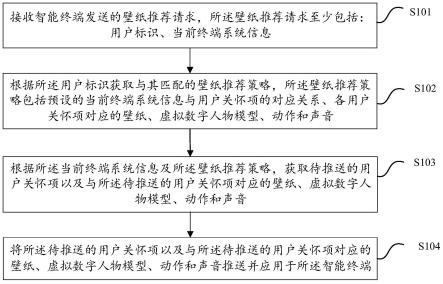
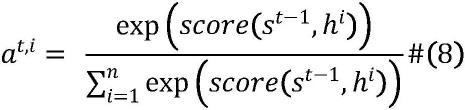技术特征:
1.一种基于多分词和多层双向长短期记忆的中文命名实体识别方法,其特征在于,通过对bert-bilstm-crf模型的修改,提高命名实体的识别精度;包括以下步骤:步骤s1:确定命名实体识别模型的输入与输出:以医疗文本为研究对象,将带有实体标注的医疗文本数据集作为命名实体识别模型的输入,模型的输出是对数据集进行医疗实体预测后给出的实体标注结果;步骤s2:设计多分词和多层双向长短期记忆的医疗命名实体识别模型,该模型由输入层、词嵌入层、语义特征提取层、crf层和输出层构成;该模型包括bert预训练语言模型、双向长短期记忆模型bilstm、注意力机制以及条件随机场crf;该医疗命名实体识别模型的主要方法依次为:
①
输入层:该层用于输入数据集;
②
词嵌入层:该层通过bert预训练语言模型将文本中的字符编码为向量表示形式;通过bert模型后的输出结果表示为v=v1,v2,...,v
n
,其中n代表当前句子所包含的字符总数;
③
语义特征提取层:该层由多分词模块和多层bilstm模块联合构成。其中多分词模块主要通过word-levei bilstm模块提取特征,多层bilstm模块通过设置不同大小的隐藏层,从而获取不同维度的特征信息,并利用注意力机制捕获重要信息;具体过程为:1)多分词模块word-level bilstm模块基于bilstm模型构成;bilstm是由前向lstm与后向lstm组合而成;lstm用数学表达式表示如公式1-6所示:f
t
=σ(w
f
·
[h
t-1
,x
t
] b
f
)#(1)i
t
=σ(w
i
·
[h
t-1
,x
t
] b
i
)#(2)c
t
=tanh(w
c
·
[h
t-1
,x
t
] b
c
)#(3)c
t
=f
t
*c
t-1
i
t
*c
t
#(4)o
t
=σ(w
o
·
[h
t-1
,x
t
] b
o
)#(5)h
t
=o
t
*tanh(c
t
)#(6)其中t和t-1分别表示当前时刻和上一时刻,h表示隐藏状态,σ和tanh分别表示sigmoid激活函数和tanh激活函数;w代表权重矩阵、b代表偏置向量;*代表点积;bilstm的输出为正向lstm输出和负向lstm输出的拼接,表示为2)多层bilstm模块该模块集成了bilstm和attention机制;通过对bllstm设置不同大小的隐藏层,以提取不同维度的语境特征;attention机制用于区分不同特征的不同重要程度;注意力机制层对bilstm层输出的特征向量h
t
进行权重分配,计算得到第t个字在bilstm层和注意力层的共同输出特征向量w
t(k)
,用数学公式表示如公式7-9:9:score(s
t
,h
i
)=vtanh(w[s
t
,h
i
])#(9)
其中a
t,j
为注意力函数,score函数为对齐模型,它基于i时刻的输入和输出的匹配程度分配分数,定义每个输出给每个输入隐藏状态多大的权重;w
t(k)
表示第t个字经过第k个mba模型的输出,其中k的取值是1,2;义特征提取层的最终输出0是多分词模块输出与多层bilstm输出融合得到,用数学表达式表示如公式10:则该层模型最终的输出序列为[o1,o2...,o
n
];
④
crf层:该层的主要作用是对标签进行预测;在训练数据的过程中,该层自动学习标签之间的约束,确保预测的标签是合法的;矩阵p是评分矩阵,p
i,j
是将第i个字符分类为第j个标记的概率值,a
i,j
是从第i个标记到第j个标记的状态转移分数;如果输入句子x=(x1,x2…
,x
n
),标记序列为y=(y1,y2,...,y
n
),得分如下:对于score(x,y)使用softmax函数进行归一化处理,公式如下:在训练时,对于训练样本(x,y
x
),采用以下公式最大化标记序列的对数概率;本实验采用维特比算法求动态规划的概率最大路径,公式如下:y
*
是得分函数中得分最高的序列,即模型的期望输出,是最大化得分函数;
⑤
输出层:该层用于输入数据集中全部文本的标注结果;评价指标由精确率p、召回率r和f1值衡量,如公式15、16和17所示:和f1值衡量,如公式15、16和17所示:和f1值衡量,如公式15、16和17所示:
其中t
p
表示模型正确识别出的医疗实体的个数,f
p
表示模型识别出的不相关医疗实体的个数,f
n
为模型未能识别的相关医疗实体的个数;f1是p和r的加权调和平均值。
技术总结
本发明公开了一种基于多分词和多层双向长短期记忆的中文命名实体识别方法,通过对BERT-BILSTM-CRF模型的修改,提高命名实体的识别精度;确定命名实体识别模型的输入与输出:以医疗文本为研究对象,将带有实体标注的医疗文本数据集作为命名实体识别模型的输入,模型的输出是对数据集进行医疗实体预测后给出的实体标注结果;本发明,通过进一步强化模型的文本的语境特征提取性能,一方面考虑了多词切分的方法来增加局部语境特征,另一方面引入了多层双向长短期记忆方法,通过设置不同深度的BILSTM模型来增加全局语境特征以及引入了医学词典这一外部知识,通过丰富模型学习过程中的语义特征信息,从而进一步提升命名实体识别任务的精度。识别任务的精度。
技术研发人员:张锋 程振宁 陈婕卿 曾可 姜会珍 李大伟
受保护的技术使用者:北京安妮福克斯信息咨询有限公司
技术研发日:2022.07.11
技术公布日:2022/10/25
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。