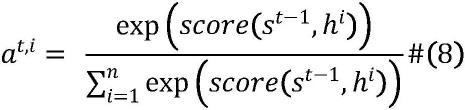
1.本发明涉及中文命名实体识别技术领域,尤其涉及一种基于多分词和多层双向长短期记忆的中文命名实体识别方法。
背景技术:
2.在自然语言处理的任务中,命名实体识别是具有挑战的基础性工作。命名实体识别作为自然语言处理中的一项基础任务,对信息抽取、知识图谱构建等起着关键作用。在一些特定领域,命名实体识别的研究已经得到了广泛而成熟的应用。目前命名实体识别的方法主要集中在基于词典和规则的方法、基于统计机器学习的方法和基于深度学习的方法。
3.基于词典和规则方法是通过使用字符串匹配和人工构建实体抽取规则来进行实体识别,这种方法在小数据集上可以获得较好的准确率,但是随着数据集的增加,这种方法不在适用。基于统计机器学习方法有隐马尔可夫模型、支持向量机、条件随机场等。虽然这些方法在一定程度上减少了基于词汇和规则的工作量,但仍不可避免的需要人工来指定特征和外部知识信息。因此这些方法一般只能适应于当前领域,很难直接解决一个全新领域的命名实体识别问题。基于深度学习方法近年来得到广泛的应用和突破性进展,包括bert模型、cnn模型、bilstm模型等。深度学习方法与机器学习模型相比,能学习到高维度与深层次的特征表示,有利于提高实体识别的泛化能力。
4.虽然现有研究的深度学习方法在医学命名实体识别取得了较好的效果,但是医学命名实体的识别仍面临着一些困难与挑战:
5.(1)现有方法的单一粒度的文本表示只能获取文本的全局语境特征,缺乏局部语境特征信息,从而阻碍了模型性能的进一步提升;
6.(2)普遍采用单个的bilstm只能捕捉特定维度的语境特征,缺乏考虑其他维度下语境特征对模型性能的贡献;
7.因此,设计一种基于多分词和多层双向长短期记忆的中文命名实体识别方法是很有必要的。
技术实现要素:
8.本发明解决的问题在于提供一种基于多分词和多层双向长短期记忆的中文命名实体识别方法,通过对命名实体识别技术中广泛使用的bert-bilstm-crf模型进行了修改;引入了多分词模块,所有的数据集通过在该模块中都会被切分成很多词语,然后通过word-level bilstm来提取局部特征;引入了多层bilstm模块,该模块由bilstm和attention组成,通过对bilstm设置不同隐藏层参数,可以学习到不同维度的文本语境特征,然后由attention捕获重要信息;通过这两个模块可以丰富模型学习过程中的信息,从而提高命名实体识别的准确率。
9.为了实现上述目的,本发明采用了如下技术方案:
10.一种基于多分词和多层双向长短期记忆的中文命名实体识别方法,通过对bert-bilstm-crf模型的修改,提高命名实体的识别精度;包括以下步骤:
11.步骤s1:确定命名实体识别模型的输入与输出:以医疗文本为研究对象,将带有实体标注的医疗文本数据集作为命名实体识别模型的输入,模型的输出是对数据集进行医疗实体预测后给出的实体标注结果;
12.步骤s2:设计多分词和多层双向长短期记忆的医疗命名实体识别模型,该模型由输入层、词嵌入层、语义特征提取层、crf层和输出层构成;该模型包括bert预训练语言模型、双向长短期记忆模型bilstm、注意力机制以及条件随机场crf;该医疗命名实体识别模型的主要方法依次为:
13.①
输入层:该层用于输入数据集;
14.②
词嵌入层:该层通过bert预训练语言模型将文本中的字符编码为向量表示形式;通过bert模型后的输出结果表示为v=v1,v2,...,vn,其中n代表当前句子所包含的字符总数;
15.③
语义特征提取层:该层由多分词模块和多层bilstm模块联合构成。其中多分词模块主要通过word-levei bilstm模块提取特征,多层bilstm模块通过设置不同大小的隐藏层,从而获取不同维度的特征信息,并利用注意力机制捕获重要信息;具体过程为:
16.1)多分词模块
17.word-level bilstm模块基于bilstm模型构成;bilstm是由前向lstm与后向lstm组合而成;lstm用数学表达式表示如公式1-6所示:
18.f
t
=σ(wf·
[h
t-1
,x
t
] bf)#(1)
[0019]it
=σ(wi·
[h
t-1
,x
t
] bi)#(2)
[0020]ct
=tanh(wc·
[h
t-1
,x
t
] bc)#(3)
[0021]ct
=f
t
*c
t-1
i
t
*c
t
#(4)
[0022]ot
=σ(wo·
[h
t-1
,x
t
] bo)#(5)
[0023]ht
=o
t
*tanh(c
t
)#(6)
[0024]
其中t和t-1分别表示当前时刻和上一时刻,h表示隐藏状态,σ和tanh分别表示sigmoid激活函数和tanh激活函数;w代表权重矩阵、b代表偏置向量;*代表点积;
[0025]
bilstm的输出为正向lstm输出和负向lstm输出的拼接,表示为
[0026]
2)多层bilstm模块
[0027]
该模块集成了bilstm和attention机制;通过对bilstm设置不同大小的隐藏层,以提取不同维度的语境特征;attention机制用于区分不同特征的不同重要程度;
[0028]
注意力机制层对bilstm层输出的特征向量h
t
进行权重分配,计算得到第t个字在bilstm层和注意力层的共同输出特征向量w
t(k)
,用数学公式表示如公式7-9:
[0029]
[0030][0031]
score(s
t
,hi)=vtanh(w[s
t
,hi])#(9)
[0032]
其中a
t,i
为注意力函数,score函数为对齐模型,它基于i时刻的输入和输出的匹配程度分配分数,定义每个输出给每个输入隐藏状态多大的权重;w
t(k)
表示第t个字经过第k个mba模型的输出,其中k的取值是1,2;
[0033]
义特征提取层的最终输出o是多分词模块输出与多层bilstm输出融合得到,用数学表达式表示如公式10:
[0034][0035]
则该层模型最终的输出序列为[o1,o2...,on];
[0036]
④
crf层:
[0037]
该层的主要作用是对标签进行预测;在训练数据的过程中,该层自动学习标签之间的约束,确保预测的标签是合法的;矩阵p是评分矩阵,p
i,j
是将第i个字符分类为第j个标记的概率值,a
i,j
是从第i个标记到第j个标记的状态转移分数;如果输入句子x=(x1,x2…
,xn),标记序列为y=(y1,y2,...,yn),得分如下:
[0038][0039]
对于score(x,y)使用softmax函数进行归一化处理,公式如下:
[0040][0041]
在训练时,对于训练样本(x,y
x
),采用以下公式最大化标记序列的对数概率;
[0042][0043]
本实验采用维特比算法求动态规划的概率最大路径,公式如下:
[0044][0045]y*
是得分函数中得分最高的序列,即模型的期望输出,是最大化得分函数;
[0046]
⑤
输出层:该层用于输入数据集中全部文本的标注结果;评价指标由精确率p、召回率r和f1值衡量,如公式15、16和17所示:
[0047]
[0048][0049][0050]
其中t
p
表示模型正确识别出的医疗实体的个数,f
p
表示模型识别出的不相关医疗实体的个数,fn为模型未能识别的相关医疗实体的个数;f1是p和r的加权调和平均值。
[0051]
本发明的有益效果是:本发明,通过进一步强化模型的文本的语境特征提取性能,一方面考虑了多词切分的方法来增加局部语境特征,获取不同维度的特征信息,并利用注意力机制捕获重要信息,另一方面引入了多层双向长短期记忆方法,通过设置不同深度的bilstm模型来增加全局语境特征以及引入了医学词典这一外部知识,通过丰富模型学习过程中的语义特征信息,从而进一步提升命名实体识别任务的精度。
附图说明
[0052]
图1是本发明的医疗命名实体识别模型的整体处理流程;
[0053]
图2是本发明中多分词模块的整体处理过程;
[0054]
图3是本发明中多层bilstm模块的整体处理过程;
具体实施方式
[0055]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0056]
下面给出具体实施例。
[0057]
参见图1-3,一种基于多分词和多层双向长短期记忆的中文命名实体识别方法,通过对bert-bilstm-crf模型的修改,提高命名实体的识别精度;结合附图1,包括以下步骤:
[0058]
步骤s1:确定命名实体识别模型的输入与输出:以医疗文本为研究对象,将带有实体标注的医疗文本数据集作为命名实体识别模型的输入,模型的输出是对数据集进行医疗实体预测后给出的实体标注结果;
[0059]
步骤s2:设计多分词和多层双向长短期记忆的医疗命名实体识别模型,该模型由输入层、词嵌入层、语义特征提取层、crf层和输出层构成;该模型包括bert预训练语言模型、双向长短期记忆模型bilstm、注意力机制以及条件随机场crf;该医疗命名实体识别模型的主要方法依次为:
[0060]
①
输入层:该层用于输入数据集;
[0061]
②
词嵌入层:该层通过bert预训练语言模型将文本中的字符编码为向量表示形式;通过bert模型后的输出结果表示为v=v1,v2,...,vn,其中n代表当前句子所包含的字符总数;
[0062]
③
语义特征提取层:该层由多分词模块和多层bilstm模块联合构成。其中多分词模块主要通过word-levei bilstm模块提取特征,多层bilstm模块通过设置不同大小的隐藏层,从而获取不同维度的特征信息,并利用注意力机制捕获重要信息;具体过程为:
[0063]
1)多分词模块
[0064]
word-level bilstm模块基于bilstm模型构成;bilstm是由前向lstm与后向lstm组合而成;lstm用数学表达式表示如公式1-6所示:
[0065]ft
=σ(wf·
[h
t-1
,x
t
] bf)#(1)
[0066]it
=σ(wi·
[h
t-1
,x
t
] bi)#(2)
[0067]ct
=tanh(wc·
[h
t-1
,x
t
] bc)#(3)
[0068]ct
=f
t
*c
t-1
i
t
*c
t
#(4)
[0069]ot
=σ(wo·
[h
t-1
,x
t
] bo)#(5)
[0070]ht
=o
t
*tanh(c
t
)#(6)
[0071]
其中t和t-1分别表示当前时刻和上一时刻,h表示隐藏状态,σ和tanh分别表示sigmoid激活函数和tanh激活函数;w代表权重矩阵、b代表偏置向量;*代表点积;
[0072]
bilstm的输出为正向lstm输出和负向lstm输出的拼接,表示为
[0073]
多分词模块如附图2所示,集成多个bilstm;以文本“产后诊断为糖尿病”为例,其经过全词切分后的序列表示为[“产后”,“诊断”,“诊断为”,“糖尿”,“糖尿病”],每个词都将经过bilstm模型进行词内局部语境特征捕捉;
[0074]
附图2中图中vi代表词嵌入层对第i个字生成的字符向量;wordsi代表多词切分后的第i个词,代表某一词语中第j次出现时第i个字经过词级局部特征分析后的输出表示,wi代表第i个字经过word-levei bilstm模块后的输出;
[0075]
2)多层bilstm模块
[0076]
该模块集成了bilstm和attention机制,见附图3;通过对bilstm设置不同大小的隐藏层,以提取不同维度的语境特征;attention机制用于区分不同特征的不同重要程度;
[0077]
注意力机制层对bilstm层输出的特征向量h
t
进行权重分配,计算得到第t个字在bilstm层和注意力层的共同输出特征向量w
t(k)
,用数学公式表示如公式7-9:
[0078][0079][0080]
score(s
t
,hi)=vtanh(w[s
t
,hi])#(9)
[0081]
其中a
t,i
为注意力函数,score函数为对齐模型,它基于i时刻的输入和输出的匹配程度分配分数,定义每个输出给每个输入隐藏状态多大的权重;w
t(k)
表示第t个字经过第k个mba模型的输出,其中k的取值是1,2;
[0082]
义特征提取层的最终输出0是多分词模块输出与多层bilstm输出融合得到,用数学表达式表示如公式10:
[0083]
[0084]
则该层模型最终的输出序列为[o1,o2...,on];
[0085]
④
crf层:
[0086]
该层的主要作用是对标签进行预测;在训练数据的过程中,该层自动学习标签之间的约束,确保预测的标签是合法的;矩阵p是评分矩阵,p
i,j
是将第i个字符分类为第j个标记的概率值,a
i,j
是从第i个标记到第j个标记的状态转移分数;如果输入句子x=(x1,x2…
,xn),标记序列为y=(y1,y2,...,yn),得分如下:
[0087][0088]
对于score(x,y)使用softmax函数进行归一化处理,公式如下:
[0089][0090]
在训练时,对于训练样本(x,y
x
),采用以下公式最大化标记序列的对数概率;
[0091][0092]
本实验采用维特比算法求动态规划的概率最大路径,公式如下:
[0093][0094]y*
是得分函数中得分最高的序列,即模型的期望输出,是最大化得分函数;
[0095]
⑤
输出层:该层用于输入数据集中全部文本的标注结果;评价指标由精确率p、召回率r和f1值衡量,如公式15、16和17所示:
[0096][0097][0098][0099]
其中t
p
表示模型正确识别出的医疗实体的个数,f
p
表示模型识别出的不相关医疗实体的个数,fn为模型未能识别的相关医疗实体的个数;f1是p和r的加权调和平均值。
[0100]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。