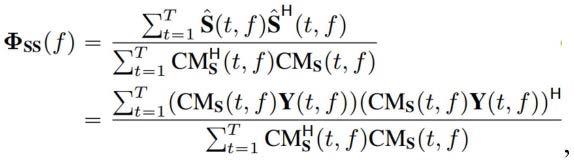技术特征:
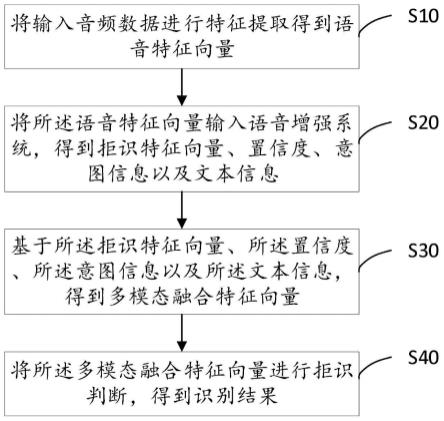
1.一种用于自动语音识别的方法,由处理器执行,包括:接收视频数据和音频数据,所述视频数据和所述音频数据对应于一个或多个说话者;对所接收的音频数据和视频数据进行最小方差无失真响应函数运算;以及基于对所运算的最小方差无失真响应函数的输出的反向传播,生成与所述一个或多个说话者中的目标说话者相对应的预测目标波形。2.根据权利要求1所述的方法,其中,生成所述预测目标波形包括:基于所生成的预测目标波形,计算尺度不变的信源噪声比损失值;反向传播所计算的尺度不变的信源噪声比损失值;以及基于反向传播的尺度不变的信源噪声比损失值,生成所述预测目标波形。3.根据权利要求2所述的方法,其中,所述最小方差无失真响应函数基于复值掩码生成协方差矩阵。4.根据权利要求3所述的方法,其中,通过使用线性激活函数估计所述复值掩码并且将所述复值掩码与所接收的音频数据和视频数据的复频谱相乘,来生成所述预测目标波形。5.根据权利要求4所述的方法,其中,在所述预测目标波形上而不是在所述复值掩码上优化所述尺度不变的信源噪声比损失。6.根据权利要求1所述的方法,其中,所述视频数据对应于由一个或多个摄像机捕获的唇运动数据,并且所述音频数据对应于由一个或多个麦克风捕获的语音。7.根据权利要求6所述的方法,其中,基于所述一个或多个麦克风之间的麦克风间相关性因子以及所捕获的唇运动数据的一个或多个帧之间的帧间相关性因子值,来生成所述预测目标波形。8.一种计算机系统,用于自动语音识别,所述计算机系统包括:一个或多个计算机可读非易失性存储介质,配置为存储计算机程序代码;以及一个或多个计算机处理器,配置为访问所述计算机程序代码,并按照所述计算机程序代码的指令进行操作,所述计算机程序代码包括:接收代码,配置为使得所述一个或多个计算机处理器接收视频数据和音频数据,所述视频数据和所述音频数据对应于一个或多个说话者;应用代码,配置为使得所述一个或多个计算机处理器对所接收的音频数据和视频数据进行最小方差无失真响应函数运算;以及生成代码,配置为使得所述一个或多个计算机处理器基于对所运算的最小方差无失真响应函数的输出的反向传播,生成与所述一个或多个说话者中的目标说话者相对应的预测目标波形。9.根据权利要求8所述的计算机系统,其中,生成所述预测目标波形包括:计算代码,配置为使得所述一个或多个计算机处理器基于所生成的预测目标波形,计算尺度不变的信源噪声比损失值;反向传播代码,配置为使得所述一个或多个计算机处理器反向传播所计算的尺度不变的信源噪声比损失值;以及生成代码,配置为使得所述一个或多个计算机处理器基于反向传播的尺度不变的信源噪声比损失值,生成所述预测目标波形。10.根据权利要求9所述的计算机系统,其中,所述最小方差无失真响应函数基于复值
掩码生成协方差矩阵。11.根据权利要求10所述的计算机系统,其中,通过使用线性激活函数估计所述复值掩码并将所述复值掩码与所接收的音频数据和视频数据的复频谱相乘,来生成所述预测目标波形。12.根据权利要求11所述的计算机系统,其中,在所述预测目标波形上而不是在所述复值掩码上优化所述尺度不变的信源噪声比损失。13.根据权利要求8所述的计算机系统,其中,所述视频数据对应于由一个或多个摄像机捕获的唇运动数据,并且所述音频数据对应于由一个或多个麦克风捕获的语音。14.根据权利要求13所述的计算机系统,其中,基于所述一个或多个麦克风之间的麦克风间相关因子以及所捕获的唇运动数据的一个或多个帧之间的帧间相关因子值,来生成所述预测目标波形。15.一种非易失性计算机可读介质,其上存储有用于查询匹配的计算机程序,所述计算机程序被配置为使得一个或多个计算机处理器执行以下步骤:接收视频数据和音频数据,所述视频数据和所述音频数据对应于一个或多个说话者;对所接收的音频数据和视频数据进行最小方差无失真响应函数运算;以及基对所运算的最小方差无失真响应函数的输出的反向传播,生成与所述一个或多个说话者中的目标说话者相对应的预测目标波形。16.根据权利要求15所述的计算机系统,其中,所述计算机程序还被配置为使得一个或多个计算机处理器执行以下步骤:基于所生成的预测目标波形,计算尺度不变的信源噪声比损失值;反向传播所计算的尺度不变的信源噪声比损失值;以及基于所反向传播的尺度不变的信源噪声比损失值,生成所述预测目标波形。17.根据权利要求16所述的计算机系统,其中,所述最小方差无失真响应函数基于复值掩码生成协方差矩阵,以及。18.根据权利要求17所述的计算机系统,其中,通过使用线性激活函数估计所述复值掩码并将所述复值掩码与所接收的音频数据和视频数据的复频谱相乘,来生成所述预测目标波形。19.根据权利要求15所述的计算机系统,其中,所述视频数据对应于由一个或多个摄像机捕获的唇运动数据,并且所述音频数据对应于由一个或多个麦克风捕获的语音。20.根据权利要求19所述的计算机系统,其中,基于所述一个或多个麦克风之间的麦克风间相关因子以及所捕获的唇运动数据的一个或多个帧之间的帧间相关因子值,来生成所述预测目标波形。
技术总结
提供了一种用于自动语音识别的方法、计算机系统和计算机可读介质。接收视频数据和音频数据,视频数据和音频数据对应于一个或多个说话者。对所接收的音频数据和视频数据进行最小方差无失真响应函数运算。基于对所运算的最小方差无失真响应函数的输出的反向传播,生成与一个或多个说话者中的目标说话者相对应的预测目标波形。测目标波形。
技术研发人员:徐勇 于蒙 张世雄 翁超 刘建明 俞栋
受保护的技术使用者:腾讯美国有限责任公司
技术研发日:2021.06.10
技术公布日:2022/11/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。