1.本发明涉及叶片含氮量检测技术领域,具体涉及一种植物叶片氮含量检测方法及系统。
背景技术:
2.樟科楠属常绿大乔木,中国特有,被列为国家二级珍稀濒危种,在楠木人工林的建造过程中,有50%以上的人工林需根据营养诊断结果进行肥力提升或低产低效林改造,因此,亟需提升闽楠的营养诊断技术,改善林地肥力结构,实施森林质量精准提升;
3.氮素(n)是闽楠生长过程中所必需的主要营养元素的一种,同时也是限制闽楠生长和产量形成的重要因素,恰当的施用氮肥不但能够有效的帮助闽楠生长,还能提升其产量,实现实时、快速的检测闽楠氮素营养水平,对楠木营养诊断技术的提升具有重大意义。
4.现有技术存在以下不足:现有闽楠叶片进行含氮量检测时,通常仅是通过对闽楠叶片做光谱图像检测,通过光谱图像数据来判断闽楠叶片的含氮量,然而,光谱图像检测仅是检测闽楠叶片的表征参数,对于闽楠叶片的含氮量检测来说,对含氮量的影响存在多种因素(如叶片洁净度、含水率等),仅通过单个参数检测闽楠叶片含氮量容易导致检测结果误差大,检测精度低。
技术实现要素:
5.本发明的目的是提供一种植物叶片氮含量检测方法及系统,以解决背景技术中不足。
6.为了实现上述目的,本发明提供如下技术方案:一种植物叶片氮含量检测方法,所述检测方法包括以下步骤:
7.s1:叶片预处理
8.采集叶片洗净晾干,于电热恒温杀青并烘干至恒重,然后经粉碎机粉碎成粉末状,干叶粉末样品装袋保存;
9.s2:化学检测
10.通过凯氏定氮法对一部分叶片粉末进行含氮量检测;
11.s3:光谱检测
12.另一部分叶片粉末装入培养皿中,置于近红外光谱仪器上进行光谱测定;
13.s4:模型建立
14.基于化学计量学软件分析粉末含氮量,结合红外光谱仪器检测结果进行建模。
15.优选的,步骤s1中:电热恒温鼓风干燥箱杀青的温度设置为105-110℃,杀青时间为10-30min,叶片烘干至恒重的温度设置为80-90℃。
16.优选的,步骤s2中,叶片粉末装入培养皿中的装样厚度为15-18mm,置于近红外光谱仪器上进行光谱测定,使用management软件设置光谱扫描参数:扫描范围10000-4000cm-1
,扫描次数32次,分辨率8cm-1
,环境温度保持恒定24-25℃。
17.优选的,所述近红外波段光谱图像采集过程包括以下步骤:
18.s2.1:图像采集前,根据光源照明程度,对高光谱镜头进行黑白校正;
19.s2.2:选择黑白校正文件加载并保存;
20.s2.3:设置红外光谱仪器的各项参数。
21.优选的,所述高光谱镜头进行黑白校正的步骤为:
22.s2.11:将高光谱镜头盖住,在完全闭光的环境下获得黑校正图像b;
23.s2.12:将反射率大于99%的白板置于载物台;
24.s2.13:根据光谱扫描样本的反光程度调整镜头光圈。
25.优选的,步骤s4中,模型建立前先对数据进行处理,数据标准化标准差计算公式为:
[0026][0027]
则标准化转换公式为:
[0028][0029]
式中,μ为总体数据的均值,σ为总体数据的标准差,x为个体的观测值。
[0030]
优选的,步骤s4中,模型建立通过选择有效波段优化,具体包括以下步骤:
[0031]
通过一个波段光谱图像的特征值与另一波段下的光谱图像特征值相除,得到相对波段反射强度的图像具体计算公式为:
[0032]
bv
i,j,r
=bv
i,j,k
/bv
i,j,l
[0033]
其中,bv
i,j,k
表示第k波段坐标为(i,j)的特征值,bv
i,j,l
为另一波段下的光谱图像特征值,bv
i,j,r
为相对波段反射强度的图像。
[0034]
本发明还提供一种植物叶片氮含量检测系统,包括采集模块、分析模块、校正模块以及处理模块;
[0035]
校正模块先对采集模块做黑白校正后,采集模块采集叶片的光谱图像信息以及叶片的化学成分信息,分析模块:分析叶片的化学成分以及叶片的光谱图像产生分析数据,处理模块接收分析模块分析数据,并依据数据建立模型。
[0036]
优选的,所述采集模块为近红外光谱采集仪器,所述近红外光谱采集仪器包括高光谱镜头。
[0037]
优选的,所述校正模块对高光谱镜头进行黑白校正,计算公式为:
[0038][0039]
其中,b表示在完全闭光的环境下获得的黑校正图像,w表示白校正图像,h0表示原始的高光谱图像。
[0040]
在上述技术方案中,本发明提供的技术效果和优点:
[0041]
1、本发明检测系统通过同时采集叶片的光谱图像信息以及叶片的化学成分信息,并通过分析模块分析叶片的光谱图像信息以及叶片的化学成分信息,通过两个数据综合分
析,再基于分析数据建立模型检测叶片的含氮量,检测精度高。
[0042]
2、本发明通过多元散射校正对红外光谱进行预处理,在减少光谱的差异性的同时,尽最大可能保留原有光谱中与化学成分相关的信息,因此,经过多元散射校正后能最大可能地消除光谱信息中的随机变异,有效消除因样本不均及样本颗粒大小差异所产生的散射对于光谱的干扰,从而提高检测精度。
[0043]
3、本发明在建立模型前通过数据标准化对数据做前期预处理,使得数据的协方差矩阵和相关系数矩阵在值上相等,便于后期计算以及建模,从而提高数据处理效率。
附图说明
[0044]
为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
[0045]
图1为本发明的系统模块图。
[0046]
图2为本发明的叶片检测流程图。
[0047]
图3为本发明实施例3中样品的近红外光谱图。
[0048]
图4为本发明实施例3中光谱预处理效果图。
[0049]
图5为本发明实施例3中模型内部交叉验证预测值和实测值关系示意图。
具体实施方式
[0050]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0051]
实施例1
[0052]
请参阅图1所示,本实施例所述一种植物叶片氮含量检测系统,包括采集模块、分析模块、校正模块以及处理模块,
[0053]
其中,
[0054]
采集模块:用于采集叶片的光谱图像信息以及叶片的化学成分信息;
[0055]
分析模块:包括化学成分分析单元以及光谱图像分析单元,化学成分分析单元用于分析叶片的化学成分,主要通过参考鲍士旦的方法进行养分含量测定,氮、磷、钾含量分别采用凯氏定氮法、钼锑抗比色法和火焰光度计法测定,光谱图像分析单元用于分析叶片的光谱图像,将所测得的样品实测值赋值于所采集得到的近红外光谱,并导入化学计量学软件nircal进行相关分析;
[0056]
校正模块:用于在采集模块采集叶片信息前,对采集模块做校正处理;
[0057]
处理模块:接收分析模块分析数据,并依据数据建立模型,该检测系统通过同时采集叶片的光谱图像信息以及叶片的化学成分信息,并通过分析模块分析叶片的光谱图像信息以及叶片的化学成分信息,通过两个数据综合分析,再基于分析数据建立模型检测叶片的含氮量,检测精度高。
[0058]
所述采集模块为近红外光谱采集仪器,近红外光谱采集仪器在采集高光谱图像
时,通过校正模块对高光谱镜头进行黑白校正,具体如下:
[0059]
首先将高光谱镜头盖住,在完全闭光的环境下获得黑校正图像b,之后将反射率99%以上的白板放置于载物台上,根据光谱扫描样本的反光程度调整镜头光圈,得到白校正图像w,计算公式如下:
[0060][0061]
其中,h0表示原始的高光谱图像,经过黑白校正后,光谱图像中的杂点与阴影大幅减少,成像更加清晰。
[0062]
所述处理模块优选主成分回归分析法(pcr)建模,做主成分分析之前一定需要先对数据进行标准化,保证所有原始数据量纲同一(如果不进行标准化,某些软件最后做出的主成分结果中,数值最大的一列指标对主成分的贡献率会非常高,结果不可靠)。
[0063]
数据标准化的方法一般选取z-score方法,因为可以保证数据的协方差矩阵和相关系数矩阵在值上相等,简便计算,或者也可以换别的标准化方法,数据标准化标准差计算公式如下:
[0064][0065]
则标准化转换公式为:
[0066][0067]
上式中,μ为总体数据的均值,σ为总体数据的标准差,x为个体的观测值,通过数据标准化对数据做前期预处理,使得数据的协方差矩阵和相关系数矩阵在值上相等,便于后期计算以及建模,从而提高数据处理效率。
[0068]
在前期数据处理结束后,就可以开始建立主成分分析模型,首先对原始数据的相关系数矩阵进行求解,求解公式为:
[0069][0070]
接下来对相关系数矩阵的特征值γi及特征向量δi进行求解,把相关系数矩阵的特征值从大到小排序,并计算每一个主成分对应的贡献率:
[0071][0072]
第i个主成分zi的求解方法为:
[0073]
zi=x*δi[0074]
一般来说,累计贡献率高于80%或85%代表包含了原始数据中足够多的信息,每一个主成分的贡献率代表了它包含的原始信息的百分比。
[0075]
主成分回归分析法模型结果读取如下:
[0076]
(1)不同主成分包含的信息不同;
[0077]
(2)主成分的含义需要人为确定,主成分分析只能把指标之间重叠的信息提取出来,但是这部分信息是什么,需要我们根据原始数据对该主成分的贡献进行判断(即看合成该主成分时每个原始指标前乘的系数)。
[0078]
建模波段:在全光谱段上不是所有的光谱信息都是对总提取物含量的预测有用,无效的光谱信息会影响所建模型的精度,因此,选择特定有效的光谱区域参与建模能够在一定程度上优化模型,提高模型的预测效果;
[0079]
通过高光谱采集得到的图像数据由一维波段以及二维空间平面图象组成,其中一维波段信息由连续不间断的光谱组成,而平面图象中又包括了样本区域和背景信息两部分,背景信息会给图像造成冗余干扰,所以在进行高光谱图像处理时应先去除背景信息,提取样本区域的有效信息。
[0080]
高光谱图像中除了叶片还有其他背景信息,在一些波段下这些冗余信息与样本的波段严重重叠,很难直接利用二值掩膜分割出叶片与背景区域。
[0081]
波段比处理的原理如下:
[0082]
通过一个波段光谱图像的特征值与另一波段下的光谱图像特征值相除,从而得到相对波段反射强度的图像。波段比处理可以降低叶片表面不平造成的光线反射不匀引起的干扰,加强光谱图像两波段的光谱差别,得到能够反映单一波段不具有的光谱信息,具体计算公式如下:
[0083]
bv
i,j,r
=bv
i,j,k
/bv
i,j,l
[0084]
其中,bv
i,j,k
表示第k波段坐标为(i,j)的特征值,bv
i,j,l
为另一波段下的光谱图像特征值,bv
i,j,r
为相对波段反射强度的图像。
[0085]
通过利用envi软件分析研究,基于近红外波段的高光谱图像中噪声或背景与样本叶片的波段部分重叠,难以分割,需要进行波段比处理。经过多次实验筛选发现1595.51nm/1446.11nm近红外光谱图像的波段比处理效果较好,通过选择有效波段参与建模能够优化模型,提高模型的预测效果。
[0086]
实施例2
[0087]
请参阅图2所示,本实施例所述一种植物叶片氮含量检测方法,所述检测方法包括以下步骤:
[0088]
(1)采集叶片通过纯水洗净晾干,于电热恒温鼓风干燥箱中105℃杀青10-30min,在调至80℃烘干至恒重,经粉碎机粉碎成粉末状,最终得到干叶粉末样品,装入聚四氟乙烯封口袋中,避光干燥保存,待用;
[0089]
其中54份作为建模集参与建模,另随机选取10份作为外部验证集用于检验模型。
[0090]
(2)将叶片粉末装入培养皿中,装样厚度15mm,反射盖压实,置于近红外光谱仪器上进行光谱测定。使用management软件设置光谱扫描参数:扫描范围10000-4000cm-1
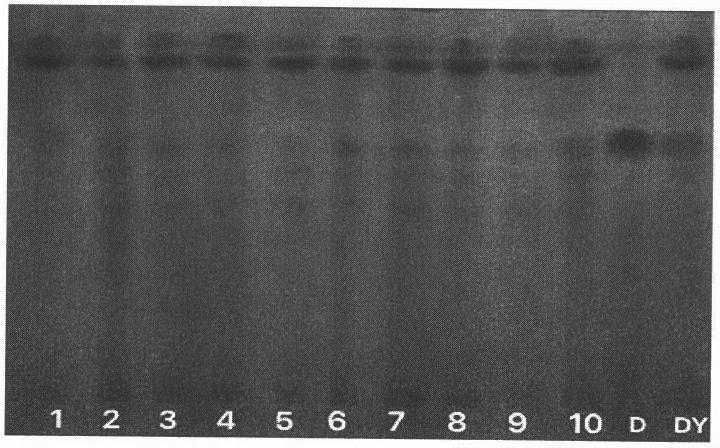
,扫描次数32次,分辨率8cm-1
,环境温度保持恒定24-25℃;
[0091]
采取单个样品重复装样3次、扫描3次,得到3张光谱,并取其平均光谱作为该样品的表征光谱;
[0092]
近红外波段光谱图像采集过程包括以下步骤:
[0093]
在图像采集之前,应先根据光源照明程度,通过spectrasens-n17e软件对高光谱镜头进行黑白校正,选择黑白校正文件加载并计算保存;
[0094]
设置好高光谱系统的各项参数以确保成像清晰。
[0095]
为了使得采集的图像更加清晰,在采集高光谱图像时需对高光谱镜头进行黑白校正,具体如下:
[0096]
首先将高光谱镜头盖住,在完全闭光的环境下获得黑校正图像b,之后将反射率99%以上的白板放置于载物台上,根据光谱扫描样本的反光程度调整镜头光圈,得到白校正图像w,计算公式如下:
[0097][0098]
其中,h0表示原始的高光谱图像,经过黑白校正后,光谱图像中的杂点与阴影大幅减少,成像更加清晰。
[0099]
(3)参考鲍士旦的方法进行养分含量测定,氮、磷、钾含量分别采用凯氏定氮法、钼锑抗比色法和火焰光度计法测定。
[0100]
(4)通过operator软件采集样品近红外光谱,再将所测得的样品实测值赋值于所采集得到的近红外光谱,并导入化学计量学软件nircal进行相关分析;
[0101]
依次通过选择合适的建模方法、最佳建模波段、预处理方法建立定量模型;
[0102]
选用内部交叉验证的方法检验模型,外部验证的方法评价模型的预测效果,以校正集相关系数(relatedcoefficientofcalibration,rc)、校正集均方根误差(rootmeansquareerrorofcalibration,rmsec)、交互验证集相关系数(relatedcoefficientofvalidation,rv)、交互验证均方根误差(rootmeansquareerrorofvalidation,rmsev)等4个值对模型进行评价,以确定最优模型;
[0103]
建模方法:包括偏最小二乘法(pls)、主成分回归分析法(pcr)、多元线性回归(mlr)等线性校正方法和人工神经网络(ann)、支持向量机(svn)等非线性校正方法。
[0104]
本实施例中,优选主成分回归分析法(pcr)建模,做主成分分析之前一定需要先对数据进行标准化,保证所有原始数据量纲同一(如果不进行标准化,某些软件最后做出的主成分结果中,数值最大的一列指标对主成分的贡献率会非常高,结果不可靠)。
[0105]
数据标准化的方法一般选取z-score方法,因为可以保证数据的协方差矩阵和相关系数矩阵在值上相等,简便计算,或者也可以换别的标准化方法,数据标准化标准差计算公式如下:
[0106][0107]
则标准化转换公式为:
[0108][0109]
上式中,μ为总体数据的均值,σ为总体数据的标准差,x为个体的观测值,通过数据标准化对数据做前期预处理,使得数据的协方差矩阵和相关系数矩阵在值上相等,便于后期计算以及建模,从而提高数据处理效率。
[0110]
在前期数据处理结束后,就可以开始建立主成分分析模型,首先对原始数据的相
关系数矩阵进行求解,求解公式为:
[0111][0112]
接下来对相关系数矩阵的特征值γi及特征向量δi进行求解,把相关系数矩阵的特征值从大到小排序,并计算每一个主成分对应的贡献率:
[0113][0114]
第i个主成分zi的求解方法为:
[0115]
zi=x*δi[0116]
一般来说,累计贡献率高于80%或85%代表包含了原始数据中足够多的信息,每一个主成分的贡献率代表了它包含的原始信息的百分比。
[0117]
主成分回归分析法模型结果读取如下:
[0118]
(1)不同主成分包含的信息不同;
[0119]
(2)主成分的含义需要人为确定,主成分分析只能把指标之间重叠的信息提取出来,但是这部分信息是什么,需要我们根据原始数据对该主成分的贡献进行判断(即看合成该主成分时每个原始指标前乘的系数)。
[0120]
建模波段:在全光谱段上不是所有的光谱信息都是对总提取物含量的预测有用,无效的光谱信息会影响所建模型的精度,因此,选择特定有效的光谱区域参与建模能够在一定程度上优化模型,提高模型的预测效果;
[0121]
通过高光谱采集得到的图像数据由一维波段以及二维空间平面图象组成,其中一维波段信息由连续不间断的光谱组成,而平面图象中又包括了样本区域和背景信息两部分,背景信息会给图像造成冗余干扰,所以在进行高光谱图像处理时应先去除背景信息,提取样本区域的有效信息。
[0122]
高光谱图像中除了叶片还有其他背景信息,在一些波段下这些冗余信息与样本的波段严重重叠,很难直接利用二值掩膜分割出叶片与背景区域。
[0123]
波段比处理的原理如下:
[0124]
通过一个波段光谱图像的特征值与另一波段下的光谱图像特征值相除,从而得到相对波段反射强度的图像。波段比处理可以降低叶片表面不平造成的光线反射不匀引起的干扰,加强光谱图像两波段的光谱差别,得到能够反映单一波段不具有的光谱信息,具体计算公式如下:
[0125]
bv
i,j,r
=bv
i,j,k
/bv
i,j,l
[0126]
其中,bv
i,j,k
表示第k波段坐标为(i,j)的特征值,bv
i,j,l
为另一波段下的光谱图像特征值,bv
i,j,r
为相对波段反射强度的图像。
[0127]
通过利用envi软件分析研究,基于近红外波段的高光谱图像中噪声或背景与样本叶片的波段部分重叠,难以分割,需要进行波段比处理。经过多次实验筛选发现1595.51nm/1446.11nm近红外光谱图像的波段比处理效果较好,通过选择有效波段参与建模能够优化模型,提高模型的预测效果。
[0128]
预处理方法:近红外光谱的实测光谱为样品的表观光谱(apparents pectrum),表
观光谱是由能够表征样品的真实光谱(realspectum)和不确定的背景(background)组成,样品的真实光谱包含了大部分物理、化学和生物等确定信息,其中有需要用到的确定信息,也有不需要的信息,此外光谱基线偏移、高频噪音、斜坡背景等偏差也会影响建模的准确性,增加近红外光谱分析的难度,因此在建立近红外光谱模型时,需要对近红外光谱进行预处理,预处理方法包括平滑算法、多元散射校正和导数算法。
[0129]
其中,
[0130]
平滑算法:应用广泛的平滑算法的数据拟合法主要有厢车平均法、移动窗口平均法和最小二乘拟合法这三个,厢车平均法原理是将光谱数据划分成几个等分,并使用每个等分的均值来代表原各个等分段的值,正因为如此,该方法会使光谱失真严重,平滑窗口宽度是移动窗口平均法的一个关键参量,窗口宽度太小会弱化去噪效果,太大则会平滑掉一些有用信息,目前只能依靠多次的尝试才能确定窗口宽度,本研究中用到的平滑算法是savitzky-golay卷积平滑法(savitzky-golaysmoothing)。
[0131]
多元散射校正:有效消除因样本不均及样本颗粒大小差异所产生的散射对于光谱的干扰,从而获得较“理想"的光谱信息。
[0132]
算法如下,先根据最小二乘法确定α值和β值的大小,然后将整个未知粒度的试样的光谱a(γ)转换成假想的基准粒度的光谱a0(γ)。设定两个因子的推定值分别为α
‘
和β
‘
,所以根据公式a(γ)=a0a0(γ) β e(γ)可得到如下变换式:
[0133]
a0(γ)=[a(γ)-β
‘
]/α
‘
[0134]
特定样品的光谱和全样品的平均光谱都可以作为α
‘
和β
‘
基准粒度的光谱,当使用平均光谱时具体计算如下:
[0135][0136]
线性回归方程为:
[0137][0138]
上式中的a表示校正集的光谱矩阵,ai表示第i个样品的光谱,通过最小二乘回归可求得α和β,通过调整α和β的大小,可以在减少光谱的差异性的同时,尽最大可能保留原有光谱中与化学成分相关的信息,因此,经过多元散射校正后能最大可能地消除光谱信息中的随机变异。
[0139]
导数算法:导数算法是光谱分析中应用最为广泛的一种光谱预处理方法,其中,一阶导数(firstderivative,1-der)和二阶导数(secondderivative,2-der)算法在原始光谱预处理中最为常见,导数光谱能够有效清除基线漂移和平缓背景的影响,但是,导数算法同时也会放大原始光谱数据带有的一些随机噪声,因此使用导数算法进行光谱数据预处理对原始光谱的分辨率和信噪比要求相对较高。
[0140]
因此,通过对上述算法进行研究,本实施例中,红外光谱进行预处理方法优选为多元散射校正,在减少光谱的差异性的同时,尽最大可能保留原有光谱中与化学成分相关的信息,因此,经过多元散射校正后能最大可能地消除光谱信息中的随机变异,有效消除因样本不均及样本颗粒大小差异所产生的散射对于光谱的干扰,从而获得较“理想"的光谱信
息。
[0141]
近红外光谱校正模型效果的评价,可以从模型自身相关性和外部预测能力两个方面来进行评价,关于模型的评价参数,较高的rc和rv,较低的rmsec和rmsev是一个好的预测模型应该具备的条件,而其中rv和rmsev又更为重要,这主要是因为虽然模型具有较高的rc和较低的rmsec,表示其预测建模样品的能力更强,但这也可能造成模型过拟合;
[0142]
本实施例中,通过化学计量学方法所建立模型的预测能力是依据样本集测量值与预测值之间的相关系数(r)和均方根误差(rootmeansquareerror,rmse)来评价的,模型的相关系数r越接近于1,均方根误差rmse越小,则表明所建模型的预测性能越好,预测精度也就越高,相关系数和均方根误差的计算公式如下:
[0143]
相关系数(r):
[0144][0145]
式中的xi为样本i的测量值,为xi的平均值,yi为样本i的预测值,为yi的平均值,n为样本数。
[0146]
均方根误差(rmse):
[0147][0148]
式中,yi为样本i的测量值,则为样本i的预测值,n为样本数。
[0149]
通过化学计量学方法所建立模型的预测能力是依据样本集测量值与预测值之间的相关系数(r)和均方根误差(rootmeansquareerror,rmse)来评价的,模型的相关系数r越接近于1,均方根误差rmse越小,则表明所建模型的预测性能越好,预测精度也就越高。
[0150]
而rv及rmsev代表模型在预测外部样本时的准确性,更高的rv和更低的rmsev就表明模型预测外部样本时更准确,同时rmsec和rmsev越接近越好,对于模型的外部验证,通过将10份未参与建模的样品的近红外光谱图导入模型,比对模型预测值和实测值,对模型的预测能力进行检测和评价,在利用spss25.0软件实施配对样本t检验,验证该方法的可靠性。
[0151]
实施例3
[0152]
于江西省永丰县官山林场楠木种子园,随机选择64棵单株,每单株为一个样本,采集中部功能叶片,不带小枝,得到64份闽楠叶片样品。
[0153]
试验所用的近红外光谱采集仪器为瑞士buchi公司生产的nirflexn-500(傅里叶变换近红外光谱仪),及其配套的operator光谱采集软件和nircal分析软件,仪器光谱范围为10000~4000cm-1
,分辨率8cm-1
。
[0154]
实验具体包括以下步骤:
[0155]
(1)闽楠叶片经实验室纯水洗净晾干,于电热恒温鼓风干燥箱中105℃杀青10~30
分钟,在调至80℃烘干至恒重,经粉碎机粉碎成粉末状,最终得到闽楠干叶粉末样品,装入聚四氟乙烯封口袋中,避光干燥保存,待用。其中54份作为建模集参与建模,另随机选取10份作为外部验证集用于检验模型。
[0156]
(2)将叶片粉末装入培养皿中,装样厚度15mm,反射盖压实,置于近红外光谱仪器上进行光谱测定。使用management软件设置光谱扫描参数:扫描范围10000~4000cm-1,扫描次数32次,分辨率8cm-1,环境温度保持恒定24~25℃。采取单个样品重复装样3次、扫描3次,得到3张光谱,并取其平均光谱作为该样品的表征光谱。
[0157]
(3)实验室氮含量的测定参考鲍士旦的方法进行闽楠养分含量测定,氮、磷、钾含量分别采用凯氏定氮法、钼锑抗比色法和火焰光度计法测定。
[0158]
(4)利用仪器配套的operator软件采集样品近红外光谱,再将所测得的样品实测值赋值于所采集得到的近红外光谱,并导入配套的化学计量学软件nircal进行相关分析,依次通过选择合适的建模方法、最佳建模波段、预处理方法建立定量模型。选用内部交叉验证的方法检验模型,外部验证的方法评价模型的预测效果。以校正集相关系数(relatedcoefficientofcalibration,rc)、校正集均方根误差(rootmeansquareerrorofcalibration,rmsec)、交互验证集相关系数(relatedcoefficientofvalidation,rv)、交互验证均方根误差(rootmeansquareerrorofvalidation,rmsev)等4个值对模型进行评价,以确定最优模型。
[0159]
建模方法选择:近红外光谱分析中,主要的建模方法有偏最小二乘法(pls)、主成分回归(pcr)、多元线性回归(mlr)等线性校正方法和人工神经网络(ann)、支持向量机(svn)等非线性校正方法。
[0160]
建模波段选择:在全光谱段上不是所有的光谱信息都是对总提取物含量的预测有用,无效的光谱信息会影响所建模型的精度。因此,选择特定有效的光谱区域参与建模能够在一定程度上优化模型,提高模型的预测效果。
[0161]
预处理方法选择:近红外光谱的实测光谱为样品的表观光谱(apparentspectrum),表观光谱是由能够表征样品的真实光谱(realspectum)和不确定的背景(background)组成。样品的真实光谱包含了大部分物理、化学和生物等确定信息,其中有需要用到的确定信息,也有不需要的信息。此外光谱基线偏移、高频噪音、斜坡背景等偏差也会影响建模的准确性,增加近红外光谱分析的难度。因此在建立近红外光谱模型时,需要对近红外光谱进行预处理。
[0162]
模型的评价近红外光谱校正模型效果的评价,可以从模型自身相关性和外部预测能力两个方面来进行评价。关于模型的评价参数,较高的rc和rv,较低的rmsec和rmsev是一个好的预测模型应该具备的条件,而其中rv和rmsev又更为重要。这主要是因为虽然模型具有较高的rc和较低的rmsec,表示其预测建模样品的能力更强,但这也可能造成模型过拟合;而rv及rmsev代表模型在预测外部样本时的准确性,更高的rv和更低的rmsev就表明模型预测外部样本时更准确,同时rmsec和rmsev越接近越好。对于模型的外部验证,通过将10份未参与建模的样品的近红外光谱图导入模型,比对模型预测值和实测值,对模型的预测能力进行检测和评价。在利用spss25.0软件实施配对样本t检验,验证该方法的可靠性。
[0163]
闽楠叶片氮含量的实测值
[0164]
按步骤(1)、(2)、(3)试验方法测定得到的样品全氮含量结果见表1:
[0165][0166]
表1
[0167]
所测64份闽楠叶片样品的氮含量最大值为19.15g
·
kg-1
,最小值为9.29g
·
kg-1
,平均氮含量为13.28g
·
kg-1
,样品含量涵盖范围较广,具有一定的代表性,可用于近红外光谱技术分析;
[0168]
全部样品的近红外光谱图如图3所示,由图看出,闽楠干叶粉末的近红外光谱总体变化趋势基本相同,但其反射率方面存在一定的区别,说明闽楠干叶粉末样品的近红外光谱可用于闽楠全氮含量的定量分析。
[0169]
本试验主要选用偏最小二乘法(pls)和主成分回归(pcr)两种方法建立模型,从中选择最优建模方法。两种建模方法的结果如表2所示:
[0170][0171]
表2
[0172]
pls和pcr两种方法所建模型的rc值均达到0.9以上,但pcr方法所建模型的rv值更高,rmsev也更低,rmsec和rmsev值更为接近,所以选择pcr方法建立的模型效果更好。
[0173]
建模方法确定之后,分别对不同的光谱区域进行建模,结果如表3所示:
[0174][0175]
表3
[0176]
虽然在三个波段内建立的模型rc值均高于0.9,但观察表中数据会发现在5000~7144,7404~10000cm-1
范围内建立的模型具有更高的rv值和更低的rmsev值,其rv值更大,且其rmsec值和rmsev值最为接近。由此表明,选择5000~7144,7404~10000cm-1
波段建立的模型效果更好。
[0177]
在选择最佳建模波段的基础上,使用标准化(normalization)、导数(derivatives)、平滑(smoothing)等一种及两种以上相结合的方式对光谱进行预处理,其结果如表4所示:
[0178]
[0179]
表4
[0180]
经一阶导数(db1)、二阶导数(db2)、sg(savitzky-golayfilter)平滑、归一化(nle)、乘法散射校正msc和snv标准化等预处理方法所建立的模型,各参数较为接近,但仔细比较后发现,经“一阶导数(db1)、平滑sg(savitzky-golayfilter)和归一化(nle)”预处理方法所建立的模型具有更高的rv值和更低的rmsev,效果最佳。图4为经预处理后所有样本的光谱图。
[0181]
选择5000~7144,7144~1000cm-1组合波段,经一阶导数、平滑sg和归一化预处理,利用pcr方法建立闽楠叶片氮元素含量模型,模型的各参数如表5所示:
[0182][0183]
表5
[0184]
图5是模型内部交叉验证预测值和实测值之间的关系图,由图可知,模型的预测值和样品实测值间没有显著差异,偏差较小。
[0185]
将10个未知样品的近红外光谱图导入模型检验所建模型的预测能力,结果如表6所示:
[0186][0187]
表6
[0188]
预测值和实测值的相对偏差在0.070~0.705范围内,预测值与实测值接近,表明模型的预测值和实测值具有较高的相关性。
[0189]
采用统计学分析方法,结合spss分析软件,对闽楠样品氮含量的预测值和实测值进行配对样本t检验,结果如表7所示:
[0190][0191]
表7
[0192]
p值为0.116,大于0.05,没有显著差异,说明nir结合pcr对闽楠叶片粉末样品的氮元素含量进行快速分析是可行的。
[0193]
借助近红外光谱仪,采集闽楠干叶粉末的光谱数据,结合其传统分析方法测得的理化值,经化学计量学分析方法处理可建立闽楠叶片氮含量预测模型,所建模型经外部检验,结果也无显著差异,足以说明应用近红外光谱分析技术建立闽楠叶片氮含量预测模型可行,为闽楠营养成分检测技术的改善奠定了一定的理论基础。
[0194]
相比于传统的化学分析方法,近红外光谱技术有着分析快速、无损,可实施大批量样品快速检测和实时在线分析的特点,其已逐渐替代传统分析方法,在工农业分析领域得到了广泛的运用。
[0195]
在植物氮含量检测方面,近红外光谱分析技术相关的研究现阶段主要集中在农业经济作物:小麦、苹果、茶等方面,对于林业经济树种方面的研究较少。
[0196]
本发明针对闽楠叶片建立近红外光谱氮含量检测模型,在建模方法方面,采用的建模方法为主成分回归,对比使用偏最小二乘法所建立的预测效果更好。
[0197]
上述实施例,可以全部或部分地通过软件、硬件、固件或其他任意组合来实现。当使用软件实现时,上述实施例可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令或计算机程序。在计算机上加载或执行所述计算机指令或计算机程序时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算机可以为通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集合的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质。半导体介质可以是固态硬盘。
[0198]
应理解,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况,其中a,b可以是单数或者复数。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系,但也可能表示的是一种“和/或”的关系,具体可参考前后文进行理解。
[0199]
本技术中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“以下至少一项(个)”或其类似表达,是指的这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b,或c中的至少一项(个),可以表示:a,b,c,a-b,a-c,b-c,或a-b-c,其中a,b,c可以是单个,也可以是多个。
[0200]
应理解,在本技术的各种实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术实施例的实施过程构成任何限定。
[0201]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0202]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0203]
在本技术所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0204]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0205]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
[0206]
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0207]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵
盖在本技术的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。