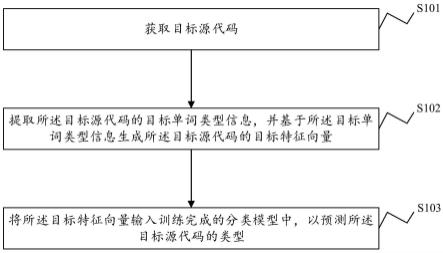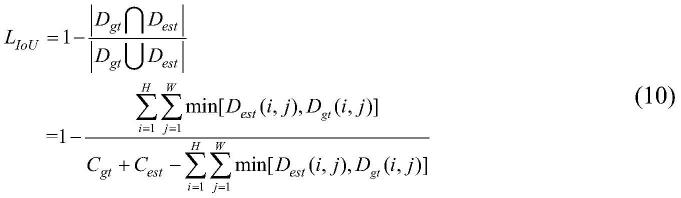
1.本发明涉及计算机视觉领域中的密集人群计数问题,具体涉及一种结合尺度感知的实时人群计数方法。
背景技术:
2.近年来,密集人群计数已经成为计算机视觉领域的一个研究热点。这项研究在现实世界有着广泛的应用,如安防监控、交通控制和智能交通。然而,由于监控场景受到尺度变化、背景噪声、遮挡等因素的影响,精确有效地预测人群数量仍然是一个严峻的挑战。许多研究者致力于通过各种先进的深度学习方法来提高预测精度,如注意机制和多尺度特征提取器,从而显著提升网络模型的性能。
3.同时在边缘设备的应用中,所设计的网络模型需要在有限的计算资源下获得精确的预测和实时的推理速度。然而,现有的模型很难同时满足速度和精度的要求。目前,这些性能优越的模型都具有复杂的网络结构和繁琐的训练操作。使用这些方法需要大量的计算资源,给边缘设备带来了巨大的负担。针对目标检测、图像分类等计算机视觉任务,已经提出各种轻量级模型来满足边缘设备的应用需求。基于这些成功的探索,一些研究人员开始研究专用于人群计数的轻量级网络模型,实现人群数量的快速推理预测。
4.可见轻量级网络模型使得实时人群预测任务成为可能。然而,我们观察到最近的轻量级网络工作仍然存在一些缺点。首先,为了在密集场景中获取更丰富的尺度信息,现有的轻量级模型多为多列或分支结构,仍然需要大量计算资源,对边缘设备不友好。其次,通过尺度信息提取和融合来增强特征图表示能力对模型精确预测至关重要。然而,目前的轻量级模型只注重尺度信息的提取,造成了一定的预测精度损失。另外,广泛采用的l2损失函数认为一幅图像中的所有像素都有存在人群的可能性。因此,在采用这种损失函数时,网络模型很难学习到人群场景中背景和前景的差异,进而影响预测精度。换而言之,在满足实时性需求的前提下,预测精度仍存在进一步提高的可能性。
技术实现要素:
5.本发明要解决的技术问题是提供一种结合尺度感知的实时人群计数方法来解决人群计数网络模型在精度和复杂度上的平衡问题。
6.解决上述技术问题采用如下技术措施:一种结合尺度感知的实时人群计数方法,主要包括以下步骤:
7.(1)图像的局部特征提取:许多先进的方法采用经预训练的vgg16前10层网络作为局部特征提取器。然而,由于参数多、计算量大,很难直接应用于轻量级网络。在vgg16的基础上,设计了专门用于轻量级网络的局部特征提取器(lfe),具体结构如表1所示。相比之前的提取器,它的网络层数和通多数都进行了限制,同时最后的特征输出通过3个maxpooling层下采样到原始输入大小的1/8,以进一步降低计算复杂度。
8.(2)多尺度信息提取:多尺度特征提取器(sfem)由6个级联的混合空洞卷积模块
(hdc)构成,其中,每相邻两个hdc模块共享相同的权重,这样在控制参数量不变的情况下,网络模型可以获得更为丰富的尺度信息。值得注意多尺度特征提取器只有0.024m参数,需要很少的计算资源。hdc模块具体结构如下:
9.作为多尺度特征提取器的基本单元,单个hdc模块参数量小于0.008m,具体结构如图2所示。首先将输入特征i∈rn×h×w×c送入1
×
1卷积层进行通道压缩得到输出特征i0∈rn×h×w×
(c/4)
,其中4为通道压缩比,n、h、w和c表示批量大小、高度、宽度,和通道数。然后将i0送入3个级联且扩张率互质的空洞卷积层d={1,2,3},以提取尺度信息并放大感受野。假设三个空洞卷积层的输出特征分别为i1∈rn×h×w×
(c/4)
、i2∈rn×h×w×
(c/4)
、i3∈rn×h×w×
(c/4)
,则hdc模块的最终输出为:
10.f
hdc
=c{i0,i1,i2,i3} i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
11.其中c表示通道拼接操作。此外,在拼接的特征和hdc输入特征i之间还建立了一个快捷连接,以增强hdc块中的梯度反向传播。
12.(3)多尺度特征信息融合:多尺度特征融合器(sffm)包含3个基于注意力机制的高效融合模块(eaf),且每个eaf模块只有0.004m的参数,旨在有效融合多种具有不同尺度信息的特征图。本发明提出的多尺度融合器主要融合了来自4个不同模块的特征图,包括lfe的输出f
lef
∈rn×h×w×c,和每两个hdc模块的输出f
hdc2
∈rn×h×w×c、f
hdc4
∈rn×h×w×c、f
hdc6
∈rn×h×w×c。同时,为增强梯度反向传播,建立了一个长跳跃连接,将融合后的特征和lfe产生的特征直接结相加,多尺度特征融合器的最终输出如下:
13.f
sffm
=e(e(e(f
lef
,f
hdc2
),f
hdc4
),f
hdc6
) f
lef
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
14.其中e表示eaf模块的操作,该模块的具体实现细节如下:
15.eaf模块旨在通过集成两种不同特征的信息来增强特征表达能力。如图3所示,假设两种特征分别为χ1∈rn×h×w×c和χ2∈rn×h×w×c。通过全局平均池化(gap)可将特征χ1、χ2压缩到一维相应输出ω1∈rn×1×1×c、ω2∈rn×1×1×c。然后我们对两种输出进行变型并拼凑在一起形成新的特征组合向量ω∈rn×2×c,并将其馈送到两个卷积核大小为9的并行一维卷积层中,以学习两种特征χ1、χ2在融合时对应的通道权重,即ω'1∈rn×1×1×c、ω’2∈rn×1×1×c。综上,通道的权重学习如下:
16.ω1=g(χ1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
17.ω2=g(χ2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
18.ω'1=r{σ[f1[c(r(ω1),r(ω2));θ2]]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0019]
ω'2=r{σ[f2[c(r(ω1),r(ω2));θ2]]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0020]
其中g表示全局平均池化,c表示拼接,f(;θ)是一维卷积运算,σ是sigmoid函数,r表示向量变型。之后我们将通道权重应用于两种输入特征χ1、χ2,并将相应的加权特征χ’1∈rn×h×w×c、χ’2∈rn×h×w×c融合在一起,同时此处采用残差连接来改善信息流。上述特征图融合过程可概括为:
[0021]
f'
eaf
=ω'1⊙
χ1 ω'2⊙
χ2 χ1 χ2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0022]
此外,我们采用归一化层对融合后的特征f’eaf∈rn×h×w×c进行处理,然后将其送入1
×
1卷积,生成eaf块的最终特征图f
eaf
∈rn×h×w×c。
[0023]
(4)密度图预测:密度图预测模块(dmr)主要利用sffm输出的特征图预测人群密度分布图,具体结构如表2所示。它是一种简单有效的全卷积结构,主要由一系列卷积层和反
卷积层构成。其中3个反卷积层主要负责将特征图恢复到和原图像大小一致。最后在网络的输出添加relu函数以保证密度图中所有的像素值不小于0。
[0024]
(5)本发明方法采用归一化欧几里得损失函数(nel)和多级交并比损失函数(miou)共同训练网络模型。nel用来度量每个像素处预测值与真值之间的误差,同时可缓解训练时样本不平衡问题,该损失函数定义如下:
[0025][0026][0027]
其中(i,j)是密度图中的像素位置,x表示输入图像,y是相应的标签,θ表示网络权重参数,f(x;θ)是网络预测的密度图,||.||2表示欧氏距离。
[0028]
经典的iou通常用于目标检测任务中,计算预测区域和真实区域之间的重合度,从而区分背景与目标。由此本发明提出了一种多级交并比(miou)损失函数来度量输出密度图的准确人群预测率,从而指导网络学习准确的人群识别和密度值估计。miou损失的可视化计算过程如图4所示,整个计算过程主要包括三个步骤,首先,利用以下公式获得预测人群数量c
est
和真实人群数量c
gt
:
[0029][0030][0031]
其中d
gt
为真实密度图,c
est
是预测的密度图,(i,j)表示密度图中的像素位置。由此,本发明方法中定义的iou损失函数如下:
[0032][0033]
其中∩表示交叉运算,∪表示并集运算。最后,如图4所示,由于预测的位置和真实位置之间可能存在像素偏差,所以进行下采样操作以减小由像素偏差带来的衡量误差,最终miou计算公式如下:
[0034][0035]
其中,l表示下采样为原图的1/(2^(l-1))大小,本发明公布的方法中将l设置为4以获得最佳性能。最终网络训练的目标损失函数lc定义如下:
[0036]
lc=nle miou
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
附图说明
[0037]
图1为本发明提出的实时人群计数网络的结构框图。
[0038]
图2为混合空洞卷积模块(hdc)结构示意图。
[0039]
图3为基于注意力机制的高效融合模块(eaf)结构示意图。
[0040]
图4为miou损失函数可视化求解过程示意图。
[0041]
图5为本发明方法预测密度图与真实密度图的可视化结果对比。
具体实施方式
[0042]
下面结合附图对本发明作进一步说明。有必要在此指出的是,以下实施例只用于本发明做进一步的说明,不能理解为对本发明保护范围的限制,该领域技术熟练人员根据上述本发明内容对本发明做出一些非本质的改进和调整,仍属于本发明的保护范围。
[0043]
(1)本发明所提方法是在深度学习标准框架1.6.0上展开的。其中比较重要的超参数如训练学习率lr设置为2e-4,权重衰减weight_decay设置为1e-3;
[0044]
(2)验证本发明所提方法预测性能时选取shanghaitec、ucf_cc_50、worldexpo'10、ucf_qnrf四个常用公开数据集。覆盖了常见的稀疏、密集、街道、广场等各类人群聚集场景;
[0045]
(3)生成密度图标签时,采用归一化为1的固定高斯核对图像中的每个头部标记进行模糊处理。整个生成过程可定义为:
[0046][0047]
其中x是标记对象的像素位置,n是图像中头部标记的总数。由此每个头部标记可以用δ函数δ(x-xi)表示。每个δ函数与固定大小的高斯核g
σ
卷积即可生成真实密度图f(x);
[0048]
(4)利用平均绝对误差(mae)和均方根误差(rmse)来评价本发明所提方法的预测精度和鲁棒性;利用每秒能够处理尺寸大小为1280*720的图像帧数(fps)评价该方法处理速度;通过测量网络模型的参数总量(单位:m)和图像的推理计算量(单位:gflops)评价本发明方法的复杂度;
[0049]
(5)本发明方法对比的常用轻量级网络为:
[0050]
方法1:zhang y,zhou d,chen s等人提出的方法,参考文献“single-image crowd counting via multi-column convolutional neural network[c]//proceedings of the ieee conference on computer vision andpattern recognition.2016:589-597”;
[0051]
方法2:cao x,wang z,zhao y等人提出的方法,参考文献“scale aggregation network for accurate and efficient crowd counting[c]//proceedings of the european conference on computervision(eccv).2018:734-750”;
[0052]
方法3:wang,p等人提出的方法,参考文献“mobilecount:an efficient encoder-decoder framework for real-time crowd counting.neurocomputing,2020.407:p.292-299”;
[0053]
(6)从表3与表4可以看出,相对于其他轻量级网络,本发明提出的方法在大部分数据集上得到了更低的mae和mse,表明本发明方法更能适应场景中的尺度变化,同时图5列出的部分结果示意图也表明本发明方法能够生成高质量的密度图。
[0054]
(7)本发明方法与其它3种轻量级网络方法均在3种gpu平台(gtx 1050ti、rtx2080、rtx 2080ti)进行速度测试。实验结果如表5所示,因其本发明方法更低的推理复
杂度,最高可达70.9fps的推理速度,远高于其它轻量级网络方法,且在精度上也达到更好的预测精度。实验结果表明本发明方法在人群计数精度和推理复杂度上达到一个更好的平衡。
[0055]
表1局部特征提取器(lfe)的具体结构
[0056][0057]
表2密度图预测模块(dmr)的具体结构
[0058][0059]
表3 shanghaitech、ucf-qnrf、mall数据及上不同方法的精度对比
[0060][0061]
表4 worldexpo'10数据及上不同方法的精度对比
[0062]
方法s1s2s3s4s5avg.参数量(m)方法13.420.612.913.08.111.60.13方法22.613.29.013.33.08.21.39方法3
‑‑‑‑‑‑
3.4本发明方法1.615.611.49.42.58.10.2
[0063]
表5不同方法的速度对比
[0064]
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。