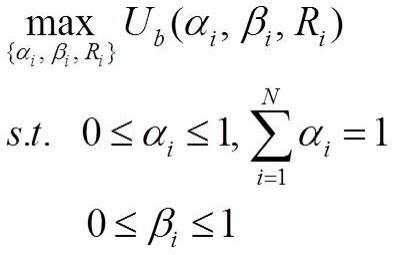
1.本发明属于多智能体系统控制技术领域,具体涉及一种多联盟非合作博弈的多智能体状态控制方法。
背景技术:
2.作为设计和分析交互代理决策机制的强大数学工具,多代理网络的分布式优化和非合作博弈在过去几年中一直是活跃的研究领域,并被广泛应用于无线传感器网络、云计算、资源分配和智能电网等各个领域。在分布式优化中,代理通过合作来实现全局目标,而在非合作博弈中,代理通过竞争来实现自身利益的最大化。值得注意的是,在许多实际情况下,合作与竞争并存。为了探索交互主体之间的合作与竞争,多联盟非合作博弈模型被学者提出。
3.然而,此类非合作博弈模型结构复杂,涉及的网络规模通常较大,现有的多联盟非合作博弈模型都要求智能体连续或周期性地进行交互,这通常会消耗大量的网络资源并导致通信拥塞,在实际应用中会导致不必要的通信。此外,事件触发机制因其在减少通信负担方面的优异性能而引起了广泛关注。事件触发机制的核心思想在于,只有在当前状态与上次触发时的状态之间的错误超过预先设计的阈值时,智能体才会交换信息。目前,主要的事件触发机制可分为静态事件触发和动态事件触发,研究表明,动态事件触发机制下的系统更新次数更少。然而,目前为止,基于动态事件触发的多联盟非合作博弈的纳什均衡求解问题并未得到研究。
技术实现要素:
4.发明目的:为解决在动态事件机制下多联盟非合作博弈中的广义纳什均衡的问题,本发明提出了一种基于动态事件触发的多联盟非合作博弈的多智能体状态控制方法,在保证系统性能的同时减轻了计算成本和通信负担,对于实现高性能控制系统具有重要的理论意义和实际意义。
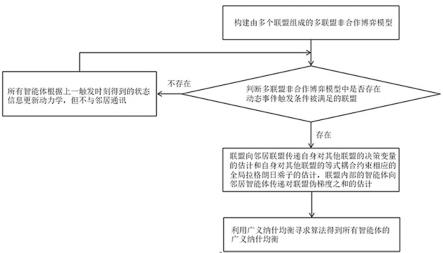
5.技术方案:一种多联盟非合作博弈的多智能体状态控制方法,包括以下步骤:步骤1:构建由多个联盟组成的多联盟非合作博弈模型;多个联盟之间存在等式耦合约束;所述等式耦合约束表示为:所有联盟的决策变量之和等于期望目标值;在每个所述联盟内部均设有多个智能体,并指定其中一个智能体作为通讯智能体,用于与邻居联盟通信;在每个所述智能体内部设置有动态事件触发条件;当任意一智能体的动态事件触发条件被满足时,对于任意一联盟内部,各智能体之间的通信关系被触发,以此来获取触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,和向邻居智能体传递触发时刻自身对其所在联盟内其他智能体的伪梯度之和的估计;所述邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计为邻居智能体的代价函数对其所在联盟内其他智能体的决策变量的估计求偏导后进行求和得到;同时
各联盟之间的通信关系被触发,通过联盟中的通讯智能体来获取触发时刻邻居联盟对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,以及联盟中的通讯智能体向邻居联盟传递触发时刻自身对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻自身对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计;采用通信拓扑有向图来表示各联盟之间的通信关系,其中表示个联盟组成的集合;为边集合,表示联盟之间的通信链路;是权重邻接矩阵,表示两个联盟构成的边的权重;当没有智能体的动态事件触发条件被满足时,对于任意一智能体,根据上一触发时刻得到的邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计更新自身对所在联盟内其他智能体的伪梯度之和的估计;对于任意一联盟,根据上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的决策变量的估计更新自身对多联盟非合作博弈模型中其他联盟的决策变量的估计,以及上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计更新自身对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计;步骤2:判断多联盟非合作博弈模型中是否存在动态事件触发条件被满足的联盟,若存在,则在动态事件触发条件被满足的联盟内部,各智能体间的通信关系被触发,利用获取到的当前触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,得到所在联盟的伪梯度之和的估计;同时,各联盟之间的通信关系被触发,利用获取到的当前触发时刻邻居联盟对其他联盟的决策变量的估计、当前触发时刻邻居联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计和每个联盟的伪梯度之和的估计,得到自身对其他联盟的决策变量的估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,转入步骤3;若不存在,则各智能体更新自身对所在联盟内其他智能体的伪梯度之和进行估计,各联盟更新自身对其他联盟的决策变量进行估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子进行估计,并重新执行步骤2;步骤3:根据步骤2得到的所在联盟的伪梯度之和的估计、自身对其他联盟的决策变量的估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,用广义纳什均衡寻求策略,寻找得到所有智能体的广义纳什均衡解;步骤4:依据所有智能体的广义纳什均衡解,控制各智能体。
6.进一步的,所述的内部的各智能体之间的通信关系,包括:采用通信子图来表示联盟中智能体与其它智能体之间的通信;,表示联盟中智能体的个数,表示联盟中的智能体集合。
7.进一步的,所述的通信子图按照以下步骤生成:采用通信拓扑无向图表示联盟内部智能体之间的通信关系,,表示个联盟组成的集合;
引入干扰图来描述联盟内部各智能体之间的交互;获取在干扰图中不是智能体的邻居的节点,记为该类节点;从通信拓扑无向图中删除该类节点,保留其余节点及其边,生成联盟中智能体的通信子图。
8.进一步的,所述的利用获取到的当前触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,得到多联盟非合作博弈模型中每个联盟的伪梯度之和的估计,包括:每个联盟内部均执行以下操作步骤为:采用下式示出的估计算法,使用获取到的当前触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,对其所在联盟的伪梯度之和进行估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)式中:表示联盟中智能体对智能体的伪梯度之和的估计;表示联盟中智能体对智能体的第二辅助变量;表示联盟中智能体的通信子图中的邻居个数;表示联盟中智能体的代价函数;表示联盟对自身的决策变量的估计;表示联盟对除自身以外其他所有联盟的决策变量的估计;表示联盟对联盟中智能体的决策变量的估计;表示的一阶导数;表示联盟中的智能体;表示联盟中智能体在干扰图中邻居的集合;表示联盟中智能体在干扰图中邻居的集合;表示联盟的通信拓扑无向图的邻接矩阵元素;表示触发时刻联盟中智能体对智能体的伪梯度之和的估计;
表示触发时刻联盟中智能体对智能体的伪梯度之和的估计。
9.进一步的,所述的利用获取到的当前触发时刻邻居联盟对其他联盟的决策变量的估计、当前触发时刻邻居联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计和每个联盟的伪梯度之和的估计,得到自身对其他联盟的决策变量的估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,具体操作步骤为:采用下式示出的控制算法,使用当前触发时刻邻居联盟对其他联盟的决策变量的估计、当前触发时刻邻居联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计和每个联盟的伪梯度之和的估计,对自身对其他联盟的决策变量进行估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子进行估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)式中:表示的一阶导数;表示参数,大于0;表示第一可调参数,大于0;表示联盟;表示通信拓扑有向图的邻接矩阵元素;表示触发时刻联盟对自身决策变量的估计;表示触发时刻联盟对联盟的决策变量的估计;表示的一阶导数;表示联盟对等式耦合约束相应的全局拉格朗日乘子的估计;表示联盟对自身决策变量的估计的权重;表示联盟的期望目标;表示联盟对自身决策变量的估计;
表示第二可调参数,;表示触发时刻的值;表示触发时刻的值,表示联盟对等式耦合约束相应的全局拉格朗日乘子的估计;表示联盟的第一辅助变量;表示的一阶导数。
10.进一步的,所述的动态事件触发条件为:若时刻时,智能体的状态信息满足以下不等式时,取的最小值作为下一触发时刻,记为;所述智能体的状态信息包括:对其所在联盟内其他智能体的伪梯度之和的估计、对其他联盟的决策变量的估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计;该动态事件触发条件表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(10)式中:表示取下限函数;表示为误差的转置,,,表示触发时刻的值;表示联盟的决策变量的估计;表示为误差的转置,;表示为误差的转置,;表示第一中间变量;表示第二中间变量;表示触发时刻的值,,其中,表示联盟对自身的决策变
量的估计,表示联盟对除自身以外其他所有联盟的决策变量的估计;表示触发时刻的值。
11.进一步的,所述的广义纳什均衡寻求策略,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)其中:表示的一阶导数;表示联盟中所有智能体对自身伪梯度之和的估计的堆栈形式,表示为:,其中,表示联盟中第个智能体对自身伪梯度之和的估计。
12.有益效果:本发明与现有技术相比,具有以下优点:(1)首次将动态事件触发机制应用于多联盟非合作博弈模型;现有的多联盟非合作博弈工作均需要智能体连续地或周期性地交换所需信息。然而,相邻智能体之间的信号传输通常会消耗大量网络资源,这意味着算法的运行需要一个理想的通信环境。但在实际应用中,通信资源往往会受到限制。因此,需要新的高效的分布式协调控制方法来保证通信效率和控制性能;本发明考虑了结合动态事件触发机制的方案,智能体不需要连续地或周期性地交换所需信息,仅在满足条件时通信,减少通信频率,大大降低通信成本,节约能量;(2)本发明的控制方法,并不需要获取全局状态信息,比如所有联盟的伪梯度之和和所有联盟的状态;现有的多联盟非合作博弈工作大多是在所有联盟的状态信息可用的情况下展开的,然而,在非合作博弈中,联盟均具有自私性质。因此,为了保护联盟的隐私,本发明设计了联盟对全局信息的分布式估计算法;(3)本发明考虑了带有等式耦合约束的多联盟非合作博弈;现有的多联盟非合作博弈着重于纳什均衡的求解,而在多联盟场景中,联盟的状态不仅与自身的状态有关,还取决与其他联盟的状态,综合考虑耦合约束下的多联盟非合作博弈的广义纳什均衡求解更适用于实际情况;(4)本发明为每个联盟引入了干涉图,用来描述联盟中智能体之间的交互;与目前大部分相关工作比较,需要更少的通信和计算成本,结合动态事件触发机制相结合,进一步增强本发明在通信效率方面的优势。
附图说明
13.图1为一种多联盟非合作博弈的多智能体状态控制方法的流程图;图2为实施例中联盟之间和联盟内部的通信关系示意图;图3为实施例中联盟1、2、3的干扰图;图4为实施例中联盟2内部每个智能体的通讯子图;图5为实施例中联盟3内部每个智能体的通讯子图;图6为实施例中所有联盟对其他联盟决策变量的估计的堆栈形式的状态轨迹图;
图7为实施例中所有联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计的堆栈形式的状态轨迹图;图8为实施例中第一辅助变量的估计的堆栈形式的状态轨迹图;图9为实施例中的状态误差,其中, 分别表示的最优决策;图10为实施例中各个联盟的触发时刻序列示意图。
具体实施方式
14.现结合附图和实施例进一步阐述本发明的技术方案。
15.实施例1:如图1所示,本实施例公开了一种多联盟非合作博弈的多智能体状态控制方法,包括以下步骤:步骤1:构建由多个联盟组成的多联盟非合作博弈模型;多个联盟之间存在等式耦合约束;等式耦合约束表示为:所有联盟的决策变量之和等于期望目标值;在每个联盟内部均设有多个智能体,并指定其中一个智能体作为通讯智能体,用于与相邻联盟通信;在每个智能体内部设置有动态事件触发条件;当任意一智能体的动态事件触发条件被满足时,对于任意一联盟内部,各智能体之间的通信关系被触发,以此来获取触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,和向邻居智能体传递触发时刻自身对其所在联盟内其他智能体的伪梯度之和的估计;邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计为邻居智能体的代价函数对其所在联盟内其他智能体的决策变量的估计求偏导后进行求和得到;同时各联盟之间的通信关系被触发,通过联盟中的通讯智能体来获取触发时刻邻居智能体对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,以及联盟中的通讯智能体向邻居联盟传递触发时刻自身对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻自身对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计;当没有动态事件触发条件被满足时,对于任意一智能体,根据上一触发时刻得到的邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计更新自身对所在联盟内其他智能体的伪梯度之和的估计;对于任意一联盟,根据上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的决策变量的估计更新自身对多联盟非合作博弈模型中其他联盟的决策变量的估计,以及上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计更新自身对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计。
16.步骤2:判断多联盟非合作博弈模型中是否存在动态事件触发条件被满足的联盟,若存在,则在动态事件触发条件被满足的联盟内部,各智能体间的通信关系被触发,利用获取到的当前触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,得到所
在联盟的伪梯度之和的估计;同时,各联盟之间的通信关系被触发,利用获取到的当前触发时刻邻居联盟对其他联盟的决策变量的估计、当前触发时刻邻居联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计和每个联盟的伪梯度之和的估计,得到自身对其他联盟的决策变量的估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,转入步骤3;若不存在,则各智能体更新自身对所在联盟内其他智能体的伪梯度之和进行估计,各联盟更新自身对其他联盟的决策变量进行估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子进行估计,并重新执行步骤2;步骤3:根据步骤2得到的所在联盟的伪梯度之和的估计、自身对其他联盟的决策变量的估计和自身对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,用广义纳什均衡寻求策略,寻找得到所有智能体的广义纳什均衡解;步骤4:依据所有智能体的广义纳什均衡解,控制各智能体。
17.本实施例将动态事件触发条件应用于多联盟非合作博弈模型,大大降低通信成本,节约能量。同时本实施例的控制方法,并不需要获取全局决策信息。以及在多联盟场景中,联盟的状态不仅与自身的状态有关,还取决与其他联盟的状态,因此本实施例考虑了带有耦合约束的多联盟非合作博弈,耦合约束下的多联盟非合作博弈的广义纳什均衡求解更适用于实际情况。
18.实施例2:本实施例公开了一种基于动态事件触发的多联盟非合作博弈模型状态控制方法,主要包括以下步骤:步骤1:构建多联盟非合作博弈模型,该多联盟非合作博弈模型由多个联盟组成,多个联盟之间存在等式耦合约束;等式耦合约束表示为:所有联盟的决策变量之和等于期望目标值。在每个联盟内部均设有多个智能体,并指定其中一个智能体作为通讯智能体,用于与相邻联盟通信。在每个智能体内部设置有动态事件触发条件。
19.当任意一智能体的动态事件触发条件被满足时,对于任意一联盟内部,各智能体之间的通信关系被触发,以此来获取触发时刻邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计,和向邻居智能体传递触发时刻自身对其所在联盟内其他智能体的伪梯度之和的估计;所述邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计为邻居智能体的代价函数对其所在联盟内其他智能体的决策变量的估计求偏导后进行求和得到;同时各联盟之间的通信关系被触发,通过联盟中的通讯智能体来获取触发时刻邻居联盟对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,以及联盟中的通讯智能体向邻居联盟传递触发时刻自身对多联盟非合作博弈模型中其他联盟的决策变量的估计和触发时刻自身对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计。当没有动态事件触发条件被满足时,对于任意一智能体,根据上一触发时刻得到的邻居智能体对其所在联盟内其他智能体的伪梯度之和的估计更新自身对所在联盟内其他智能体的伪梯度之和的估计;对于任意一联盟,根据上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的决策变量的估计更新自身对多联盟非合作博弈模型中其他联盟的决策变量的估计,以及上一触发时刻得到的邻居联盟对多联盟非合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计更新自身对多联盟非
合作博弈模型中其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计。
20.在多联盟非合作博弈模型中,每个联盟充当虚拟玩家,而实际决策者是联盟中的智能体。
21.为方便表述,现采用通信拓扑有向图 来表示各联盟之间的通信关系,其中表示个联盟组成的集合;为边集合,表示联盟之间的通信链路;是权重邻接矩阵,表示两个联盟构成的边的权重;为了方便表示,现采用通信拓扑无向图,来表示联盟内部智能体之间的通讯关系。
22.为了降低通信负担,本实施例引入干扰图来描述联盟内部智能体之间的交互,从通信拓扑无向图中删除在干扰图中不是智能体的邻居的节点,保留其余节点(包括其本身)及其边,这样生成的图来表示联盟中智能体的通信子图。
23.步骤2:根据各智能体的代价函数和等式耦合约束,构建分布式伪梯度估计算法和全局信息估计算法。本步骤提及的智能体的代价函数为预先设置的。
24.现对步骤2的具体实施子步骤做进一步说明:s210:联盟的代价函数是由该联盟中各智能体的代价函数之和构成,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)并且带有一个等式耦合约束:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)其中:表示联盟中智能体的局部代价函数。
25.,,,表示维实向量。表示联盟的决策变量的堆栈形式。是联盟中智能体的决策变量。
26.,表示除了联盟以外其他联盟的决策变量的堆栈形式。
27.是二次连续可导的,,,表示联盟中智能体的个数。
28.为所有联盟的决策变量的堆栈形式。
29.表示维实矩阵的集合,表示维实向量的集合。
30.表示等式约束向量的权重,由用户自行定义,表示某一期望目标,由用户自行定义。
31.定义联盟的代价函数关于的伪梯度为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)是强凸且全局李普希兹连续的:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)s220:为了估计联盟的伪梯度之和,建立估计算法如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)以上两个公式为一个典型的平均一致性协议,作用是估计伪梯度之和。
32.其中:表示联盟中智能体对智能体的伪梯度之和的估计;表示联盟中智能体对智能体的第二辅助变量;表示联盟中智能体的通信子图中的邻居个数;表示联盟中智能体的代价函数;表示联盟对自身的决策变量的估计,特别强调,联盟对联盟自己的决策变量的估计等于联盟的真实决策变量;表示联盟对除自身以外其他所有联盟的决策变量的估计;表示联盟对联盟中智能体的决策变量的估计;表示的一阶导数;表示联盟中的智能体;表示联盟中智能体在干扰图中邻居的集合;表示联盟中智能体在干扰图中邻居的集合;表示联盟的通信拓扑无向图的邻接矩阵元素;
表示触发时刻联盟中智能体对智能体的伪梯度之和的估计;表示触发时刻联盟中智能体对智能体的伪梯度之和的估计。
33.s230:联盟为估计其他联盟的决策变量的估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,设计估计算法如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)其中:表示的一阶导数;表示参数,大于0;表示第一可调参数,大于0;表示联盟;表示通信拓扑有向图的邻接矩阵元素;表示触发时刻联盟对自身决策变量的估计;表示触发时刻联盟对联盟的决策变量的估计;表示的一阶导数;表示联盟对等式耦合约束相应的全局拉格朗日乘子的估计;表示联盟对自身决策变量的估计的权重;表示联盟的期望目标;表示联盟对自身决策变量的估计;表示第二可调参数,;表示触发时刻的值;表示触发时刻的值,表示联盟对等式耦合约束相应的全局拉格朗日乘子的估计;
表示联盟的第一辅助变量;表示的一阶导数。
34.步骤3:设置动态事件触发条件,仅当动态事件触发条件被触发时,才会触发联盟内部智能体之间的通信和各联盟之间的通信,此时,基于s220的估计算法和s230的估计算法,得到所在联盟的伪梯度之和的估计、对其他联盟的决策变量的估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计。
35.为了简化公式,定义、为 和的堆栈形式;其中,表示触发时刻联盟中智能体对智能体的第二辅助变量的估计。
36.令,,,分别表示上一次触发时刻的状态信息与当前时刻的状态信息的误差。,表示触发时刻的值;表示联盟的决策变量的估计。此处的状态信息包括对其所在联盟内其他智能体的伪梯度之和的估计、对其他联盟的决策变量的估计、对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计。智能体在无触发时,状态信息也会一直变化,但不会向邻居智能体传递,在触发时刻,智能体向邻居智能体传递实际状态。只要联盟满足动态事件触发条件,联盟内所有智能体和该联盟均被触发更新状态。
37.本实施例设置的动态事件触发条件为:若时刻时,状态信息满足以下不等式时,取的最小值作为下一触发时刻,记为,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)式中:表示取下限函数;表示为误差的转置;表示为误差的转置;表示为误差的转置;
表示第一中间变量,无具体含义;表示第二中间变量,无具体含义;表示智能体;表示联盟中智能体的个数;表示触发时刻的值;表示触发时刻的值,,其中,表示联盟对自身的决策变量的估计,表示联盟对除自身以外其他所有联盟的决策变量的估计;表示触发时刻的值。
38.其中,是内部动态变量,与的关系表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(11)表示的一阶导数。
39.其中,的初始值。
40.此外,与的关系表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)这意味着:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)步骤4:根据步骤3输出的所在联盟的伪梯度之和的估计、对其他联盟的决策变量的估计和对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计,为联盟设计广义纳什均衡寻求策略,完成基于动态事件触发的分布式多联盟非合作博弈。
41.本实施例的广义纳什均衡寻求策略,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
其中,表示的一阶导数;表示联盟中所有智能体对自身伪梯度之和的估计的堆栈形式,表示为:,其中,表示联盟中第个智能体对自身伪梯度之和的估计。
42.为了简便标注,定义为所有状态变量的堆栈形式。根据输出的所有联盟的伪梯度之和估计以及其他联盟的决策信息估计,寻找联盟内所有智能体的广义纳什均衡,广义纳什均衡为在满足等式耦合约束的条件下,没有智能体可以通过单方面改变决策变量来降低联盟的代价函数时,所有智能体的决策变量。本实施例公开了一种在智能体的局部决策受等式约束的耦合的情况下,基于动态事件触发的多联盟非合作博弈的多智能体状态控制方法,每个智能体根据所提供的事件触发条件,仅在满足条件时智能体才会与邻居交换信息,对联盟伪梯度之和以及所有联盟的状态进行估计,从而减轻了系统的计算与通信负担,对实现控制器的高性能控制具有重要理论价值和实际意义。此外,本实施例所考虑的事件触发类型是动态的,在减少通信次数方面效果更加显著。
43.实施例3现以解决具有生产约束的子公司的资源调度问题为例,对本发明的方法做进一步说明。
44.假设解决具有生产约束的子公司的资源调度问题的对应场景为:有3家相互影响的父公司,分别对应有3家、5家和5家子公司。每个父公司都是一个联盟,通过调整产品数量来争夺客户。同一父公司的子公司为其父公司生产零部件,合作沟通生产的产品数量,使父公司的利益最大化。各个父公司指定第一个子公司作为代表,与其他父公司的代表进行通信,每个父公司生产产品的数量受其他父公司生产数量的影响,具有耦合约束。
45.本实施例采用如下步骤来计算3家相互影响的父公司的最优产品数量。
46.为方便理解,在本实施例中,将本发明方法中涉及到的联盟用父公司来说明。涉及到的智能体用子公司来说明。
47.如图2所示,建立3个父公司的通信拓扑有向图和父公司中子公司之间的通信拓扑无向图。
48.为了降低通信负担,引入干扰图来描述父公司中子公司之间的交互,相应的干扰图如图3所示,从通信拓扑无向图中删除在干扰图中不是子公司的邻居的节点,保留其余节点(包括其本身)及其边,这样生成的图就是父公司中子公司的通信子图,父公司2和父公司3的通信子图如图4、5所示。
49.父公司的等式约束表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
在本实施例中,令的所有元素为0.3,。
50.子公司的代价函数为:式中,为父公司中子公司生产产品的成本,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)其中,为父公司中子公司的产量。
51.式中,为父公司中子公司生产的每个产品的单价,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)其中,是由0和1两个元素组成的随机矩阵。在本实施例场景中,为所有父公司的决策变量的堆栈形式。
52.为了所在父公司的伪梯度之和,建立估计算法如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)在本实施例场景中,表示父公司中子公司对子公司的伪梯度之和的估计;在本实施例场景中,表示父公司中子公司对子公司的第二辅助变量;在本实施例场景中,表示父公司中子公司的通信子图中的邻居个数;在本实施例场景中,表示父公司中子公司的代价函数;在本实施例场景中,表示父公司对自身的生产产品的数量的估计;特别强调,父公司对自身的生产产品的数量的估计等于父公司的真实状态;在本实施例场景中,表示父公司对除自己以外其他所有父公司的生产产品的数量的估计;在本实施例场景中,表示父公司对父公司中子公司的生产产品的数量的估计;在本实施例场景中,表示第二辅助变量的一阶导数;
在本实施例场景中,表示父公司中的子公司;在本实施例场景中,表示父公司中子公司在干扰图中邻居的集合;在本实施例场景中,表示父公司中子公司在干扰图中邻居的集合;在本实施例场景中,表示父公司的通信拓扑无向图的邻接矩阵元素;在本实施例场景中,表示触发时刻父公司中子公司对子公司的伪梯度之和的估计;在本实施例场景中,表示触发时刻父公司中子公司对子公司的伪梯度之和的估计。
53.父公司为了估计其他父公司的产量,建立控制算法如下:(7)(8)(9)在本实施例场景中,表示的一阶导数;在本实施例场景中,表示参数,=0.2;在本实施例场景中,表示第一可调参数,=1;在本实施例场景中,表示父公司;在本实施例场景中,表示通信拓扑有向图的邻接矩阵元素;在本实施例场景中,表示触发时刻父公司对自身生产产品的数量的估计;在本实施例场景中,表示触发时刻父公司对父公司生产产品的数量的估计;在本实施例场景中,表示的一阶导数;表示父公司对等式耦合约束相应的全局拉格朗日乘子的估计;在本实施例场景中,表示父公司对自身决策变量的估计的权重;
在本实施例场景中,表示父公司的期望目标;在本实施例场景中,表示父公司对自身生产产品的数量的估计;在本实施例场景中,表示第二可调参数,;在本实施例场景中,表示触发时刻的值;在本实施例场景中,表示触发时刻的值,表示父公司对等式耦合约束相应的全局拉格朗日乘子的估计;在本实施例场景中,表示父公司的第一辅助变量;在本实施例场景中,表示的一阶导数。
54.为了简化公式,定义、为 和的堆栈形式。在本实施例场景中,表示触发时刻父公司中子公司对子公司的第二辅助变量的估计。
55.令,,,分别表示上一次触发时刻的状态信息与当前时刻的状态信息的误差。
56.本实施例设置的动态事件触发条件为当时刻子公司的状态信息满足以下不等式时,取的最小值作为下一个触发时刻,下一个触发时刻记为,表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)在本实施例场景中,表示取下限函数;在本实施例场景中,表示为误差的转置;在本实施例场景中,表示为误差的转置;在本实施例场景中,表示为误差的转置;在本实施例场景中,;在本实施例场景中,;
在本实施例场景中,表示子公司;在本实施例场景中,表示父公司中子公司的个数;在本实施例场景中,;在本实施例场景中,表示触发时刻的值,,其中,表示父公司对自己生产产品的数量的估计,表示父公司对除自己以外其他所有父公司生产产品的数量的估计;在本实施例场景中,表示触发时刻的值。
57.其中,是内部动态变量,与的关系表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(11)式中,表示的一阶导数。
58.其中,。此外,可以得出:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)这意味着:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)对于父公司,当触发条件满足时,才会触发父公司内部子公司之间的通信,估计父公司的伪梯度之和以及触发父公司之间的通信,估计其他父公司生产产品的数量。
59.基于动态事件触发机制设计广义纳什均衡寻求策略,即根据所在父公司的伪梯度之和估计以及对其他父公司生产产品的数量的估计,寻找父公司内所有子公司的广义纳什均衡,表示如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)其中,表示的一阶导数;在本实施例中表示父公司中所有子公司对
自身伪梯度之和的估计的堆栈形式,表示为:,其中,表示父公司中第个子公司对自身伪梯度之和的估计。
60.在本实施例场景中,广义纳什均衡为使3家相互影响的父公司的利益最大化时,所有子公司生产产品的数量。
61.如图6所示,根据上述模型和数据,经计算可得到广义纳什均衡:参见图7至图8,表明所有变量,其中,为伪梯度之和的估计的堆栈形式,为所有联盟对其他联盟决策变量的估计的堆栈形式,为所有联盟对其他联盟的等式耦合约束相应的全局拉格朗日乘子的估计的堆栈形式,为第一辅助变量的估计的堆栈形式都以指数速率收敛。图6、7、8、9表明了每个变量的轨迹,各父公司的触发时刻如图10所示。
62.为了更直观地展现动态事件触发机制地优势,表1中给出了触发时间、最大、平均和最小间隔。
63.表1 实施例中各联盟的触发数据表1表明所提出的事件触发算法可以排除zeno行为。从上述结果可以看出,本发明所提出的方法不仅能够保证系统的控制性能,也能够大大提高系统的通信效率,减轻计算成本,是十分高效的分布式协调控制方法。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。