1.本发明涉及深度学习视频理解技术领域,具体涉及一种泛化增强的少数民族舞蹈视频动作分割方法。
背景技术:
2.理解视频中人的行为,对于人机交互、视频监控、服务机器人等应用领域十分关键。随着深度学习的发展,基于深度神经网络的视频理解技术成为一大研究热点。其中,视频动作识别方法主要针对裁剪过的短视频,即每个视频仅包含一个动作,然而现实生活中人体动作是连续的,因此这类方法在实际应用中价值有限。视频动作分割方法旨在识别未裁剪的长视频中的多种连续动作,更符合现实应用场景。
3.将视频动作分割技术应用于少数民族舞蹈视频,有助于少数民族舞蹈的教学与推广,从而促进少数民族文化的传承与发展。但是,少数民族舞蹈动作复杂多变,不同民族舞蹈视频中存在跨域差异问题,即不同场景、服饰等因素影响深度神经网络模型的泛化能力,面对这类问题,现有视频动作分割方法性能受到严重影响。
4.目前动作分割算法主要以多阶段时间卷积网络为基础,通过捕捉多尺度时间关系,推理动作类别,经过多阶段逐步细化,得出逐帧的动作分类结果。基于此,公开号为cn114266990a的发明专利提出一种自下而上改进的视频动作分割网络,通过可分离和共享卷积改进每一层空洞一维卷积,提出自适应时间融合模块,在增加输入单元之间的依赖关系的同时自适应加权网络不同层的时间上下文特征,从而减少无效高频信号的传输,提高多尺度时间上下文特征融合的有效性,提高每一帧的可识别性。多阶段时间卷积网络中,每层空洞卷积的空洞率决定卷积获取的感受野范围,公开号为cn112883776a的发明专利提出一种神经网络架构搜索方法,用于寻找优质的感受野组合。通过先进行全局搜索,再进行局部搜索的方式,获得较好的感受野组合,通过迭代搜索过程,局部搜索逐渐找到更有效的低成本细粒度感受野组合,从而提高动作分割网络性能。未裁剪视频中,多种动作间的动作边界难以准确预测,边界附近帧容易预测错误,为解决此类问题,公开号为cn113591529a的发明专利提出预测视频中的动作边界来提升动作分类任务准确性。具体通过每一视频帧的边界类别,来辅助视频帧的动作分类,将帧级边界预测和帧级动作分类联合训练,使得动作分割模型学习到更具鉴别性的边界附近帧特征,提高对动作边界附近视频帧的分类准确度。为解决长视频中时空变化导致的域差异问题,公开号为cn112528780a的发明专利将动作分割视为域自适应问题。为减少视频时空域差异,结合无监督域自适应思想提出混合时域自适应方法,以跨域联合对齐帧级和视频级嵌入特征空间,通过域关注机制,加强处理具有更高域差异的帧级特征,实现更有效的域自适应。
5.目前大多数研究致力于改进网络模型提升预测精度,很少关注未裁剪长视频中的域差异问题。针对少数民族舞蹈视频的动作分割任务,同样面临跨域差异问题。现有研究通过域自适应方法对齐跨域特征分布,这种方法需要访问目标域数据,在实际应用中难以实现。而域泛化方法能够避免这一问题,仅通过源域数据来提升模型泛化能力。因此,如何在
不访问目标域数据的情况下,通过域泛化方法提升模型对未知域的泛化能力,保证动作分割模型适用多种少数民族舞蹈视频,成为一个关键问题。
技术实现要素:
6.本发明的目的在于,提出一种泛化增强的少数民族舞蹈视频动作分割方法,通过对抗性数据增强方式,实现视频动作分割中的域泛化。
7.为实现上述目的,本发明的技术方案为:一种泛化增强的少数民族舞蹈视频动作分割方法,包括:
8.准备训练和测试视频动作分割网络的视频数据集,所述视频数据集包含训练集和测试集;获取训练集中的视频,得到视频帧集合b
t
为视频中第t帧宽为w高为h的rgb三通道图像;所述视频帧集合使用特征提取器,获得特征通道数为d
in
的源域视频特征序列
9.复制所述源域视频特征序列x
in
,获得视频特征序列保留x
adv
梯度,使其受到反向传播影响;将源域视频特征序列x
in
和视频特征序列x
adv
分别输入至第一个单阶段域泛化时间卷积dg-tcn1,得到预测结果和预测结果
10.将预测结果和预测结果分别输入至第二个单阶段域泛化时间卷积dg-tcn2,得到预测结果和预测结果
11.……
12.将所述预测结果和预测结果分别输入至第n个单阶段域泛化时间卷积dg-tcnn,得到预测结果和预测结果
13.对每个阶段的帧级预测结果和预测结果添加分类损失l
cls
,用于约束视频动作分割网络准确预测动作类别,对所有阶段的f
iⅰadv
|
i∈[1,n]
、f
iⅱadv
|
i∈[1,n]
、f
iⅲadv
|
i∈[1,n]
和使用对抗损失l
adv
,通过反向传播更新视频特征序列x
adv
;
[0014]
经过多阶段对抗训练,视频特征序列x
adv
迭代更新为与源域视频特征序列具有不同分布的增广域视频特征序列;
[0015]
将源域视频特征序列与增广域视频特征序列共同作为训练集,对整体多阶段域泛化视频动作分割网络进行训练,此时仅使用分类损失l
cls
进行训练;
[0016]
在测试集上进行测试,获得视频动作分割性能评价结果。
[0017]
本发明由于采用以上技术方案,能够取得如下有益效果:可应用于少数民族舞蹈动作教学、视频监控、视频检索、人机交互以及工业或服务机器人等。下面对本发明的有益效果分点列举介绍:
[0018]
(1)适用于应用场景变化情况
[0019]
本发明使用的多阶段域泛化视频动作分割网络,通过数据增强的方法提升网络面对不同场景的泛化能力,能够适应如天气、环境、人员等存在变化的应用场景。
[0020]
(2)适用于动作模糊、遮挡等复杂场景
[0021]
本发明能够捕捉多尺度时间关系,包括帧间关系、动作内关系和动作间关系,在面对人体遮挡、动作模糊等情况时,能够结合上下文信息有效推理出动作类别,适用于人体动作模糊、遮挡等复杂场景。
[0022]
(3)适用于公共安防监控系统
[0023]
本发明对场景变换适应性强,泛化能力强,能够应用于各种场景的天眼监控,如街道、地下车库、室内等,并且能够适应各种天气变化,如雨天、雪天、雾天等恶劣天气,为公共安防监控提供保障。
[0024]
(4)适用于网络视频内容审核系统
[0025]
本发明能够识别人体细粒度动作,且能有效减少人员、服饰变化对识别性能的影响,适用于各种网络视频的内容审核任务,通过持续识别视频中的人体行为,判断视频中是否出现违规行为,从而完成视频内容审核任务,维护健康良好的网络环境。
[0026]
(5)适用于少数民族舞蹈视频教学
[0027]
本发明主要功能为识别长视频中人体的多种连续动作,因此,适用于少数民族舞蹈视频教学。并且在面对不同场景数据时具有较强的泛化能力,能够适应不同的民族服饰、不同的表演人员以及不同的场景。
附图说明
[0028]
图1是单阶段域泛化时间卷积网络结构图;
[0029]
图2是整体多阶段域泛化视频动作分割网络结构图;
[0030]
图3是实施例1中公共安防监控情况示意图;
[0031]
图4是实施例2中网络视频内容审核情况示意图;
[0032]
图5是实施例3中少数民族舞蹈视频教学情况示意图。
具体实施方式
[0033]
在以下描述中,出于解释的目的,阐述具体细节以提供对本技术的理解。图中示出的组件或模块是本公开的示例性实施例的说明,并且意在避免使本公开模糊。此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术,以下描述的本技术的实施例可以多种方式来实施。
[0034]
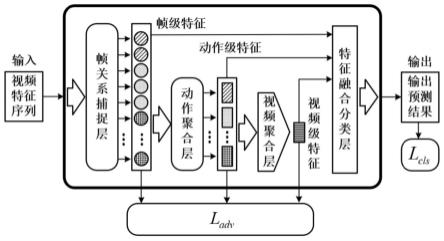
本发明提出一种泛化增强的少数民族舞蹈视频动作分割方法,一是通过多尺度关系捕捉提升动作类别推理能力,提升动作分割网络分类性能;二是通过对抗性数据增强方法实现域泛化,提升动作分割网络面对不同场景视频中的泛化能力,减少不同数据间域差异对网络性能的影响。具体通过一个多阶段域泛化视频动作分割网络实现,如图1所示,步骤如下:
[0035]
第1步:准备训练和测试视频动作分割网络的视频数据集,所述数据集中每个视频包含多个连续动作;每个视频均有视频帧集合b
t
为视频中第t帧宽为w高为h的rgb三通道图像,t为单个视频总帧数;所述视频帧集合使用特征提取器,获得特征通道数为d
in
的源域视频特征序列
[0036]
第2步:复制所述源域视频特征序列x
in
,获得视频特征序列保留x
adv
梯度,使其受到反向传播影响;将源域视频特征序列x
in
和视频特征序列x
adv
分别输入至第一个单阶段域泛化时间卷积dg-tcn1,得到预测结果和预测结果具体为:
[0037]
(1)对视频特征序列x
in
使用一维线性映射函数f
1in
调整特征通道数为df,获得隐藏层特征
[0038][0039]
其中,*为卷积操作,为一维线性映射函数f
1in
的权重矩阵,为一维线性映射函数f
1in
的偏置向量;
[0040]
(2)使用包含l层空洞残差单元的帧关系捕捉层对隐藏层特征f
1in
捕捉多跨度时间关系,获得帧级特征具体为:每层空洞残差单元包括一维空洞映射函数f
ldilate
和激活函数γ(
·
);第l∈[1,l]层空洞残差单元输出特征
[0041][0042]
其中,为第l层一维空洞映射函数f
ldilate
的权重矩阵,为第l层一维空洞映射函数f
ldilate
的偏置向量;
[0043]
所述帧级特征为第l层空洞残差单元输出特征;
[0044]
(3)对帧级特征f
1ⅰ使用一维线性映射函数f
1out
调整特征通道数为c,获得帧级预测结果
[0045][0046]
其中,为一维线性映射函数f
1out
的权重矩阵,为一维线性映射函数f
1out
的偏置向量;
[0047]
(4)根据帧级预测结果获得动作分段区间,从而将帧级特征f
1ⅰ划分为j个动作区间,针对第j|
j∈[1,j]
个动作区间内对应的帧级特征,使用动作聚合层,遍历所有j个动作区间,获得动作级特征
[0048][0049]
其中,为f
1ⅰ中的第i帧特征,为f
1ⅰ中第j个动作段对应的帧特征集合,s为帧数。对每个帧特征集合使用动作聚合层,得到对应的动作特征,第j个帧特征集合获取方式为:
[0050][0051]
其中,g
average
(
·
)为全局平均池化操作,为一维线性映射函数f
1ffn
的权重矩阵,为一维线性映射函数f
1ffn
的偏置向量,和是线性映射矩阵;对进行三次线性映射,将和的转置相乘,将结果除以常数并进行softmax激活,从而捕捉内帧特征间的相关性,将结果与相乘,通过一个一维线性映射函数f
1ffn
和一个全局平均池化g
average
(
·
),获得第j个动作特征对所有j个帧特征集合,执行上述操作,获得动作级特征
[0052][0053]
(5)对动作级特征f
1ⅱ使用视频聚合层,获得视频级特征
[0054][0055]
其中,为一维线性映射函数f
1video
的权重矩阵,为一维线性映射函数f
1video
的偏置向量,经过卷积核为k的一维线性映射函数f
1video
捕捉动作间关系,并通过g
average
(
·
)聚合为全局特征,得到视频级特征f
1ⅲ;
[0056]
(6)对动作级特征f
1ⅱ和视频级特征f
1ⅲ分别使用复制操作,将二者尺寸拓展为1
×df
×
t,获得特征f1ⅱ′
和f1ⅲ′
具体为:对于动作级特征f
1ⅱ,将第j个动作特征复制s份,s为对应第j个动作区间内的帧数,遍历所有j个动作特征,得到对于视频级特征f
1ⅲ,将其复制t份,t为视频总帧数,得到具体过程如下:
[0057][0058]
f1ⅲ′
=[f
1ⅲ,f
1ⅲ,f
1ⅲ…f1ⅲ]
ꢀꢀꢀ
(9)
[0059]
(7)特征f
1ⅰ、f1ⅱ′
和f1ⅲ′
输入至特征融合分类层,通过拼接操作获得融合帧级特征使用一维线性映射函数f
1fusion
调整特征通道数为c,获得输出预测结果
[0060]f1fusion
=π(f
1ⅰ,f1ⅱ′
,f1ⅲ′
)
ꢀꢀꢀ
(10)
[0061]
[0062]
其中,π(
·
)为拼接操作,为一维线性映射函数f
1fusion
的权重矩阵,为一维线性映射函数f
1fusion
的偏置向量;
[0063]
对视频特征序列x
adv
重复(1)~(7)操作得到对应的帧级特征动作级特征视频级特征和输出预测结果
[0064]
第3步:将预测结果和预测结果分别输入至第二个单阶段域泛化时间卷积dg-tcn2,得到预测结果和预测结果具体步骤与dg-tcn1相同;
[0065]
……
[0066]
第4步:将所述预测结果和预测结果分别输入至第nn个单阶段域泛化时间卷积dg-tcnn,得到预测结果和预测结果
[0067]
具体的,依次执行n个阶段,对任意第i|
i∈[2,n]
个单阶段域泛化时间卷积dg-tcni,输入和获得和经过第n个阶段的单阶段域泛化时间卷积dg-tcnn,获得和作为最终输出结果;
[0068]
第5步:执行对抗训练过程,对每个阶段的帧级预测结果和预测结果添加分类损失l
cls
,对所有阶段的f
iⅰadv
|
i∈[1,n]
、f
iⅱadv
|
i∈[1,n]
、f
iⅲadv
|
i∈[1,n]
和使用对抗损失l
adv
,通过反向传播更新视频特征序列x
adv
:
[0069][0070][0071]
其中,l
ce
为交叉熵损失,l
mse
为均方误差,l
t-mse
为截断均方误差,α用于调节分类损失l
cls l
cls
中断均方误差的权重,λⅰ、λⅱ和λⅲ用于调节对抗损失l
adv
中各部分的权重。
[0072]
第6步:经过多阶段对抗训练,x
adv
受到反向传播更新,视频特征序列x
adv
迭代更新为与源域视频特征序列具有不同分布的增广域视频特征序列;
[0073]
第7步:将源域视频特征序列与增广域视频特征序列共同作为训练集,对多阶段域泛化视频动作分割网络仅使用分类损失l
cls
进行训练,以第n阶段输出作为最终预测结果,经过训练后,网络对不同域样本的泛化能力得到提升。
[0074]
本发明在每个单阶段域泛化时间卷积中捕捉视频内的多层次关系,通过帧关系层捕捉基础的视频帧间关系,从细粒度角度推理每一帧的动作类别,在此基础上,通过动作聚合层捕捉每一动作区间内的帧间关系,即动作内关系,从而获得每一动作段的聚合表示,得到动作级特征,进一步地,通过视频聚合层捕捉动作间关系,获得视频整体的特征表示。故本发明能够捕捉帧间关系、动作内关系和动作间关系,利用多层次关系共同参与分类推理
过程,从而更准确地得出分类结果。同时,在执行对抗训练过程中,帧级特征和动作级特征更具有分类判别性,视频级特征更能体现视频的域信息,利用三种层次的特征,能够有效将视频中的多层次时间关系迁移到新的域中,使生成的增广域样本更有效。综上所述,所提出的多阶段域泛化动作分割网络,能过有效处理包含多种复杂动作的视频,并且拥有较强的泛化能力,面对来自不同域的数据能够保持有效性,适用于少数民族舞蹈视频。
[0075]
本实施例中网络结构的约束条件可以分为结构约束条件和参数约束条件,所述结构约束条件可以为:(1)多阶段域泛化视频动作分割网络包含n个单阶段域泛化时间卷积,其中n∈{4,5,6,7,8,9,10};(2)任意第i个单阶段域泛化时间卷积中,帧关系捕捉层包含l个空洞残差单元,每个空洞残差单元包含1个一维空洞映射函数f
ldilate
和1个激活函数γ(
·
),层数越高,所捕捉的时间跨度越远,其中l∈{5,6,7,8,9,10,11,12,13,14,15},任意第l层空洞残差单元所捕捉的时间跨度为2
l 1-1;(3)任意第i个单阶段域泛化时间卷积中,动作聚合层包含3个线性映射矩阵1个一维线性映射函数f
iffn
和一个全局平均池化操作g
average
(
·
);(4)任意第i个单阶段域泛化时间卷积中,视频聚合层包含1个一维线性映射函数f
ivideo
和一个全局平均池化操作g
average
(
·
);(5)任意第i个单阶段域泛化时间卷积中,特征融合分类层包含1个一维线性映射函数f
ifusion
。所述参数约束条件可以为:(1)任意第i∈[1,n]个单阶段域泛化时间卷积中,隐藏层特征通道数为df∈{64,128,256};(2)第1个单阶段域泛化时间卷积中,x
in
和x
adv
的特征通道数为d
in
=2048,一维线性映射函数f
1in
的权重矩阵尺寸为1
×din
×df
;(3)其余任意第i∈[2,n]个单阶段域泛化时间卷积中,一维线性映射函数f
iin
的权重矩阵尺寸为1
×c×df
,其中,c为单个视频中所包含的动作类别总数;(4)任意一个单阶段域泛化时间卷积中,帧关系捕捉层中一维空洞映射函数f
ldilate
的权重矩阵尺寸为3
×df
×df
,其中,卷积核大小为3,df为隐藏层特征通道数;(5)任意一个单阶段域泛化时间卷积中,视频聚合层中一维线性映射函数f
1video
的权重矩阵尺寸为k
×df
×df
,其中,卷积核大小为k∈{1,3,5,7,9},df为隐藏层特征通道数;(6)损失函数中,分类损失l
cls
中断均方误差的权重α∈[0,1],对抗损失l
adv
中各部分的权重λⅰ∈[0,1]、λⅱ∈[0,1]和λⅲ∈[0,1]。
[0076]
实施例1:多场景公共安防监控
[0077]
本实例针对学校、十字路口、室内等多种公共场景实施监控。本发明通过域泛化方法,提升视频动作分割算法应用于多种场景下的泛化能力,使得面对不同场景时,均能保持良好的性能,准确识别人体行为,以室内场景为例的安防监控情况如图3所示。
[0078]
实施例2:网络视频内容审核
[0079]
本实例针对网络视频进行内容审核。本发明能够识别多种连续人体动作,应用于手机、电脑等设备上,能够对网络视频进行内容审核,识别视频中人物是否有违规行为。网络视频内容审核情况如图4所示。
[0080]
实施例3:少数民族舞蹈视频教学
[0081]
本实例针对少数民族舞蹈进行视频教学,少数民族舞蹈视频中包含多种复杂的连续舞蹈动作,本发明通过捕捉多层次关系参与分类推理,能够有效识别各种复杂动作。并且本发明通过域泛化方法提升视频动作分割方法应用于多种场景下的泛化能力,在处理不同民族舞蹈视频时,能够减少人员变化、服饰变化、场景变化对网络性能的影响,从而有效应用于多种民族舞蹈视频中,将复杂舞蹈动作一一分解识别,有助于少数民族舞蹈的视频教
学。少数民族舞蹈视频教学情况如图5所示。
[0082]
本领域的普通技术人员将会意识到,以上描述的本发明的实施例仅用于阐述本发明的原理,帮助理解本发明,应当理解本发明的保护范围并不局限于这样的特别陈述和实施例。本发明的实施例可以多种方式来实施,凡是根据上述描述做出各种可能的等同替换或改变,均被认为属于本发明的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。