1.本发明涉及水泥烧成系统熟料游离氧化钙的预测领域,特别是涉及基于生成对抗网络的水泥熟料游离氧化钙数据的预测方法。
背景技术:
2.目前,新型干法水泥制造方法被广泛应用于我国主要的水泥生产企业,其生产工艺流程通常可分为生料制备、熟料煅烧和水泥制备三个环节。其中,熟料煅烧是水泥生产的核心工艺,直接影响水泥熟料的性能,其中水泥熟料游离氧化钙(fcao)的含量是评价水泥质量的一个重要指标。水泥熟料fcao含量很难在线监测,主要是离线人工采样化验,每小时采样化验一次,离线测量结果对水泥烧成过程的指导具有明显的滞后性,导致难以实现水泥烧成过程的实时控制和优化。水泥熟料烧成过程具有多时间尺度、标签样本数据少等特性,难以建立精确的水泥熟料fcao预测模型。随着科学技术的进步与发展,软测量技术被引入到水泥制造业熟料在线检测的研究中,软测量技术是通过建立易测变量(或称辅助变量、输入变量)与主导变量(或称输出变量,一般不易测量)之间的软测量模型,实现主导变量的在线预测,该技术不但经济可靠,不需要进行设备的维护,而且动态响应迅速,有利于水泥熟料fcao烧成过程的实时控制和优化,但是在生产过程中水泥熟料fcao含量样本数据是离线测量,单纯的应用软测量模型时并不能解决由离线测量导致的水泥熟料fcao含量样本数据量小的问题,水泥熟料fcao难以准确预测的问题依然存在,所以本文中引入生成对抗网络模型用于水泥熟料fcao含量样本数据的增强。
3.生成对抗网络是goodfellow在2014年提出的框架,模型中生成器和判别器相互博弈相互学习,生成器输入随机噪声生成图像,判别器通过判别图像是真实图像还是生成图像来训练并更新参数,而生成器则通过判别器误差的反向传播来更新权重和偏置,当生成器生成的图像能够“骗”过判别器时,二者博弈达到平衡并结束训练,但是该网络自提出以来就存在难以训练和训练不稳定等问题,有学者根据wasserstein距离的思想提出wasserstein生成对抗网络(wasserstein generative adversarial network,wgan),解决了原始生成对抗网络训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度,基本解决了模型崩溃的问题,判别器的损失函数能直接指示训练进程,这个数值越小代表wgan训练得越好,代表生成器产生的图像质量越高。本发明提出的网络结构采用wgan与回归预测网络融合的方法,借助wgan生成器强大的数据生成能力,将wgan用于流程工业中缺失标签样本数据的填补,解决了水泥熟料fcao含量样本数据量小的问题,又在wgan的基础上融合回归预测网络,随着标签样本数据量的扩充,回归预测网络能够更充分地从数据中捕获时空特征,从而提升了回归预测网络的性能,解决了应用软测量模型时水泥熟料fcao含量难以准确预测的问题。
技术实现要素:
4.本发明提出基于生成对抗网络的水泥熟料游离氧化钙数据的预测方法,采用将
wgan与回归预测网络结合的方法,将wgan应用于流程工业中缺失标签样本的生成,利用wgan生成的伪标签数据扩充数据集,用来训练回归预测网络,既解决了水泥熟料fcao含量离线检测造成的数据量小的问题,又解决了应用软测量模型时水泥熟料fcao含量难以准确预测的问题。
5.为实现上述目的,本发明所述方法包括以下步骤:
6.步骤1:根据对水泥生产工艺分析,获取与水泥熟料fcao含量相关的时间序列数据为辅助变量,将所述的n个辅助变量组成的时间序列进行归一化处理;
7.步骤2:将归一化后的数据输入回归预测网络进行预训练,其中,回归预测网络由cnn gru构成;
8.步骤3:根据步骤1中的水泥生产工艺流程,将所选的n个辅助变量的无标签样本数据组成的时间序列矩阵作为wgan网络中的生成器的输入;
9.步骤4:搭建wgan网络,包含生成器和判别器,采用wasserstein距离作为判别器的损失函数;将输入生成器的无标签辅助变量与生成器输出的伪标签数据进行数据拼接,并与有标签辅助变量与真实标签数据拼接成的样本对一起输入判别器,训练wgan;
10.步骤5:搭建ssp-wgan模型,结合wgan与回归预测网络,将wgan的生成数据与真实数据混合作为回归预测网络的训练数据集,并训练;
11.步骤6:通过训练好的回归预测网络,实现水泥熟料游离氧化钙的预测。
12.本方法的进一步改进在于:所述n个辅助变量的无标签相关变量的时序矩阵为:
13.其中,n对应影响水泥熟料f-cao生产相关变量的采样频率,n代表步骤1中所选的n个影响f-cao含量的相关变量。
14.本方法的进一步改进在于:使用wgan实现缺失标签的填补,wasserstein距离作为损失函数,wasserstein距离定义如下:
[0015][0016]
其中,pr为真实数据分布,pg为生成数据分布,hw为含参数w的判别器网络,在wgan中,判别器做的是近似拟合wasserstein距离,距离l可以指示训练进程,其数值越小,表示真实分布与生成分布的wasserstein距离越小,生成对抗网络训练的越好。
[0017]
本方法的进一步改进在于:将wgan生成的标签用于扩充cnn gru组成的回归预测模型的训练集,cnn gru网络的训练集数据由真实数据和生成对抗网络生成的数据两部分组成,将无标签样本按照真实数据中n个变量的排列顺序作为输入,生成的伪标签数据作为输出的方式排列,其中代表水泥熟料fcao值,无标签数据与伪标签和真实样本对混合训练回归预测模型,实现水泥熟料fcao含量的预测。
[0018]
本方法的进一步改进在于:所述回归预测网络的模型为:
[0019]yja
=σ
relu
(w
aj
*a b
aj
),j=1,2,...n
[0020]uja
=σ
down
(y
ja
),j=1,2,..n
[0021]rt
=σ(wr·
[h
t-1
,u
ja
]),j=1,2,..n
[0022]ct
=tanh(wc·
[r
t
×ht-1,
,u
ja
]),j=1,2,..n
[0023]ut
=σ(wu·
[h
t-1
,u
ja
]),j=1,2,..n
[0024]ht
=(1-u
t
)
×ht-1
, u
t
×ct
,j=1,2,..n
[0025]
其中*表示一维卷积运算,w
aj
表示第j个大小为2*1的卷积核,b
aj
表示第j个一维卷积的偏执。a为经过数据增强后输入的辅助变量矩阵,y
ja
表示第经过卷积后再通过relu激活函数激活后的结果。u
ja
代表经过最大池化操作后的低维向量,r
t
代表gru中的重置门,c
t
代表候选状态,h
t-1
,表示上一时刻的状态,wr和wc分别表示重置门权重矩阵和单元状态权重矩阵。x
t
表示经过卷积后的低维数据。u
t
代表更新门,h
t
代表当前状态。由u
t
判断需要从上一个时间节点的隐藏状态h
t-1
,中遗忘或记忆的信息。
[0026]
本方法的进一步改进在于:所述wgan网络模型为:
[0027][0028]
其中,x
n(i)
代表无标签辅助变量,代表生成器输出的伪标签,x
r(i)
代表有标签辅助变量,y
r,(i)
代表真实标签。d
ω
代表参数为ω的判别器网络,l(i)代表wgan的损失函数。
[0029]
由于采用了上述技术方案,本发明取得的技术进步是:
[0030]
1、本发明采用的水泥熟料游离钙含量样本数据增强及预测方法,采用wgan与回归预测网络结合的方式,将wgan应用于水泥工业中无标签样本数据的生成,解决了由于水泥熟料fcao含量离线检测导致的时滞和水泥熟料fcao样本量小的问题。
[0031]
2、本发明建立的基于ssp-wgan水泥熟料fcao含量样本数据增强及预测模型,充分利用wgan的优势,生成大量伪标签数据,在wgan的基础上融合回归预测网络,将生成的可靠数据应用于回归预测网络,实现水泥熟料fcao含量的预测,解决了水泥熟料fcao难以准确预测的问题。
附图说明
[0032]
图1为基于ssp-wgan的水泥熟料fcao含量样本数据增强及预测模型的结构图;
[0033]
图2为wgan网络生成器的结构图;
[0034]
图3为wgan网络判别器的结构图;
[0035]
图4为回归预测网络的结构图;
[0036]
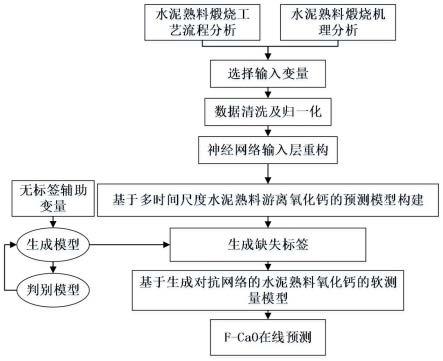
图5为本发明提出的基于ssp-wgan的水泥熟料fcao含量数据增强和预测模型流程图。
具体实施方式
[0037]
下面结合附图对本发明做进一步的阐释:
[0038]
本发明提出了一种基于ssp-wgan的水泥熟料fcao样本数据增强及预测方法,采用wgan和回归预测网络结合的方式,通过重构wgan生成器的输入层和输出层,将高维时序数据映射为低维标签值,填补了缺失标签数据。将影响熟料f-cao含量的相关变量和熟料f-cao数据按照时间尺度的关系进行数据拼接并作为判别器的输入层,解决了多时间尺度不平衡的问题。借助生成对抗网络博弈的思想,生成器捕捉到蕴含在标签样本数据中的高维特征并生成可靠的数据,实现了对输入无标签样本缺失标签值的填补,生成的伪标签用于
扩充由cnn和gru组成的回归预测模型,从而实现水泥熟料fcao的预测。整体结构如图1所示,wgan网络中的生成器结构如图2所示,判别器结构如图3所示,回归预测网络结构如图4所示,基于ssp-wgan的水泥熟料fcao含量生成预测模型流程如图5所示。
[0039]
步骤1:分析水泥回转窑工艺流程,选取与水泥熟料fcao含量相关的12个变量,首先将选择的变量数据按照时间序列排列,其次将数据按照cnn gru网络的输入层数据形式进行处理,再将数据进行归一化作为回归预测网络的输入数据。
[0040]
在步骤1中,首先分析水泥回转窑的生产工艺,选取12个与水泥熟料fcao含量相关的过程参量为辅助变量集,水泥熟料fcao含量为预测变量,所选的12输入变量分别为窑电流平均值x1、二次风温平均值x2、烟室nox平均值x3、分解炉出口温度1x4、分解炉出口温度2x5、窑头负压反馈x6、烟室氧气滤波x7、二室北篦下压力反馈x8、二室南篦下压力反馈x9、分解炉喂煤量x
10
、高温风机转速x
11
和窑头煤反馈x
12
,水泥熟料fcao含量y为输出变量。将上述12个变量数据作为回归预测模型的输入层数据输出变量为y。由于所选取的不同变量间差异较大,为了提高模型收敛速度以及减少数据特征的损失,对数据进行归一化处理。
[0041]
步骤2:建立基于cnn gru的回归预测网络,将步骤1中归一化后的数据输入到回归预测网络,进行预训练并保存模型。
[0042]
回归预测网络的结构如图4所示,首先对输入数据进行卷积运算,并对经过卷积运算的输入数据进行池化,从中提取时空特征,将输出的特征图谱输入到gru网络中,gru中每个时间步的隐藏节点会学习捕捉不同时间步跨度下不同依赖信息的特征,经过两层堆叠gru结构后输出的序列最后进入全连接层中,通过全连接层将局部特征链接为全局特征,以此提高网络的特征提取能力和预测精度。从而完成了回归预测模型的前向训练过程,通过反向传播算法更新卷积层中以及gru中更新门、重置门、单元状态的权重矩阵参数,实现输出误差最小化。
[0043]
步骤3:将与水泥熟料fcao相关的12个的无标签变量组成的时间序列矩阵作为wgan中生成器的输入数据。
[0044]
在步骤3中,传统的噪声被替换为相关变量时序矩阵作为生成器的输入,通过生成器中的卷积层实现从高维无标签变量到低维标签值的映射。水泥熟料f-cao的采样间隔约为一小时,滞后性较大。通过工艺分析可知,f-cao的含量受相关变量的共同影响而变化。这些相关变量的采样间隔约为一分钟,因此生成器的输入数据集为n对应影响水泥熟料f-cao生产相关变量的采样频率,即n=60,12代表步骤1中所选的12个影响f-cao含量的相关变量,即60条相关变量数据对应一个f-cao数据,在这个矩阵中12个变量每一时刻的数值都影响着下一时刻的f-cao数值,以此作为wgan生成器的输入。
[0045]
步骤4:搭建wgan网络,该网络包括生成器和判别器两部分,将步骤3中整合好的无标签数据集输入生成器,将相关变量数据与真实标签拼接的样本对输入判别器。采用wasserstein距离作为判别器的损失函数,同时指示训练进程。
[0046]
①
wasserstein生成对抗网络模型中的生成器结构如图2所示,其输入不在是随机噪声而是影响水泥熟料f-cao含量相关变量数据组成的时间序列矩阵。生成器内部采用多层卷积神经网络代替传统的反卷积网络。图中的conv2d、bn、dense、gap分别表示二维卷积
计算、批标准化层、全连接层和全局平均池化层。leakyrelu是激活函数。样本数据首先通过二维卷积操作提取其中的时空特征,在每一层卷积之后都跟着一个批标准化层,批标准化可以加速网络的收敛进程,经过bn层之后的数据将通过leakyrelu激活函数输出为零均值的分布,进一步加快收敛的速度。生成器结构中共堆叠了4层卷积层,随后数据将流入gap层,gap层会对每个特征图进行平均池化操作,形成一个特征点,最后通过全连接层将这些特征点组成的特征向量整合在一起并输出一个值。图3所示为判别器的结构,将影响熟料f-cao含量的相关变量和熟料f-cao数据按照时间尺度的关系进行拼接并作为判别器的输入,此输入包含两个部分:真实标签与有标签辅助变量拼接成的样本对和生成器生成的标签与无标签辅助变量拼接成的样本对。为了增强熟料f-cao数据在拼接数据中的影响,判别器借鉴了残差网络的结构,将拼接数据中第二个通道的熟料f-cao数据再次输入到卷积网络当中,使蕴含在f-cao数据中的特征被充分提取。每一层激活函数的后面都加了一个dropout层,增强了模型的稳定性和鲁棒性。判别器中一共使用了3层卷积,经过特征提取后的数据通过flatten层展平,最后进入全连接层将特征整合并输出真实样本与生成样本的分布距离,在训练过程中,判别器训练5次,生成器训练一次并更新参数。
[0047]
②
沃瑟斯坦生成对抗网络中的wasserstein距离为
[0048][0049]
其中,pr为真实数据分布,pg为生成数据分布,fw为含参数w的判别器网络,在wgan中,判别器做的是近似拟合wasserstein距离,距离l可以指示训练进程,其数值越小,表示真实分布与生成分布的wasserstein距离越小,生成对抗网络训练的越好。
[0050]
③
沃瑟斯坦生成对抗网络中判别器的损失函数
[0051][0052]
④
沃瑟斯坦生成对抗网络中生成器的损失函数
[0053][0054]
步骤5:搭建ssp-wgan模型,模型整体结构如图1所示,先对wgan训练15000万次,生成2000组数据与步骤1中处理后的数据混合为训练集,用于训练基于cnn和gru组成的的回归预测网络,随着数据量的扩充,回归预测模型的训练集也在扩大并不断更新预测模型的网络参数。
[0055]
在步骤5中,cnn gru网络的训练集数据由真实数据和生成对抗网络生成的数据两部分组成,将无标签样本按照真实数据中12个变量的时间序列为输入,生成的伪标签数据即水泥熟料fcao含量为输出的方式排列,并和步骤1中处理好的数据混合作为回归预测网络的训练集,经过生成数据与真实数据混和后训练的ssp-wgan预测模型具有更高的精度。
[0056]
步骤6:将ssp-wgan中训练好的cnn gru回归预测网络实现水泥熟料fcao含量的预测。
[0057]
以上所述的实施案例仅仅是对本发明提出的方法进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。