用于目标声音检测的方法及装备
1.i.相关申请的交叉引用
2.本技术要求来自于2020年4月1日提交的共同所有的美国非临时专利申请no.16/837,420的优先权权益,该申请通过援引被整体纳入。
3.ii.领域
4.本公开一般涉及在音频数据中检测目标声音。
5.iii.相关技术描述
6.音频上下文检测通常被用于使电子设备能够基于该电子设备所捕获的音频来标识上下文信息。例如,电子设备可以分析所接收到的声音以确定该声音是否指示预定的声音事件。作为另一示例,电子设备可以分析所接收到的声音以分类周围环境,诸如家庭环境或办公室环境。“常通”的音频上下文检测系统使电子设备能够连续扫描音频输入以检测该音频输入中的声音事件。然而,音频上下文检测系统的连续操作导致相对较大的功耗,这在移动设备中实现时会降低电池寿命。此外,系统复杂性和功耗随着音频上下文检测系统被配置成检测的声音事件的数目的增加而增加。
7.iv.概述
8.根据本公开的一个实现,用于执行声音检测的设备包括一个或多个处理器。该一个或多个处理器包括配置成存储音频数据的缓冲器。该一个或多个缓冲器还包括:包含第一级和第二级的目标声音检测器。第一级包括配置成处理该音频数据的二元目标声音分类器。第一级被配置成响应于第一级检测到目标声音而激活第二级。第二级被配置成响应于检测到该目标声音而从该缓冲器接收该音频数据。
9.根据本公开的另一实现,目标声音检测的方法包括将音频数据存储在缓冲器中。该方法还包括:在目标声音检测器的第一级中使用二元目标声音分类器来处理该缓冲器中的该音频数据;以及响应于第一级检测到目标声音而激活该目标声音检测器的第二级。该方法进一步包括:在第二级中使用多目标声音分类器来处理来自该缓冲器的该音频数据。
10.根据本公开的另一实现,计算机可读存储设备存储指令,这些指令在由一个或多个处理器执行时使该一个或多个处理器:将音频数据存储在缓冲器中;以及在目标声音检测器的第一级中使用二元目标声音分类器来处理该缓冲器中的该音频数据。这些指令在由该一个或多个处理器执行时还使得该一个或多个处理器:响应于第一级检测到目标声音而激活该目标声音检测器的第二级;以及在第二级中使用多目标声音分类器来处理来自该缓冲器的该音频数据。
11.根据本公开的另一实现,一种装备包括用于检测目标声音的装置。用于检测该目标声音的装置包括第一级和第二级。第一级包括用于生成音频数据的二元目标声音分类以及用于响应于将该音频数据分类为包括目标声音而激活第二级的装置。该装备还包括:用于缓冲音频数据和用于响应于将该音频数据分类为包括该目标声音而向第二级提供该音频数据的装置。
12.v.附图简述
13.图1是根据本公开的一些示例的包括包含多级目标声音检测器的设备的系统的特
定解说性实现的示图。
14.图2是根据本公开的一些示例的对图1的设备的特定实现的示图。
15.图3是根据本公开的一些示例的对包括多级音频场景检测器的图1的设备的另一特定实现的示图。
16.图4是根据本公开的一些示例的可被纳入多级音频场景检测器的组件的特定示例的示图。
17.图5是根据本公开的一些示例的可被纳入多级音频场景检测器的组件的另一特定示例的示图。
18.图6是根据本公开的一些示例的对包括场景检测器的图1的设备的另一特定实现的示图。
19.图7是根据本公开的一些示例的可被纳入图6的设备中的组件的特定示例的示图。
20.图8是根据本公开的一些示例的可被纳入图6的设备中的组件的另一特定示例的示图。
21.图9解说了根据本公开的一些示例的包括多级目标声音检测器的集成电路的示例。
22.图10是根据本公开的一些示例的包括多级目标声音检测器的交通工具的第一示例的示图。
23.图11是根据本公开的一些示例的包括多级目标声音检测器的交通工具的第二示例的示图。
24.图12是根据本公开的一些示例的包括多级目标声音检测器的头戴式设备(诸如虚拟现实或增强现实头戴式设备)的示图。
25.图13是根据本公开的一些示例的包括多级目标声音检测器的可穿戴电子设备的示图。
26.图14是根据本公开的一些示例的包括多级目标声音检测器的声控扬声器系统的示图。
27.图15是根据本公开的一些示例的可由图1的设备执行的目标声音检测方法的特定实现的示图。
28.图16是根据本公开的一些示例的可操作用于执行目标声音检测器的设备的特定解说性示例的框图。
29.vi.详细描述
30.公开了使用多级目标声音检测器以降低功耗的设备和方法。由于连续扫描音频输入以检测该音频输入中的音频事件的常通声音检测系统导致相对较大的功耗,所以当该常通声音检测系统在功率受限的环境中(诸如在移动设备中实现时),电池寿命会缩短。虽然可以通过减少声音检测系统被配置成检测的音频事件的数目来减少功耗,但是减少音频事件的数目降低了声音检测系统的利用。
31.如本文中所描述的,多级目标声音检测器支持针对常通操作使用相对较低的功率来检测相对较大量的感兴趣目标声音。该多级目标声音检测器包括第一级,该第一级支持音频数据在所有感兴趣的目标声音(作为一群)与非目标声音之间的二元分类。多级目标声音检测器包括第二级,该第二级用于执行进一步的分析并将音频数据分类为包括感兴趣目
标声音中的特定的一个或多个目标声音。第一级的二元分类由于低复杂度和小存储器占用而使得低功耗能够在常通操作状态中支持声音事件检测。第二级包括更强大的目标声音分类器,该目标声音分类器用于区分目标声音并减少或消除可能由第一级生成的假阳性(例如,对目标声音的不准确检测)。
32.在一些实现中,响应于在音频数据中检测到感兴趣目标声音中的一个或多个目标声音,第二级(例如,从睡眠状态)被激活以使得能够实现对音频数据的更强大的处理。在第二级完成对音频数据的处理之际,第二级可以返回到低功率状态。通过针对常通操作使用第一级的低复杂度二元分类并选择性地激活第二级的更强大的目标声音分类器,目标声音检测器能够以针对常通操作的降低的平均功耗来实现高性能的目标声音分类。
33.在一些实现中,多级环境场景检测器包括常通的第一级并且还包括更强大的第二级,该第一级检测是否已发生环境场景改变,该第二级在第一级检测到环境中的改变时被选择性地激活。在一些示例中,第一级包括二元分类器,该二元分类器被配置成在不标识任何特定环境场景的情况下检测音频数据是否表示环境场景改变。在其他示例中,分层场景改变检测器包括配置成在第一级中检测相对较少数目的宽泛类别(例如,室内、室外和在交通工具中)的分类器,并且第二级中更强大的分类器被配置成检测更大数目的更具体的环境场景(例如,在汽车中、在火车上、在家里、在办公室中等)。作为结果,可以用与多级目标声音检测类似的方式用针对常通操作的降低的平均功耗来提供高性能的环境场景检测。
34.在一些实现中,目标声音检测器基于其环境来调整操作。例如,当目标声音检测器在用户房间中时,目标声音检测器可以使用与诸如狗吠或门铃之类的家庭声音相关联的训练数据。当目标声音检测器在诸如汽车之类的交通工具中时,目标声音检测器可以是与诸如玻璃破碎或汽笛之类的交通工具声音相关联的训练数据。各种各样的技术可被用来确定环境,诸如使用音频场景检测器、相机、位置数据(例如,来自基于卫星的定位系统)、或各技术的组合。在一些示例中,目标声音检测器的第一级激活相机或其他组件以确定环境,并且该目标声音检测器的第二级被“调谐”以更准确地检测与检出环境相关联的目标声音。将相机或其它组件用于环境检测能够实现增强的目标声音检测,并且将该相机或其它组件保持在低功率状态中直到由目标声音检测器的第一级激活能够实现降低的功耗。
35.除非明确地受其上下文限制,否则术语“产生”被用于指示其任何普通含义(诸如计算、生成和/或提供)。除非明确地受其上下文限制,否则术语“提供”被用于指示其任何普通含义(诸如计算、生成和/或产生)。除非明确地受其上下文限制,否则术语“耦合”被用于指示直接或间接的电连接或物理连接。如果该连接是间接的,则在“耦合”的结构之间可存在其他块或组件。例如,扬声器可以经由居间介质(例如,空气)在声学上耦合至附近的墙壁,该居间介质使得波(例如,声音)能够从扬声器传播到墙壁(反之亦然)。
36.如由其特定上下文指示的,术语“配置”可以参考方法、装置、设备、系统或其任何组合来使用。当在本说明书和权利要求书中使用术语“包括”时,其不排除其他元件或操作。术语“基于”(如在“a基于b”中)被用于指示其任何普通含义,包括情形(i)“至少基于”(例如,“a至少基于b”)以及在特定上下文中恰适的情况下,(ii)“等于”(例如,“a等于b”)。在其中a基于b包括至少基于的情形(i)中,这可包括其中a耦合至b的配置。类似地,术语“响应于”被用于指示其任何普通含义,包括“至少响应于”。术语“至少一个”被用于指示其任何普通含义,包括“一个或多个”。术语“至少两个”被用于指示其任何普通含义,包括“两个或更
多个”。
37.除非由特定上下文另外指示,否则术语“装备”和“设备”被一般地且可互换地使用。除非另有指示,否则具有特定特征的装备的操作的任何公开也明确地旨在公开具有类似特征的方法(反之亦然),并且根据特定配置的装备的操作的任何公开也明确地旨在公开根据类似配置的方法(反之亦然)。除非由特定上下文另外指示,否则术语“方法”、“过程”、“规程”和“技术”被一般地且可互换地使用。术语“元素”和“模块”可被用于指示较大配置的一部分。术语“分组”可以对应于包括报头部分和有效载荷部分的数据单元。通过引用将文件的一部分的任何纳入也应当被理解为纳入该部分中所引用的术语或变量的定义(其中该定义出现在该文件的其他地方),以及所纳入部分中引用的任何数字。
38.如本文所使用的,术语“通信设备”是指可用于无线通信网络上的语音和/或数据通信的电子设备。通信设备的示例包括智能扬声器、音箱、蜂窝电话、个人数字助理(pda)、手持式设备、头戴式设备、无线调制解调器、膝上型计算机、个人计算机等。
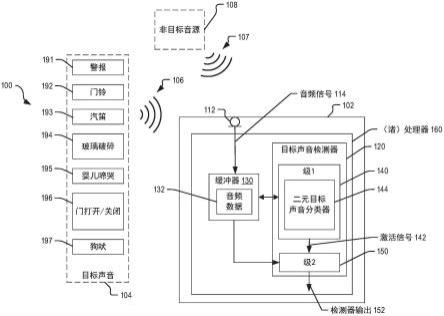
39.图1描绘了包括设备102的系统100,该设备102被配置成接收输入声音并且用多级目标声音检测器120处理该输入声音以在该输入声音中检测一个或多个目标声音的存在或不存在。设备102包括一个或多个话筒(表示为话筒112)、以及一个或多个处理器160。一个或多个处理器160包括目标声音检测器120和被配置成存储音频数据132的缓冲器130。目标声音检测器120包括第一级140和第二级150。在一些实现中,设备102可以包括具有集成辅助应用的无线扬声器和语音命令设备(例如,“智能扬声器”设备或家庭自动化系统)、便携式通信设备(例如,“智能电话”或头戴式设备)或交通工具系统,作为解说性的非限制性示例。
40.话筒112被配置成响应于所接收到的输入声音而生成音频信号114。例如,输入声音可以包括目标声音106、非目标声音107或这两者。音频信号114被提供给缓冲器130,并且被存储为音频数据132。在解说性示例中,缓冲器130对应于脉冲编码调制(pcm)缓冲器,并且音频数据132对应于pcm数据。缓冲器130处的音频数据132可被目标声音检测器120的第一级140和第二级150访问以进行处理,如在本文中进一步描述的。
41.目标声音检测器120被配置成处理音频数据132以确定音频信号114是否指示一个或多个感兴趣目标声音。例如,目标声音检测器120被配置成检测目标声音集合104中的每一者,该目标声音集合104包括可能在目标声音106中的警报191、门铃192、汽笛193、玻璃破碎194、婴儿啼哭195、门打开或关闭196、以及狗吠197。应当理解,被包括在目标声音集合104中的目标声音191-197是作为解说性示例提供的,在其他实现中,目标声音集合104可以包括更少、更多或不同的声音。目标声音检测器120被进一步配置成检测源自一个或多个其他声源(表示为非目标声源108)的非目标声音107不包括目标声音191-197中的任一者。
42.目标声音检测器120的第一级140包括配置成处理音频数据132的二元目标声音分类器144。在一些实现中,二元目标声音分类器144包括神经网络。在一些示例中,二元目标声音分类器144包括贝叶斯分类器或高斯混合模型(gmm)分类器中的至少一者,作为解说性的非限制性示例。在一些实现中,二元目标声音分类器144被训练以生成以下两个输出之一:指示被分类的音频数据132包含目标声音191-197中的一者或多者的第一输出(例如,1),或者指示该音频数据132不包含目标声音191-197中的任一者的第二输出(例如,0)。在解说性示例中,二元目标声音分类器144不被训练成在目标声音191-197中的每一者之间进
行区分,从而实现减少的处理负载和较小的存储器占用。
43.第一级140被配置成响应于检测到目标声音而激活第二级150。为了解说,二元目标声音分类器144被配置成:响应于检测到音频数据132中存在多个目标声音104中的任一者而生成用于激活第二级150的信号142(也被称为“激活信号”142),以及响应于检测到多个目标声音104中没有一个目标声音在音频数据132中而抑制生成信号142。在特定方面,信号142是包括第一值(例如,第一输出)和第二值(例如,第二输出)的二元信号,并且生成信号142对应于生成具有第一值(例如,逻辑1)的二元信号。在该方面,抑制生成信号142对应于生成具有第二值(例如,逻辑0)的二元信号。
44.在一些实现中,第二级150被配置成响应于信号142而被激活以处理音频数据132,诸如参照图2进一步描述的。在解说性示例中,控制寄存器的特定比特表示激活信号142的存在或不存在,并且第二级150内或耦合到第二级150的控制电路被配置成读取该特定比特。比特的“1”值指示信号142并且使第二级150激活,而比特的“0”值指示信号142的不存在并且第二级150可以在完成对音频数据132的当前部分的处理之际被禁用。在其他实现中,激活信号142取而代之被实现为总线或控制线上的数字或模拟信号、中断控制器处的中断标志、或者光学或机械信号,作为解说性非限制性示例。
45.第二级150被配置成:响应于检测到目标声音106而从缓冲器130接收音频数据132。在一示例中,第二级150被配置成处理音频数据132的包括目标声音106的一个或多个部分(例如,帧)。例如,缓冲器130可以将音频信号114的一系列帧缓存为音频数据132,以便在激活信号142被生成之际,第二级150可以处理经缓冲的一系列帧并且生成检测器输出152,该检测器输出152针对多个目标声音104中的每个目标声音指示音频数据132中存在或不存在该目标声音。
46.当被停用时,第二级150不处理音频数据132并且比激活时消耗更少的功率。例如,第二级150的停用可包括:对第二级150的输入缓冲器进行门控以防止音频数据132被输入到第二级150、对时钟信号进行门控以防止第二级150内的电路切换、或这两者,以减少动态功耗。作为另一示例,第二级150的停用可包括:在不丢失电路元件的状态的情况下减少对第二级150的供电以减少静态功耗、断开第二级150的至少一部分的电源、或其组合。
47.在一些实现中,目标声音检测器120、缓冲器130、第一级140、第二级150或其任何组合是使用专用电路系统或硬件来实现的。在一些实现中,目标声音检测器120、缓冲器130、第一级140、第二级150或其任何组合是经由执行固件或软件来实现的。为了解说,设备102可包括被配置成存储指令的存储器、以及被配置成执行这些指令以实现目标声音检测器120、缓冲器130、第一级140和第二级150中的一者或多者的一个或多个处理器160。
48.因为与由第二级150执行的处理操作相比,二元目标声音分类器144的处理操作不那么复杂,所以第一级140处对音频数据132的常通处理相较于第二级150处对音频数据132进行处理而言使用显著较少的功率。作为结果,节省了处理资源,并且降低了总体功耗。
49.在一些实现中,第一级140还被配置成激活设备102的一个或多个其他组件。在解说性示例中,第一级140激活被用于检测设备102的环境(例如,在家里、室外、在汽车中等)的相机,并且第二级150可被操作以聚焦于与检出环境相关联的目标声音,诸如参照图6进一步描述的。
50.图2描绘了设备102的示例200,其中二元目标声音分类器144包括神经网络212,并
且二元目标声音分类器144和缓冲器130被包括在低功率域203(诸如一个或多个处理器160的常通低功率域)中。第二级150在另一功率域205(诸如按需功率域)中。在一些实现中,目标声音检测器120的第一级140(例如,二元目标声音分类器144)和缓冲器130被配置成在常通模式中操作,并且目标声音检测器120的第二级150被配置成在按需模式中操作。
51.功率域205包括目标声音检测器102的第二级150、声音上下文应用240和激活电路系统230。激活电路系统230响应于激活信号142(例如,唤醒中断信号)而选择性地激活功率域205的一个或多个组件,诸如第二级150。为了解说,在一些实现中,激活电路系统230被配置成响应于接收到信号142而将第二级150从低功率状态232转换到激活状态234。
52.例如,激活电路系统230可包括或被耦合到电源管理电路系统、时钟电路系统、头触开关或脚踏开关电路系统、缓冲器控制电路系统、或其任何组合。激活电路系统230可被配置成诸如通过选择性地施加或升高第二级150、功率域205或这两者的电源电压来发起第二级150的通电。作为另一示例,激活电路系统230可被配置成选择性地对去往第二级150的时钟信号进行门控或去门控,诸如以在无需移除电源的情况下防止电路操作。
53.第二级150包括配置成生成检测器输出152的多目标声音分类器210,该检测器输出152针对该多目标声音104中的每个目标声音指示该音频数据132中存在或不存在该目标声音。多个目标声音对应于声音事件的多个类别290,声音事件的该多个类别290包括以下至少两者:警报291、门铃292、汽笛293、玻璃破碎294、婴儿啼哭295、门打开或关闭296、或狗吠297。应当理解,声音事件类别291-297是作为解说性示例来提供的。在其他示例中,多个类别290包括更少、更多或不同的声音事件。例如,在其中设备102在交通工具(例如,汽车)中被实现的实现中,多个类别290包括在交通工具中更常遭遇的声音事件,诸如交通工具门打开或关闭、道路噪声、窗户打开或关闭、收音机、制动、手制动器接合或脱离、挡风玻璃雨刮器、转向信号、或引擎加速转动中的一者或多者,作为解说性的非限制性示例。尽管描绘了声音事件类别(例如,多个类别290)的单个集合,但在其他实现中,多目标声音分类器210被配置成基于设备102的环境来从声音事件类别的多个集合(例如,当设备102在家里时的一个目标声音集合,以及当设备102在交通工具中时的另一目标声音集合)之间进行选择,如参照图6进一步描述的。
54.在一些实现中,多目标声音分类器210执行对音频数据132的“快于实时”处理。在解说性的非限制性示例中,缓冲器130的大小被确定为以循环缓冲器配置存储大致上两秒的音频数据,在该循环缓冲器配置中缓冲器130中最旧的音频数据由最新近接收到的音频数据替代。第一级140可被配置成以以低功耗并实时方式周期性地处理音频数据132的被顺序接收到的20毫秒(ms)分段(例如,帧)(例如,二元目标声音分类器144每20ms处理一个20ms分段)。然而,当第二级150被激活时,多目标声音分类器210以更快的速率和更高的功耗来处理经缓冲的音频数据132,以更迅速地处理经缓冲的音频数据132以生成检测器输出152。
55.在一些实现中,检测器输出152包括多个值,诸如针对每个目标声音的指示检测到该目标声音(或检测到该目标声音的可能性)的一比特或多比特值。在一个解说性的示例中,检测器输出152包括七比特值,其中第一比特对应于检测或未检测到被分类为警报291的声音、第二比特对应于检测或未检测到被分类为门铃292的声音、第三比特对应于检测或未检测到被分类为汽笛293的声音、第四比特对应于检测或未检测到被分类为玻璃破碎294
的声音、第五比特对应于检测或未检测到被分类为婴儿啼哭295的声音、第六比特对应于检测或未检测到被分类为门打开或关闭296的声音、并且第七比特对应于检测或未检测到被分类为狗吠297的声音。
56.由第二级150生成的检测器输出152被提供给声音上下文应用240。声音上下文应用240可被配置成基于检测到一个或多个目标声音来执行一个或多个操作。为了解说,在其中设备102在家庭自动化系统中的实现中,声音上下文应用240可以生成用户接口信号242来向用户提示检出的一个或多个声音事件。例如,用户接口信号242可以使输出设备250(例如,话音接口设备的显示屏或扬声器)向用户提示在建筑物的后门处已检出狗吠和玻璃破碎。在另一示例中,当用户不在建筑物内时,用户接口信号242可使输出设备250(例如,耦合到无线网络(诸如蜂窝网络或无线局域网)的发射机)向用户的电话或智能手表传送该提示。
57.在其中设备102在交通工具(例如,汽车)中的另一实现中,声音上下文应用240可生成用户接口信号242以在该交通工具在运动中的同时经由输出设备250(例如,显示屏或语音接口)来警告该交通工具的操作者已经经由外部话筒检测到汽笛。如果交通工具被关闭并且操作者已经离开该交通工具,则声音上下文应用240可以生成用户接口信号242以经由输出设备250(例如,去往车主的电话或智能手表的无线传输)警告该交通工具的车主已经经由该交通工具的内部话筒检测到啼哭的婴儿。
58.在其中设备102集成在诸如头戴式耳机或头戴式设备的音频回放设备中或耦合到该音频回放设备的另一实现中,声音上下文应用240可生成用户接口信号242以经由输出设备250(例如,显示屏或扬声器)来警告回放设备的用户已经检测到汽笛,或可传递该汽笛以供在该头戴式耳机或头戴式设备的扬声器处回放,作为解说性示例。
59.尽管激活电路系统230在功率域205中被示为不同于第二级150,但在其他实现中,激活电路系统230可被包括在第二级150中。尽管在一些实现中,输出设备250被实现为设备102的用户接口组件(诸如显示屏或扬声器),但在其他实现中,输出设备250可以是远离并耦合到设备102的用户接口设备。尽管多目标声音分类器210被配置成检测和与七个类别291-297相对应的声音事件并且在其之间进行区分,但在其他实现中,多目标声音分类器210可被配置成检测作为七个类别291-297中的任一者或多者的替代或补充任何其他声音事件,并且多目标声音分类器210可被配置成根据任何其他数目的类别来分类声音事件。
60.图3描绘了其中设备102包括缓冲器130和目标声音检测器120并且还包括音频场景检测器302的实现300。音频场景检测器302包括音频场景改变检测器304和音频场景分类器308。音频场景改变检测器304被配置成处理音频数据132并且响应于检测到音频场景改变而生成场景改变信号306。在一些实现中,音频场景改变检测器304在音频场景检测器302的第一级(例如,低功率、常通处理级)中实现,音频场景分类器308在音频场景检测器302的第二级(例如,更强大、高性能的处理级)中实现,该第二级由场景改变信号306以类似于图2的由激活信号142激活多目标声音分类器210的方式来激活。与目标声音检测不同,音频环境始终存在,并且通过检测音频环境中的改变而不引起与标识准确音频环境相关联的计算损失,在第一级中增强了音频场景检测器302的操作效率。
61.在一些实现中,音频场景改变检测器304被配置成:基于检测噪声统计310或非平稳声音统计312中的至少一者的改变来检测音频场景中的改变。作为示例,音频场景改变检
测器304处理音频数据132以确定在相对较大的时间窗口(例如,3-5秒)上被时间平均的噪声统计310(例如,被标识为包含噪声的音频帧的平均频谱能量分布)和非平稳声音统计312(例如,被标识为包含非平稳声音的音频帧的平均频谱能量分布)。基于确定噪声统计310、非平稳声音统计312、或这两者中的改变来检测音频场景之间的改变。例如,办公室环境的噪声和声音特性充分不同于移动的汽车内的噪声和声音特性,以使得从办公室环境到交通工具环境的改变可被检测到,并且在一些实现中,改变可被检测到而无需将噪声和声音特性标识为与办公室环境或交通工具环境中的任一者相对应。响应于检测到音频场景改变,音频场景改变检测器生成场景改变信号306并将其发送到音频场景分类器308。
62.音频场景分类器308被配置成响应于检测到音频场景改变而从缓冲器130接收该音频数据132。在一些实现中,音频场景分类器308是相较于音频场景改变检测器304而言更强大、更高复杂度的处理组件,并且被配置成将音频数据132分类为与多个音频场景类别330中的特定一个音频场景类别相对应。在一个示例中,多个音频场景类别330包括在家里332、在办公室中334、在餐厅中336、在汽车中338、在火车上340、在街道上342、室内344和室外346。
63.场景检测器输出352由音频场景检测器302生成并表示对检出音频场景的指示,该指示可被提供给图2的声音上下文应用240。例如,声音上下文应用240可以基于检出音频场景来调整设备102的操作,诸如改变显示屏处的图形用户界面(gui)以表示与环境相关联的顶层菜单项。为了解说,当检出环境是在汽车中时可以呈现导航和通信项(例如,免提拨号),当检出环境是在室外时可以呈现相机和音频记录项,并且当检出环境是在办公室中时可以呈现笔记和联系人项,作为解说性的非限制性示例。
64.尽管多个音频场景类别330被描述为包括八个类别332-346,但在其他实现中,多个音频场景类别330可包括以下至少两者:在家里332、在办公室中334、在餐厅中336、在汽车中338、在火车上340、在街道上342、室内344或室外346。在其它实现中,类别330中的一者或多者可被省略,一个或多个其它类别可被用作为类别332-346的替代、补充或其任何组合。
65.图4描绘了音频场景改变检测器304的实现400,其中音频场景改变检测器304包括使用与场景之间的转换相对应的音频数据来训练的场景转换分类器414。例如,场景转换分类器414可以对针对办公室到街道转换、汽车到室外转换、餐厅到街道转换等的所捕获音频数据进行训练。在一些实现中,场景转换分类器414使用相较于参照图3所描述的音频场景改变检测器304的实现而言更小的模型来提供更稳健的改变检测。
66.图5描绘了实现500,其中音频场景检测器302对应于分层检测器以使得与音频场景分类器308相比,音频场景改变检测器304使用减少的音频场景集合来分类音频数据132。为了解说,音频场景改变检测器304包括分层模型改变检测器514,该分层模型改变检测器514被配置成基于检测减少的类别集合530的音频场景类别之间的改变来检测音频场景改变。例如,减少的类别集合530包括“交通工具中”类别502、室内类别344和室外类别346。在一些实现中,减少的类别集合530中的一者或多者(或全部)包括或跨越音频场景分类器308所使用的多个类别。为了解说,“在交通工具中”类别502被用于将音频场景分类器308区分为“在汽车中”或“在火车上”的音频场景进行分类。在一些实现中,减少的类别集合530中的一者或多者(或全部)形成音频场景分类器308所使用的类别330子集,诸如室内类别344和
室外类别346。在一些示例中,减少的类别集合530被配置成包括最可能遭遇的音频场景中的两者或三者以提高检测音频场景改变的概率。
67.与音频场景分类器308的类别330相比,减少的类别集合530包括减少数目的类别。为了解说,对减少的类别集合530的音频场景类别的第一计数(三个)小于对音频场景类别330的第二计数(八个)。尽管减少的类别集合530被描述为包括三个类别,但在其他实现中,减少的类别集合530可以包括比音频场景分类器308所支持的类别的数目更少的任何数目的类别(例如,至少两个类别,诸如两个、三个、四个或更多个类别)。
68.因为分层模型改变检测器514从与音频场景分类器308相比较小的类别集合之中执行检测,所以与更强大的音频场景分类器308相比,音频场景改变检测器304可以用降低的复杂性和功耗来检测场景改变。环境之间分层模型改变检测器514未检出的转换可能不太可能发生,诸如在没有到交通工具或室外环境的中间转换的情况下直接从“在家里”转换到“在餐厅中”(例如,两者都在“室内”类别344中)。
69.尽管图3-5对应于其中音频场景检测器304和目标声音检测器120两者都被包括在设备102中的各种实现,但在其他实现中,音频场景检测器302可以在不包括目标声音检测器的设备中实现。在解说性示例中,设备102包括缓冲器130和音频场景检测器302,并且省略目标声音检测器120的第一级140、第二级150、或两者。
70.图6描绘了特定示例600,其中设备102包括场景检测器606,场景检测器606被配置成基于相机、位置检测系统或音频场景检测器中的至少一者来检测环境。
71.设备102包括一个或多个传感器602,该一个或多个传感器602生成场景检测器606在确定环境608时可用的数据。一个或多个传感器602包括一个或多个相机以及位置检测系统的一个或多个传感器,分别解说为相机620和全球定位系统(gps)接收机624。相机620可以包括任何类型的图像捕获设备,并且可以支持或包括静止图像或视频捕获,可见、红外或紫外光谱,深度感测(例如,结构光、飞行时间),任何其他图像捕获技术、或其任何组合。
72.第一级140被配置成响应于第一级140检测到目标声音而从低功率状态激活传感器602中的一者或多者。例如,信号142可被提供给相机620和gps接收机624。相机620和gps接收机624响应于信号142而从低功率状态(例如,当未被设备102的另一应用使用时)转换到活跃状态。
73.场景检测器606包括音频场景检测器302,并且被配置成基于相机620、gps接收机624或音频场景检测器302中的至少一者来检测环境608。作为第一示例,场景检测器606被配置成至少部分地基于来自相机624的输入信号622(例如,图像数据)来生成对设备102的环境608的第一估计。为了解说,场景检测器606可被配置成处理输入数据622,以基于视觉特征来生成环境608的第一分类,诸如在家里、在办公室中、在餐厅中、在汽车中、在火车上、在街道上、室外或室内。
74.作为第二示例,场景检测器606被配置成至少部分地基于来自gps接收机的位置信息626来生成对环境608的第二估计。为了解说,场景检测器606可以使用位置信息626来搜索地图数据,以确定该位置是对应于用户的家、用户的办公室、餐厅、火车路线、街道、室外位置还是室内位置。场景检测器606可被配置成基于位置数据626来确定设备102的行进速度,以确定设备102是在汽车还是飞机中行进。
75.在一些实现中,场景检测器606被配置成基于对音频场景检测器302的第一估计、
第二估计、场景检测器输出352以及与第一估计、第二估计和场景检测器输出352相关联的相应置信水平来确定环境608。对环境608的指示被提供给目标声音检测器120,并且多目标声音分类器210的操作至少部分地基于场景检测器606对环境608的分类。
76.尽管图6描绘了包括相机620、gps接收机624和音频场景检测器302的设备102,但在其他实现中,相机620、gps接收机624或音频场景检测器302中的一者或多者被省略,一个或多个其他传感器被添加、或其任何组合。例如,音频场景检测器302可被省略或替代为一个或多个其他音频场景检测器。在其他示例中,场景检测器606仅基于来自相机的图像数据622、仅基于来自gps传感器624的位置数据62、或仅基于来自音频场景检测器的场景检测来确定环境608。
77.尽管一个或多个传感器602、音频场景检测器302和场景检测器606响应于信号142而被激活,但在其他实现中,场景检测器606、音频场景检测器302、一个或多个传感器602或其任何组合可以独立于信号142而被激活或禁用。作为非限制性示例,在非功率受限的环境中(诸如在交通工具或家用电器中),即使没有检测到目标声音活动,一个或多个传感器602、音频场景检测器302和场景检测器606也可以保持活跃状态。
78.图7描绘了示例700,其中多目标声音分类器210被调整以聚焦于声音事件的多个类别中与环境608相对应的一个或多个特定类别。在示例700中,环境608被检测为“在汽车中”,并且多目标声音分类器210被调整以更多地聚焦于将音频数据132中的目标声音标识为多个类别290中在汽车中更常遭遇的类别之一:警笛293、玻璃破碎294、婴儿啼哭295、或门打开或关闭296,并且被调整以更少地聚焦于将目标声音标识为在汽车中不那么常遭遇的类别之一:汽笛291、门铃292、或狗吠297。作为结果,可以比不使用环境信息来聚焦目标声音检测的实现更准确地执行目标声音检测。
79.图8描绘了示例800,其中多目标声音分类器210被配置成从声音事件类别的多个集合中选择与环境608相对应的特定声音事件类别集合。第一训练数据集合802包括与第一环境(例如,在家里)相关联的第一声音事件类别集合812。第二训练数据集合804包括与第二环境(例如,在汽车中)相关联的第二声音事件类别集合814,并且一个或多个附加训练数据集合包括第n训练数据集合808,该第n训练数据集合808包括与第n环境(例如,在办公室中)相关联的第n声音事件类别集合818,其中n是大于一的整数。在非限制性示例中,训练数据集合802-808中的每一者对应于类别330之一(例如,n=8)。在一些实现中,训练数据集合802-808中的一者或多者对应于当环境未被确定时要使用的默认训练数据集合。作为示例,图2的多个类别290可被用作默认训练数据集合。
80.在解说性实现中,第一声音事件类别集合812对应于“在家里”,并且第二声音事件类别集合814对应于“在汽车中”。第一声音事件类别集合812包括在家中较常遭遇的声音事件,诸如火灾警报、婴儿啼哭、狗吠、门铃、门打开或关闭以及玻璃破碎中的一者或多者,作为解说性的非限制性示例。第二事件类别集合814包括在汽车中更常遭遇的声音事件,诸如车门打开或关闭、道路噪声、窗户打开或关闭、收音机、制动、手制动接合或脱离、挡风玻璃雨刮器、转向信号、或引擎加速转动中的一者或多者,作为解说性的非限制性示例。响应于环境608被检测为“在家里”,多目标声音分类器210选择第一声音事件类别集合812,以基于该特定集合(即,第一声音事件类别集合812)的声音事件类别来分类音频数据132。响应于环境608被检测为“在汽车中”,多目标声音分类器210选择第二声音事件类别集合814,以基
于该特定集合(即,第二声音事件类别集合814)的声音事件类别来分类音频数据132。
81.作为结果,通过将不同的声音事件集合用于每个环境,可以检测到更大总数的目标声音,而不会增加对针对任何特定环境执行目标声音分类的总体处理和存储器使用。此外,通过使用第一级140来激活传感器602、场景检测器606,或这两者,与传感器602和场景检测器606的常通操作相比,功耗被降低。
82.尽管示例800将多目标声音分类器210描述为基于环境608来选择声音事件类别集合812-818之一,但是在一些实现中,训练数据集合802-808中的每一者还包括供二元目标声音分类器144检测存在或不存在与特定环境相关联的(作为一群的)目标声音的训练数据。在一示例中,目标声音检测器120被配置成:从训练数据集合802-808之中选择与设备102的所检测环境608相对应的特定训练数据集合,并且基于该特定训练数据集合来处理音频数据132。
83.图9将设备102的实现900描绘为集成电路902,该集成电路902包括一个或多个处理器160。集成电路902还包括传感器信号输入910(诸如一个或多个第一总线接口)以使得能够从话筒112接收到音频信号114。例如,传感器信号输入端910从话筒112接收音频信号114,并且将音频信号114提供给缓冲器130。集成电路902还包括数据输出912(诸如第二总线接口)以使得能够(例如,向显示设备、存储器或发射机,作为解说性的非限制性示例)发送检测器输出152。例如,目标声音检测器120将检测器输出152提供给数据输出912,并且数据输出912发送检测器输出152。集成电路902使得能够将多级目标声音检测实现为包括一个或多个话筒的系统(诸如图10或11所描绘的交通工具、图12所描绘的虚拟现实或增强现实头戴式设备、图13所描绘的可穿戴电子设备、图14所描绘的语音控制扬声器系统或图16所描述的无线通信设备)中的组件。
84.图10描绘了实现1000,其中设备102对应于交通工具1002(被解说为汽车)或被集成在其内。在一些实现中,多级目标声音检测可基于从内部话筒接收到的音频信号(诸如针对汽车中啼哭的婴儿)、基于从外部话筒(例如,话筒112)接收到的音频信号(诸如针对汽笛)、或这两者来执行。图1的检测器输出152可被提供给交通工具1002的显示屏、提供给用户的移动设备、或这两者。例如,输出设备250包括显示屏,该显示屏显示指示目标声音(例如,汽笛)在交通工具1002外部被检测到的通知。作为另一示例,输出设备250包括发射机,该发射机向移动设备传送指示目标声音(例如,婴儿的啼哭)在交通工具1002中被检测到的通知。
85.图11描绘了另一实现1100,其中设备102对应于交通工具1102(被解说为有人驾驶或无人驾驶空中设备(例如,包裹递送无人机))或被集成在其内。多级目标声音检测可以基于从交通工具1102的一个或多个话筒(例如,话筒112)接收到的音频信号(诸如针对门的打开或关闭)来执行。例如,输出设备250包括发射机,该发射机向控制设备传送指示交通工具1102检测到目标声音(例如,门的打开或关闭)的通知。
86.图12描绘了实现1202,其中设备102是与虚拟现实、增强现实或混合现实头戴式设备1202相对应的便携式电子设备。一个或多个处理器160和话筒112被集成到头戴式设备1202中。多级目标声音检测可以基于从头戴式设备1202的话筒112接收到的音频信号来执行。可视接口设备(诸如输出设备250)被放置在用户眼睛的前面,以使得在头戴式设备1202被佩戴时能够向用户显示增强现实或虚拟现实图像或场景。在特定示例中,输出设备250被
配置成显示指示在头戴式设备1202外部检测到目标声音(例如,火警或门铃)的通知。
87.图13描绘了实现1300,其中设备102是与可穿戴电子设备1302(被解说为“智能手表”)相对应的便携式电子设备。一个或多个处理器160和话筒112被集成到可穿戴电子设备1302中。多级目标声音检测可以基于从可穿戴电子设备1302的话筒112接收到的音频信号来执行。。可穿戴电子设备1302包括显示屏(诸如输出设备250),该显示屏被配置成显示指示由可穿戴电子设备1302检测到目标声音的通知。在一特定示例中,输出设备250包括触觉设备,触觉设备响应于检测到目标声音而提供触觉通知(例如,振动)。触觉通知可以使用户查看可穿戴电子设备1302,以看见指示检测到目标声音的所显示通知。可穿戴电子设备1302可以由此向有听力障碍的用户或戴着头戴式设备的用户提示检测到该目标声音。
88.图14是无线扬声器和语音激活式设备1400的解说性示例。无线扬声器和语音激活式设备1400可具有无线网络连通性,并且被配置成执行辅助操作。一个或多个处理器160、话筒620、和一个或多个相机(诸如相机620)被包括在无线扬声器和语音激活式设备1400中。相机620被配置成响应于集成助理应用1402(诸如响应于发起视频会议的用户指令)而被激活。相机620被进一步配置成响应于目标声音检测器120中的二元目标声音分类器144检测到来自话筒112的音频数据中存在多个目标声音中的任一者而被激活,诸如响应于检测到目标声音而充当监控相机。
89.无线扬声器和语音激活式设备1400还包括扬声器1404。在操作期间,响应于接收到口头命令,无线扬声器和语音激活式设备1400可以(诸如经由执行集成辅助应用1402来)执行辅助操作。辅助操作可包括调整温度、播放音乐、开灯、发起视频会议等。例如,辅助操作是响应于在关键词(例如,“你好助手”)之后接收到命令而执行的。多级目标声音检测可以基于从无线扬声器和语音激活式设备1400的话筒142接收到的音频信号来执行。在一些实现中,集成辅助应用1402响应于目标声音检测器120中的二元目标声音分类器144检测到来自话筒112的音频数据中存在多个目标声音中的任一者而被激活。对所标识的目标声音的指示(例如,检测器输出152)被提供给集成辅助应用1402,并且集成辅助应用1402使无线扬声器和语音激活式设备1400提供通知(诸如经由扬声器1404播放可听话音通知或向移动设备传送通知),该通知指示无线扬声器和语音激活式设备1400检测到目标声音(例如,门的打开或关闭)。
90.参照图15,示出了多级目标声音检测的方法1500的特定实现。在一个特定的方面,方法1500的一个或多个操作由以下至少一者执行:图1的系统100的二元目标声音分类器144、目标声音检测器120、缓冲器130、处理器160、设备102,图2的系统200的激活信号单元204、多目标声音分类器210、激活电路系统230、声音上下文应用240、输出设备250,图3的音频场景检测器302、音频场景改变检测器304、音频场景分类器308,图4的场景转换分类器414,图5的分层模型改变检测器514,图6的场景检测器606,或其组合。
91.该方法1500包括将音频数据存储在缓冲器中(在1502)。例如,图1的缓冲器130存储音频数据132,如参照图1所描述的。在特定方面,音频数据132对应于从图1的话筒112所接收到的音频信号114。
92.方法1500还包括在目标声音检测器的第一级中使用二元目标声音分类器来处理该缓冲器中的该音频数据(在1504)。例如,图1的二元目标声音分类器144处理存储在缓冲器130中的音频数据132,如参照图1所描述的。二元目标声音分类器144在图1的目标声音检
测器150的第一级140中。
93.该方法1500进一步包括响应于第一级检测到目标声音而激活该目标声音检测器的第二级(在1506)。例如,图1的第一级140响应于第一级140检测到目标声音106而激活目标声音检测器120的第二级150,如参照图1所描述的。在一些实现中,该二元目标声音分类器和该缓冲器在常通模式中操作,并且激活第二级包括:从第一级向第二级发送信号,以及响应于在第二级处接收到该信号而将第二级从低功率状态转换到激活状态,诸如参照图2所描述的。
94.该方法1500包括在第二级中使用该多目标声音分类器来处理来自该缓冲器的该音频数据(在1508)。例如,图2的多目标声音分类器210在第二级150中处理来自缓冲器150的音频数据132,如参照图2所描述的。多目标声音分类器可以基于与声音事件的多个类别(诸如类别290、或者声音事件类别812-818的集合中的一个或多个集合,作为解说性的非限制性示例)相对应的多个目标声音来处理音频数据。
95.方法1500还可以包括生成检测器输出(诸如检测器输出152),该检测器输出针对多个目标声音中的每个目标声音指示音频数据中存在或不存在该目标声音。
96.在一些实现中,方法1500还包括:在音频场景改变检测器(诸如图3的音频场景检测器302)处处理音频数据。在此类实现中,响应于检测到音频场景改变,方法1500包括激活音频场景分类器(诸如音频场景分类器308),以及使用音频场景分类器来处理来自缓冲器的音频数据。该方法1500可包括在音频场景分类器处根据多个音频场景类别(诸如类别330)来分类音频数据。在解说性示例中,多个音频场景类别包括以下至少两者:在家里、在办公室中、在餐厅中、在汽车中、在火车上、在街道上、室内或室外。
97.检测音频场景改变可以基于检测噪声统计或非平稳声音统计中的至少一者中的改变,诸如参照图3的音频场景改变检测器304所描述的。附加地或替换地,可以使用分类器(诸如图4的场景转换分类器414)来执行对音频场景改变的检测,该分类器使用与场景之间的转换相对应的音频数据来训练。替换地或附加地,方法1500可以包括:基于检测第一音频场景类别集合(例如,图5的减少的类别集合530)中的音频场景类别之间的改变来检测音频场景改变,并且根据第二音频场景类别集合(例如,图3的类别330)来分类该音频数据,其中对第一音频场景类别集合中的音频场景类别的第一计数(例如,3)小于对第二音频场景类别集合中的音频场景类别的第二计数(例如,8)。
98.因为与第二级所执行的处理操作相比,二元目标声音分类器的处理操作不那么复杂,所以与在第二级处处理音频数据相比,在二元目标声音分类器处所处理的音频数据消耗更少的功率。通过响应于第一级检测到目标声音而选择性地激活第二级,方法1500能够节省处理资源并且降低总功耗。
99.图15的方法1500可由现场可编程门阵列(fpga)设备、专用集成电路(asic)、处理单元(诸如中央处理单元(cpu))、dsp、控制器、另一硬件设备、固件设备、或其任何组合来实现。作为示例,图15的方法1500可以由执行指令的处理器来执行,诸如参照图16所描述的。
100.参照图16,描绘了设备的特定解说性实现的框图并将其一般性地指定为1600。在各种实现中,设备1600可具有比图16中所解说的更多或更少的组件。在解说性实现中,设备1600可对应于设备102。在解说性实现中,设备1600可执行参照图1-15所描述的一个或多个操作。
101.在特定实现中,设备1600包括处理器1606(例如,中央处理单元(cpu))。设备1600可包括一个或多个附加处理器1610(例如,一个或多个dsp)。处理器1610可包括话音和音乐编解码器(codec)1608、目标声音检测器120、声音上下文应用240、激活电路系统230、音频场景检测器302、或其组合。话音和音乐编解码器1608可包括语音编码器(“声码器”)编码器1636、声码器解码器1638或两者。
102.设备1600可包括存储器1686和codec 1634。存储器1686可包括指令1656,这些指令1656可由一个或多个附加处理器1610(或处理器1606)执行以实现参照目标声音检测器120、声音上下文应用240、激活电路系统230、音频场景检测器302、或其组合所描述的功能性。存储器1686可包括缓冲器160。设备1600可包括经由收发机1650耦合到天线1652的无线控制器1640。
103.设备1600可包括耦合到显示器控制器1626的显示器1628。扬声器1692和话筒112可耦合至codec 1634。codec 1634可包括数模转换器1602和模数转换器1604。在特定实现中,codec 1634可从话筒112接收模拟信号,使用模数转换器1604来将这些模拟信号转换为数字信号,以及将这些数字信号提供给话音和音乐编解码器1608。话音和音乐编解码器1608可以处理数字信号,并且数字信号可进一步由目标声音检测器120和音频场景检测器302中的一者或多者来处理。在特定实现中,语音和音乐编解码器1608可以向codec 1634提供数字信号。codec 1634可使用数模转换器1602来将数字信号转换为模拟信号,并且可以将模拟信号提供给扬声器1692。
104.在特定实现中,设备1600可被包括在系统级封装或片上系统设备1622中。在特定实现中,存储器1686、处理器1606、处理器1610、显示器控制器1626、codec 1634和无线控制器1640被包括在系统级封装或片上系统设备1622中。在一特定实现中,输入设备1630和电源1644被耦合到片上系统设备1622。此外,在特定实现中,如图16中所解说的,显示器1628、输入设备1630、扬声器1692、话筒112、天线1652、和电源1644在片上系统设备1622的外部。在特定实现中,显示器1628、输入设备1630、扬声器1692、话筒112、天线1652和电源1644中的每一者可耦合至片上系统设备1622的组件(诸如接口或控制器)。
105.设备1600可包括智能扬声器、音箱、移动通信设备、智能电话、蜂窝电话、膝上型计算机、计算机、平板设备、个人数字助理、显示设备、电视、游戏控制台、音乐播放器、收音机、数字视频播放器、数字视频光盘(dvd)播放器、调谐器、相机、导航设备、交通工具、头戴式设备、增强现实头戴式设备、虚拟现实头戴式设备、航空交通工具、或其任何组合。
106.结合所描述的实现,一种用于处理表示输入声音的音频信号的装备包括用于检测目标声音的装置。用于检测该目标声音的装置包括第一级和第二级。第一级包括用于生成音频数据的二元目标声音分类以及用于响应于将该音频数据分类为包括目标声音而激活第二级的装置。例如,用于检测目标声音的装置可以对应于目标声音检测器120、一个或多个处理器160、一个或多个处理器1610、配置成检测目标声音的一个或多个其他电路或组件、或其任何组合。用于生成二元目标声音分类和用于激活第二级的装置可以对应于二元目标声音分类器144、配置成生成二元目标声音分类和激活第二级的一个或多个其他电路或组件、或其任何组合。
107.该装备还包括用于缓冲音频数据和用于响应于将音频数据分类为包括目标声音而向第二级提供音频数据的装置。例如,用于缓冲音频数据和用于将该音频数据提供给第
二级的装置可以对应于缓冲器160、一个或多个处理器160、一个或多个处理器1610、配置成缓冲音频数据并响应于将音频数据分类为包括目标声音而将该音频数据提供给第二级的一个或多个其他电路或组件、或其任何组合。
108.在一些实现中,该装备进一步包括用于检测音频场景的装置,该用于检测音频场景的装置包括用于检测音频数据中的音频场景改变的装置和用于响应于检测到音频场景改变而将音频数据分类为特定音频场景的装置。例如,用于检测音频场景的装置可以对应于音频场景检测器302、一个或多个处理器160、一个或多个处理器1610、配置成检测音频场景的一个或多个其他电路或组件、或其任何组合。用于检测音频数据中的音频场景改变的装置可以对应于音频场景改变检测器304、场景转换分类器414、分层模型改变检测器514、配置成检测音频数据中的音频场景改变的一个或多个其他电路或组件、或其任何组合。用于响应于检测到音频场景改变而将音频数据分类为特定音频场景的装置可以对应于音频场景分类器308、被配置成响应于检测到音频场景改变而将音频数据分类为特定音频场景的一个或多个其他电路或组件、或其任何组合。
109.在一些实现中,一种非瞬态计算机可读介质(例如,存储器1686)包括指令(例如,指令1656),这些指令在由一个或多个处理器(例如,一个或多个处理器1610或处理器1606)执行时使该一个或多个处理器执行操作以将音频数据存储在缓冲器(例如,缓冲器130)中,以及在目标声音检测器的第一级(例如,目标声音检测器120的第一级140)中使用二元目标声音分类器(例如,二元目标声音分类器144)来处理缓冲器中的音频数据。这些指令在由一个或多个处理器执行时还使得该一个或多个处理器响应于第一级检测到目标声音而激活目标声音检测器的第二级(例如,第二级150),以及在第二级中使用多目标声音分类器(例如,多目标声音分类器210)来处理来自缓冲器的音频数据。
110.技术人员将进一步领会,结合本文所公开的实现来描述的各种解说性逻辑框、配置、模块、电路、和算法步骤可实现为电子硬件、由处理器执行的计算机软件、或这两者的组合。各种解说性组件、框、配置、模块、电路、和步骤已经在上文以其功能性的形式作了一般化描述。此类功能性是被实现为硬件还是处理器可执行指令取决于具体应用和加诸于整体系统的设计约束。技术人员可针对每种特定应用以不同方式来实现所描述的功能性,此类实现决策不应被解读为致使脱离本公开的范围。
111.结合本文所公开的各实现所描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中实施。软件模块可驻留在随机存取存储器(ram)、闪存、只读存储器(rom)、可编程只读存储器(prom)、可擦式可编程只读存储器(eprom)、电可擦式可编程只读存储器(eeprom)、寄存器、硬盘、可移动盘、压缩盘只读存储器(cd-rom)、或本领域中所知的任何其他形式的非瞬态存储介质中。示例性存储介质耦合至处理器,以使该处理器可从/向该存储介质读写信息。在替换方案中,存储介质可被整合到处理器。处理器和存储介质可驻留在专用集成电路(asic)中。asic可驻留在计算设备或用户终端中。在替换方案中,处理器和存储介质可作为分立组件驻留在计算设备或用户终端中。
112.提供前面对所公开的实现的描述是为了使本领域技术人员皆能制作或使用所公开的实现。对这些实现的各种修改对于本领域技术人员而言将是显而易见的,并且本文中定义的原理可被应用于其他实现而不会脱离本公开的范围。因此,本公开并非旨在被限定
于本文中示出的实施例,而是应被授予与如由所附权利要求定义的原理和新颖性特征一致的最广的可能范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。