1.本公开涉及一种系统、方法、软件和设备,用于处理内容查询以检索相关的视频和视频剪辑,并且用于训练其系统和设备以实现改进的内容发现。
背景技术:
2.随着越来越大的视频库的出现,相关视频和视频剪辑的识别变得越来越困难和耗时。当前,基于内容描述符对库中的视频进行索引,可以对其进行搜索以识别相关结果。但是,大型数据库的迭代搜索非常耗时,并且通常会返回大量包含不相关内容的视频。
3.因此,需要一种识别视频库中保存的相关视频的改进方法。
技术实现要素:
4.在本公开的第一方面,提供一种系统,包括:视频内容发现模块,其被配置为:接收内容查询;从一个或多个信息源中检索与内容查询的至少一部分有关的一段文本;使用自然语言处理来处理文本的传递,以将内容查询转换为包括与该内容查询有关的一个或多个视频内容描述符的集合;并使用一个或多个视频内容描述符来识别多个可用视频片段中的一个或多个视频片段,其中,所识别的一个或多个视频片段与一个或多个视频内容描述符中的至少一个相关联(例如,通过搜索包括多个可用视频片段的数据库来找到一个或多个视频片段,以找到在数据库中与一个或多个视频内容描述符中的至少一个相关联的视频片段)。
5.一个或多个视频内容描述符中的每一个可以是被自然语言处理识别为在所检索的文本中的内容查询的预定距离之内的词。
6.检索与内容查询有关的文本的步骤可以进一步包括:处理内容查询以识别与内容查询有关的一个或多个搜索项;以及从一个或多个信息源检索文本,该文本包括一个或多个已识别的搜索项中的至少一个。在这种情况下,一个或多个视频内容描述符中的每一个可以是由自然语言处理识别为在内容查询的预定距离之内的词或检索到的文本中的搜索项之一。
7.内容查询可以包括图像,并且其中系统可以进一步被配置为从接收到的图像中提取图像元数据和/或图像描述符。在内容查询被处理以识别一个或多个搜索项的实施方式中,内容查询以识别一个或多个搜索项的处理可以包括从接收到的图像中提取图像元数据和/或图像描述符。
8.所检索的信息可以包括所提取的图像元数据和/或图像描述符,并且其中,通过在所检索的信息上使用nlp来识别视频内容描述符,以变换所提取的图像元数据和/或图像描述符的至少一部分。
9.一个或多个信息源可以包括因特网,并且其中可选地,基于所识别的搜索项,通过网络数据抽取(web scraping)从因特网检索相关信息。附加地或可替代地,一个或多个信息源可以包括本地数据库,其中相关信息是基于所识别的搜索项从本地数据库中检索的。
10.视频内容描述符可以包括以下中的一个或多个:对象描述符;对象生存期描述符;面部描述符;上下文描述符;语义描述符;类别描述符;情绪描述符;语言环境描述符;人口统计描述符;动作描述符;每日时间描述符;年度季度描述词;和天气描述符。
11.一个或多个视频内容描述符中的每一个可以与相关性得分相关联,该相关性得分指示与内容查询有关的相关性。另外,可以基于视频内容描述符的相关性得分对所识别的视频片段进行排名。
12.该系统可以进一步包括内容数据库,该内容数据库包括可用视频片段库,其中可用视频片段库中的每个视频片段与一个或多个视频内容描述符相关联。
13.视频内容发现模块可以通过将至少一个识别的视频内容描述符与与可用视频片段库中的视频片段相关联的视频内容描述符进行匹配,来识别多个可用视频片段中的一个或多个视频片段。
14.该系统还可以包括映射数据库,该映射数据库包括将每个可用视频片段链接到一个或多个视频内容描述符的映射表。可选地,映射表可以包括神经网络,该神经网络定义了每个可用视频片段和多个视频内容描述符之间的链接。另外,视频内容发现模块可通过用至少一个识别出的视频内容描述符查询映射表来识别多个可用视频片段中的一个或多个视频片段。
15.内容发现模块还可以被配置为:识别或获得用于一个或多个识别出的视频片段中的每一个的代表图像;以及并输出一个或多个已识别视频片段中每个视频片段的代表图像。该代表性图像可以至少部分地基于与内容查询的相关性来选择。
16.可选地,内容发现模块还可以被配置为:基于相关性得分对一个或多个识别出的视频片段进行排名,该相关性得分指示每个识别出的视频片段与内容查询的相似度;并按照其各自视频片段的排名顺序输出代表图像。
17.该系统还可以包括映射模块,该映射模块被配置为:接收视频片段;运行第一过程以识别与接收到的视频片段有关的一个或多个视频片段描述符;至少部分地使用人工智能基于视频片段描述符运行第二过程以创建映射表,其中该映射表将接收到的视频片段链接到一个或多个视频内容描述符,其中一个或多个视频内容描述符从可搜索视频内容描述符的列表中选择。
18.该第一过程可以包括以下中的一个或多个:对象检测算法;面部检测算法;情绪检测算法;上下文检测算法;语义检测算法;类别检测算法;情绪检测算法;语言环境检测算法;人口统计检测算法;动作检测算法;每日时间检测算法;年度季度检测算法;以及天气检测算法。
19.第二过程可以包括自然语言处理算法。
20.内容查询可以包括一个或多个否定关联,其中一个或多个否定关联限制对多个可用视频片段中与一个或多个否定关联相关的任何视频片段的识别。
21.所检索的与内容查询有关的信息可以包括先前为相同或相似的内容查询确定的相关视频内容描述符的记录,并且处理所检索的信息还可以包括从所检索的记录中提取一个或多个视频内容描述符。
22.在本公开的第二方面,提供了一种系统,该系统包括映射模块,该映射模块被配置为:接收视频片段;运行第一过程以识别与接收到的视频片段有关的一个或多个视频片段
描述符;并且至少部分地使用人工智能基于视频片段描述符运行第二过程以创建映射表,其中该映射表将接收到的视频片段链接到一个或多个视频内容描述符,其中一个或
23.多个视频内容描述符从可搜索视频内容描述符的列表中选择。
24.在本公开的第三方面,提供了一种搜索视频内容的方法,该方法包括:接收内容查询;基于所述内容查询,从一个或多个信息源中检索与所述内容查询有关的信息;至少部分地使用人工智能处理检索到的信息,以识别与内容查询有关的一个或多个视频内容描述符;使用一个或多个视频内容描述符,识别多个可用视频片段中的一个或多个视频片段。
25.在本公开的第四方面,提供了一种计算机程序,当该计算机程序在电子设备的处理器上执行时,执行第三方面的方法。
26.在本公开的第五方面,提供了一种电子设备,其包括:用于存储第四方面的计算机程序的存储器;以及用于执行第四方面的计算机程序的处理器。
27.在本公开的第六方面,提供了一种计算机可读介质,其包括指令,当该指令由一个或多个硬件处理器执行时,执行第三方面的方法。
28.本公开的方面
29.以下阐述了本公开的非限制性方面,但是仅是示例性的:
30.根据本公开的一实施例,提供了一种系统,包括:
31.视频内容发现模块,其配置为:
32.接收内容查询;
33.基于所述内容查询,从一个或多个信息源中检索与该内容查询有关的信息;
34.至少部分地使用自然语言处理来处理检索到的信息,以将内容查询转换为包括与内容查询有关的一个或多个视频内容描述符的集合;和
35.使用一个或多个视频内容描述符来识别多个可用视频片段中的一个或多个视频片段。
36.在该实施例中,检索与内容查询有关的信息的步骤还包括:
37.处理内容查询以识别与内容查询有关的一个或多个搜索项;和
38.基于一个或多个所识别的搜索项从一个或多个信息源中检索信息,并且可选地,其中一个或多个信息源包括互联网,其中基于所识别的搜索项通过网络数据抓取从互联网检索相关信息,和/或其中一个或多个信息源包括本地数据库,其中基于所识别的搜索项从本地数据库中检索相关信息。
39.在该实施例中,内容查询包括图像,并且其中内容查询的处理以识别一个或多个搜索项包括从接收到的图像中提取图像元数据和/或图像描述符,并且可选地,其中所检索到的信息包括提取的图像元数据和/或图像描述符,并且其中视频内容描述符是通过处理提取的图像元数据和/或图像描述符来识别的。
40.在该实施例中,所述视频内容描述符包括以下中的一个或多个:
41.对象描述符;
42.对象生存期描述符;
43.面部描述符;
44.上下文描述符;
45.语义描述符;
46.类别描述符;
47.情绪描述符;
48.语言环境描述符;
49.人口统计描述符;
50.动作描述符;
51.每日时间描述符;
52.年度季节描述词;和
53.天气描述符。
54.在该实施例中,一个或多个视频内容描述符中的每个与相关性得分相关联,指示与该内容查询相关的相关性,并且可选地,其中,基于该视频内容描述符的相关性得分对所识别的视频片段进行排名。
55.在该实施例中,还包括:
56.内容数据库,其包括可用视频片段库,其中该可用视频片段库中的每个视频片段与一个或多个视频内容描述符相关联,并且可选地,其中视频内容发现模块通过将至少一个识别的视频内容描述符与与可用视频片段库中的视频片段相关联的视频内容描述符进行匹配,来识别多个可用视频片段中的一个或多个视频片段。
57.在该实施例中,还包括:
58.映射数据库,其包括映射表,该映射表将每个可用视频片段链接到一个或多个视频内容描述符,可选地,其中该映射表包括神经网络,该神经网络定义每个可用视频片段和多个视频内容描述符之间的链接,并且可选地,其中视频内容发现模块通过用至少一个所识别的视频内容描述符查询映射表来识别多个可用视频片段中的一个或多个视频片段。
59.在该实施例中,该内容发现模块还被配置为:
60.为一个或多个所识别的视频片段中的每个识别或获得代表性图像;和
61.输出一个或多个识别的视频片段中的每个视频片段的代表图像,并且可选地,其中至少部分地基于与内容查询的相关性来选择代表图像,并且可选地,内容发现模块还被配置为:
62.根据相关性得分对一个或多个所识别的视频片段进行排名,该相关性得分指示每个所识别的视频片段与内容查询的相似度;和
63.按照各自视频片段的排名顺序输出代表图像。
64.在该实施例中,还包括:
65.映射模块,其被配置为:
66.接收视频片段;
67.运行第一过程,以识别与接收到的视频片段有关的一个或多个视频片段描述符;和
68.至少部分地使用人工智能基于视频片段描述符运行第二过程以创建映射表,其中该映射表将接收到的视频片段链接到一个或多个视频内容描述符,其中一个或多个视频内容描述符是从可搜索的视频内容描述符的列表中选择的,并且可选地:
69.其中第一过程包括以下一个或多个:
70.对象检测算法;
71.面部检测算法;
72.情绪检测算法;
73.上下文检测算法;
74.语义检测算法;
75.类别检测算法;
76.情绪检测算法;
77.语言环境检测算法;
78.人口统计检测算法;
79.动作检测算法;
80.每日时间检测算法;
81.年度季节检测算法;和
82.天气检测算法,
83.其中第二过程包括自然语言处理算法。
84.在该实施例中,所述内容查询包括一个或多个否定关联,其中,该一个或多个否定关联限制与一个或多个否定关联有关的多个可用视频片段中的任何视频片段的识别,和/或其中与内容查询有关的所检索到的信息包括先前为相同或相似内容查询确定的相关视频内容描述符的记录,
85.并且其中处理检索到的信息还包括从检索到的记录中提取一个或多个视频内容描述符。
86.根据本公开的一实施例,提供了一种系统,包括:
87.映射模块,其被配置为:
88.接收视频片段;
89.运行第一过程,以识别与接收到的视频片段有关的一个或多个视频片段描述符;和
90.至少部分地使用人工智能基于视频片段描述符运行第二过程以创建映射表,其中该映射表将接收到的视频片段链接到一个或多个视频内容描述符,其中一个或多个视频内容描述符从可搜索的视频内容描述符列表中选择。
91.在该实施例中,该方法包括:
92.接收内容查询;
93.基于该内容查询,从一个或多个信息源中检索与该内容查询有关的信息;
94.至少部分地使用人工智能处理检索到的信息,以识别与内容查询有关的一个或多个视频内容描述符;和
95.使用一个或多个视频内容描述符来识别多个可用视频片段中的一个或多个视频片段。
96.根据本公开的一实施例,提供了一种计算机程序,当由电子设备的一个或多个处理器执行时,用于执行上述方法。
97.根据本公开的一实施例,提供了一种电子设备,包括:
98.用于存储上述计算机程序的存储器;和
99.用于执行上述计算机程序的处理器。
100.根据本公开的一实施例,提供了一种包含指令的计算机可读介质,该指令在由一个或多个硬件处理器执行时,使得上述方法得以执行。
101.附图简要说明
102.仅通过示例的方式并参考附图对本公开的实施例的以下描述,本公开的其他特征和优点将变得显而易见,其中,相同的附图标记指代相同的部件,并且其中:
103.图1示出了根据本公开的一方面的系统的示例示意图。
104.图2示出了由图1的系统执行的示例过程。
105.图3示出了由图1的系统执行的示例过程;
106.图4示出了根据本公开的一方面的系统的示例示意图。
107.图5示出了由图4的系统执行的示例过程;以及
108.图6示出了根据本公开的一方面的示例电子设备。
具体实施方式
109.本公开涉及用于使用人工智能来索引视频库中的视频的技术。本公开还涉及用于识别和检索在视频内容库中保存的视频的技术。
110.特别地,本公开涉及用于识别存储在视频片段库内的视频片段的系统和方法。本公开使得能够识别与特定搜索查询有关的而通过现有的搜索方法无法识别到的视频片段。
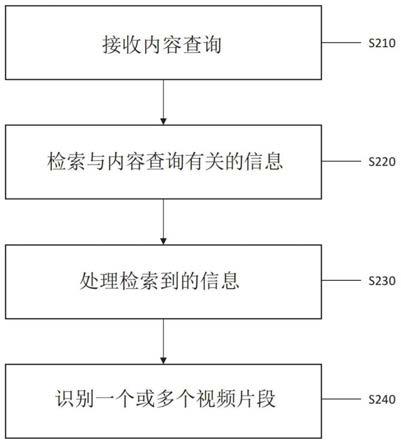
111.本文描述的系统和方法接收对内容的初始查询,并使用该查询来检索附加的相关信息,可以对其进行处理以找到附加的相关术语。这些新的相关术语可用于识别与初始内容查询相关的库中保存的视频片段。
112.另外,可以对视频片段库进行索引,以提高识别存储在库中的视频片段的速度。索引可以利用计算机视觉处理来识别与视频片段有关的描述符,该描述符可以与视频片段相关联,并随后用于搜索视频库。
113.图1示出了根据本公开的一方面的系统100的示例示意图。系统100包括视频内容发现模块110和信息源120、125。尽管示出了具有两个信息源的系统100,但是该系统可以适当地包括任意数量的信息源,例如一个信息源或三个或更多信息源。
114.图2示出了由系统100执行的用于使用一个或多个视频内容描述符来识别多个可用视频片段中的至少一个视频片段的示例过程。
115.在步骤s210中,视频内容发现模块110接收内容查询。该内容查询提供系统100使用的初始搜索定义,以识别视频内容。在最简单的情况下,内容查询可包含文本查询。例如,希望发现与猫有关的视频内容的用户可以输入内容查询“猫”。替代地或另外,内容查询可以包括搜索运算符,例如“or”,“and”,“not”(负关联)“*”(通配符),“()”(分组术语),“相关:”等等。
116.替代地或附加地,内容查询可以包括图像。当内容查询包括图像时,视频内容发现模块100可以提取元数据和/或运行图像识别技术来为对象定义合适的搜索定义。例如,猫的图像可以包括诸如“猫”的图像标签的元数据。类似地,视频内容发现模块100可以运行返回“猫”标签的图像识别技术。
117.此外,在内容查询包括图像的情况下,运行对象识别或元数据提取算法不是必需的。取而代之,该过程可以包括计算图像的描述符向量。该描述符向量可以用于通过到相关
视频片段描述符的距离来识别可用视频片段中最接近的视频片段。例如,给定演员的图像,查询可以返回该演员的视频片段。在这种情况下,描述符向量将是面部描述符向量。
118.在步骤s220中,视频内容发现模块110基于内容查询从一个或多个信息源120、125中检索与内容查询有关的信息(例如,它可以检索一个或多个文本段落,每个段落包括至少部分内容查询)。在该过程的该阶段,视频内容发现模块110没有试图直接识别视频片段。相反,视频内容发现模块正在搜索可以从中提取相关视频内容描述符的信息(将在下面进行更详细的说明)。
119.系统100使用的一个信息源120可以是因特网。在这种情况下,视频内容发现模块从互联网检索与内容查询有关的数据。该数据可以包括例如包含与内容查询有关的内容(纯文本,图像,视频等)的网页。当处理包括词“猫”的内容查询时,视频内容发现模块可以检索被互联网搜索引擎指示为与搜索项相关的一个或多个网页。
120.可以通过使用从互联网抓取网络(web)内容的工具或过程从互联网检索信息。网络数据抓取工具是一种应用程序编程接口(api),可从网站中提取数据。包括亚马逊网络服务(rtm)和谷歌(rtm)在内的许多公司向终端用户免费提供合适的网络数据抓取工具、服务和公共数据。
121.在步骤s220中,可以通过使用社交媒体网页(例如,博客,社交网络网站和推特(rtm))上的网络数据抓取工具来检索与内容查询有关的相关信息(诸如文本的段落)。附加地或可替代地,可以在步骤s220中通过从公共新闻网站(通过搜索并提取包含至少一部分内容查询的网页)提取信息来检索与内容查询有关的相关信息。类似地,可以在步骤s220中通过从公共视听内容(例如音乐、电视节目或电影)、脚本和/或音频描述服务(例如字幕)中提取信息来检索与内容查询有关的相关信息。
122.系统100使用的附加或替代信息源125可以是私有本地或联网数据库。私有数据库可以包括预先索引的信息,该索引信息可以基于系统进行的先前信息检索和处理来快速检索相关信息。
123.在步骤s230中,视频内容发现模块110处理检索到的信息以识别与内容查询有关的一个或多个视频内容描述符。该处理至少部分地使用人工智能处理来执行。能够基于初始内容查询从检索到的信息中识别视频内容描述符的任何合适的人工智能处理。为了简单起见,以下描述将集中于使用自然语言处理作为示例人工智能技术。然而,任何其他合适的人工智能处理的使用是被设想的
124.自然语言处理(以下简称nlp)已被定义为“计算机科学,人工智能领域,涉及计算机与人类(自然)语言之间的交互,并且特别是涉及对计算机进行编程以有效处理大型自然语言数据的领域”。自然语言处理中使用的主要度量是“向量距离”,它是分隔两个特定对象(例如单词)的距离。例如,词组“nice fruit”产生较高的nlp相关性,因为单词“nice”和“fruit”靠得很近(在这种情况下,彼此相邻)。包含“nice”和“fruit”的较长短语由许多其他单词分隔开,则相关性要低得多。例如,在短语“乔恩(jon)坐在办公桌旁吃水果(fruit)的外面,这是美好的一天(nice day)”中,“nice”不是指“fruit”,这可以通过低nlp相关性来反映。但是,此较长的短语将在“nice”和“day”之间产生较高的nlp相关性。
125.注意,该矢量距离可以以二进制的方式使用,例如通过提供关于单词“nice”和“fruit”是否少于三个单词来分隔它们的二进制指示。如果少于三个词,则在两个词之间建
立关联。如果有三个以上的单词,则不会建立关联。以三个字的分隔为例,可以使用更多或更少数量的分隔字,依次改变二元决策所表示的相关强度(一个或两个字的分隔表明相关性更强,四个或更多单词的分隔,表示相关性较弱)。
126.备选地,nlp可以利用加权关联,其中加权关联反映了关联的强度。如果“nice”和“fruit”之间的单词数为两个,则与单词数为五个时相比,可以建立更强的关联。一种简单的加权机制可以用作(字数 1)的倒数的乘数。如果单词是相邻的,这可能会赋予100%的关联权重;如果中间存在两个单词之间,则权重为33%;如果是四个单词,则权重为20%。当然也可以使用其他加权,包括非线性加权。
127.返回到步骤s230,视频内容发现模块110通过nlp对检索到的信息的处理产生了包括与内容查询相关联的词的一组数据,每个词具有对应的关联级别(二进制关联或加权关联)。例如,nlp可用于识别在最小接近度内的一个或多个相关术语,这些术语在所检索信息中至少一部分内容查询的一个单词,两个单词,三个单词等内(例如,检索到的信息中距内容查询的预定距离内的一个或多个相关术语)。以这种方式,视频内容发现模块发现了与原始内容查询相关的一组术语,否则这些术语将不会被明显地关联(例如,原始内容查询的明显拼写错误或相关拼写可能表示明显的关联,而此处公开的技术可以识别一个或多个不是明显关联的单词)。
128.继续内容查询“猫”的简单示例,在步骤s220,视频内容发现模块110可能已检索到一个或多个网页,包括例如,对最近一部名为《猫》的电影的评论、有关一只著名的“猫”的博客文章和在线词典网站中“猫”的定义。在步骤s230,视频内容发现模块110利用nlp处理这三个信息源,以找到与内容查询“猫”高度相关的术语。通过此nlp过程,获得了一个数据集,包括相关术语“新”和“电影”(来自评论“the new movie cats...”中的短语),术语“脾气暴躁”(来自重复引用著名猫的博客文章以“脾气暴躁的猫”被熟知),以及“软毛”(根据猫的词典定义)可以形成。在本公开中,由视频内容发现模块110在步骤s230中发现的这些附加的相关术语将被称为“视频内容描述符”。
129.在步骤s240,视频内容发现模块110使用一个或多个视频内容描述符来从多个可用视频片段中识别一个或多个相关视频片段。在步骤s240中,不必在该识别处理中使用原始内容查询。替代地,有利地,系统可以使用视频内容描述符基于视频内容描述符来识别视频片段,以识别通过仅使用原始内容查询的传统搜索算法不能识别的视频片段。
130.例如,以“猫”为例,将识别链接到搜索项“新”、“电影”、“脾气暴躁”和“软毛”中的一个或多个的视频片段,从而使相关视频片段能够被如果仅使用原始内容查询,则不会被识别。
131.作为步骤s220的一部分,视频内容发现模块110可以可选地基于相关搜索项从一个或多个信息源检索信息。在这种情况下,视频内容发现模块执行处理接收到的内容查询的附加步骤,以识别与该内容查询有关的一个或多个搜索项。例如,对于原始内容查询“猫”,视频内容发现模块110可以识别相关的搜索项,例如“猫”和“猫科”。然后,一个或多个附加搜索项可用于在s220中检索附加信息(可选地,除了使用内容查询本身之外),例如,检索包含一个或多个搜索字词中的至少一个的文本段落。然后,s230的过程可以使用与上述相同的方式,对检索到的文本段落使用nlp,以将搜索项和/或内容查询转换为一个或多个视频内容描述符的集合(例如,识别内容查询或搜索到的信息中搜索项的预定距离内的相
关词条)。这可以导致在步骤s230中获得更大的相关项数据集,从而导致在步骤s240中识别出额外的相关视频片段的可能性。
132.在本公开中,描述了“视频片段”的识别。视频片段可以是例如视频,视频的一部分(例如场景)或视频的任何其他划分。
133.根据系统100检索和处理的信息量,可以产生视频内容描述符的非常大的数据集。一些视频内容描述符可以导致系统100识别出更多相关的视频和/或可以使系统100处理起来更简单。因此,现在描述另一种方法,该方法优先考虑一个或多个视频内容描述符。
134.人工智能(例如机器学习过程)可用于从首选描述符列表中优先识别视频内容描述符,以简化后续的识别步骤。在这种情况下,仅当视频内容描述符出现在允许的视频内容描述符的列表上时,才可以在步骤s230识别或保留视频内容描述符。限制系统使用的可能视频内容描述符的数量可以减少用于识别视频片段的计算负担。
135.可以选择允许的视频内容描述符以使其与系统可用的视频片段相关。例如,如果大多数可用视频片段与电影有关,则可以选择允许的视频内容描述符以帮助区分不同的电影,着重于与类别、情感、动作、情感、对象等有关的视频内容描述符。
136.在本公开中,步骤s230中识别的视频内容描述符和允许的视频内容描述符可以包括以下一项或多项:
137.对象描述符,指示内容查询所涉及的内容
‑“
猫”与动物有关,“可口可乐”(rtm)与饮料有关;
138.对象生存期描述符,指示内容查询中描述的对象的预期生存期或持续时间;
139.面部描述符,指示与内容查询相对应的面部、面部类型或面部一部分的
‑“
芭蕾舞女演员”与女性面孔有关;
140.上下文描述符,指示与内容查询有关的上下文
‑“
海滩”涉及炎热和晴天,“葬礼”涉及阴雨和黑暗等;
141.语义描述符,与内容查询有关的图形和/或文字描述符有关;
142.类别描述符,指示与内容查询有关的类别
‑“
教父”涉及电影、电视、书籍、黑帮等;
143.情感描述符,指示与内容查询有关的情感的,“小狗”与快乐和喜悦有关,“葬礼”与悲伤有关;
144.语言环境描述符;指示与内容查询有关的位置,例如海滩,山脉或地理位置等;
145.人口统计描述符,指示与内容查询相关联的人口统计;
146.动作描述符,指示与内容查询相关联的动作;
147.每日时间描述符,指示与内容查询相关联的一天中的时间;
148.年度季节描述符,指示与内容查询相关的季节;和
149.天气描述符,指示与内容查询关联的天气类型。
150.图3示出了由系统100执行的用于使用一个或多个视频内容描述符来识别多个可用视频片段中的至少一个视频片段的示例过程。
151.在步骤s310中,视频内容发现模块110接收内容查询。内容查询提供系统100使用的初始参数,以识别视频内容。在一个示例中,该内容查询可以是图像或文本查询。当内容查询包括图像时,可以运行附加的图像识别过程以提取人的身份(可以代替上一示例中所述的文本查询来使用)和/或与图像有关的描述符。例如,“海滩场景”中未知电影明星的图
像可能导致识别出的描述符包括“老”和“人”(人描述符)“幸福”(语义描述符)“海滩”(位置描述符)和“晴天”(天气描述符)。
152.在步骤s320中,视频内容发现模块110基于内容查询(和/或基于内容查询确定的搜索项或描述符)从一个或多个信息源120、125检索与内容查询有关的信息(和/或基于内容查询识别的搜索项或描述符)。在该步骤中,一些或全部内容查询和/或相关搜索项和/或相关描述符可用于单个或组合地检索该信息。在上面给出的示例中,“人、快乐、海滩”可用于检索相关新闻文章、博客文章、维基百科条目等。
153.在步骤s330中,视频内容发现模块110处理检索到的信息(在这种情况下,例如新闻文章、博客文章和/或维基百科条目)以识别一个或多个视频内容描述符,所识别的视频内容描述符对应于允许的视频内容描述符列表上的允许的视频内容描述符。该处理至少部分地使用人工智能来执行。
154.使用允许的内容描述符列表可以通过使从人工智能处理中获得的与允许的内容描述符不匹配的结果被排除在进一步处理之外,从而提高此方法的效率。其中,在大量已识别信息上运行nlp流程,可识别出大量相关的相关术语。将这些识别出的术语与一系列允许的术语进行匹配,极大地简化了进一步处理大型数据集所需的计算处理。
155.回到我们的简化示例,作为步骤s330的一部分在术语“海滩”上运行的nlp处理可以返回高度相关的视频内容描述符,例如“沙子”和“海岸”。在使用相对简短的允许的视频内容描述符列表的情况下,术语“海滩”和“海岸”可能不包含在列表中,而术语“沙子”可能会包含在内(因为术语“沙子”可能是相关的到海滩视频片段和沙漠视频片段
‑
代表了更广泛的搜索字词)。因此,在该示例中,步骤s330已经从初始内容查询中识别出允许的视频内容描述符(“沙子”),从而能够稍后识别在与描述符“沙子”相关联的库中的视频内容。
156.可选地,如果在步骤s330中没有识别出允许的视频内容描述符,或者在步骤s330中识别了不足的允许的视频内容描述符,则该方法可以返回到步骤s320以检索与内容查询有关的附加信息以进行处理。可以根据需要重复此过程。
157.虽然单个允许的视频内容描述符的识别将使您能够从内容查询中识别视频片段,但是识别更多允许的视频内容描述符可导致在下一步中识别出更多数量的视频片段。因此,可选地,该方法可以重复步骤s320和s330,直到识别出阈值数量的允许的视频内容描述符。此阈值数可以是1,也可以是任何更高的数。
158.在步骤s340中,视频内容发现模块110使用一个或多个允许的视频内容描述符来从多个可用视频片段中识别一个或多个相关视频片段。在此步骤中,可允许的视频内容描述符(例如“沙子”)可导致识别与词“沙子”相关的相关视频片段。应当理解,在已识别了进一步的允许的视频内容描述符(例如“演员”作为来自“人”的相关的允许的视频内容描述符)的情况下,可以提高所识别的视频片段与原始搜索查询的相关性(如此进一步的示例将返回与“沙子”和“演员”相关联的视频片段。
159.在此简化的示例中,将识别出的搜索描述符与允许的视频内容描述符直接进行比较似乎更为有效,从而避免了检索和处理相关信息的需求。但是,这样做会错过对与内容查询间接相关(即,通过诸如文本的段落之类的检索信息而相关)的视频内容描述符的识别。本文描述的方法的主要优点在于能够基于有限的信息来识别视频内容描述符(因为从例如互联网检索到附加的相关信息)。
160.再举一个例子,基于未知的(对于系统而言)新饮料的初始内容查询
‑
例如“雪碧可乐”的文本查询。该初始内容查询甚至与饮料无关,也没有明显的联系,因此,现有技术的系统将难以检索任何相关的视频片段。但是,根据本公开,该内容查询可以用于执行互联网搜索,该互联网搜索可以检索适当的定义(它是一种饮料)和博客“评论”(强调它可能是年轻人喜欢的运动饮料),从而可以识别视频内容描述符(例如“饮料”、“体育”和“活跃”),从而识别相关的视频内容。
161.识别相关视频
162.在以上示例中,所识别的视频片段可各自被认为是同等相关的。在这种情况下,可以将每个识别出的视频片段呈现给用户,以使用户能够选择和观看他们选择的识别出的视频片段。
163.为了将识别出的视频片段呈现给用户,该系统和方法可以进一步适于为一个或多个识别出的视频片段中的每个视频片段识别或获得代表图像。代表性图像可以是从视频片段获取的图像,例如第一张图像,最后一张图像或从视频片段的任何其他部分获取的图像。然后可以例如通过在视频显示器上示出,来输出一个或多个识别出的视频片段中的每个视频片段的代表图像。
164.还可以至少部分基于与原始内容查询的相关性(和/或基于内容查询所识别的任何识别的搜索项),作为人工智能处理结果的相关性来衡量选择每个视频片段的代表性图像。例如,包括多个“场景”的视频片段可以具有与视频片段中的特定场景更相关的相关内容描述符。因此,可以从与从内容查询中识别出的视频内容描述符最相关的视频片段内的场景中选择代表图像。
165.本文所述的系统和方法还可以寻求对所识别的视频片段进行排序,以使得具有较高相关性的所识别的视频被显示在相关性较低的视频片段之前和/或比不相关的视频片段更突出。
166.在这种情况下,视频内容发现模块110可以进一步被配置为基于相关性得分对一个或多个识别的视频片段进行排名。关联性得分指示每个识别的视频片段与内容查询的相似度。链接到最高数量的已识别视频内容描述符和/或最相关的已识别视频内容描述符的已识别视频片段被认为是最相关的已识别视频片段。可以预先确定所识别的视频内容描述符的相关性(通过对可用视频内容描述符列表中的视频内容描述符进行加权),或者基于视频内容描述符的相关强度(例如,在使用加权nlp算法时所识别的强度)。
167.一旦已经为每个识别的视频片段建立了相关性得分,就可以按照它们各自视频片段的排名顺序将代表性图像呈现给用户。
168.视频片段的处理
169.上述示例描述了如何获得视频内容描述符。在下文中,描述了使用这些视频内容描述符来识别视频片段的示例方法。
170.感兴趣的视频片段可以从可用视频片段库中检索。可用视频库可以被预先索引,使得每个视频与视频内容描述符相关联。用于在库中为视频编制索引的方法是本领域已知的,并且可以采用任何合适的方法。对视频进行预索引会导致库中的每个视频都具有元数据,该元数据可以包括标准化标签,该标签可以包括包含以下一项或多项的详细信息:标题、影片长度、一个或多个视频内容描述符(描述视频图像内容的各个方面)和/或任何其他
相关的元数据。
171.可以通过将确定的视频内容描述符与与保存在库中的每个视频片段相关联的视频内容描述符进行迭代比较来识别相关的视频片段。可选地,可以随后对匹配的视频进行排序。该排序可以基于给定视频与确定的允许的视频内容描述符共有的视频内容描述符的数量。在这种情况下,共同的视频内容描述符的数量越多,特定视频片段的排名就越高。该概念基于以下思想:如果给定的视频片段具有大量的视频内容描述符,这些内容描述符与基于内容查询识别的视频内容描述符相同,则视频很可能具有很高的相关性。如果视频片段的共同描述符较少,则可能相关性较低。
172.另外或作为替代,当匹配的视频内容描述符的相关强度可用时(例如,当使用加权nlp算法时),所识别的视频片段的排序可以将匹配的视频内容描述符的相关强度考虑在内。例如,可以认为仅具有单个匹配视频内容描述符但与搜索查询高度相关的视频片段比具有两个具有低相关性值的匹配视频内容描述符的视频片段更相关。可以使用任何合适的加权排序方法。
173.通过使用上面允许的视频内容描述符能够改进迭代比较方法。限制需要比较的视频内容描述符的数量可以减少处理库中每个视频片段所需的计算负担。
174.为了进一步改进该方法,可以基于视频内容描述符的允许列表对库中的视频片段重新索引,从而在视频片段识别步骤中,仅考虑允许的视频内容描述符。可选地,该重新索引编制可以包括通过人工智能处理来创建映射表。下面将进一步描述用于执行该重新索引的系统和方法。
175.图4示出了根据本公开的一方面的系统400的示例性示意图。该系统400包括映射模块450和可用视频片段库460。
176.可选地,系统400还可以包括映射数据库470。因为可用视频片段库460可以用于存储与可用视频片段库有关的所有元数据,所以该映射数据库是可选的。当提供时,映射数据库470可以包括映射表(未示出)。映射表也可以存储在可用视频片段库460中。
177.图5示出了由系统400执行的用于重新索引多个可用视频片段中的至少一个视频片段的示例过程。
178.在步骤s501,映射模块450接收视频片段。在该步骤中,映射模块450可以从外部源接收新视频,或者可以从库460中检索可用视频。
179.在步骤s502,映射模块450可以运行第一过程以识别与所接收的视频片段有关的一个或多个视频片段描述符。第一过程可以是识别视频片段内的对象和/或场景的任何合适的计算机实现的方法,可以从中提取视频片段描述符。
180.例如,可以使用一个或多个计算机视觉过程来自动检测和识别视频片段内的一个或多个对象。能够用于产生视频片段中的对象列表的典型方法包括来自微软(rtm)的“fast
‑
cnn”(rtm)。还有许多其他类似的工具可用于将场景转换为对象列表。所识别的对象本身可以用作视频片段描述符,从而使包含共有对象的视频片段能够由公共视频片段描述符链接。
181.另外或可替代地,在许多情况下有可能从所识别的对象中推断出位置。例如,包含电视和椅子的视频片段可能导致推断出“休息室”的位置。类似地,包含桌子和椅子的视频片段可以替代地导致推断出“厨房”或“饭厅”。这些推断的位置可以用作视频片段描述符,
从而使得具有共同位置的视频片段能够被公共视频片段描述符链接。
182.通过对视频片段的进一步分析,可以推断出其他因素,例如情绪。分析情绪的方法通常需要在视频片段中找到或推断出的文本才能输入。推断视频片段情感的一种示例方法是使用ibm的watson(rtm)。视频片段的情感分析可能会导致视频片段描述符为“快乐”或“悲伤”等。
183.推断视频片段的情感的另一示例方法是使用亚马逊网络服务(amazon web services)的aws(rtm)情感分析工具(或类似的api)。基于对视频片段和/或与视频片段相关联的字幕的文本描述的分析(可以从视频内容中提取或使用其他内容识别工具从视频内容中自动生成)和/或从视频片段中所获取的语音音调,可以将情感描述符分配给视频片段。推断视频片段的情绪的另一个示例是直接分析视频片段内的图像,并预测观众的情绪,并可选地与视频片段角色的情绪预测一起。除了视频片段情感分析之外,还可以直接分析与视频片段关联的音频,以从背景音乐和噪音中推断出情感视频片段描述符。
184.组合地,这些过程可导致每个视频片段与一个或多个视频片段描述符相关联,这使得以后能够基于一个或多个视频片段描述符来识别库中的相关视频片段(例如,参考图2和3使用以上所描述的过程)。例如,在包含视频片段的视频内容上训练的神经网络,该视频片段带有具有位置描述符(例如,一般描述符,例如“室内”或“室外”,和/或更精确的描述符,例如“公园”、“森林”、“市区”或“客厅”)的注释,然后可以用来识别与特定位置相关的视频片段。
185.在以上示例中,第一过程包括对象检测、位置检测和情感检测中的一个或多个。但是,第一过程还可以包括以下一项或多项:面部检测算法、上下文检测算法、语义检测算法、类别检测算法、情绪检测算法、人口统计检测算法、字幕识别算法、语音识别算法、动作检测算法、每日时间检测算法、年度季节检测算法以及天气检测算法。
186.一旦处理完,视频片段描述符就可以与传统的迭代搜索方法一起使用,以在库中找到视频片段。另外,这些视频片段描述符使该库能够与以上关于图1至图4描述的视频内容发现的系统和方法一起使用。因此,在步骤s502之后,一旦接收到视频片段已按照步骤s502中所述进行了处理,则该方法可以在步骤s503处结束。因为已经对库中的视频进行了索引,以使它们能够基于关联的视频片段描述符进行迭代搜索,故该过程可以在此步骤结束。
187.可替代地,可以发生附加的处理步骤。在步骤s502之后,在步骤s504中,可以运行第二过程以基于视频片段描述符来创建映射表。映射表将每个接收到的视频片段链接到一个或多个视频内容描述符,其中,一个或多个视频内容描述符是从可搜索视频内容描述符的列表中选择的。一旦创建了映射表,就可以将其用于更快地识别相关视频片段,而无需迭代检查每个视频片段以查看其是否与特定的视频内容描述符相关联。
188.为了创建映射表,第二过程可以至少部分地包括人工智能处理。人工智能处理可以包括nlp算法,用于将所识别的视频片段描述符与可搜索视频内容描述符列表中的一个或多个视频内容描述符相关。人工智能处理可能导致形成用作映射表的神经网络。
189.例如,可以基于对链接到视频内容的视频片段描述符的分析来构建映射表以学习视频内容的类型。在使用视频内容描述符来描述在视频内容中检测到的情绪和/或情境的情况下,可以预测给定视频片段的类型。例如,一个谋杀案的神秘节目可能具有“恐惧”和
“
痛苦”的情感描述符,并带有“警察局”作为背景。相比之下,浪漫的表演可能具有“爱”和“快乐”的情感描述符,可能与“海滩”或“餐厅”结合在一起作为情境描述符。
190.可以通过使用适于将视频片段链接到视频内容描述符列表的任何标准工具或过程来创建映射表。在一个简单的示例中,视频内容描述符的列表仅由对象描述符组成(例如,100个常见对象的列表,例如“椅子”、“桌子”、“球”、“电视”),则映射表可以是通过在每个视频片段上使用对象识别算法识别和创建每个视频片段,然后将每个视频片段与其中包含的100个常见对象中的任何一个进行链接,来创建“视频”。一旦创建了此映射表,就可以通过从视频内容描述符列表中选择100个常见对象中的一个或多个来轻松获得相关视频,这将导致识别出包含这些对象的视频片段。
191.在使用中,视频内容描述符列表可能包含来自一个以上描述符类别的视频内容描述符(如上所述,例如语义,位置,天气等)。因此,可以使用多个工具或过程来创建映射表。例如,除了100个常见对象之外,视频内容描述符的列表还可以包括20个语义描述符的列表(例如“快乐”和“悲伤”)。可以通过使用任何合适的算法(例如由亚马逊网络服务(rtm)提供的算法)从视频片段中推断出语义描述符。附加地或可替代地,可以从已经使用现有工具或算法(例如,可以从包括电视,沙发和茶几等物品的识别中推断出“客厅”位置描述符)识别的其他描述符中推断出一些描述符(例如语义描述符或位置描述符等)。在此另外的示例中,映射表使视频片段能够被识别,该视频片段包括一个或多个对象描述符和一个或多个语义描述符(例如返回包含“球”或“悲伤”视频片段的“快乐”视频片段,其中“快乐”视频片段包含“桌子”和“椅子”)。
192.随着视频内容描述符列表中使用更多类别的视频内容描述符,可以识别出高度特定的视频片段。例如,在具有足够大的描述符集的情况下,可以轻松识别具有非常特定标准的视频片段,例如从“电影”,包含“猫”,附加“面部”,“海滩场景”,这是“快乐的”,在“夏天”中尽管有“暴风云”却包含“日出”的片段。
193.技术人员将容易地意识到,可以在不脱离本公开的范围的情况下,对本公开的上述方面进行各种改变或修改。
194.上面描述的本公开的各方面可以通过软件、硬件或软件和硬件的组合来实现。例如,视频内容发现模块110的功能可以由包括计算机可读代码的软件来实现,该软件在任何电子设备的一个或多个处理器上执行时,执行上述功能。该软件可以存储在任何合适的计算机可读介质上,例如,非暂时性计算机可读介质,例如只读存储器、随机存取存储器、cd
‑
rom、dvd、蓝光、磁带、硬盘驱动器、固态驱动器和光盘驱动器。所述计算机可读介质可以分布在网络耦合的计算机系统上,从而以分布式方式存储和执行计算机可读指令。备选地,视频内容发现模块110的功能可以由被配置为例如借助诸如fpga的可编程逻辑来执行该功能的电子设备来实现。
195.图6示出了电子设备600的示例表示,该电子设备600包括计算机可读介质610,例如存储器,该计算机可读介质610包括被配置为执行上述过程的计算机程序。该电子设备600还包括用于执行计算机程序的计算机可读代码的处理器620。将意识到,电子设备600可以可选地包括任何其他合适的组件/模块/单元,例如一个或多个i/o终端,一个或多个显示设备,一个或多个另外的计算机可读介质,一个或多个另外的处理器等等。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。