1.以下说明书涉及化学、药物和/或生物技术产品的生产过程。特别地,本技术的方面涉及在整体性能方法整体优化此类过程。
2.背景
3.化学、制药和/或生物技术产品的生产过程是复杂的过程,涉及将输入或成分转化为最终产品的非线性动力学。这种过程的一个例子是药物制造中的上游细胞培养。该过程的设计可能涉及关于最终药物产品(大规模)、如何调整过程以优化最终药物产品(中等规模)或确定最能做到这一点的细胞系(小规模)的考虑。在每种规模上,生物体、培养设备、试剂、物理条件和过程步骤的时间之间的相互作用决定了成功或失败;因此过程设计至关重要。
4.然而,确定如何最好地针对特定生物体、培养设备部件或试剂组执行生产过程具有挑战性,因为培养对驱动参数的响应通常是高度非线性的,并且调节生产过程的可能参数的空间很大。
5.传统上,对此类过程的优化集中在识别和优化,然后实现特定的设定点,即单个过程输出的目标值。这种简单化的方法低估了表征过程性能的不同因素之间的复杂相互作用。例如,最大化产品滴度并不一定会导致执行该过程的最佳方式。另外,在传统方法中,驱动过程结果的不同因素之间的复杂相互作用被低估了。
6.此外,传统上,可能来自理论假设和先前执行的关于过程的可用知识仅以基本方式被考虑,例如,为过程中涉及的物理和生物动力学的参数或模型选择先验值。例如,在实验设计(doe)中,通常先验地选择过程对驱动参数响应的形状(例如线性或二次)。
7.发明概述
8.本发明的一个目的是优化化学、药物和/或生物技术产品的生产过程,其中所述过程被认为是在其整体性和复杂性中的。特别地,一个目的是准确地考虑影响过程的执行和可能结果的多个因素,并适当地考虑表征过程性能的多个方面。在这种背景下,将关于过程的可用知识有效整合到优化程序中也是一个目的。
9.根据本发明的这些目的的实现在独立权利要求中阐述。本发明的进一步发展是从属权利要求的主题。
10.根据一个方面,提供了确定生产化学、药物和/或生物技术产品的生产过程的至少一种配方的计算机实现的方法。特别地,在生产过程在效用函数方面被优化的意义上,所确定的配方可以是最优配方,如下面将解释的。
11.根据本技术的过程的例子是工业过程,特别是生物制药过程。其他例子包括研究和开发过程或科学研究。
12.根据本技术的生产过程的输入或成分的例子可以包括生物材料,即包含生物系统的材料,如细胞、细胞成分、细胞产物和其他分子,以及来源于生物系统的材料,如蛋白质、抗体和生长因子。其他成分可以包括化合物和各种底物。
13.输入的例子可以包括气体和液体。气体包括空气、氧气、氮气、富氧空气和二氧化
碳中的任何一种或全部。液体通常是:
[0014]-培养基(缓冲液中的营养混合物,例如葡萄糖 氨基酸 盐 水)
[0015]-接种物(培养基中相对高密度的生物体)
[0016]-碱(用于调节ph值,例如氢氧化铵溶液)
[0017]-酸(用于调节ph值,例如hcl溶液)
[0018]-营养补料(缓冲液中的高浓度营养混合物)
[0019]-诱导剂(调节生物体的行为)。
[0020]
本技术的生产过程可以涉及材料的化学或微生物转化以及质量、热量和动量的传递。所述过程可以包括均相或异相化学和/或生化反应。所述过程可以包括但不限于混合、过滤、纯化、离心和/或细胞培养。生产过程可能涉及需要时间才能完成的化学或生物反应,例如大肠杆菌(e.coli)微生物批次需要6小时,哺乳动物细胞培养需要18天,且哺乳动物灌注过程需要60天。
[0021]
特别地,“生产”化学、药物和/或生物技术产品表示对输入的任何处理,包括但不限于修改任何输入的状态(例如改变其温度、氧含量等)、可逆或不可逆地结合任何输入,以及使用输入来创建新材料。
[0022]
可能的产品可以包括转化的底物、面包酵母、乳酸培养物、脂肪酶、转化酶、凝乳酶。可以根据本技术中描述的技术生产的其他示例性生物药物产品包括以下:重组和非重组蛋白质、疫苗、基因载体、dna、rna、mrna、抗生素、次级代谢物、生长因子、用于细胞治疗或再生医学的细胞、半合成产品(例如人造器官)。可以使用各种生产系统来促进所述过程,例如基于细胞的系统,如动物细胞(例如cho、hek、perc6、vero、mdck)、昆虫细胞(例如sf9、sf21)、微生物(例如大肠杆菌、酿酒酵母(s.ceravisae)、巴斯德毕赤酵母(p.pastoris)等)、藻类、植物细胞、无细胞表达系统(细胞提取物、重组核糖体系统等)、原代细胞、干细胞、天然和基因操作的患者特异性细胞、基于基质的细胞系统。
[0023]
示例性地,生产过程可以是分批过程,其中提供特定量的用于饲喂生物体的补料培养基作为初始条件,然后是控制期。生产过程可以是补料分批过程。补料分批过程可以涉及培养,其中基础培养基支持初始细胞培养,并且一旦初始营养物已经耗尽,则添加补料培养基以支持进一步的生长和/或产品生产。换言之,补料分批过程可以涉及分批周期,然后是补料周期。生产过程可以是灌注过程,其中分批周期之后是补料周期,例如通过过滤连续去除例如产品。
[0024]
示例性地,过程可以是哺乳动物和/或微生物培养过程。
[0025]
本技术中描述的技术可用于生物反应器过程,以及用于在生产的其他水平上执行的过程。
[0026]
生产过程通过由控制生产过程执行的一个或多个配方参数指定的多个步骤进行定义。
[0027]
生产过程由为生产产品和/或产生与产品相关的特定结果而执行的步骤序列定义。一些步骤可以彼此同时发生,且其他步骤可以以时间顺序一个接一个地发生。步骤可以对应于在生产过程中执行的动作,其中所述动作可以是被动的,如等待事件发生(如由于培养物的不活动而导致氧气水平增加),或者是主动的,如导致事件发生(例如搅拌或添加流体)或为给定数量设置值和/或特征。
[0028]
示例性地,在生物反应器内的生产过程中执行动作的步骤可以由以下非详尽列表来代表:
[0029]-在搅拌、气体供应、气体混合、温度、ph方面设置设定点
[0030]-在搅拌、气体供应、气体混合、温度、ph方面执行特征变化
[0031]-将选定的液体添加到生物反应器容器中
[0032]-从生物反应器容器中去除液体
[0033]-指定特定流体与生物反应器的连接以及这些流体的组成。
[0034]
此外,所述过程可以包括描述执行流程的步骤类型,例如指定事件发生的方式/时间,如:重复一个或多个步骤,直到满足条件和/或指定的迭代次数,根据生物反应器的状态在各种选项之间进行选择,等待直到条件变为真(例如等待直到溶解氧升高以指示开始进料前分批阶段结束),同时执行一个或一组步骤(例如,在控制温度的同时执行ph控制)。
[0035]
多个步骤的执行由一个或多个配方参数控制。示例性地,多个步骤可以由多个配方参数指定,其中每个步骤由一个或多个配方参数指定。
[0036]
换言之,生产过程可以包括(即可以根据
…
执行)至少一个对过程的性能(例如,产品滴度、品质属性)和由该过程生产的产品有影响的配方参数。配方参数在它们影响过程进程的意义上控制过程的执行。
[0037]
具体地,配方参数可以是可控的,即,配方参数的值可以在执行过程之前和/或期间被具体地调整。换言之,可以设置至少一个配方参数,例如由操作员或控制系统。具体地,配方参数可以是描述和/或管理用于生产过程的设备,例如,生物反应器的状态和/或行为的参数。
[0038]
在生物反应器的情况下,配方参数可以包括但不限于:
[0039]-一个或多个与生物反应器中的干预直接相关的参数,例如在取样步骤中要取出的液体量;
[0040]-为控制回路提供输入的一个或多个参数,例如生物反应器中氧气的设定点(然后生物反应器系统中的控制回路将监测氧气并调整例如搅拌或充气以达到设定点);
[0041]-为特征,例如进料指数增加的速率指数提供输入的一个或多个参数;和/或
[0042]-指定要满足的条件(例如,在进料阶段开始之前,溶解氧必须达到90%)的一个或多个参数。
[0043]
示例性地,配方参数可以包括(但不限于)以下任何参数:搅拌速度、取样频率和体积、总放气速率、收获时间、进料中的葡萄糖浓度、进料的时间、频率或体积、溶解氧或其他气体浓度的设定点、施加于细胞群的剪切应力(例如来自剧烈搅拌)、进料中的氨基酸或其他营养物浓度、通过灌注更换培养基的速率、接种量、接种浓度和下一阶段过程的触发点(例如%o2)、定义进料策略的参数(团注相对于连续)、温度特征、ph特征、控制方法(比例-积分-微分(pid)控制中的设定点、p、i和d参数)、执行时间和等待时间、体积和浓度或各种试剂、进料或其他液体、填充体积、变化/转变到任何参数或变量设定点的幅度和时间。特征可以是:
[0044]-恒定速率(例如恒定速率进料)
[0045]-指数(例如进料指数增加,这通常大致对应于生物体将要做什么)
[0046]-多项式(例如,对应于特定生物体生长模式的3阶多项式);
[0047]
并且可以通过一个或多个配方参数进行参数化。
[0048]
具有配方参数a-x的示例性配方可以如下:
[0049]-用al培养基填充生物反应器,其中葡萄糖浓度为b gl-1
,且乳酸盐浓度为c gl-1
,且接种密度为d个细胞l-1
。
[0050]-以e lpm开始对生物反应器充气。在pid循环中利用p、i和d参数f、g和h搅拌,以调节o2至i%。控制温度至j度。
[0051]-等待直到%o2下降至低于l%,然后等待直到%o2升高超过m%。同时,每n h从生物反应器中进行一次取样o l。
[0052]-一旦%o2升高,即根据指数特征进料,提供pe
qt lpm的r%葡萄糖溶液。
[0053]-在s h间隔处,从生物反应器取样t l并测量细胞计数。当细胞计数达到u个细胞l-1
时,通过在w h时间内每小时将温度增加v度来执行温度转变。
[0054]-等待另一个x h,然后收获。
[0055]
特别地,配方参数可以被赋予由给定数字表示的恒定、固定值。配方参数的值可以在生产过程的执行开始时设置,或者可以在生产过程的执行期间动态确定。例如,可以动态确定设定点和特征以考虑生产过程中出现的事件。
[0056]
配方中的给定步骤可以由给定的配方参数以不同的方式指定。在一些情况下,直接使用分配给配方参数的值,如在步骤“用al培养基填充生物反应器”中。在其他情况下,分配给配方参数的值可能会被“处理”。例如,配方参数可以用作数学表达式和/或条件语句的参数。除了配方参数的值之外,数学表达式和/或条件语句可以采用一个或多个另外的参数。其他参数可以包括但不限于过程变量(见下文)、时间、部署配方的机器的属性(例如生物反应器体积)或以上的组合。
[0057]
示例性地,配方的一个步骤可以是“当溶解氧(do)降至20%以下时,然后补充氧气”。配方参数“20%”的选择是预先确定的,但是这在给定运行中的表现方式会有所不同。这同样适用于模拟运行,其中do降至20%以下的时间(如果其完全如此)可能会因任何以下因素或以下因素的组合等而异:过程演化信息、机器规格和随机实现(这些因素将在下面讨论)。
[0058]
配方包括定义生产过程的多个步骤。换句话说,配方是生产过程,例如生物反应器活性的结构化表示。这意味着多个步骤以结构化方式表示,例如以机器可以解释的格式。
[0059]
如上文解释的,有指示动作(被动或主动)的步骤和控制流程的步骤,例如顺序(按顺序执行包含的步骤),重复(重复包含的步骤,直到满足条件或给定次数)和决策(根据条件,执行一个或另一个步骤)。
[0060]
如所讨论的,在(真实或模拟)执行期间步骤的实际行为,即发生了什么,由一个或多个配方参数,以及如果适用,它们对过程变量,即过程状态响应的预定依赖性决定。
[0061]
因此,配方包括多个步骤以及用于指定步骤的配方参数的一个或多个值。换句话说,配方提供了一个定义明确的程序,其可以在执行生产过程时直接实施,并规定如何随时间控制过程设备。
[0062]
如上文解释的,配方中的配方参数的值是预先确定的,即使它们可以在执行期间动态地进料到配方(例如,当它们取决于过程变量时)。相反,配方模板是这样的配方,其中指定多个步骤的配方参数中的至少一个是可变的且在开始时没有预定值的可变配方参数。
[0063]
方法包括检索一个或多个配方模板组合,其中配方模板组合包含一个或多个配方模板。
[0064]
如所解释的,配方模板涉及一个或多个关于如何执行生产过程的自由度。至少一个可变配方参数的不同值导致从给定配方模板产生的不同配方。差异可能仅在于配方参数的值,或者也可能在于步骤顺序,例如如果配方模板中的执行路径取决于可变配方参数。在一个配方模板中可能有多个配方参数或只有一个配方参数是自由的。
[0065]
可自由变化的示例性配方参数(即可变配方参数)可包括但不限于以下一项或多项:
[0066]-关于生物反应器系统的附件
[0067]
·
分批培养基中的主要碳源浓度
[0068]
·
进料培养基中主要氮源的浓度
[0069]
·
附上以用于对ph值进行最高控制的酸的ph值
[0070]
·
分批培养基的缓冲能力
[0071]
·
接种物中的细胞密度
[0072]
·
富氧空气中的氧气百分比
[0073]-关于特征和设定点
[0074]
·
分批阶段中恒定充气的供应速率
[0075]
·
分批阶段中搅拌速度随时间增加的速率
[0076]
·
用于充气控制的pi反馈回路中的p或i参数
[0077]
·
补氧发生前的最大空气流速
[0078]
·
进料指数曲线中的指数系数
[0079]
·
进料指数曲线中的初始进料速率
[0080]
·
进料曲线中的平稳期(例如,在指数期之后)的持续时间
[0081]
·
感应温度转变期间的温度下降速率
[0082]
·
分批阶段期间的温度设定点
[0083]-关于配方中的离散事件
[0084]
·
生物反应器填充体积(占生物反应器总体积的比例)
[0085]
·
接种体积(例如,生物反应器填充体积的比例)
[0086]-关于配方结构和流程控制
[0087]
·
溶解氧(do)控制中的级联顺序(例如,搅拌然后充气然后补充o2;或充气然后搅拌然后补充o2)
[0088]
·
初级碳源和/或do启动补料阶段的阈值
[0089]
·
取样频率
[0090]
·
每次取样或特定取样步骤的样品量
[0091]
·
样品中触发进料补充的主要碳源阈值开始收获的
·
开始收获的阈值细胞密度。
[0092]
不同的配方模板可以不同生物体的粒度、克隆或生产过程、部署系统(例如一次性相对于不锈钢可重复使用的生产生物反应器)使用。可选地或另外,给定的配方模板可用于一系列不同的生物体、克隆、生产过程或部署系统,利用配方参数的使用,这些参数本身是变量或参数的函数,例如生物反应器体积。
[0093]
配方模板也可以在组织之间共享或在网络上的存储库中分类。可以根据用户反馈选择它们。
[0094]
配方模板可以是库的一部分。例如,配方模板可以以结构化数据格式存储(例如,通过xml中的串行器持久化)。配方模板同样可以存储在数据库、电子表格中,并且可以存储在本地、组织文件系统、组织内的数据库或云中(远程)。
[0095]
此外,每个配方模板组合包括一个或多个配方模板。在配方模板组合仅包含一个配方模板的情况下,该组合与配方模板一致。在其他情况下,配方模板组合包括多个配方模板,其中配方模板在一个或多个步骤的执行方面可以不同或者可以相同。同一配方模板组合中的配方模板可以具有相同的可变配方参数,可变配方参数的子集可以在组成配方模板之间共享,或者没有可以共享的可变配方参数的子集。组合中的多个配方模板旨在用于生产过程的并行、顺序或重叠执行,例如在多个生物反应器上。
[0096]
并行执行多个生产过程可能有几种不同的动机,例如如果需要大量滴度,并且应该合并运行的输出以获得它,或者为了解决失败运行之一的风险,或者为了从多个过程中获得组合信息。
[0097]
如下文解释的,配方模板组合用于模拟生产过程。在多于一个配方模板组合的情况下,分别基于多个配方模板组合运行多个模拟使得所述方法能够探索更广泛的可用替代方案以找到关于其中考虑了单个配方模板组合情况的最佳配方。
[0098]
所述方法还包括检索描述过程变量的时间演化的过程演化信息,所述过程变量描述生产过程的状态,其中所述过程演化信息包括演化参数,并且至少一个演化参数是可变的且在开始时没有预定值的可变演化参数。
[0099]
过程变量描述生产状态,这当然至少部分取决于设备的行为,以及所用设备和输入(例如生物体)的细节。这些过程变量的值可能是生产过程固有的,并且不能直接调整。但是,可以通过修改影响它们的因素,如配方参数来间接调整它们。此外,过程变量可能会相互影响。
[0100]
过程变量的值在生产过程中发生变化。过程(在现实世界中执行或模拟)中给定时间的过程变量的测量值通常称为“过程值”。
[0101]
例如,生物反应器中生产过程的过程变量可以分为:
[0102]
a.由于生物反应器的几何形状和能力引起的配方参数的可计算连锁效应,例如尖端速度、作为最大生物反应器搅拌速度的比例的搅拌速度,表观气体速度;
[0103]
b.可以从以前的实证研究中获得的连锁效应,例如k
l
a、混合时间、功率输入、最小涡流尺寸;
[0104]
c.可以从(b)点中的变量以及生物反应器的特性,例如单位体积功率计算的变量;
[0105]
d.由于过程中的控制回路而从来自模拟生物反应器特性和过程方面,例如放气速率、气体混合和搅拌速度的反馈产生的变量;
[0106]
e.由生物反应器内的氧气或其他气体的动力学所产生的变量,例如受以下因素的影响:搅拌速度、充气等,例如do、二氧化碳分压(ppco2);
[0107]
f.由生物体动力学产生的变量,由生物体模型和上文和下午的其他变量(例如细胞计数、细胞活性、细胞代谢、细胞活力)决定;
[0108]
g.由可从配方参数计算的液体添加或去除产生的变量,例如填充量,以及潜在的
蒸发模型;
[0109]
h.由液体添加和去除以及生物体动力学的组合产生的变量,例如分析物浓度;
[0110]
i.既可以通过配方步骤也可以通过生物体进行调节的环境条件,例如ph、渗透压和温度。
[0111]
过程演化信息表征一个或多个过程变量如何随时间变化,包括过程变量的初始条件。特别地,过程演化信息可以包括从生产过程的先前执行经验地导出的关系和/或由关于生产过程的演化的理论模型导出的方程。过程演化信息可以包括一个或多个变量对时间的显式依赖性以及将过程变量彼此连接的关系。
[0112]
过程演化信息可能有许多组成部分,例如与细胞动力学、生物反应器动力学和/或生物反应器内发生的化学反应相关的过程演化信息。
[0113]
过程演化信息还可以描述相关的并且超出了可能被严格认为是生产过程本身的事件。特别地,过程演化信息还可以描述生物反应器外部发生的情况,例如采集的样品的时间演化,或在二级反应器容器中,或在下游处理设施(例如纯化单元)中,和/或在一件分析设备中。
[0114]
在一个例子中,过程演化信息的细胞培养成分是使用一组描述“细胞过程”的分层常微分方程建模的,其中任何单个细胞过程等都描述了该细胞过程的依赖性,即其速率如何取决于ph、do、温度和各种营养物质的浓度,以及该过程的结果,即由于该过程处于活动状态,细胞计数、滴度、ph、do等发生的变化。通常注意到“集合”可以包括一个或多个元素。
[0115]
允许给定细胞过程a依赖于一个或多个驱动过程x、y...,以便计算a的速率,然后乘以x、y速率的总和或乘积。给定细胞过程可能不依赖于驱动细胞过程或任何数量的驱动细胞过程,并且给定的细胞过程可能不驱动其他细胞过程或任何数量的其他细胞过程。
[0116]
例如,在一种非常简单的情况下,只有一个依赖性(温度)和一个结果(细胞生长),这相当于求解微分方程:
[0117][0118]
其中ρ是细胞密度,t时间,rg最大生长速率,t温度,t
opt
最佳生长温度,t
sens
表示生长对温度的敏感性,且n(x,s)表示在x处标准偏差正态分布的值。
[0119]
更典型的情况将具有多出很多的依赖性(例如对关键营养素的依赖性)和结果(例如由于细胞活动导致的do减少、微生物细胞活动情况下的温度升高、营养素数量的减少等)。另外,可能有许多这样的细胞过程,其具有累加效应,例如组成性生长、因毒素存在而死亡、产物积累等。
[0120]
然后,细胞生长的过程演化信息相当于描述“细胞过程”变量和相互依赖性。这可能有几种形式:
[0121]
a.表格数据(如可能存在于电子表格中),其中每个细胞过程都有自己的一行,并且在每一行中,提供了各种潜在依赖性的参数(相对于依赖性的函数形式的硬编码库)
[0122]
b.数据库表格,例如,可以存在以下表格:db_细胞_培养_模型、db_细胞_培养_过程、db_细胞_培养_过程_链接、db_细胞_培养_过程_依赖性、db_细胞_培养_过程_依赖性_参数,
[0123]
其中db_细胞_培养_模型对命名模型进行编目,然后软件可以引用这些模型,db_
细胞_培养_过程对任何模型中的细胞培养过程进行编目,db_细胞_培养_过程_链接将db_细胞_培养_过程中的条目关联在一起以指示一些过程驱动其他过程的事实,db_细胞_培养_过程_依赖性指示特定的依赖性(例如,通过指示依赖性的轨迹变量和依赖性的形式)等。
[0124]
c.结构化数据格式,如xml,或者同样的json或专有形式。
[0125]
然后这些数据可能会以多种方式存储:
[0126]
a.在负责执行配方确定的软件中,例如,嵌入在dll或可执行文件中
[0127]
b.在文件系统上可供s/w使用的文件中(文件可能提供这些形式中的任何一种)
[0128]
c.在数据库实例中
[0129]
然后这些数据可被进一步存储和处理:
[0130]
a.在执行确定的软件本地,例如在同一文件系统上,或由内置在s/w中的数据库引擎访问,可能在内存、sd卡、硬盘驱动器、cdrom、dvdrom等中。
[0131]
b.在软件可访问的网络上的文件共享中
[0132]
c.跨客户端/服务器(例如网络服务)系统,客户端与服务器物理分离,即位于软件附近(物理上),或由软件通过网络访问,在后一种情况下,要么存储在一个位置或分布在多个站点间。
[0133]
除了细胞培养外,过程的物理动力学也在过程演化信息中描述。这包括过程变量在某个时间点如何相互关联,以及每个过程变量如何随时间演化。
[0134]
与细胞培养模型一样,物理动力学模型可以存储为xml、数据库表等,并且数据的基底可以是dvd、cdrom、硬盘等,并且数据的位置是本地的或不同的,并且数据分布在一个地方或分布式。
[0135]
总而言之,可以根据多种不同的实现方式来检索表示过程演化信息的数据。
[0136]
过程演化信息由一个或多个演化参数确定。这些演化参数(也可称为“模型参数”)是表征一个或多个过程变量如何依赖于时间和/或其他过程变量的因素。演化参数是出现在经验导出的关系和/或理论方程中的参数。特别地,演化参数可能具有不依赖于时间的值,即不随时间变化的值。
[0137]
参考上面针对细胞生长讨论的示例性微分方程,ρ(细胞密度)和t(温度)代表过程变量,而rg(最大生长速率)、t
opt
(最佳生长温度)和t
sens
(生长对温度的敏感度)代表演化参数。
[0138]
更一般地,演化参数可以示例性地包括以下的任何一项:生长速率、细胞凋亡或溶解速率或其他状态变化、诱导物或抑制剂的产生速率、营养物或产物的速率或产生或消耗、对外部因素,如ph/压力/溶解氧(do)/温度/co2/紫外线或可见光或其他化学或物理因素的敏感性或其他描述性反应参数(例如临界值、容量等)、对营养物质或化学物质梯度、细胞因子浓度、生长速率变异性(在随机微分方程的上下文中)、细胞类型分布的耗氧量的敏感性或其他描述性响应参数、拥挤/容量常数(例如最大活细胞密度)、营养物质、产物或其他物质的衰减或降解速率、变化的大小、变化或转变的相对或绝对幅度、上述任何一项的时间或控制参数。
[0139]
特别地,与敏感性或其他描述性参数相关的外部因素可以包括由配方参数设置的因素。例如,细胞的生长可能依赖于ph,可以根据相应的配方参数对其进行设置。
[0140]
如所解释的,过程演化信息提供了基于生物、物理、化学等关于生产过程中所涉及的现象的考虑的生产过程如何表现的模型。这样的模型对于模拟生产过程是必要的,如下文所讨论的,并从模拟中获取有关如何运行实际过程的有价值的信息。
[0141]
如果过程演化信息的演化参数具有固定的、预定的或可预先确定的值,则对过程背后的科学采取单一观点。然而,生产过程相当复杂,并且这样的假设可能会过度影响过程模拟的结果。换言之,最优配方的确定可能受到演化参数值的特定选择的影响。
[0142]
因此,为了通过减轻假定的过程演化信息的影响来更准确地确定最优配方,至少一个演化参数是可变的并且在开始时没有预定值的可变演化参数。示例性地,只有演化参数的适当子集可以是可变的。在其他实例中,所有演化参数可以自由变化。
[0143]
一个或多个可变演化参数的存在需要一组演化参数的多组值。例如,如果在一组三个进化参数中存在一个可变演化参数,并且为可变演化参数分配了n个不同的值v1,
…
,vn,则将有n组值:(v1,fa,fb)、(v2,fa,fb)、
…
,(vn,fa,fb),其中fa和fb是其他两个演化参数的固定值。为任何演化参数考虑的不同值的数量可能与为另一演化参数考虑的数量不同。参考下面的似然函数,可以预先确定或动态确定表征或评估的不同值的数量,直到达到足够的准确度,这取决于所使用的精确算法。
[0144]
如前所述,过程演化信息用于模拟生产过程。相对于其中只有一组值用于演化参数的情况,运行与演化参数的多组值相对应的多个模拟使得该方法能够探索更广泛的可用替代方案以找到最优配方。
[0145]
实际上,传统上,对生物、物理和化学动力学的见解经常根据单一选择模型来表达,并通过确定该选择模型的最佳拟合参数来进一步细化。然而,这过度代表了有关机制背后的科学的确定性,并低估了围绕观测数据最可能的解释的变化和不确定性。
[0146]
应该注意的是,具有可变的演化参数不仅可以解释模型参数的不确定性,还可以解释模型本身选择的不确定性。实际上,过程演化信息可以包括多个竞争模型,每个模型具有不同的演化参数。在仅是说明性的实例中,可能有两个竞争模型来描述过程变量x和y的演化,其中第一个模型包括方程
[0147][0148][0149]
并且第二个模型包括方程
[0150][0151][0152]
因此,第一个模型具有演化参数(a,b),且第二个模型具有演化参数(c,d),并且过程演化信息的可变演化参数可以是(a,b,c,d)。通过赋值(a’,b’,0,0)或(0,0,c’,d’),可以分别选择第一或第二模型,从而可以根据不同的动力学模拟生产过程。在一些实例中,如果没有为给定的演化参数分配值,则可以假定它默认为零。因此,在一些情况下,为演化参数
选择不同组的值可能意味着为生产过程选择不同的模型。
[0153]
可以基于似然函数来分配一个或多个变量演化参数的值,如下文将解释的。
[0154]
所述方法还包括针对演化参数检索似然函数,其中似然函数提供演化参数的值对于生产过程可行的可能性。换句话说,似然函数提供了演化参数的每个值能够描述生产过程的充分性如何的度量,如通过过程演化信息建模的。换句话说,似然函数将演化参数的可能性值映射到这些值正确描述过程演化,即描述生产过程状态的过程变量的时间演化的可能性。
[0155]
在一个实例中,似然函数可以是矩形分布,这意味着所有值都是同样可行的。在其他实例中,似然函数可以不同于矩形分布并且可以描述哪些值比其他值更可行。特别地,在多个演化参数的情况下,似然函数可以是多元概率分布。
[0156]
似然函数可以是所有演化参数,即可变演化参数和非可变或固定演化参数的函数。在这种情况下,似然函数可以被认为是可变演化参数的边际分布和固定演化参数的边际分布的乘积,其中后者是δ分布,可能是多维的,峰值在通过固定演化参数实际假设的值上。否则,似然函数可以更简单地仅表示为可变演化参数的函数。
[0157]
似然函数的可能形状包括但不限于以下任何一种:
[0158]-在最大值附近具有高斯或类似分布的单个最大值(单变量、双变量或多变量高斯或类似分布)
[0159]-在最大值附近具有高斯或类似分布的单个最大值,在一定范围之外被截断
[0160]-多个局部最大值(单变量、双变量或多变量)
[0161]-范围内的常数(单变量、双变量或多变量)
[0162]-类似可能性的谷、区域、超体积或曲线
[0163]-周期性分布,其中似然函数例如在其一个或多个维度上与正弦函数或衰减正弦函数对应。
[0164]
似然函数可以存储在数据库中并存储在本地、在本地或组织文件系统中、在组织内或云上(远程)的数据库中。
[0165]
似然函数描述并可以可视化为似然空间。通过扩展,似然函数可以称为“似然空间”、“概率空间”或“知识空间”。
[0166]
似然函数可以基于关于演化参数值的先验知识来确定。所述先验知识可以来源于以下任何来源及其任何组合:来自文献的数据、用户的个人经验、基于理论考虑的数据、来自同一生产过程的已完成运行的数据、来自同一生产过程的持续运行的数据、来自与相关生产过程相关的已完成或持续运行的生产过程的数据。这些选项将在下面单独讨论。在本文中,“运行”一词用于生产过程在现实世界中的实际执行,而“模拟运行”则用于其模拟执行。
[0167]
一般来说,可以表达先验知识的方式包括但不限于:
[0168]-进化参数值的简单界限
[0169]-半定性描述,例如手动描绘表面上的单个或同心似然区域、手动设置边界、设置/拖动样条曲线上的点等。半定量描述可以通过参数化通用函数或模板来实现,所述通用函数或模板本身描述了一类似然面,例如提供二维似然函数中恒定似然矩形区域的最小值和最大值,参数可以手动指定,也可以通过与图形系统交互。
[0170]-围绕一个共同平均值分布,例如正态分布,其中σ描述自然(非定向)方差和实验噪声
[0171]-其他通过形状参数描述的常见分布,如β、bernoulli等。
[0172]-长尾分布(例如cauchy、γ变量),描述参数更可能落在均值的一侧而不是另一侧的知识,或者考虑大的方向异常值
[0173]-platykurtic分布,其中参数具有很强的边界但不太明确定义的平均值
[0174]-有界或无界的均匀分布
[0175]-双模型(或更高阶)分布,例如细胞可以处于两种(或多种)“状态”之一
[0176]-多种类型的高维多元分布,描述与其他演化参数的关系(例如多元正态、γ或β分布)
[0177]-使用上述任何分布或简单的算术描述或半定性描述,对成对的(或更多个)演化参数或演化参数和环境条件的比率、差异、总和或乘积的先验或约束
[0178]-描述演化参数与彼此或其环境的关系或约束的其他函数
[0179]-通过索引到经验确定值的多维数组中,从进化参数到可能性的映射的近似值,可能与插值相结合
[0180]-以上任意组合。
[0181]
在一些实例中,可能必须根据过程演化信息来解释先验知识,以便确定似然函数。因此,可以基于描述相关生产过程和/或其他过程的先验知识和过程演化信息来计算似然函数。
[0182]
从先验知识导出似然函数可以是完全自动化的过程或者可能需要至少部分来自用户的输入。示例性地,当先验知识本身基于用户的经验时(例如上面的半定性描述实例),可能需要用户输入。另外或可选地,可能需要用户输入来确定在导出似然函数时应该如何准确地使用先验知识,例如用户可以选择分布形状来拟合一些数据和/或表达给定的假设。
[0183]
在一特定实例中,化学、药物和/或生物技术产品可以是第一产品,并且检索似然函数可以包括:
[0184]-检索产生第二化学、药物和/或生物技术产品的至少一个同类生产过程相关的同类数据,其中所述至少一个同类生产过程已被至少部分地执行,并且其中所述至少一个同类生产过程不同于所述生产过程;
[0185]-检索提供生产过程和同类生产过程之间相似性的定量表征的相关性信息;
[0186]-基于同类数据和相关性信息计算似然函数。
[0187]
换句话说,根据该特定实例,使得过程知识在彼此不同的过程之间的转移,例如由于配方、细胞类型或使用的培养基,成为可能。如果没有关于给定过程/产品的先前可用知识,则使用相关性信息可能特别有用。此外,即使先前的知识可用,它也有助于更准确地表征似然空间,即通过调制似然图,并可能,例如,增加具有零或极小似然性的演化参数值的集合。
[0188]
同类生产过程是生产过程,并因此,上文关于生产过程的性质和特征的解释同样适用。然而,同类生产过程与生产过程不同。在一些情况下,差异可能是过程固有的,例如这两个过程可能至少在其中使用的输入或成分和/或产品和/或执行这些过程的规模方面有所不同。在其他情况下,差异可能是由于一个或多个“外部”因素造成的,如使用不同的设备
(包括分析设备),其中设备也可能不同,因为例如,在时间过程中,它已被升级/修改。因此,第一产品可能不同于或可能不会不同于第二产品。
[0189]
同类数据是从同类生产过程的运行中测量和/或导出的数据,和/或以另一种方式与同类生产过程相关的数据。同类生产过程的运行可能已经完成,即同类生产过程可能已经全部执行,或者运行可能仍在进行中,即同类生产过程可能仅部分执行。
[0190]
同类数据可以包括但不限于与同类生产过程的过程变量和/或来源于同类生产过程(例如,通过假设同类生产过程的给定过程演化信息)的演化参数相关的数据。示例性地,同类数据可以包括同类生产过程的过程变量的轨迹。轨迹对应于在生产过程的执行(真实或模拟的)期间可记录的值的基于时间的特征。另外或可选地,同类数据可以包括关于演化参数的值的先验(例如,以概率分布的形式)。
[0191]
相关性信息(以下也简称为“相关性”)提供了生产过程与同类生产过程之间相似性的定量表征。正如所解释的,这两个过程是不同的,但它们可能仍然具有一些程度的相似性(即使在区分它们的方面),因此从同类生产过程中提取的信息也可以提供有关生产过程的见解。相关性是一种对来自同类生产过程的信息给予适当权重的方法,即表达它对于相关生产过程如何相关。相关性也可以表示不存在相似性。
[0192]
相关性通常可以涉及但不限于以下之间的相似性:
[0193]-细胞系
[0194]-生物体
[0195]-微生物种群,包括但不限于代数、细胞制备条件,例如冷冻后的解冻条件,或预培养条件
[0196]-细胞系亚群或上述任何细胞系(例如,激活细胞相对于休眠细胞)
[0197]-分子或蛋白质
[0198]-过程中产生的其他产品或副产品。
[0199]-操作环境,包括机器属性,但也可能包括位置和/或从中获得似然函数的运行的执行时间
[0200]-机器条件。
[0201]
特别地,由相关性量化的过程之间的相似性可能存在于过程动态中,其由过程演化信息建模,如上所述。因此,特别地,相关性可以是链接与两个过程相关联的一个或多个演化参数的函数。换句话说,两个过程之间的相似性反映在演化参数的值不独立于相关同类演化参数的值这一事实。因此,相关性可以指示进化参数pa相对于相关同类演化参数pb的给定值取某个值的概率。
[0202]
示例性地,可以对两个过程建模的过程演化信息可以至少部分重叠,使得两个过程的演化参数集具有非零交叉。在一些情况下,过程演化信息可能是相同的。
[0203]
相关同类演化参数可以是等效的同类演化参数,即相同的演化参数,例如生长速率r,使得pa=ra且pb=rb。在其他情况下,相关同类演化参数可能不同,例如抑制剂浓度容量k,使得pa=ra且pb=kb。换句话说,相似性可能仅对等效演化参数对(前一种情况)或者也对不同进化参数对(后一种情况)有统计意义。
[0204]
这同样适用于多个演化参数p
a1
、p
a2
…
p
an
和相关的同类演化参数p
b1
、p
b2
、
…
p
bn
。在相似性仅对等效演化参数显著的情况下,相关函数r(p
a1
,p
a2
…
p
an
,p
b1
,p
b2
,
…
p
bn
)可以简化
为乘积r(p
a1
,p
b1
)*r(p
a2
,p
b2
)*
…
*r(p
an
,p
bn
)。
[0205]
过程之间的相关性可以通过对相关实体的了解进行先验估计(例如,先验性地已知中国仓鼠卵巢(cho)细胞的5种不同的克隆比cho、大肠杆菌、巴斯德毕赤酵母、人类胚胎肾(hek)和禾顶囊壳(g.graminis)中的每种的克隆具有更高的相似性)。例如,对于给定分子和生物体的细胞系,可以假设给定的恒定相关性rc,对于同一生物体的不同分子的细胞系之间为0.1*rc,且不同生物体之间为0.01*rc。
[0206]
可选地或另外,相关性也可以在给定关于相关实体的动态的数据后确定,例如通过贝叶斯推理。
[0207]
可以表达相关性的方式包括(但不限于):
[0208]-用户对系统的定性描述,例如“相同”、“相似”、“不相似”、“无相似性”,与常数值相关联
[0209]-用户的半定性描述,例如手动描绘表面上的单个或同心似然区域、手动设置边界、设置/拖动样条曲线上的点等,其中将用户输入转换为定量约束
[0210]-围绕共同平均值分布,例如正态分布,其中σ描述自然(非定向)方差和实验噪声
[0211]-长尾分布(例如cauchy、γ变量)描述参数更有可能落在均值的一侧而不是另一侧的知识,或者考虑到大的方向异常值
[0212]-platykurtic分布,其中参数具有很强的边界但不太明确定义的平均值
[0213]-边界内的均匀分布(即没有相似性)
[0214]-双模型分布(例如,细胞可以处于两种“状态”之一)
[0215]-多种类型的更高维多元分布,不仅描述等效演化参数的相关性,而且同时描述它们与其他演化参数的关系(例如多元正态分布、γ或β分布)
[0216]-使用上述任何分布描述成对或更多参数的比率、差异、总和或乘积的相关性
[0217]-以上的任意组合。
[0218]
检索相关性信息可以包括接收选择相关性信息的用户输入,例如分布形状和/或分布形状的参数。
[0219]
使用同类数据和相关性信息,可以计算似然函数。例如,可以按如下获得演化参数pa的似然函数l(pa):
[0220]
l(pa)=∫r(pa,pb)l
′
(pb)dpbꢀꢀꢀ
(2)其中r(pa,pb)是相关性信息,且l’(pb)是从同类数据获得的同类演化参数pb的似然函数。
[0221]
如果同类数据仅包含轨迹,则l’(pb)可被替换为l’(pb|pvarb,其中pvarb是同类生产过程的过程变量值的元组(或向量)。l’(pb|pvarb)可以示例性地使用贝叶斯定理、关于过程变量的同类数据并假设没有先验或广泛先验来估计。可选地,先验也可以是同类数据的一部分,并且起源于例如理论模型。特别地,为了估计如前所述的l’(pb|pvarb),可以执行对同类生产过程建模的过程演化信息与同类数据的拟合。
[0222]
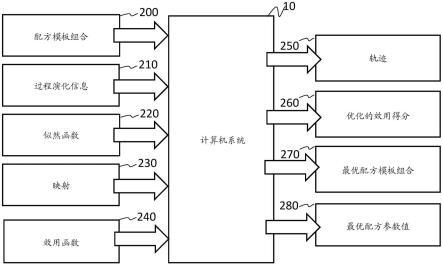
如前所述,同类数据涉及至少一种同类生产过程。在一些实例中,可能存在多个同类生产过程,并且可以相应地检索多组同类数据。类似地,可以检索指示每个同类生产过程和生产过程之间的相似性的相关性信息,并且可以使用同类数据和关于每个同类生产过程的相关性信息来计算似然函数。
[0223]
可选地或另外,检索似然函数可以包括检索与生产过程的持续运行相关的当前数据并基于当前数据计算似然函数。
[0224]
可选地或另外,检索似然函数可以包括检索与生产过程的一个或多个过去运行相关的历史数据并基于历史数据计算似然函数。
[0225]
可以基于通过已经运行生产过程获得的知识来获得对演化参数值的约束。可以认为生产过程与自身具有最大的相似性,即完全相同。从这个角度来看,考虑与生产过程本身相关的数据可能被认为是考虑同类生产过程的特殊情况,相关性等于1。例如,更准确地说,上述方程(2)中的r(pa,pb)将是狄拉克δ函数δ(p
a-pb)。
[0226]
因此,历史数据和当前数据,类似于同类数据,是从生产过程的运行中测量和/或导出的数据和/或以其他方式与生产过程相关的数据。在历史数据的情况下,生产过程的运行可能已经完成,或者在当前数据的情况下,运行可能仍在进行中。
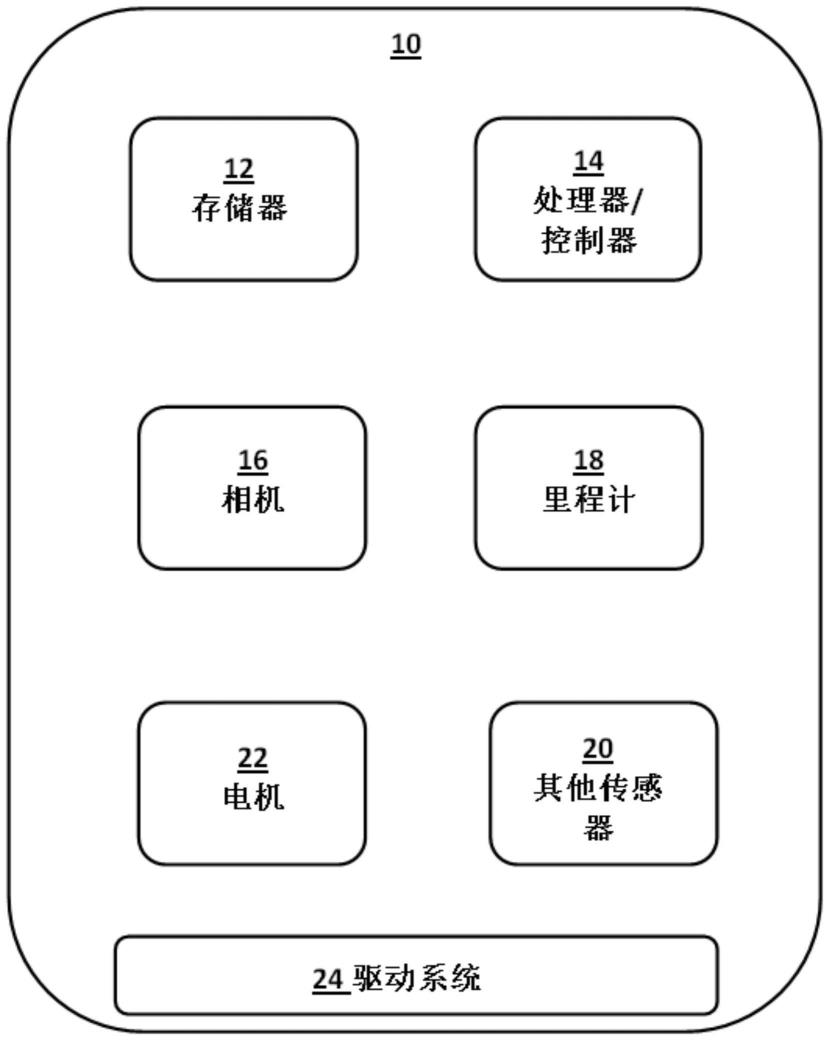
[0227]
历史/当前数据尤其可以包括生产过程的过程变量的数值,例如作为时间的函数,即轨迹。在一些实例中,似然函数可以计算为后验概率l(p|pvar),其中p是演化参数的元组,且pvar是过程变量的元组。使用贝叶斯推理,后验概率由下式给出
[0228][0229]
l(pvar|p)表示在给定演化参数的一组值的情况下观察过程变量某些值的概率,l(p)是先验概率,且l(pvar)是边际似然。
[0230]
l(pvar|p)可以通过将过程变量的值拟合到过程演化信息来从它们确定。任选地,历史/当前数据还可以包括关于演化参数l(p的先验,或者可以输入先验,例如由用户响应提示。l(pvar)也可以从过程变量的值中确定。可选地,由于l(pvar)是一个归一化因子,当目标是优化时,它可以被忽略,如在本文描述的方法的情况下。
[0231]
可以组合上面讨论的各种来源中的任何一个来计算似然函数,从而可以基于同类数据结合相关性和/或当前数据和/或历史数据来计算似然函数。
[0232]
应当注意,似然函数可以是具有解析表达式的函数,或者可以是数值估计值的函数,例如数值优化或经由蒙特卡罗方法。在似然函数至少部分地通过考虑同类数据和/或通过拟合过程变量的轨迹来确定的情况下,所述函数通常是非分析性的。
[0233]
似然函数是一种以系统和准确的方式考虑有关演化参数值的任何先验知识的方法。总之,似然函数可以基于从相关生产过程和/或同类生产过程的当前和/或过去运行中获得的知识。另外或可选地,似然函数可以基于来自科学文献和/或理论假设的知识。在一些实例中,似然函数可以从所有这些来源导出。
[0234]
所述方法还包括包括检索将一个或多个过程变量映射到一个或多个性能指标的映射。映射将过程变量的值与至少一个性能指标的值相关联。在一些实例中,映射将一个或多个过程变量的时间系列(或轨迹)映射到一个或多个性能指标。
[0235]
性能指标是描述生产过程的一个或多个输出的特征的量,在示例性情况下,是产品本身。特别地,性能指标可以是与一个或多个输出的化学、生物、物理属性相关的可测量的量。
[0236]
性能指标的实例包括但不限于最终滴度、滴度增加率、使用的总进料、产品质量、实验或生物反应器的运行时间、完成下游过程的时间、细胞存活或细胞活性的持续时间、细
胞群的最大生长速率或密度、杂质浓度,包括但不限于细胞代谢和细胞死亡的副产物、过程的稳健性或可重复性、产品的稳健性(产品在受控条件下随时间的降解率)、细胞系的的稳健性(遗传密码在几代中的稳定性和/或细胞承受特定条件的能力,例如极端ph值或高剪切)、基底成本、一次性材料或其他成本。
[0237]
示例性地,使用的总进料、最大细胞密度和滴度增加速率等性能指标需要过程变量的轨迹,而其他性能指标,例如最终滴度从过程变量的单个值映射,例如在终点处。
[0238]
一个或多个过程变量可以映射到一个性能指标。这意味着性能指标的值受一个或多个过程变量的值的影响。此外,给定的过程变量可能与一个以上的性能指标相关,即影响一个以上的性能指标。在一些实例中,过程变量本身可以是性能指标,因此映射是身份。在其他实例中,映射可能与身份不同。
[0239]
如果生产过程的状态由多个过程变量表征,则映射可以映射所有过程变量或仅映射其适当子集。
[0240]
在一些实例中,例如对于其中配方模板组合包括多于一个配方模板的情况,映射可以为单个过程变量取多个值,其中这些值来自生产过程的并行或多次运行(真实或模拟的)。
[0241]
映射可以取决于如何执行生产过程,即取决于用于生产过程的配方。因此,映射可以不仅需要过程变量而且还需要配方参数作为输入。可选地,所述方法可以包括检索多个映射,每个映射对应于不同的配方。
[0242]
映射可以基于例如生产过程的先前运行和/或理论预测。映射可以存储在数据库、电子表格中,以及存储在本地、在组织文件系统中、在组织内的数据库中或在云(远程)上。需要注意的是,映射可以是具有解析表达式的函数,或者可以是数值估计的函数,例如经由蒙特卡罗方法。
[0243]
所述方法还包括检索至少一个性能指标的效用函数,其中所述效用函数提供与性能指标相关联的合意性值。换句话说,效用函数根据性能指标的值来量化生产过程性能的整体价值或收益。
[0244]
在单个性能指标的情况下,效用函数可以简单地量化性能指标的特定值的好坏程度。例如,如果性能指标是滴度,则效用函数可以是单调函数,表明较大的滴度值优于较小的值。如果有更多的性能指标,效用函数在评估性能的整体价值时会考虑不同性能指标的相互作用。例如,如果性能指标是产品的滴度和品质,那么与非常高的品质相关的较低滴度可能仍然是可取的。在一些实例中,效用函数可能在一个范围内是恒定的,并且在该范围之外基本上是负的(即对“鲁棒性”的强烈要求)。
[0245]
性能的价值可以根据一个或多个不同的因素来评估,包括但不限于效率、产量、安全性、可靠性、成本。特别地,效用函数可以根据用于确定最优配方的特定的、期望的目标来定义。实际上,生产过程可以针对许多不同方面进行优化。目标的实例可以包括但不限于优化给定的性能指标、评估一组克隆中的哪个克隆最适合生产分子、补偿意外条件、扩展生产过程。
[0246]
即使映射将过程变量映射到一个以上的性能指标,效用函数也可能只是性能指标子集的函数。此外,效用函数可以是性能指标的函数,所述性能指标并非来源于过程变量,如生产过程的总运行时间。换句话说,效用函数将至少一个经由映射从过程变量导出的性
能指标作为参数(在一些情况下,起可能只是恒等函数),并且也可以任选地将一个或多个并非来源于过程变量的性能指标作为参数。需要注意的是,效用函数可以是具有解析表达式的函数,或者可以是数值估计的函数,例如经由蒙特卡罗方法。
[0247]
在一些实例中,例如对于其中配方模板组合包括多于一个配方模板的情况,效用函数可以为单个性能指标采用多个值,其中这些值来自生产过程的并行和/或多次运行(真实或模拟的)。
[0248]
正如到目前为止所解释的,效用函数的输出直接取决于性能指标,并且由于性能指标可以经由映射链接到过程变量,它间接取决于过程变量。此外,由于过程变量依赖于过程演化信息,特别是演化参数,所以效用函数的输出也间接依赖于演化参数。由于可变演化参数的值基于似然函数,因此效用函数的输出也间接取决于似然函数。
[0249]
总而言之,所述方法需要多个输入,即一个或多个配方模板组合、过程演化信息、似然函数(其任选地基于相关性信息)、映射和效用函数。如下文解释的,这些输入用于模拟生产过程的执行,并根据模拟结果选择最优配方模板组合,其中最优配方模板分别与与多个配方模板组合中的可变配方参数和可变的配方参数的多个可能值的最优值组合。
[0250]
所述方法包括
[0251]-选择配方模板组合并进行第一优化步骤,包括:
[0252]
‑‑
为配方模板组合中的至少一个可变配方参数提供一组输入值;
[0253]
‑‑
进行第二优化步骤,以提供效用得分;
[0254]
‑‑
对至少另一组输入值重复第二优化步骤,从而获得多个效用得分;
[0255]
‑‑
从多个效用得分中鉴定最优效用得分;
[0256]-如果仅检索到一个配方模板组合,则选择产生最优效用得分的一组输入值以及一个配方模板组合,作为生产过程的至少一个配方;或者
[0257]-如果检索到多于一个配方模板组合:
[0258]
‑‑
对每个配方模板组合重复第一优化步骤,从而获得多个最优效用得分;
[0259]
‑‑
从多个最优效用得分中鉴定最佳的最优效用得分;
[0260]
‑‑
选择配方模板组合和产生最佳的最优效用得分的一组输入值,作为生产过程的至少一个配方。
[0261]
所述方法包括一系列嵌套循环,其中一些循环在一些情况下可以减少为单次迭代。最外面的循环涉及考虑不同的配方模板组合,而下一个循环涉及考虑可变配方参数值的不同选项。
[0262]
每个循环的不同迭代可以按顺序执行,即一个接一个。可选地,可以并行执行迭代。通常,方法的执行可以包括循环迭代的并行和顺序执行的组合。因此,本文使用的“循环”仅表示在执行模拟时考虑多种可能性中的每一种可能性,且不一定表示时间上的连续性。因此,以下描述的任何一个步骤的一次或多次重复可以与步骤的“第一次”执行同时发生和/或可以按时间顺序发生。
[0263]
对于给定的配方模板组合,执行第一优化步骤,其包括为给定配方模板组合中的至少一个可变配方参数提供一组输入值。
[0264]
如已经提到的,一组输入值可以包括一个或多个元素。如果配方模板组合仅包括一个配方模板,并且配方模板仅包括一个可变配方参数,则该组输入值仅包括一个输入值。
在其他情况下,该组输入值包括一个以上的值。例如,如果配方模板组合包括两个配方模板,每个都具有一个可变配方参数(对于两者来说可能是相同的量,例如ph设定点),则该组输入值包括两个值,一个用于第一配方模板中的可变配方参数,且一个用于第二配方模板中的可变配方参数。如果配方模板组合包括具有多个可变配方参数的单个配方模板,则该组输入值包括对应的多个输入值。
[0265]
输入值可以是基于过程知识的有根据的猜测,并且可以是与特定配方模板组合相关联的一组可能值的一部分。例如,每个配方模板组合可以包括一个或多个候选值以及每个值的测试范围,使得输入值可以被选择为位于候选值周围的区间中的任何值。因此,候选值可以与配方模板组合一起被检索。可选地,输入值可以由用户提供。
[0266]
一旦已为可变配方参数分配了一组输入值,则执行第二优化步骤以提供效用得分。第二优化步骤的细节将在下文中讨论;在任何情况下,效用得分都是与某一配方模板组合和某一组输入值相关的数值。对至少另一组输入值重复第二优化步骤,在一些情况下,对多个其他输入值组重复第二优化步骤。各组输入值在至少一个输入值方面彼此不同。
[0267]
对于每组输入值,第二优化步骤关联效用得分。由于对多组输入值执行第二优化步骤,因此获得了多个效用得分。第二优化步骤的重复构成第二个最外面的循环,嵌套在配方模板组合上的潜在最外面的循环中,这将在下文中讨论。不同组输入值的数量,即第二优化步骤的迭代次数,可以是固定的预定数量,或者可以在每次执行该方法时设置,例如由用户设置,或者可以通过计算确定,例如通过达到算法收敛所需的迭代次数。
[0268]
除了对不同的输入值组执行第二优化步骤之外,第一优化步骤包括从多个效用得分中识别最优效用得分。如前所述,效用得分的每个值都与一组输入值相关联。换句话说,效用得分的值取决于分配给所选配方模板组合中的可变配方参数的值等。因此,效用得分可被视为一个或多个可变配方参数的函数,以下称为“得分函数”。在多个可变配方参数的情况下,得分函数是一个多变量函数。可以基于实际计算的多个离散值通过数值方法来评估得分函数。
[0269]
得分函数被优化以找到可变配方参数的最优输入值集合。寻找可变配方参数的最佳值是一个优化问题,其中得分函数被最大化或最小化。取决于可变配方参数的数量,优化问题可能是一个多维问题。取决于效用函数以及从它导出的量以及下文讨论的(例如效用计数、效用值)如何定义,最佳效用得分可能是最高或最低效用得分。优化算法的实例是nelder-mead方法和最速下降法。
[0270]
优化的结果是找到了为所选配方模板组合提供最佳(例如最高分数)的一组输入值。可以示例性地存储最优效用得分和与其相关联的一组输入值,例如在诸如硬盘等存储设备中。
[0271]
如果仅检索到一个配方模板组合,则最外面的循环“折叠”为单次迭代,并且第一优化步骤仅执行一次。因此,产生在该第一优化步骤中识别的最优效用得分的输入值集合或“输入值的最优集合”连同配方模板组合被选为生产过程的至少一个配方。实际上,根据定义,具有分配给其可变配方参数值的配方模板成为配方。以这种方式,确定执行生产的最佳方式,即优化得分函数的配方,即配方模板组合加上一组输入值。
[0272]
如果存在多于一个配方模板组合,则对它们中的每一个重复第一优化步骤,以便为每个配方模板组合确定最优效用得分。一旦对所有配方模板组合的迭代结束,即一旦完
成最外面的循环,则识别对应于多个配方模板组合的最优效用得分中的最佳的最优效用得分。同样,最佳的最优效用得分可能是最高或最低的最佳效用得分,这取决于效用函数的定义方式。最优效用得分可以形成离散集合,从而可以通过将最优效用得分相互比较来简单地识别最佳的最优效用得分。可以示例性地存储最佳的最优效用得分和与其相关联的配方模板组合,例如在诸如硬盘等存储设备中。
[0273]
同样在这种情况下,配方模板组合和与最佳的最优效用得分相关联的一组输入值被选为要用于生产过程的配方。
[0274]
如果配方模板组合仅包含一个配方模板,则只有一个配方被确定为运行生产过程的最优配方。如果配方模板组合包括更多配方模板,则识别多个配方以用于生产过程的并行、顺序或重叠运行。
[0275]
例如,配方模板组合(a)可以包括用于在生物反应器上进行两次平行运行的两个配方模板,其中根据一个配方模板使用团注进料,并且根据另一个使用逐步进料。另一配方模板组合(b)可以包括具有取决于葡萄糖测量值的体积的团注进料的两个相同的配方模板。对于这两个组合,所有配方模板中的可变配方参数是收获时间。根据本文所公开的方法,可以确定最好使用来自组合a而不是b的配方模板进行两次平行运行,且特别是对于团注进料的收获时间为15天,且对于逐步进料的收获时间为18天。
[0276]
总而言之,所述方法提供的最终结果是用于运行生产过程的至少一个配方,其中该配方可以基于通过效用函数表示的一个或多个特定标准被认为是最优的。下面将解释从效用函数到效用得分的路径。应当注意,术语“第一/第二/第三/第四优化步骤”不一定表示在该步骤中正在执行优化过程。相反,这些步骤中的每一个都有助于整个方法实现的优化,即找到最优配方。
[0277]
如上所述,第二优化步骤提供了效用得分,它是通过潜在地循环可变演化参数的不同值而获得的。特别地,第二优化步骤包括:
[0278]
‑‑
基于似然函数为至少一个可变演化参数提供一组可能值;
[0279]
‑‑
进行第三优化步骤以提供效用计数;
[0280]
‑‑
如果存在至少另一组合适的可能值,则对至少另一组可能值重复第三优化步骤,从而获得多个效用计数;
[0281]
‑‑
通过根据似然函数加权效用计数来计算效用得分。
[0282]
每次执行第二优化步骤时,配方模板组合和可变配方参数的输入值集都是“固定的”。在第二优化步骤中,第三优化步骤的重复表示第三个最外面的循环,嵌套在输入值集的第二个最外面的循环内。
[0283]
第三个最外面的循环是对可变演化参数的可能值的可能集合的循环,然而该循环仅涉及任选地多次迭代,即仅当存在多于一组合适的可能值时。在一些情况下,仅考虑可变演化参数的一组可能值,并因此,第三个最外面的循环“折叠”为单次迭代。
[0284]
如果配方模板组合包括多于一个配方模板,则在一些情况下,相同的可能值可用于模拟时的可变演化参数,而与所考虑的特定配方模板无关。因此,如果只有一个可变演化参数,则每组可能值可以包括一个可能值,或者如果存在更多可变演化参数,则可以包括多个可能值。在其他情况下,当使用不同的配方模板进行模拟时,可能会使用不同的可能值。因此,即使当只有一个可变演化参数时,每组可能值也可以包括对应于配方模板组合中的
多个配方模板的多个可能值。
[0285]
可能值的集合是基于似然函数来选择的,它可以包含不同类型的知识并可以采用不同的形式,如上文解释的。换言之,一个或多个可能值是从似然空间中抽取的点。
[0286]
在一个实例中,可能值可以是根据似然函数的最大似然估计,即最大化似然函数的值。在这种情况下,找到可变演化参数的可能值是一个最大化问题,其中通过系统地从允许的集合中选择值并计算似然函数的值来最大化似然函数。取决于可变演化参数的数量,最大化问题可能是一个多维问题。数值方法,如monte-carlo模拟,或算法,例如nelder-mead方法,可用于解决最大化问题。在一些情况下,可能需要使用多个起始值进行最大化,因为正在探索的似然空间可能是高度非线性的并且可能表现出多个最大值。
[0287]
根据这个例子,可能只有一组使似然函数最大化的可能值,在这种情况下,第三个最外面的循环不是实际循环,或者可能有不止一组使似然函数最大化的可能值,在这种情况下,对每个集合重复第三优化步骤。
[0288]
在另一实例中,可能值可以从似然空间中取样,其中例如取样可以满足给定的约束条件,如似然函数假定一个大于特定预定或可预定阈值的值。取样可以可替代地是随机的。同样根据这些实例,可能存在一组或多组可能值。如果考虑多于一组的可能值,则可能值的不同组的数量,即第三优化步骤的迭代次数,可以是固定的预定数量,或者可以在每次执行该方法时设置,例如由用户设置,或动态确定,例如,基于来自连续样本结果的可变性。
[0289]
第三个最外面的循环的结果是将效用计数与每组可能的值相关联,这将在后面解释。除了不同组可能值的潜在循环之外,第二优化步骤包括基于一个或多个效用计数计算效用得分。
[0290]
效用计数是与某一配方模板组合、某组输入值和可变演化参数的某组可能值相关联的数值。在某种意义上,效用计数可以看作是这三个因素的函数(效用计数函数),且在计算效用得分时,“消除”了对可能值集合的依赖。具体来说,这是通过组合不同的效用计数来实现的,每个根据演化参数值正确描述过程演化的概率,即似然函数进行加权。
[0291]
在一个实例中,效用得分us(对于某一配方模板组合和某组输入值)可获得为
[0292]
us=∫ut(p)l(p)dp
ꢀꢀꢀ
(4)
[0293]
其中ut是效用计数函数,p表示演化参数的向量(或元组),且l是似然函数。方程(4)是一个示意性方程,其中可能省略了其他细节以说明计算效用得分的基本概念,即在演化参数的空间上进行积分。效用计数函数不是一个公式化为分析表达式的函数,而是通过考虑与不同的可能值集相关的不同效用计数来进行数值评估。
[0294]
如果只考虑一组可能值p’,它可以解释为似然函数是一个以p’为中心的diracδ函数,因此us=ut(p’)。
[0295]
根据上述方程,效用得分可以认为是效用计数函数的期望值。在其他实例中,可以考虑效用计数函数的更高矩,如方差。
[0296]
总而言之,第二优化步骤为给定的配方模板组合提供效用得分,并为可变配方参数提供一组给定的输入值,然后如上所述对其进行优化。可以示例性地存储每个效用得分,例如在诸如硬盘等存储设备中。
[0297]
如上所述,第三优化步骤提供了一个效用计数,它是通过潜在地循环不同的随机实现来获得的。特别地,第三优化步骤包括:
[0298]
‑‑
进行第四优化步骤以提供效用值;
[0299]
‑‑
如果设置了随机性标志,则重复第四优化步骤,从而获得多个效用值;
[0300]
‑‑
计算效用计数作为效用值,或通过混合多个效用值。
[0301]
每次执行第三优化步骤时,配方模板组合、可变配方参数的输入值集和可变演化参数的可能值集都是“固定的”。在第三优化步骤中,第四优化步骤的重复表示第四个最外面的循环,嵌套在可能值集的第三个最外面的循环内。
[0302]
第四个最外面的循环是一个循环,它使用相同的标称输入创建多个模拟版本(模拟的生成是第四优化步骤的一部分),以考虑生产过程中的潜在变化。然而,该循环仅涉及任选的多次迭代,即仅在考虑随机性的情况下。如果不考虑可变性,则第四优化步骤仅执行一次,并因此,第四个最外面的循环“折叠”为单次迭代。
[0303]
生产过程中的随机性可能是由于设备或机器的可变性和/或过程演化可变性。实际上,在现实生活中模拟或执行生产过程的方式是由配方及其配方参数决定的。然而,实际上,配方需要由过程设备实施,并且配方参数被“转换”为设备参数(也称为“机器参数”或“设置参数”)。机器参数描述特定设备设置如何根据配方参数执行配方步骤。对于给定的设备设置,配方参数和机器参数之间的“映射”是固定的。然而,与配方参数不同的是,机器参数可能会受到随机性的影响。
[0304]
设备可能将随机性引入生产过程中的方式可能包括但不限于:
[0305]-液体添加量或时间的变化
[0306]-取样体积或时间的变化
[0307]-添加液体中化学或其他浓度的测量错误
[0308]-ph测量的精度/时间不完善(在反馈回路中)
[0309]-温度测量的准确度/时间不完善
[0310]-其他系统测量的准确度/时间不完善,例如co2、活细胞密度(vcd)、do、体积等。
[0311]-机械运动的可变性,例如搅拌,摇晃
[0312]-与控制方法相关的容器几何形状产生的化学或物理梯度。
[0313]
下表中报告了一些配方参数和机器参数之间的示例性对应关系:
[0314]
通过在模拟时考虑配方参数到机器参数的映射,可以在模拟运行中引入会影响生
产过程实际运行的随机性。例如,可以通过在模拟中使用随机微分方程或通过在模拟期间从分布中取样来引入随机性,分布本身由机器参数决定。下面在设置规范的上下文中进一步讨论随机性是由机器可变性引起的情况。
[0315]
如已经提到的,另外或可选地,随机性可能是过程演化本身所固有的。在这种情况下,过程演化信息可能是随机的。例如,细胞生长的随机模型可能是:
[0316]
dr=a dw,r(t=0)=n(r
g,c
,r
g,s
)
[0317]
dρ=rρdt,
[0318]
其中演化参数a、r
g,c
和r
g,s
(分别为生长速率漂移、平均初始生长速率和初始生长速率变化)驱动随机性,并且其中w是wiener过程,ρ是细胞密度,且n是具有指定均值和标准差的正态分布。
[0319]
因此,在第三优化步骤中,如果设置了随机性标志,则多于一次执行第四优化步骤(起将在下面讨论),即模拟的生成。随机性标志向执行该方法的计算机系统发出信号,表明需要重复第四优化步骤。
[0320]
随机性标志可以在方法开始执行之前设置或者可以在运行中设置。它可以是一个标志,指示第四优化步骤应重复多少次,例如非boolean标志。可选地,标志可以是boolean,即仅指示是否必须发生重复,并且重复次数可以从查找表中检索或由用户根据提示输入。可以进一步根据过程模拟的连续迭代的结果动态地确定重复次数。随机性标志可以存储在易失性或非易失性存储器中。
[0321]
第四优化步骤的结果是效用值。效用值是与某一配方模板组合、某一输入值集、可变演化参数的某一可能值集和某一模拟运行相关联的数值。如果模拟运行受到随机性的影响,则可以减轻随机性的影响,或者以其他方式明确地将其视为通过混合的多个效用值来确定过程的最优配方的一个因素,如下文解释的。
[0322]
如果模拟中没有引入随机性(即未设置标志),则仅执行第四优化步骤,并且仅通过将其设置为等于从第四优化步骤获得的单个效用值来计算效用计数。
[0323]
如果在模拟中引入了随机性(即设置了标志),则至少重复第四优化步骤一次,并从而获得多个效用值。在这种情况下,效用计数是通过混合多个效用值来计算的。“混合”意味着以有意义的方式组合效用值以解决随机性问题。
[0324]
示例性地,混合可以包括计算效用值之外的统计数据,例如位置(平均值、中位数、众数
…
)、散布(标准差、方差、平均绝对差
…
)、形状(偏度、峰度
…
)。在一个实例中,效用计数可以是效用值的平均值,从而减轻随机性的影响。在另一实例中,确定配方中的部分优化可以是减少随机性,从而效用计数可以是效用值的平均绝对差。在这种情况下,第一优化步骤中的效用得分通过找到最小值来优化。
[0325]
总而言之,第三优化步骤为给定的配方模板组合、给定的一组可变配方参数的输入值和给定的一组可变演化参数的可能值提供了效用计数,然后将其用于计算效用得分,如上文所述。可以示例性地存储每个效用计数,例如在诸如硬盘等存储设备中。
[0326]
如上所述,第四优化步骤提供了一个效用值,它是从模拟轨迹中获得的,并且可能通过循环不同的配方模板来获得。特别地,第四优化步骤包括:
[0327]
‑‑
通过使用配方模板组合中的配方模板模拟所述生产过程的执行来生成模拟,所述配方模板组合具有用于至少一个可变配方参数的一组输入值、过程演化信息和用于至少
一个可变演化参数的一组可能值;
[0328]
‑‑
如果配方模板组合包括多于一个配方模板,则对配方模板组合中的每个配方模板重复生成模拟的步骤;
[0329]
‑‑
从一个或多个模拟中确定过程变量的轨迹,其中轨迹对应于在生产过程的模拟执行期间可记录的值的基于时间的特征;
[0330]
‑‑
通过使用轨迹的过程变量和映射评估效用函数,来计算效用值。
[0331]
生产过程执行的模拟(或“模拟运行”)是通过计算机系统的方式在现实世界中对生产过程的执行进行的模拟。
[0332]
基于配方模板组合中的给定配方模板和可变配方参数的一组输入值生成模拟,其共同提供配方,以及具有可变演化参数的一组可能值的过程演化信息。配方提供了对要模拟的过程的描述,而过程演化信息提供了过程变量的初始条件并模拟了过程随时间的演化。
[0333]
在第四优化步骤中,重复生成模拟代表最里面的循环,嵌套在第四个最外面的循环内以实现随机性。最里面的循环是为配方模板组合中的每个配方模板生成模拟的循环。然而,该循环仅任选地涉及多个迭代,即仅当配方模板组合包括多个配方模板时。如果配方模板组合仅包含一个配方模板,则仅执行一次模拟,并因此最里面的循环“折叠”为单次迭代。
[0334]
任选地,所述方法可以包括检索设置规范(也称为“机器规范”)。设置规范包括有关用于执行生产过程的过程设备设置的信息,如设备的规模值,例如以升表示的生物反应器的容量。此外,设置规范可以包括设置的组件中的至少一个及其特性,例如,指定设备包括叶轮,以及任选地叶轮类型等。而且,设备的其他特性可以通过参考产品模型来表示,例如sartorius换句话说,设置规范描述了用于执行生产过程的设备。
[0335]
此外,设置规范是指设置(机器)的属性,其在过程规范(在配方中)和系统动态(在演化参数中)之间进行调解。
[0336]
设置规范的一个实例可能是带有标准分布器和哺乳动物叶轮的250生物反应器或带有环形分布器和两个3叶片叶轮的sartorius50。
[0337]
如上文解释的,配方参数对过程变量的时间演化的影响,如由过程演化信息支配的,可以由机器设置,且特别是由该机器设置识别的机器参数来调节(或调制)。这可能会在模拟运行中引入随机性。实际上,带有其配方参数的配方决定了机器所设置的运行方式。对过程动态的影响由机器调节。因此,机器参数决定了机器所需的行为(如由配方规定的)如何映射到其实际行为(如由所需行为和机器参数的组合确定的)。然后设置的实际行为与过程演化信息交互以确定过程变量如何随时间演化。
[0338]
示例性地,设置规范可以封装关于用于温度控制的反馈回路的信息,特别是在机器加热或冷却培养物以响应与设定点的偏差的方式方面,以及在与设定点的偏差方面的随机性方面。通过实例的方式,培养容器内的温度可以通过如下所示的随机微分方程建模
[0339]
dt=(f,dt) a(t*-t)dt
[0340]
其中ε(f,dt)是噪音项,或者例如等效地:
[0341]
dt=a(t*-t) f dw
[0342]
其中w是wiener过程。在本实例中,f和a都是机器参数,且t*是当前温度设定点,如
配方所示。在这种情况下,随机性然后通过例如生长速率对温度的依赖关系影响轨迹。该效应可以通过随机微分方程系统建模
[0343]
dt=a(t*-t) fdw
[0344]
dρ=r
g n(t-t
opt
,σ)ρdt
[0345]
其中a、f和以前一样是机器参数,t*来自配方的模拟,和以前一样,t是作为时间函数的温度,w是wiener过程,ρ是细胞密度,t
opt
、σ和rg是演化参数,分别为最佳温度、温度敏感性和最大生长速率,n是具有指定均值和标准偏差的正态分布。上述系统的解在t和ρ中都是随机的。
[0346]
从模拟推导出过程演化期间不同时间过程变量的值,以获得轨迹。每个轨迹可以被理解为总结和提供相关过程变量的概览。每个轨迹可以表示为曲线或图形,其描述在模拟执行生产过程期间过程变量的时间演化。特别地,每个轨迹可以包括多个点,这些点表示对应于不同时刻的变量的值。例如,连续点之间的时间单位可以是一小时。在替代实例中,连续点之间的时间单位可以是十秒或天。时间单位也可以在轨迹内不均匀地间隔开。
[0347]
如果配方模板组合中只有一个配方模板且只有一个过程变量,则只确定一个轨迹。在所有其他情况下,确定多个轨迹。
[0348]
如上文解释的,效用函数至少取决于性能指标。性能指标的值可以通过检索到的映射的方式从过程变量的值获得,并且过程变量的值从模拟获得。因此,效用函数可以经由映射基于轨迹进行评估。如上文已经解释的,在一些情况下,过程变量本身可能是性能指标,且映射只是恒等函数。一般来说,如果u是效用函数,i是性能指标的元组,m是映射,且v是过程变量的元组,u(i)=u{m[v(t)]}。在第四优化步骤中计算的效用值通常可以是效用函数输出的函数,即uv=f[u(i)。示例性地,uv=u(i)。
[0349]
在一些实例中,效用函数可以随时间累积评估以便计算效用值。换句话说,如果轨迹点(即过程变量随时间的不同值)对应于时间t1,t2…
tn,则效用值可以计算为或在选定时间点的效用值的一些其他组合。在其他实例中,效用值可以对应于在单个时间评估的效用函数,例如tn。
[0350]
在一些情况下,一个或多个可变配方参数中的每一个可以是时间点。例如,可能只有一个可变配方参数,即收获时间。在第一优化步骤中循环输入值集的目的是获得与不同输入值集相关的效用得分,在这些特定情况下,这意味着获得与不同时间点相关的效用得分。在这种情况下,轨迹已经提供了作为时间函数的过程变量的值,因此可能直接从轨迹获得多个效用得分(经由其间的步骤)。因此,在这些特定情况下,可以省去第二个最外面的循环。
[0351]
如果配方模板组合中有多于一个配方模板,即如果要执行并行或顺序运行,则应考虑整体效用。在一个实例中,计算效用值可以包括组合部分效用值,每个部分效用值与配方模板相关联。效用价值可以例如由部分效用值的算术平均值、几何平均值、总和或乘积给出。
[0352]
在另一实例中,如上所述,到性能指标的映射可能已经考虑了给定过程变量的多个轨迹,每个轨迹对应于配方模板组合中的不同配方模板。在这种情况下,对于配方模板组合中的m个配方模板,映射m可以是m(v1(t),v2(t),
…vm
(t)),其中vj(t)是与第j个配方模板相关联的过程变量v的轨迹。
[0353]
在又一实例中,如上所述,效用函数本身可以将对应于利用配方模板组合内的不同配方模板的模拟运行的性能指标的输入值,即u{m[v1(t)],m[v2(t)],
…
m[vm(t)]}。
[0354]
总而言之,第四优化步骤为给定的配方模板组合提供了效用值、一组给定的可变配方参数的输入值和一组给定的可变演化参数的可能值,然后将其用于按如上所述计算效用计数。可以示例性地存储每个效用值,例如在诸如硬盘等存储设备中。
[0355]
总之,从效用函数到其优化形式的路径,即得分函数,可以——仅示例性地——描述如下(为清楚起见,假设配方模板组合仅包含一个配方模板):
[0356]
1)计算全部与某个配方模板组合和某组输入值相关联的多个效用值,每个效用值uvi与一组不同的可能值相关联。关联源于这样一个事实,即通过评估效用函数来计算某个效用值,所述效用函数经由映射以过程变量的模拟值作为参数,并且使用某个配方模板组合r1、可变配方参数的某组输入值rp1和可变演化参数的某组可能值pp1运行模拟。因此,过程变量的值取决于这些输入,因此其可以写成因此,效用值也取决于这些输入,使得决于这些输入,使得
[0357]
2)在考虑随机性时,每个效用值都有一个或多个副本,例如其被复合以得到效用计数,例如通过取平均值用计数,例如通过取平均值然后,多个效用计数是ut1|《r1,rp1,pp1》,ut2|《r1,rp1,pp2》,...,utn|《r1,rp1,ppn》。从这些效用计数中,效用计数函数ut(pp)|《r1,rp1》可以被数值定义,其中效用计数函数是演化参数的值的函数,即可能的值。如果不考虑随机性,则效用计数函数简化为效用值函数uv(pp)|《r1,rp1》。
[0358]
3)与配方模板组合r1和输入值集rp1相关联的效用得分是通过根据似然函数对效用计数加权来获得的,例如us1|《r1,rp1》=∫l(pp)
·
ut(pp)|《r1,rp1》dpp,其中pp可以是向量,如果是多个可变演化参数,使得积分可以是多维的。这样,可以计算多个效用得分us1|《r1,rp1》,us2|《r1,rp2》
…
,usk|《r1,rpk》,并且同样地,这些得分可以用来在数值上定义一个函数,即得分函数us(rp)|《r1》。当一个函数用数字表示时,它由值对列表(rp1,us1|《r1,rp1》),(rp2,us2|《r1,rp2》)
…
,(rpk,usk|《r1,rpk》)定义。考虑到每个效用得分是如何获得的,得分函数和效用计数函数之间的关系可以以紧凑的形式写为us(rp)|《r1》=∫l(pp)
·
ut(pp)|《r1,rp》dpp,如果不考虑随机性,则ut变为uv。
[0359]
上面示出的步骤1-3提供了关于如何从效用函数得出得分函数的一般数学形式;然而,它们并不意味着涵盖所有可能的情况。如前面已经详细解释的,例如,在一些情况下只计算一个效用值,或者考虑效用计数函数的更高矩。
[0360]
在特定实例中,所述方法可以进一步包括将至少一个配方提供给控制系统,并且由控制系统基于至少一个配方执行生产过程。
[0361]
换言之,通过上述方法选择的具有相对输入值的配方模板组合可以直接馈送到控制系统,所述控制系统配置为控制设置设备以执行该过程。在包含多个配方模板的配方模板组合的情况下,所述过程并行或顺序运行多次,例如在多个生物反应器上。
[0362]
当在现实世界中执行生产过程时,结果可用于为正在进行的运行和/或未来的运
行提供反馈。因此,所述方法还可以包括将来自执行的生产过程的数据存储为历史数据,和/或将来自执行的生产过程的数据存储为当前数据。
[0363]
本文描述的方法,或至少其方面,可以在扩大生产过程的范围内应用。化学、制药和/或生物技术产品的生产过程取决于规模;换句话说,与大规模(例如,在生产中)相比,一个过程在小规模(例如,在实验室中)上表现至少部分不同。通常,过程首先以小规模进行,然后以连续更大的规模进行。在下文中,将考虑两个示例性缩放场景,即从用于过程开发的规模缩放到用于制造的规模,以及从用于克隆选择的规模缩放到用于过程开发的规模。
[0364]
过程开发场景
[0365]
在这种情况下,过程开发处于源规模a,且制造处于目标规模b。可以有两个配方空间α和β,其分别包含规模a和b的配方模板组合。目标可能是在规模a上找到配方(配方模板组合加上可变配方参数的值),当规模扩大时,它将优化规模b的生产过程的执行。
[0366]
与上述类似,可以检索一个或多个配方模板组合(从空间α),以及过程演化信息和似然函数。选择配方模板组合,将一组输入值分配给可变配方参数,并根据似然函数将一组可能值分配给可变演化参数。使用所有这些输入,可以模拟规模a的生产过程,从而获得过程变量的一个或多个轨迹,例如对应于组合中的不同配方模板的轨迹。
[0367]
与上述关于同类数据、当前数据和历史数据的描述类似,模拟数据,即轨迹也可以用作创建后验分布的证据。换言之,可以基于作为先验的检索的似然函数以及作为证据的模拟数据来计算更新的似然函数。
[0368]
然后可以针对规模b执行用于确定至少一个最佳配方的上述方法,其中配方模板组合取自空间β,并且检索到的似然函数是先前获得的更新的似然函数。因此,可以获得规模b的配方。
[0369]
可选地,可以经由以下方式获得规模b的配方:(a)一般缩放程序,(b)doe方法和线性/二次曲线拟合,(c)欧洲专利申请18 000 132中描述的方法,(d)(a)-(c)的一些组合。
[0370]
不管如何获得规模b的配方,它都可以与过程演化信息和从更新的似然函数中提取的演化参数值一起用于在规模b上执行模拟。从模拟中获得的轨迹,可以在规模b上评估效用函数,其中效用函数的输出量化规模b下执行生产过程的整体价值或收益。
[0371]
正如上面参考效用函数的特征所提到的,效用函数的输出间接依赖于似然函数。在这种情况下,从规模a的模拟轨迹获得的更新的似然函数用于规模b的模拟。因此,效用函数的输出将间接取决于规模a的模拟输入,特别是所选的配方模板组合和分配给可变配方参数的一组输入值。
[0372]
因此,数值优化方法可用于在规模a上找到配方模板组合和可变配方参数的输入值集,其优化规模b上的效用函数的输出。以这种方式,可以确定在缩放时将优化规模b上的过程执行的规模a上的配方(配方模板组合加上可变配方参数值)。
[0373]
如上所示的更新似然函数的计算可以作为一个独立的准备步骤来执行,以用于确定考虑到未来制造的过程开发规模的最优配方。可选地,更新的似然函数可以在执行仅根据本发明的方法时被计算和存储,以用于确定规模a的配方。在这种情况下,如果稍后要考虑缩放到b,则更新的似然函数可能已经可用。因此,在特定实例中,所述方法还可以包括基于轨迹更新似然函数并存储更新的似然函数。
[0374]
克隆选择场景
[0375]
在这种情况下,克隆选择处于源规模a,且过程开发处于目标规模b。可能有两个配方空间α和β,其分别包含规模a和b的配方模板组合。目标可能是找到规模a的克隆,其将在规模b下执行生产过程时优化执行。
[0376]
与上述类似,可以检索一个或多个配方模板组合(从空间α),以及过程演化信息和似然函数。在这种情况下,配方空间α中的每个配方模板组合包含多个配方模板,其中每个配方模板与一个克隆相关联。在典型情况下,这里的配方模板是相同的,尽管在替代实现中,多个不同的配方模板可能与每个克隆相关联,例如一组模板(d、e、f)可用于所有组合中的克隆(1、2、3、4),即d1、d2、d3、d4、e1、e2、e3、e4、f1、f2、f3、f4。
[0377]
选择配方模板组合,将一组输入值分配给可变配方参数,并根据似然函数将一组可能值分配给可变演化参数。特别地,该组可能值g包括对应于多个克隆的多个子集g1,...,gn。因此,每个子集被分配给所选配方模板组合中的一个配方模板。
[0378]
使用所有这些输入,可以模拟规模a的生产过程,从而获得过程变量的多个轨迹,其中,对于给定的过程变量,获得对应于多个克隆的多个轨迹t1,...,tn。
[0379]
基于轨迹,可以识别最佳克隆,例如通过使用轨迹的值评估一些度量。可以使用性能指标和/或效用函数,类似于在上述用于确定最优配方的方法中使用它们的方式。
[0380]
一旦选择了最佳克隆,可变演化参数的相关值子集gb可以与过程演化信息和配方一起使用,以执行规模b的模拟。配方(即来自空间β的配方模板组合及其可变配方参数的值)可以使用根据本发明的方法来确定。
[0381]
从模拟中获得的轨迹,可以在规模b评估效用函数,其中效用函数的输出量化规模b的生产过程性能的整体价值或收益。
[0382]
如上面参考效用函数的特征所提到的,效用函数的输出间接地取决于演化参数的值。在这种情况下,演化参数的值与给定的克隆相关联。因此,效用函数的输出将间接取决于在规模a选择的克隆。
[0383]
因此,数值优化方法可用于在规模a上找到克隆,其优化规模b上的效用函数的输出。
[0384]
根据本发明的另一方面,提供了计算机程序产品。计算机程序产品包括计算机可读指令,当在计算机系统上加载和执行时,计算机可读指令使计算机系统执行如上所述的操作。计算机程序产品可以有形地体现在计算机可读介质中。
[0385]
本发明的又一方面涉及计算机系统,其可操作地确定生产化学、药物和/或生物技术产品的生产过程的至少一种配方,其中所述生产过程由控制生产过程执行的配方参数指定的多个步骤定义,并且配方包括定义生产过程的多个步骤。计算机系统包括:
[0386]-检索模块,其配置为检索:
[0387]
‑‑
一个或多个配方模板组合,其中配方模板组合包括一个或多个配方模板,并且配方模板是这样的配方,其中指定多个步骤的至少一个配方参数是可变的且在开始时没有预定值的可变配方参数;
[0388]
‑‑
过程演化信息,其描述了描述生产过程状态的过程变量的时间演化,其中所述过程演化信息包括演化参数,并且至少一个演化参数是可变的且在开始时没有预定值的可变演化参数;
[0389]
‑‑
演化参数的似然函数,其中所述似然函数提供演化参数的值对于生产过程可行
的可能性;
[0390]
‑‑
将过程变量映射到性能指标的映射;
[0391]
‑‑
至少一个性能指标的效用函数,其中所述效用函数提供与性能指标相关的合意性值;
[0392]-计算模块,其配置为选择配方模板组合并执行第一优化步骤,包括:
[0393]
‑‑
提供配方模板组合中的至少一个可变配方参数的一组输入值;
[0394]
‑‑
进行提供效用得分的第二优化步骤;
[0395]
‑‑
对至少另一组输入值重复第二优化步骤,从而获得多个效用得分;
[0396]
‑‑
从多个效用得分中鉴定最优的效用得分;
[0397]
其中计算模块进一步配置为在仅检索到一个配方模板组合时,选择产生最优效用得分的一组输入值以及一个配方模板组合作为生产过程的至少一个配方;
[0398]
或者计算模块进一步配置为在检索到多于一个配方模板组合时:
[0399]-对每个配方模板组合重复第一优化步骤,从而获得多个最优效用得分;
[0400]-从多个最优效用得分中鉴定最佳的最优效用得分;
[0401]-选择配方模板组合和产生最佳的最优效用得分的一组输入值作为生产过程的至少一个配方;
[0402]
并且其中:
[0403]-所述第二优化步骤包括:
[0404]
‑‑
基于似然函数为至少一个可变演化参数提供一组可能值;
[0405]
‑‑
进行第三优化步骤以提供效用计数;
[0406]
‑‑
如果存在至少另一组合适的可能值,则对至少另一组可能值重复第三优化步骤,从而获得多个效用计数;
[0407]
‑‑
通过根据似然函数加权效用计数,计算效用得分;
[0408]-所述第三优化步骤包括:
[0409]
‑‑
进行第四优化步骤以提供效用值;
[0410]
‑‑
如果设置了随机性标志,则重复第四优化步骤,从而获得多个效用值;
[0411]
‑‑
计算效用计数作为效用值或通过混合多个效用值;
[0412]-所述第四优化步骤包括:
[0413]
‑‑
通过使用配方模板组合中的配方模板模拟所述生产过程的执行来生成模拟,所述配方模板组合具有用于至少一个可变配方参数的一组输入值、过程演化信息和用于至少一个可变演化参数的一组可能值;
[0414]
‑‑
如果配方模板组合包括多于一个配方模板,则对配方模板组合中的每个配方模板重复生成模拟的步骤;
[0415]
‑‑
从一个或多个模拟中确定过程变量的轨迹,其中轨迹对应于在生产过程的模拟执行期间可记录的值的基于时间的特征;
[0416]
‑‑
通过使用轨迹的过程变量和映射评估效用函数,来计算效用值。
[0417]
换言之,计算机系统可操作以执行根据上述方面的方法。
[0418]
计算机系统可以特别包括存储器和处理器以操作模块。检索模块和计算模块可以是单独的实体或者可以至少部分地彼此重叠。
[0419]
此外,计算机系统可以配置为经由网络、共享磁盘或数据库系统与控制系统接口,其中控制系统控制现实世界中生产过程的执行。接口可以特别允许数据和/或命令的传输。在一些实例中,计算机系统可以与控制系统一致。
[0420]
总而言之,上面讨论的方法、产品和系统能够确定生产过程的最优配方,其中可以在执行之前或在过程执行期间确定配方,从而支持动态配方调整。
[0421]
在生产过程运行之前确定配方的实例包括以下场景:
[0422]
ο优化性能指标的配方;
[0423]
ο确保一个规模的系统准确地向第二规模的系统提供可转移的预测的配方;
[0424]
ο评估培养条件变化的非线性影响的配方;
[0425]
ο评估用于生产分子的一组克隆的配方。
[0426]
在生产过程运行期间确定(即调整)配方的实例包括以下场景:
[0427]
ο使配方适应意外情况(例如,如果在执行期间发生机器故障,确定对配方进行哪些修改以尽可能恢复)
[0428]
ο根据运行期间获得的先前信息调整配方(即,如果在运行的中点,来自该运行的数据告知关于生物体性质或过程动态的信息,从该点进行的最佳运行可能与最初的设计不同)。
[0429]
此外,根据本发明,可以充分且准确地考虑关于过程的知识,特别是最小化在其整个过程中对生产过程的假设的作用。特别地,由于使用了可变演化参数的似然函数并考虑了多个配方模板组合,因此可以通过在整个优化程序中保持概率景观来解释不知情。另外,通过使用相关性信息,可能在不同生物体、细胞类型、介质等之间传递过程知识。
[0430]
因此,上述方法、产品和系统可以成功地用于许多不同的背景中,下面报告了其中一些,以及对每种情况下传统方法问题的解释:
[0431]
细胞系选择
[0432]
在细胞系选择阶段,使用只是已知大规模目标过程的配方的“按比例缩小”模型的配方无法承认最佳“细胞系和配方”组合可能包含与将针对一些(基本上是任意的)配方选择的细胞系不同的细胞系。例如,给定两种配方a和b,以及两种细胞系1和2,其中配方a是标准的“平台”配方,在规模和细胞系(克隆)选择期间的性能可以排名为b1》a2》b2》a1。然而,仅使用平台配方进行克隆选择,就会选择细胞系2,从而最终导致性能低于最优水平。
[0433]
在组织进行细胞系选择的时间点,它通常可以访问来自先前分子开发过程的数据。这提供了确定候选克隆集中预期变化的先前估计的机会。这种估计有可能用于在克隆选择期间驱动配方设计(以期随后扩大生产规模)。由于多个配方模板组合和可变演化参数提供的自由度,本发明提供了这样做的机制。
[0434]
过程开发
[0435]
在过程开发阶段,可以评估的潜在有益配方变化的范围受到可用时间和来自由配方参数(例如ph设定点)与时间(例如何时执行ph设定点的变化)的交互引起的实际上无限数量的可能性的来源的限制。因此,过程开发通常限于可能的配方参数值范围的一个非常小的子空间,并且在这个子空间内,可以根据生物系统的线性行为得出结论。
[0436]
目前,无法预先确定所探索的子空间本身是接近最优还是远离最优,以及该子空间内的线性假设是否合理。例如,可以进行一系列实验以确定在培养20小时后ph从7到6.6、
6.7或6.8的转换是否是最优的,并结合20、25和30的do%设定点,使用doe。结果可能是一个结论,经由ph值和do响应面的统计建模(例如,拟合低次多项式和基于拟合表面确定最佳值),ph 6.65和do 23%是最佳值。然而,如果例如对ph的响应是高度非线性的,6.6比6.7差很多,其本身只比6.8差一点,这可能是不明智的。同样,它可能是不明智的,因为真正的最佳值可能是培养15小时而不是20小时后ph值的变化。
[0437]
本发明提供了一种机制,通过该机制可以探索配方参数的适当子空间并确定它们对于给定过程的最优值。
[0438]
转移到制造
[0439]
以前放大和转移到制造的方法只考虑模拟模型的最可能参数,这些参数驱动放大配方的选择。这些方法具有本发明解决的缺陷,即使用具有固定演化参数的单一模型来模拟目标制造规模。确实存在模型选择权重过高的风险(放大优化因此对使用系统的人的定性理解反应过于强烈)。此外,对最优配方的确定可以:(a)对过程条件的偏差缺乏鲁棒性,(b)由于相关过程的固有非线性而是次最优的。
[0440]
过程中偏差
[0441]
在过程执行期间,由于生物、化学或物理系统的随机变化或部分设备的故障或损坏,可能会出现与预期条件的偏差。众所周知,“基于模型的控制”是应对这种偏差的有力方法。传统的基于模型的控制涉及例如调整设定点以恢复平衡或过程的原始轨迹。它采用过程模型,并根据偏差,通过模拟受模型影响的过程来确定最佳调整设定点。
[0442]
这种基于模型的控制有两个重要的缺陷:
[0443]-从那时起,它未能优化配方。相反,它以逐步的方式进行调整。这具有选择局部但不一定是全局最优的效果。
[0444]-它未能考虑模型中的不确定性。这有两层:首先,模型中的(演化)参数存在不确定性,其次,模型本身的选择存在不确定性。结果是,mbc可能导致与最佳值的偏差越来越大,因为该过程逐渐偏离了更好表征的最佳值(即,存在过程中坏行为螺旋式上升的风险)。
[0445]
本文提出的发明解决了上述两个缺陷。
[0446]
值得注意的是,上文讨论方法的相同原理可以应用于解决与寻找最优配方不同的问题,即效用函数的定义。实际上,深入了解如何以可量化、客观的方式系统地评估生产过程等复杂过程的性能可能会有用。因此,可能存在一个或多个与效用函数的属性有关的循环(例如,其中的参数、对性能指标的依赖关系
……
),而不是配方模板组合、可变配方参数和配方模板上的循环。
[0447]
附图的简要说明
[0448]
下面参照示例性附图阐述示例性实施方案的细节。从描述、附图和权利要求中,其他特征将是显而易见的。然而,应当理解,即使实施方案被单独描述,不同实施方案的单个特征也可以组合到进一步的实施方案中。
[0449]
图1显示了确定生产化学、药物或生物技术产品的生产过程的配方的计算机系统。
[0450]
图2显示了指示配方确定的输入和输出的框图。
[0451]
图3a-3e显示了确定生产过程的配方的方法。
[0452]
图4显示了配方确定方法的嵌套循环。
[0453]
图5a-5c显示了代表配方确定的一些输入的示例性图。
[0454]
图6a-6d显示了示例性配方确定的概念图和相关图。
[0455]
图7a-7f显示了另一示例性配方确定的概念图和相关图。
[0456]
图8a-8c显示了又一示例性配方确定的概念图和相关图。
[0457]
图9a-9e显示了另一示例性配方确定的概念图和相关图。
[0458]
详细描述
[0459]
在下文中,将参照附图给出实例的详细描述。应当理解,可以对实例进行各种修改。除非另有明确说明,否则一个实例的元素可以组合并用于其他实例以形成新的实例。
[0460]
图1显示了确定生产化学、药物或生物技术产品的生产过程的至少一种配方的计算机系统10。
[0461]
计算机系统10可以包括处理单元、系统存储器和系统总线。系统总线将包括系统存储器在内的各种系统组件耦合到处理单元。处理单元可以通过访问系统存储器来执行算术、逻辑和/或控制操作。系统存储器可以存储与处理单元结合使用的信息和/或指令。系统存储器可以包括易失性和非易失性存储器,如随机存取存储器(ram)和只读存储器(rom)。
[0462]
计算机系统10还可包括用于读取和写入硬盘(未示出)的硬盘驱动器,以及用于读取或写入可移动单元的外部单元驱动器。驱动器及其相关联的计算机可读介质为个人计算机920提供计算机可读指令、数据结构、程序模块和其他数据的非易失性存储。数据结构可以包括用于实施上述方法的相关数据。
[0463]
多个程序模块可以存储在硬盘、外部磁盘、rom或ram上,包括操作系统(未示出)、一个或多个应用程序、其他程序模块(未示出)和程序数据。应用程序可以包括如下所述的至少一部分功能。
[0464]
用户可以通过诸如键盘和鼠标等输入设备将命令和信息输入计算机系统10中。监视器或其他类型的显示设备也经由接口连接到系统总线,如视频输入/输出。
[0465]
计算机系统10可以与其他电子设备通信。为了进行通信,计算机系统10可以使用与一个或多个电子设备的连接在网络环境中操作。
[0466]
特别地,计算机系统可以与控制系统20接口和通信。计算机系统10可以是可操作的,可能与其他设备结合,以确定生产过程的配方。
[0467]
控制系统20可以连接到构成用于执行生产过程的设备的生物反应器30。控制系统20和计算机系统10可以位于同一设施的不同空间或任何两个信息连接(例如通过网络)的位置中。计算机系统10可以是与控制系统20分离的实体。在其他实例(未示出)中,计算机系统10可以与控制系统20一致。
[0468]
在一些实例中,可以提供数据库40。数据库可以连接到网络,使得数据库可以被多个设备/用户访问。数据库可以实现为云数据库,即运行在云计算平台上的数据库。换言之,数据库可以经由提供者通过互联网访问,该提供者使共享的处理资源和数据可按需提供给计算机和其他设备。可以使用虚拟机映像或数据库服务来实现数据库。数据库可以使用基于sql或nosql的数据模型。
[0469]
数据库40可以存储以下的任何一种:配方参数的值集、配方模板组合、过程演化信息、设置规范、似然函数、效用函数、映射。数据库40和计算机系统10之间的通信可以是安全的,例如经由互联网协议安全(ipsec)或其他安全协议。也可以使用虚拟专用网络(vpn)。
[0470]
数据库40可以由服务提供商托管,可能在虚拟机上,并且可以由来自多个组织的
各种用户访问,这些组织可能位于世界各地的各种不同地理位置。可选地,数据库40可以在本地托管,例如在计算机系统10中。因此,计算机系统10和数据库40可以位于物理接近处或可以不位于物理接近处。特别地,数据库40可以位于地理上远离计算机系统的位置(例如在另一大陆上)。
[0471]
由计算机系统10确定配方的生产过程的实例可以是包括以下阶段的补料分批过程:
[0472]-将培养基添加到生物反应器
[0473]-条件(设定温度、ph)
[0474]-添加接种物
[0475]-允许在分批阶段中生长(控制ph、do、温度;间隔取样)
[0476]-当营养耗尽时,进入补料阶段
[0477]-允许在补料阶段中生长(控制ph、do、温度;间隔取样;提供额外的营养)
[0478]-收获产品。
[0479]
图3a-3e显示了用于确定生产过程的配方的示例性方法300。所述方法将结合图2和图4进行描述,图2显示了指示配方确定的输入和输出的框图,且图4从其中的嵌套循环的角度显示了该方法。图4分为两半,根据相应的数字在点处连接。在下文中,将结合生物反应器中的生产过程来描述该方法。
[0480]
以图3a开始,在步骤310处,检索一个或多个配方模板组合200,其中每个配方模板组合包括一个或多个配方模板。配方模板是具有一个或多个自由参数,即可变配方参数的配方。
[0481]
此外,在310处,检索过程演化信息210,其中过程演化信息描述了描述生产过程状态的一个或多个过程变量的时间演化。过程演化信息210表征过程变量如何随时间变化,示例性地包括过程变量的初始条件和过程变量之间的关系。
[0482]
特别地,过程演化信息210可以包括从生产过程的先前执行经验地导出的关系,和/或通过关于生产过程的演化的理论模型导出的方程。这些关系和方程可以用称为演化参数的各种参数来表征。这些演化参数中的至少一个可以是自由参数。
[0483]
此外,在310处,检索似然函数220、映射230和效用函数240。似然函数220是演化参数值的概率分布。换言之,似然函数220指示过程演化信息210在给定演化参数的某一值的情况下以准确方式对生产过程建模的可能性有多大。图5a显示了两个演化参数,即生长率和死亡率的似然函数220的示例性图。
[0484]
映射230将过程变量的值转换成性能指标的值。在一些情况下,理解过程变量和生产过程的相关输出之间的联系并不简单,并且映射230正好提供了这种联系。图5b显示了映射230的示例性图,映射230将两个过程变量,即抑制剂浓度和活细胞密度映射到作为性能指标的产品品质。
[0485]
效用函数240通过将合意性值与性能指标的值相关联来对评估生产过程的性能进行进一步的改进。换言之,效用函数240根据其性能指标的值提供过程性能的定量表征。图5c显示了两个性能指标,即产品的滴度和品质的效用函数240的示例性图。
[0486]
配方模板组合200、过程演化信息210、似然函数220、映射230和效用函数240可以通过文件系统的方式进行检索。示例性地,这些输入数据可以存储在数据存储设备中。
[0487]
在320处,选择配方模板组合并执行第一优化步骤。第一优化步骤如图3b所示。在410,为可变配方参数提供一组输入值,并且使用这组输入值,在415执行第二优化步骤,其给出效用得分作为结果。在420,通过对不同组的输入值执行第二优化步骤来获得多个效用得分。第二优化步骤的重复对应于图4中所示的循环510。
[0488]
第二优化步骤如图3c所示。在430处,基于似然函数220为可变演化参数提供一组可能值。一旦分配了一组可能值,即在435执行第三优化步骤,这给出效用计数作为结果。如果还有其他组的可能值需要考虑,则重复第三优化步骤,如图4中的循环520所示。
[0489]
第三优化步骤如图3d所示。在445处,执行第四优化步骤,其给出效用值作为结果。如果考虑随机性,则将第四优化步骤重复预定或可预定次数。第四优化步骤的重复对应于图4中的循环530。
[0490]
第四优化步骤如图3e所示。在455处,基于在320选择的配方模板组合、在410提供的一组输入值和在420提供的一组可能值,生成对生产过程的模拟。在模拟期间,在460处,过程变量的值随着时间的推移被记录以获取轨迹250。如果在320处选择的配方模板组合中存在一个以上的配方模板,则对每个配方模板执行步骤455和460。步骤455和460的重复对应于图4中的循环540。
[0491]
一旦循环540完成,即在465处,通过使用来自轨迹250和映射230的过程变量的值评估效用函数240来计算效用值。
[0492]
一旦已经为相同的配方模板组合、一组输入值和一组可能值获得了一个或多个效用值,取决于是否考虑了随机性,所述方法在450处通过从一个或多个效用值计算效用计数来继续进行。
[0493]
一旦获得了分别对应于一组或多组可能值的一个或多个效用计数,并且对于相同的配方模板组合和一组输入值,在440处,通过利用似然函数220对效用计数加权来计算效用得分。
[0494]
根据在420处获得的多个效用得分,在425处鉴定最优效用得分。换言之,鉴定了优化效用得分的一组最优的输入值。如果只有一个配方模板组合,则该配方模板组合270与一组最优的输入值280组合被确定为生产过程的至少一种配方。
[0495]
如果存在多于一个配方模板组合,则依次选择每个配方模板组合,并且在330处,针对所有剩余的配方模板组合重复第一优化步骤。第一优化步骤的重复对应于图4中所示的最外面的循环500。
[0496]
因此,对应于多个配方模板组合的多个最优效用得分已被鉴定,然后在340处,在其中鉴定了最佳的最优效用得分260,即多个最优效用得分的最大值或最小值。配方模板组合270和与(即导致)最佳的最优效用得分260相关联的一组输入值280的组合在350处被确定为生产过程的至少一种配方。
[0497]
上面参考图2、3a-3e和4说明的一般方法将在下面结合四种具体示例性场景进行讨论。
[0498]
第一种场景
[0499]
图6a-6d显示了示例性配方确定的概念图和相关图。第一种场景涉及简单生长的培养过程。
[0500]
在310处,检索过程演化信息210。该生产过程的模型可以假设活细胞以最大速率r
繁殖,并且随着细胞群接近最大容量,生长减慢。在这种情况下的过程演化信息210包括以下两个微分方程:
[0501][0502][0503]
其中v是活细胞密度(vcd)[细胞/ml],r是细胞生长速率[hr-1
],kv是容量常数的一半[细胞.hr/ml],且iv是累积细胞计数[细胞.hr/ml]。在这种情况下,过程演化信息210仅包括一个可变演化参数,即细胞生长速率。
[0504]
此外,检索包括一个配方模板的单个配方模板组合200,并且该配方模板具有一个可变配方参数,即收获时间。还检索映射230,其中映射230是vcd的函数并且是恒等函数,即vcd本身被认为是性能指标。另外,检索效用函数240,其中效用函数240只是vcd的函数,u(v)=a*log(v),其中a是常数。
[0505]
在本实例中,检索似然函数220包括检索同类数据、相关性信息和历史数据,并基于所有那些来计算似然函数220,如下文解释的。
[0506]
将用于生产过程的细胞类型是b型细胞。可用的先验知识包括b型细胞的历史数据,特别是过程变量db的轨迹和b型细胞生长速率rb的先验知识,源自例如文献或经验,以及与使用a型细胞和相关性信息的同类生产过程相关的同类数据。同类数据包括过程变量da的轨迹,以及a型细胞生长速率ra的先验知识。过程b(使用b型细胞)和过程a(使用a型细胞)之间的相关性信息可以基于细胞系行为的实验/文献知识和/或源自历史数据和同类数据之间的比较。
[0507]
rb的先验知识是区间[0,0.15)内的均匀分布,且ra的先验知识是区间[0.02,0.12)内的均匀分布。对于每种细胞类型x,贝叶斯推断可用于获得后验分布p(r
x
|d
x
)~p(d
x
|r
x
)p(r
x
),其中对于给定的生长速率值,p(r
x
)是先验分布,且p(d
x
|r
x
)是数据的条件分布。可以在每个数据点计算条件分布的值,例如通过假设以均值r
x.
为中心的高斯分布。以这种方式获得的后验分布如图6b所示。
[0508]
在这种情况下,相关性信息是给定ra值的rb值的概率。相关性为r(rb,ra)=n(r
b-ra,σ
ab
),其中n为正态分布。图6c显示了两个相关性图,上图中的方差设置为0.01,且下图中的方差设置为0.02。在这种场景下,假设方差为0.01。
[0509]
上面讨论的可用先验知识合并到ra和rb的联合概率分布中,即p(ra,rb|da,db)~p(ra|da)p(rb|db)r(rb,ra)。需要注意的是,如果不考虑相关性,联合概率会降低到p(ra|da)p(rb|db。图6d显示了没有相关性(左图)和有相关性(右图)的归一化联合概率之间的差异。概率景观受到更多限制,且最大概率区域高出两倍以上。
[0510]
似然函数220,l(rb),被计算为联合概率分布上的积分:
[0511]
l(rb)=∫r(rb,ra)p(rb|db)p(ra|da)draꢀꢀꢀ
(6)
[0512]
在检索到所有必要的输入之后,在320处执行第一优化步骤,其包括为收获时间提供410输入值(一个元素的集合),然后执行415第二优化步骤。第二优化步骤包括基于似然函数220为生长速率提供430可能值(一个元素的集合)。在该实例中,rb的可能值被选为最
可能值,即最大化似然函数的值。然后在435处执行第三优化步骤。生长速率不考虑其他值,这意味着在第二优化步骤中没有循环,并且在440处计算的效用得分将与唯一的效用计数一致。此外,如果不考虑随机性,则通过在445处执行第四优化步骤,在450处计算的效用计数将与在465计算的效用值一致。
[0513]
在第四优化步骤中,在455处,使用方程(5)的过程演化信息210生成模拟,其中具有最可能的生长速率值和给定的初始条件,检索到的仅包括一个配方模板的配方模板组合200,以及收获时间的输入值,例如用ht1表示。从模拟中,在460处获得不同时间的vcd值,即vcd的轨迹。特别地,为了评估效用函数240,可以考虑在与收获时间一致的时间时的vcd值。然后在465处,效用值被计算为u[v(ht1)]。
[0514]
在420重复上述步骤并且获得多个效用得分u[v(ht1)],
…
u[v(htn)],其中n大于或等于2。收获时间的多个输入值可以与配方模板组合一起检索,或由用户输入,或根据某些标准从分布中提取。
[0515]
可选地,在这种非常特殊的情况下,不是执行循环来获得多个效用得分,而是可以使用从单个模拟获得的vcd轨迹来计算u[v(ht1)],
…
u[v(htn)],因为轨迹确实是v(t)。这种“捷径”通常可以应用于可变配方参数是时间点的情况,例如用于执行动作,因为轨迹已经提供了不同时间过程变量的值。如果有更多可变配方参数并且每个参数都是一个时间点,则同样适用。
[0516]
在425处,得分函数us(ht)=u[v(ht)]被优化,例如使用数值方法,以便找到最优效用得分和相关的ht
opt
。将具有收获时间ht
opt
的配方模板提供给生物反应器的控制系统,以便在ht
opt
处自动进行收获,从而优化效用得分,并从而优化生产过程。
[0517]
第二种场景
[0518]
图7a-7f显示了示例性配方确定的概念图和相关图。第二种场景涉及具有生长和细胞凋亡以及抑制剂产生的培养过程。
[0519]
在310处,检索过程演化信息210。该生产过程的模型可以假设活细胞以最大速率r繁殖,并且生长减慢被作为细胞生长副产物产生的抑制性毒素减慢。此外,细胞具有有限的寿命,并以恒定速率δv发生凋亡,且凋亡细胞以δa速率快速裂解,之后可能无法再检测到它们。这种情况下的过程演化信息210包括以下三个微分方程:
[0520][0521][0522][0523]
其中v是活细胞密度[细胞/ml],r是细胞生长速率[hr-1
],s是对抑制剂的敏感性[mm],c是抑制剂反应的s形中心[mm],δv是凋亡率[hr-1
],a是凋亡细胞密度[细胞/ml],δa是裂解率[hr-1
],τ是抑制剂浓度[mm],且θ是抑制剂产量[μmol/细胞]。在这种情况下,过程演化信息210包括两个可变演化参数,即细胞生长速率和抑制剂产生。
[0524]
此外,检索包括一个配方模板的单个配方模板组合200,并且该配方模板具有一个
可变的配方参数,即收获时间。还检索映射230,其中映射230是vcd和抑制剂浓度的函数并且是恒等函数,即v和τ都是过程变量和性能指标。另外,检索效用函数240,其中效用函数240不仅取决于达到足够的细胞密度,还取决于培养基中抑制剂的量,即
[0525][0526]
在该实例中,检索似然函数220包括检索与两个不同同类过程a和b相关的同类数据,以及对应的相关性信息,并基于所有那些来计算似然函数220,如下文解释的。
[0527]
应该确定最优配方的生产过程c大规模使用某种细胞类型。可用的先验知识包括同类生产过程a的同类数据da,它使用与c相同的细胞类型但规模更小,以及生产过程b的同类数据db,它使用与c不同的细胞类型,但与c相同的规模。例如,数据集da和db可以包括来自大量运行的轨迹数据。
[0528]
对于每个过程(a和b),贝叶斯推理可用于获得后验分布p(r
x
,θ
x
|d
x
)~p(d
x
|r
x
,θ
x
),其中p(d
x
|r
x
,θ
x
)为对于给定的生长速率和抑制剂产生值,数据的条件分布,而先验是均匀的。可以通过计算对于d
x
中的每次运行,如果演化参数的“真实”值是r
x
,θ
x
可能已经产生运行数据的概率来获得条件分布。例如,d
x
中的运行数据可以包括细胞密度的时间序列a(t),并且可以基于演化参数r
x
,θ
x
获得时间序列的模拟数据b(t)。示例性地,概率被估计为n(a(t)-b(t),σ)的积分,其中σ是细胞密度测量系统的标准误差的估计值。以这种方式获得的后验分布如图7b所示。
[0529]
相关性信息可以基于关于生产过程的实验/文献知识。在这种情况下,相关性信息是考虑到过程a/b的演化参数值,过程c的演化参数值的概率。可以假设r(a,c)=r(rc,ra)*r(θc,θa),且对于b也类似。
[0530]
如前所述,过程a和c的细胞类型相同。根据科学文献,由于溶解氧的限制,这种细胞类型会减慢其在c的规模下的过程。即使溶解氧不是过程演化信息中的演化参数,也可以在a和c之间的相关性中考虑该信息。特别地,相关性被选择为具有朝向下端的更长尾的分布,反映了过程c的增长率和抑制剂产量均低于过程a的概率。图7c左侧显示了相关性r(rc,ra)的图,假设分布具有方差0.02和偏度4,并且右侧是相关性r(θc,θa)的图,假设分布的方差为0.03,偏度为4。
[0531]
过程b和c的细胞类型不同但相似,并假设它们在生长速率和抑制剂产生方面表现相似,尽管后者存在更大的不确定性,这反映在选择更大的方差中。图7d左侧显示了相关性r(rc,rb)的图,假设方差为0.01的正态分布,且右侧显示了相关性r(θc,θb)的图,假设方差为0.04的分布。
[0532]
从同类数据获得后验分布,并且相关性信息被组合以计算过程c的似然函数220。具体地,
[0533][0534]
在检索到所有必要的输入之后,在320处执行第一优化步骤,其包括为收获时间提供410输入值(一个元素的集合),然后执行415第二优化步骤。第二优化步骤包括基于方程(9)的似然函数220为可变演化参数提供430一组可能值。在该实例中,生长速率和抑制剂产生的可能值被选为最可能的值,即最大化似然函数的值。然后在435处执行第三优化步骤。没有考虑可变演化参数的其他值,这意味着在第二优化步骤中没有循环,并且在440处计算的效用得分将与唯一的效用计数一致。此外,如果不考虑随机性,则通过在445处执行第四优化步骤,在450处计算的效用计数将与在465处计算的效用值一致。
[0535]
在第四优化步骤中,在455处,使用方程(7)的过程演化信息210生成模拟,其中具有(rc,θc)的最可能的值和给定的初始条件,检索到的仅包括一个配方模板的配方模板组合200,以及收获时间的输入值,例如用ht1表示。从模拟中,在460处获得不同时间的过程变量值(特别是vcd和抑制剂浓度),即轨迹。图7f中的左侧图显示了过程变量v、τ和a的轨迹。
[0536]
在本实例中,与第一种场景类似,效用得分函数可以直接从轨迹中获得,这些轨迹已经提供了v和τ作为时间的函数,而无需循环第二优化步骤。过程变量的值被馈送到方程(8)的效用函数240,其图显示在图7f的右侧。
[0537]
在425处,得分函数us(ht)=u[v(ht),τ(ht)]被优化,例如使用数值方法以便找到最优效用得分和相关的ht
opt
。在本实例中,最优效用得分等于13.13,而ht
opt
=108小时。这些值对应于v=23.65*105个细胞/ml和τ=2.54mm。将具有收获时间ht
opt
的配方模板提供给生物反应器的控制系统,以便在ht
opt
处自动进行收获,从而优化效用得分,并从而优化生产过程c。
[0538]
第三种场景
[0539]
图8a-8c显示了示例性配方确定的概念图和相关图。第三种场景涉及具有生长、抑制剂产生和蛋白质产生的培养过程。
[0540]
在310处,检索过程演化信息210。该生产过程的模型可以假设活细胞以最大速率r繁殖,并且生长减慢被作为细胞生长副产物产生的抑制性毒素减慢。此外,细胞具有有限的寿命,并以恒定速率δv凋亡。活细胞产生具有活性r的蛋白质,并且蛋白质被产生的抑制剂以δτ的速率降解。这种情况下的过程演化信息210包括以下四个微分方程:
[0541][0542]
[0543][0544][0545]
其中v是活细胞密度[细胞/ml],r是细胞生长速率[hr-1
],k是抑制剂浓度容量[mm*hr/ml],δv是细胞凋亡率[hr-1
],i
τ
是累积抑制剂浓度[抑制剂*hr/ml],τ是抑制剂浓度[mm],θ是抑制剂产量[μmol/细胞],δτ是蛋白质降解[mm-1
*hr-1
],p是活蛋白浓度[单位/ml],且ρ是蛋白质产生速率[单位/细胞*hr]。在这种情况下,过程演化信息210包括两个可变演化参数,即细胞生长速率和抑制剂浓度容量。
[0546]
此外,检索映射230,其中映射230是vcd和活蛋白浓度的函数并且是恒等函数,即v和p都是过程变量和性能指标。另外,检索效用函数u(v,p)240。
[0547]
在这种场景下,生产过程已经开始,并且配方会即时更新和优化。因此,检索到的配方模板组合200对应于当前正在使用的配方,其中收获时间是可变的配方参数,其值必须被选择以优化效用函数。
[0548]
在本实例中,检索似然函数220包括检索与正在进行的生产过程b相关的当前数据db,、与同类过程a相关的当前数据da,,以及相应的相关性信息,并基于所有那些计算似然函数220,如下文解释的。过程b使用细胞类型b,且过程a使用细胞类型a。
[0549]
特别地,数据集da可以包括来自大量运行的轨迹数据。对于过程a,可以使用贝叶斯推理来获得概率或后验分布p(ra,ka|da)~p(da|ra,ka),其中p(da|ra,ka)是对于给定的生长速率r和抑制剂浓度饱和常数k的值,数据的条件分布,而先验再次是均匀的。可以通过计算对于da中的每次运行,如果演化参数的“真实”值为ra,ka时可能已经产生运行数据的概率来获得条件分布。
[0550]
实际上,如果可以获得与不止一次运行相关的数据,则可以将概率表面相加组合,以对概率景观提供越来越丰富的信息描述。数据集越大,预测每个目标演化参数的总体平均值的概率景观就越接近。图8b显示了当数据与单次运行(左侧)和500次运行(右侧)相关时,从数据da获得的r和k的概率表面。单次运行中r和k的总体均值估计值为r=0.054和k=17.2。500次运行中r和k的总体均值估计值为r=0.069和k=15.7。
[0551]
相关性信息可以基于关于生产过程的实验/文献知识,并且可以是两个可变演化参数上的联合分布r(rb,ra,kb,ka),例如多元正态分布,其具有的生长速率的标准偏差等于0.012,且抑制剂饱和常数的标准偏差等于0.008(协方差矩阵的非对角项设置为零)。
[0552]
基于来自正在进行的过程的部分数据db,也有可能获得类似于上面对a解释的后验或概率分布p(rb,kb|db)。由于它基于单个部分运行,因此该分布可能没有特别丰富的信息,但它可以与p(ra,ka|da)和相关性信息r(rb,ra,kb,ka)组合以获得更多信息的似然函数220,即
[0553]
l(rb,kb)=∫∫p(rb,kb|db)r(rb,ra,kb,ka)p(ra,ka|da)dradkaꢀꢀ
(11)
[0554]
图8c显示了左侧的p(rb,kb|db)和右侧的l(rb,kb)之间的差异。
[0555]
在检索到所有必要的输入之后,在320处执行第一优化步骤,其包括为收获时间提
供410输入值(一个元素的集合),然后执行415第二优化步骤。第二优化步骤包括基于方程(11)的似然函数220为可变演化参数提供430一组可能值。在本实例中,生长速率和抑制剂浓度容量的可能值被选为最可能的值,即最大化似然函数的值。然后在435处执行第三优化步骤。没有考虑可变演化参数的其他值,这意味着在第二优化步骤中没有循环,并且在440处计算的效用得分将与唯一的效用计数一致。此外,如果不考虑随机性,则通过在445处执行第四优化步骤,在450处计算的效用计数将与在465处计算的效用值一致。
[0556]
在第四优化步骤中,在455处,使用方程(10)的过程演化信息210,来生成模拟,其中具有(rb,kb)最可能的值和给定的初始条件、在持续运行中使用的配方以及收获时间的输入值,例如用ht1表示。从模拟中,在460处获得不同时间的过程变量的值,即轨迹。
[0557]
在本实例中,类似于第一种和第二种场景,效用得分函数可以直接从轨迹中获得,这些轨迹已经提供了v和p作为时间的函数,而无需在第一优化步骤中循环。在425处,得分函数us(ht)=u[v(ht),p(ht)]被优化,例如使用数值方法以便找到最优效用得分和相关的ht
opt
。将收获时间ht
opt
的值提供给生物反应器的控制系统,以便动态更新配方并在ht
opt
处自动进行收获,从而优化效用得分,并从而优化生产过程b。
[0558]
一旦运行完成,轨迹数据就会被存储起来,这样它们就可以成为后续运行的先验知识空间的一部分。
[0559]
第四种场景
[0560]
图9a-9e显示了示例性配方确定的概念图和相关图。第四种场景涉及具有ph依赖性生长、抑制剂产生和蛋白质产生的培养过程。
[0561]
在310处,检索过程演化信息210。该生产过程的模型可以假设活细胞以最大速率r繁殖,并且生长减慢被作为细胞生长副产物产生的抑制性毒素减慢。此外,细胞具有有限的寿命,并以恒定速率δv凋亡。活细胞产生具有活性ρ的蛋白质,并且蛋白质被产生的抑制剂以δ
τ
的速率降解。细胞生长速率取决于维持在最优水平ph
gro
附近的ph值,而该最佳值任一侧的偏差都会抑制生长。蛋白质在高ph下是稳定的,但在低ph下会以δ
ph
的速率和反应中心点c变性。
[0562]
这种情况下的过程演化信息210包括以下四个微分方程:
[0563][0564][0565][0566][0567]
其中v是活细胞密度[细胞/ml],r是细胞生长速率[hr-1
],k是抑制剂浓度容量[mm*
hr/ml],δv是细胞凋亡率[hr-1
],i
τ
是累积抑制剂浓度[抑制剂*hr/ml],τ是抑制剂浓度[mm],θ是抑制剂产量[μmol/细胞],δ
τ
是蛋白质降解[mm-1
*hr-1
],p是活蛋白浓度[单位/ml],ρ是蛋白质产生速率[单位/细胞*hr],ph
gro
是最优生长ph[ph],σ是对ph
gro
偏差的耐受性[ph],δ
ph
是ph介导的蛋白质降解速率[hr-1
],s是对ph变化的敏感性[ph-1
],且c是反应中心点[ph]。在这种情况下,过程演化信息210包括三个可变演化参数,即细胞生长速率、抑制剂产生和蛋白质产生速率。
[0568]
除了过程演化信息之外,还检索了两个配方模板组合200,每一个都包括单一配方模板。第一配方模板涉及执行期间的ph值转变,并包括三个可变配方模板,即ph的起始值、ph转变的幅度δ
ph
和转变的时间t
ph
。第二配方模板包括一个可变配方模板,即设置ph的值,并且根据该配方模板,ph保持恒定。
[0569]
此外,检索映射230,其中映射230是活蛋白浓度的函数m并将其与作为性能指标的滴度t相关联。另外,检索效用函数240。优化的目标不仅是生产最多的蛋白质,而且还考虑过程的成本,特别是由于运行时间ft。效用函数240由(13)给出,并绘制在图9b中。可以看出,由于增加蛋白质滴度而获得的收益与实现滴度所增加的运行时间成本相权衡。
[0570]
在该实例中,检索似然函数220包括检索与必须针对其优化配方的生产过程的一个或多个先前运行相关的历史数据,并基于那些计算似然函数220,如下文解释的。特别地,历史数据可以包括至少一些过程变量的轨迹数据。图9c包括两个示例性图,显示了对于ph=6.9的运行(左侧)和ph=7.4的运行(右侧),vcd和活蛋白浓度的轨迹。
[0571]
基于历史数据,贝叶斯推理可用于获得似然函数l(r,ρ,θ)作为概率或后验分布p(r,ρ,θ|d)~p(d|r,ρ,θ),其中p(d|r,ρ,θ)是对于给定的生长速率和抑制剂浓度容量值,数据的条件分布,而先验是均匀的。可以通过计算如果演化参数的“真实”值为r,ρ,θ,对于d中的每次运行,运行数据可能已经产生的概率来获得条件分布。图9d显示了固定θ等于0.1的三维似然空间切片。给定x=[r,θ,ρ],似然函数的推断分布参数为,
[0572]
μ
x
=[0.07,0.1,0.01]
[0573][0574]
在检索到所有必要的输入之后,选择第一配方模板并在320处执行第一优化步骤,其包括提供410ph、δ
ph
和t
ph
的一组输入值,然后执行415第二优化步骤。第二优化步骤包括基于似然函数220为可变演化参数r、θ、ρ提供430一组可能值。在该实例中,可能值可以随机抽取,选择概率取决于似然函数220。
[0575]
然后在435处执行第三优化步骤。如果不考虑随机性,则第三优化步骤与第四优化步骤一致,并且通过在445处执行第四优化步骤,在450处计算的效用计数将与在465处计算的效用值一致。在第四优化步骤中,在455处使用方程(12)的过程演化信息210来生成模拟,其中具有提供的一组可能值、给定的初始条件、第一配方模板和可变配方参数的一组输入值。
[0576]
从模拟中,在460处获得不同时间的过程变量的值,即轨迹,特别是对于蛋白质浓度p。经由映射,可以获得滴度t的值并将其馈送到方程(13)的效用函数240,特别是最后时间的t,它也是运行时间t(ft)。然后效用值是uv=u[t(ft),ft],并与给定的配方模板组合、给定的一组输入值和一组可能值相关联。
[0577]
通过提供不同组的可能值集重复第三/第四优化步骤,从而获得多个效用值/效用计数uv1,uv2,...uvn。在440处,通过根据似然函数22加权效用值计算一组特定的输入值的效用得分
[0578][0579]
在420处,通过迭代不同的ph、δ
ph
、t
ph
值来重复第二优化步骤,从而获得多个效用得分,从中定义得分函数us(ph,t
ph
,δ
ph
)|《r1》,并且在425确定最优效用得分,即通过优化得分函数
[0580][0581]
与第一配方模板r1相关的最优效用得分相关的最优效用得分等于78.9。图9e在左侧显示了效用得分作为δ
ph
,t
ph
的函数,初始转变前ph值为7.1。
[0582]
对于第二配方模板r2,在330处再次重复整个程序,获得与其相关的最优效用得分,在340处,鉴定出最佳的最优效用得分,在这种情况下其为图9e在右侧的上图中显示了利用第一配方模板执行的模拟轨迹和可变配方参数的值,其给出了78.93的最优效用得分,即起始ph=7.1,δ
ph
=0.24和t
ph
=106小时。图9e右侧的下图显示了利用第二配方模板执行的模拟轨迹以及给出37.55的最优效用得分的值,即恒定ph=7.1。
[0583]
具有起始ph=7.1,δ
ph
=0.24和t
ph
=106小时的值的第一配方模板被提供给生物反应器的控制系统,从而优化生产过程,即以最大化效用的方式执行。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。