1.本发明属于图像处理、机器学习技术领域,尤其涉及一种小规模数据视觉语言预训练方法。
背景技术:
2.预训练模型是从大量标记和未标记的数据中获取知识,从中学习一个通用的模型以适用于不同的下游任务。近年来,不断出现的大规模预训练模型在许多领域取得了巨大的突破,这证明了训练一个通用模型,在处理特定任务时使用特定数据集来进行微调,能在任务上取得更好的效果,同时节省一定的算力。多模态进行预训练期望学习到两种及多种模态间的关联关系,较单一模态进行预训练,可综合获取多种信息,使得预训练模型具有更好的泛化性。虽然视觉或语言等单一模态的理解在视觉或语言任务中不可或缺,但各个模态之间的相互关系也同样重要。然而,现有的视觉语言预训练任务大多依赖于遮盖图片/文本补全或通过目标检测的方法,提取某一区域的特征,并对提取的特征进行细粒度的局部对齐,大多数预训练任务的设计缺少了不同模态之间的交互。
3.随着互联网上数据规模的不断壮大,数据类型越来越呈现多样化的特点,用户感兴趣的数据模态不再单一,用户的检索需求也越来越呈现出从单一模态到跨模态的发展态势。模态是指数据的表达形式,包括文本、图像、视频和音频等。多模态数据是指对于同一个描述对象,通过不同领域或视角获取到的数据,并且把描述这些数据的每一个领域或视角叫作一个模态。预训练的作用是从大量的训练数据中提取出尽可能多的共性特征,使模型对特定任务的学习负担变轻。在大规模的未标记数据上对模型进行预训练,并使用特定于任务的标记数据对下游任务进行微调
1.。
4.对于图像-文本预训练模型(pre-training model,ptm),当前的大多数工作都是基于视觉语言bert
2.的架构。主要挑战在于统一语义空间中视觉和文本内容的对齐。因此发展出两种模型架构设计:双流和单流。
5.在双流模型方面,2019年由lu等提出vilbert模型
3.,首次将bert
2.结构扩展到多模态双流模型中,使用类似bert
2.的架构学习对图像-文本的联合表示,但由于视觉和语言都有单独的transformer
4.结构,导致参数量显著提高。同vilbert
3.相似,lxmert
5.模型也是将两个transformer
4.应用于图像和文本,并通过第三个transformer
4.进行融合。2021年,radford等提出的clip(contrastive language-image pre-training)
6.模型,用4亿个来自网络的图文数据对,将文本作为图像标签进行训练,使用两个编码器分别处理文本和图片,在图像-文本检索任务上取得了显著的性能,但在其他视觉-语言任务中表现不佳。针对以上问题,之后由li等提出的albef(align before fuse)
7.模型,引入中间的图像-文本对比损失,首先将单模态图像表示与文本表示进行对齐,再与多模态编码器进行融合,引导视觉和语言表示学习,在多个下游任务中获得了更快的推理速度。
6.在单流模型中,sun等在2019年提出videobert
8.,作为单流模型,它在结构上使用堆叠的transformer
4.结构,使用聚类技术对视频帧和音频语言进行处理。visualbert
9.,
与videobert
8.相比拥有更简单的架构,可以在无监督的条件下建立语音、图像之间的联系,但还未将该模型应用于纯图像任务中。随即,2020年由li等提出的unicoder-vl
10.作为图像-文本领域的预训练模型,继续采用堆叠的transformer
4.结构,相较于以上三个模型,使用大量的图像-文本对进行训练,可学习常见的跨模态知识并应用于更广泛的下游任务中,但无法从单个的图像模态中提取信息。
7.由于现有的视觉语言预训练任务大多依赖于遮盖模态数据补全或通过目标检测的方法,提取某一区域的特征,并对提取的特征进行细粒度的局部对齐,大多数预训练任务模态间的交互也较少,遮盖补全任务主要依靠于单模态的特征,训练时主要是提高了单模态的特征提取能力,没有学习到不同模态特征之间的语义关联。除此之外,以往的预训练模型往往使用百万级甚至十亿级规模的数据来做预训练任务,需要花费大量的算力。
8.可供参考的现有技术文献包括:
9.[1]luo h,ji l,shi b,et al.univl:a unified video and language pre-training model for multimodal understanding and generation[j].arxiv preprint arxiv:2002.06353,2020.
[0010]
[2]devlin j,chang m w,lee k,et al.bert:pre-training of deep bidirectional transformers for language understanding[j].arxiv preprint arxiv:1810.04805,2018.
[0011]
[3]lu j,batra d,parikh d,et al.vilbert:pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[j].advances in neural information processing systems,2019,32.
[0012]
[4]vaswani a,shazeer n,parmar n,et al.attention is all you need[j].advances in neural information processing systems,2017,30.
[0013]
[5]tan h,bansal m.lxmert:learning cross-modality encoder representations from transformers[j].arxiv preprint arxiv:1908.07490,2019.
[0014]
[6]radford a,kim j w,hallacy c,et al.learning transferable visual models from natural language supervision[c]//international conference on machine learning.pmlr,2021:8748-8763.
[0015]
[7]li j,selvaraju r,gotmare a,et al.align before fuse:vision and language representation learning with momentum distillation[j].advances in neural information processing systems,2021,34:9694-9705.
[0016]
[8]sun c,myers a,vondrick c,et al.videobert:a joint model for video and language representation learning[c]//proceedings of the ieee/cvf international conference on computer vision.2019:7464-7473.
[0017]
[9]li l h,yatskar m,yin d,et al.visualbert:a simple and performant baseline for vision and language[j].arxiv preprint arxiv:1908.03557,2019.
[0018]
[10]li g,duan n,fang y,et al.unicoder-vl:a universal encoder for vision and language by cross-modal pre-training[c]//proceedings of the aaai conference on artificial intelligence.2020,34(07):11336-11344.。
技术实现要素:
[0019]
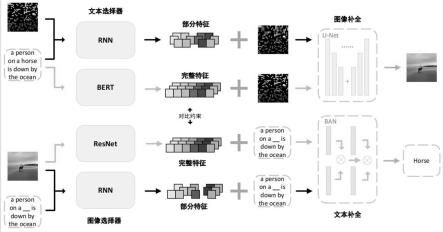
为了弥补现有技术的空白和不足,为了通过设计更好的预训练框架,从而在小规模的数据预训练中学习到更好的模型,本发明提出一种小规模数据视觉语言预训练方法,其包括一种基于神经网络的视觉语言预训练框架。该框架以神经网络为基础,在预训练过程中,通过重建缺失的图像/文本,以此来学习到更好的特征提取模型,以较小的预训练开销实现高性能的跨模态任务。
[0020]
不同于以往大多数只考虑模态内数据的预训练任务,本发明提出了一种新的方案来执行“细粒度视觉语言预训练”。学习细粒度对齐的关键是在给定缺失的图像/文本后,利用另一模态的数据进行数据补全,又在此基础上,为了增加任务难度,提高预训练后的模型表现,本发明进一步提出了部分辅助的思想。
[0021]
在该方案里,缺失的图像利用u-net网络,在每组对应的下采样和上采样阶段之间与额外输入的文本特征进行通道注意力,利用文本信息来进行图像的补全;而缺失的文本利用双线性注意力网络,混合了缺失的文本信息和额外输入的图像信息来进行文本的补全。此外,本发明在此基础上提出了部分补全的想法。使用一个简单的rnn网络,根据缺失的模态数据和完整的另一模态数据,选择出尽可能互补的另一模态数据,减低不同模态数据之间的语义重叠,从来减少模型误差,提高模型表现。该技术方案在减少了预训练数据的规模的同时,提高了下游任务,如跨模态检索、图像字幕生成的表现。
[0022]
具体来说,对于图像端,本发明使用了语义分割领域最近经常使用到的u-net网络,在编码缺失图像之后,将编码特征和文本描述特征融合,然后输入到解码器中,解码成一个正常图像;对于文本端,本发明使用了视觉问答领域经常使用的双线性注意力网络。文本特征可以由文本经过lstm模型提取而来,将文本特征写为x,图像特征为y,注意力权重图w根据不同模态特征之间的亲和度计算得来,在注意力权重图的辅助下,模型实现了x和y之间的特征融合。最后一层ban网络输出的结果输入到一个多层感知机构建的分类器之后,最终输出缺失单词的预测结果。在此基础上,本发明进一步提出了部分辅助补全的想法,使用一个简单的选择器,根据缺失的模态数据互补的选择另一模态数据,并代替原先完整的另一模态数据。
[0023]
本发明具体采用以下技术方案:
[0024]
一种小规模数据视觉语言预训练方法,其特征在于:对于图像端的预训练子任务,采用u-net网络,在编码缺失图像之后,在每组对应的下采样和上采样阶段之间与额外输入的文本特征进行通道注意力,利用文本信息来进行图像的补全,将编码特征和文本描述特征融合,输入到解码器中,解码成一个正常图像;
[0025]
对于文本端的预训练子任务,使用双线性注意力网络;其中,将文本特征记为x,图像特征为y,注意力权重图w根据不同模态特征之间的亲和度计算得到,在注意力权重图的辅助下,进行x和y之间的特征融合,最终输出缺失单词的预测结果。
[0026]
进一步地,在图像端的预训练子任务中,对文本使用文本选择器;在文本端对图像使用图像选择器;所述文本选择器和图像选择器采用循环神经网络,逐位的输出每个区域的选择结果;所述文本选择器的输入为缺失的图像和完整的文本,所述图像选择器的输入为缺失的文本和完整的图像。
[0027]
进一步地,对于图像端的预训练子任务,在编码阶段,从输入图像中提取多种尺度
的视觉特征;并通过特征提取得到文本特征f
t
,之后输入到模型当中,与编码器输出相融合;
[0028]
解码阶段时,先通过通道注意力机制将编码后的图像特征和文本特征进行特征融合;开始时,特征图通过一个全局池化层转换成一个特征向量,和文本特征连接到一起后,输入到一个带有softmax层的简单前馈神经网络,从而生成一个注意力权重,最终被用来更新特征值,以得到最终融合的特征:
[0029][0030]
下标i∈{1,2,...,cs}表示索引通道,}表示索引通道,表示一个标量;
[0031]
u-net网络的解码器带有多个反卷积层;每一个反卷积层的输入由同一阶段的编码层输出的编码特征和文本特征结合后得到的融合特征和前一反卷积层的输出连接而成,第一个反卷积层使用编码器最后一层的输出代替前一反卷积层的输出;最后一层输出的特征图a,经过上采样和卷积之后作为最终的图像输出。
[0032]
进一步地,在训练过程中,将子任务总体看成一个像素级别的回归问题,g
if
表示图像补全模型,将成对的缺失图像i
miss
和文本特征f
t
作为输入,最终输出补全后的图像i
normal
;原先的正常图像作为模型的补全目标,使用一个像素级的均方误差,如下所示:
[0033][0034]
进一步地,对于文本端的预训练子任务,对于给定两个模态的特征x,y,注意力权重根据不同模态特征之间的亲和度计算得来:
[0035][0036]
其中u∈rn×d和v∈rm×d是映射矩阵,是一个向量,ph∈rd,其中是注意力图索引,是逐元素乘积;
[0037]
在注意力权重图的辅助下,模型进行x和y之间的特征融合,并在在模型中使用残差连接,在第n个残差块中,模型输出如下所示:
[0038][0039]
p∈rd×c是映射矩阵,x作为模型的初始输入f0,banh是生成中间特征的函数,定义为:
[0040][0041]
其中u
′
∈rn×d,v
′
∈rm×d,
[0042]
最后一层ban网络输出的结果输入到一个多层感知机构建的分类器之后,最终输出缺失单词的预测结果。
[0043]
进一步地,将文本端的预训练子任务当作一个视觉问答问题,g
tf
表示文本补全模型,以成对的缺失的文本t
miss
和图像特征fi作为模型输入,最终输出缺失的单词t
tar
;模型预测目标为数据集的文本里被遮盖掉的部分;损失函数使用交叉熵损失,公式如下:
[0044][0045]
相比于现有技术,本发明提出了模态辅助补全的预训练策略,利用另一模态的数据来补全缺失的模态数据,在预训练阶段寻找更通用的,更细粒度的关联关系。并在此基础上提出部分辅助补全的想法,进一步提高了任务表现。
[0046]
受到transformer
4.模型的启发,本发明将transformer
4.模型中添加的位置嵌入变为另一模态的数据,作为额外信息,进行数据的补全。具体来说,对于图像端,本发明使用了u-net网络,在编码缺失图像之后,将编码特征和文本描述特征融合,然后输入到解码器中,解码成一个正常图像;对于文本端,本发明使用了视觉问答领域经常使用的双线性注意力网络。文本特征可以由文本经过lstm模型提取而来,将文本特征记为x,图像特征为y,注意力权重图w根据不同模态特征之间的亲和度计算得来,在注意力权重图的辅助下,模型实现了x和y之间的特征融合。最后一层ban网络输出的结果输入到一个多层感知机构建的分类器之后,最终输出缺失单词的预测结果。在此基础上,本发明进一步提出了部分辅助补全的想法,使用一个简单的选择器,根据缺失的模态数据互补地选择另一模态数据,并代替原先完整的另一模态数据。本发明提出的方法利用选择器选择的部分模态数据,进行缺失数据的补全,进一步减少了不同模态之间的语义重叠,提高了模型的表现。
[0047]
与现有技术相比,本发明及其优选方案的方案训练所需算力和下游任务表现了都取得了进步。本发明的主要贡献包括:
[0048]
(1)提出了两个新的跨模态预训练任务,去寻找视觉内容和文本内容之间更通用,更细粒度的关联关系,学习到更好的统一表征。
[0049]
(2)为了进一步减少误差,提高任务表现,本发明提出了部分辅助的思想,尽可能减少不同模态数据之间的重合部分,以求降低因此引起的模型误差。
[0050]
(3)通过该设计,在预训练阶段,只使用了小规模的数据来做模型的预训练,相较于现有百万级甚至十亿级规模的预训练,节省了大量的算力。
附图说明
[0051]
图1本发明实施例视觉语言预训练框架总体架构示意图;
[0052]
图2本发明实施例当中u-net网络的基本结构示意图;
[0053]
图3本发明实施例当中ban网络的基本结构示意图;
[0054]
图4本发明实施例选择器选择结果及数据补全效果可视化图。
具体实施方式
[0055]
为让本专利的特征和优点能更明显易懂,下文特举实施例,作详细说明如下:
[0056]
应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本说明书使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0057]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包
括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0058]
实施例一:
[0059]
参见图1,基于神经网络的视觉语言预训练框架的基础结构设计,根据其执行要素本实施例在数据通信场景中提出了一个多模态预训练方案,它主要包含两方:服务提供方,用户。
[0060]
其具体实现步骤如下:
[0061]
(1)服务提供方依据需要在安全的计算环境上使用大量图文对对神经网络进行训练,以此得到符合预期要求的预训练模型。训练集样本遮盖特定比例后作为缺失的数据集。模型是针对缺失数据进行补全,因此需要事先对数据集进行预处理。有缺失的数据才能用于本实施例的方案。
[0062]
(2)服务提供方将训练好的预训练模型分发给所有有需求的用户。用户的模型根据进行的下游任务,其网络结构有一定差异。
[0063]
(3)用户利用预训练模型对于特定的任务使用特定的数据集进行微调。
[0064]
(4)用户将不同模态数据输入微调后的模型,得到已对齐的模态无关的高级抽象特征,用于之后的特定任务。
[0065]
正如图1所示,当模型进行预训练时,对于图像端,在编码缺失图像之后,将编码特征和文本描述特征融合,解码成一个正常图像;对于文本端,根据不同模态特征之间的亲和度计算注意力权重,在注意力权重图的辅助下,实现了特征融合,最终输出缺失单词的预测结果。在模型微调阶段,用户根据不同的下游任务保留不同的子模型,使用特定的数据集训练少量批次就可得到微调后的模型。
[0066]
实施例二:
[0067]
假设用户没有足够的算力进行预训练阶段的模型训练。本实施例的基于神经网络的跨模态预训练方案的框架可以通过预训练、微调的过程,达到一次训练后,针对下游任务只需少量算力进行微调的要求。
[0068]
在实例一中本实施例对基于神经网络的跨模态预训练方案所需要的基础结构进行了大体的阐述,接着本实施例便在实例一的基础上进一步阐述具体的实施细节。特别之处体现如下:
[0069]
(1)、数据预处理和模型初始化:
[0070]
网络模型训练的好坏很大程度上取决于训练样本和网络模型的初始参数。
[0071]
因此首先,服务提供方使用一个合理的初始化参数设置对模型参数进行初始化;
[0072]
mscoco数据集是模型预训练的训练集,有133287张图片,每张图片同样有五个描述,本实施例使用123287张图片作为训练集,5000张图片作为验证集,5000张图片作为测试集。本实施例将现有的数据集遮盖特定比例后,作为缺失的数据集,然后训练本实施例方案的模型;
[0073]
服务提供方在对模型进行训练时,方案的总体流程图如图1所示。
[0074]
(2)、图像补全:
[0075]
图像补全模块根据缺失的图像和文本特征进行图像补全。在这个子任务中,模型通过理解文本描述,发掘有用的上下文语义,并以此作为图像补全的额外信息。本实施例希望在补全的过程中,模型能够学习到不同模态数据间更细粒度的关联关系,本实施例使用
了语义分割领域常用的u-net网络,模型基本结构如图2所示。
[0076]
在编码阶段,模型从输入图像中提取多种尺度的视觉特征。文本分支中,通过特征提取模型得到文本特征f
t
,之后输入到模型当中,与编码器输出相融合;
[0077]
解码阶段时,需要先将编码后的图像特征和文本特征进行特征融合。这一步本实施例通过通道注意力机制来完成,实现图像补全过程中的文本辅助。开始时,特征图通过一个全局池化层转换成一个特征向量,和文本特征连接到一起后,输入到一个带有softmax层的简单前馈神经网络,从而生成一个注意力权重,最终被用来更新特征值,以得到最终融合的特征;
[0078][0079]
u-net网络的解码器带有多个反卷积层。每一个反卷积层的输入由同一阶段的编码层输出的编码特征和文本特征结合后得到的融合特征和前一反卷积层的输出连接而成,第一个反卷积层使用编码器最后一层的输出代替前一反卷积层的输出。最后一层输出的特征图a,经过简单的上采样和卷积之后作为最终的图像输出。
[0080]
在训练过程中,子任务总体可以看成一个像素级别的回归问题,将成对的缺失图像和文本特征作为输入,最终输出补全后的图像。原先的正常图像作为模型的补全目标,使用了一个像素级的均方误差,如下所示:
[0081][0082]
(3)、文本补全:
[0083]
文本补全,利用图像特征来补全缺失的文本。模型通过更全面的理解图像的不同区域及区域之间的关联,发掘细粒度的语义信息,并作为文本补全的额外信息。跟图像补全相同,本实施例旨在通过这个任务,构建图像文本之间更精确的关联信息。为了解决这个子问题,本实施例使用了视觉问答领域经常使用的双线性注意力网络,模型细节如图3所示。
[0084]
其中,文本特征是由文本经过lstm模型提取而来,将文本特征写为x,图像特征为y。给定两个模态的特征x,y,注意力权重根据不同模态特征之间的亲和度计算得来;
[0085][0086]
在注意力权重图的辅助下,模型实现了x和y之间的特征融合。本实施例也使用了注意力的残差化学习,保证模型性能,本实施例在模型中使用了残差连接,在第n个残差块中,模型输出如下所示:
[0087][0088]
ban是生成中间特征的函数,定义为:
[0089][0090]
最后一层ban网络输出的结果输入到一个多层感知机构建的分类器之后,最终输出缺失单词的预测结果。
[0091]
这个子任务可以近似地当作一个视觉问答问题,以成对的缺失的文本和图像特征作为模型输入,最终输出缺失的单词。模型预测目标为数据集的文本里被遮盖掉的部分。损失函数使用了典型的交叉熵损失,公式如下:
[0092][0093]
(4)、选择策略:
[0094]
在进一步研究中发现,在模型完成图像或文本的补全时,给予完整的另一模态数据也许不是个好的选择。缺失的图像(文本)与完整的文本(图像)特征之间具有语义上的重叠,这也许会误导模型,让模型产生一定的误差。因此,本实施例在两个子任务的基础上,提出了部分辅助补全的策略,借助前置选择器,选出辅助数据中与缺失的模态数据更为互补的一部分,进一步提高模型的表现,形成一个整体的端到端模型。
[0095]
因为网络整体已经较为复杂,本实施例希望通过一个简单的模型来实现这个选择器的功能,所以本实施例利用了自然语言处理中常用的循环神经网络,逐位的输出每个区域的选择结果,如图4所示;
[0096]
将图像选择器记为si,文本选择器为s
t
,si的输入为缺失的文本,以供选择的完整图像,s
t
输入为缺失的图像,以供选择的完整文本,最终分别输出图像/文本的选择结果,如下所示:
[0097]
maski=si(t
miss
,i
normal
)
ꢀꢀ
(7)
[0098]
mask
t
=s
t
(i
miss
,t
normal
)
ꢀꢀ
(8)
[0099]
(5)、模型训练:
[0100]
以上子任务在模型中可以和一些常用的模态特征对齐方法结合使用,作为一个整体的多模态预训练模型,本实施例使用了对比学习来对齐图像特征和文本特征。本实施例使用了resnet50模型和bert模型分别来提取图像特征和文本特征。
[0101]
模型的总体损失可以列为:
[0102][0103][0104]
λ1,λ2,λ3是可调整的超参,用来平衡各个子任务的重要程度。是两个选择模型的选择比例,本实施例希望通过这个约束,让模型选择尽可能少的数据,更好的达到互补的效果。
[0105]
(6)、模型微调:
[0106]
在模型预训练完成后,因为预训练阶段使用的数据集跟下游任务的数据集不一定相同,模型存在一定的偏差,用户用于特定的下游任务之前,需要进行少批次的微调,根据所执行的任务,选择特定的数据集,微调模型的偏差。
[0107]
对于跨模态检索任务,本实施例保留提取图像/文本特征的resnet模型和bert模型,由于在预训练阶段就已经通过对比损失将不同模态特征作了对齐,在下游任务时,本实施例直接选择通过这两个网络直接输出模态无关的共同表征;
[0108]
对于图像字幕生成任务,由于模型在预训练阶段对齐了不同模态特征,可以把resnet网络输出的图像特征认为时模态无关的高级抽象语义特征,所以本实施例只保留提取图像特征的resnet网络,通过resnet网络输出图像特征后,再通过一个预训练好的seq2seq网络,将图像特征转换为文字。
[0109]
由以上实施例可以看出本发明方案具有以下方面的特色:一是本发明提出了两个
新的跨模态预训练任务,去寻找视觉内容和文本内容之间更通用,更细粒度的关联关系,学习到更好的统一表征。二是为了进一步减少误差,提高任务表现,本发明提出了部分辅助的思想,尽可能减少不同模态数据之间的重合部分,以求降低因此引起的模型误差。三是本发明只使用了小规模的数据来做模型的预训练,相较于百万级甚至十亿级规模的预训练,本发明节省了大量的算力。
[0110]
本实施例提供的以上涉及算法的程序设计方案可以代码化的形式存储在计算机可读取存储介质中,并以计算机程序的方式进行实现,并通过计算机硬件输入计算所需的基本参数信息,并输出计算结果。
[0111]
本领域内的技术人员应明白,本发明的实施例可提供为方法、装置、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0112]
本发明是参照根据本发明实施例的方法、设备(装置)、和计算机程序产品的流程图来描述的。应理解可由计算机程序指令实现流程图中的每一流程、以及流程图中的流程结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程中指定的功能的装置。
[0113]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程图中指定的功能。
[0114]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程中指定的功能的步骤。
[0115]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
[0116]
本专利不局限于上述最佳实施方式,任何人在本专利的启示下都可以得出其它各种形式的小规模数据视觉语言预训练方法,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本专利的涵盖范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。