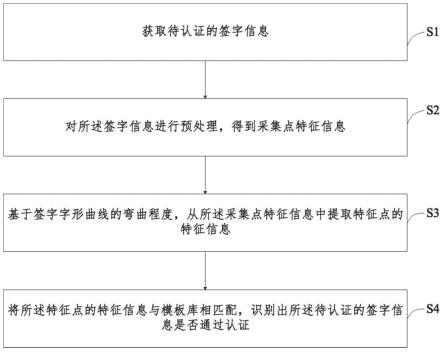
1.本发明涉及批式任务计算平台技术领域,具体为一种大数据批式任务计算 平台技术的方法。
背景技术:
2.实现批处理的技术有许多,现有常见的方式是有限数据流处理,即从某一 个时间点开始处理数据,然后在另一个时间点结束,但是,输入数据可能本身 是有限的,也可能出于分析的目的被人为地设定为有限集,因此在大数据批任 务计算平台的应用中存在一定的问题,导致使用效果有限。
技术实现要素:
3.本发明的目的在于提供一种大数据批式任务计算平台技术的方法,以解决 上述背景技术中提出的问题。
4.为实现上述目的,本发明提供如下技术方案:一种大数据批式任务计算平 台技术的方法,至少包括以下步骤:
5.建立数据湖,配合数据湖将大数据进行存储的同时进行分化处理;
6.采用一个底层引擎,在其上面建设flink,利用flink形成整个大数据批式 任务计算平台的基础框架,使得平台同时支持流处理和批处理;
7.在平台内扩展sql语言,采用sql语言对数据湖中的数据进行高效批量统 计,同时充分利用大数据批式任务计算平台的内部数据结构以及全局/辅助索引 进行sql执行加速,可以满足高速的olap数据分析应用需求;同时也支持高速 的sql离线批处理。支持在在一个事务中批量执行多个增删改操作,在正式提 交前事务不生效,可以回退;
8.在基础框架内侧搭载列式存储,通过将数据按列的形式存储能够减少查询 过程中从磁盘中读取的数据量、减少cpu处理数据量,从而能够极大地提升查 询性能;
9.在基础框架内搭载mpp查询引擎;
10.在底层引擎外侧搭建向量化执行引擎;
11.在基础框架内增加代码动态生成技术;
12.在基础框架内侧搭载预聚合技术,形成整体的大数据批式任务计算平台
13.优选的,所述flink至少包括有第一机制和第二机制
14.优选的,所述flink的第一机制至少包括以下内容:
15.检查点机制和状态机制:用于实现容错、有状态的处理;
16.水印机制:用于实现事件时钟;
17.窗口和触发器:用于限制计算范围,并定义呈现结果的时间。
18.优选的,所述flink的第二机制至少包括以下内容:
19.用于调度和恢复的回溯法:由microsoftdryad引入,现在几乎用于所有批 处理器;
20.用于散列和排序的特殊内存数据的结构:可以在需要时,将一部分数据从 内存溢出到硬盘上;
21.优化器:尽可能地缩短生成结果的时间优选的,yy4。
22.与现有技术相比,本发明的有益效果是:
23.本发明通过数据湖与品台整体框架的配合设计,使得平台便于采用无限流 处理的方式满足高速的olap数据分析应用需求,同时也支持高速的sql离线批 处理,并具备更好的使用效果。
具体实施方式
24.一种大数据批式任务计算平台技术的方法,至少包括以下步骤:
25.建立数据湖,配合数据湖将大数据进行存储的同时进行分化处理;
26.采用一个底层引擎,在其上面建设flink,利用flink形成整个大数据批式 任务计算平台的基础框架,使得平台同时支持流处理和批处理;
27.采用flink因为既可以将数据当作无限流来处理,也可以将它当作有限流来处理。
28.在平台内扩展sql语言,采用sql语言对数据湖中的数据进行高效批量统 计,同时充分利用大数据批式任务计算平台的内部数据结构以及全局/辅助索引 进行sql执行加速,可以满足高速的olap数据分析应用需求;同时也支持高速 的sql离线批处理。支持在在一个事务中批量执行多个增删改操作,在正式提 交前事务不生效,可以回退;
29.在基础框架内侧搭载列式存储;
30.对于olap数据来说,每个查询请求会请求大量的数据,但是并不会请求所 有列的数据,通过将数据按列的形式存储能够减少查询过程中从磁盘中读取的 数据量、减少cpu处理数据量,从而能够极大地提升查询性能;
31.在基础框架内搭载mpp查询引擎;
32.为了提升查询性能需要能够让查询的执行充分利用多核、多机的计算能力, 这样一个查询就能够得到成倍的性能提升,mpp技术正是一种能够将一个查询语 句分布在多机上执行的技术,现代的数据仓库为了能够得到快速执行性能需要 采用mpp技术;
33.在底层引擎外侧搭建向量化执行引擎;
34.向量化执行引擎是将数据按照向量的方式进行批处理从而能够达到更高的 处理性能,向量化执行引擎相比于传统的数据库计算引擎会获得近10倍的性能 提升,向量化执行引擎利用当前的主流cpu都提供的simd指令,simd指令可以 在一个指令周期中处理更多的数据,这样cpu就能够在相同的时间内,处理更 多的数据,除了利用simd指令外,向量化执行引擎还会最大限度的减少函数调 用的开销,并且能够更加充分的利用cpu提供的cache,使用更少的指令完成同 样的工作。
35.在基础框架内增加代码动态生成技术;
36.动态代码生成技术也叫做sql编译技术,就是能够将sql动态编译成可执 行的代码,从而提高单个查询的执行性能。如果没有动态代码生成技术的话, 执行引擎对于任何查询请求都是一样处理的,中间可能会存在很多条件判断从 而造成cpu的执行效率不高,通过代码动态生成技术,可以极大的减少分支判 断,从而能够提升查询的整体执行效率。
37.在基础框架内侧搭载预聚合技术,形成整体的大数据批式任务计算平台。
38.对于数据仓库的查询请求模式来说,可以预先创建一些cube来提升一些查 询请求的性能,一方面这样可以使数仓处理一些请求的时候更加快速,而且能 够在pb级别的数据集上达到亚秒级响应时间从而支持高并发查询场景,所以新 型的数据仓库也需要支持预聚合技术来提升查询性能。
39.flink至少包括有第一机制和第二机制;
40.flink的第一机制至少包括以下内容:
41.检查点机制和状态机制:用于实现容错、有状态的处理;
42.水印机制:用于实现事件时钟;
43.窗口和触发器:用于限制计算范围,并定义呈现结果的时间。
44.flink的第二机制至少包括以下内容:
45.用于调度和恢复的回溯法:由microsoftdryad引入,现在几乎用于所有批 处理器;
46.用于散列和排序的特殊内存数据的结构:可以在需要时,将一部分数据从 内存溢出到硬盘上;
47.优化器:尽可能地缩短生成结果的时间。
48.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节, 而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现 本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非 限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落 在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
技术特征:
1.一种大数据批式任务计算平台技术的方法,其特征在于:至少包括以下步骤:建立数据湖,配合数据湖将大数据进行存储的同时进行分化处理;采用一个底层引擎,在其上面建设flink,利用flink形成整个大数据批式任务计算平台的基础框架,使得平台同时支持流处理和批处理;在平台内扩展sql语言,采用sql语言对数据湖中的数据进行高效批量统计;在基础框架内侧搭载列式存储;在基础框架内搭载mpp查询引擎;在底层引擎外侧搭建向量化执行引擎;在基础框架内增加代码动态生成技术;在基础框架内侧搭载预聚合技术,形成整体的大数据批式任务计算平台。2.根据权利要求1所述的一种大数据批式任务计算平台技术的方法,其特征在于:所述flink至少包括有第一机制和第二机制。3.根据权利要求1所述的一种大数据批式任务计算平台技术的方法,其特征在于:所述flink的第一机制至少包括以下内容:检查点机制和状态机制;水印机制;窗口和触发器。4.根据权利要求1所述的一种大数据批式任务计算平台技术的方法,其特征在于:所述flink的第二机制至少包括以下内容:用于调度和恢复的回溯法;用于散列和排序的特殊内存数据的结构;优化器。
技术总结
本发明公开了一种大数据批式任务计算平台技术的方法,涉及批式任务计算平台技术领域。本发明至少包括以下步骤:建立数据湖,配合数据湖将大数据进行存储的同时进行分化处理;采用一个底层引擎,在其上面建设Flink,利用Flink形成整个大数据批式任务计算平台的基础框架,使得平台同时支持流处理和批处理;在平台内扩展SQL语言,采用SQL语言对数据湖中的数据进行高效批量统计。本发明通过数据湖与平台整体框架的配合设计,使得平台便于采用无限流处理的方式满足高速的OLAP数据分析应用需求,同时也支持高速的SQL离线批处理,并具备更好的使用效果。的使用效果。
技术研发人员:魏俊杰 蓝岸 陈晓玩 冷佳琪 陈飞
受保护的技术使用者:深圳新闻网传媒股份有限公司
技术研发日:2022.04.14
技术公布日:2022/11/1
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。