其它算法,并且考虑了跳频代价c的影响,可以在跳频和增加脉宽之间保持平衡。
[0083]
综上所述,本发明提出一种基于深度强化学习的联合自适应跳频和脉宽分配的雷达抗干扰智能决策方法,可以有效应对外部恶意干扰,并提高雷达回波处理的积分效率和多普勒频率分辨率。不同于传统的随机跳频策略,根据当前雷达的状态选择最优发射频率和脉冲宽度。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。